分享一个企业备案查询的脚本-2
声明:本资料仅供学习交流,严禁使用于商业、非法用途!!!
之前不是发了一个备案查询的脚本嘛,详情可见[bspost cid="3384"]
有师傅反应说接口数据不太对,因为那个接口用的都是缓存库,确实太老了,新的得vip(手动狗头)
根据我的需求确实能满足,以下改的就纯单学习交流了,获取的还是比之前要全很多
另外师傅们注意,还是根据需求来写的,所以仅限根据企业名称获取备案功能!!!
还有,没去细扣js了,直接用的selenium,师傅们如果使用可能还得去装个驱动,这个直接上网搜就行,毕竟在工作(摸鱼)时间写的,发现还挺好用的,对token验证还是乱杀,也学习了一波
直接上代码吧
import re
import time
import random
import csv
from urllib import parse
from urllib.parse import quote
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from pathlib import Path
import warnings
#忽略warning
warnings.filterwarnings("ignore")
# 定义备案爬虫类
class BeianSpider(object):
# 获取url
def __init__(self):
#判断beian.csv是否存在,不存在则创建
my_file = Path("beian.csv")
if my_file.exists():
print("[+]beian.csv已存在!")
else:
with open('beian.csv','a',newline='',encoding="utf-8") as f:
#生成csv操作对象
writer = csv.writer(f)
header = ["主办单位名称","单位性质","网站备案/许可证号","网站名称","网站首页网址","审核时间","记录时间","备案域名"]
writer.writerow(header)
print("[+]beian.csv已创建!")
def get_url(self,word):
url = 'https://icp.chinaz.com/record/{}'
name=quote(word, 'utf-8')
#params = parse.urlencode(name)
url = url.format(name)
#print(url)
return url
# 正则行数,提取内容
def parse_html(self,name,html):
# 正则表达式
re_bds = '<td>(.*?)</td><td class="tc">(.*?)</td><td>(.*?)</td><td>(.*?)</td><td class="Now"><span><a href="//(.*?)".*?<td class="tc">(.*?)</td><td class="tc">(.*?)</td><td class="tc"><a href="/record/(.*?)".*?'
# 生成正则表达式对象
pattern = re.compile(re_bds,re.S)
r_list = pattern.findall(html)
print(r_list)
self.save_html(r_list)
with open('success.txt','a+',newline='',encoding="utf-8") as f:
f.write(name)
f.write('\n')
# 保存数据函数,使用python内置csv模块
def save_html(self,r_list):
#生成文件对象
with open('beian.csv','a',newline='',encoding="utf-8") as f:
#生成csv操作对象
writer = csv.writer(f)
#整理数据
lenth = len(r_list)
#print(lenth)
for i in range(lenth):
#主办单位名称
save_organizer_name = r_list[i][0]
#print(name)
#单位性质
save_unit_nature = r_list[i][1]
#网站备案/许可证号
save_ICP_number = r_list[i][2]
#网站名称
save_website_name = r_list[i][3]
#网站首页网址
save_website_index = r_list[i][4]
#审核时间
save_review_time = r_list[i][5]
#记录时间
save_record_time = r_list[i][6]
#备案域名
save_ICP_domain = r_list[i][7]
L = [save_organizer_name,save_unit_nature,save_ICP_number,save_website_name,save_website_index,save_review_time,save_record_time,save_ICP_domain]
# 写入csv文件
writer.writerow(L)
print("[+]",r_list[0][0],"查询写入完成")
# 主函数
def run(self):
try:
url = "http://icp.chinaz.com/record"
#禁止浏览器窗口弹出
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
#browser = webdriver.Chrome()
with open('qiye.txt','r',newline='',encoding="utf-8") as f:
data = f.read().splitlines()
lenth = len(data)
for i in range(lenth):
#print(data[i])
url = self.get_url(data[i])
browser.get(url)
try:
#设置显示等待时间及标签,此处可改,实测受网络波动影响
wait = WebDriverWait(browser, 5)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'bg-list')))
#显示等待没有找到标签会报错,此处写入faild.txt后跳到下一个查找
except Exception as e:
with open('faild.txt','a+',newline='',encoding="utf-8") as f:
f.write(data[i])
f.write('\n')
print("[-]",data[i],"无备案信息")
continue
html = browser.page_source
self.parse_html(data[i],html)
#随机延时,根据需求设置
#time.sleep(random.uniform(1,2))
print("[+]","All Finished")
#except Exception:
finally:
browser.close()
# 以脚本方式启动
if __name__ == '__main__':
#捕捉全局异常错误
try:
spider = BeianSpider()
spider.run()
except Exception as e:
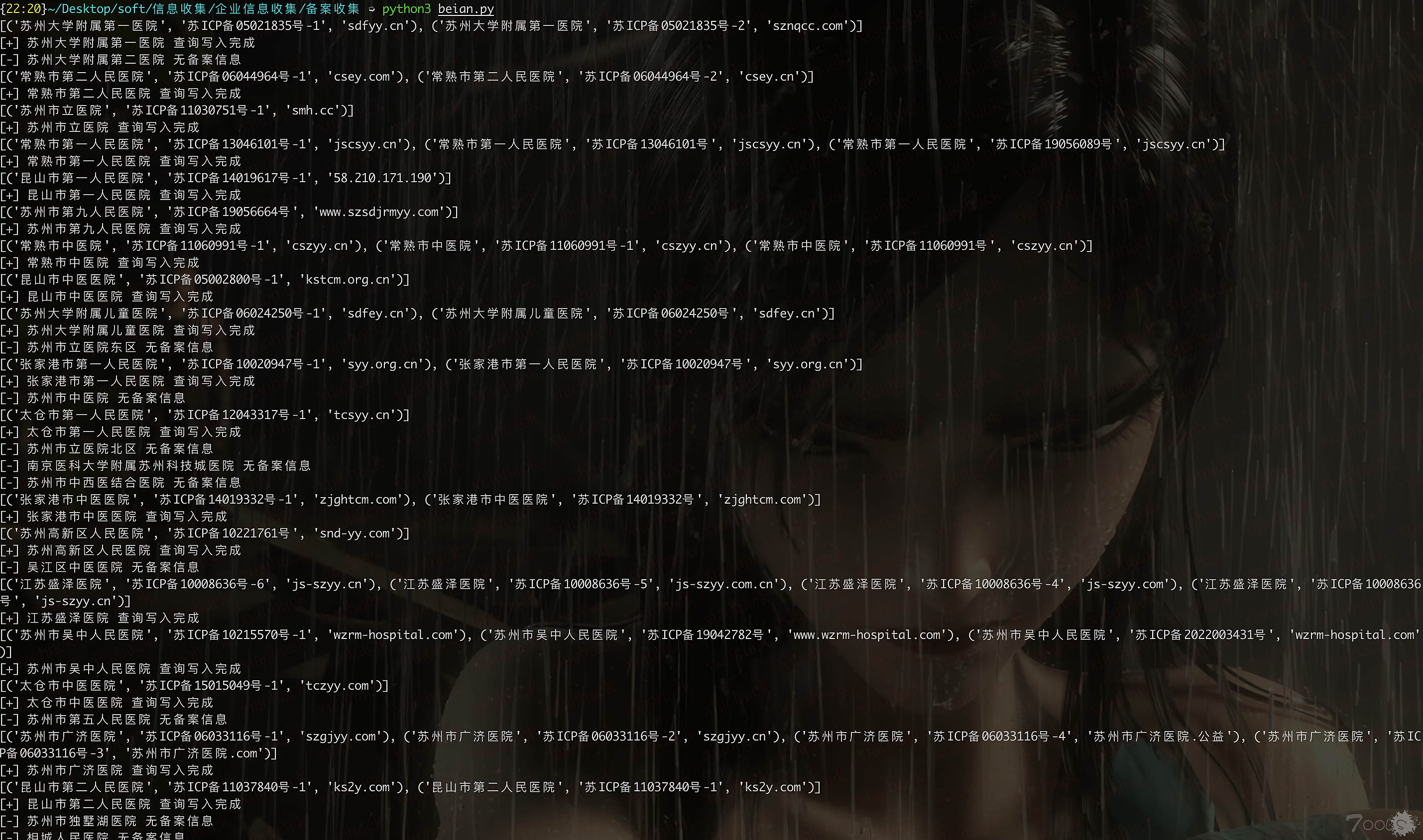
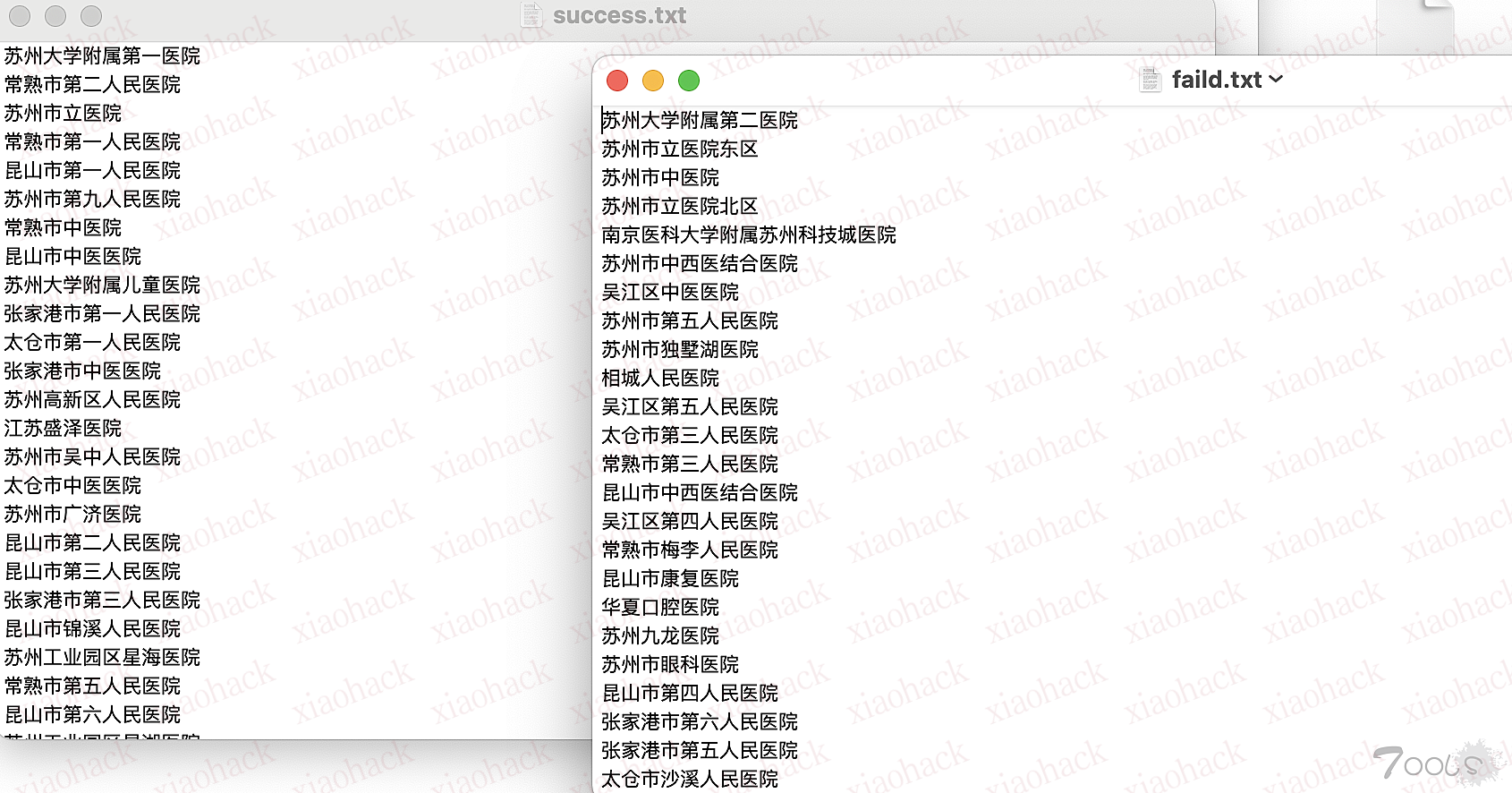
print("错误:",e)使用还是跟之前一样,在qiye.txt里写上所有企业名称,一行一个,直接python3运行beian.py就好,然后脚本跑起来会输出到beian.csv里,同时输出success和faild的企业名,这样没找到备案的企业还能找其他站捞一波,以网上随便找的全省医院为例,结果见下图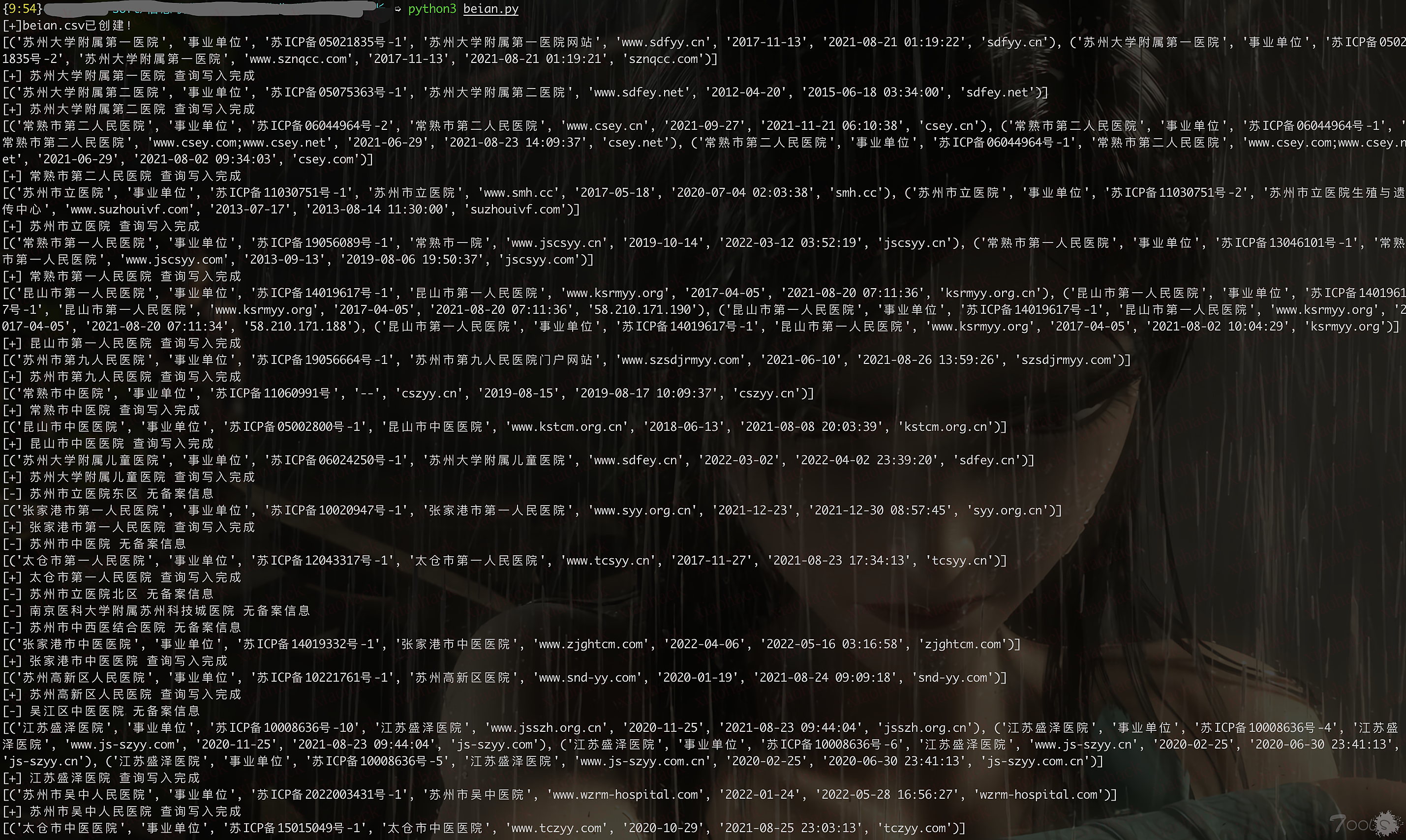

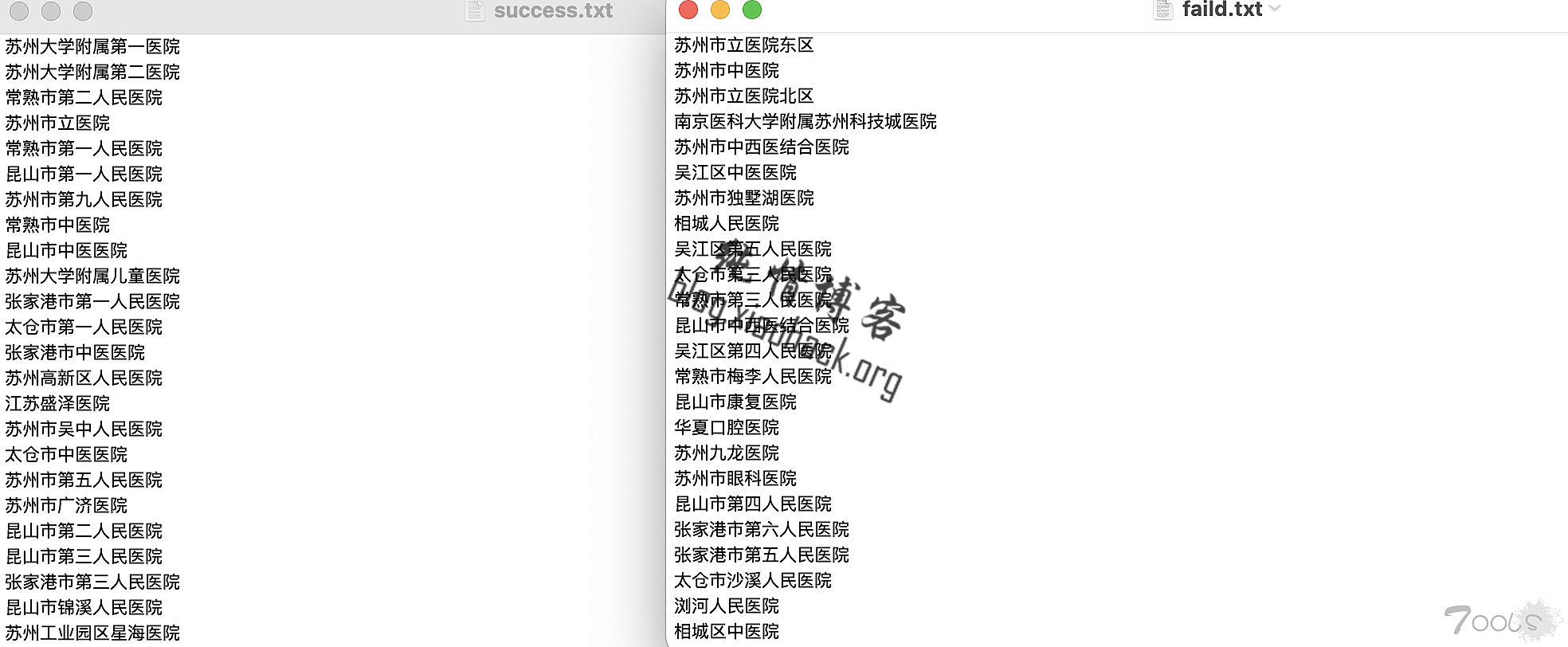

实测还是获取的信息多一点,没vip只能查一页,所以就只获取一页了
而且实测跟网速还是有挺大关系,师傅们可以看看代码微调下参数,等待啥的
另外祝师傅们七夕快乐啊~~
有的人七夕有花有爱有对象,有的人居然从六月一直加班到现在,需坚强