立省 200 刀!Claude Code 接入 GMI Cloud Inference Engine API 教程>>
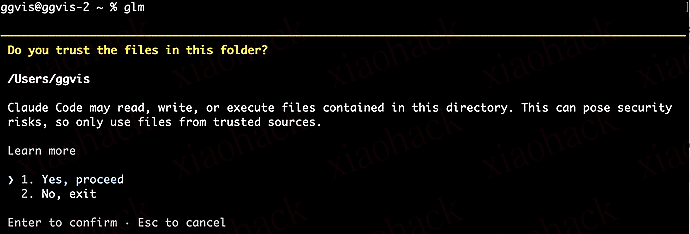
GMI Cloud Inference Engine 是全球 AI 模型统一接入与在线使用的“高性能推理引擎平台”,底层搭载 H100/H200 芯片,集成全球近百个最前沿的大语言模型和视频生成模型,如 Gemini、Claude、Minimax、DeepSeek、GPT、Qwen、Kling 等,为 AI 开发者与企业提供速度更快、质量更高的模型服务。 欢迎来到!🎉🎉🎉 GMI Cloud Inference Engine AI 场景实践案例集【AI Coding 篇】之二。 **本期任务目标:**在 Windows 终端里,使用 Claude Code 命令行工具,连接 GMI Cloud Inference Engine 的 MiniMax 模型 API。 Claude Code 是 Anthropic 推出的命令行 AI 编程工具,基于 Claude 大模型,可在终端 / IDE 中用自然语言交互,深度理解代码库,支持跨文件编辑、Git 协作。其具有 agent 优势,与超大上下文+多文件编辑+终端原生+安全自主执行+顶级模型能力,在处理大型项目、复杂重构和企业级开发时展现出明显优势。 本文将以接入 Inference Engine 中的 MiniMax-M2 api 为例,详细讲解在 Claude Code 中接入 api 的过程。Token福利文末自行领取!! MiniMax-M2 界面: https://console.gmicloud.ai/playground/llm/minimax-m2/bbfb2cb... 01 准备工作 Get ready? 确保你已经掌握 AI Coding 基础知识,没有可看上一篇: 附上链接~ Kooty,公众号:GMI Cloud 黑板报小白友好教程!如何在 Cursor 接入 GMI Cloud 的 API 确保你的电脑已经安装了: 02 接入步骤 API Connection Guide 步骤 1:安装必要工具 打开 PowerShell,依次运行以下命令: 1.安装 Claude Code 工具 2.安装 LiteLLM(带代理功能) 如果不懂怎么安装,可以直接在 Cursor 聊天框输入(亲测 Gemini3 可以直接一步到位,模型不够好可能中途会报错): 无论是通过哪种安装方式,Claude Code 在安装后都会引导你配置参数或者注册登录,如果你有账号可以按照引导往下走。如果没有、希望和笔者一样直接接入自己的(便宜的)api,可以登录到非得付费的那一步退出,然后继续步骤 2。 步骤 2:启动“翻译官” (LiteLLM) 我们需要启动一个本地服务,用来做连接我们的 api 和 Anthropic 之间的桥梁。在 PowerShell 中运行(替换为你自己的 API Key): ✅ 成功标志:看到 Running on http://0.0.0.0:4000。 ⚠️ 注意:这个窗口不要关闭。步骤 3 打开一个新的 powershell 窗口。 步骤 3:配置 PowerShell 连接 现在我们要告诉 Claude 工具:“别去连官网了,来连我们本地的翻译官”。 1. 打开配置文件: 在新的 PowerShell 窗口中输入: 2.粘贴以下代码: 步骤 4:开始使用 🎉 看到回复即搞定! 现在你就在用 Anthropic 的顶级命令行体验,驱动着公司的 MiniMax 模型了。 大家可以对比输入“claude code”和“minimax”下的差别: 步骤 5:将 LiteLLM 的启动简化(选做) Cursor 聊天框输入: 下次使用时,就只需两步: 另外,如果想更方便,比如在桌面启动 LiteLLM,也可以将这个 .bat 的文件和 .yaml 的参数文件一起复制到目标位置。比如我将其复制到了桌面。 💡 常见报错 Q: 报错 ImportError: Missing dependency 'backoff'? A: 你安装时少装了组件。请运行 pip install "litellm[proxy]"。 Q: 报错 UnsupportedParamsError: ... reasoning\_effort? A: 启动 LiteLLM 时忘了加 --drop\_params 参数。 Q: 输入 minimax 提示找不到命令? A: 修改完配置文件后,需要重启 PowerShell 窗口,或者运行 。 $PROFILE 刷新一下。 03 总结和拓展 Summary & Expansion 总结 1. 核心文件 2. 完整的逻辑链路图 运行 start\_minimax\_proxy.bat。 关键动作:它不仅加载了 yaml 配置,还通过 set OPENAI\_API\_KEY 把**通行证(Token)**交给了 LiteLLM 进程。 结果:本地 4000(或其他)端口开始监听。 你输入 minimax。 关键动作:系统执行 ps1 脚本里的函数。 关键动作:ps1 脚本在内存里临时改了两个环境变量: ANTHROPIC\_BASE\_URL:指路,让 Claude Code 走向本地端口。 ANTHROPIC\_MODEL:定名,告诉 Claude Code 要发出的“暗号”是什么。 结果:Claude Code 启动并按照这个路标发包。 关键动作:这是最复杂的一步。 收包:LiteLLM 收到 Claude Code 的 Anthropic 格式请求。 查表:它看一眼 yaml,发现 model\_name(暗号)对上了。 变身:它把请求拆开,去掉多余参数(drop\_params),重新包装成标准的 OpenAI 格式。 送达:最后,它带着 .bat 里的那个 Token,把请求发给供应商的 v1 接口。 拓展:思考题 如果不想用MiniMax了,想用Inference Engine平台的其他模型,该修改哪几个文件? **正确答案:**以Deepseek为例 修改.ps1、修改yaml,将 minimax function 一样的格式复制一份、修改模型名称部分就可以啦! 在启动时则可在终端输入deepseek,同样能成功启动 教程完毕!😍😍😍 快去试试吧~npm install -g @anthropic-ai/claude-code
# 注意加上引号,因为[proxy]是特殊字符
pip install "litellm[proxy]"https://docs.claude.com/en/docs/claude-code/overview参考这个文档,帮我安装claudecode
# 设置 Key (必须加引号)
$env:OPENAI_API_KEY = "你的MiniMax_API_Key"
# 启动服务
# --drop_params: 自动丢弃不兼容的参数,防止报错
litellm --model openai/MiniMaxAI/MiniMax-M2 --api_base https://api.gmi-serving.com/v1 --drop_params notepad $PROFILE
function minimax {
& {
# 1. 把目标地址指向本地 LiteLLM (端口 4000)
$env:ANTHROPIC_BASE_URL = "http://localhost:4000"
# 2. Key 随便填,因为真实的 Key 已经在 LiteLLM 那边配好了
$env:ANTHROPIC_AUTH_TOKEN = "sk-placeholder"
# 3. 模型名称要和 LiteLLM 启动时的匹配
$env:ANTHROPIC_MODEL = "MiniMaxAI/MiniMax-M2"
$env:ANTHROPIC_SMALL_FAST_MODEL = "MiniMaxAI/MiniMax-M2"
# 4. 启动 Claude 工具
if (Get-Command claude -ErrorAction SilentlyContinue) {
claude @args
} else {
Write-Error "请先安装 claude-code: npm install -g @anthropic-ai/claude-code"
}
}
}
# 启动自设定的minimax程序
minimax
# 进行测试
你好
帮我将LiteLLM的启动简化,生成一个一键启动脚本。