生育对女性的影响真的好大。
有个女同事之前一直脾气不算太好,我每次听到她声音时,不是和同事因为接口吵架,就是因为业务问题在拌嘴,永远皱着眉头,额头中间隐约呈现出一个“川”字形。
后来她回家生孩子去了,最近回来上班之后,我惊奇的发现她似乎变了一个人;再也没有听到她和同事争辩,和谁说话都是温温柔柔,眉头挥之不去的川字也消失不见。
如果她是解决了心中的什么事情导致心情很好,那我由衷的为她祝福;如果是生育、激素的影响,那我觉得这也太可怕了。
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
有个女同事之前一直脾气不算太好,我每次听到她声音时,不是和同事因为接口吵架,就是因为业务问题在拌嘴,永远皱着眉头,额头中间隐约呈现出一个“川”字形。
后来她回家生孩子去了,最近回来上班之后,我惊奇的发现她似乎变了一个人;再也没有听到她和同事争辩,和谁说话都是温温柔柔,眉头挥之不去的川字也消失不见。
如果她是解决了心中的什么事情导致心情很好,那我由衷的为她祝福;如果是生育、激素的影响,那我觉得这也太可怕了。
大家好我是地鼠哥。 如果你也是从 但其实,Go语言的设计虽然崇尚简洁,却在细节中隐藏了很多巧思。从经典的Go 1.11到最新的Go 1.26,它一直在稳步进化,引入了很多实用的特性和设计模式。用好它们,不仅能让代码更清晰,还能在同事面前展示你的专业能力。 下面就聊几个在实际工作中非常实用的技巧,看看你是否都在使用。 在业务代码里,我们经常用 比如下面这个函数: 为了解决这个问题,我们可以利用Go的自定义类型特性,给ID加一层身份验证。这在编译阶段就能帮我们发现错误。 这个简单的改动,几乎零成本地消除了ID混用的隐患。 在Java中如果你需要创建一个复杂的对象,可能会用Builder模式。而在Go中,我们经常遇到初始化一个服务或组件时,有几十个配置项,但大部分都用默认值的情况。 如果写一个包含所有参数的 这时候,函数选项模式就是最佳选择。 这种模式让初始化的代码变得非常灵活,而且未来增加新的配置项时,不需要修改现有的调用代码,兼容性极好。 在代码中拼接SQL语句或者JSON字符串时,使用双引号往往需要大量的转义字符 Go语言原生支持反引号 这在编写内嵌的SQL、HTML模板或者测试用的JSON数据时非常有用。 Go语言标准库非常推崇表格驱动测试。如果你还在写大量的 通过定义一个包含输入和期望输出的结构体切片,我们可以用一个循环覆盖所有的测试用例。 新增测试用例只需要在列表中加一行数据,逻辑与数据分离,非常易于维护。 Go的 它能自动处理 看到这里,你可能意识到,Go的版本更新也非常快。从Go 1.11引入Module,到Go 1.18引入泛型,再到Go 1.22修复循环变量问题,每个版本都有重要的变化。在实际工作中,我们经常面临这样的场景: 在本地同时管理多个Go版本,配置 所以,这时候就需要ServBay。 虽然它常被认为是Web开发工具,但它对Go语言的支持也非常出色。最让我满意的是,它可以一键安装和管理多个Go版本。你可以同时安装Go 1.20、1.23、1.26等多个版本,它们之间完全隔离,互不干扰。 而且,你可以为不同的项目指定使用不同的Go版本。比如,设置项目A使用Go 1.20,项目B使用Go 1.25。这样一来,在切换项目时,根本不用担心版本不兼容的问题,ServBay会自动处理好环境变量。 对于Go开发者来说,这意味着可以把更多精力放在架构设计和代码逻辑上,而不是被环境配置这些琐事消耗时间。 Go语言虽然以简单著称,但写出地道的Go代码(Idiomatic Go)依然需要不断的积累。掌握这些技巧,可以让你的代码更加健壮、优雅。而借助像ServBay这样的工具,又能帮你轻松搞定环境管理,让你专注于创造价值。 你还有什么Go语言的开发技巧吗?欢迎在评论区分享交流。 如果你也对Go语言感兴趣,欢迎关注并私信我领取pdf面经资料,保证完全免费!fmt.Println("Hello, World!") 和 if err != nil 开始Go语言生涯的,那说明你已经是个成熟的Go开发者了。在日常的业务开发中,我们每天都在写着各种各样的结构体和接口,有时候会觉得Go的语法过于简单,写起来甚至有点繁琐。用自定义类型(Defined Types)提升安全性
int64 或 string 来表示各种ID,比如 UserID, OrderID, ProductID。直接使用基础类型的一个主要风险是,方法的参数很容易传混。// 很容易写错的调用
func ProcessOrder(userID int64, orderID int64) {
// ...
}
// 调用时可能不小心把两个ID搞反
var uid int64 = 1001
var oid int64 = 9527
ProcessOrder(oid, uid) // 编译器不会报错,但逻辑全错了type UserID int64
type OrderID int64
func ProcessOrder(uid UserID, oid OrderID) {
fmt.Printf("处理用户 %d 的订单 %d\n", uid, oid)
}
func main() {
var uid UserID = 1001
var oid OrderID = 9527
ProcessOrder(uid, oid) // 正确
// ProcessOrder(oid, uid) // 编译错误:cannot use oid (variable of type OrderID) as type UserID
}用函数选项模式(Functional Options)优化配置
NewServer 函数,调用起来会非常麻烦;如果传入一个配置结构体,又需要定义一个很大的Struct。type Server struct {
Host string
Port int
Timeout time.Duration
}
type Option func(*Server)
func WithHost(h string) Option {
return func(s *Server) {
s.Host = h
}
}
func WithPort(p int) Option {
return func(s *Server) {
s.Port = p
}
}
func NewServer(opts ...Option) *Server {
// 默认配置
server := &Server{
Host: "localhost",
Port: 8080,
Timeout: 30 * time.Second,
}
// 应用选项
for _, opt := range opts {
opt(server)
}
return server
}
func main() {
// 使用默认配置
s1 := NewServer()
// 只修改端口
s2 := NewServer(WithPort(9090))
// 修改多个配置,清晰直观
s3 := NewServer(WithHost("127.0.0.1"), WithPort(8888))
}用反引号(Raw String Literals)优雅处理多行文本
\,写起来麻烦,读起来也费劲。 ` 来定义原生字符串,所见即所得。func main() {
// 以前的方式,难以阅读
jsonStr := "{\n" +
" \"name\": \"Alice\",\n" +
" \"age\": 30\n" +
"}"
// 使用反引号,清晰明了
jsonNew := `
{
"name": "Alice",
"age": 30
}
`
fmt.Println(jsonNew)
}用表格驱动测试(Table-Driven Tests)简化测试代码
if-else 或者重复的测试逻辑,是时候改变一下了。func Add(a, b int) int {
return a + b
}
func TestAdd(t *testing.T) {
tests := []struct {
name string
a int
b int
want int
}{
{"正数相加", 1, 2, 3},
{"负数相加", -1, -1, -2},
{"零相加", 0, 0, 0},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := Add(tt.a, tt.b); got != tt.want {
t.Errorf("Add() = %v, want %v", got, tt.want)
}
})
}
}用 ErrGroup 并发处理任务
go 关键字让并发变得很容易,但协调多个并发任务并处理错误却不简单。手动使用 sync.WaitGroup 和 channel 来收集错误会写出很多样板代码。errgroup 包(golang.org/x/sync/errgroup)能完美解决这个问题。import (
"context"
"fmt"
"golang.org/x/sync/errgroup"
)
func main() {
g, _ := errgroup.WithContext(context.Background())
urls := []string{"http://www.google.com", "http://www.bing.com"}
for _, url := range urls {
url := url // 注意闭包捕获问题(Go 1.22之前需要)
g.Go(func() error {
// 模拟请求
fmt.Printf("Fetching %s\n", url)
return nil // 或者返回错误
})
}
// 等待所有任务完成,如果有任何一个返回错误,这里会返回那个错误
if err := g.Wait(); err != nil {
fmt.Println("出错了:", err)
} else {
fmt.Println("所有任务完成")
}
}WaitGroup 的计数,并且一旦有一个任务出错,可以取消其他任务(配合 Context),是处理并发任务的有效工具。管理好Go环境,才能高效开发
GOROOT, GOPATH,修改环境变量,是一件非常繁琐的事情。总结
最新云开发的ChatGPT微信小程序源码支持流量主,调用openai官网接口,是国内最接近chagpt的回答内容。使用的时候自己替换API就行了,有能力自己改改UI。
先修改chatgpt.php文件里面的key在把chatgpt.php上传服务器然后修改小程序里面的url,当然这些是需要去自己官网注册的啦!
扫码进入小程序
1、登录小情书站点进行注册:https://localhost/ 这里换成你自己部署后的域名
2、注册成功后会发送一封邮件到您的邮箱,进入邮箱访问接收到的地址即可激活账户。
3、登录账号会跳转到小程序的建立页面
4、如果提交没反应可以换个浏览器试试
小程序的名字必须和你微信注册的名称一模一样,填写完成之后提交就可以进入后台了。
生成的小程序需要审核通过才能获取到alliance_key和域名,叫叶子通过一下就可以了。管理后台就注册完成了。
找到服务器域名配置,如下图
request合法域名
https://love.qiuhuiyi.cn //你的后台域名
uploadFile合法域名
https://up-z2.qbox.me
https://love.qiuhuiyi.cn
downloadFile合法域名
https://baldkf.bkt.clouddn.com
https://love.qiuhuiyi.cn //你的后台域名
这样子微信小程序就和后台服务器绑定好了。
前端代码存放在githubs上,地址是下面这个
https://github.com/oubingbing/school_wechat //替换成你的后台域名
拉代码的时候顺便帮忙点一下start,哈哈。
有两种获取源码的方式
1、直接下载后解压
2、会使用git的最好用这种方式拉取,怎么拉取你应该是知道的,如果你会用,哈哈。
两种方式二选一都可以的。
用微信开发者工具打开源码后在项目根目录的config.js进行如下配置。
只要替换好后台生成的alliance_key以及在腾讯地图开放平台注册一个账号,把开发者ID粘贴到const TX_MAP_KEY = '';就可以了。
对比一下插件版本号,看看是否是最新的版本,如果不是就在app.json里面填上最新的版本号即可。
然后dev是开发环境,prod是生产环境,进行相应的配置即可。
到这里基本上配置就完成了
下载:https://wwxb.lanzoul.com/i6csx0p3ckab 密码:5ug6
解压密码:blog.xiaohack.org
声明:本资料仅供学习交流,严禁使用于商业、非法用途!!!
之前不是发了一个备案查询的脚本嘛,详情可见[bspost cid="3384"]
有师傅反应说接口数据不太对,因为那个接口用的都是缓存库,确实太老了,新的得vip(手动狗头)
根据我的需求确实能满足,以下改的就纯单学习交流了,获取的还是比之前要全很多
另外师傅们注意,还是根据需求来写的,所以仅限根据企业名称获取备案功能!!!
还有,没去细扣js了,直接用的selenium,师傅们如果使用可能还得去装个驱动,这个直接上网搜就行,毕竟在工作(摸鱼)时间写的,发现还挺好用的,对token验证还是乱杀,也学习了一波
直接上代码吧
import re
import time
import random
import csv
from urllib import parse
from urllib.parse import quote
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from pathlib import Path
import warnings
#忽略warning
warnings.filterwarnings("ignore")
# 定义备案爬虫类
class BeianSpider(object):
# 获取url
def __init__(self):
#判断beian.csv是否存在,不存在则创建
my_file = Path("beian.csv")
if my_file.exists():
print("[+]beian.csv已存在!")
else:
with open('beian.csv','a',newline='',encoding="utf-8") as f:
#生成csv操作对象
writer = csv.writer(f)
header = ["主办单位名称","单位性质","网站备案/许可证号","网站名称","网站首页网址","审核时间","记录时间","备案域名"]
writer.writerow(header)
print("[+]beian.csv已创建!")
def get_url(self,word):
url = 'https://icp.chinaz.com/record/{}'
name=quote(word, 'utf-8')
#params = parse.urlencode(name)
url = url.format(name)
#print(url)
return url
# 正则行数,提取内容
def parse_html(self,name,html):
# 正则表达式
re_bds = '<td>(.*?)</td><td class="tc">(.*?)</td><td>(.*?)</td><td>(.*?)</td><td class="Now"><span><a href="//(.*?)".*?<td class="tc">(.*?)</td><td class="tc">(.*?)</td><td class="tc"><a href="/record/(.*?)".*?'
# 生成正则表达式对象
pattern = re.compile(re_bds,re.S)
r_list = pattern.findall(html)
print(r_list)
self.save_html(r_list)
with open('success.txt','a+',newline='',encoding="utf-8") as f:
f.write(name)
f.write('\n')
# 保存数据函数,使用python内置csv模块
def save_html(self,r_list):
#生成文件对象
with open('beian.csv','a',newline='',encoding="utf-8") as f:
#生成csv操作对象
writer = csv.writer(f)
#整理数据
lenth = len(r_list)
#print(lenth)
for i in range(lenth):
#主办单位名称
save_organizer_name = r_list[i][0]
#print(name)
#单位性质
save_unit_nature = r_list[i][1]
#网站备案/许可证号
save_ICP_number = r_list[i][2]
#网站名称
save_website_name = r_list[i][3]
#网站首页网址
save_website_index = r_list[i][4]
#审核时间
save_review_time = r_list[i][5]
#记录时间
save_record_time = r_list[i][6]
#备案域名
save_ICP_domain = r_list[i][7]
L = [save_organizer_name,save_unit_nature,save_ICP_number,save_website_name,save_website_index,save_review_time,save_record_time,save_ICP_domain]
# 写入csv文件
writer.writerow(L)
print("[+]",r_list[0][0],"查询写入完成")
# 主函数
def run(self):
try:
url = "http://icp.chinaz.com/record"
#禁止浏览器窗口弹出
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
#browser = webdriver.Chrome()
with open('qiye.txt','r',newline='',encoding="utf-8") as f:
data = f.read().splitlines()
lenth = len(data)
for i in range(lenth):
#print(data[i])
url = self.get_url(data[i])
browser.get(url)
try:
#设置显示等待时间及标签,此处可改,实测受网络波动影响
wait = WebDriverWait(browser, 5)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'bg-list')))
#显示等待没有找到标签会报错,此处写入faild.txt后跳到下一个查找
except Exception as e:
with open('faild.txt','a+',newline='',encoding="utf-8") as f:
f.write(data[i])
f.write('\n')
print("[-]",data[i],"无备案信息")
continue
html = browser.page_source
self.parse_html(data[i],html)
#随机延时,根据需求设置
#time.sleep(random.uniform(1,2))
print("[+]","All Finished")
#except Exception:
finally:
browser.close()
# 以脚本方式启动
if __name__ == '__main__':
#捕捉全局异常错误
try:
spider = BeianSpider()
spider.run()
except Exception as e:
print("错误:",e)使用还是跟之前一样,在qiye.txt里写上所有企业名称,一行一个,直接python3运行beian.py就好,然后脚本跑起来会输出到beian.csv里,同时输出success和faild的企业名,这样没找到备案的企业还能找其他站捞一波,以网上随便找的全省医院为例,结果见下图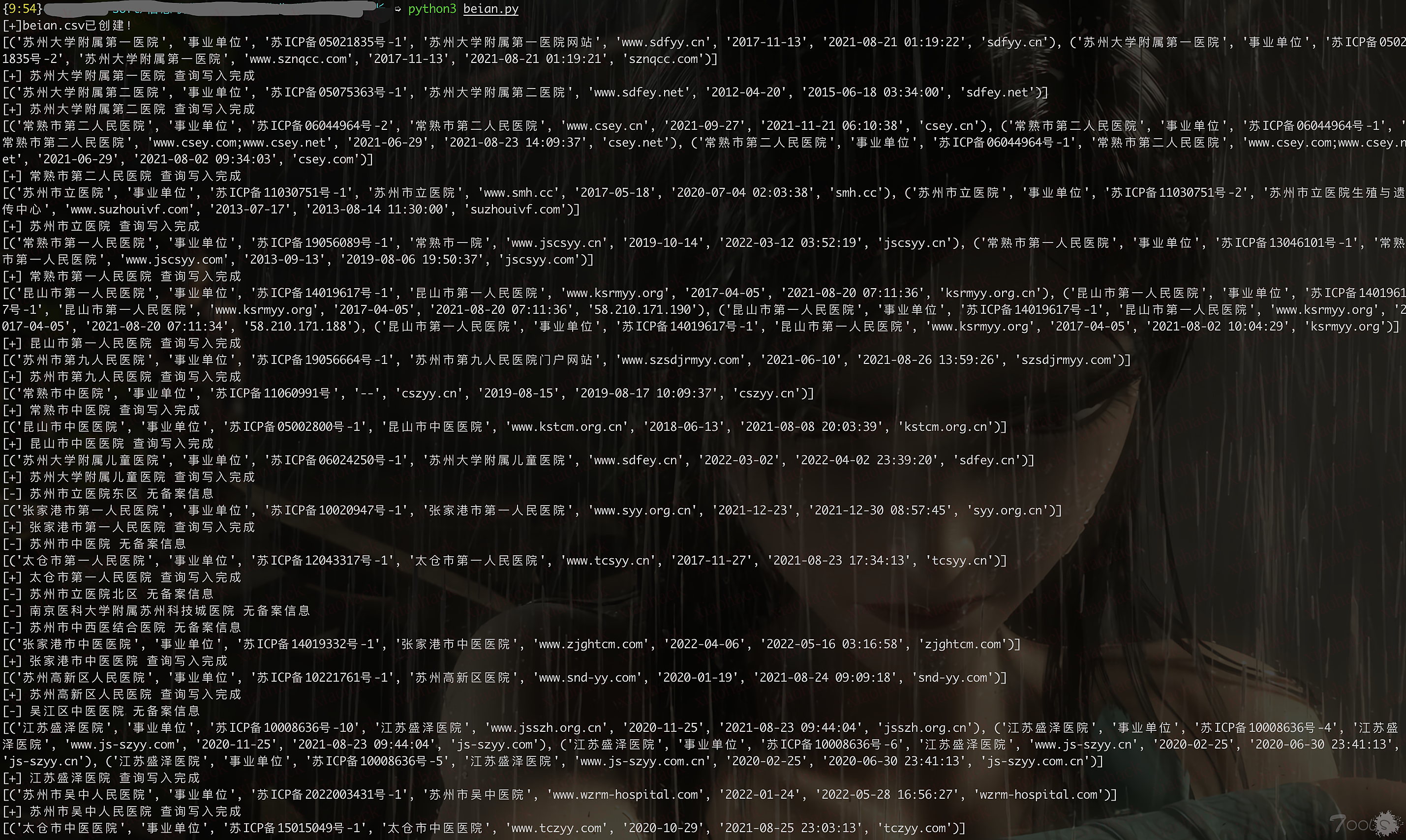

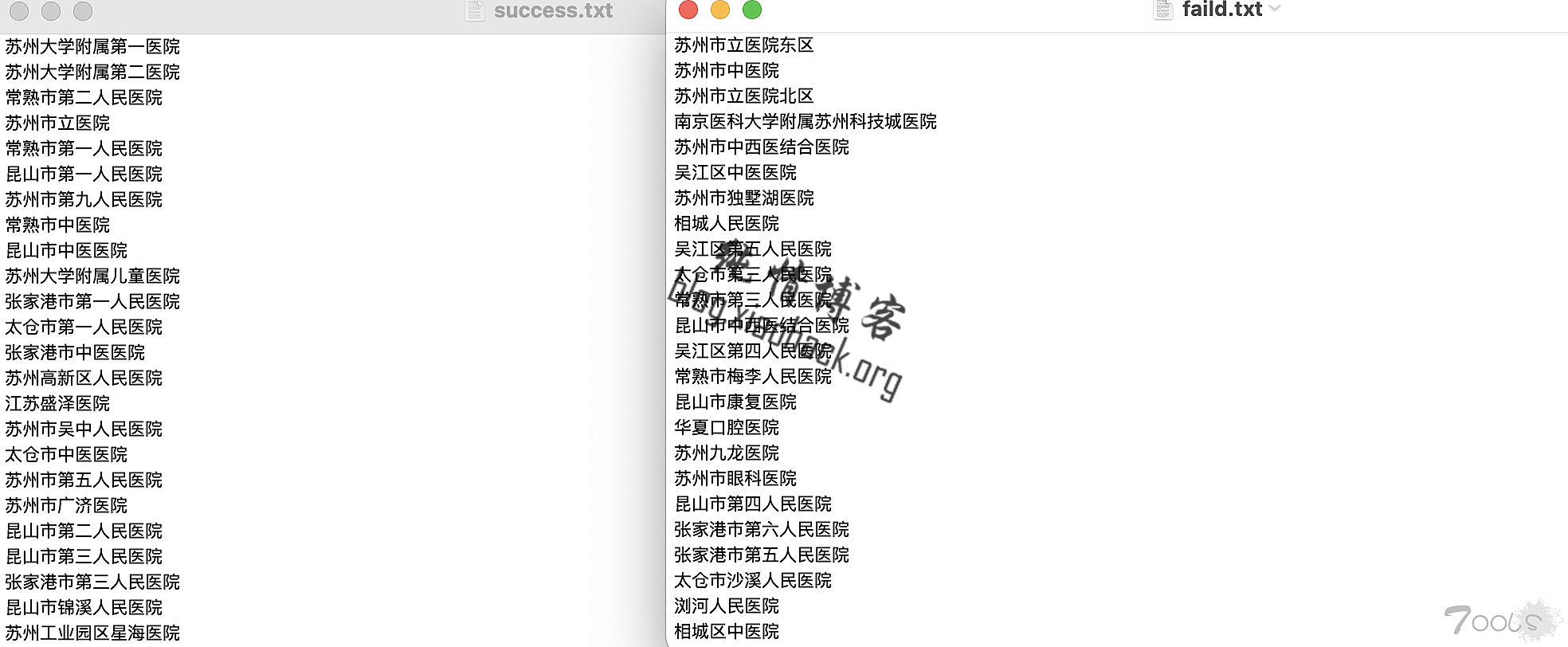

实测还是获取的信息多一点,没vip只能查一页,所以就只获取一页了
而且实测跟网速还是有挺大关系,师傅们可以看看代码微调下参数,等待啥的
另外祝师傅们七夕快乐啊~~
有的人七夕有花有爱有对象,有的人居然从六月一直加班到现在,需坚强