pgBackRest
简介
pgBackRest 旨在提供一个简单可靠,容易纵向扩展的 PostgreSQL 备份恢复系统。pgBackRest 并不依赖像 tar 和 rsync 这样的传统备份工具,而是通过在内部实现所有备份功能,并使用自定义协议来与远程系统进行通信。 消除对 tar 和 rsync 的依赖可以更好地解决特定于数据库的备份问题。 自定义远程协议提供了更多的灵活性,并限制执行备份所需的连接类型,从而提高安全性。
相关网站
pgBackRest 主页:http://pgbackrest.org
手册:pgBackRest User Guide - RHEL
pgBackRest
Github 主页:GitHub - pgbackrest/pgbackrest: Reliable PostgreSQL Backup & Restore
pgbackRest 特征
- 并行备份和还原
- 本地或远程操作
- 完整,增量和差异备份
- 备份轮换和存档到期
- 备份完整性
- 页面校验和
- 备份恢复
- 流压缩和校验和
- 增量还原
- 并行,异步 WAL Push&Get
- 表空间和链接支持
- S3、Azure 和 GCS 兼容对象存储支持
- 加密
- 与 PostgreSQL > = 8.3 的兼容性
pgbackRest 安装
| ip | 软件 | 角色 |
|---|
| 192.168.1.11 | postgres,pgbackrest | primary |
| 192.168.1.12 | postgres,pgbackrest | standby |
| 192.168.1.13 | postgres, | standby |
| 192.168.1.16 | pgbackrest | 远程备份工具端 |
ubuntu (所有节点) :
sudo apt-get install pgbackrest
创建所需目录并赋予权限
su - root
mkdir -p -m 770 /var/log/pgbackrest
chown postgres.postgres /var/log/pgbackrest/
chown postgres.postgres -R /etc/pgbackrest/
主从 pgbackrest 配置文件
su postgres
vim /etc/pgbackrest.conf
[pg_5433]
pg1-port=5433
pg1-path=/data/postgresql/pgdata/pg-5433/
pg1-socket-path=/var/run/postgresql/
[global]
repo1-host=192.168.28.14
repo1-host-user=postgres
repo1-path=/var/lib/pgbackrest
repo1-retention-full=2
process-max=3
[global:archive-push]
compress-level=3
主库参数解释:
[pg_5433] 部分
这个 pg_5433 是备份集群的名字,多个备份集群可以添加 比如:[test-1],[test-2] 等等
pg1-path=/data/postgresql/pgdata/pg-5433/: 指定 PostgreSQL 数据库实例的数据目录路径。这是 pgBackRest 需要备份的主要内容所在的位置。
pg1-socket-path=/var/run/postgresql/: 指定 PostgreSQL 服务器的套接字文件(socket file)路径。pgBackRest 使用这个路径来通过 UNIX 套接字连接到数据库。
pg1-user=postgres: 定义 pgBackRest 连接到 PostgreSQL 实例时应该使用的用户名。这个用户需要有足够的权限来读取数据库文件和执行备份相关的操作。
[global] 部分
这部分的配置适用于 pgBackRest 的全局设置,影响所有备份和恢复操作。
repo1-host=192.168.28.14: 指定远程备份仓库的主机地址。这表明备份数据将被存储在指定 IP 地址的服务器上。pgBackRest 支持多个备份仓库,这里的 repo1 表示第一个仓库。
repo1-host-user=postgres: 定义访问远程备份仓库主机时使用的用户名。postgres 将以这个用户的身份在远程主机上执行操作。
log-level-file=detail: 设置文件日志记录的详细级别。detail 级别会记录更详细的操作信息,有助于故障排查和监控备份过程。
log-path=/var/log/pgbackrest: 指定日志文件的存储路径。pgBackRest 会将运行日志写入这个目录下,便于后续的日志分析和问题定位。
远程备份工具端配置文件
su postgres
vim /etc/pgbackrest.conf
[pg_5433]
pg1-path=/data/postgresql/pgdata/pg-5433/
pg1-port=5433
pg1-socket-path=/var/run/postgresql/
pg1-host-config=/etc/pgbackrest.conf
pg1-user=postgres
pg1-host=192.168.28.11
pg1-host-port=22
pg1-host-user=postgres
pg2-path=/data/postgresql/pgdata/pg-5433/
pg2-port=5433
pg2-socket-path=/var/run/postgresql/
pg2-host-config=/etc/pgbackrest.conf
pg2-user=postgres
pg2-host=192.168.28.12
pg2-host-port=22
pg2-host-user=postgres
pg3-path=/data/postgresql/pgdata/pg-5433/
pg3-port=5433
pg3-socket-path=/var/run/postgresql/
pg3-host-config=/etc/pgbackrest.conf
pg3-user=postgres
pg3-host=192.168.28.13
pg3-host-port=22
pg3-host-user=postgres
[global]
backup-standby=y
process-max=3
start-fast=y
repo1-path=/var/lib/pgbackrest
repo1-retention-full=2
backup-user=postgres
log-level-console=info
log-level-file=debug
buffer-size=16MiB
compress-type=gz
[global:archive-push]
compress-level=3
工具端参数解释
[pg_5433]
这个 pg_5433 是备份集群的名字,多个备份集群可以添加 比如:[test-1],[test-2] 等等
pg1-path :指定了数据库实例的数据目录路径。
pg1-port :定义了实例的端口号,通常 PostgreSQL 默认端口是 5432。
pg1-socket-path:指定了 UNIX 套接字文件的路径,用于本地连接。
pg1-user :定义 pgBackRest 连接到各个 PostgreSQL 实例时使用的用户名。
pg1-host-config-path :指定远程主机上 pgBackRest 配置文件的路径。
pg1-host:定义了各实例所在的主机地址。
pg1-host-port :指定了用于 SSH 连接的端口号,默认为 22。
pg1-host-user:定义了 SSH 连接时使用的用户名。
[global] 部分
这部分定义了全局备份策略和行为。
backup-standby=y:启用备份从备用服务器进行,这有助于减少对生产数据库的性能影响。
process-max=3:定义了 pgBackRest 同时执行任务的最大进程数。
start-fast=y:启用快速启动模式,尝试减少备份期间的停机时间。
repo1-path:指定了备份仓库的路径。
repo1-retention-full=2:定义了完整备份的保留数量,超过这个数量的旧备份将被删除。
backup-user:指定执行备份操作的用户。
log-level-console:设置控制台日志级别。
log-level-file:设置文件日志的详细级别。
buffer-size:定义了缓冲区大小,用于优化性能。
compress-type=gz:指定了压缩类型,这里使用的是 gzip。
[global:archive-push] 部分
这部分专门用于配置归档推送操作。
compress-level=3:定义了压缩级别,数值越高,压缩效果越好,但需要更多的 CPU 资源。
ssh 免密登陆配置
在各个服务器上,生成 postgres 的 ssh 密钥
su postgres
ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa -N ""
在主从服务器上 postgres 用户 配置备份服务器 postgres 的用户公钥
登录备份服务器 192.168.28.14
su postgres
cd ~
cat ./.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQDnvcOPSQgi2zKWqNHsFjKC0zp4X5+yG1eNf5fEr25r2+NlBGMRrBFh2pONh2pWSLiglbhOZA5Pr1ILpllwP34eiGNjxTp0ys0U1YjnOuvgY7iwwR+xkXJmywDb0g0ALSEi3TS0lu5z3u4mBcW03q4m/oS++Fi+7ieDinyQAZOXXOyvj8k7g7/NiUXzONN83do/+KC5htVm9Q77A2DrDmZWQGbypMKQYPY66RjcWvApPOVYbrUxHlndq3fU4IhHPOVwiAdpHm5bh8dyb9k1FWcIS9sxLVm4KsUbt99VeDC8ri7iglMKen+gcktIyo80rGRoIdzJrD6JPP8cTlhpTwV/uW42kWgS9lZ8I/Ahk7lWoDdiF/pVNkMiiTOgZ2/YGV88CE0khpOtRl3nPHFlUZHi1QLdfH9omI0FZWeLYAuQbKWBGZ8GgfAweKjEtMy/J43NO5qGK6JZ0KB2ve03JowCGbW65cmTuPQgz3Hwo5I0fv3YEy88LK9nVnLub44zunGqJ4JBAc2H/WrmSqLYtLtljo/5EuKmc34SS75WimY9wh1nTmhVPODuLzurXjz28zx245tkcLeImbn4C8Gge4I7TgtPj8VkWTXC6WlrTTLjebLuMjYR3qFfuGqfD2vuLEHU4CBGHAnpDCG51v96gBpw+m9Cman6f9KvA3iZRBOXHw== postgres@k8s-node01
在主从服务器上添加备份服务器的公钥
root@k8s-master01:~
postgres@k8s-master01:/root$cd ~
postgres@k8s-master01:~$vim ./.ssh/authorized_keys
同样的在备份服务器的 postgres 的用户上配置主从服务器上 postgres 用户的公钥
设置 postgresql 归档
在主库上修改 archive 归档
patronictl -c /etc/patroni/patroni-5433.yaml edit-config archive_mode = on archive_command = 'pgbackrest --stanza=pg_5433 archive-push %p'
max_wal_senders = 3
stanza 名需要和配置文件一致
修改完之后,通过 patronictl 重启所有数据库
patronictl -c /etc/patroni/patroni-5433.yaml restart pg_patroni_etcd pg_patroni_5433_01
patronictl -c /etc/patroni/patroni-5433.yaml restart pg_patroni_etcd pg_patroni_5433_02
patronictl -c /etc/patroni/patroni-5433.yaml restart pg_patroni_etcd pg_patroni_5433_03
初始化备份
在备份服务器上执行
su postgres
pgbackrest
#删除方式
pgbackrest
pgbackrest
检查配置
pgbackrest --stanza=pg_5433 --log-level-console=info check
#执行结果如下
postgres@k8s-node01:~$ pgbackrest --stanza=pg_5433 --log-level-console=info check
2025-10-27 15:40:57.655 P00 INFO: check command begin 2.50: --backup-standby --buffer-size=16MiB --exec-id=3943474-ea8cda56 --log-level-console=info --log-level-file=debug --pg1-host=192.168.28.25 --pg1-host-config=/etc/pgbackrest.conf --pg1-host-port=22 --pg1-host-user=postgres --pg1-path=/data/postgresql/pgdata/pg-5433/ --pg1-port=5433 --pg1-user=postgres --repo1-path=/var/lib/pgbackrest --stanza=pg_5433
WARN: option 'backup-standby' is enabled but standby is not properly configured
2025-10-27 15:41:00.980 P00 INFO: check repo1 configuration (primary)
2025-10-27 15:41:01.387 P00 INFO: check repo1 archive for WAL (primary)
2025-10-27 15:41:06.703 P00 INFO: WAL segment 000000230000000000000059 successfully archived to '/var/lib/pgbackrest/archive/pg_5433/16-1/0000002300000000/000000230000000000000059-0c80b7903193612ee31642ac12c2548bba36bc1b.gz' on repo1
2025-10-27 15:41:06.806 P00 INFO: check command end: completed successfully (9159ms)
完全备份
在备份机上操作即可
pgbackrest --stanza=pg_5433 --log-level-console=info backup --type=full
增量备份
pgbackrest pgbackrest --stanza=pg_5433 --log-level-console=info backup --type=incr
差异备份
pgbackrest pgbackrest --stanza=pg_5433 --log-level-console=info backup --type=diff
查看备份信息
备份恢复
这个恢复操作的一台新的 postgresql 主机上操作,并配置好 pgbackrest.conf 文件 和 备份机可以免密登陆 ssh 登陆
$ pgbackrest --stanza=pg_5433 restore --pg1-path=/data/postgresql/pgdata/pg-5433/
pgbackrest --stanza=pg_5433 --set=20251027-134949F restore
pgbackrest --stanza=pg_5433 --set=20250713-195747F_20250713-195909I info
pgbackrest --stanza=pg_5433 --type=lsn --target="0/41000028" restore
pgbackrest --stanza=pg_5433 --delta --type=time "--target=2025-10-27 14:11:02+08" restore
常用命令
pgbackrest --stanza=pg_5433 stanza-create
pgbackrest --stanza=pg_5433 stanza-delete
pgbackrest --stanza=pg_5433 stanza-upgrade
pgbackrest --stanza=pg_5433 start
pgbackrest --stanza=pg_5433 stop
pgbackrest --stanza=pg_5433 backup
pgbackrest --stanza=pg_5433 restore
pgbackrest --stanza=pg_5433 info
pgbackrest expire --stanza=pg_5433
pgbackrest expire --set=20250713-195747F_20250713-195909I --stanza=demo
pgbackrest --stanza=pg_5433 check
pgbackrest --stanza=pg_5433 --config=/pg14/pgbackrest/etc/pgbackrest.conf repo-get /pg14/pgbackrest/lib
pgbackrest_exporter 监控备份状态
一般我们可以通过 pgbackrest info 去查看备份状态,但是这样并不直观
所以可以借助 exporter 获取 pgbackrest 的状态,从而及时监控到备份信息
安装 pgbackrest_exporter
pgbackrest_exporter 支持二进制运行,同时也支持 docker 运行,此处用二进制服务运行的方式
下载对应服务器版本的二进制包
wget https://ghfast.top/https://github.com/woblerr/pgbackrest_exporter/releases/download/v0.21.0/pgbackrest_exporter-0.21.0-linux-x86_64.tar.gz
tar -zxvf pgbackrest_exporter-0.21.0-linux-x86_64.tar.gz
mv pgbackrest_exporter-0.21.0-linux-x86_64/pgbackrest_exporter /usr/local/bin/pgbackrest_exporter
chown postgres:postgres /usr/local/bin/pgbackrest_exporter
创建 pgbackrest_exporter.service
touch /usr/lib/systemd/system/pgbackrest-exporter.service
vim /usr/lib/systemd/system/pgbackrest-exporter.service
[Unit]
Description=pgbackrest-exporter Service
After=network.target
[Service]
Type=simple
User=postgres
ExecStart=/usr/local/bin/pgbackrest_exporter --backrest.config=/etc/pgbackrest.conf
Restart=on-failure
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
Alias=pgbackrest-exporter.service
启动 pgbackrest_exporter.service
systemctl daemon-reload
systemctl start pgbackrest-exporter.service
systemctl enable pgbackrest-exporter.service
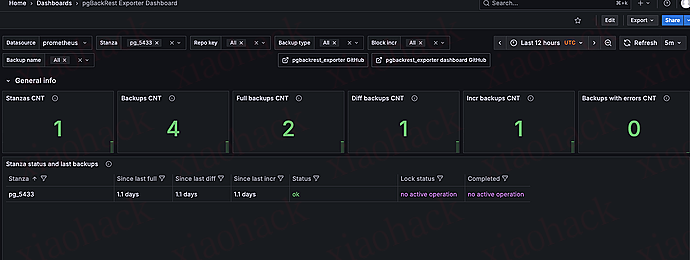
通过 grafana 展示页面
grafana id:17709
ON_Backs 通知 脚本
"""
Patroni钉钉通知脚本 - 增强诊断和错误修复版
主要解决:日志显示发送成功但实际未收到消息的问题
作者:资深SRE/数据库高可用架构师
""" import os
import string
import subprocess
import sys
import json
import logging
import requests
import socket
import traceback
from datetime import datetime
import time import patroni
DINGTALK_WEBHOOK = 'https://oapi.dingtalk.com/robot/send?access_token=********' if not DINGTALK_WEBHOOK:
print("错误:钉钉Webhook环境变量未设置,请配置 DINGTALK_WEBHOOK_URL", file=sys.stderr)
sys.exit(1)
logger = logging.getLogger('patroni-dingtalk')
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s [%(levelname)s] %(message)s')
file_handler = logging.FileHandler("/var/log/patroni/dingtalk_diagnostic.log")
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
stdout_handler = logging.StreamHandler(sys.stdout)
stdout_handler.setFormatter(formatter)
logger.addHandler(stdout_handler)
def verify_dingtalk_network():
"""验证网络连通性到钉钉服务器"""
target_host = "oapi.dingtalk.com"
target_port = 443 try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(3)
result = sock.connect_ex((target_host, target_port))
sock.close()
if result == 0:
logger.info(f"网络连通性检查: 可访问 {target_host}:{target_port}")
return True else:
logger.error(f"无法连接钉钉服务器 {target_host}:{target_port}, 错误代码: {result}")
return False except socket.gaierror:
logger.error("DNS解析故障 - 无法解析钉钉服务器地址")
return False except Exception as e:
logger.exception(f"网络检查异常: {str(e)}")
return False def send_with_retry(message_data):
"""带重试机制的消息发送函数 - 解决偶发网络问题"""
headers = {'Content-Type': 'application/json'}
max_retries = 3
retry_delay = 2 for attempt in range(max_retries):
try:
logger.debug(
f"发送请求 (尝试 #{attempt + 1}):\nURL: {DINGTALK_WEBHOOK}\nBody: {json.dumps(message_data, indent=2)}")
response = requests.post(
DINGTALK_WEBHOOK,
json=message_data,
headers=headers,
timeout=(3, 5)
)
logger.debug(f"钉钉响应状态码: {response.status_code}")
logger.debug(f"钉钉响应体: {response.text[:500]}...") if response.status_code == 200:
json_response = response.json()
if json_response.get('errcode') == 0:
logger.info(f"钉钉API确认消息已发送! (尝试#{attempt + 1})")
return True else:
logger.error(f"钉钉API错误: [{json_response.get('errcode')}] {json_response.get('errmsg')}")
if json_response.get('errcode') == 130101:
logger.error("常见原因: 钉钉机器人关键词不匹配 - 检查消息中是否包含设置的keyword")
elif json_response.get('errcode') in [310000, 310001]:
logger.error("常见原因: 被钉钉限流 - 请降低通知频率或添加特殊关键词")
else:
logger.warning(f"HTTP错误码: {response.status_code}")
except requests.exceptions.RequestException as e:
logger.exception(f"网络请求异常 (尝试 #{attempt + 1}): {str(e)}")
except json.JSONDecodeError:
logger.error(f"响应JSON解析失败: {response.text[:200]}")
if attempt < max_retries - 1:
logger.info(f"{retry_delay}秒后将重试...")
time.sleep(retry_delay)
return False def parse_event_args():
"""解析Patroni回调参数-增强容错""" if len(sys.argv) < 4:
logger.error(f"错误: 参数不足! 期望至少4个参数,实际收到 {len(sys.argv)}")
logger.info(f"完整参数列表: {sys.argv}")
return None try:
PATRONI_LEADER=subprocess.run("/usr/local/bin/patronictl -c /etc/patroni/patroni-5433.yaml dsn -r leader", shell=True, capture_output=True, text=True).stdout.strip()
PATRONI_MEBERS=json.loads(subprocess.run("/usr/local/bin/patronictl -c /etc/patroni/patroni-5433.yaml list -f json", shell=True, capture_output=True, text=True).stdout.strip())
PATRONI_MEBERS_HOST=[]
for i in PATRONI_MEBERS:
PATRONI_MEBERS_HOST.append(i.get('Host'))
PATRONI_MEBERS_HOST=str(PATRONI_MEBERS_HOST)
len_members=len(PATRONI_MEBERS)
leader_num=0
replica_num=0 for i in PATRONI_MEBERS:
if i.get('Role')=="Leader":
i.get('State')=="running"
leader_num+=1 elif i.get('Role')=="Replica":
i.get('State')=="streaming"
replica_num+=1 else:
continue if len_members>=2 and leader_num==1 and replica_num==len_members:
PATRONI_HA_STATE='green' elif leader_num==1 and replica_num>=1 and replica_num < len_members:
PATRONI_HA_STATE='yellow' else:
PATRONI_HA_STATE='red'
event_info = {
'script_path': sys.argv[0],
'event_type': sys.argv[1],
'node_role': sys.argv[2],
'cluster_name': sys.argv[3],
'leader': PATRONI_LEADER,
'mebers': PATRONI_MEBERS_HOST,
'len_members': len_members,
'hostname': socket.gethostname(),
'ipaddress': socket.gethostbyname(socket.gethostname()),
'timestamp': datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'ha_state': PATRONI_HA_STATE,
'old_role': os.getenv('PATRONI_OLD_ROLE', None)
}
logger.debug(f"解析事件成功: {json.dumps(event_info, indent=2)}")
return event_info
except Exception as e:
logger.exception(f"参数解析错误: {str(e)}")
return None def build_safe_message(event):
"""构建安全的消息格式 - 兼容钉钉要求""" if not event:
logger.error("无法构建消息: 事件数据为空")
return None if event['event_type'] in ['stop', 'failover']:
title= f"**<font color={'#FF0000'}>**🔴 Patroni故障事件**</font>**" elif event['event_type'] in ['start', 'promote']:
title = f"**<font color={'#008000'}>**🟢 Patroni恢复事件**</font>**" elif event['event_type'] in ['reload', 'restart']:
title = f"**<font color={'#FFA500'}>**🟡 Patroni维护事件**</font>**" else:
title = f"**<font color={'#0000FF'}>**🔔 Patroni状态变更**</font>**"
message_content = f"""
### {title}
- **事件类型**: {event['event_type']}
- **集群名称**: {event['cluster_name']}
- **集群当前Leader**: {event['leader']}
- **集群当前成员**: {event['mebers']}
- **集群成员数量**: {len(event['mebers'].split(','))}
- **集群状态**: **<font color={'#008000' if event['ha_state'] == 'green' else '#FFFF00' if event['ha_state'] == 'yellow' else '#FF0000'}>{event['ha_state']}</font>**
- **当前节点角色**: {event['node_role']}
- **当前主机名称**: {event['hostname']}
- **当前主机IP**: {event['ipaddress']}
- **集群状态**: {event['ha_state']}
- **发生时间**: {event['timestamp']}
""" if event.get('old_role'):
message_content += f"- **变更前角色**: {event['old_role']}\n"
message_content += "\n> **Patroni数据库高可用系统**" return {
"msgtype": "markdown",
"markdown": {
"title": title,
"text": message_content
},
"at": {
"isAtAll": False
}
}
if __name__ == "__main__":
logger.info("=" * 60)
logger.info("🚦 Patroni钉钉通知脚本启动 | 诊断模式开启")
logger.info(f"收到参数: {sys.argv}")
logger.info(f"环境变量 WEBHOOK={DINGTALK_WEBHOOK[:20]}...") if not verify_dingtalk_network():
logger.critical("网络诊断失败! 消息无法发送 - 请检查网络连接或防火墙设置")
sys.exit(10)
event_data = parse_event_args()
if not event_data:
logger.error("无法解析事件数据,消息发送中止")
sys.exit(20)
message_payload = build_safe_message(event_data)
if not message_payload:
logger.error("消息体构建失败")
sys.exit(30)
logger.info("尝试发送消息到钉钉...")
success = send_with_retry(message_payload)
if success:
logger.info("✅ 消息发送确认成功")
else:
logger.error("❌ 消息发送失败 - 请查看上述诊断信息")
logger.info("=" * 60)
sys.exit(0 if success else 40)
📌 转载信息
原作者:
xxdtb
转载时间:
2026/1/19 17:45:53