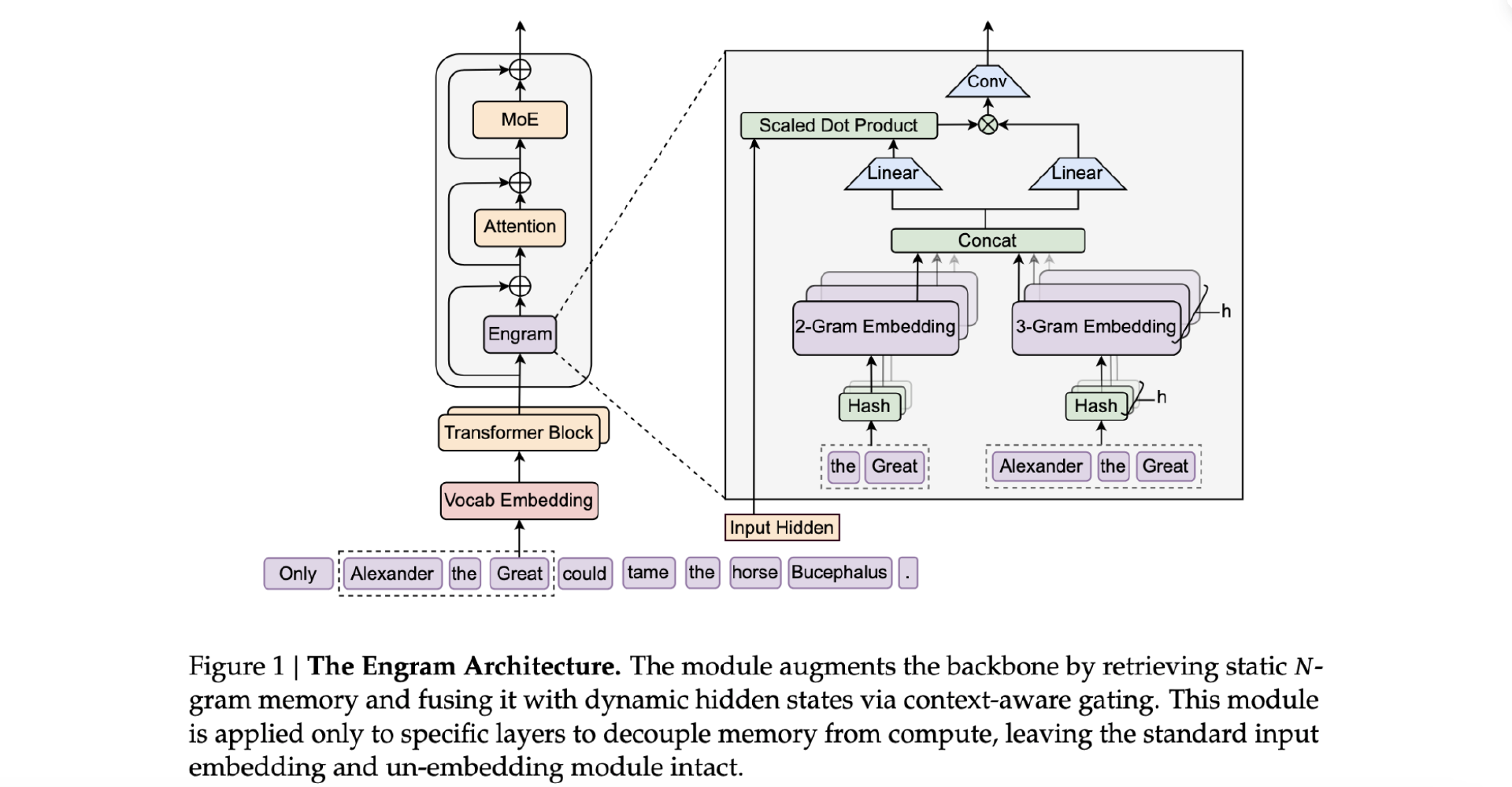
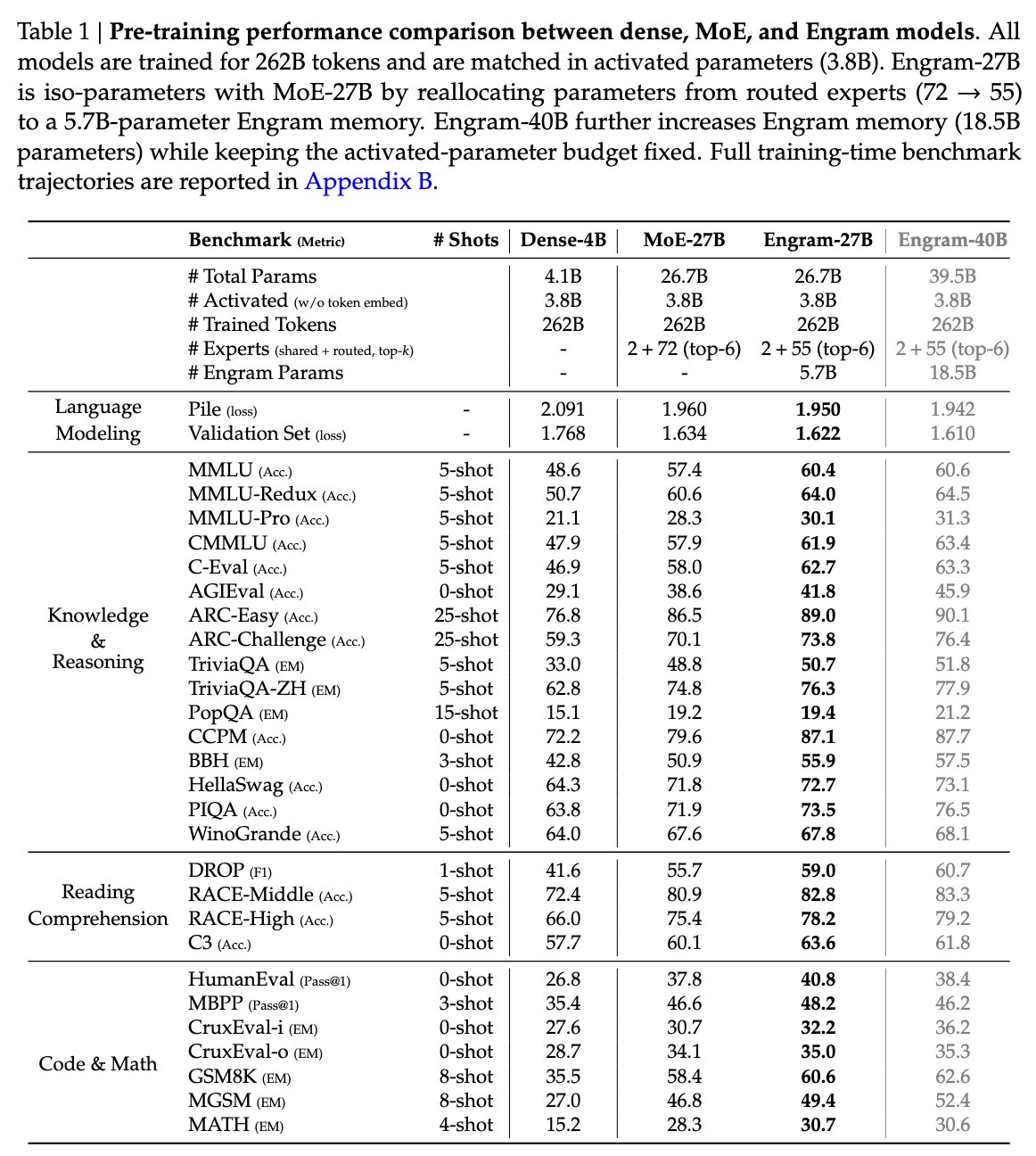
大模型低价趋势延续!智象未来姚霆:B 端、C 端界限模糊,API 不够、逼出 “按结果付费”
本文为《2025 年度盘点与趋势洞察》系列内容之一,由 InfoQ 技术编辑组策划。本系列覆盖大模型、Agent、具身智能、AI Native 开发范式、AI 工具链与开发、AI+ 传统行业等方向,通过长期跟踪、与业内专家深度访谈等方式,对重点领域进行关键技术进展、核心事件和产业趋势的洞察盘点。内容将在 InfoQ 媒体矩阵陆续放出,欢迎大家持续关注。 我们采访了智象未来联合创始人姚霆,他指出在多模态领域,深度 Scaling up 模型能力提升收益放缓,而广度 Scaling up 会带来更多惊喜,多模态能力也在重塑大模型推理过程。另外,2025 年的模型价格战倒逼厂商三大加速:研发新模型抢占短暂的版本优势、提升推理速度、升级高性价比架构降本。他认为,低价趋势 2026 年将延续,核心原因是市场远未饱和。结合公司情况,姚霆表示模型商业模式从卖 API、积分制转向“按结果付费”。下面是详细对话内容,以飨读者。 InfoQ:Scaling up 是否仍是最佳路线? 姚霆: 对于多模态大模型而言,Scaling up 有深度和广度。深度 scaling up 就是类似于单一多模态任务的纯粹模型参数 scaling up 过程,我们会发现这种 scaling up 下模型能力提升收益放缓,并不是指数级的增长,与之搭配的还需要高质量数据和架构的“Scaling up”,而且盲目扩增模型参数也会对推理 cost 带来极大地负担,所以我们在深度 scaling up 过程中除了模型性能之外更多地会去考虑训练和推理的 cost,期望达到极致的性能 - 效率平衡。 而广度 scaling up 指的是从垂域场景和商业化落地的视角下去看 scaling up,即不同多模态任务之间的 scaling up,我们发现这种广度上的 scaling up 会带来更大的惊喜,例如在联合架构中去实现多模态理解和生成任务的统一,以及视频生成和音频生成任务的统一,衍生出类似音画同步的特色。 InfoQ:MoE 架构为什么会成为 2025 年的主流架构?其在参数效率与推理成本间的平衡能力,是否彻底改变了大模型的开发与部署逻辑?非 MoE 路线的企业如何构建差异化竞争力? 姚霆: 稀疏 MoE 架构的一大优势是较高的推理效率,尽管其模型参数量很大,但在推理过程中只有部分参数被激活,这样既保持了高参数量带来的模型学习能力,也在部署推理过程中表现出较高的效率。 而对于非 MoE 架构,也就是参数稠密型的模型,虽然推理的性价比会比 MoE 架构低,但是对于垂域任务,稠密型模型由于总参数量更小,部署更加灵活,也可以体现出较好的效果。 InfoQ:2025 年多模态能力取得了哪些飞跃性发展?Nano Banana Pro 代表的图片生成模型、OpenAI Sora、Google Veo 3 代表的视频生成模型,分别做了哪些优化得到了不错的效果? 姚霆:2025 年多模态大模型能力有几个代表性的发展: 音画同步生成,让视频从默片时代进入了有声时代; 主体参考的一致性,实现了从片段化到连贯叙事的转变,AI 漫剧因此迎来了井喷的爆发; 运镜表达、表情演绎,让视频生成更具备影视表达,从“形似”到“神似”。 Veo 3 就在音画同步上做的很出彩,而 Nano Banana Pro 则将主体参考一致性发挥到新的高度,因为都是闭源模型,所以只能猜测在技术上不会局限于单一的 DiT 架构,例如借助多模态推理和生成的统一(VLLM+DiT)实现更精准的多模态内容编辑,而将更多不同模态的 token(文本、图像、视频、语音等)融入到统一的架构中则能端到端实现类似音画同步的能力。 InfoQ:多模态能力是否会重塑推理?跨模态推理是否也成为必答题?预计推理能力的突破方向在哪里? 姚霆:2025 年 多模态能力已经在重塑大模型推理过程,从 DeepSeek OCR 中使用图片来进行长文本压缩,到 Nano Banana 中直接生成解题过程的图片,多模态能力已经成为大模型推理能力中不可或缺的一部分。 多模态数据往往能提供比纯文本数据更稠密、直观和具备逻辑关联的信息。目前多模态数据越来越多的引入,对于大模型结构、训练方法以及数据三方面都会带来新的挑战。其中,大模型结构要尽可能支持原生多模态的输入或者输出,对于模型的参数量上提出了更高的要求;训练方法上需要去平衡各种不同的任务,保证模型在不同任务上都达到一定的收敛程度;数据上则对数据的广度和精度上又有了进一步的要求,广度上需要尽可能涵盖需要的多模态推理任务,同时高质量精品数据可以在训练后期提升推理能力。 InfoQ:从语言模型到多模态模型,再到世界模型,这个演进的本质是什么?您认为世界模型未来发展趋势如何? 姚霆: 从语言模型到多模态模型,再到世界模型,演进的本质是“大模型对真实世界的建模能力升级”:语言模型是“理解人类符号”,多模态理解模型是“感知世界表象”,多模态生成模型则是“模拟世界表象”,而世界模型是“掌握物理规律和因果关系并与之交互”,这也是通往 AGI 的必经之路。 因此,世界模型未来必将会在理解物理世界空间结构的同时,提升对物理规律和因果关系的刻画能力,而且通过与物理真实世界的交互实现从感知到决策的闭环。 InfoQ:2025 年模型价格战最关键的影响是什么?价格战倒逼厂商做了哪些架构演进?低价趋势在 2026 年是否会继续延续? 姚霆: 主要还是倒逼模型厂商去持续加速,一是加速研发新模型形成短暂的版本优势,二是加速模型的推理时间,时间就是金钱,三是加速模型架构的升级,引入性价比更高的架构设计来降低成本。低价趋势肯定会延续,因为市场还远没有饱和。 InfoQ:2025 年在 B 端和 C 端,都有哪些创新的商业模式出来吗? 姚霆: 创新的商业模式是很难的,所以我觉得更多是一些特色吧。 B 端和 C 端的界限越来越模糊,总体来说都是内容的生成者,真正的海量 C 端其实是内容的消费者,所以可以把两个端一起谈,商业模式的创新就是从售卖 API 提升到了售卖结果,以前 B、C 两端都是积分制,本质就是价值折算的积分,但是我们在不断探索按照结果来付费。 在移动端,我们也在突破过去 web 端复杂的积分逻辑对应的不同的会员等级,pro、ultra 等等,我们只会把功能区分为会员功能和非会员功能,然后按需充值即可,不会再纠结额度来觉得是否续费。 InfoQ:在您看来,2026 年大模型竞赛的核心是什么?您认为下一次“大模型代际飞跃”可能来自哪条技术路线? 姚霆:2026 年 大模型竞赛的核心,会从“技术能力”转向“价值落地能力”,类似于比拼“行业收入规模”和“客户留存率”。谁能更快将技术转化为行业实效,谁就能占据先机。 下一次“代际飞跃”很可能来自两个方向: 一是新颖的用户交互体验,随着基础原子能力目前逐渐饱和,2025 年 Agent 相关的应用出现了爆发式的增长,而 Agent 爆发的背后实际上代表了用户在认可大模型能力的同时又对于 AI 应用的交互体验提出了更高的要求,让大模型从单一的原子能力向完整解决方案提供者演变,一旦在用户交互方式、交互体验上跨越式提升,就会带来新的机遇。 二是专业级能力的大众化,目前大模型能力对于专业从业者来说已经达到一个很惊艳的程度,但是对于大众来说还是存在一些使用上的“困难”,这种困难可能来自于高昂的推理成本,编写专业级 prompt 的入门难度,以及缺乏大模型使用经验以及思维,而下一次飞跃可能就来自于如何拉近大模型对于大众的隔阂,出现真正的全民级 AI 应用。 InfoQ:根据您的观察,科技公司 2025 年面临的压力如何?对此采取了什么样的应对措施?员工们的状态如何? 姚霆: 对我们这样的模型研发的公司来说,模型和商业化一直会是两个最大的挑战,这两个挑战汇集在一起就是对于底层模型架构的突破变成必选项,模型公司不能像过去那样不断的优化数据和推理来解决用户的问题,而是要在架构上做出突破,敢为人先。 非常开心的是我们的员工状态始终保持战斗状态,因为我们不要 80 ->85,而是要 120 分的创新和颠覆,同时模型团队也和业务团队有了更多的协同,这种协同对于模型团队的能力落地起到非常重要的作用。 InfoQ:经过一年竞赛,国内前沿 AI 水平取得了怎样的成绩?是否赶上了硅谷科技公司? 姚霆: 在多模态大模型这个赛道,我觉得国内外是百花齐放,例如我们在 2025 年 4 月的图像模型 HiDream-I1 开源打响了国内多模态生成式大模型登顶国际竞技场的第一枪,同时大家也开始重视了多模态生成式大模型的竞技场,这些过去只有硅谷科技公司的模型名单里开始快速出现国内的各家模型。 InfoQ:您认为,2026 年的技术赛点可能是什么?您会重点关注哪些行业和技术? 姚霆: 技术赛点从多模态模型架构上来说我觉得还有比较长的路,但是在应用上我觉得技术的赛点是多模态 agent 的成熟落地。2025 年上半年的 Manus,下半年持续火热的 vibe coding 都是大语言模型的应用落地的典型案例,多模态模型看似比大语言模型更解决用户,但是生图生视频场景还没有出现真正技术应用上完全解决用户痛点的 agent,所以我们也会更关注多模态 agent 。多模态大模型的 Scaling up
多模态大模型的代表性发展
“低价趋势肯定会延续”
“模型和商业化一直会是两个最大挑战”




















 生物智能与人工智能的演化路径截然不同,但它们是否遵循某些共同的计算原理?
生物智能与人工智能的演化路径截然不同,但它们是否遵循某些共同的计算原理?