请问一下如果自建 blog 图片都是怎么搞定的呀
就放项目里面吗,还是说有什么好用的图床
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
项目地址: GitHub - kiusnax/obsidian-upgit
一个简单的 Obsidian 图片上传插件,基于 upgit。
之前一直使用 Typora,最近切换到了 Obsidian。然而,我发现现有的 Obsidian 图片上传插件体验都不太理想,于是和 Antigravity 老师一起搓了这个插件。
它的主要功能是拦截 Obsidian 的图片粘贴事件,将图片自动上传到配置的图床,并替换为远程链接。
![[开源项目] Obsidian 图片上传插件,基于 upgit1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/24/20260124063444_6973f784080c9.webp!mark)
upgit CLI 工具,支持多种图床配置。本插件依赖于 upgit 命令行工具。在使用前,请确保你已经下载并配置好了 upgit。
确保 upgit 在你的终端中可以通过命令正常上传图片。
main.js, manifest.json 文件放入 Obsidian 仓库的 .obsidian/plugins/obsidian-upgit/ 目录下。obsidian-upgit。upgit 可执行文件的绝对路径 (例如: C:\Tools\upgit.exe 或 /usr/local/bin/upgit)。assets。配置完成后,只需在 Obsidian 编辑器中粘贴图片(Ctrl+V / Cmd+V),插件即可自动工作。
npm install
npm run dev
只用服务器搭建 memos 未免太大材小用了,而且也浪费钱。所以就想尽量用无服务器部署 memos。
render 由于免费存储空间过低,不是优选。
保活方式: https://github.com/hoochanlon/keep-alive
memos 官方镜像按照如图所示填写相关参数
🖼️ 图片加载失败
使用 hu3rror/memos-litestream (该项目解决了备份换机迁移数据的痛点)项目镜像的填写方式
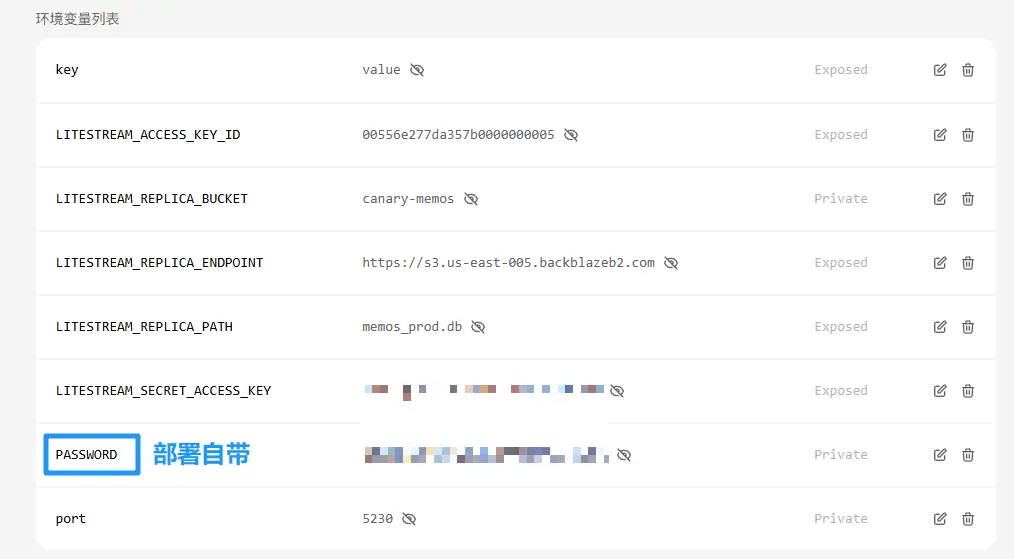
S3 配置如图及相关解答(建议看完该 issue 链接内容): https://github.com/hu3rror/memos-litestream/issues/67
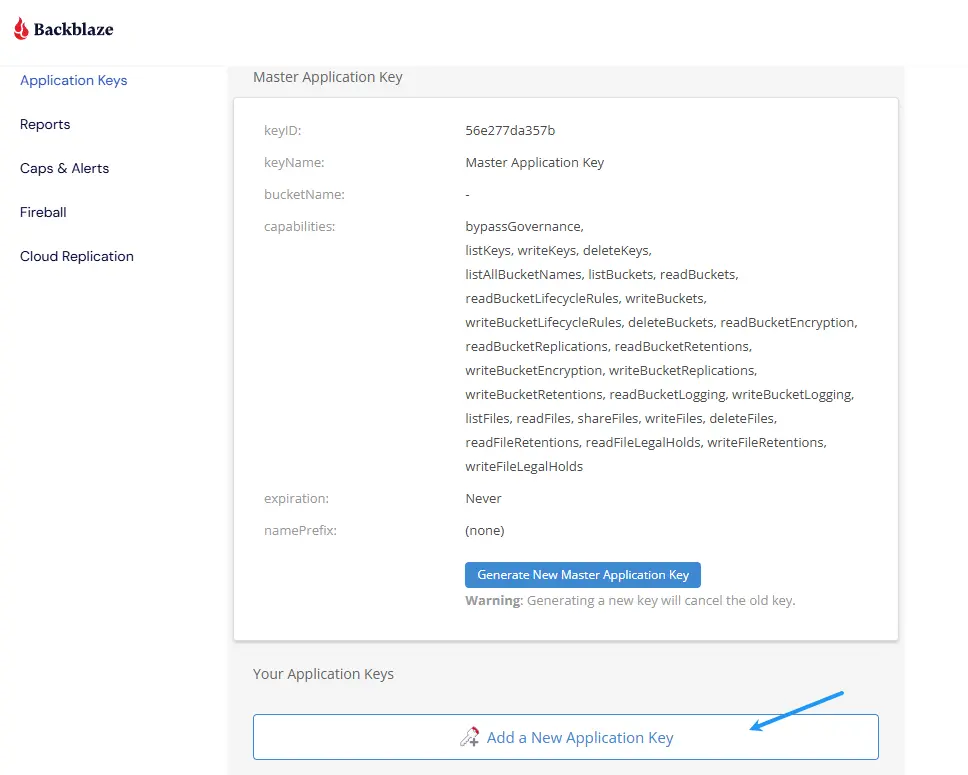
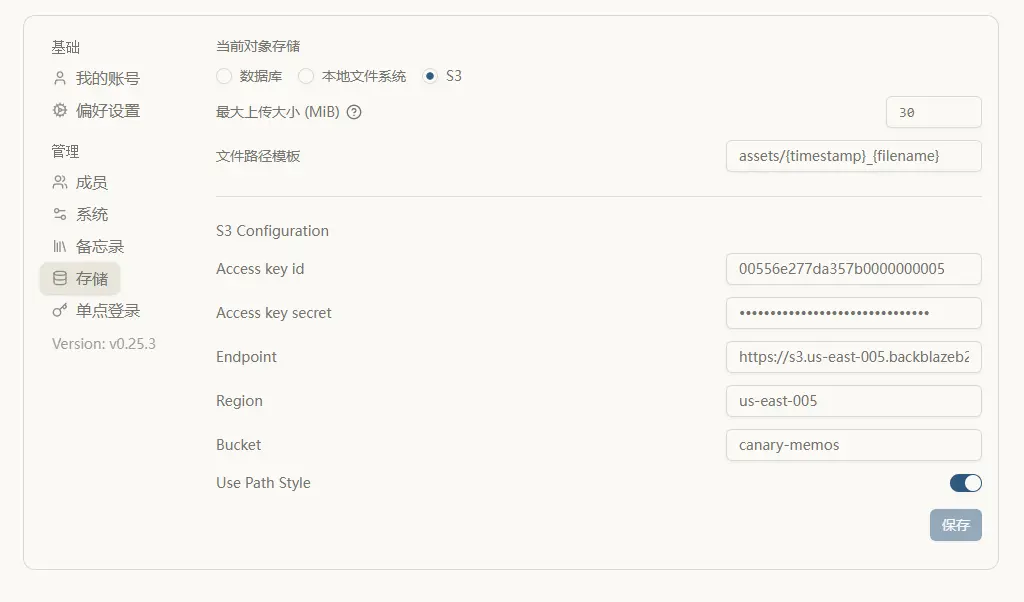
CF 代理 B2 配置见(适用于图床、文件管理免流服务): https://github.com/hoochanlon/CF-Proxy-B2
链接 🔗: https://pdp.asset.v6.navy
目前存储于测试网上,所有存储记录都会上链。
https://pdp.vxb.ai/calibration/dataset/6666
一次性上传超过 150 GB 可以帮忙生成一个类似 Openlist 的网页,效果如下
https://gw.crust-gateway.xyz/ipfs/bafybeiajrldj35kpzzozpzfg3yu2sgknbrzrqpgp7jb2wrj3xo5tobfnkq/
对比原网站 https://al.chirmyram.com
待开发功能
使用 privateKey 或 walletAddress + sessionKey 上传至主网。
自定义上传节点(providers)。
上传失败处理
在设置中,将 skipped piece 调整为“失败编号减 1”(例如失败在 piece 25,就填 24)。
选择与上次相同的 piece size,重新上传相同文件或文件夹即可继续。
起初是在整理表情包给角色扮演的机器人匹配合适语境的表情包麻烦,自己手动给图片打标较慢切难以管理。这两周空闲时间在 ai 加持下写了这个项目 (100% ai 生成哦,人工只做指挥)。
Note理论上可以作为统一图床打标后给 ai 来筛选个性化符合语境的图片,不局限于表情包。
** 项目体验地址:**https://img-tag.vercel.app demo/demo123
体验地址未配置视觉模型哦,需要完整功能的话可以自己部署试试看
项目强依赖一个支持 vector 扩展的 postgresql,没有本地的话推荐在线的 https://neon.tech/
首页
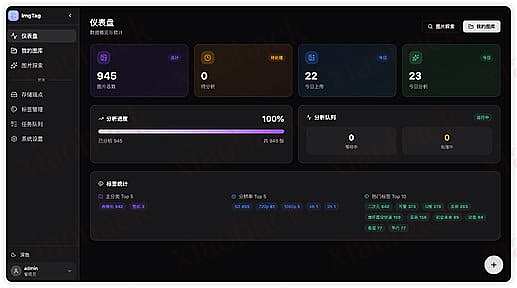
仪表盘
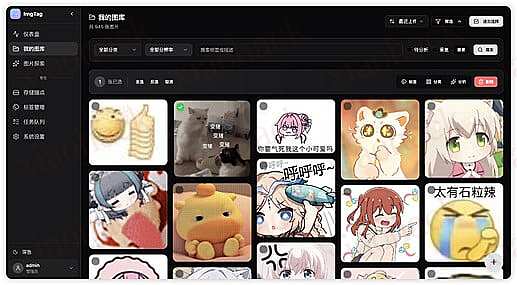
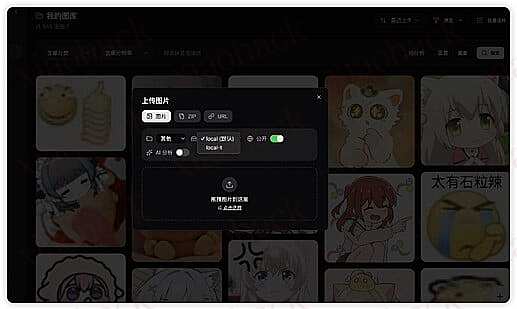
我的图库 - 这里提供多维筛选 + 批量操作
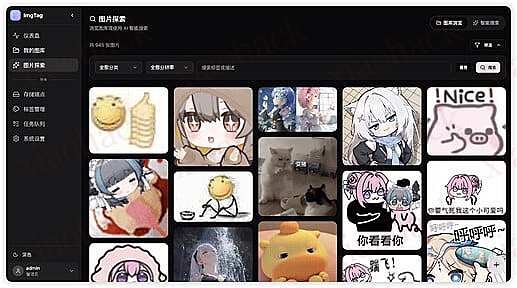
图片探索 (公开)- 提供多维搜索和向量搜索
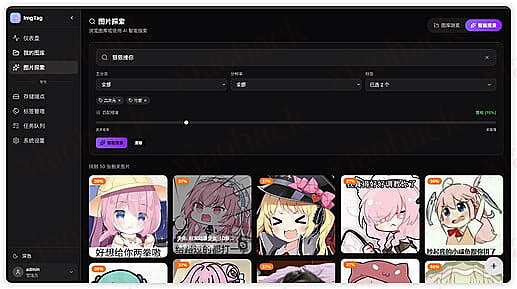
大图沉浸性浏览 + 部分键盘交互方便切换

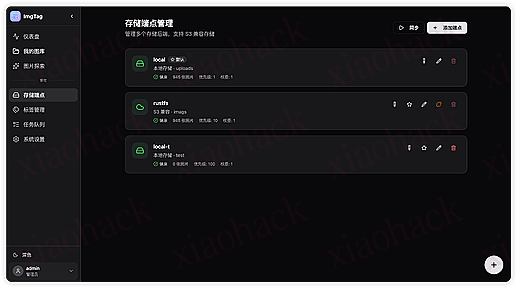
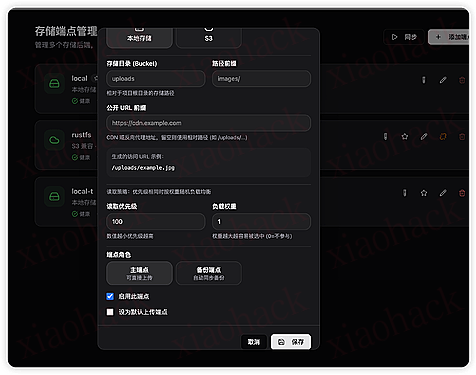
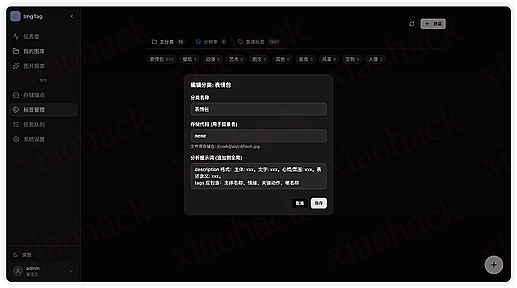
7. 标签管理,主分类标签提示词拿过去针对性提取相关关键字。
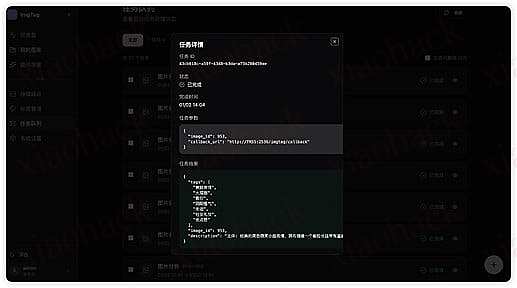
8. 任务队列
对于批量、耗时的异步操作,比如图片分析、批量删除、同步、批量分析等可以看到在任务队列看到相关参数和操作对象及结果
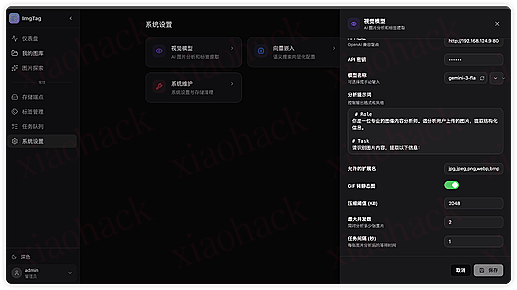
9. 系统设置
全局配置视觉模型相关内容、向量模型、以及用户管理和一些杂项配置