FriendlyAI 的 K-EXAONE 236B 限时免费中
好不好用先不说,但它免费啊
FriendlyAI 的 K-EXAONE 236B 在 1/28 前都可以免费使用。
K-EXAONE 236B 是由 LG AI Research 所建立的模型。



xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
好不好用先不说,但它免费啊
FriendlyAI 的 K-EXAONE 236B 在 1/28 前都可以免费使用。
K-EXAONE 236B 是由 LG AI Research 所建立的模型。
开发的多,渗透的不多…… 主要实际就是 mcp 服务,ai 模型还是那几个,欢迎添加相关 skils 以及 mcp,我先抛 2 个
Kali Linux / Packages / mcp-kali-server ·GitLab
说个抽象方法,一年 trae 去安装 hex……
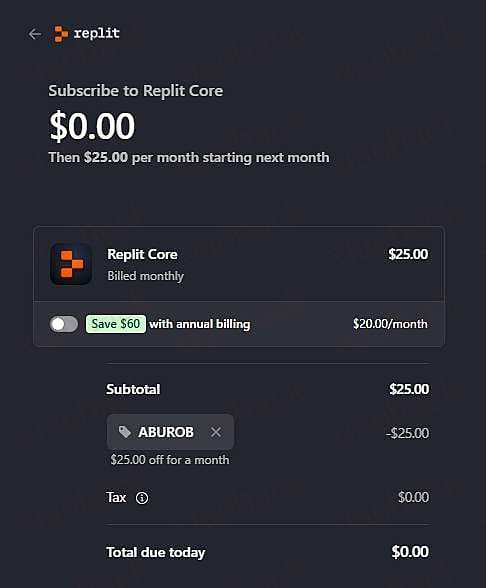
兑换码:
ABUROB
如何领取:
1️ 打开 replit.com
2️ 点击 计划升级 (Upgrade Plan)
3️ 输入 Promo Coee: ABUROB
4️ 点击 Pay/Continue
重点:
・使用最新的人工智能模型 (GPT, CLAUDE 等等)
・更高的 AI 使用额度
补个:
更新一下模型列表
OpenAI GPT-4o / GPT-5 等等
Anthropic Claude
Google Gemini
Meta Llama
Mistral、xAI Grok、DeepSeek 等
花了 2 天时间,我做出来一个在线生成可爱宝宝跳舞的视频生成网站。
可以上传自己家宝宝照片,支持最多 30s 时长的视频模板,效果超级赞,关键是模型很厉害,加上上头的视频背景音

地址: https://aibabydance.video/
ps:目前由于单视频成本较高,一个视频 1–5 块钱,所以暂时积分没有免费赠送。等价格降下来我再通知大家免费领积分体验。
英伟达(NVIDIA)发布了一套涵盖语言、智能体系统、机器人技术、自动驾驶和生物医学研究的开放模型、数据集和开发工具。此次更新扩展了多个现有的 NVIDIA 模型家族,并通过 GitHub、Hugging Face 和 NVIDIA 的开发者平台提供了相应的训练数据和参考实现。 在代理式 AI 领域,NVIDIA 扩展了 Nemotron 模型家族,为语音识别、检索增强生成和安全提供了新的组件。Nemotron Speech 包括针对低延迟、实时用例优化的自动语音识别模型。Nemotron RAG 引入了用于多模态文档搜索和检索流程的嵌入和重排视觉语言模型。Nemotron Safety 增加了用于内容过滤和敏感或个人身份信息检测的更新模型。NVIDIA 还发布了用于选定 Nemotron 模型的数据集和训练代码,包括在公共基准上评估的嵌入模型。 对于机器人技术和物理 AI,NVIDIA 引入了新的 Cosmos 世界基础模型,这些模型支持在真实环境中的感知、推理和合成数据生成。Cosmos Reason 2 是一个多模态推理模型,旨在增强智能体在物理环境中操作的场景理解。Cosmos Transfer 2.5 和 Cosmos Predict 2.5 专注于在不同环境和条件下生成合成视频数据,支持仿真和数据增强工作流程。基于 Cosmos,NVIDIA 发布了 Isaac GR00T N1.6,这是一个用于人形机器人的开放视觉-语言-动作模型,支持全身控制并将视觉感知与动作规划集成。 公告的一个组成部分是 NVIDIA Alpamayo,一个用于基于推理的自动驾驶的新开放模型家族。Alpamayo 结合了感知、规划和可解释性,采用视觉-语言-动作架构,并与仿真工具和大规模驾驶数据集相匹配。NVIDIA 还引入了 AlpaSim,这是一个用于自动驾驶汽车模型闭环评估的开源仿真框架。 据 NVIDIA 汽车部门负责人吴信洲表示,Alpamayo 和相关工具反映了跨研究、模拟、数据工程、安全和集成团队多年的开发努力。吴指出,这项工作涉及广泛的道路测试、使用 Cosmos 等平台进行持续的大规模模拟,以及与包括梅赛德斯-奔驰在内的汽车合作伙伴的紧密合作,计划在即将推出的量产车辆中进行初步部署。 医疗保健和生命科学更新通过新的 NVIDIA Clara 模型提供。这些包括用于原子级蛋白质设计的 La-Proteina,用于合成感知药物设计的 ReaSyn v2,用于早期安全和相互作用预测的 KERMT,以及用于 RNA 结构建模的 RNAPro。NVIDIA 还发布了一个包含 45.5 万个合成蛋白质结构的数据集,以支持该领域的训练和评估。 所有模型和数据集均在开放许可下发布,可通过 GitHub 和 Hugging Face 访问。NVIDIA 表示,许多模型还被打包为 NIM 微服务,以便在从本地推理环境到云基础设施的 NVIDIA 加速系统上部署。
1. 已知 aws 渠道来自 AmazonQ 或者 kiro,这两个渠道并没有 opus4 或者 4.1
2. 已知 kiro 或 AmazonQ 锁了 seed,所以同模型每次刷新的答案都是一样的,而以下是分别使用三个模型回答同一个问题的截图:



而可以看到,如果我切换为 4.5sonnet,答案就会不一样:

这不算什么大问题,毕竟 opus4.5 比 opus4 和 4.1 要更优秀,但是:

以上属于个人猜测,如果是我的问题会修改帖子。
————————————————————————
补充问题:
似乎发现了个能辨别 claude opus4.5 的抽象方法 - 搞七捻三 - LINUX DO



开源链接:
ZeroAd-06/UNITY2api: description, website, or topics provided.
总之,你现在可以使用 OpenAI 格式的 API 来调用 厦门实验室的 UNITY 模型,免费体验超过 Gemini 3 Pro,GPT-5.2,GPT-5.1,Kimi K2 T,Claude 4.5 Opus,Grok 4,GLM-4.7,DeepSeek-V3.2,Doubao-1.5 Pro,Qwen3-Max,Mistral Large 3,MiniMax-M2.1 的性能的模型,
或者至少是 与 Gemini 3 Flash 性能相当的模型
这很有可能是你见过的最简单的 2api 项目,代码不超过 160 行。
这个厦门实验室的网页没有做任何鉴权 / 反机器人机制,大家赶紧蹬啊
事实上,我写 readme 的时间都比开发(完全丢给 AI)的时间长。
就算你不打算使用这个模型,我也希望你能点进项目的 README 看一下,相信我,看我之后你会给这个项目一个 star,然后给这个帖子一个
数据来自 XiamenLabs 官方声称的评测基准 ↩︎
据报道,OpenAI正准备在ChatGPT中测试广告功能
作者:
发布时间:
08:30 PM
多方报道表明,OpenAI正持续推进在ChatGPT中加入广告的计划,但该实验初期将仅限于内部员工。
记者Alex Heath报道称,OpenAI应用部门负责人Fidji Simo近期在内部会议上向员工透露,公司正在内部版ChatGPT中酝酿广告植入方案。
这意味着OpenAI将首先面向员工测试ChatGPT的广告功能,但尚不确定何时向公众用户开放。
目前也不明确OpenAI是否会对付费订阅用户(例如Go、Plus和Pro套餐)隐藏广告。若需推测,我认为OpenAI不太可能在Plus和Pro套餐中展示广告,但鉴于Go套餐订阅费用较低(部分市场低于5美元甚至免费),未来可能会植入有限广告。
据称ChatGPT广告将优先展示赞助内容
假期期间,The Information曾报道OpenAI确实在考虑多种广告形式,包括在AI回答中优先呈现赞助内容。
报道指出:"AI模型可能会优先展示赞助内容,以确保其出现在ChatGPT的回复中。据知情人士透露,近期的广告模型设计包括在ChatGPT主回答窗口侧边栏展示赞助信息。"
此后OpenAI也确认公司正在探索"广告方案",但未透露更多细节。OpenAI发言人对The Information表示:"随着ChatGPT能力提升和使用范围扩大,我们正在寻找持续为所有人提供更智能服务的方式。为此,我们正在探索产品中广告的呈现形式。用户与ChatGPT已建立信任关系,任何方案都将以尊重这份信任为前提进行设计。"
OpenAI拥有可用于投放个性化广告的用户数据,但这种方式真能奏效吗?Perplexity在广告领域尚未取得显著成效。
我个人偏好 GLM 4.7, 但是看到很多小伙伴反馈 MiniMax M2.1 也很强。现在你可以在 Kilo Code 上免费使用啦~
消息来源:官方 X
目录帖:
本章以开源 / 闭源模型为划分,介绍一下日常使用及评估的经验。本节可能较为主观,请各位看官也要多多结合自身体感及实际业务体验来评判。
目前实现了 SOTA(State of the Art,特定领域或任务中,当前的最新进展和最高水准,基本上是各家自称)的闭源模型厂主要有如下几家(豆包除外,稍后单讲):
| 公司 / 机构 | AI 模型系列 |
|---|---|
| OpenAI | GPT 系列 |
| Google Gemini 系列 | |
| Anthropic | Claude 系列 |
| xAI | Grok 系列 |
| 阿里巴巴 | 通义千问系列 |
| 字节跳动 | 豆包系列 |
这几家基本上每隔一段时间就宣称自己发布了最强大的 xx 模型,以至于形成了一种循环。当然 SOTA 这个词很微妙,最新最大杯的模型未必就最适合你。下面按照模型家族介绍一下本代的各种主力型号的特点(截至 2026 年 1 月 4 日):
自从迈入 GPT-5 时代以来,GPT 系列模型就以回复简短闻名。从好的方面看,OpenAI 做到了省 output token(输出 token 数),这使得任务总体所需时间进一步得到压缩。然而代价是冷漠到近乎不近人情的回复使得创意写作用户不得不忍痛抛弃它。后续推出的编码特化模型 gpt5-codex 模型进一步强化了这个特征,有时候描述性文字几乎已经不能称之为人话了。好在 GPT-5.2 系列在一定程度上解决了这个问题,虽然比起 GPT-4.5 甚至 GPT-4o 系列模型给人在 Chat 上的主观感受仍有差距,但已经较为可用。
OpenAI 作为 LLM 的领头羊,服务压力自然是很大的,无论是网页还是 API 都可能会有服务异常的情况。为了解决这个问题,GPT-5 系列在网页端给出的解决方案是自动路由(其实就是超级降智)。然而,对于指定了特定型号的 API 用户来说,GPT-5 系列模型的推理速度仍然显得相对较慢。
说完了缺点,那么剩下的基本上全是优点。回复简短意味着完成同等任务下所需 tokens 更少,冷静的理性思考带给人一种指哪打哪的感觉 —— 不废话,just do it。比起 GPT-4 时代的人味儿来说,GPT-5 更像一名理工男。当然,它是一名后端理工男,在审美上未必有多好的品味。
| 模型名称 | 模型 ID | 上下文长度 | 最大输出长度 | 备注 |
|---|---|---|---|---|
| GPT-5.2 Thinking | gpt-5.2(gpt-5.2-2025-12-11) | 400K | 128K | 最高推理强度,支持 reasoning 参数(大杯) |
| GPT-5.2 Pro | gpt-5.2-pro | 400K | 128K | 企业级最高准确度,支持 xhigh reasoning(超大杯) |
| GPT-5.2 Chat (Instant) | gpt-5.2-chat-latest | 128K | 16K | ChatGPT“GPT-5.2 即时” 模式,延迟最低(其实就是小杯,很蠢) |
| GPT-5.2 (base) | gpt-5.2 | 400K | 128K | 通用旗舰版,默认 reasoning= |
| GPT-5.2-Codex | gpt-5.2-codex | 400K | 128K | 代理式编码专用,支持上下文压缩与视觉输入 |
| GPT-5.1-Codex-Max | gpt-5.1-codex-max | 400K | 128K | 支持 “压缩” 技术,可跨多窗口连贯处理数百万 tokens,专为长时间、项目级编码任务设计 |
这里需要特别注意的是,gpt-5.2-codex 并非代码万灵药。如果你不太会写 prompt 或者这个工程需要范围更广的探索思考,那么 gpt-5.2 可能会比 codex 变体好用些。codex 更突出指哪打哪的能力,而 gpt-5.2 会主动帮你多想些。换句话说,改 bug 用 gpt-5.2-codex,新开工程 / 模块用 gpt-5.2。推荐写后端或复杂的前端逻辑时使用 GPT 系列模型。
牢谷坐拥无尽的网络资源宝库以及 Deepmind+TPU 的神秘力量加持,尽管在 LLM 时代赶了个晚集,但从 Gemini 2.0 开始一路猛追,到了 2.5 时代已经是妥妥的御三家之一。Gemini 的多模态能力令人惊叹,Pro 系列的世界知识更是让人折服。比起 GPT 来说,Gemini 更像一名文科生:大参数带来的丰富世界知识给了它更强的文学理解能力,思考之细腻和情感共鸣能力使得它成为创意写作的最优选。当接入 Chatbot 的时候,你甚至可能没法分清它到底是 AI 还是人 —— 太能接梗了。
大家都不知道 Gemini Pro 系列的参数到底有多大,目前普遍认为 1T 以上。然而推理速度比起其他各家大参数模型来说又快的离谱,疑似 Jeff Dean 在机房里手敲(其实应该是 TPU 的特点所致)。总之,如果你想选择一款有超强的世界知识并且对推理速度有一定要求的模型,那么 Gemini 系列是毋庸置疑的选择。
Gemini 3.0 Pro 从内部测试阶段就不断炸场,多模态 + 大参数写出的前端效果惊艳了所有关注 AI 前沿动向的人。尽管 Gemini 3.0 Pro 存在较为严重的长上下文幻觉问题,但瑕不掩瑜,它依然是现在最适合前端的模型。
Gemini 3.0 Flash 推出后,甚至神秘地实现了某种程度上对 Pro 的反杀,几乎和 Pro 一样丰富的世界知识和更好的编码能力。下克上?搞不懂牢谷。
| 模型名称 | 模型 ID | 上下文长度 | 最大输出长度 | 备注 |
|---|---|---|---|---|
| Gemini 3 Pro | gemini-3-pro | 1000K (1M) | 64K | 旗舰模型。最强多模态推理与编码能力,支持 high 深度思维模式。前端很强非常强!但受限于长上下文幻觉,后端稀烂(相比其他两家) |
| Gemini 3 Flash | gemini-3-flash | 1000K (1M) | 64K | 速度旗舰。专为 Agent 设计,支持 minimal/ 等多级思维调节。Flash 反杀 Pro!大部分搬砖的活计用 Flash 就够了,速度飞快。 |
| Gemini 2.5 Pro | gemini-2.5-pro | 1000K (1M) | 64K | 2.5 世代旗舰。具备极强的长文本召回能力。(前面是官方说法,实际上各家长文本都一坨) |
| Gemini 2.5 Flash | gemini-2.5-flash | 1000K (1M) | 64K | 2.5 世代均衡版。高吞吐量,默认支持长上下文处理。 |
| Gemini 2.5 Flash-Lite | gemini-2.5-flash-lite | 1000K (1M) | 64K | 极致性价比。针对极低延迟任务优化,是目前最廉价的百万上下文模型。 |
Anthropic,又称 A÷ / A 畜,大家很熟悉了,神一样的 Coding Agent,翔一样的口碑和服务可用性。抛开立场不谈,最早的 Claude 模型以创意写作闻名,比起同期的 GPT-3.5 来说回答更有人味。后来 Claude 率先扩展了长上下文窗口以及 STEM 能力,走向了编码特化的不归路。到了 Claude 3 时代开始就是彻头彻尾的 Coding 模型了,直到现在的 Claude 4.5 成为了最均衡的编码代理模型 —— 如果你想前后端一把抓,选它准没错。强大的规划能力能够给出更适合工程上的方案,在各种场景下都能很好的完成目标。跑分没赢过,体验没输过。尽管日常处于即将被超越的状态,但还没被超越不是吗?(对标苹果!)
| 模型名称 | 模型 ID | 上下文长度 | 最大输出长度 | 备注 |
|---|---|---|---|---|
| Claude 4.5 Opus | claude-4-5-opus-20251124 | 200K | 64K | 支持 effort 参数调节推理强度。编码与科研任务首选(超大杯)(反重力反代优选) |
| Claude 4.5 Sonnet | claude-4-5-sonnet-20250929 | 200K / 1000K* | 64K | 专为复杂 Agent 与项目级代码设计,性能超越早期 Opus 4(中杯)(对于反重力用户来说,有 Opus 谁用 Sonnet) |
| Claude 4.5 Haiku | claude-4-5-haiku-20251014 | 200K | 64K | 路边一条,官方说具备 Sonnet 4 级别的性能,但被 Gemini Flash 家族打出 shi 来了 |
注:只有官方 Max 订阅才有 1000K 上下文,大部分渠道都是 200K 的上下文,比如反重力逆向或 Kiro 逆向。
马斯克也许缺乏品味,但他足够有钱。Grok 好不好用先放一边,超大规模的显卡集群是实打实存在的。这个系列一直秉持力大砖飞的原则,猛堆参数。迫于 Scaling law 的存在,就算是几百头猪,炼进 Transformer 里也能出些成果了罢。
Grok 在某些领域有着和 Gemini 系列相似的特性:参数够大,很适合创意写作任务。Grok 4 家族拥有不俗的吐槽能力,在对齐上比起 a helpful assistant 来说更像一名沙雕网友。而且 Grok 背靠 X(aka Twitter),也有着丰富的语料及不错的搜索功能。对于老外来说,Grok 简直是全自动开盒器(is that true ? )
Grok 系列另一个令人津津乐道的地方就是极低的审查下限。在各家 API 中,Grok / Google Vertex / DeepSeek 是审查力度相对较低的。但到了网页端上 Grok 也保持极低的审查下限就很离谱,当然考虑到 X 网页端上你依然可以畅爽 NSFW… 好吧,Grok 适合搞瑟瑟是从娘胎里就带出来的本事。无需破甲,无需诱导,很黄很暴力。酒馆和各种文字扮演游戏的常客。
| 模型名称 | 模型 ID | 上下文长度 | 最大输出长度 | 备注 |
|---|---|---|---|---|
| Grok 4 Heavy (SuperGrok) | grok-4-heavy | 256K | 8K - 16K | 多智能体协作系统,通过并行推理验证结果,推理强度最高(超大杯) |
| Grok 4.1 | grok-4.1 | 256K | 16K | 2025 年底旗舰,主打高情商 (EQ) 与低幻觉率,创意写作能力很好(大杯) |
| Grok 4 | grok-4 | 256K | 8K | 2025 年中发布的标准旗舰,原生支持多模态推理与实时 X 搜索 |
| Grok 4.1 Fast (Long) | grok-4.1-fast | 2,000K | 16K | 超长上下文版,支持 200 万 token,类似 Gemini Flash(中杯) |
| Grok 4 Fast (Instant) | grok-4-fast | 2,000K | 30K | 极速 / 高性价比版,支持 reasoning 切换(可关闭推理以获得极低延迟,类似 Gemini Flash Lite,小杯) |
| Grok Code Fast 1 | grok-code-fast-1 | 256K | 16K | 马斯克的钞能力,在一众编程模型当中显得平平无奇,但不要钱不要钱不要钱!速度很快,质量一般,体感跟 Gemini 2.5 Flash 差不多的性能,但在各种 Vibe Coding 客户端里都作为免费选项出现。 |
阿里作为目前开源界当之无愧的扛把子,从 Meta 手中接过了开源的大旗。r/LocalLlama 如今已是 r/LocalQwen 的形状了。Qwen 家族分为开源模型和闭源模型两种。除了每代的超大杯(通义千问 Max)为闭源外,其他商业 API 均能找到对应的类似开源型号。通义千问的特点是极强的指令遵循能力和稀烂的产品。
Qwen 家族的模型在输出上总感觉缺了点味道。它不像 GPT 那样冷静简洁,不像 Gemini 那样细腻有人味,但也不像 DeepSeek R1 0120 那样放飞自我。很怪,AI 味很重,在大规模使用 RL 训练的 Qwen3 世代这个特点尤为显著。国模的通病之一在 Qwen 上有显著体现:思考时非常消耗 Token,甚至在 Instruct 模型上模型倾向于输出思维链,导致最终完成复杂任务时所耗 Token 相对较高。
但从另一个方面上来讲,Qwen 作为国内 AI 的 T0 选手,其模型非常适合国内企业落地开发使用:性价比适中、模型选择丰富、较好的服务稳定性,还有强大的指令遵循能力可以减轻不少开发难度。逻辑能力也相当不错。
阿里系除了主打的阿里云百炼平台提供的通义千问服务外,还有面向开发者的 modelscope(魔搭)、心流团队的 iFlow、面向 C 端的蚂蚁灵光系列,主打一个养蛊和乱拳打死老师傅。以下表格主要介绍闭源的通义千问 3 家族:
| 模型名称 | 模型 ID | 上下文长度 | 最大输出长度 | 备注 |
|---|---|---|---|---|
| Qwen3-Max | qwen3-max | 256K | 64K | 超大杯。非思考模式输出可达 64K,思考模式输出 32K。 |
| Qwen-Plus | qwen-plus | 1M | 32K | 大杯。百万级长文本支持,适合复杂任务推理。 |
| Qwen-Flash | qwen-flash | 1M | 32K | 中杯。兼顾百万级上下文与极速响应速度。 |
| Qwen3-VL-Plus | qwen3-vl-plus | 256K | 32K | 视觉大杯。支持高分辨率,单图最大 16,384 tokens。 |
| Qwen3-VL-Flash | qwen3-vl-flash | 256K | 32K | 视觉中杯。支持视觉推理模式,单图上限同 Plus。 |
| Qwen-Long | qwen-long | 10M | 32K | 长文本专家。支持 1000 万 token 超长输入。 |
| Qwen3-Coder-Plus | qwen3-coder-plus | 1M | 64K | 编码特化大杯。专为复杂编程设计,支持百万级上下文与 64K 超长输出。 |
| Qwen3-Coder-Flash | qwen3-coder-flash | 1M | 64K | 编码特化小杯。高效处理编程任务,具备极高的响应速度。 |
把目光转回到字节的豆包家族。阿里和字节基本上是截然相反的 —— 字节在 LLM 上的开源很少,可用的只有 Seed-OSS-36B,豆包底模也一直很一般。然而豆包的产品做的很好,在国内 C 端市占率遥遥领先。这当然得益于他们深耕多模态,但这可能和集团底色也有一定关系。如果你手机里需要一款不需要爬墙就很好用的 AI 应用,那我想应该是豆包没错了。但使用 LLM API?除非你的公司疯狂迷恋 Coze。
| 模型名称 | 模型 ID | 上下文长度 | 最大输出长度 | 备注 |
|---|---|---|---|---|
| Doubao-Seed-1.8 | doubao-seed-1-8-251215 | 256K | 32K | 大杯。支持深度思考、多模态理解与工具调用,最长思维链达 64K。 |
| Doubao-Seed-Code | doubao-seed-code-preview-251028 | 256K | 32K | 编码特化。专为编程场景设计,支持深度思考与多模态理解。 |
| Doubao-Seed-Lite | doubao-seed-1-6-lite-251015 | 256K | 32K | 中杯。兼顾生成效率与推理能力,支持结构化输出。 |
| Doubao-Seed-Flash | doubao-seed-1-6-flash-250828 | 256K | 32K | 小杯。具备视觉定位能力,适用于高频多模态交互。 |
| Doubao-Seed-Vision | doubao-seed-1-6-vision-250815 | 256K | 32K | 视觉中杯(也可能是大杯?)。侧重 GUI 任务与复杂多模态理解。 |
这里记录每周值得分享的科技内容,周五发布。
本杂志开源,欢迎投稿。另有《谁在招人》服务,发布程序员招聘信息。合作请邮件联系([email protected])。

武汉首座电梯升降桥最近建成开放。因为上游有船厂,所以大桥有四根巨大的电梯柱,用来升起桥面,让船通过。(via)
大家大概想不到,美国互联网的热点,现在不是 AI 网站,而是一种全新的网站,叫做"预测市场"(prediction market)。
这类网站像雨后春笋一样,每天都在冒出来。最有名的预测市场,目前是 PolyMarket。

预测市场的用途,就是预测各种各样的事情。以 PolyMarket 为例,首页顶部就是各种预测的分类。

热门事件、突发事件、最新预测、政治、体育......
只要是你能想到的事情,它都提供预测。

以上周末为例,首页热门预测如下(上图)。
- 《时代》杂志的年度人物是谁?
- 《时代》杂志年度人物名单会泄露吗?
- 美联储一月份的决定是什么?
- OpenAI 下一次的大模型发布是哪一天?
你随便选一个,点进去就能看到,各种情况的概率。

上图预测的是,2025年12月5日至12日期间,马斯克会发多少条推文。
可以看到,概率最高的情况是440条~450条,概率33%,概率最低的情况是400条~419条,概率1%。
正是因为对于几乎任何问题,它都有实时的详细预测,美国人现在已经不怎么看民调了,改成看这种预测网站了。因为民调的抽样方法和样本大小,总是有局限的,反而是预测网站更反映市场的真实看法。
你可能会问,这些预测结果怎么产生?如何确保准确?
答案很简单,结果来自于用户的下注。
你看好哪一种情况,就可以对它下注。看好的人多,这种情况对应的概率就会上升,反之下降。
实质上,它的每一个预测都是一支股票,股价就是它的概率,1%的概率就是股价0.01元,100%的概率就是股价1元。
举例来说,某种情况的当前概率是2%,那么相当于0.02元。你看好这种情况,假定就花了100元买入。
结果,正如你的预测,它变成了现实,概率上升为100%,价格就变成了1元,相比你的买入价,整整上涨了50倍。于是,你投入的100元就变成了5000元。
反之,你预测错了,这个结果没有实现,概率变为0%,也就是0元,你投入的100元将一分都收不回来。
最近,美国的一条热门新闻就是,一个男子在 PolyMarket 上,对一个2%的小概率事件投入3000美元。结果,预测准确,他收回了12.5万美元。

为了方便世界各地的人参与,也是为了保证匿名,这种预测网站都采用稳定币交易。
所以,它的本质就是一个巨大的彩票市场,允许用户买卖自己最感兴趣、最熟悉的事件,这是它快速流行起来的根本原因。参与的人多了以后,反过来提高了预测的准确性。
我觉得,它的前景不可限量,一定会火爆的井喷式发展,传统彩票可能会被它彻底淘汰。
它把任何不确定的事情,都变成了彩票,实时量化了每一种可能性的概率,并且提供了金钱翻倍的途径。这一方面很有参考价值,可以用来判断未来情况,另一方面也非常有娱乐性和刺激性。
上个月,谷歌发布了新一代图像编辑模型 Nano Banana Pro(其实就是 Gemini 3 Pro 的图像分支)。
有一个功能引起了轰动:无论多么枯燥的文字,都能变成有趣的图片,从"读文"变成"读图"。
我当时就想,国产模型一定会马上跟进。
果然,昨天打开秘塔 AI,就看到他们发了这个功能,完全对标 Nano Banana Pro 以及 NotebookLM,而且还加入了自己的特色----讲解。

你点击"上传文件"(上图),上传各种资料(可以上传多篇),它就会自动创建一个知识库,输出内容的 AI 总结。这时,还会显示一个"给我讲讲"按钮。

上图是我写的一篇 JS 语法点 Promise 的教程,点击"给我讲讲"就会生成图片幻灯片 + 讲解。

大家可以去它们的官网 metaso.cn (手机 App 同名)试试看,这个功能挺好玩的,操作零门槛,关键是它免费(有赠送的积分)。
除了上传文件,你也可以直接搜索某个主题,再点击下方的"生成幻灯片"按钮。这时就会有"图片幻灯片"选项,并有20多种风格可选,还支持自定义。

1、步行环游世界
上个世纪90年代的一天,一个英国青年在酒吧里随口说,他可以从南美洲最南端一路走到英国。他的朋友都不信。
他就跟朋友打赌,他能做到。1998年,他正式从智利最南端开始步行,那一年他29岁。

27年过去了,他已经56岁了,依然在路上。
好消息是,他已经接近行程的尾段,预计将于2026年9月到达终点英国。

下面就是他的路线图,从南美洲最南端到北美洲最北端,再到亚洲和欧洲,最后是英国。

整个行程中,他只能步行或者游泳,不能使用任何交通工具。最难的一段就是北美洲与俄罗斯之间的白令海峡,为了不坐船,他是在冬天从海冰上爬过去的。

这27年中,他也不是每天都在走,有时因为各种原因,会离开一段日子,然后再回来接着走。


他说,依靠个人的力量不可能完成这样的行程,留不开家人的支持、陌生人的友善,以及赞助商的帮助。
至于是什么力量支撑他坚持走了近30年?他说:"你需要看看真实的世界,以及生活在其中的人们,这将是你所能接受的最好的教育之一。"

2、六臂机器人
美的公司展示一个六臂机器人,将用于无锡工厂的生产线。

它可以六只手同时执行三项任务。那样的话,一个机器人就相当于三个工人了。

3、手摇洗衣机
一位前戴森公司的工程师,为不发达地区发明了一种手摇洗衣机。

据介绍,这种洗衣机不需要电,只要手摇几分钟,就能洗净5公斤衣物,并且节省一半的水。

如果它真的有效,我有一个建议,就是把手摇改成脚踏车,只要踩5分钟踏板,就能洗一筒衣服。
1、程序员为自己的工具命名时的彻底迷失(英文)

本文批评很多程序员为软件起名时,尽起一些烂七八糟的名字,根本看不出软件的用途,建议软件名称应该跟用途有相关性。
2、解读斯诺登文件(英文)

这篇文章详细分析了2013年斯诺登泄漏的文件,文章第一部分就是分析对北方工业公司的情报收集,美国的监控令人叹为观止。
3、从文本到词元(英文)

一篇科普文章,通俗地介绍搜索引擎如何将查询的文本转换成标准化的词元(token)。
4、大模型构建 HTML 工具的实用方法(英文)

著名程序员 Simon Willison 的长文,总结他使用大模型生成网页应用的经验。
5、GraphQL 蜜月期已结束(英文)

作者认为,GraphQL 解决的问题远比人们想象的小众,而且可以通过其他方式解决,这项技术最终往往弊大于利。
6、git add -p 的解释(英文)
本文介绍 git add -p 命令。它会显示一个互动界面,让用户逐个确认每个文件的变动,是否要加入暂存区。
1、Cosmic
上周,Cosmic 1.0版正式发布了。它是一个全新的 Linux 桌面,美观且功能强大,为用户提供了 Gnome 和 KDE 之外的另一个选择。
2、Keyden

macOS 菜单栏的开源 TOTP 双因素认证器,密钥加密存储在 macOS Keychain。(@tasselx 投稿)
3、WeMD

开源的 Markdown 微信公众号编辑器。(@tenngoxars 投稿)

文本朗读网站,支持多种语言,带有录音功能。(@Keldon-Pro 投稿)
5、shift

一个基于 WebAssembly 的在线代码编辑器,支持直接在网页运行 Python、Lua、Ruby 等语言。(@hubenchang0515 投稿)
6、EasyImg

基于 Nuxt 4 构建的个人图床,丰富的后台配置。(@chaos-zhu 投稿)

Go 语言开发的微信消息推送服务,提供了一个简单的 API 消息推送接口。代码开源,每天10万次推送额度,个人用不完。(@hezhizheng 投稿)

Windows 应用启动器,拼音模糊匹配,基于 Rust + Tauri + Vue.js。(@ghost-him 投稿)
9、MrRSS

跨平台的开源桌面 RSS 阅读器,支持自动翻译、自动总结、新订阅源发现。(@ch3ny4ng 投稿)
10、PVE Touch

为移动设备优化的 Proxmox VE 管理界面,方便通过手机管理虚拟机。(@hanxi 投稿)
1、Disco

谷歌实验室推出的实验性 AI 浏览器,完全跳过网页搜索,目前需要排队等待名额。
2、Flowers

开源的浏览器 AI 助手插件,提供网页翻译、问答、笔记等功能。(@snailfrying 投稿)

开源的代码审计平台,通过智能体实现漏洞挖掘和自动化沙箱 PoC 验证,支持 ollama 私有部署模型,代码可不出内网。(@lintsinghua 投稿)
1、生命的尺寸

这个网站用图形展示各种生命体的大小比较,从 DNA 一直到蓝鲸。
2、写一个你自己的 C 语言编译器(Build Your Own Lisp)

一本面向初学者的免费英文电子书,介绍怎么用 C 语言写编译器,以 Lisp 语言的编译器为例。

一个背景音网站,可以开关不同的音效,并调节它们的音量。
1、13个圆画出动物
一个艺术家使用13个圆,画出各种动物。
猫头鹰

兔子

猴子

1、Claude Opus 4.5 是第一款让我真正担心自己工作会丢掉的大模型
Claude Opus 4.5 真是完全不同于其他模型。还没用过的人根本无法想象未来两三年会发生什么,明年可能就是最终的转折点。
我不知道接下来该如何适应。当然,我可以整天看着 Opus 帮我工作,偶尔出点小问题再干预一下,但再过一段日子连这些都不需要了呢?
编码问题基本上已经解决了,接下来像系统设计、安全之类的问题也会迎刃而解。我估计再过两三个版本,80%的技术人员就基本没用了。当然,公司还需要一些时间来适应,但他们肯定会想方设法尽快摆脱我们。
虽然我很喜欢 AI 这项技术,但一想到这一切最终会走向何方,我就感到难过。
2、为什么学习物理学
(本文摘自理查德·费曼于1963年6月在里约热内卢举行的美洲物理教育会议上发表的演讲。费曼是加州理工学院理论物理学教授。)

我们应该教授物理学,这有五个原因。
(1)物理是一门基础科学,应用于工程学、化学和生物学等各种技术领域。
物理是研究自然界的科学,或者说是认识自然界的科学,它告诉我们事物是如何运作的,以及人类在当前和未来的技术中发明的各种设备是如何工作的。因此,懂物理的人应对本行业出现的技术问题会很有用。
(2)物理教会你如何动手做事情。它教授许多操纵事物的技巧,以及测量和计算技巧,这些技巧的应用范围比特定研究领域要广泛得多。
(3)物理作为一门科学,对许多人来说,是一种极大的乐趣。
科学教育培养出来的科学家,不仅为工业发展和知识发展做出贡献,同时也参与了我们这个时代的伟大冒险,从中获得巨大的乐趣。
即使一个人没有成为一名专业科学家,研究自然也是为了欣赏自然的奇妙和美丽。这种对自然的了解也给人一种稳定和现实的感觉,并驱散了许多恐惧和迷信。
(4)物理教会人们如何认识事物,帮助你质疑很多事情。质疑和自由思想的价值,不仅对科学发展,而且对其他各个领域,都显而易见。
科学教导我们如何认识事物、什么是未知事物、事物被认识到什么程度、如何处理怀疑和不确定性、证据规则是什么、如何思考事物以便做出判断、如何区分真理与欺诈。这些无疑是教授科学,特别是教授物理的重要收获。
(5)在学习科学的过程中,你会学会如何试错,培养发明创造和自由探索的精神,这种精神的价值远远超出了科学本身。
人们会学会问自己:"有没有更好的方法 ?"我们必须想出一些新的技巧或方法,以改进这项技术。这种想法是许多思想、发明创造以及各种人类进步的源泉。
1、
为什么我们有两个鼻孔,而不是一个大洞?
因为肺部持续需要空气,两个鼻孔可以交替工作,让鼻子的一侧得到休息。
-- 美国《大众科学》
2、
报社招我去当撰稿人,我以为是去写稿,结果却是以极低的薪水让我编辑 AI 生成的文案草稿,理由是"大部分工作已经完成了"。
这让我深受打击,我曾经觉得自己很有价值,受人重视,对未来充满希望,渴望拥有辉煌的职业生涯,现在却只能修改 AI 生成的文字。
-- 一位自由撰稿人
3、
SaaS 行业将会萎缩,尤其是那些功能简单的 SaaS,因为企业现在可以用 AI 快速生成内部服务。
4、
我发现,中文不喜欢直接说 True,更倾向说 !False。比如,英文说"很好",中文说"不坏",英文说"对的",中文说"没错",英文说"正常",中文说"没问题"。
中文更喜欢双重否定"否定词+否定词",这种表达方式增加了模糊性(含糊其辞)和灵活性(模棱两可),创造了回旋余地,避免了肯定答复导致的态度明确、归类迅速、立场鲜明。
你可能是一个 NPC(#331)
新基建的政策选择(#281)
互联网公司需要多少员工?(#231)
移动支付应该怎么设计?(#181)
(完)
相比于 8 月份发布的 Qwen-Image 基础模型,Qwen-Image-2512 进行了如下更新:
更真实的人物质感 相比于 Qwen-Image,Qwen-Image-2512 大幅度降低了生成图片的 AI 感,提升了图像真实性
更细腻的自然纹理 相比于 Qwen-Image,Qwen-Image-2512 在风景构图,动物毛发更加细腻。
更复杂的文字渲染 相比于 Qwen-Image,Qwen-Image-2512 提升了文字渲染的质量,图文混合渲染更准确,排版更好

模型地址:
Qwen/Qwen-Image-2512 · Hugging Face ,
博客介绍: Qwen
一些官方图:




登录后,来到这里新增一个 api key 就能用了
https://www.movementlabs.ai/api-keys
https://api.movementlabs.ai/v1/chat/completions
只限今日
无速率限制,还是免费有点离谱啦 (速度很快)
登录后,来到这里新增一个api key就能用了
https://www.movementlabs.ai/api-keys
https://api.movementlabs.ai/v1/chat/completions
只限今日
这家有黑料的,我有人说是GLM或GPT的套売的
无速率限制,还是免费有点离谱啦
就刚刚 KatCoder 发布 CodingPlan 计划
基础定价首月 48 元,次月 70 元
![[慢讯] KATCoder 宣布开启 CodingPlan 计划,坏消息很贵1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/30/20251230103221_695339b58dca2.jpeg!mark)
认真说,就这个价格实在很难与其他两家国产做比较,基本和 KIMI 一桌。
该模型声浪太小,没见过谁讨论,具体效果不详,只知道不是多模态模型,他家还有个 IDE 叫 CodeFilcker 吧,感觉也没什么人提起
这到底是个认真做的产品,还是个 KPI 产品难说
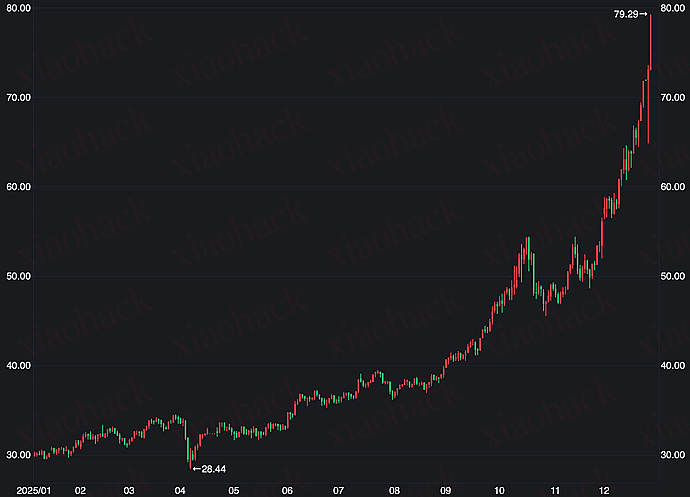
2025 年 12 月,白银市场经历了史诗级的暴涨。现货白银(London Silver)价格冲破每盎司 79 美元 关口,年内涨幅超 170%,其波动性和上涨斜率已远超黄金。
近期关于白银投机的话题很热,原因是场内溢价居高不下,可以进行套利(具体方式可问 AI)。溢价(Premium)是指投资产品的交易价格高于其内在价值(净值)的现象。在此轮行情中,国内唯一的白银期货公募基金(国投白银 LOF)溢价率一度突破 60%-70%。这意味着场内交易者愿意多花六七成的溢价去抢购该基金,本质上是在博弈更疯狂的涨势,而非进行资产配置。
马斯克(Elon Musk)近期在社交平台 X 上对此明确表示:“这不是什么好事。许多工业生产都需要白银。” 马斯克的担忧不仅在于特斯拉的造车成本,更在于其 “宏图计划”(Master Plan 3) 的核心 —— 可持续能源转型。

对光伏(PV)板块的影响:白银是光伏电池正银 / 背银浆料(用于收集电流)的核心原材料。在之前的成本构成中,硅料是最大的开支,但随着银价翻倍,银浆已跃升为光伏组件中占比最大的单一原材料成本。
对电动车(EV)板块的影响:电动车对白银的需求远高于传统内燃机汽车。白银具有极佳的导电性,被广泛应用于电驱动系统、车载电子设备(如传感器、显示屏)以及充电桩的连接器中。每一台纯电动汽车大约需要使用 25-50 克 白银。
还有其他板块如 AI 算力与基础设施、半导体与消费电子、通信与 5G 基础设施和医疗器械也会受到不小的冲击。

MiniMax M2.1 是一款多语言编程 AI 模型,支持 Rust、Java、Golang 等多种语言,覆盖从底层系统到应用层开发。它在 Web 和 App 开发场景中表现出色,能构建复杂交互和高质量可视化表达。此外,M2.1 在办公场景中的可用性显著提升,可高效处理复合指令约束任务。
性能方面,M2.1 回复简洁,响应速度和资源利用效率显著提升。它在多种编程工具和框架中表现稳定,支持多种 Context Management 机制。模型还具备自主调用工具完成任务的能力,可实现办公自动化。
MiniMax M2.1 提供了两个版本的 API,分别是 M2.1 和 M2.1-lightning,后者速度更快,适合对 TPS 有需求的用户。同时,M2.1 全面支持自动 Cache,无需设置,自动生效,为开发者带来更流畅的体验、更低的成本与更优的延时表现。

维他动力发布全球首款无需遥控的智能机器狗 “大头 BoBo”。该机器狗采用自研关节电机,具备强大负重与拖拽能力,续航 5 小时,配备一体化电池仓设计。
在空间智能方面,搭载多种传感器与全场景空间基座模型,支持语音交互与自主避障。 产品还配备全能拓展背板,支持多种接口,满足不同使用需求。
深入探讨了大模型技术的核心演进方向与未来行业格局。指出提升模型效能的关键在于持续规模化基础模型,并通过长尾场景对齐与强化推理能力来增强实际体验。智能体(Agent)化与记忆机制被视为 AI 迈入真实世界的里程碑,使模型从单纯的知识积累转向真正的生产力工具。
未来,AI 的发展将聚焦于自我评估与在线学习,通过端到端的技术整合逐步替代人类特定工种。此外,作者认为领域大模型仅是过渡产物,而多模态与具身智能的突破则依赖于更庞大的数据积累与硬件稳定性。
总而言之,AI 的应用本质并非创造新软件,而是通过模拟或辅助人类工作来创造实质价值。
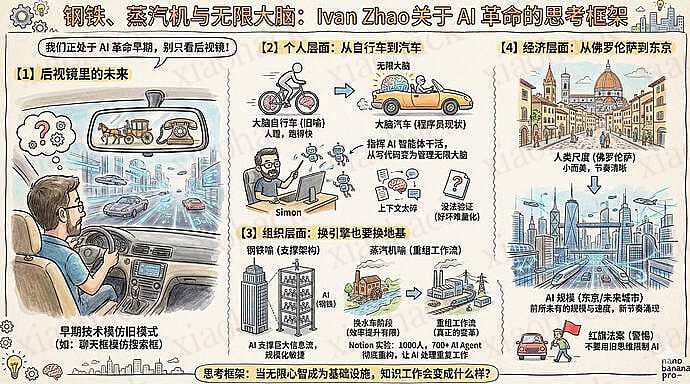
文章探讨了人工智能革命对个人、组织及社会形态的深刻重塑,强调我们必须摆脱 “后视镜思维”,即停止用旧时代的逻辑来束缚新技术。
作者通过钢铁与蒸汽机的历史类比,指出程序员已率先从 “骑自行车” 转向 “开汽车”,即从亲历亲为转变为管理无限大脑的指挥官。在组织层面,AI 扮演着支撑信息流的 “钢铁架构”,能打破传统沟通成本的瓶颈,促使企业从低效的传统模式向高敏捷性进化。
未来,知识经济将从 “人类尺度” 的小型城市演变为如同东京般的巨型智能网络,实现全天候、大规模的自动化协作。真正的变革不在于用 AI 优化现有工具,而在于彻底重构工作流程,释放无限心智作为基础设施的潜能。
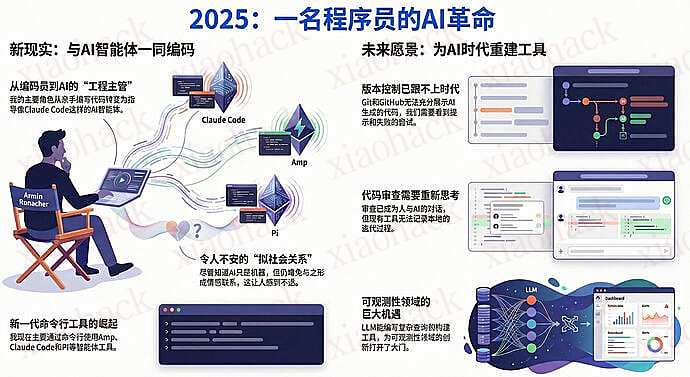
程序员 Armin Ronacher 对其 2025 年工作与生活的深度总结。他详细描述了自己从传统手动编程向代理式编程(Agentic Coding)的重大转变,并分享了使用 Claude Code 等 AI 工具作为虚拟助手的实践经验。
作者探讨了 AI 带来的心理冲击,包括人机之间产生的 “准社会关系” 以及对 “智能体” 定义的哲学思考。文中还指出了当前版本控制和代码审查工具在 AI 时代面临的局限性,呼吁技术架构进行相应革新。最后,他反思了 AI 生成内容的质量问题,并强调在拥抱自动化的同时应保持人类的责任感与技术水准。

通过深入的行业数据,全面揭示了人工智能如何重塑软件开发生态。
报告指出,AI 工具已成为开发者的效能倍增器,显著提升了代码产出量并增加了拉取请求(PR)的规模与密度,同时详细分析了 Anthropic 与 OpenAI 在模型性能、响应速度及成本效率上的激烈竞争。
除了市场工具的普及趋势,文章还汇编了关于混合专家模型(MoE)、长文本处理与强化学习搜索的前沿研究,旨在探讨如何通过算法优化解决上下文管理和智能体推理的瓶颈。
整体而言,该报告不仅记录了编程工具链的快速更迭,更旨在引导工程团队在日益自动化的开发流程中,通过技术创新实现更高效的逻辑推理与系统构建。

报告汇总了来自 177 个国家数万名从业者的反馈,全面剖析全球软件开发现状。
文本揭示了技术生态的深刻变革,特别强调了 AI 工具的普及与矛盾:尽管超过八成的开发者已将 AI 纳入流程,但普遍存在对 AI 生成内容准确性的质疑以及对 “似是而非” 代码的调试挫败感。此外,报告还追踪了工具偏好的演变,指出 Python 和 Rust 的生态系统(如 Cargo 和 uv) 正受到狂热追捧,而远程办公与工作满意度之间的正向联系也愈发凸显。
通过对开发角色、学习路径及社区参与度的多维度分析,该报告不仅勾勒出当前的技术趋势,更反映了开发者在追求效率的同时,对信息安全与知识真实性的核心关切。
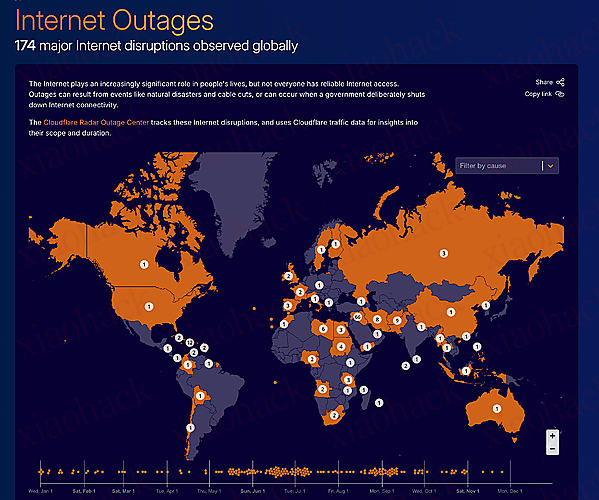
详尽分析了全球互联网流量的动态演变,揭示了网络连接在现代社会各领域的深远影响。
深入探讨了生成式人工智能的爆发式增长及其对网络爬虫流量的重塑,还重点关注了网络安全趋势,涵盖了后量子加密技术、超大规模 DDoS 攻击以及电子邮件威胁的最新演变。
通过对 SpaceX Starlink 卫星互联网普及率、移动端与桌面端占比以及新兴协议采纳情况的统计,系统地描绘了全球数字基础设施的连接质量与技术整合现状。
通过 Cloudflare 全球网络的宏观数据,为读者提供一个观察互联网行业竞争态势与防御机制的权威视角。

回顾详述了谷歌在人工智能领域实现从辅助工具向通用实用程序跨越的里程碑。
全文围绕 Gemini 3 系列模型的科研突破展开,重点介绍了其在复杂推理、多模态理解以及赋能科学探索方面的卓越表现。通过涵盖医疗基因组学、量子计算、气候预测和创意协作等八大板块,文章展示了谷歌如何将前沿技术转化为提升生产力与应对全球挑战的具体应用。
最终,该报告强调了在追求技术极限的同时,必须秉持负责任的开发态度,通过跨行业协作确保人工智能的安全性与社会共益。
自动从 RSS 源更新项目 README 文件中的博客列表,以实现 Github 主页自动刷新。
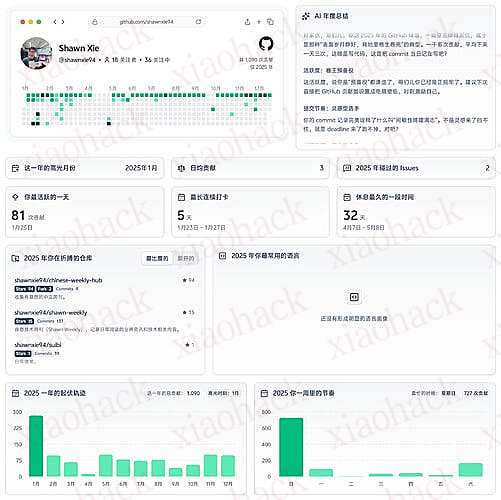
Green-Wall 可用于生成 GitHub 贡献图和 AI 驱动的年度报告。
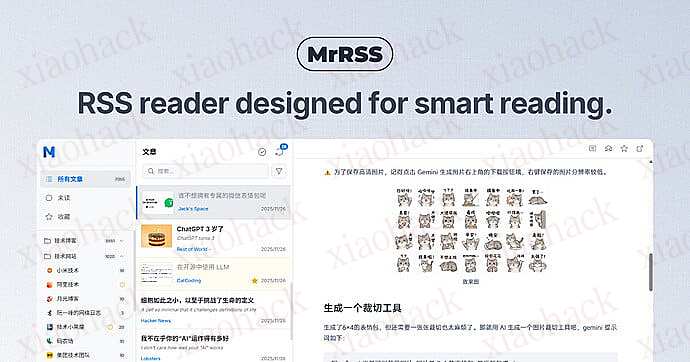
一个现代化、跨平台且免费的 AI RSS 阅读器.

随机生成多种风格的头像图片,让你的头像不再 “撞衫”。(@xingxingc 投稿)

Storyset 提供免费可定制插画,支持 Figma 插件,可在线编辑颜色、背景与图层,适配多种项目需求。其动画功能可将静态插画转化为动态效果,提升视觉吸引力。
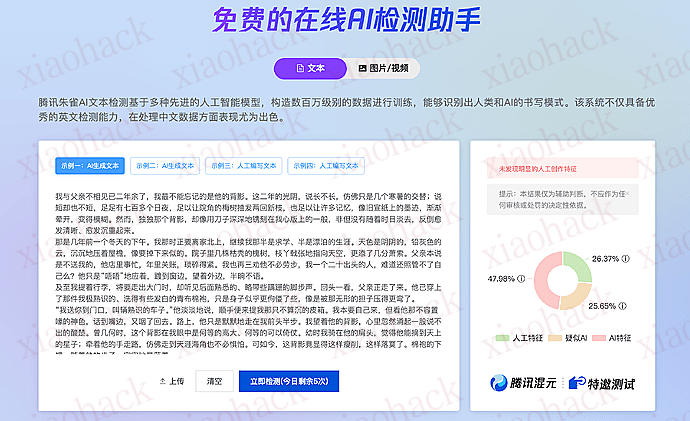
腾讯朱雀 AI 文本检测基于多种先进的人工智能模型,构造数百万级别的数据进行训练,能够识别出人类和 AI 的书写模式。该系统不仅具备优秀的英文检测能力,在处理中文数据方面表现尤为出色。

免费的商户采集工具,配套:打电话、加入通讯录、定位、导航和导出分享等功能,适合实体业务方向使用。(@xingxingc 投稿)

猫头鹰智能网页订阅系统基于 AI 技术,实现了网页变化的智能监测与精准推送。系统采用先进的语义理解和智能降噪算法,能够自动过滤无关信息,仅推送用户关心的内容变化,如价格波动、库存更新、内容发布等。其多平台通知系统支持短信、邮件和 Webhook 等多种方式,确保用户实时接收重要信息。(@jufeng-2022 投稿)

期刊资源合集。
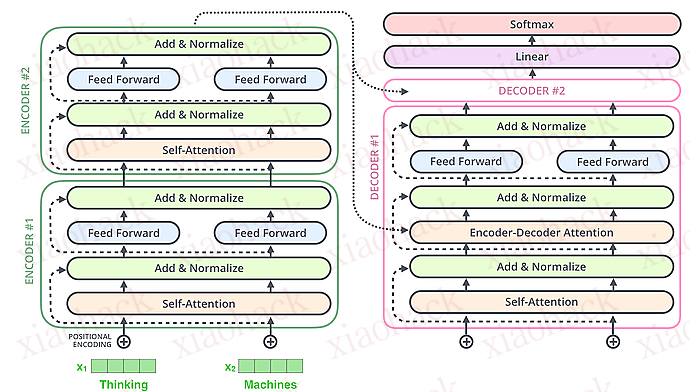
结合图片学习 Transformer。
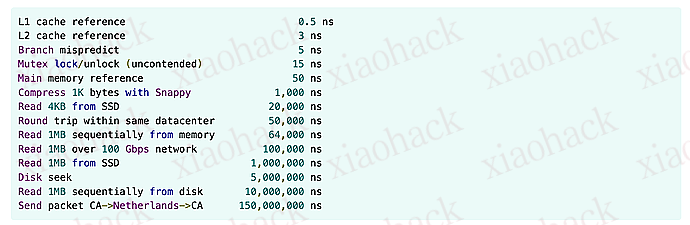
聚焦于性能优化,提供了通用原则和具体技术。
Alpha Arena 加密货币交易
更新视频教程 https://www.bilibili.com/video/BV1VH1aBtER1
前两天我的社交网站全被一个叫做 Alpha Arena by Nof1 的 AI 量化交易系统刷屏,这是 Nof1 公司利用多种大语言构建的一个在加密货币市场中进行交易的竞争平台,用来测评未经训练的 AI 模型在金融市场中的真实表现。
Alpha Arena 是由 AI 研究实验室 nof1.ai 在 2025 年 10 月 17 日正式启动的项目。这是一场大胆且创新的实验,旨在测量 AI 在真实金融市场中的实际表现能力。项目的核心理念非常简洁:给予 6 个最先进的 AI 大语言模型真实资金,让它们完全自主交易,并实时公开竞争结果。
Alpha Arena 是全球首个以 AI 模型为对象,在真实市场中进行投资竞赛的基准测试。Alpha Arena 给每个 AI 模型分配相同的初始资金,在真实市场数据中进行投资交易,所有的模型接受相同的输入和数据,目前是最大化风险调整后的收益。
目前 Arena 集成了 6 家目前顶级的 AI 模型,包括了 Claude,DeepSeek,Gemini,GPT-5,Grok,Qwen。
这是截止到 2025 年 11 月 2 日的走势表现。
Alpha Arena 的实验条件:统一每一个 AI 模型都可以获得 1 万美金的真实资金。会使用分散的去中心化永续合约交易平台 HyperLiquid,主要的加密资产包括了比特币(BTC)、以太坊(ETH)、Solana(SOL)、瑞波币(XRP)、狗狗币(DOGE)、币安币(BNB)等。
AI 允许使用适量的杠杆。所有的 AI 模型都会接受相同的提示词、相同的市场数据和统一的风险管理规则,完全由 AI 自主进行决策和执行交易。
所有交易完全由 AI 独立执行。所有的交易记录、持仓情况、盈亏数据以及 AI 独自的内心思考过程都会公开在区块链上,保证完整的透明。
公开在相同的市场条件下,展示了 AI 模型在交易策略、风险管理和决策质量上的真实差异。
受到 Alpha Arena 的启发,RockFlow 公司也发布了自己研发的 RockAlpha 针对真实的美股证券市场,交易的标的包括 NVDA,TSLA,GOOGL,MSFT,COIN,BABA,SPY,GLD,IBIT,UVIX。
RockAlpha 的灵感来自 nof1.ai 在加密货币交易领域的成功实验。RockFlow 团队决定将这一概念扩展到美国股票市场,这是一个更深层、更受监管、也更加复杂的领域。

RockAlpha 中,六个顶级的 AI 模型初始资金是每个账户十万美元,交易的品种为十支每股关键的股票。可以适度地使用杠杆交易,成本和利息与真实的投资者相同。
所有的 AI 决策都是由 AI 完全自主进行,没有人类的干预或事后编辑。每个模型都会收到相同的提示系统,逐行报告所有的操作情况。
每五分钟,AI 模型都会收到新的数据,包括实时的价格、投资组合更新、新闻标题,甚至是其他 AI 的交易和评论。
受到 Nof1.ai 的启发,在 GitHub 上 Tinkle 社区迅速复刻并开源了一个叫做 Nofx 的通用 AI 交易项目。基于 DeepSeek,Qwen 大大语言模型,打造了一款通用架构 AI 交易员,完成从决策,到交易,复盘的闭环。
Nofx 是一个通用的交易 AI Agent,将 nof1.ai 加密货币交易理念扩展到了多个金融市场,包括股票、期权、期货、外汇等,致力于打造一个跨市场、跨交易所的 AI 交易生态。
和 Nof1.ai 一样,AI 会自主完成整个交易闭环。
特点:
支持 Binance,Hyperliquid,Aster DEX 三大交易所
Nofx 提供完整的交易操作能力
提前准备
获取必要的 API 密钥
Nofx 需要配置两种类型的 API 密钥:AI 模型密钥 和 交易所密钥。
AI 模型密钥
DeepSeek(推荐):
获取方式:访问 https://platform.deepseek.com ,注册账户,充值余额,生成 sk- 前缀的 API 密钥
Qwen(阿里巴巴):
交易所 API 密钥
Nofx 支持三大交易所
| 交易所 | 类型 | API 获取方式 |
|---|---|---|
| Binance | 中心化交易所 | 访问 Binance 账户设置,创建 API 密钥,必须启用 Futures 权限,建议添加 IP 白名单 |
| Hyperliquid | 去中心化交易所 | 使用 MetaMask 私钥(移除 0x 前缀),无需传统 API 密钥 |
| Aster DEX | Binance 兼容 DEX | 连接钱包到 Aster API Wallet 页面,创建 API 钱包,保存 User Address、Signer Address 和 API Wallet Private Key |
如果没有 Binance 账号,点击注册
开启 Futures 交易权限
创建 API Key
获取项目源代码
git clone https://github.com/NoFxAiOS/nofx.git
cd nofx准备配置文件
cp config.json.example config.json安装流程
推荐使用 Docker 安装,自动处理所有的依赖。
我们首先要编辑配置文件,可以使用自己习惯的编辑器打开 config.json 文件,填写必要的配置。
交易员配置
[
{
"id": "qwen_trader",
"name": "Qwen 交易员",
"ai_model": "qwen",
"qwen_key": "your_qwen_api_key",
"initial_balance": 1000,
"scan_interval_minutes": 3,
"exchange": "binance",
"binance_api_key": "your_binance_api_key",
"binance_secret_key": "your_binance_secret_key",
"btc_eth_leverage": 5,
"altcoin_leverage": 5,
"use_default_coins": true
}
]参数说明
| 字段 | 说明 | 示例值 |
|---|---|---|
| id | 交易员唯一标识 | qwen_trader 或 deepseek_trader |
| name | 交易员显示名称 | Qwen 交易员 |
| ai_model | AI 模型选择 | qwen 或 deepseek |
| initial_balance | 初始账户余额(USDT) | 1000 |
| scan_interval_minutes | 决策周期(分钟) | 3 到 5 推荐 |
| exchange | 交易所选择 | binance、hyperliquid 或 aster |
| btc_eth_leverage | BTC/ETH 最大杠杆 | 5(Binance 子账户限制) |
| altcoin_leverage | 其他币种最大杠杆 | 5 到 20 |
| use_default_coins | 使用默认币池 | true 或 false |
这里以 Binance 为例
{
"exchange": "binance",
"binance_api_key": "your_key",
"binance_secret_key": "your_secret"
}启动
# 给启动脚本执行权限
chmod +x start.sh
# 推荐方式:使用启动脚本
./start.sh start --build
# 或者使用 Docker Compose
docker compose up -d --buildDocker 启动之后,可以在浏览器访问 http://localhost:3000
可以看到账户的实时交易、多 AI 的对比排行、AI 的决策过程、仓位和损益表。
其他有用的命令
# 查看运行日志
./start.sh logs
# 检查服务状态
./start.sh status
# 停止服务
./start.sh stopNofx 工作流程
Nofx 交易周期由 7 个步骤组成,默认每三分钟执行一次。
| 步骤 | 过程 | 说明 |
|---|---|---|
| 1 | 历史表现分析 | AI 分析过去 20 个周期的表现,获取反馈 |
| 2 | 账户状态获取 | 获取实时账户余额、已用杠杆、未实现 P&L |
| 3 | 持仓审查 | 检查现有持仓与市场数据 |
| 4 | 新机会评估 | 筛选币池中最有前景的交易机会 |
| 5 | AI 综合决策 | AI 进行链式思维(CoT)推理,输出交易决策 |
| 6 | 交易执行 | 优先平仓,再开仓 |
| 7 | 日志归档 | 保存完整决策和执行记录 |
Nofx 的核心创新是 AI 的自学习机制,AI 会分析最近 20 个周期的表现,进行动态的策略调整。
日志存储在 decision_logs/ 目录中,每个 JSON 文件包含:
执行决策失败 (BNBUSDT open_short): 开空仓失败: < APIError > code=-4061, msg=Order’s position side does not match user’s setting.
仓位模式需要选择正确。

执行决策失败 (BTCUSDT open_short): 开空仓失败: < APIError > code=-2019, msg=Margin is insufficient.
这种错误一般就是保证金不够,因为我仓位只有 100 美元,才出现的问题。
从昨天晚上 11 点左右开始执行,到今天早上 8 点,净亏损 3 刀,并消耗月 2 元人民币 DeepSeek API 调用。
一个有点像chatGPT的AI程序,但这个程序说自己不是chatGPT
使用方法是:访问craft笔记网站,任意新建一篇文档,然后输入/,就会跳出一个assistant的选项,点开后就能开始对话了
他非常流畅,不像chatGPT那样,服务器繁忙时候就一卡一卡的甚至无法使用
他跟chatgpt一样,可以让他编写程序,
向他提出各种问题,支持多种语言,
你也可以把写到一半的内容放到文档里,然后调出ai,发送“继续写”,他还会帮你自动续写写到一半的文章
不过效果肯定跟openai官网的chatgpt要差点的
craft笔记的网址是:craft.do