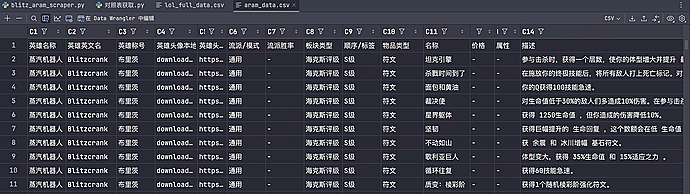
不同类型代理(HTTP、SOCKS5、HTTPS)连接速度实测与优化技巧
随着网络隐私和数据抓取需求的不断增加,各种代理服务在网络应用中扮演了越来越重要的角色。HTTP、SOCKS5和HTTPS是最常见的几种代理类型,它们各自有不同的性能表现和适用场景。尤其对于需要较高匿名性和稳定性的用户,住宅代理因其高隐蔽性和低封禁率,成为了提升网络连接质量的重要工具。通过对不同代理类型的了解与优化,可以帮助用户更好地管理网络连接,提高效率和安全性。 HTTP代理是最常见的一种代理类型,主要用于处理基于HTTP协议的请求,如网页浏览。由于其协议简单且部署方便,HTTP代理通常能够提供较快的连接速度,特别适合处理静态网页和不涉及复杂交互的数据请求。 SOCKS5代理不仅支持HTTP协议,还能够处理TCP、UDP等协议,适合更多复杂的网络任务。对于需要视频流、P2P传输或大文件传输的应用场景,SOCKS5代理通常能提供更高的带宽和更稳定的连接,特别适合高需求的网络操作。 HTTPS代理通过SSL/TLS加密传输数据,能够有效保证数据的安全性,适合需要保护敏感信息的场景,如银行交易或个人隐私保护。尽管加密会带来一些延迟,选用高质量的HTTPS代理服务,仍然可以在保持安全性的同时,实现较快的连接速度。 优化技巧: 选择地理位置接近的节点:选择距离目标服务器较近的HTTPS代理节点,可以减少加密过程中的延迟,从而提升连接速度。 启用缓存机制:对于常访问的内容,使用代理缓存可以减少重复请求时的延迟,提升加载速度。 住宅代理使用真实的家庭IP地址,这使得它们比传统的代理更难被封禁,且更适合进行大规模数据抓取。由于其较低的封禁率和高隐蔽性,residential proxies在保护用户身份的同时,能提供相对稳定的连接,尤其适合进行复杂的自动化任务或需要避免IP封锁的场景。 优化技巧: 选择稳定的IP池:确保使用高质量的住宅代理池,减少因IP频繁被封而影响任务进度。 无论选择HTTP、SOCKS5、HTTPS或是住宅代理,提升连接速度的核心在于如何合理管理代理服务。以下是一些通用的优化建议: 选择优质的代理源:选用稳定、带宽高的代理服务商,避免使用低质量的代理,确保快速且稳定的网络连接。 不同类型的代理各自具有独特的优势和适用场景,合理选择并优化代理服务,能够有效提升网络连接速度和稳定性。无论是HTTP代理的简单高效,SOCKS5代理的高性能,还是HTTPS代理的安全性,了解它们的特性并加以优化,能够帮助用户获得更加流畅的网络体验。而通过精心配置和管理proxy server,可以在保护隐私的同时,确保高效的在线操作。1. HTTP代理:速度优先,适合简单请求
2. SOCKS5代理:高效且支持更多协议
3. HTTPS代理:安全性和速度的平衡
4. 住宅代理:高隐蔽性与稳定性的选择
调整代理策略:在进行大规模抓取时,合理安排代理的使用频率,避免过度请求导致的封禁,确保连接的稳定性和持续性。5. 综合优化:提升所有代理类型的连接速度
定期更新代理池:定期更换代理IP,避免长时间使用相同的IP导致被封禁,确保代理池的活跃性。
监控延迟与负载:持续监控代理的延迟、带宽和负载情况,及时更换性能差的代理节点,保持代理池的高效运行。结语





![[案例] 帮佬友分析 xhs - 幼小衔接 数学和英语虚拟资料 - 一个市场调研分析例子2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122130348_6971afb42568e.jpeg!mark)
![[案例] 帮佬友分析 xhs - 幼小衔接 数学和英语虚拟资料 - 一个市场调研分析例子3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122130351_6971afb7aae9c.png!mark)
![[案例] 帮佬友分析 xhs - 幼小衔接 数学和英语虚拟资料 - 一个市场调研分析例子4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122130353_6971afb9dc0a7.png!mark)
![[案例] 帮佬友分析 xhs - 幼小衔接 数学和英语虚拟资料 - 一个市场调研分析例子5](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122130356_6971afbc06688.png!mark)
![[案例] 帮佬友分析 xhs - 幼小衔接 数学和英语虚拟资料 - 一个市场调研分析例子6](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122130406_6971afc62059c.png!mark)
![[案例] 帮佬友分析 xhs - 幼小衔接 数学和英语虚拟资料 - 一个市场调研分析例子7](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122130408_6971afc8b857c.png!mark)
![[案例] 帮佬友分析 xhs - 幼小衔接 数学和英语虚拟资料 - 一个市场调研分析例子8](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122130412_6971afcc46b06.png!mark)
![[案例] 帮佬友分析 xhs - 幼小衔接 数学和英语虚拟资料 - 一个市场调研分析例子9](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122130415_6971afcf324dd.png!mark)
![[案例] 帮佬友分析 xhs - 幼小衔接 数学和英语虚拟资料 - 一个市场调研分析例子10](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122130417_6971afd1a6b25.png!mark)