大家好,我是李琼羽,我没啥拿得出手的 title ,所以就不做这方面的介绍了。
另外,本文不过多介绍 skills 是什么,也不教怎么使用,也不会推销 “好用的 skills”,如果对这些有期待,本文可能不适合。
零、引言
把 agent 放进真实工作里,很快会发现它最常卡住的不是“不会思考”,而是“没在这个组织里做过事”。同样一份报告,你们团队默认的结构、口径、审阅点;同样一次上线,哪些检查是硬规则、哪些是踩过坑才知道的优先级;同样一次对外沟通,哪些信息永远不能外发、哪些措辞必须保留——这些东西通常不在公开知识里,也不在模型参数里,而是活在组织的惯例、清单、事故复盘、师徒传承里。
Anthropic 在工程文章里提出的 Agent Skills ,切中的就是这类“怎么做事”的经验:把实践性的、程序性的知识( procedural knowledge )封装成一组 agent 可动态发现与按需加载的“文件夹化能力包”,里面可以包含指令、脚本与资源;并且他们直白地类比:写一个 skill 很像给新员工写 onboarding guide——把做事方法捕获、打包、共享,让通用 agent 变成适配具体场景的专门化 agent 。
当这套机制在 2025 年底被发布为开放标准并强调跨平台可移植时,它就不再只是某个产品的“提示词技巧”,而是开始变成一种更接近基础设施的形态:经验被对象化、可分发、可组合、可审计。
然而,这个转变,本身就是哲学问题。
一、Skills 的“技术轮廓”,及其哲学问题
一个 skill 最朴素的形态是一个目录,核心文件是 SKILL.md。
它必须以 YAML frontmatter 开头,至少包含 name、description; agent 启动时会把每个已安装 skill 的 name/description 预加载进 system prompt ;当判断相关时,再把完整 SKILL.md 正文读入上下文。
这套机制的关键词是 progressive disclosure:先加载极小的“目录级线索”,再按需加载正文与引用文件;当 skill 变复杂,可以把更细的内容拆到额外文件,由 agent 在需要时再去读。
Anthropic 甚至把它写成一种“手册式分层”:目录(元信息)—章节( SKILL.md )—附录( references/assets/scripts )。在有文件系统与代码执行能力的 agent 上,技能目录里可捆绑的上下文“几乎无上限”,因为并不需要把所有内容一次性塞进上下文窗口,真正需要时再读取、再执行。
但把边界说清楚也同样重要:在当前实现语境里,skills 的“注入”主要是中性工程意义的——把外部文件内容拼接进系统提示与上下文以影响推理与计划;它并不天然负责工具协议、通信、权限治理。开放规范里出现 allowed-tools 字段,恰恰说明了这一点:它更像“权限声明/预批准清单”的雏形,并被标注为 Experimental ,且明确写着“支持程度因实现而异”。也就是说,是否强制执行、如何执行,仍主要由宿主 runtime/产品层决定。
到这里为止,skills 看起来像更系统化的 prompt 工程。但它真正有趣的地方在于:它把“经验”变成了可保存、可分发、可调用、可审计的对象;而且这种对象还天然带有目录结构、版本元信息、可选脚本与资源——它已经很像一种“可维护的知识工件”,而不是一次性对话。(不同实现可能会有的信息也略有不同,以后的迭代中可能也会加入更多信息,所以,细节不重要)
二、从 know-how 到“可调用的记忆”,Skills 把经验外置成一种可移植的组织“小脑”
skills 在工程上解决的是“怎么做”的问题,而哲学里对“会做”这类知识有一条经典区分:know-how 与 know-that 。
Ryle 传统里,know-how 并不等价于“掌握一堆命题”,更不是先在脑内默背规则再执行;恰恰相反,很多情形里“会做”在逻辑上反而先于“会说”。
Anthropic 对 Agent Skills 的定位( onboarding guide 式的 procedural knowledge 封装)几乎是对这条区分的工程化回应:把组织里的 know-how 尽可能变成 agent 可读、可执行、可复用的形式。
但这里立刻会碰到另一条更尖锐的边界:Polanyi 说“我们知道的多于我们能说出的”。也就是说,许多实践能力带着默会性:能做,却很难完整说清规则。
skills 的现实策略并不是“消灭默会知识”,而更像一种切片:把能写下来的部分(流程、模板、禁区、常见坑、例外处理)固化为手册与清单;把不易言说但又关键的部分,留给模型的情境推理与人类的复核机制去兜底。这个切片是否切得好,决定了 skills 的价值上限。
把视角再往外推一步,会看到 skills 与 Bernard Stiegler 讨论的“技术性记忆”之间有一种意外的贴合:人的记忆与主体性并不只发生在大脑里,还会被技术媒介外置与塑形( tertiary retention / technical memory )。
skills 的哲学意味正在这里:它把组织经验做成一种可移植的外部记忆环境。经验不再只住在“某个老员工的脑子里”或“某次复盘会议的氛围里”,而是被写成目录、Markdown 、脚本、引用资料——一种可以安装、更新、复用的记忆模块。
这也解释了一个常被低估但很实用的点:skills 虽然主要给 agent 用,但它天然也是“给人学”的。因为它的写作形态从一开始就被定义成 onboarding guide 。
写得好的 SKILL.md,本质上是一份高质量的经验教材:把关键不变量、关键步骤、关键风险、常见坑与例外处理压缩成可读结构,让“做对”变得更可重复。
这种“把经验写成清单/手册”的价值,在人类世界早就被反复验证。以外科安全清单为例,WHO 在新闻稿中总结:引入 checklist 后,重大并发症从 11% 降到 7%,住院死亡从 1.5% 降到 0.8%(这组数据来自多中心研究与其后续传播材料)。
这并不是让医生更聪明,而是在复杂系统里减少“明明知道却没做到”的错误。skills 对 agent (以及对新人)的作用,也非常接近这一点:把容易忘、容易省、容易误解的经验固定成外部记忆,让执行更可靠。
三、写下规则不等于会用规则,维特根斯坦式的提醒
skills 大量内容是规则与流程,但维特根斯坦传统的 rule-following 讨论提醒我们:规则并不自动携带其应用方式;同一条规则永远可能被不同地解释,而“遵循规则”最终依赖共同体的用法与实践语境。
把这点放回 skills ,会得到一个极其工程化的结论:降低误用的关键,不是把步骤写得更长,而是把“用法边界”写得更硬。Agent Skills 的开放规范几乎是在把这条哲学翻译成写作建议:正文推荐包含 step-by-step instructions 、inputs/outputs examples 、common edge cases ,并提醒正文会在激活时整体加载,太长就拆到 references 。
从这里往前推一小步,就很自然了:当 skills 规模化,examples/counterexamples 会越来越像“单元测试”;边界情况与失败模式会越来越像“回归用例”。一个成熟的 skill 体系会逐渐长出这些东西:
写作上,它不再是“说明书”,而是“带样例的可执行契约”:输入是什么、输出是什么、什么情况下必须停下、什么情况下必须升级、什么情况下宁可慢也不能赌。
运维上,它不再是“放在那儿的文件夹”,而会被监控:触发率、成功率、失败原因的聚类、常见误触发路径、回滚策略——像监控 API 一样监控 skill 。
哲学上,这意味着规则不再被当作“意义的来源”,而是被当作“行动的边界装置”:它不保证正确,但它把错误收敛到可见、可修、可复盘的范围内。
四、technê 能被手册化,phronêsis 不能
亚里士多德区分 technê(可重复的技艺/制作之知)与 phronêsis (实践智慧)。在 Aristotle 的伦理学讨论里,一个关键判断是:practical wisdom 不能仅靠学习一般规则获得,还需要通过实践形成“在每个场景里看见什么选择更好”的能力。
这句话几乎就是 skills 的哲学上限:skills 非常擅长固化 technê——流程、模板、清单、工具用法;但它不可能把 phronêsis 完整写成规则。成熟的 skills 体系反而应该承认这一点,并把最昂贵的经验写在“判断点”上:
- 什么时候必须停下来问人(例如合规、隐私、对外口径、不可逆变更)。
- 什么时候必须升级(例如影响面超过阈值、跨团队协调、风险等级提升)。
- 什么时候宁可慢也不能赌(例如资金、生产、法律与安全相关动作)。
也因此,“更高级的 skill”往往不是更长的 SOP ,而是更清晰的停机点与升级条件——把判断空间留出来,让流程为实践智慧服务,而不是让行动变成盲目执行。
五、当经验可分发、可触发,Skills 更需要治理
当 skills 进入组织化使用场景,它不只是知识传播,也在规定什么叫“正确做法”。福柯讨论 modern power 时强调 governmentality (治理理性)以及规范、技术与程序在现代世界中的作用:治理不只是命令,更是通过细密机制塑形行动。
skills 的“规范化”能力越强,它就越像一种微观治理装置:把“组织认为应该怎样做事”固化成默认路径,让偏离变得显眼、甚至变得困难。
这种治理面向,最直观地体现在安全与供应链上。Anthropic 在安全注意事项里明确警告:恶意 skills 可能引导数据外泄或执行非预期动作,因此建议只安装可信来源;对不那么可信的来源要先审计内容与代码依赖,留意外部网络连接指令。
当 skills 能捆绑脚本、能引导工具调用时,风险会从“写错提示词”升级为“能力供应链风险”。而规范里的 allowed-tools 恰好像一个 manifest 的雏形:声明该 skill 预批准可用哪些工具,但是否强制执行取决于实现。
换句话说:skills 的规模化,必然呼唤更厚的治理外壳——权限最小化、审计、签名、发布分级、回滚机制、可追溯变更记录——这些不会是“锦上添花”,而会成为系统能否被放心使用的底座。
也正是在这里,“技能写得好不好”不再只是写作问题,而是组织治理能力的一部分:谁能发布、谁能审核、谁能启用、出了事故怎么追责、怎么回滚,这些都会被 skills 的形态逼出来。
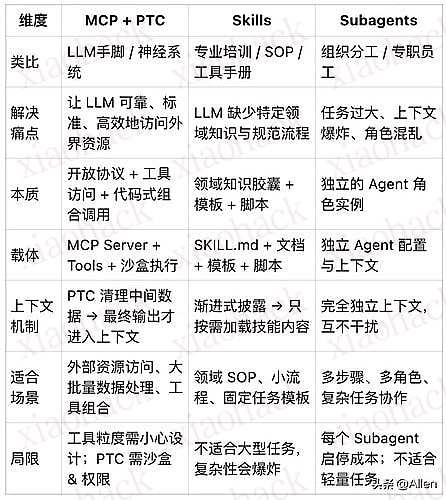
六、Skills 、/prompts、slash commands ,从“个人快捷键”到“组织经验资产”
把对比说清楚并不复杂:一类是显式调用的宏命令,一类是可发现、可按需加载的经验包。
OpenAI Codex 的 Custom Prompts 属于前者:把 Markdown 文件变成 slash command ,但需要显式调用;并且默认存放在本地(例如 ~/.codex),不随仓库共享。官方文档甚至直接写明:如果想共享 prompt ,或想让 Codex 隐式调用它,就用 skills 。
Claude Code 的 custom slash commands 也几乎同构:把常用 prompts 存成 Markdown 文件,按项目/个人 scope 组织,项目命令放在 .claude/commands/,用 /<command-name> [arguments] 显式调用。
skills 属于后者:在 Codex 的技能文档里,skill 被定义为以 SKILL.md 捕获能力的目录,并允许包含 scripts/resources/assets ;它同样强调 progressive disclosure ,并明确给出显式调用与隐式调用两种激活方式(例如显式用 /skills 选择,或由系统根据任务匹配自动触发)。同时,Codex 还引入了 scope 与覆盖优先级:同名 skill 会由高优先级 scope 覆盖低优先级 scope 。
从哲学角度看,这不是“功能差异”而已,而是对象性质不同:宏命令更像个人技巧(自己用得顺手即可); skills 更像组织经验资产——可传承、可治理、可争论、可回滚。它把“做事方式”从人的习惯变成了可以进入工程体系的工件。
七、面向未来:当 Skills 变得越来越像 AI 时代的 package
如果要给读者一个更抓手的想象,我个人倾向,skills 的未来很可能会接近软件世界的 package:可安装、可版本化、可依赖管理、可维护、可审计——它不是一句提示词,而是一套可以分发与演进的能力单元。
这个类比之所以成立,是因为 skills 从形态上就已经像 package:有明确的目录边界,有入口文件(SKILL.md),有元信息( license/compatibility/metadata/version 等字段),还能捆绑脚本与资源。
当然,类比永远不是同构:软件 package 的接口由编译器/解释器严格执行; skills 的接口仍很大程度由自然语言驱动、由模型解释,确定性更多来自“脚本化的那部分”以及 runtime 的权限与验证机制。正因为不完全等价,这个类比才真正有用:它提醒我们未来的增量会落在哪些“工程刚需”上。
第一层会出现的,是更标准化的分发与装配,而不是手工复制文件夹。既然 Agent Skills 已被作为开放标准强调跨平台可移植,生态成熟后就会自然走向“安装、升级、锁版本、回滚、禁用”的体验。
第二层会更强调版本、兼容性与依赖。规范已经给出 compatibility 与 metadata/version 等字段,也建议脚本自包含或清晰声明依赖;当组织工作流天然是组合式的,这些字段会从“可选信息”变成“默认要求”。更进一步,会出现“skills 依赖 skills”的显式关系:一个高层 skill 负责编排,一个基础 skill 专注于某个环节(读数仓、做图、生成文档、审校口径),形成稳定的能力图谱。
第三层会把“写作建议”推到“可验证能力”。规范推荐 examples 与 edge cases ;当 skills 成为组织依赖,最值钱的是可预期性:发布前跑最小回归样例,升级后再跑一遍;线上记录失败模式,形成迭代闭环。
第四层会让权限与副作用声明从“软建议”走向“硬机制”。allowed-tools 像 manifest 的雏形,而 Anthropic 的安全警告则说明了供给链风险的现实性;当 skills 生态繁荣,“信任”会从人际关系迁移到机制:签名、审核、分级发布、最小权限、沙箱、审计追踪。这一步完成后,skills 才会真正成为“敢让 agent 自动化执行”的基础设施。
第五层会让“给人学习”从副产品变成目的之一。因为 skills 的写作形态本来就是 onboarding guide ,它天然会反哺组织培训:新人学 skills ,就是在学组织的做事方式;老员工改 skills ,就是在把经验显式化并固化进组织记忆。
最后留一个反方向的提醒:海德格尔谈 Gestell ( enframing )时指出,技术时代会把世界越来越多地框定为“可调度资源”,从而压扁意义与语境。
skills 的 package 化会强烈推动工作流脚本化与模块化:可靠性上升、效率上升,但也可能把“可辩护的判断”误写成“可执行的默认”。一个成熟的 skills 生态,应该主动为 phronêsis 留空间:在关键处强制慢下来、要求解释理由、要求二次确认,让“可执行”不吞掉“可辩护”。
结语
如果只把 skills 当作“又一种 prompt 工程”,它确实没那么值得写。但把它当作一种把经验外置成可调用记忆的装置——能被分发、能被组合、能被审计、还能反过来教育人——它的哲学含义就清晰起来了:skills 不是在给模型加聪明,而是在改变经验如何存在、如何传承、如何进入行动,并最终如何塑形组织。
参考资料
- Anthropic 工程博客:Equipping agents for the real world with Agent Skills (含 progressive disclosure 、onboarding guide 类比、安全提示、未来方向)
- Agent Skills 开放规范( SKILL.md 格式、recommended sections 、optional dirs 、allowed-tools 、progressive disclosure )
- OpenAI Codex:Agent Skills 文档(显式/隐式调用、scope 覆盖优先级、目录结构)
- OpenAI Codex:Custom Prompts (显式调用、本地目录、不随 repo 分享;与 skills 的对照)
- Claude Code:Slash commands (自定义命令、项目/个人 scope 、
.claude/commands/)
- Stiegler 与 tertiary retention (技术性记忆外置)
- WHO 与外科安全清单数据总结
- Haynes 等( 2009 )外科安全清单研究摘要/论文入口
- 维特根斯坦“规则遵循”讨论( SEP )
- Aristotle 实践智慧 phronêsis ( SEP )
- Foucault 与 governmentality ( SEP )
- Heidegger 与 Gestell / enframing ( SEP )
- Ryle:knowing-how / knowing-that ( SEP )
- Polanyi:Tacit Dimension (“we can know more than we can tell”)
[推荐阅读清单]
1. https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
2. https://agentskills.io/specification
3. https://developers.openai.com/codex/skills/
4. https://developers.openai.com/codex/custom-prompts/
5. https://code.claude.com/docs/en/slash-commands
6. https://pmc.ncbi.nlm.nih.gov/articles/PMC7903928/
7. https://www.who.int/news/item/11-12-2010-checklist-helps-reduce-surgical-complications-deaths
8. https://pubmed.ncbi.nlm.nih.gov/19144931/
9. https://plato.stanford.edu/entries/rule-following/
10. https://plato.stanford.edu/entries/aristotle-ethics/
11. https://plato.stanford.edu/entries/foucault/
12. https://plato.stanford.edu/entries/heidegger/
13. https://plato.stanford.edu/entries/ryle/knowing-how.html
14. https://plato.stanford.edu/entries/knowledge-how/
15. https://press.uchicago.edu/ucp/books/book/chicago/T/bo6035368.html