今年的 CES 真可谓是八仙过海,黄仁勋、苏姿丰、陈力武等“经典面孔”齐亮相; 不过台上谈的已不只限于显卡、算力和制程,还在于 AI 接下来要被带去哪里。
在 AMD 的专场演讲中,苏妈甩出一个大胆判断:
“未来五年内,将有 50 亿人每天使用 AI,超过世界人口的一半。”
——什么概念?就是这个增长速度将远超互联网早期阶段,自 ChatGPT 在 2022 年底发布以来,AI 活跃用户已从 100 万暴涨至 10 亿+。
值得一提的是,这场演讲还请来了“AI 教母”李飞飞。
李飞飞并不是来站台新品的,她和苏妈主要探讨空间智能和世界模型,这也是她已耕深 20 余年的领域。

此外,OpenAI 总裁兼联合创始人 Greg Brockman 也登台助阵,指出行业痛点:“计算能力,仍然是 AI 走向通用智能的最大瓶颈。世界需要的 GPU 数量,远超我们现在拥有的规模。”
而这正是 AMD 接下来要解决的事情,他们希望能补齐 AI 普及所需的算力基础设施。在苏姿丰描述的未来世界里,AI 将无处不在,算力将人人可及——她这次在 CES 上抛出的,不只是几块更强的 GPU,而是一套完整的 AI 版图。
对于云端,基于下一代 MI455 GPU 的 Helios 机架级平台成为全场焦点:单机架集成 72 块 AI GPU,算力高达 2.9 ExaFLOPS,可通过成千上万个机架拼接成超大训练集群,直指千亿参数大模型的核心战场。
谈到云端算力的未来,苏姿丰毫不掩饰 AMD 的野心:
“全球人工智能运行在云端,而云端运行在 AMD 平台上。”
另外,她还指出,下一代 Instinct 数据中心 AI 加速器平台 MI500 系列,将在 2027 年推出并全面转向 2nm 工艺,并放出狠话:希望借此在四年内 AI 芯片性能提升 1000 倍(远超摩尔定律啊...)。
与此同时,AMD 还在推动把 AI 从云端下放到本地,而他们的一个很核心的落点,是 AIPC。
Ryzen AI 通过内置 NPU(神经网络处理单元,一种专门为 AI 推理设计的处理器)让 AI 本地运行、离线可用。

Helios 机架级平台和 AIPC
在数据中心这一 AI 算力的核心战场,AMD 开始卖“一整个机架”的算力方案 Helios,一个几乎重新定义“数据中心硬件形态”的存在。
Helios,是 AMD 面向 YottaFLOPS 级 AI 的下一代机架级平台,也是本场 AMD 发布会的“镇场之作”。
所谓 YottaFLOPS 级 AI,就是算力达到 10²⁴ 次浮点运算/秒 的人工智能系统。直观地说,它不只是“更快的 AI”,而是能在极短时间内模拟、理解和优化极其复杂的世界系统,如全球气候、全人类基因等,能力规模远超今天任何单一 AI 模型。
Helios 从一开始就按大模型需求设计,用开放的 OCP 机架标准做底座,并与 Meta 合作开发,强调模块化、可扩展、能快速堆出大集群。
Helios 的核心是一种全新的算力组织方式,能将 72 颗芯片协同工作。
其中的系统设计是通过高速互联和软件栈,把这些 GPU 组织成一个可以统一调度的算力池,让它们更像一个整体,而不是“72 个独立设备”。在 FP4 这种推理常用的低精度口径下,单台 Helios 机架式服务器可提供高达 2.9 ExaFLOPS 的算力,并搭载 31TB 容量的 HBM4。
如果再把数千个 Helios 机架互联起来,就能搭建出面向万亿参数模型训练和推理的超大规模集群。
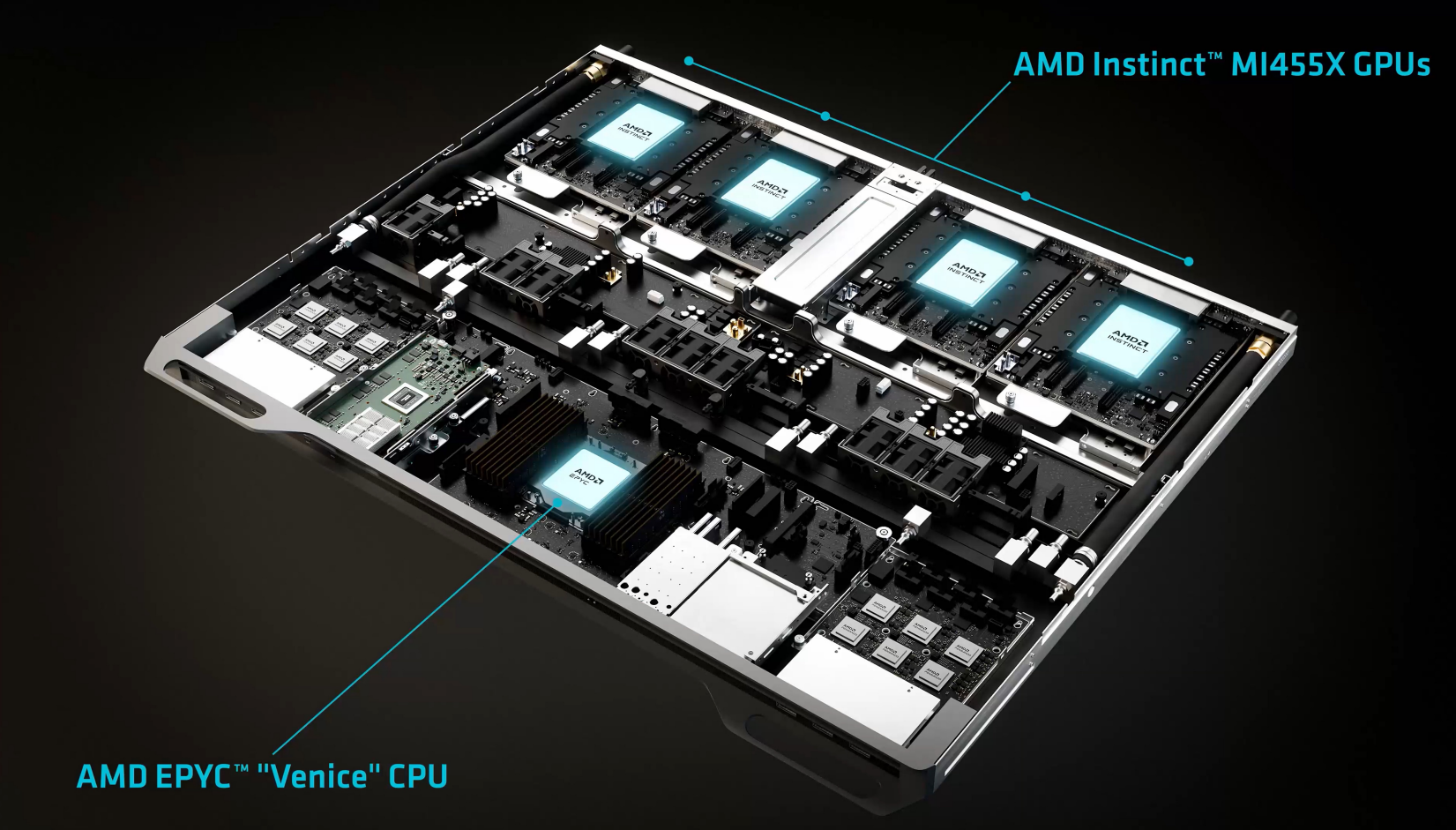
至于 Helios 的算力底座,是 AMD 最新一代 Instinct MI455 GPU,也是 AMD 历史上跨代提升幅度最大的 Instinct GPU。
这颗芯片拥有超过 3000 亿个晶体管,相比 MI300 系列提升约 70%,推理与训练综合性能最高可达 10× 提升。
AMD 对 MI455 GPU 的定位非常明确:它要解决大模型训练和推理里最棘手的瓶颈“内存墙”。大模型跑不动,很多时候不是算力不够,而是数据喂不进去、内存带宽跟不上。
这颗加速器芯片采用 2nm 与 3nm 混合工艺打造,再配上先进的 3D 小芯片封装技术,并搭载新一代 HBM4 高带宽内存。
更重要的是,MI455 并不是孤立地“做一颗更强的 GPU”,它在计算托盘层面就与 EPYC 服务器 CPU、Pensando 网络芯片深度集成,让 CPU、GPU、网络协同成为平台能力,而不再是分散组件的简单拼接。
苏姿丰打了个生动的比方:“Helios 是个庞然大物般的货架,它不是普通的货架,而是双倍宽度的设计,重量接近 7000 磅。”她指出,这个机架的重量超过两辆小型轿车的总重量。

时至今日,AI 的推理能力已被推到聚光灯下,其特点是调用频率高、负载长期持续,进一步带来更明显的算力缺口。
苏姿丰分享称,AMD 下一代 MI500 系列正在开发中,计划全面转向 2nm 工艺,发布时间定在 2027 年。按照 AMD 给出的路线图,从 MI300 到 MI500 的四年周期内,其 AI 计算性能目标提升幅度达到 1000 倍。

她将这一跨代跃迁称为“公司历史上幅度最大的一次性能提升规划”,并将其视为支撑下一阶段超大模型训练和推理需求的关键基础。
在数据中心之外,AMD 还把另一张牌打到终端侧:把原本只能在云端完成的 AI 工作,搬到个人电脑上。
Ryzen AI Max 400 系列(代号 Strix Halo)正是这一策略的核心载体。AMD 给它的定位并不含糊:面向 AI 开发者和高端创作者,做一颗“能真正干活”的本地 AI 芯片。

与 Ryzen AI 300 一样,Ryzen AI Max 400 系列依然是 Zen 5 和 RDNA 3.5,但支持更快内存速度。
简单来说,Ryzen AI 400 是一颗为 AI 笔记本打造的高性能处理器,最高配备 12 核 CPU,同时集成了 更强的核显 和 最高 60 TOPS 的专用 AI 引擎。再加上对高速内存的支持,让它在多任务、创作以及本地 AI 应用中运行得更流畅。
但相比传统性能参数,更关键的是它的系统设计:芯片同时集成 XDNA 2 NPU,并采用统一内存架构,CPU 与 GPU 之间可共享最高 128GB 内存。
这也是能否跑大模型的前提条件。对本地 AI 来说,算力是否够强是一回事,模型能不能完整装进内存、数据能不能顺畅流动,往往才是决定成败的关键。
AMD 用一场直观的演示给出了答案:一台搭载 Ryzen AI 的设备,在完全离线的情况下,流畅运行了一个 700 亿参数的医疗大模型。
这意味着,开发者可以直接在笔记本上调试生成式模型;医疗、金融等行业,也可以在不把数据上传云端的前提下,完成模型推理和分析。本地终端不再只是“调用云端 AI”,而是开始真正承载模型本身。
摆数据:在高端笔记本形态下,Ryzen AI Max 在 AI 与内容创作类应用中的表现,快于最新一代 MacBook Pro;在小型工作站场景中,成本明显低于英伟达的 DGX Spark,而且原生支持 Windows + Linux。
AMD 还贴心地发布了一个本地 AI 参考平台:Ryzen AI Halo 。

官方将其称为“世界上最小的 AI 开发系统”,可在完全离线的条件下运行多达 2000 亿参数模型,面向需要随时随地进行模型开发和部署的专业用户。
那些过去只能在数据中心机房里完成的工作,正在被压缩进一个可以随身携带的设备。
和李飞飞同台聊空间智能
前文提到“AI 教母”李飞飞也亮相了;其实在这种聚焦硬件与平台发布的商业舞台上,李飞飞不常露面,她更常被视为学术界和公共讨论中的“定锚者”。
李飞飞此次在 AMD 的专场讲演登台,强调 AI 不仅要生成内容,更要理解并参与真实世界。

在这一点上,苏姿丰的判断高度一致,她表示,过去几年,大语言模型的出圈(LLM)推动了 AI 的爆发,但无论是人类还是机器,智能并不只来自“看和说”,真正连接“感知 → 推理 → 行动”的关键能力,是空间智能(Spatial Intelligence)。
过去这几年,GPU 的快速发展已让画质起飞了,但 3D 和 4D 世界却还在慢慢搭,往往需要团队花费数月甚至数年完成;而现在 AI 正在改变这种节奏。
李飞飞表示,她认为 AI 正进入一个新阶段:从语言智能,迈向具备空间理解与行动能力的生成式 AI:
“AI 在过去几年取得了巨大突破,我在这个领域工作了二十多年,从未像现在这样,对未来的发展感到如此兴奋。”
她也介绍了自己创业公司 World Labs 的核心动向:
已炼成的关键能力,包括仅凭几张照片,甚至单张图片,模型即可补全被遮挡区域、推断物体背后的结构,然后生成一致、持久、可导航的 3D 世界。
不是照片也不是视频,而是真正保持几何一致性的三维空间,具备“空间补全与想象”能力,而非拼贴。
李飞飞指出,过去需要数月才能完成的 3D 场景建模,现在可以在几分钟内完成。
她举例说明潜在影响:创作者:实时“在世界中创作”;机器人 / 自动驾驶:在物理一致的虚拟世界中训练,再进入现实;设计师 / 建筑师:直接“走进”设计,而不是看平面图。
她还特别强调了一个常被忽略的点:世界模型并不是“离线生成完就结束”,它需要实时响应、即时编辑,连续保持空间一致性。
这意味着:极高的内存需求,大规模并行计算,非常快的推理速度,否则世界就无法“活起来”。
谈及算力,李飞飞也透露称:World Labs 的世界模型已运行在 AMD 的 MI325X GPU 与 ROCm 软件栈之上,并在短短几周内实现了 超过 4 倍的推理性能提升。
她还提到,随着 MI450 等后续平台 推出,更大规模世界模型的训练与实时运行将成为可能。
其他亮眼新品
在消费级图形领域,AMD 本次带来的主要新品是 Radeon RX 9070 和 Radeon RX 9070 XT。
这两张显卡均搭载了 AMD 的全新 RDNA 4架构,以及最新 AI 图像技术(包括 FSR 4),将游戏体验推向“AI 加速 + 实时渲染”双驱动的新时代。
其中 RX 9070 XT 的 64 个计算单元、较高频率设计,让其在多款 3A 游戏中表现强劲,在 4K 最高设置下帧率表现明显领先前代,在 30 多款游戏中平均比 RX 7900 GRE 快 42%

而 RX 9070 的规格稍低一些(但同样 16 GB 显存),其光追与 AI 能力也因较少计算单元略弱,不过仍能在高画质下保持流畅体验,在 30 多款游戏中平均比 RX 7900GRE 的帧率快 21%。

综合来看,这两款显卡延续了 RDNA 4 在 高效能比、AI 支持(如 FSR 4)、光追性能提升 上的特性,适用于 1440p 到 4K 游戏场景。
EPYC Venice 是 AMD 为“AI 数据中心时代”打造的下一代服务器 CPU。
它采用 2nm 工艺,最多可集成 256 个 Zen 6 高性能核心,定位不只是“算得更快”,而是专门为 AI 集群服务。
相比上一代 EPYC,Venice 的内存带宽和 GPU 带宽都实现了翻倍,核心目标只有一个:在机架级规模下,持续、稳定地把数据“喂”给 MI455X 等 AI GPU。
换句话说,它不追求抢 GPU 的计算活,而是负责调度、通信和数据供给,避免 GPU 因“等数据”而空转。
为了支撑这种规模,EPYC Venice 还配套 800G 以太网,并结合 Pensando Volcano / Selena 网络芯片,面向万级机架规模的横向扩展。
在 AMD 的设计中,Venice 不只是服务器 CPU,而是 AI 机架级系统里的“中枢处理器”,决定整个集群能否高效运转。
参考链接:
https://www.youtube.com/watch?v=UbfAhFxDomE&list=TLGGBbam0h3MCckwNjAxMjAyNg&t=3063s
https://www.techtimes.com/articles/313772/20260105/amd-ceo-lisa-su-declares-ai-everyone-ces-2026-guests-openai-luma-ai-liquid-ai-world-labs.htm
https://www.amd.com/content/dam/amd/en/documents/corporate/events/amd-ces-2026-distribution-deck.pdf