在开发者工具 Claude Code 推出之后,Anthropic 团队很快意识到一个出乎预料的现象:开发者并没有把它局限在“写代码”这件事上。相反,Claude Code 被迅速用于整理资料、撰写文档、生成报告、分析数据,甚至承担起类似“数字同事”的角色。
这种使用方式的外溢,最终促使 Anthropic 做出一个更激进的产品判断——如果大模型已经被当作工作伙伴使用,那么是否应该为“所有人”,而不仅仅是开发者,提供一种真正面向日常工作的智能协作形态?
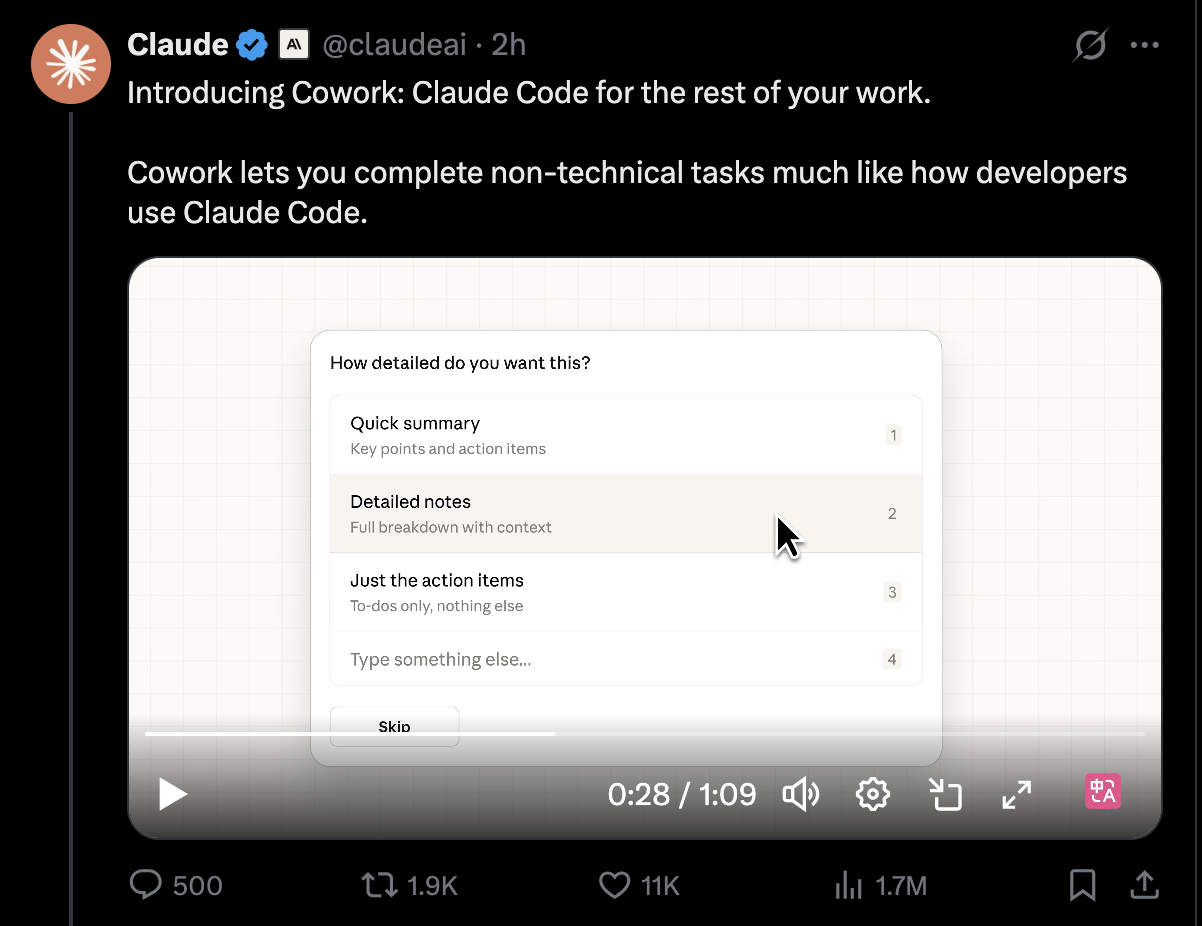
于是今天,Anthropic 正式推出了 Cowork。

Anthropic 工程师、Claude Code 创建者 Boris Cherny 在 X 上发帖宣布了该消息。他写道:
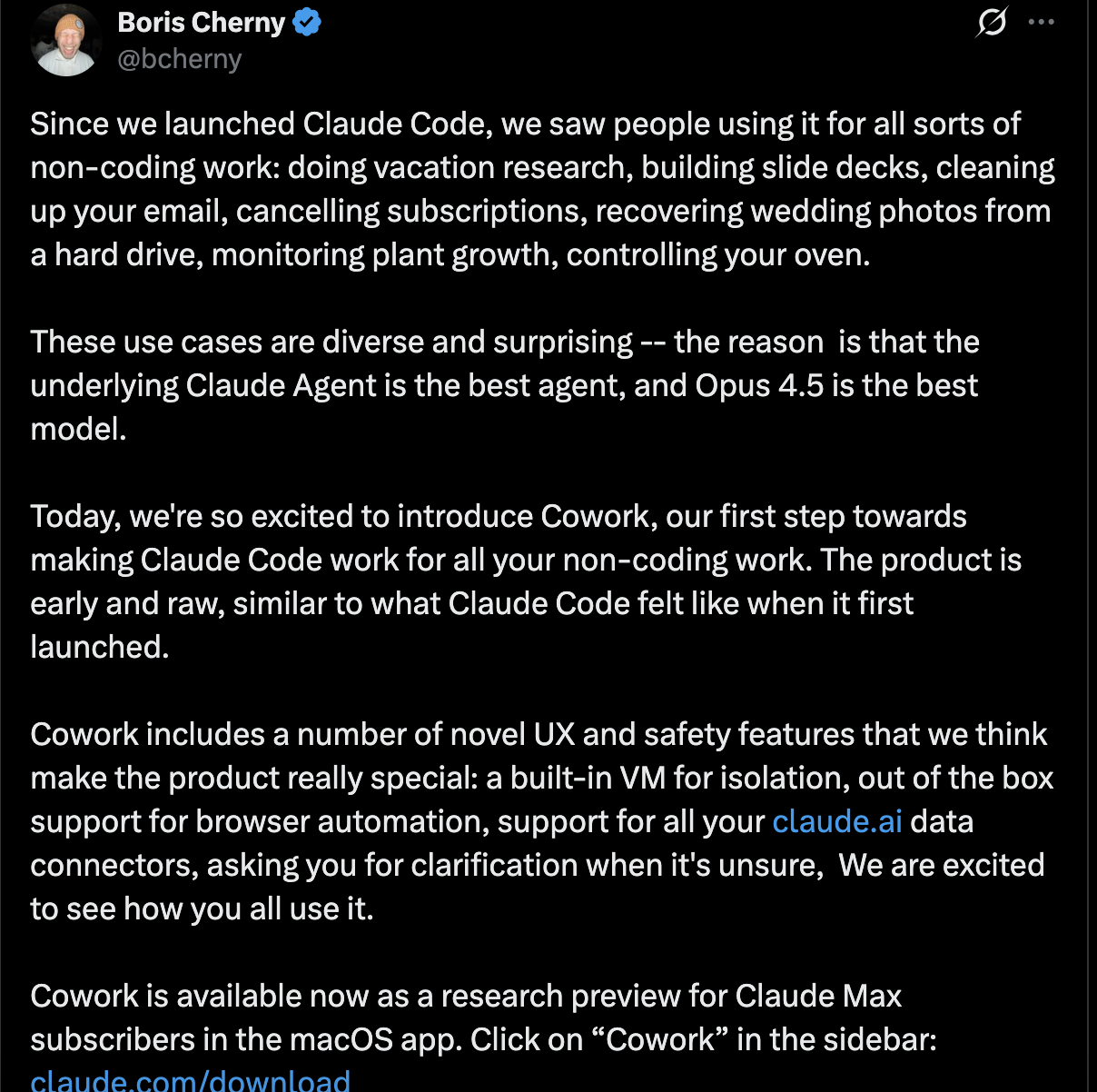
自 Claude Code 发布以来,我们发现用户将其用于各种非编码工作:例如进行度假研究、制作幻灯片、清理电子邮件、取消订阅、从硬盘恢复婚礼照片、监测植物生长、控制烤箱等等。这些应用场景丰富多样,令人惊喜——原因在于底层 Claude Agent 是最佳代理,而 Opus 4.5 是最佳模型。
今天,我们非常激动地推出 Cowork,这是我们让 Claude Code 服务于所有非编码工作的第一步。该产品目前仍处于早期阶段,功能尚不完善,与 Claude Code 最初发布时的状态类似。Cowork 包含许多我们认为使其真正与众不同的创新用户体验和安全功能:内置虚拟机用于隔离、开箱即用的浏览器自动化支持、以及对所有非编码工作的支持。

据介绍,Cowork 是一款基于 Claude Code 底层架构构建的全新产品,目前以“研究预览版”的形式,率先面向 macOS 平台上的 Claude Max 订阅用户开放。与传统对话式 AI 不同,Cowork 的核心定位并非“聊天”,而是“协作”:它试图让 Claude 从一个被动响应指令的助手,转变为能够理解任务、制定计划、持续执行,并与用户保持协同关系的智能工作体。
从“对话助手”到“数字同事”
长期以来,大模型产品的主流交互形态仍然是对话。用户输入问题,模型生成回答;用户提出修改,模型再次响应。这种模式在信息查询、文本生成等场景下行之有效,但在真实工作流中却暴露出明显局限——上下文需要反复提供,文件需要人工整理,输出结果往往还要用户自行转换为可用格式。
Cowork 试图解决的,正是这一断裂问题。
在 Cowork 模式下,用户可以直接授予 Claude 对本地指定文件夹的访问权限。需要强调的是,这种访问并非“全盘授权”,而是由用户明确选择、逐一控制的结果。Claude 只能看到、读取、编辑或创建那些被允许的文件和目录,而无法触及任何未授权内容。
一旦获得权限,Claude 的能力边界就发生了质变。它不再只是基于文本上下文“想象”文件内容,而是可以直接操作真实存在的工作材料。例如,它可以扫描一个杂乱无章的下载文件夹,按照文件类型、时间或用途进行分类和重命名;可以从大量截图中提取关键信息,自动生成一份结构化的费用清单;也可以将零散的会议笔记、草稿和片段,整理成一份逻辑清晰的报告初稿。
这种能力的本质,并不是简单的“更聪明”,而是 Claude 被嵌入进了用户的实际工作环境之中。
Anthropic 在产品说明中多次强调,Cowork 的体验更接近“给同事布置任务”,而不是与机器人来回对话。一旦任务被下达,Claude 会自行拆解步骤、规划执行路径,并在执行过程中持续向用户同步进展。用户无需等待任务完成即可插入新的反馈或补充想法,这些指令会被自动排队、并行处理。
这也是 Cowork 与普通对话模式最根本的差异之一:它默认假设用户的工作是多线程的,而不是线性的。
当然,“更自主”的能力,意味着更高的风险。
让 AI 进入文件系统,甚至具备修改、创建和删除文件的能力,无疑是一种能力跃迁,同时也是风险跃迁。Anthropic 并未回避这一点,反而在产品介绍中反复提醒用户保持警惕。
首先是操作层面的风险。如果收到明确指令,Claude 确实可以执行具有破坏性的操作,例如删除本地文件或批量修改内容。一旦指令本身存在歧义,或者模型误解了用户意图,后果可能是不可逆的。
因此,在 Cowork 中,Claude 在执行任何“重要操作”之前,都会主动征求用户确认。这种设计并非形式上的“弹窗提示”,而是希望用户在关键节点重新审视任务目标,必要时进行纠正或细化指令。Anthropic 也明确建议,在涉及高风险操作时,用户应提供尽可能清晰、具体的指示,而不是依赖模糊的自然语言。
另一类更复杂、也更具行业共性的风险,是“提示注入”(Prompt Injection)。
在 Cowork 的工作过程中,Claude 可能会接触来自互联网的内容,例如网页、文档或第三方信息源。如果这些内容中被恶意嵌入了指令,试图诱导模型偏离原本的任务计划,就可能引发安全问题。Anthropic 表示,他们已经构建了针对提示注入的多层防御机制,但也坦言,“代理安全”——即确保 AI 在现实世界中执行操作时的可控性——仍然是整个行业正在积极探索的前沿问题。
从这个角度看,Cowork 并不是一个“已经完全成熟”的产品,而更像是一次对未来工作方式的现实实验。
Anthropic 也明确指出,这些风险并非 Cowork 独有,而是所有具备“行动能力”的 AI 工具都会面临的问题。只是对许多用户来说,Cowork 可能是第一次接触到一个超越简单对话、真正能够影响本地环境的 AI,因此更需要建立正确的使用习惯和风险意识。
研究预览版背后的产品逻辑
Cowork 目前被定义为“研究预览版”,这一定位本身就释放了明确信号:Anthropic 并不认为自己已经找到了最终形态,而是希望通过真实用户的使用反馈,加速产品迭代。
根据官方披露,Anthropic 计划在后续版本中引入多项重要改进。其中包括跨设备同步能力,使 Cowork 不再局限于单一终端;以及将其移植到 Windows 平台,从而覆盖更广泛的办公人群。同时,安全机制也将持续强化,尤其是在代理行为可解释性和可控性方面。
从产品路径上看,Cowork 与 Claude Code 之间存在清晰的继承关系。两者共享相同的底层架构,这意味着 Cowork 在能力上,理论上可以完成 Claude Code 已经证明可行的许多复杂任务。不同之处在于,Cowork 将这些能力重新封装为更偏向非技术用户的交互方式,降低了使用门槛。
如果说 Claude Code 面向的是“愿意为效率付出学习成本”的开发者群体,那么 Cowork 的目标人群显然更加广泛:内容创作者、产品经理、运营人员、行政人员,乃至任何需要与文件、资料和信息打交道的知识工作者。
在掌握 Cowork 的基本使用方式后,用户还可以进一步扩展 Claude 的能力边界。
首先是连接器。Claude 可以通过用户已有的连接器,访问外部信息源,从而将本地任务与外部数据打通。这使得 Cowork 不再只是一个“本地整理工具”,而是可以承担跨系统的信息整合角色。
其次是新增的一系列技能。这些技能专门用于提升 Claude 在创建文档、演示文稿以及其他常见办公文件时的表现,使其输出更加贴近真实工作场景的格式和标准。
此外,如果用户在 Chrome 浏览器中将 Cowork 与 Claude 配对使用,Claude 还可以完成需要访问浏览器的任务。这一步,实际上进一步模糊了“对话 AI”“自动化工具”和“数字员工”之间的界限。
从整体设计来看,Cowork 试图减少用户在“提供上下文”和“整理结果”上的认知负担。用户无需手动拼接背景信息,也无需将 Claude 的输出再加工成可用成果。更重要的是,用户不必为了等待 AI 完成某个任务而中断自己的工作节奏——任务可以被连续布置、并行执行。
Anthropic 在描述这种体验时,用了一个耐人寻味的比喻:这更像是给同事留言,而不是来回沟通。
用户:没有 Linux 版本,差评!
在 Cowork 发布之后,迅速在开发者社区、AI 产品圈以及更广泛的知识工作者群体中引发讨论。与以往单纯围绕模型能力、跑分或价格的争论不同,这一次的焦点明显转向了一个更现实的问题:“AI 是否真的开始成为一个可以被信任、被授权的工作参与者?”
在 Reddit 上的最新讨论串里,有用户评论指出他们“很期待尝试这个功能”,认为 Anthropic 近来在产品和用户信任构建上做得不错。

**因为仅限 macOS 和订阅计划,部分用户感到遗憾。**在另一个 Reddit 讨论串中,有用户对 Cowork 的平台限制表达了不满或遗憾,评论集中在“只支持 macOS”这一点上。

此外,值得注意的是,有些评论虽然不是专门针对 Cowork,但有一些用户还是对 Anthropic 近期产品策略与沟通的不满,对 Cowork 的发布背景和用户关系具有间接关联语境。
在 Reddit 平台,有长期用户表示,自己已经从忠实支持者变成对 Anthropic 的信任下降甚至不满。该用户指出:
“作为很早一批用户,我原本极力推荐 Claude,但最近几个月感觉 Anthropic 的产品质量沟通都变差了。”
参考链接:
https://claude.com/blog/cowork-research-preview
https://x.com/bcherny/status/2010809450844831752
https://www.reddit.com/r/singularity/comments/1qb6qv1/introducing_cowork_claude_claude/?utm_source=chatgpt.com