艾体宝方案 | API 已经快了,系统为什么还是慢?
在不少后端团队里,都发生过类似的场景: 于是问题开始在群里反复出现: 一个被反复误解的事实 在微服务架构下,Redis 几乎成了“性能优化”的默认答案。只要接口慢,第一反应往往是:“加一层缓存”。 在这条链路里,Redis 只是其中极短的一段。如果你把注意力全部放在“Redis 查得够不够快”,那基本已经跑偏了。 但在引入分段 Trace 后,结果令人意外: 超过 85% 的耗时,发生在: 为什么“加了 Redis”却几乎没加速? 让 Redis 真正“拉开差距”的设计方式 第一原则:缓存要尽可能早 这里 Redis 的角色已经发生变化: 第三原则:预热比你想象得重要 数据不会说谎 值得记住的几条经验 结语:Redis 从来不是问题 测量全链路、设计有缓存意识的架构,让 Redis 只做它最擅长的事。
Redis 上线后,监控显示 API 核心查询耗时下降了 80%,但用户依旧抱怨接口“卡”“慢”“不稳定”。
直到真正拆开一次请求的完整生命周期,才会意识到一个事实:Redis 可能已经做到极致了,只是你把它用在了最不应当的位置。
必须先说清楚一句话:
Redis 并不能让一个设计本身就臃肿的 API 变快,它只会让问题暴露得更明显。
但在真实生产环境中,API 的执行路径通常远比你想象得复杂。客户端
↓
API 网关
↓
鉴权 / 鉴权扩展
↓
参数校验 / 特性开关
↓
缓存查询
↓(未命中)
数据库查询 → 关联查询 → ORM 映射
↓
DTO 转换 / 序列化
↓
日志 / 监控 / Trace
↓
响应返回
Redis 并不是瓶颈,但常常被用来背锅
我们曾协助排查过一个典型系统:
一个对外提供实时报表查询的金融 API,客户团队坚信性能问题出在 Redis。
他们的监控面板显示:
结论很直接:
缓存很快,API 还是慢。
这也是许多团队真正“顿悟”的时刻——
Redis 没有失效,只是你让它介入得太晚了。
归纳下来,问题通常集中在三个方面。
很多系统在设计时,把缓存当作“数据库前的一层挡板”,而不是请求生命周期的一部分。
结果是:
此时即便 Redis 命中,绝大部分 CPU 和延迟成本已经付出。
另一个常见错误,是缓存整个领域对象,甚至直接缓存 ORM 实体。
后果通常是:
在这种情况下,Redis 更像是一个昂贵的、不稳定的旁路系统。
很多团队只关注“平均命中率”,却忽略了两个危险时刻:
在这些时刻,大量并发请求同时穿透缓存,数据库和后端逻辑被瞬间放大执行,抖动也由此产生。
当你接受 Redis 不是万能解药之后,优化路径反而变得清晰了。
如果某个请求的数据已经在缓存中,就不应该再经历完整的业务管道。
理想状态是:
第二原则:缓存的是“可直接返回的结果”
与其缓存领域对象,不如缓存“已经准备好返回给客户端的内容”。String key = "user:profile:resp:" + userId;
String cached = redis.get(key);if (cached != null) {return cached;}// 未命中,走完整流程
User user = userRepository.findById(userId);
String responseJson = responseMapper.toJson(user);// 合理 TTL,例如 5 分钟
redis.setex(key, 300, responseJson);return responseJson;
它不再是“数据缓存”,而是响应加速。
在优化后,我们为以下场景引入了缓存预热:
这一步往往可以显著降低首批请求的抖动风险。
在重构缓存策略后,性能变化非常直观:
从约 410 ms 降至 70–90 ms
下降超过 65%
稳定在 90% 以上
更重要的是:延迟开始变得可预测,而不是偶发性飙升。
Redis 很少是系统变慢的原因,但它经常成为暴露问题的那面镜子。
如果你的 API 在“加了 Redis 之后”依然迟缓,不妨换个角度思考:
也许不是 Redis 没有加速系统,
而是系统本就不该让 Redis 来兜底。
这,才是真正的性能提升来源。
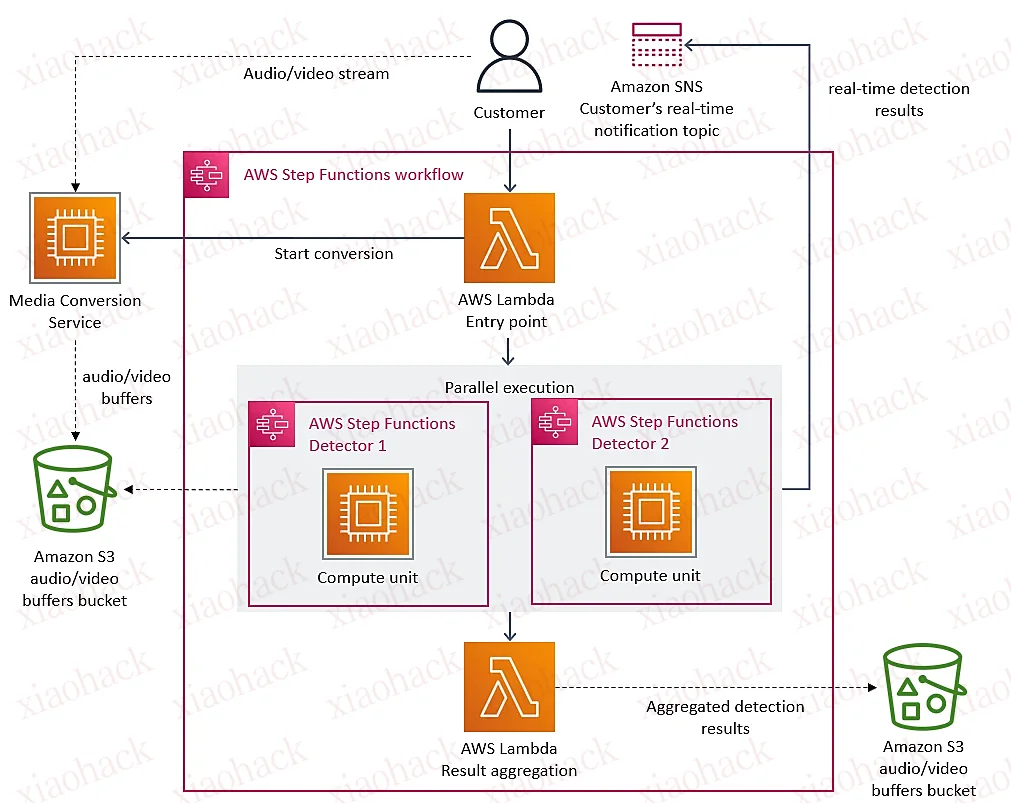
 这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《
这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《