For everyone, by everyone 的 AI 硬件
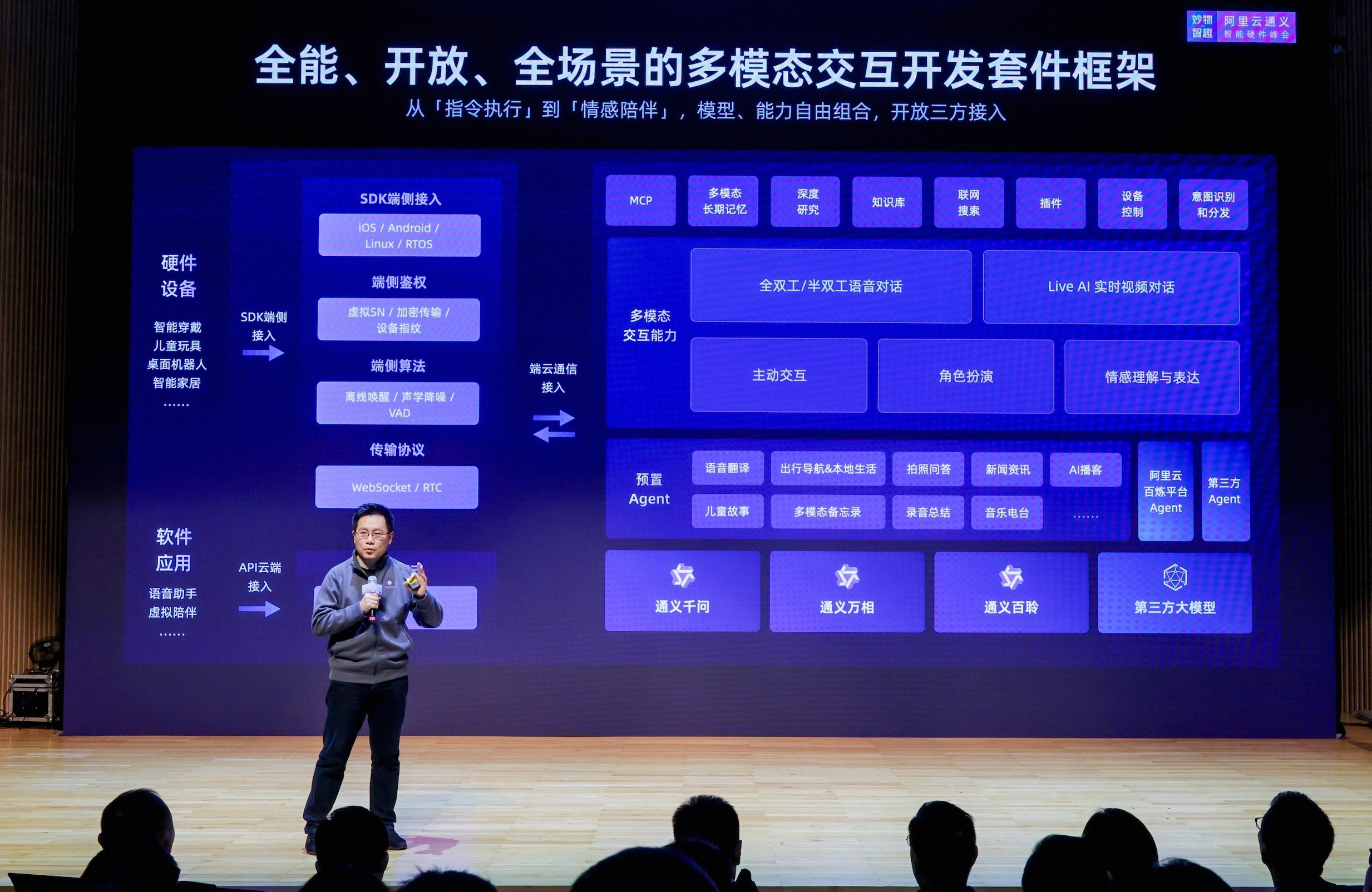
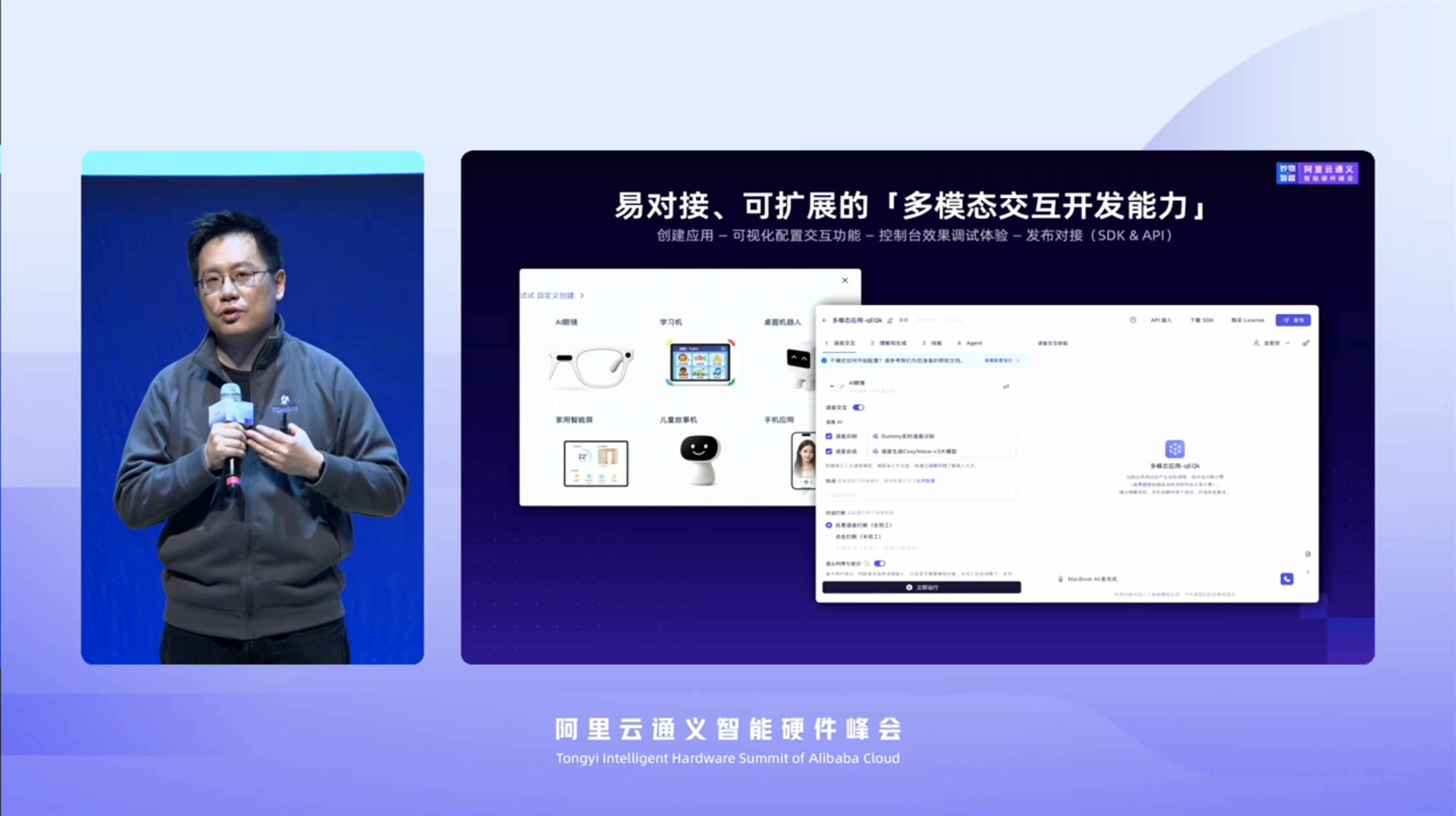
今年的 CES,中国硬件又一次成为主角。活跃在拉斯维加斯展台上的诸多出海产品,背后依托的是深圳的研发效率与供应链能力,而其智能化核心,则越来越多建立在以 Qwen 为代表的多模态、全尺寸的大模型基础上。 与沙漠赌城的 CES 同期,在深圳蛇口,阿里云也举办了一场智能硬件展。这场展会面向公众免费开放,选址于本地居民日常散步、观海和看展的滨海文化地标,却意外成为 AI 硬件从实验室走向真实市场的缩影。1000 余款智能硬件在这里集中亮相,其中超过 200 款与 CES 同款甚至首发。这里既有来自北京、杭州的创新团队,也有来自义乌、华强北等产业带的制造与渠道力量——他们对技术趋势的嗅觉,向来快过任何市场报告。 技术验证与市场反馈在同一空间同时发生。在这里你可以听到合作方直接询价“多少钱,做 OEM 吗,能做多少套”,也可以看到消费者直接下单,把 399 元的 AI 玩具带回家。许多普通家庭第一次在这里集中体验到能对话的毛绒玩具、教用户跳舞的镜子、能翻跟头的机器狗,和具备实时提醒能力的 AI 眼镜。 早在 2024 年云栖大会上,阿里云董事长吴泳铭就明确指出,未来 AI 最大的想象力会来自于物理世界:“我们不能只停留在移动互联网时代去看未来,深层次 AI 最大的想象力绝对不是在手机屏幕上做一两个超级 APP,而是接管数字世界,改变物理世界。” 但在这轮 AI 硬件浪潮中,阿里云没有选择去做终端硬件的制造者,而是以软硬一体的融合理念,向产业提供底层模型能力、云基础设施与生态支持。 数据显示,通义大模型的多模态能力已深度赋能超过 15 万家智能硬件厂商。 从雷鸟的 AI 眼镜、听力熊的儿童 AI Pin,到优必选机器人、趣丸科技的生成式 AI 吉他,这些走进全球家庭的产品背后,都能看到以通义为代表的阿里云基础设施的支撑。而它们从概念到量产、从深圳到世界的惊人速度,也再次印证了深圳这座“硬件硅谷”在研发、供应链与商业化效率上的独特优势。 逛完阿里云通义智能硬件展,一个强烈的感受是,这是我经历过为数不多,能让普通人玩得开心、让创业者看到机会、让厂商验证商业模式,同时清晰传递主办方战略意图的展会。 阿里云租下深圳海上世界文化艺术中心三层空间,用一种近乎“生活化”的方式,向公众展示:AI 能长在玩具里、眼镜上、健身镜中,甚至成为家庭一员的日常存在。向企业展示:你能快速依托阿里云的生态,快速做出能进入全球家庭的产品。 展会围绕两条主线展开:一是呈现阿里云的底层能力,二是展示其赋能下的千款智能硬件成果。 一楼以“智能中枢”为核心,展示通义大模型的能力:观众上传一张照片,就能生成一段短视频;走过一段互动迷宫,便能直观感受多模态 AI 如何理解图像、语音和动作。 智能中枢周围环绕着“创造有 AI”“生活有 AI”“AI 实训营”等主题区,OPPO、理想、影石等品牌在此展示手机、智能座舱和 AI 影像设备,而像趣丸科技的 AI 吉他、Looki 这样的新奇产品,则让人看到 AI 如何重塑音乐、娱乐等日常互动。 趣丸科技与阿里云合作推出的全球首款生成式 AI 吉他 TemPolor Melo-D,在通义大模型的支持下,重新定义了人与音乐的交互方式,提供了个性化的 AI 音乐创作体验。 三楼聚焦陪伴、健康与安防,专设义乌厂商展区;四楼覆盖家居、教育、健身等提效场景,华强北的硬件老板们也把“一米柜台”搬到了现场。 通义联合听力熊为青少年定制随身 AI 对话智能体,打造国内首款儿童 “AI Pin” Mooni M1,提供多种角色选择。经过通义千问大模型加持,用户的 AI 使用时长提升 40 分钟。 阿里云想让大家知道,AI 有能力在所有场景里带来更好的体验。它同时也呈现出一种可能——不管是软件应用还是硬件产品,每个人都可以在这个时代搭建些什么。 阿里云 AI 实训营的 Agent 硬件搭建小课堂 对于普通人来说,硬件展是一个游戏体验。孩子和 AI 毛绒玩具对话,年轻人跟着镜子学舞,有人让 AI 解读运势、推荐香水,还有中学生在阿里云 AI 实训营中搭建了自己的第一个交互硬件。我们这代人仍然处于有“AI 硬件”概念的时期,而对于下一代人来说,可能已经不存在“AI 硬件”。当生活总所有一切都有 AI,AI 之于人,阿里云之于硬件和应用产品,就是水之于人的存在。 对创业者和企业主而言,展会成了高效的信息源。有用户的直接提问和反馈,也有工程师在展位前递上简历。采购顾问带着非洲、拉美的客户穿梭其间,现场询价、谈订单。 TCL、影石、安克创新的案例,更是为想要入局 AI 硬件和出海的企业打气——依托阿里云全球全栈 AI 基础设施,大型制造企业可实现研发、服务、出海一体化,新锐品牌也能快速站稳全球舞台。 刚在 CES 获得 Best of Innovation 奖项的影石,依托 Qwen-VL 实现视频与图片的分类打标和场景识别,结合 Qwen-Plus 生成剪辑脚本,赋能全球百万视频创作者。 安克创新依托阿里云“全球一张网”,实现跨境资源调度与合规部署,核心系统互访提速 30%,并将 Qwen 与 Wan 深度融入语音助手、多模态交互等产品功能。 TCL 则基于通义大模型打造了半导体显示专家系统 X-Intelligence,支撑其全球研发体系。 同时,阿里云把义乌、华强市场这些产品背后的“制造和分发网络”呈现在大家面前。在他们的摊位上,你可以看到很多产品尽管“粗糙”,却仍然有市场。在很多欠发达国家,AI 硬件需要的不是精致,而是先以成本最低的方法被用上。很多义乌玩具、小 3C 产品的批发商,嗅到 AI 风潮后,已经在深圳有了自己的硬件工厂。华强科技生态园等孵化器,也开始重点招募 AI 硬件的创业公司。 正如阿里云智能集团通义大模型业务总经理徐栋所说:“这样一个平台(以通义多模态交互开发套件为代表的 AI 硬件赋能平台)是我们非常重要的业务的选择,我们需要更多贴近阿里云的智能硬件开发伙伴。很多场景是碎片化的,只有做更贴近实际的生产环节、消费环节,每个人对 AI 硬件的体验才能更深。” AI 硬件,正在成为 for everyone, by everyone 的日常现实。而阿里云的角色,不是站在台前造产品,而是站在幕后,让创新更快实现。 AI 硬件从极客圈层走向大众日常,标志着市场已从“启蒙期”进入“挑剔期”。当用户开始为 AI 服务付费、并将设备融入日常生活,产品的成败就不再取决于功能数量,而在于能否持续兑现可感知的价值——这要求厂商必须拥有一套覆盖模型、工程、服务与生态的系统性能力。 AI 硬件,特别是在消费级市场,正经历着一场根本性的转型。从传统的联网设备到如今的“端侧智能体”,AI 不再只是硬件的附加功能,而是直接决定产品核心价值的引擎。这一转变的核心标志在于:AI 不再作为附加功能嵌入硬件,而是成为产品定义、体验构建与价值交付的底层引擎。 早期智能硬件以“连接+控制”为基本范式,其智能化主要体现在远程操作与数据回传;而新一代 AI 硬件则要求设备具备持续感知、上下文理解、自主决策与协同执行的能力,成为一个能在真实场景中与用户形成闭环互动的“智能体”。 这一转变正在重塑硬件的设计逻辑、用户的价值预期与厂商的技术路径。 用对 AI 硬件的认知早已超越“新奇感”,转而关注端到端体验是否流畅、可靠、有用。更重要的是,用户开始愿意为持续服务付费。例如按月订阅儿童 AI 陪伴内容,或为高级健身指导功能续费。这催生了“硬件+服务”的新商业模式,但也带来新挑战,如果 AI 不能提供可感知的显性价值,订阅就难以为继。 技术架构也随之重构。端云协同的逻辑发生了变化。之前的端云协同更多指向算力分工,即端上承载不了的算力放在云上,但现在的端云协同是指能力互补。安全、延时、功耗的问题必须在端上解决,而生态打通这些能力可能在云上做。同时,交互方式正走向“无感化”——不是让用户察觉不到 AI 存在,而是让使用门槛足够低,无需学习就能自然融入原有生活节奏。 然而,对大多数硬件厂商而言,这场转型并不轻松。模型迭代速度远超硬件研发周期,而一个产品往往需要组合多个模型才能实现完整功能,集成复杂度陡增。与此同时,Agent 架构、工具链和工程平台快速演进,传统硬件团队难以跟上软件层的节奏。更棘手的是,许多厂商擅长制造和渠道,却缺乏用户运营、数据闭环和订阅服务能力,难以构建可持续的商业模型。 面对这些系统性挑战,阿里云提供了 AI 硬件的全链路支持体系。 在基础设施层面,阿里云面向 AI 应用场景全面升级计算、存储与网络能力,为高并发、低延迟的智能硬件业务提供稳定底座。 在模型层面,通义大模型家族(包括 Qwen3、Qwen-VL、QwQ 等)全面开源,并提供闭源高阶版本,同时接入第三方优质模型,帮助厂商一站式、低成本调用全球先进 AI 能力。针对多模态交互场景,阿里云还推出专有优化模型,降低端到端语音和视频交互时延。 阿里云的模型能力,已经获得顶尖手机、汽车、具身智能、智能配件品牌的认可和验证: 目前,全球 Top 10 手机厂商已都在使用阿里云的大模型能力。例如,OPPO 利用阿里云人工智能平台 PAI 对 Qwen 开源模型进行后训练,以支持其 AI 多场景应用;荣耀则联合阿里云百炼打造 VQA 端到端方案,图片细分场景识别率提升近 40%,延迟降低 30%。荣耀 Magic V5 接入飞猪旅行、高德地图两个垂直 Agent 两个月即斩获百万级用户好评。基于“模型+工程+生态”三位一体的战略,阿里云正持续加速手机行业的 AI 功能创新与规模化落地。 理想汽车基于阿里云 MindGPT 大模型,整合高德、飞猪、支付宝等生态,实现全球首个“车机 AI 扫码支付”; 雷鸟创新联合阿里云推出行业首个面向智能眼镜的 AI 大模型,意图识别准确率达 98%,搭载该模型的雷鸟眼镜出货量领跑 AR 行业。 优必选的萌 UU 陪伴机器人,搭载通义千问与自研情感智能体“点灵”,且具有长期记忆 特别值得注意的是,阿里云此次还推出了全模态智能交互开发套件,将上述能力封装为标准化工具。该套件适配 30 多款主流 ARM、RISC-V 和 MIPS 架构芯片,覆盖市面上绝大多数终端设备。未来,通义大模型还将与玄铁 RISC-V 实现软硬全链路协同优化,进一步提升在国产芯片上的部署效率与推理性能。 这套开发套件不仅提供基础能力,还预置十余款 MCP 工具和 Agent,覆盖生活、工作、娱乐、教育等高频场景。例如,基于出行规划 Agent,用户可直接调用路线规划、旅行攻略、本地探索等功能。同时,套件深度集成阿里云百炼平台生态,支持开发者添加社区模板,或通过 A2A 协议兼容第三方 Agent,极大扩展了应用边界。 无论是 OPPO、理想这样的品牌厂商,还是华强北的创客、义乌的出海团队,甚至“一人公司”,都能借助阿里云的解决方案快速验证想法、打造产品,并参与全球竞争。 正是阿里云“基础设施先行”的思路,让展会上那些看似天马行空的产品,得以从概念走向量产。 有趣的是,阿里云大模型能力的升级节奏,与 AI 硬件的集中爆发高度同步。 2023 年 8 月,阿里云开源 Qwen-VL 视觉语言模型,首次让中小厂商能免费调用工业级多模态能力;2024 年,Qwen-Audio、Qwen2-VL 等模型集中发布,补齐了语音、图像与文本融合交互的关键拼图;到 2025 年初,原生端到端的 Qwen3-Omni 模型的发布,以及 Qwen-Agent,进一步支持硬件端构建任务型智能体。这一连串技术释放,恰好为 AI 硬件创新提供了可落地的底层支撑。 从 2024 年下半年起,阅读器、眼镜、耳机、学习机等细分品类迎来 AI 功能的规模化落地:文石、闪极、AIxFU、听力熊、云希谷等能纷纷接入阿里云大模型能力。 这些产品的共同点,是都受益于通义的“全谱系开源”策略——0.5B 到 480B 的模型全覆盖,文本、语音、视觉、视频能力一应俱全。无论是大型企业,还是华强北的硬件作坊,都能找到适合自己的解决方案。 正是这种低成本接入到快速验证的正向循环,让 AI 硬件从概念走向规模化落地。阿里云没有造 AI 硬件产品,却通过持续开源和能力迭代,成为这场硬件浪潮背后最坚实的推手。
For everyone, by everyone 的 AI 硬件






阿里云,在 AI 硬件变革前夜