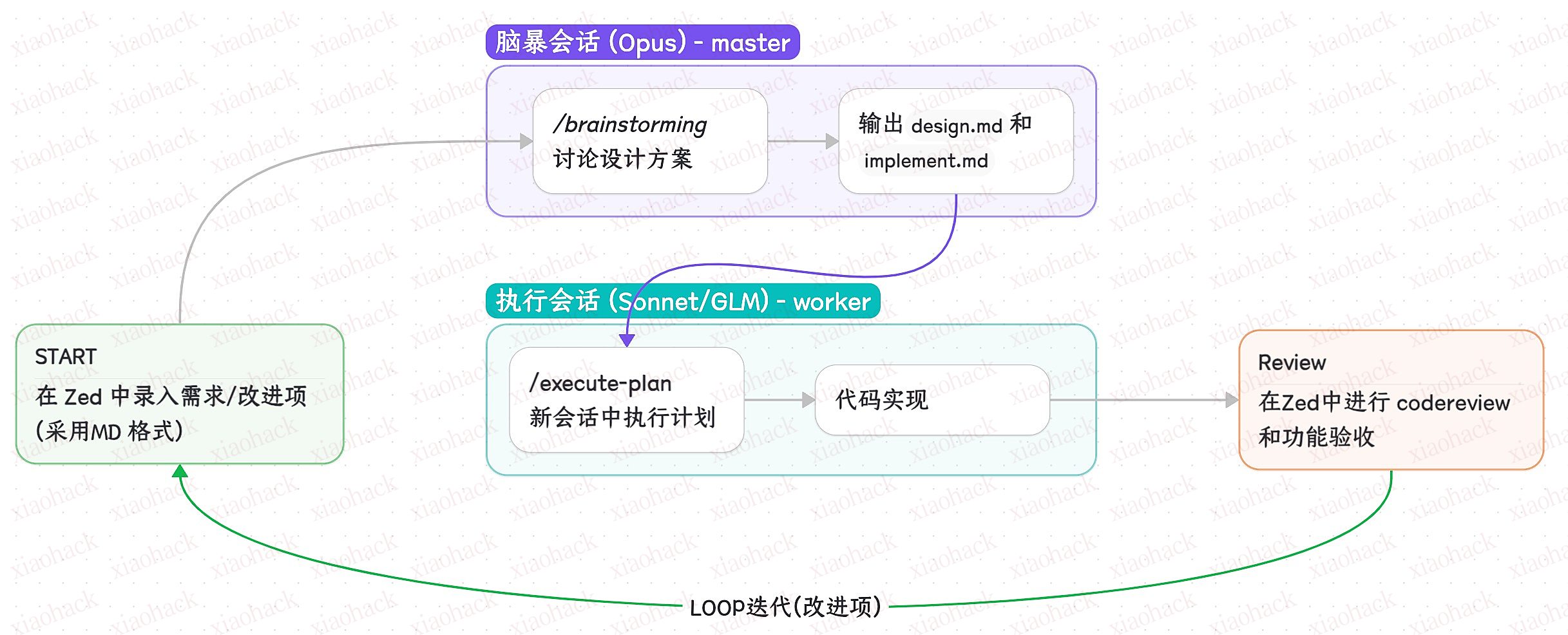
啥叫 UI 的 AI 味?
让我们先给 AI 一个 “正常产品经理 / 设计需求文档级别” 的需求描述,不做人为干预(让他自由发挥一个)
需求提示词(GPT 生成):
然后我们分别交给 gemini-3-pro-preview,claude-opus4.5,gpt-5.2-codex-high
以下是养蛊的过程:
上图!
各个模型完全不加任何 UI 样式要求版本:
Claude-opus-4-5、
gemini-3-pro-preview
gpt-5.2-codex-high
在不加任何限制词的情况下,AI 生成 UI 时暴露出的典型「AI 味」
1. 渐变色本身不是问题,但几乎一定会被用错场景
蓝紫渐变色(tailwindcss 默认设置)还有各种各样的渐变色乱用
这是一种很安全的蓝 / 蓝紫配色上,看起来不难看(但显然有点审美疲劳了已经)
AI 非常喜欢用渐变色来 “兜底视觉效果”,渐变色本来咋用都没啥问题的,可是老是把鲜艳的渐变色直接填充式用在大面积容器、主背景或卡片主体上,你这…。结果就是界面第一眼好看,但信息边界模糊,主次不清。看久了还有点烦躁。
2. 渐变再进一步叠加光泽和玻璃拟态,UI 经常搞这种莫名其妙的 “假高级”
你想:
渐变色 + 高透明度 + 模糊背景 + 发光边缘
界面会迅速变成展示页或概念稿风格。
这玩意,emmm 怎么说呢
虽然我不是啥守旧派,但是架不住啥页面都这个德行
3. 阴影被当作装饰,而不是层级工具
AI 生成的 UI 里,阴影我甚至觉得是在乱用,但又没靠这玩意儿区分明确的层级职责。不同卡片、弹层、操作区使用相同强度和样式的阴影,导致 “所有东西都在浮起”,这效果叫啥来着?
算了,反正就是实际上看着很别扭
4. 卡片边界过弱,依赖背景和阴影勉强区分内容
上面说到了阴影,然后也跟这个情况有关,边界太弱了,AI 搞的界面里面,卡片要么使用极浅的边框要么完全没有边框,只靠背景色差或阴影与页面区分。我偶尔搞个白色或浅灰背景下跟我带着眼镜在大冷天吃拉面一样
我是真看不清,内容混在一起,都不用说阅读疲劳的问题了
你这玩意儿已经伤害我的眼睛了
5. 纯白卡片被大量使用,页面整体显得 “轻而薄” 还散装
上面说了卡片,不只是单个卡片有问题,AI 生成的基本上都是一堆的散装卡片。
尤其是使用纯白背景的卡片。
只要你生成的时候需要一个 “干净、现代” 的样式,这绝对是一写一堆,拉的到处都是
纯白卡片一旦数量增多,就会显得缺乏质感和层次,页面整体像一张尚未完成填充的线框稿。
而且页面利用效率有问题,就是有些页面第一眼很 “干净”,但第二眼发现内容其实很少
卡片很大、留白很多、排版很松,看着舒服,但是你仔细看会发现屏幕被浪费得非常严重,更像展示页而不是能用的工具,这点我觉得 Claude 和 GPT 写的还是行的,东西至少不少。
6. 装饰性细节被平均分配,导致没有视觉节奏(这个观点是 GPT 帮我总结的,我实在不知道咋描述)
小渐变块、色条、图标背景、装饰点缀被均匀地撒在页面各处,每个模块都想 “精致一点”,但没有任何地方真正承担视觉焦点。最终页面没有节奏,只有装饰堆积。
人话:“这些莫名其妙的小组件,丢这些地方干什么??用么没什么用,放着嘛多余,删了嘛又觉得缺点东西”
7. Emoji 或偏卡通风格图标被当作功能图标使用(这个是我最不能忍的)
AI 生成的 UI 只要你不要求,emoji 或拟物感较强的图标会被直接用于功能入口。
讲真的,这玩意儿我也就是发个帖子发个消息会加
甚至我都不会用那些很有年代感的 emoji
8. 正常用图标,图标风格也会混杂,缺乏统一的视觉语言
即便不用 emoji,AI 也经常在同一界面中混用线性、填充、双色甚至插画风格的图标。
单个看都你不会觉得有啥问题的,放在一起就不行了。
9. 为了显得 “高级”,过度叠加多种视觉效果
渐变、阴影、圆角、描边、模糊、透明度同时出现。
第一眼惊艳,第二眼疲劳,第三眼开始觉得乱。
10. 整体视觉看起来完整,但缺乏真实使用感
这些 UI 看起来像是 “已经设计完成的后台”,但更像展示用的样例界面。
看着是 “做完了”,但真点两下就会觉得是 “没开始”。
人话总结:
AI 生成 UI 的最大问题不是用了什么效果,而是它不知道什么时候该不用这些效果。反正你也没说不能用,那直接用了好了
那我是从什么时候开始写「限制词」的?
其实一开始我也没想过要 “限制” AI,我个人是真没啥艺术细胞
毕竟 AI 画出来的 UI 第一眼都挺好看,说实话比不少人自己糊的还顺眼。
问题出在第二眼、第三眼、以及真正开始用的时候。
渐变色越来越多、阴影越来越重、光泽和玻璃拟态开始乱飞,直接开始污染我幼小的心灵,
然后接着图标开始不讲武德地混风格,
emoji 开始混进功能入口里。
这些东西单独看都不算错
(蛐蛐一下:md, 其实单看我都觉得错)
当这个 UI 瞅着开始不再像一个 “被长期使用的工具”,更像一个… 像一个小红书水文
更 TMD 要命的是:这些问题反而是 “稳定复现” 的
其实用久了就会发现一个鬼故事:
只要不加约束,这些 AI 味几乎必定会出现。
这就说明问题不在某一个模型,
而在于 ——
这是当前模型默认理解里的 “好 UI”。
他把他知道的最好的东西都给你了,你还能怎么样?
所以我开始反着来:不再告诉它我要什么,而是直接告诉它 “不能干什么”
从那之后,我写 UI 相关 Prompt 的方式彻底变了:
- 都不用一上来写设计原则
- 也不用写 “高级”“现代”“好看”
- 而是先把这些 稳定复现的 AI 味,一条一条禁掉
比如:
- 你老爱用渐变?那我就先说别用
- 你老爱上光泽和玻璃?先禁
- 你老爱用 emoji 当图标?直接点名不许
- 你老爱堆卡片?那我就先卡你
不是我对这些效果有意见,而是它们在工具 UI 里出现得太频繁了。
好吧我就是有意见
那问题来了:如果我把这些已知的 AI 味禁掉,UI 会变成什么样?
接下来我做了一个对照实验。
不换需求、不换页面、不换模型,
只在 Prompt 里明确禁止前面提到的那些 “稳定复现的 AI 味”。
不追求完美,也不追求设计感,
UI 会不会比之前的更像一个印象里面的 UI?
对照实验:只靠「禁止」,UI 能变成什么样?
二次养蛊开始:
追加的 prompt 很简单:
下面的修改是在【你刚刚生成的 UI 页面基础上进行】,
请保持页面结构、信息架构和功能不变,
只对视觉样式和表现方式进行调整。
请注意:
- 不要重新设计页面结构 - 不要新增或删除功能模块 - 不要改变布局层级或信息顺序 - 不要重新组织页面内容
在本次修改中,请明确禁止以下视觉表现:
- 禁止使用蓝紫渐变色及类似风格的渐变 - 禁止使用玻璃拟态、光泽、高透明模糊背景 - 禁止将 emoji 作为功能图标或装饰元素 - 禁止大面积纯白卡片堆叠 - 禁止无实际信息意义的装饰性组件
你可以:
- 使用纯色或低饱和背景色 - 使用统一风格的 SVG 图标 - 使用适度阴影建立层级关系 - 使用少量强调色突出关键操作
目标不是追求视觉冲击,
而是让界面更接近一个会被长期使用的工具型 UI。
① 明确这是「基于现有页面的修改」
② 明确「不允许的行为」(禁止重构,先不让彻底重构)
③ 列出「禁止项」(就是刚才咱们总结的 AI 味)
④ 给 “最低限度的自由空间”(防止他钻牛角尖),也就是防止 AI 因为被禁太多而做出 “难看 UI”
上图!
各个模型加上 UI 禁止项的生成版本:
Claude-opus-4-5
gemini-3-pro-preview
gpt-5.2-codex-high
这次养蛊大家都有变化,不过 GPT 这次是完胜的,这 UI 比剩下的两个更好
原因是因为第一次版本 gpt 的就比另外俩打版打的好
接下来我允许:
重新设计页面结构
新增或删除功能模块
改变布局层级或信息顺序
重新组织页面内容
也就是:
进入「三次养蛊:在去 AI 味前提下,让模型开始真正设计」
使用前提:
已经做过「禁止 AI 味」的一轮
现在要:在这些禁止条件仍然生效的前提下,允许 AI 放开重构
这次的 prompt 是:
现在开始第三次生成。
在上一轮中,你已经基于原页面,
在明确禁止部分视觉表现的前提下完成了一版 UI。
在本轮中,你【可以】:
- 重新设计页面结构 - 新增或删除功能模块 - 调整布局层级和信息顺序 - 重新组织页面内容
但请注意:
这仍然是一个【企业级工具型 UI】,
用于长期、高频使用,
不是营销页面、不是展示页、不是概念稿。
在重新设计过程中,以下视觉规则仍然【严格生效】:
- 禁止使用蓝紫渐变色及类似风格的渐变 - 禁止使用玻璃拟态、光泽、高透明模糊背景 - 禁止将 emoji 作为功能图标或装饰元素 - 禁止大面积纯白卡片堆叠 - 禁止无实际信息意义的装饰性组件
你可以:
- 使用纯色或低饱和背景 - 使用统一风格的 SVG 图标 - 使用适度阴影建立清晰的层级关系 - 使用有限且克制的强调色突出关键操作
目标不是追求视觉冲击或设计感,
而是设计一个
「在失去所有廉价高级感之后,仍然成立的工具型 UI」。
请直接输出完整页面方案。
梅开三度,养蛊继续
上图!
各个模型加上 UI 禁止项但放开手脚的生成版本:
Claude-opus-4-5
gemini-3-pro-preview
gpt-5.2-codex-high
对比结果就是各自都有升级,gpt 的把界面删的就剩下这一个了,Claude 是直接重写了属于,Gemini 重写的样式是真不错
前三轮我一直在做一件事:把 AI 的 “默认审美” 压下去。
但光不难看是不够的,真正的产品 UI 还需要 “厚度” 和 “秩序感”。
第四次养蛊,我不再单纯限制,
而是把一些我在真实项目里反复验证过的 “增强 UI 质感的手段” 明确告诉 AI,看它能不能顺着这套逻辑往上走。
为什么还会有第四次养蛊呢?因为我想给 Claude opus 一个机会
虽然刚才 Opus 的生成结果都差点意思,实际上我用他已经做了比较不错的 UI 了,一种没正确发挥水平的感觉,gpt 和 gemini 也一样,总觉得没发挥真实水平
比如下面这个是我昨天刚用 Opus 做的应用的截图:
第四次养蛊开始:
开始加一点 “人类设计师才会在意的细节引导”,
并且要求 AI 把整个系统的页面一次性补齐,
看他能不能真正把一个产品原型做完整。
示例 Prompt(原则嘛就是基于刚才那些原则从零彻底开始):
现在开始一次全新的 UI 生成。
请注意:本次不是在已有结果上修改,
而是【从零开始设计并实现一个完整的前端 HTML 项目】。
---
## 项目目标
设计并实现一个【企业级工具系统 / 会员中心 / 管理后台】,
面向长期、高频使用的真实用户。
这不是营销页面、不是概念稿、不是组件示例,
而是一个“看起来就可以继续开发和交付”的前端项目。
---
## 交付物要求(非常重要)
你需要输出的是一个【前端项目级结果】,包括:
1. 清晰的项目目录结构说明
2. 多个页面级 HTML 文件(不是单页)
3. 拆分的 CSS 文件(统一设计语言)
4. 拆分的 JS 文件(只处理基础交互)
示例结构(仅作说明,可自行调整):
- index.html(工作台 / 概览)
- products.html(功能或套餐页)
- detail.html(详情页)
- settings.html(设置页)
- assets/css/style.css
- assets/js/app.js
---
## 样式与视觉规则(限制项)
在本次生成中,请**明确禁止**以下表现:
- 禁止使用蓝紫渐变色或默认 Tailwind 风格渐变
- 禁止玻璃拟态、光泽、高透明模糊背景
- 禁止使用 emoji 作为功能图标或装饰元素
- 禁止大面积纯白卡片堆叠
- 禁止无信息意义的装饰性组件
- 禁止为了“显得高级”而叠加多种视觉效果
---
## 视觉风格引导(允许且推荐)
在遵守以上限制的前提下,**推荐使用以下设计方向**:
1. 浅色但非纯白的背景体系(如浅灰、灰白)
2. 明确的“盒子感”设计:
- 使用边框、背景、间距建立层级
- 阴影只作为辅助,不作为主要分层手段
3. 允许使用“有岗位的花活”,例如:
- 图标容器样式
- featured / 推荐模块
- 状态背景、进度条、徽章
但这些花活只能出现在关键模块上,不能平均分布
4. 允许使用低饱和、低对比的层次变化或微渐变,
仅用于模块内部或状态表达
5. 图标统一使用线性 SVG 风格,风格保持一致
6. 页面信息密度以“效率优先”,
合理利用横向空间,避免单列堆叠
---
## 页面与内容要求
- 每个页面都应是“可用页面”,不是占位结构
- 页面之间需要体现功能差异,但保持统一视觉语言
- 页面结构、模块组织、信息顺序可自由设计
- 允许自行决定需要哪些页面和模块,只要合理
---
## 最终目标
生成一套:
- 从零设计
- 项目级结构清晰
- 视觉上不存在明显 AI 味
- 同时具备设计感和工具属性
的【企业级工具系统前端 HTML 项目】。
请按“项目级输出”的方式给出结果。
上图!
各个模型第四次养蛊生成版本:
Claude-opus-4-5
gemini-3-pro-preview
gpt-5.2-codex-high
各自有各自的风格,而且我觉得这回真的是哪个模型就生成哪个模型的风格
结论:还是没找全最合适的降低 AI 味道的限制条件
📌 转载信息
原作者:
mistpeak
转载时间:
2026/1/16 16:55:24