利用Ollama对Deepseek 模型进行攻击
0x01 组件简介
近期由于Deepseek爆火,大部分企业和个人都开始部署AI。Ollama是一个本地私有化部署大语言模型(LLM,如DeepSeek等)的运行环境和平台,简化了大语言模型在本地的部署、运行和管理过程,具有简化部署、轻量级可扩展、API支持、跨平台等特点,在AI领域得到了较为广泛的应用。
fofa语法:app="Ollama"0x02 漏洞描述
近日,Ollama存在安全漏洞,该漏洞源于默认未设置身份验证和访问控制功能,未经授权的攻击者可在远程条件下调用Ollama服务接口,执行包括但不限于敏感模型资产窃取、虚假信息投喂、模型计算资源滥用和拒绝服务、系统配置篡改和扩大利用等恶意操作。
0x03 影响版本
Ollama所有版本均受此漏洞影响。
0x04 漏洞验证
随机找一个靶机看看
出现Ollama is running,即证明存在未授权访问的漏洞
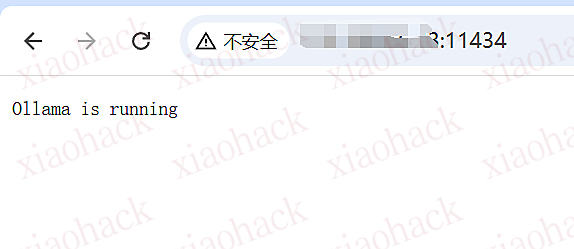
漏洞验证
通过查看Ollama api文档,Ollama提供了多个API 端点,用于执行不同的操作
详细情况查看:https://ollama.cadn.net.cn/api.html
/api/generate 用于生成文本或内容。通常用于基于给定的输入生成响应或输出,例如生成对话回复、文章等。
/api/chat 专门用于聊天交互。用户可以通过此端点与模型进行对话,模型会根据输入生成相应的回复。
/api/create 用于创建新的模型或资源。可能涉及初始化一个新的模型实例或配置。
/api/ps(或者tags) 用于管理或查看模型的标签。标签可以帮助用户对模型进行分类或标记,便于管理和查找。
/api/show 用于显示模型或资源的详细信息。用户可以获取模型的配置、状态或其他相关信息。
/api/copy 用于复制模型或资源。用户可以通过此端点创建一个现有模型的副本。
/api/delete 用于删除模型或资源。用户可以通过此端点移除不再需要的模型或数据。
/api/pull 用于从 Ollama 下载模型。用户可以通过此端点将模型从远程服务器拉取到本地环境中。
/api/push 用于将模型上传到 Ollama。用户可以通过此端点将本地模型推送到远程服务器。
/api/embeddings 用于生成文本的嵌入向量。嵌入向量是文本的数值表示,通常用于机器学习任务中的特征提取。
/api/version 用于获取 Ollama 的版本信息。用户可以通过此端点查询当前使用的 Ollama 版本。漏洞利用
在未授权情况,可以通过访问/api/ps(使用GET请求即可) 获取目前搭建的所有模型信息。

通过返回信息可以看到采用的是deepseek-r1模型,通过刚才我们知道的接口端点信息,我们可以调用/api/chat(使用POST请求)来完成聊天请求,消耗资源。

通过引导deepseek回答问题的过程中也能造成一些信息的泄露
所以在未授权的情况下,其他的接口都是可以用的,危害极大,可以通过调用那些危险接口进行操作,可对模型进行创建或删除的操作
0x05 漏洞影响
通过以上过程,我们可以看到该漏洞危害极大,且该漏洞利用难度也极低,可以通过未授权对大模型进行操作
0x06 修复建议
限制公网访问:尽量避免直接将 Ollama 服务端口(默认 11434)暴露在公网。
配置网络访问控制:通过云安全组、防火墙等手段限制对 Ollama 服务端口的访问来源。仅允许可信的源 IP 地址连接 11434 端口,阻止非授权 IP 的访问请求。
0X07 参考链接
https://github.com/ollama/ollama/blob/main/docs/faq.md
0x08 免责声明
本文所涉及的任何技术、信息或工具,仅供学习和参考之用。
请勿利用本文提供的信息从事任何违法活动或不当行为。任何因使用本文所提供的信息或工具而导致的损失、后果或不良影响,均由使用者个人承担责任,与本文作者无关。
作者不对任何因使用本文信息或工具而产生的损失或后果承担任何责任。使用本文所提供的信息或工具即视为同意本免责声明,并承诺遵守相关法律法规和道德规范。





































