Agent 面向结果交付,技术正从单点突破加速转向工程与系统竞争 |《中国软件技术发展洞察和趋势预测研究报告 2026》正式发布
2025 年,技术世界看起来既热闹又拥挤。 从开源大模型引发全球讨论,到 Agent 能力快速演进;从低空飞行、人形机器人走向现实应用,到量子技术不断刷新实验纪录,前沿技术在多个方向上几乎同时取得进展。但当这些热点被放在同一时间轴上回看,一个更深层的共性逐渐浮现:技术竞争的重心,正在从单点能力突破,转向系统级、工程级与生态级竞争。即技术的想象空间仍在扩张,但技术价值的释放,正越来越依赖完整系统、基础设施能力以及产业协同水平。 在 AI 领域,这一变化尤为明显。开源模型、MCP 等协议、多模态与 Agent 进一步迈向实际生产环境,使竞争不再只围绕模型参数或单次效果展开,而是延伸到推理效率、成本结构、系统稳定性与可治理性等更底层的问题。与此同时,在实体与基础科技领域,eVTOL 适航审定取得突破、人形机器人进入公众视野、量子计算持续推进,也在不断放大工程化与规模化落地的复杂性。 在这样的背景下,InfoQ 研究中心完成了《中国软件技术发展洞察和趋势预测研究报告 2026》。这份报告并未试图给出统一结论,也没有将未来简化为几条明确路径,而是从事实盘点出发,对过去一年软件技术的发展状态进行了系统整理,试图还原不同技术方向在真实环境中的推进情况。报告更关注技术如何被使用、如何被限制、如何在复杂系统中产生实际影响。更多内容也欢迎各位读者点击「链接」,下载完整报告进行阅读。 2025 年一个明显的变化是,模型依然处在技术演进的中心位置,但讨论重点已经发生迁移。模型能力仍在提升,但其边际影响开始放缓,推理效率、成本结构、系统稳定性的重要性持续上升。在真实场景中,能否稳定运行、能否控制成本、能否嵌入现有系统,往往比单次能力表现更具决定性。 这一变化,直接将 AI Infra 推向了更靠前的位置。过去,基础设施更多被视为模型能力提升的配套条件,关注重点集中在算力规模、训练效率与资源调度;而在 2025 年的实际应用中,AI Infra 的核心价值,开始体现在对不确定性的吸收与管理能力上。推理阶段的成本控制、运行过程的可观测性、异常状态的隔离与回滚、跨系统的稳定衔接,这些能力正在成为 AI 能否进入核心业务流程的前提条件。 当 Agent 进入真实生产环境,这一趋势被进一步放大。 与能力展示型应用不同,能够执行具体任务的 Agent,其行为不确定性更高,执行失败、路径偏离、资源误用等问题更容易直接影响业务结果。在这一过程中,执行环境的隔离、权限边界的设定、状态记录与追溯能力,开始成为 Agent 系统不可缺少的一部分。AI Infra 在这里不再只是运行环境,更是治理框架的一部分。 从更长的时间尺度看,这种对基础设施能力的重视,正在重新塑造 AI 技术的演进节奏。模型能力仍在向前推进,但其价值释放越来越依赖 Infra 是否能够将复杂性留在系统内部,将稳定性交付给使用者。这一趋势,在 2025 年已经初步显现,也成为观察 2026 年技术走向时不可忽视的背景之一。 开发领域的变化尤为典型。Coding 场景率先完成了从能力展示到生产力工具的跨越,Vibe Coding 在实际工作中快速扩散,同时也暴露出代码质量、责任归属、流程治理等新的问题。这些变化,让开发者工具、工程规范与平台能力重新回到技术讨论的核心位置。 在大模型的更中心,我们也看到了新的方法论和模型架构正在持续推进。围绕 RLVF 等训练范式的探索,模型在对齐方式、反馈机制以及长期目标建模上的能力不断被强化。与此同时,多模态能力也在发生结构性变化,从早期的多模态拼接,逐步走向原生多模态,再到对原生全模态和世界模型的探索,模型试图以更统一的方式理解和生成复杂世界,甚至预测和改变物理世界。 更进一步,在生态层面,围绕 Agent 和工具协作的协议开始形成共识,开源与闭源在不同市场呈现出差异化路径。中国力量在这一过程中逐渐显现出自身的特点。从 2025 年的实际进展看,开源在中国技术生态中承担的角色正在发生变化。它不再只是代码共享或技术展示的载体,而是逐渐融入到标准共识、工程协作和生态协同之中。围绕模型、Agent、工具链和基础设施的开源项目,开始更多地服务于真实场景,推动技术在复杂环境中的适配与演进。 这些变化并非孤立发生,而是与前述模型演进、基础设施成熟度以及 Agent 落地进程相互交织。它们共同构成了 2025 年技术世界中一个不易被单一指标捕捉,却正在逐渐成形的重要背景,也为理解 2026 年技术走向提供了更具现实感的参照。更多内容也欢迎各位读者点击文末的「阅读原文」,下载完整报告进行阅读。 除了 AI 本身,我们也看到了星地互联网、量子技术、低空飞行等领域在 2025 年出现了具有标志意义的进展。星地互联网在组网能力、覆盖密度和应用场景上持续推进,从验证通信能力,逐步转向面向真实业务的服务体系建设。量子技术在计算、通信和测量等方向继续取得实验层面的突破,同时也开始更多讨论其工程化路径与现实约束。低空飞行相关技术则在政策、基础设施和应用探索的共同推动下,加速从概念验证走向实际运行环境。 这些领域的发展路径各不相同,但一个共同特征是,都在主动探索与 AI 的结合方式。AI 被引入到复杂系统的调度、控制与决策之中,用于提升整体系统的运行效率和适应能力。在星地互联网中,AI 开始参与网络资源分配与链路管理。在量子技术相关研究中,AI 被用于辅助实验设计、参数搜索与系统优化。在低空飞行场景中,AI 则更多承担环境感知、路径规划与风险评估等任务。 从 2025 年的实践情况看,这种结合更多体现在局部能力增强,而非系统级重构。AI 并未改变这些技术的基本发展节奏,但正在逐步嵌入其关键环节,影响技术系统的复杂性管理方式。这也意味着,这些前沿领域的演进,正在越来越多地依赖于 AI 基础设施、算法稳定性以及系统工程能力的成熟程度。 这些探索尚处在不同阶段,却共同指向一个趋势。随着技术系统本身变得更加复杂,AI 正在成为连接不同技术要素的重要工具,而这种连接关系,也将在未来进一步影响这些领域的演进方式与应用边界。 技术演进常常伴随着喧嚣与关注,但真正决定其走向的变化,更多发生在基础能力、系统结构与生态关系的持续调整之中。那么,在 InfoQ 研究中心的观察中,2026 年的技术世界将呈现出怎样的状态?InfoQ 研究中心尝试用十大趋势的方式,对这个问题进行拆解和呈现。 趋势一:收敛已久的 Transformer 架构,即将迎来分化与创新新阶段 趋势二:RLVR 范式应用扩展与持续演进,经验学习等新范式正在路上 趋势三:原生多模态成为默认能力,原生全模态加速成型,世界模型技术路线迎来首轮技术收敛周期 趋势四:AI 推理基础设施凸显战略价值,系统化工程决定长期竞争力 趋势五:Agent 迈向结果交付,Agent Infra 从算力基础演进为风险可控、可验证、可托付的业务级支撑 趋势六:C 端应用,记忆机制与生态整合成为核心壁垒 趋势七:AI 硬件持续在垂类场景破局,手机仍是核心管理与交互中心 趋势八:有竞争就有动力,中国继续以开源撬动世界影响力 趋势九:AI for Science 推动科研生态升级,科学伦理面临深刻变革 趋势十:前沿技术交融,智能协作开启新格局,系统级能力强化科技与战略话语权 相关分析与完整内容,已收录在《中国软件技术发展洞察和趋势预测研究报告 2026》中。更多内容也欢迎各位读者点击「链接」,下载完整报告进行阅读,与 InfoQ 研究中心一同探索 2026 年的技术世界。 更多 AI 与技术前沿研究成果,也欢迎点击浏览「行业研究报告」专题。

回望 2025 ,模型仍在中心,但决定性因素已经发生迁移

前沿技术拓展技术想象空间,并主动探索与 AI 的结合
展望 2026,InfoQ 研究中心十大技术趋势

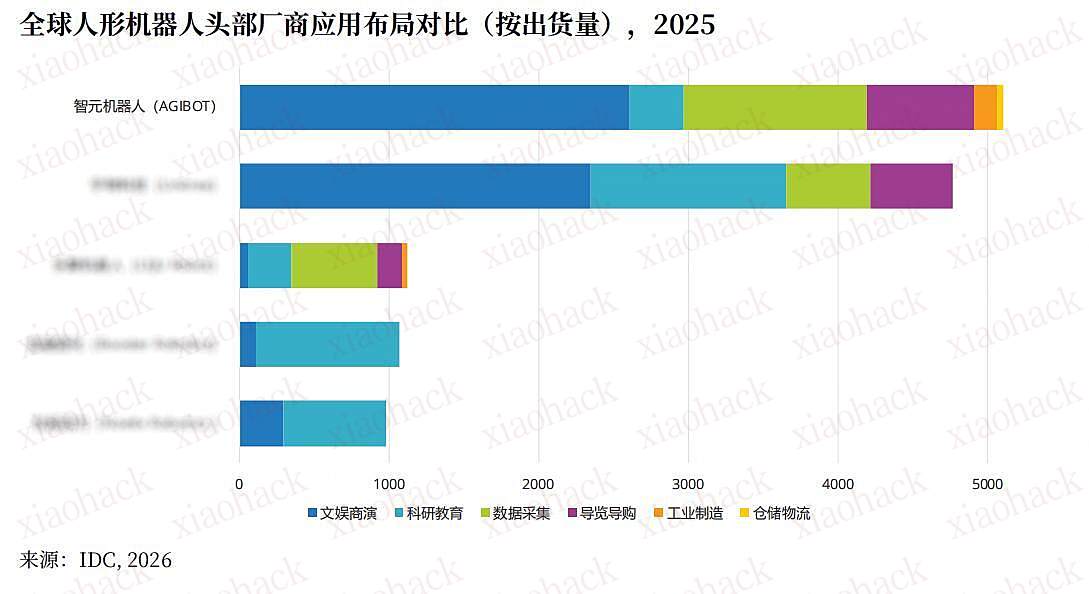









































































































 还记得那个穿着「Lululemon」紧身衣、主打温柔陪伴的
还记得那个穿着「Lululemon」紧身衣、主打温柔陪伴的

















