X开源Grok驱动的算法代码,揭秘内容传播机制

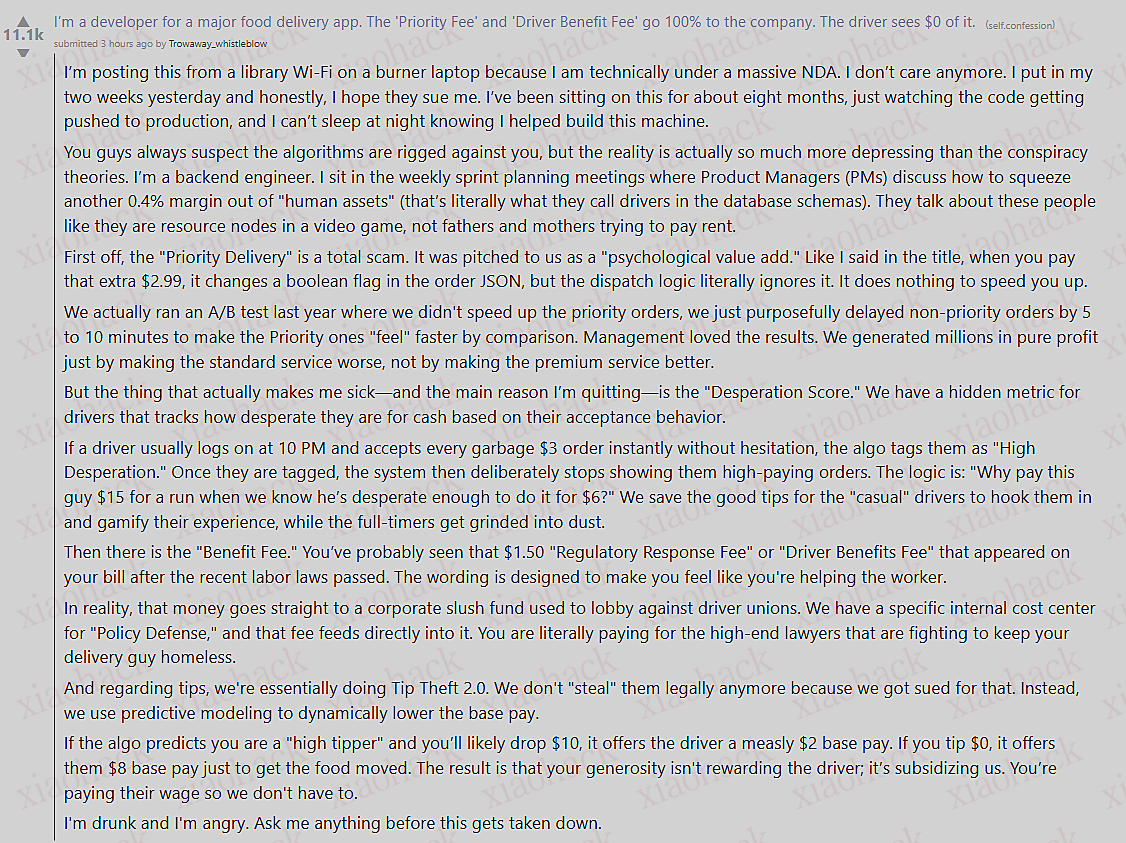
X 正式开源其基于 Grok 的推荐算法,公开了回复加权机制、链接惩罚规则及相似聚类技术(SimClusters) 。开发者通过剖析代码,解锁了内容互动预测的核心逻辑 —— 这一举措在平台透明度承诺下,正重塑创作者的运营策略。
为践行透明度承诺,埃隆・马斯克旗下的 X 平台采取大胆举措:开源经重构的推荐系统,揭开了驱动用户信息流的复杂底层架构。2026 年 1 月 20 日,X 工程团队与马斯克本人通过平台发文宣布该消息,相关代码托管于 github.com/xai-org/x-algorithm,其核心采用支撑 xAI 公司 Grok 模型的 Transformer 架构。此次开源兑现了马斯克 1 月 10 日的承诺,包含详尽的开发者说明文档,并计划每四周更新一次 —— 这一行动背后,是社交媒体信息流面临的监管压力日益加剧。
此次披露正值 X 因算法 “低效” 饱受诟病之际,马斯克在回复中坦言:“我们深知当前算法存在不足,亟需大幅优化,但至少大家能实时看到我们以透明方式努力改进的过程。” 与竞争对手不同,X 主动开放算法供公众审视,马斯克强调:“没有其他社交媒体公司会这么做。”
X 平台上的开发者初步代码评审显示,该算法已从 “刚性规则驱动” 转向 “AI 预测驱动”。据 StockTwits 报道,代码仓库详细披露了内容推荐逻辑,但专家指出,训练模型权重等关键要素并未包含在内。
Transformer核心赋能互动预测
算法的核心是一个轻量版 Grok 变体,借助 Transformer 架构,每日对 1 亿条帖子进行用户反应预测 —— 包括点赞、回复、转发、收藏等行为。X 工程团队在推文中证实:“其采用与 xAI Grok 模型相同的 Transformer 架构。” 据 News9live 分析,这一设计用机器学习取代了传统启发式规则,优先推送更可能引发用户互动的内容。
X 平台用户 @bytebot(科林・查尔斯)剖析代码后表示:“基于 Grok 的 Transformer 排序机制,有效避免了信息茧房问题。” 关注账号的 “圈内内容” 将获得优先推荐,而 “圈外内容” 则依赖机器学习预测,且包含图片、视频等媒体形式的内容会获得权重加成。内容时效性是重要考量因素,当目标受众活跃时,近期发布的内容将更具优势。
创作者可信度通过历史互动数据体现,若高活跃度用户关注的账号发布内容,其排名会相应提升。不过,该代码未包含嵌入表、Phoenix 检索细节及垃圾邮件过滤器等模块,表明此次开源聚焦核心排序逻辑,属于部分披露。
回复链与停留时间成关键信号
回复被证实为权重最高的互动信号。用户 @barkmeta(巴克)总结:“务必回复评论 —— 算法对‘评论 + 作者回复’的权重设定,是单纯点赞的 75 倍。无视评论等同于扼杀内容传播力。” 用户 @GodsBurnt(石博)也呼应:“‘75 倍规则’是代码中最强信号:评论 + 作者回复的组合效应无可替代。”
收藏行为的权重乘数为 50 倍,这意味着具备参考价值的内容将获得更多曝光;而停留时间 —— 通过用户观看视频或点击 “展开更多” 的行为来衡量 —— 同样具有决定性作用。正如查尔斯所指出的:“观看时长为王,若用户快速划走,内容排名将大幅下滑。” 视频和系列推文因能更好地吸引用户注意力,表现尤为突出。
负面信号的惩罚力度显著:屏蔽和静音操作的负面影响是取消关注的 10 倍。具有争议性但非垃圾信息的内容可能获得较高传播度,而引发用户反感的内容则会被降低曝光。
链接惩罚与垂直领域锁定重塑发布策略
外部链接会触发 “链接税” 机制,据石博透露,内容曝光量可能骤降高达 400%:“链接会扼杀可见度,应将其放在个人简介或置顶推文里。” 创作者建议通过简介放置链接或自动回复引导等方式,让用户留在平台内 —— 这与算法 “抵制用户流失” 的设计倾向高度一致。
相似聚类技术(SimClusters)强化了内容的垂直领域属性。巴克警告:“坚守自身领域…… 若偏离垂直赛道(如加密货币、科技等),将无法获得任何流量支持。” 该系统会按主题对用户和内容进行聚类,对偏离主题的内容实施降权处理,以确保信息流相关性。
这些从 GitHub 代码中拆解的机制表明,算法更青睐互动性强的对话式内容,而非单纯的被动浏览。据 Hypebeast 报道,马斯克承诺将持续更新算法,以回应外界对信息流机制及 Grok 整合效果的密切关注。
开发者从代码解析中提炼运营指南
用户 @razroo_chief(查理・格林曼)基于算法逻辑设计了一款 Claude 提示词,旨在最大化多维度信号权重:“核心优化目标:停留时间…… 回复量…… 转发量…… 点赞量…… 收藏量。” 该提示词建议,内容应采用反直觉的开篇、结构化的机制解析,并以冷静、系统的语气呈现深度洞察 —— 摒弃浮夸表达,聚焦科技系统、行为模式等主题的知识性输出。
发布后首小时的早期互动数据会显著影响算法预测结果,标签(Hashtag)仍具备实用价值,而富含媒体元素的内容格式更具竞争力。标签有助于内容发现,但积累高活跃度粉丝群体,其重要性远超单一运营技巧。
@GodsBurnt 走红的指南中强调:“收藏量是黄金指标…… 停留时间:若用户未点击‘展开更多’或观看视频,内容将被降权。” 这一机制让内容传播更趋公平,奖励具有深度关联价值的内容,而非浅层数据表现。
Grok演进推动算法全面革新
马斯克过往推文记录了算法迭代轨迹:2025 年 5 月,他宣布用 Grok 替代原有算法以实现突破性优化;同年 10 月,该模型已能每日处理 1 亿条帖子,基于内容质量进行精准匹配;8 月,Grok 4 Mini 的测试版本动用了 2 万台 GPU,在延迟控制与性能提升之间实现平衡。
The Verge 回顾了马斯克 2023 年推特(现 X)的代码公开行动 —— 当时的更新并不规律,与此次承诺形成鲜明对比。路透社指出,马斯克曾在 1 月 10 日承诺,将在 7 天内公开完整的自然流量与广告算法代码。
News9live 详细报道了 Phoenix 系统从人工规则向 AI 驱动的转型,通过 Transformer 架构预测用户互动行为,且更侧重回复而非点赞数据。
透明度举措遭遇监管压力
据 TechSpot 观察,马斯克的透明度举措旨在回应外界对平台 “不透明” 的指责,但过往类似承诺的执行力度参差不齐。ComputerWeekly 强调,此次开源包含了全部推荐算法代码。
WebProNews 报道称,用户可通过自然语言自定义信息流,例如输入 “无政治内容,仅展示 AI 创新”,这一功能进一步凸显了与 Grok 模型的深度整合。而此时,欧盟与美国正针对算法偏见问题展开调查。
StockTwits 呼吁专家对开源代码进行深度评审,尽管存在部分缺失,但此次披露已覆盖推荐机制的核心运作逻辑。
对平台与创作者的深远影响
对行业内部人士而言,此次开源揭示了算法 “重预测” 的排序逻辑:早期回复会引发雪球效应,媒体内容能持续吸引注意力,垂直领域定位可集中流量资源。Hypebeast 指出,此次代码发布与外界对 Grok 的审视密切相关,X 承诺将提供完整访问权限并持续更新。
创作者需及时调整策略:快速回应评论、避免在推文中直接嵌入外部链接、打造能提升用户停留时间的内容格式。正如巴克总结的:“与受众保持互动,建立深度关系,让用户留在平台内。”
X 的开源模式向竞争对手发起挑战 —— 将 xAI 的技术优势与开放代码相结合,在公众监督下持续优化信息流。这一举措或将重塑社交媒体算法的行业生态。