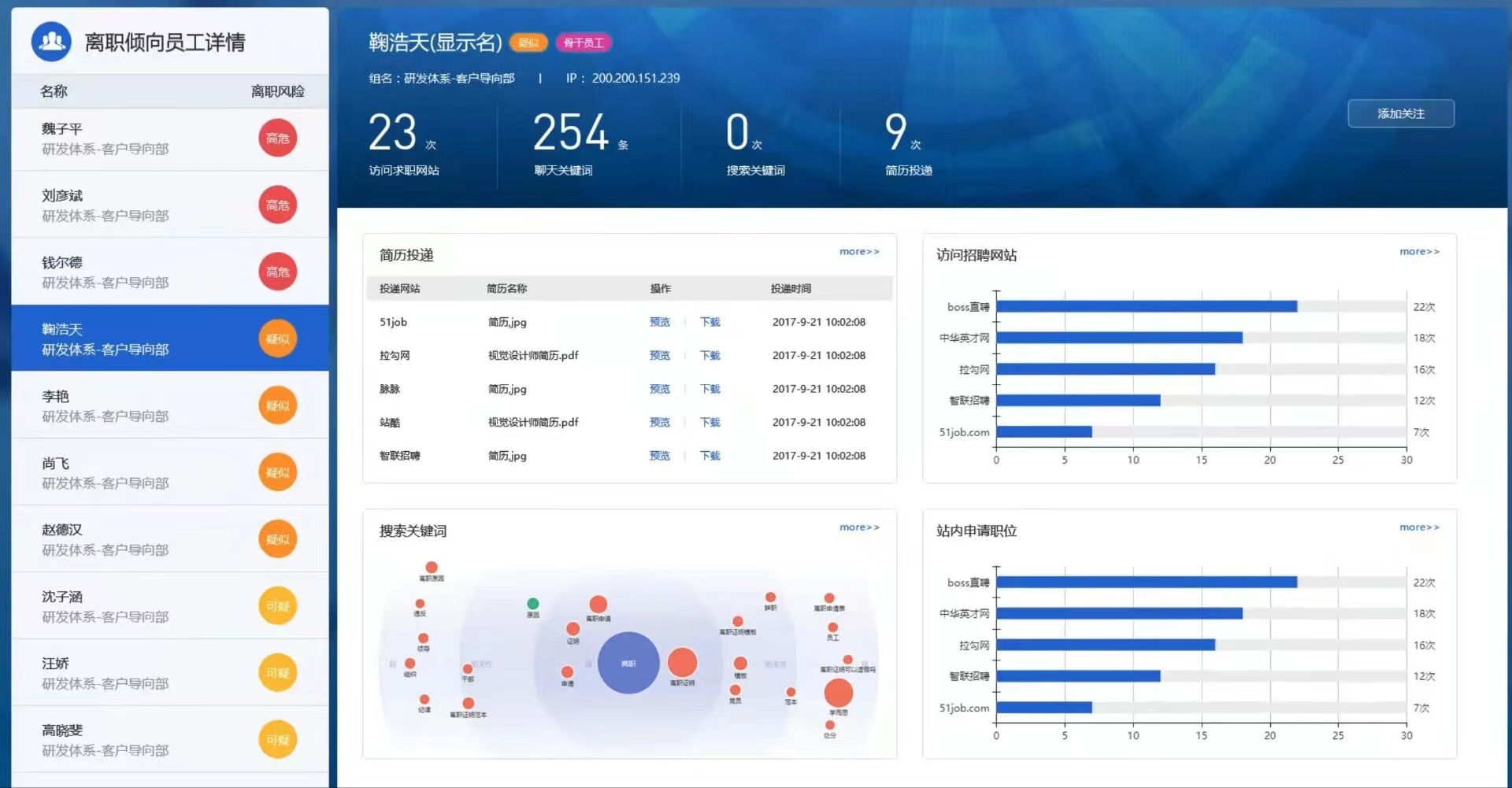
什么是 Headless Browser?B2Proxy解析无头浏览器的原理、应用场景与真实价值
随着自动化技术、数据采集和智能测试的普及,“Headless Browser(无头浏览器)”已经从一个偏工程师内部使用的工具,逐渐演变为数据工程、爬虫系统、自动化测试乃至 AI 应用中的核心组件。很多人听说过这个概念,却并不真正理解它的工作原理、真实能力以及在复杂网络环境中的价值。 Headless Browser,直译为“无头浏览器”,这里的“头”指的是图形用户界面。也就是说,它本质上是一个没有可视化界面的浏览器内核,能够像普通浏览器一样解析 HTML、执行 JavaScript、加载 CSS、发起网络请求、处理 Cookie 和本地存储,但所有过程都在后台完成,不向用户展示页面。 理解 Headless Browser 的关键,在于理解现代网页的加载逻辑。 很多初学者会把 Headless Browser 与传统 HTTP 爬虫混为一谈,但两者在能力层级上有明显差异。 正因为 Headless Browser 具备强大的模拟能力,它也成为各大平台重点识别和限制的对象。 很多人忽略了一个关键问题:Headless Browser 再强,也只是“浏览器”,它依然运行在某个网络环境之中。 这是一个经常被误解的问题。 随着反自动化技术的不断升级,Headless Browser 也在持续进化。从早期简单执行脚本,到如今强调完整指纹一致性、行为轨迹自然化和环境真实性,无头浏览器正在向“高度拟真浏览环境”发展。 Headless Browser 并不是一个神秘或危险的概念,它只是现代 Web 技术发展下的必然产物。理解它的原理、边界和真实价值,远比盲目使用或一味回避更重要。
本文将系统性地解析什么是 Headless Browser,它与传统浏览器的本质区别,以及它在现代互联网应用中的实际意义。Headless Browser 的基本定义
从功能角度看,Headless Browser 并不是“阉割版浏览器”,恰恰相反,它在网页渲染和脚本执行层面,与完整浏览器几乎一致,只是去掉了 UI 渲染这一步。
正因为这一特性,它非常适合被程序控制,用于自动化任务。无头浏览器是如何工作的
当你用普通浏览器访问一个网站时,背后会经历一整套流程:
浏览器发起请求、接收 HTML、解析 DOM、加载 CSS、执行 JavaScript、请求接口数据、动态更新页面内容。Headless Browser 运行的正是这套完整流程,只是整个过程由代码驱动,而不是由用户点击和操作触发。开发者可以通过脚本控制它打开页面、等待资源加载、模拟滚动、填写表单、点击按钮,甚至执行复杂的交互逻辑。
从服务器的角度看,它看到的并不是一个“工具”,而是一个行为极其接近真实用户的浏览器环境。Headless Browser 与普通爬虫的根本区别
传统爬虫更多依赖直接请求接口或页面源代码,适合结构简单、反爬较弱的网站。但面对大量使用前端框架、动态渲染、接口签名和行为校验的网站时,传统爬虫往往寸步难行。
Headless Browser 的优势在于,它可以完整执行前端逻辑,获取最终渲染后的真实页面状态。这意味着即使网站内容完全由 JavaScript 动态生成,也依然可以被正确获取。
在很多复杂网站场景中,无头浏览器已经成为“唯一可行方案”。为什么 Headless Browser 会被重点风控
近年来,网站风控系统不再只看 IP 和请求频率,而是更加关注浏览器指纹、行为轨迹和执行环境。一些常见的 Headless Browser 在默认配置下,会暴露出明显的自动化特征,例如特定的 JavaScript 属性、异常的渲染行为或不符合真实用户的操作节奏。
这也是很多人会遇到“明明用了无头浏览器,却还是被封”的根本原因。
Headless Browser 本身不是问题,问题在于环境是否足够真实、行为是否足够自然、网络身份是否可信。无头浏览器与网络环境的关系
如果网络出口本身存在异常,例如 IP 来源不可信、ASN 被标记、地址被滥用过,那么即使浏览器层面完全模拟真实用户,依然可能在请求阶段就被拦截。
这也是为什么在高风控场景下,无头浏览器往往需要配合更稳定、更接近真实用户的网络环境使用。真实住宅网络、干净的出口地址,往往比复杂的浏览器参数伪装更重要。Headless Browser 是否等同于“自动化作弊”
Headless Browser 本身是一种技术工具,它既可以用于合规的自动化测试、数据分析和效率提升,也可能被滥用于违规操作。关键并不在于工具本身,而在于使用方式是否符合平台规则和法律边界。
在合规使用前提下,无头浏览器反而是很多正规企业和开发团队不可或缺的基础设施。未来趋势:Headless Browser 正在变得“更像人”
未来,它不再只是一个技术工具,而是整个网络身份系统中的一个重要组成部分。结语
当你真正把它看作一个“没有界面的真实浏览器”,并将其放入合适的网络与合规框架中使用,它所能发挥的价值,远远超出想象。