vibe 了一个临时邮箱,有需要的自取
大佬们轻点玩,1c1g 禁不起折腾
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
大佬们轻点玩,1c1g 禁不起折腾
原贴
前些天看到大佬发了个开源的 outlook 管理工具,个人还是更喜欢使用 docker,所以在大佬的基础上加了 docker 的部署方式,功能和原版一致
最近有佬分享带有令牌的 outlook 邮箱;
正好手上也有一批号,想着做个管理和取件功能;
功能可能比较简单,简约风格;
这批有使用痕迹,不保证还有效哈。我试了几个是有效的;
增加了域名的临时邮箱功能,多种选择!
感谢佬提供的 API,暂时搞不到密钥,只能用默认的了;
400 + 域名的临时邮箱已就绪,API 已开放 (域名数量动态变化,以实际为准) - 资源荟萃 - LINUX DO

直接产出 Dreamy-rain/gemini-business2api 所需 json 注册效率~60s 一个
日抛 直接每日重新注册即可
刚刚那个版本有点问题 已修复
已经生成的佬记得把 config_id 后缀的?csesidx=.* 清理掉重新导入
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
from datetime import datetime
import time, random, json, os, requests
# 配置
TOTAL_ACCOUNTS = 20
MAIL_API = "https://mail.chatgpt.org.uk"
MAIL_KEY = "gpt-test"
OUTPUT_DIR = "gemini_accounts"
LOGIN_URL = "https://auth.business.gemini.google/login?continueUrl=https:%2F%2Fbusiness.gemini.google%2F&wiffid=CAoSJDIwNTlhYzBjLTVlMmMtNGUxZC1hY2JkLThmOGY2ZDE0ODM1Mg" # XPath
XPATH = {
"email_input": "/html/body/c-wiz/div/div/div[1]/div/div/div/form/div[1]/div[1]/div/span[2]/input",
"continue_btn": "/html/body/c-wiz/div/div/div[1]/div/div/div/form/div[2]/div/button",
"verify_btn": "/html/body/c-wiz/div/div/div[1]/div/div/div/form/div[2]/div/div[1]/span/div[1]/button",
}
NAMES = ["James Smith", "John Johnson", "Robert Williams", "Michael Brown", "William Jones",
"David Garcia", "Mary Miller", "Patricia Davis", "Jennifer Rodriguez", "Linda Martinez"]
def log(msg, level="INFO"): print(f"[{level}] {msg}")
def create_email():
"""创建临时邮箱""" try:
r = requests.get(f"{MAIL_API}/api/generate-email",
headers={"X-API-Key": MAIL_KEY}, timeout=30)
if r.status_code == 200 and r.json().get('success'):
email = r.json()['data']['email']
log(f"邮箱创建: {email}")
return email
except Exception as e:
log(f"创建邮箱失败: {e}", "ERR")
return None def get_code(email, timeout=30):
"""获取验证码"""
log(f"等待验证码 (最多{timeout}s)...")
start = time.time()
while time.time() - start < timeout:
try:
r = requests.get(f"{MAIL_API}/api/emails", params={"email": email},
headers={"X-API-Key": MAIL_KEY}, timeout=30)
if r.status_code == 200:
emails = r.json().get('data', {}).get('emails', [])
if emails:
html = emails[0].get('html_content') or emails[0].get('content', '')
soup = BeautifulSoup(html, 'html.parser')
span = soup.find('span', class_='verification-code')
if span:
code = span.get_text().strip()
if len(code) == 6:
log(f"验证码: {code}")
return code
except: pass print(f" 等待中... ({int(time.time()-start)}s)", end='\r')
time.sleep(3)
log("验证码超时", "ERR")
return None def save_config(email, cookies, url):
"""保存配置"""
os.makedirs(OUTPUT_DIR, exist_ok=True)
parsed = urlparse(url)
path_parts = url.split('/')
config_id = None for i, p in enumerate(path_parts):
if p == 'cid' and i+1 < len(path_parts):
config_id = path_parts[i+1]
# 清理 config_id 结尾的 ?csesidx=xxx if config_id and '?' in config_id:
config_id = config_id.split('?')[0]
break
cookie_dict = {c['name']: c for c in cookies}
ses_cookie = cookie_dict.get('__Secure-C_SES', {})
data = {
"id": email,
"csesidx": parse_qs(parsed.query).get('csesidx', [None])[0],
"config_id": config_id,
"secure_c_ses": ses_cookie.get('value'),
"host_c_oses": cookie_dict.get('__Host-C_OSES', {}).get('value'),
"expires_at": datetime.fromtimestamp(ses_cookie.get('expiry', 0) - 43200).strftime('%Y-%m-%d %H:%M:%S') if ses_cookie.get('expiry') else None
}
with open(f"{OUTPUT_DIR}/{email}.json", 'w') as f:
json.dump(data, f, indent=2, ensure_ascii=False)
log(f"配置已保存: {email}.json")
return data
def register(driver):
"""注册单个账号"""
email = create_email()
if not email: return None, False, None
wait = WebDriverWait(driver, 60)
# 1. 访问登录页
driver.get(LOGIN_URL)
time.sleep(5)
# 2. 输入邮箱
log("输入邮箱...")
inp = wait.until(EC.visibility_of_element_located((By.XPATH, XPATH["email_input"])))
inp.click(); time.sleep(0.3); inp.clear(); time.sleep(0.3)
for c in email: inp.send_keys(c); time.sleep(0.05)
log(f"邮箱: {email}, 实际值: {inp.get_attribute('value')}")
time.sleep(1)
# 3. 点击继续
btn = wait.until(EC.element_to_be_clickable((By.XPATH, XPATH["continue_btn"])))
driver.execute_script("arguments[0].click();", btn)
log("点击继续")
time.sleep(3)
# 4. 获取验证码
code = get_code(email)
if not code: return email, False, None # 5. 输入验证码
time.sleep(2)
log(f"输入验证码: {code}")
try:
pin = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "input[name='pinInput']")))
pin.click(); time.sleep(0.2)
for c in code: pin.send_keys(c); time.sleep(0.1)
except:
try:
span = driver.find_element(By.CSS_SELECTOR, "span[data-index='0']")
span.click(); time.sleep(0.3)
driver.switch_to.active_element.send_keys(code)
except Exception as e:
log(f"验证码输入失败: {e}", "ERR")
return email, False, None # 6. 点击验证
time.sleep(1)
try:
vbtn = driver.find_element(By.XPATH, XPATH["verify_btn"])
driver.execute_script("arguments[0].click();", vbtn)
except:
for btn in driver.find_elements(By.TAG_NAME, "button"):
if '验证' in btn.text: driver.execute_script("arguments[0].click();", btn); break
log("点击验证")
time.sleep(5)
# 7. 输入姓名 try:
name_inp = WebDriverWait(driver, 30).until(EC.visibility_of_element_located(
(By.CSS_SELECTOR, "input[formcontrolname='fullName'], input[placeholder='全名'], input#mat-input-0")))
name = random.choice(NAMES)
name_inp.clear(); time.sleep(0.3)
for c in name: name_inp.send_keys(c); time.sleep(0.03)
log(f"姓名: {name}")
from selenium.webdriver.common.keys import Keys
name_inp.send_keys(Keys.ENTER)
except Exception as e:
log(f"姓名输入异常: {e}", "WARN")
# 8. 等待进入工作台
log("等待工作台...")
time.sleep(6)
for _ in range(30):
if 'business.gemini.google' in driver.current_url and 'auth' not in driver.current_url:
break
time.sleep(2)
time.sleep(3)
# 9. 保存配置
config = save_config(email, driver.get_cookies(), driver.current_url)
log(f"注册成功: {email}")
return email, True, config
def main():
print(f"\n{'='*50}\nGemini Business 批量注册 - 共 {TOTAL_ACCOUNTS} 个\n{'='*50}\n")
driver = uc.Chrome(options=uc.ChromeOptions(), use_subprocess=True)
success, fail, accounts = 0, 0, []
for i in range(TOTAL_ACCOUNTS):
print(f"\n{'#'*40}\n注册 {i+1}/{TOTAL_ACCOUNTS}\n{'#'*40}\n")
try:
driver.current_url # 检查driver是否有效 except:
driver = uc.Chrome(options=uc.ChromeOptions(), use_subprocess=True)
try:
email, ok, cfg = register(driver)
if ok: success += 1; accounts.append((email, cfg))
else: fail += 1 except Exception as e:
log(f"异常: {e}", "ERR"); fail += 1 try: driver.quit()
except: pass
driver = uc.Chrome(options=uc.ChromeOptions(), use_subprocess=True)
print(f"\n进度: {i+1}/{TOTAL_ACCOUNTS} | 成功: {success} | 失败: {fail}")
if i < TOTAL_ACCOUNTS - 1:
try: driver.delete_all_cookies()
except: pass
time.sleep(random.randint(3, 5))
try: driver.quit()
except: pass print(f"\n{'='*50}\n完成! 成功: {success}, 失败: {fail}\n配置保存在: {OUTPUT_DIR}/\n{'='*50}")
if __name__ == "__main__":
main()
感谢佬友的临时邮箱 gptmail 也感谢谷大善人不限域名大赦天下
特别感谢 2api 作者 大家也别忘了给他的帖子和仓库 star 一下~
Git Hub
有空可以帮忙支持一下小白新人
** 有能力的老板可以资助一下 LDC,球球辣 **
50LDC 即可鼓励新人

半自动化是因为 API 化失败了,所以采用开浏览器半自动化的模式了。
欢迎有实力的佬友进行调优,本人是小白,用哈基米和 Codex 写的。写得很粗糙,不要见怪。
使用方法看 README
自备一个订阅机场,clash 核心自下。配置我个人是通过 clash 右键订阅机场,打开文件,复制到 local.yaml 覆盖全部使用。运行后,本地的 clash(或者其他代理)可以关了,或者切换为规则。不要开全局,系统代理。否则两个 clash 会冲突。
邮箱注册功能来自: DuckMail

Business 登录地址:
后续登录也靠佬的前端:
运行界面:

账号密码保存在 csv 文件下:

| 功能 | 状态 | 说明 |
| 纯 API 注册 | 未实现 | Google 使用 reCAPTCHA Enterprise,纯 API 无法绕过
| 问题 | 说明 |
| IP 封锁 | 部分代理节点被 Google 封禁,程序会自动切换节点 |
| 按钮匹配不正确 | 有大概率触发点击验证和重发验证码两个按钮,但是不影响功能 |
| 页面加载慢 | 网络不稳定时页面加载较慢,可能导致超时 |
| 存在僵尸进程 clash.exe| 在后台会占用资源,可自己手动进任务管理器结束 |
更新预告:
大兵自助验证 API 已完成,完全全自动,使用方法参考市面上的 BOT,输入验证 URL 即可完成验证。这几天活动关了,等稳定了可能考虑开源给大家。



IP: 德国
1- 首先,在这里开设一个新账户:https://chatgpt.com/
2- 使用此电子邮件地址创建账户
3- 然后订阅为期 1 个月的免费商业计划,并选择 SEPA 付款方式
4- 这里:https://fakeiban.org/ 或 https://fakeit.receivefreesms.co.uk/c/de/
需要 Gemini Enterprise 位置加入?
不过还是很感谢分享位置加入的佬,感谢你们的分享
我自己也在测试 Gemini Enterprise2api 这个项目
1:Gemini Business 2APl Helper 的佬
2:business-gemini2api 的佬
在两位佬的基础上优化了一下,改成推送云端的解决 cookie 时效过期问题。目前还是手动推送,项目不稳定,后续还是要优化成:定时 / 每小时获取推送,实现反代自由。
佬友们社区搜索这两个项目问问 AI 也能自己部署
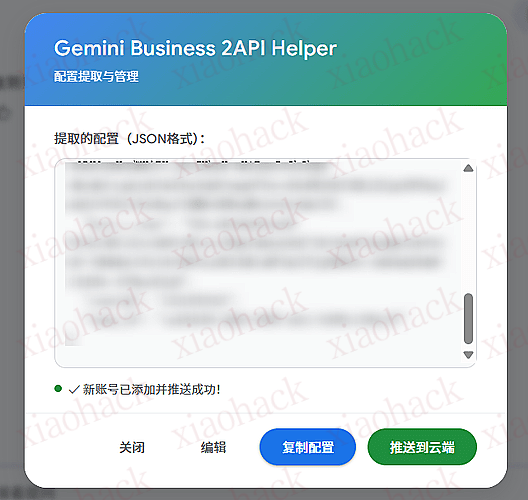
cookie 时效问题:
实测是可以用的,就是 cookie 时效太短,重新推送 cookie 就能用


目前临时邮箱也搭建好了,我想着是临时邮箱 + 无图形化 + 自动化实现切号,但是现在无图形化 Google 验证我搞不定
给大家分享下 通过临时邮箱获取 ProxyScrape 7 天试用 IP 池 的方法,可多次注册使用(单次最多 100 个 IP)。
ProxyScrape 官网
📄 Free Proxy List - Updated every 5 minutes
临时邮箱(推荐)
https://tmailor.com/
测试过多个临时邮箱服务,目前该站可正常接收 ProxyScrape 验证邮件
浏览器无痕模式
用于避免缓存、Cookie 影响注册流程
打开注册页面
ProxyScrape Sign up
使用 tmailor.com 获取的临时邮箱填写注册信息
输入验证码
前往临时邮箱查收验证邮件并完成注册
注册完成后,即可在控制台中创建并使用 7 天试用 IP 池:
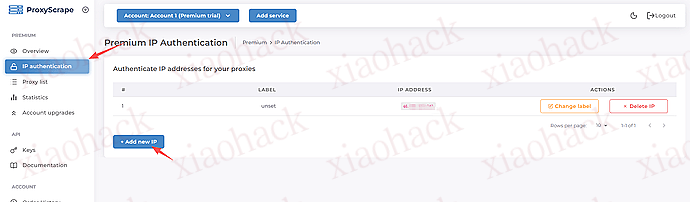
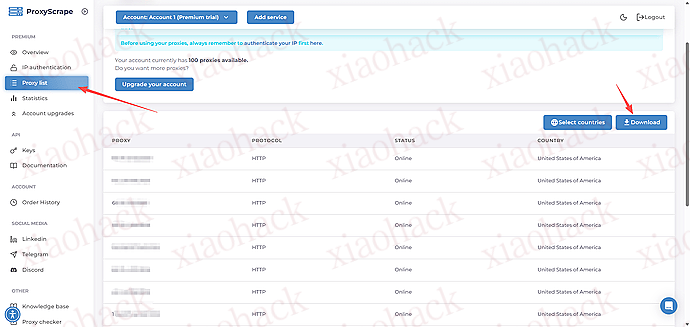
接下来就可以放心使用你的 IP 池了。
给大家分享下 通过临时邮箱获取 ProxyScrape 7 天试用 IP 池 的方法,可多次注册使用(单次最多 100 个 IP)。
ProxyScrape 官网
📄 Free Proxy List - Updated every 5 minutes
临时邮箱(推荐)
https://tmailor.com/
测试过多个临时邮箱服务,目前该站可正常接收 ProxyScrape 验证邮件
浏览器无痕模式
用于避免缓存、Cookie 影响注册流程
打开注册页面
ProxyScrape Sign up
使用 tmailor.com 获取的临时邮箱填写注册信息
输入验证码
前往临时邮箱查收验证邮件并完成注册
注册完成后,即可在控制台中创建并使用 7 天试用 IP 池:
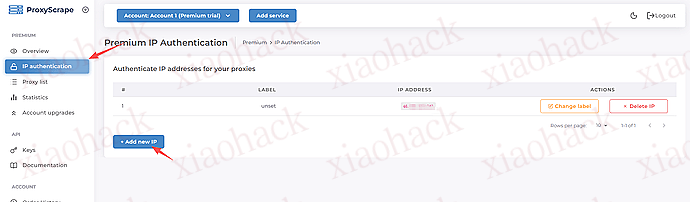
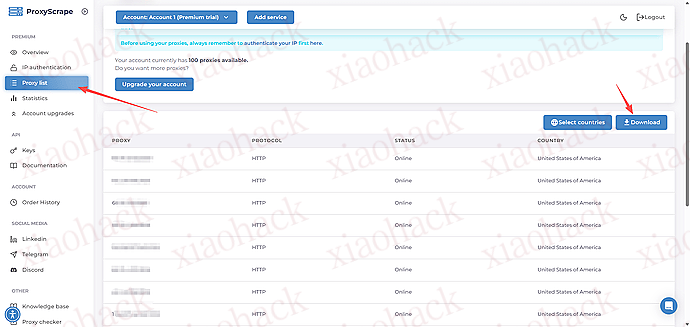
接下来就可以放心使用你的 IP 池了。