2025

时光奔流,我们即将与 2025 年挥手作别。感谢这一路上,每一位伙伴的并肩前行与坚定支持。
今年,美团技术团队在持续深耕中涌现出不少值得分享的实践与开源产品&服务。我们从中精选了18篇具有代表性的技术文章,内容涵盖大模型开源、研发技能、产品服务三大方向。值得一提的是,美团 LongCat 团队今年在大模型开源领域成果显著,陆续发布了涵盖基座模型、图像、视频、语音等多个方向的开源产品与工具,期望能够持续推动AI技术分享与生态共建。
希望这些开源的大模型产品、服务及凝结一线技术实战经验的内容,能为大家带来启发和帮助,陪伴同学们在技术前行的道路上扎实成长。愿我们在新年里,继续向下扎根、向上生长,迎着光,奔赴更高、更远的山海。2026,期待继续同行!
大模型开源
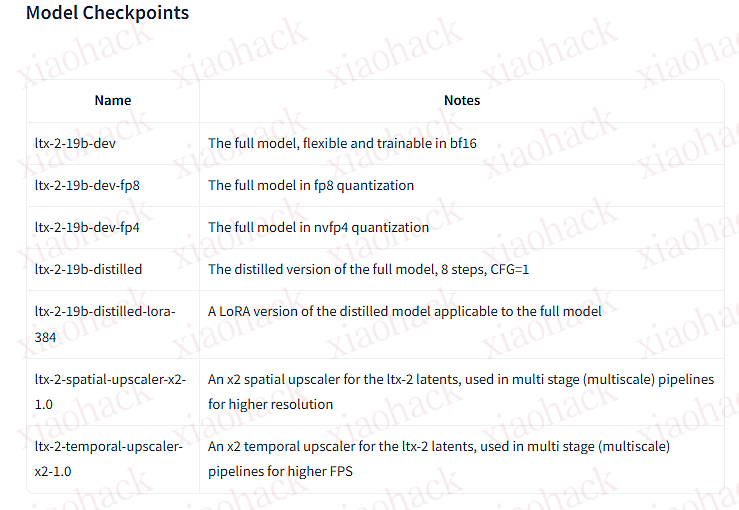
01 | 美团正式发布并开源 LongCat-Flash-Chat,动态计算开启高效 AI 时代

9月初,美团正式发布并开源 LongCat-Flash-Chat。LongCat-Flash 采用创新性混合专家模型(Mixture-of-Experts, MoE)架构,总参数 560 B,激活参数 18.6B~31.3B(平均 27B),实现了计算效率与性能的双重优化。
根据多项基准测试综合评估,作为一款非思考型基础模型,LongCat-Flash-Chat 在仅激活少量参数的前提下,性能比肩当下领先的主流模型,尤其在智能体任务中具备突出优势。并且,因为面向推理效率的设计和创新,LongCat-Flash-Chat 具有明显更快的推理速度,更适合于耗时较长的复杂智能体应用。
目前,已在 Github、Hugging Face 平台同步开源,同时你也可以访问官网 https://longcat.ai/,与 LongCat-Flash-Chat 开启对话。(阅读全文)
开源地址:Hugging Face | Github
02 | LongCat-Flash-Thinking 正式发布,更强、更专业,保持极速!

9月,美团 LongCat 团队正式发布全新高效推理模型 LongCat-Flash-Thinking。在保持了 LongCat-Flash-Chat 极致速度的同时,全新发布的 LongCat-Flash-Thinking 更强大、更专业。综合评估显示,LongCat-Flash-Thinking 在逻辑、数学、代码、智能体等多个领域的推理任务中,达到了全球开源模型的先进水平。
同时,LongCat-Flash-Thinking 不仅增强了智能体自主调用工具的能力,还扩展了形式化定理证明能力,成为国内首个同时具备「深度思考+工具调用」与「非形式化+形式化」推理能力相结合的大语言模型。我们发现,尤其在超高复杂度的任务(如数学、代码、智能体任务)处理上, LongCat-Flash-Thinking 具备更显著的优势。目前, 该模型已在HuggingFace、Github全面开源。(阅读全文)
开源地址:Hugging Face | Github
03 | LongCat-Video 视频生成模型正式发布,探索世界模型的第一步

要让人工智能真正理解、预测甚至重构真实世界,“世界模型”(World Model)已成为通往下一代智能的核心引擎。作为能够建模物理规律、时空演化与场景逻辑的智能系统,世界模型赋予AI“看见”世界运行本质的能力。而视频生成模型有望成为构建世界模型的关键路径——通过视频生成任务压缩几何、语义、物理等多种形式的知识,AI得以在数字空间中模拟、推演乃至预演真实世界的运行。
基于这一关键目标,10月,美团 LongCat 团队正式发布 LongCat-Video 视频生成模型 —— 不仅以统一模型在文生、图生视频基础任务上达到开源先进水平,更依托原生视频续写任务预训练,实现分钟级长视频连贯生成,从根源上保障跨帧时序一致性与物理运动合理性,尤其在长视频生成领域具备显著优势。
作为一款视频生成模型,LongCat-Video 凭借其精准重构真实世界运行状态的能力,正在成为美团探索世界模型的第一步,也是关键的一步。同时,这也为后续支撑更多自动驾驶、具身智能等深度交互业务场景,夯实了技术基础。(阅读全文)
开源地址:GitHub | Hugging Face | Project Page
04 | LongCat-Flash-Omni 正式发布并开源:开启全模态实时交互时代

11月,LongCat-Flash-Omni 正式发布并开源。LongCat-Flash-Omni 以 LongCat-Flash 系列的高效架构设计为基础( Shortcut-Connected MoE,含零计算专家),同时创新性集成了高效多模态感知模块与语音重建模块。即便在总参数 5600 亿(激活参数 270 亿)的庞大参数规模下,仍实现了低延迟的实时音视频交互能力,为开发者的多模态应用场景提供了更高效的技术选择。
综合评估结果表明,LongCat-Flash-Omni 在全模态基准测试中达到开源先进水平,同时在文本、图像、视频理解及语音感知与生成等关键单模态任务中,均展现出极强的竞争力。LongCat-Flash-Omni 是业界首个实现 “全模态覆盖、端到端架构、大参数量高效推理” 于一体的开源大语言模型,首次在开源范畴内实现了全模态能力对闭源模型的对标,并凭借创新的架构设计与工程优化,让大参数模型在多模态任务中也能实现毫秒级响应,解决了行业内推理延迟的痛点。模型已同步开源,欢迎体验。(阅读全文)
开源地址:Hugging Face | Github
05 | 美团开源 LongCat-Audio-Codec,高效语音编解码器助力实时交互落地

语音大语言模型(Speech LLM)想落地,绕不开一个死结:既要快速理解语音里的语义,又要说出自然的音色,还得实时响应。比如智能音箱 “听不懂” 语音,车载助手 “说” 得像机器人,实时翻译延迟卡半秒。深究根源,全在 “语音 Token 化”:作为拆分语音为 Speech LLM “离散单元” 的关键步骤,传统方案始终没平衡好 —— 要么缺语义、要么丢声学、要么延迟高,刚好卡了 Speech LLM 落地的 “死结”。
针对 Speech LLM 落地中的音频处理难题,11月,美团 LongCat 团队正式开源专用语音编解码方案 LongCat-Audio-Codec。它提供了一套一站式的 Token 生成器(Tokenizer)与 Token 还原器(DeTokenizer)工具链,其核心功能是将原始音频信号映射为语义与声学并行的 token 序列,实现高效离散化,再通过解码模块重构高质量音频,为 Speech LLM 提供从信号输入到输出的全链路音频处理支持。通过创新的架构设计与训练策略,LongCat-Audio-Codec 在语义建模、声学重建、流式合成三大维度实现突破。(阅读全文)
开源地址:Github | Hugging Face
06 | 美团发布 LongCat-Image 图像生成模型,编辑能力登顶开源SOTA

12月初,美团发布 LongCat-Image 图像生成模型。当前 AI 图像生成技术需求旺盛,但行业陷入 “两难困境”:闭源大模型性能强劲但无法自行部署或二次定制开发,开源方案普遍存在轻量化与模型性能难以兼顾、面向商用专项能力不足的痛点,制约商业创作与技术普惠。
为此,美团 LongCat 团队正式发布并开源 LongCat-Image 模型,通过高性能模型架构设计、系统性的训练策略和数据工程,以 6B 参数规模,成功在文生图和图像编辑的核心能力维度上逼近更大尺寸模型效果,为开发者社区与产业界提供了 “高性能、低门槛、全开放” 的全新选择。(阅读全文)
开源地址:Hugging Face | GitHub
07 | 美团 LongCat-Video-Avatar 发布,实现开源SOTA级拟真表现

今年 8 月,美团开源的 InfiniteTalk 项目凭借无限长度生成能力与精准的唇形、头部、表情及姿态同步表现,迅速成为语音驱动虚拟人领域的主流工具,吸引全球数十万名开发者的使用。10月底,LongCat 团队开源了 LongCat-Video 视频生成模型,尤其在长视频生成领域具备显著优势。
在 InfiniteTalk 和 LongCat-Video 基座的良好基础上,LongCat 团队针对实际场景中的核心痛点持续优化,12月正式发布并开源 SOTA 级虚拟人视频生成模型 —— LongCat-Video-Avatar。
该模型基于 LongCat-Video 基座打造,延续 “一个模型支持多任务” 的核心设计,原生支持 Audio-Text-to-Video(AT2V)、Audio-Text-Image-to-Video(ATI2V)及视频续写等核心功能,同时在底层架构上全面升级,实现动作拟真度、长视频稳定性与身份一致性三大维度的显著突破,为开发者提供更稳定、高效、实用的创作解决方案。(阅读全文)
开源地址:GitHub | Hugging Face | Project
研发技能
08 | MTGR:美团外卖生成式推荐Scaling Law落地实践

美团外卖推荐算法团队基于HSTU提出了MTGR框架以探索推荐系统中Scaling Law。MTGR对齐传统模型特征体系,并对多条序列利用Transformer架构进行统一建模。通过极致的性能优化,样本前向推理FLOPs提升65倍,推理成本降低12%,训练成本持平。MTGR离在线均取得近2年迭代最大收益,且于2025年4月底在外卖推荐场景全量。本文系相关工作的实践与经验总结,希望能给从事相关方向研究的同学带来一些帮助。(阅读全文)
09 | JDK高版本特性总结与ZGC实践

美团信息安全技术团队核心服务升级JDK 17后,性能与稳定性大幅提升,机器成本降低了10%。高版本JDK与ZGC技术令人惊艳,且Java AI SDK最低支持JDK 17。本文总结了JDK 17的主要特性,然后重点分享了JDK 17+ZGC在安全领域的一些实践,希望能对大家有所帮助或启发。(阅读全文)
10 | 鸿蒙应用签名实操及机制探究

华为鸿蒙单框架操作系统HarmonyOS NEXT已于2024年10月23日正式发布Release版。HarmonyOSNEXT仅支持鸿蒙原生应用,不再兼容安卓。本文对鸿蒙公开资料进行了深入分析和解读,梳理了鸿蒙单框架应用的签名机制,拆解每一步的实操过程和背后的实现原理,并对源码分析整理签名的校验机制。从中管中窥豹,探究鸿蒙系统的安全设计思路,给从事鸿蒙研发的同学提供一些借鉴。(阅读全文)
11 | 预测技术在美团弹性伸缩场景的探索与应用

管理企业大规模服务的弹性伸缩场景中,往往会面临着两个挑战:第一个挑战是精准的负载预测,由于应用实例的启动需要一定预热时间,被动响应式伸缩会在一段时间内影响服务质量;第二个挑战是高效的资源分配,即在保障服务质量的同时控制资源成本。为了解决这些挑战,美团与中国人民大学信息学院柴云鹏教授团队展开了“预测技术在弹性伸缩场景的应用”科研合作,相关论文《PASS: Predictive Auto-Scaling System for Large-scale Enterprise Web Applications》在具有国际影响力的会议The Web Conference 2024(CCF-A类会议)上作为Research Full Paper发表。(阅读全文)
12 | 从0到1建设美团数据库容量评估系统

美团数据库团队推出了数据库容量评估系统,旨在解决数据库容量评估与变更风险防控等领域难题。本文介绍了系统架构和主要功能:系统使用线上流量在沙盒环境回放验证变更安全,结合倍速回放技术探测集群性能瓶颈,构建容量运营体系实现集群容量观测与治理闭环。系统具备数据操作安全、结果真实可靠、灵活高效赋能等特点,有效提升数据库稳定性与资源利用率。(阅读全文)
13 | AI Coding与单元测试的协同进化:从验证到驱动

AI生成代码质量难以把控!本文分享来自美团的技术实践,三大策略破解AI编程痛点。单测快速验证逻辑正确性,安全网保护存量代码演进,TDD模式精准传递需求。告别「看起来没问题」的错觉,构建AI时代的代码质量保障体系。(阅读全文)
14 | LongCat-Flash:如何使用SGLang部署美团Agentic模型

SGLang 团队是业界专注于大模型推理系统优化的技术团队,提供并维护大模型推理的开源框架SGLang。近期,美团M17团队与SGLang团队一起合作,共同实现了LongCat-Flash模型在SGLang上的优化,并产出了一篇技术博客《LongCat-Flash: Deploying Meituan’s Agentic Model with SGLang》,文章发表后,得到了很多技术同学的认可,因此我们将原文翻译出来,并添加了一些背景知识,希望更多同学能够从LongCat-Flash的系统优化中获益。(阅读全文)
15 | 可信实验白皮书系列:从0到1的方法论与实践指南

增长与优化是企业永恒的主题。面对未知的策略价值,数据驱动的AB实验已经成为互联网企业在策略验证、产品迭代、算法优化、风险控制等方向必备的工具。越来越多的岗位,如数据科学家、算法工程师、产品经理以及运营人员等,要求候选人了解AB实验相关知识。然而,许多从业者由于缺乏有效的学习渠道,对AB实验的理解仍停留在初级阶段,甚至存在一些误解。我们希望通过系统性地分享和交流AB实验的理论基础、基本流程、核心要素及其应用优势,能够帮助更多相关人员深入了解实验,提升实验文化的普及度,最终辅助企业在更多领域做出精确数据驱动决策。
除了广泛传播实验文化外,该白皮书在深度上也可给实验研究人员,提供复杂业务制约下进行可信实验设计与科学分析评估的参考经验和启发。从美团履约技术团队、美团外卖业务的实践来看,实验者常常面临多种复杂的实验制约和难题,例如,在美团履约业务中,实验往往需要应对小样本、溢出效应(即实验单元间互相干扰)以及避免引发公平性风险等多重约束,需设计科学复杂的实验方案以克服相应挑战。通过撰写白皮书,我们系统性地总结和分享应对复杂实验约束的研究经验,进而能够促进实验技术的传播与升级,推动实验科学持续进步。
本白皮书以AB实验为中心,涵盖AB实验概述与价值、实验方法基础原理与案例剖析以及配套SDK代码分析等,内容丰富且易于理解和应用。适合从事AB实验研究的数据科学家、系统开发人员,以及需要实验驱动策略决策的业务和产研团队,同时也适合对数据驱动增长和数据科学等领域感兴趣的读者。(阅读全文)
产品服务
16 | 无需代码!美团 NoCode 像聊天一样轻松搭建你的专属网站

这是一款由美团技术团队打造的 AI 编程类产品——NoCode,可以像聊天一样轻松搭建你的专属网站、游戏、各种小工具等等,当然还有更多的隐藏功能等你发现,文末我们还准备了2项互动奖励,期待跟大家一起,开启全新的 AI 编程之旅。(阅读全文)
17 | 美团首款 AI IDE 产品 CatPaw 开启公测

Meituan CatPaw (以下统一使用“CatPaw”)是美团推出的 AI IDE,以 Agent & 人协作为核心,通过 Agent 智能驱动编程,辅以代码补全、项目预览调试等功能,结合美团自研的基于编程场景特训的 LongCat 模型,并支持多种模型混合调用,让编码过程更专注,项目交付更高效!
CatPaw 早在 2023 年就在美团内部以编辑器插件形态正式上线,此次完成全新升级后进行公开测试。目前在美团内部研发渗透率超 95%,增量代码 AI 生成率超 50%。(阅读全文)
18 | 美团 LongCat 上线 AI 生图!精准高效,AI 创作不设限

美团 LongCat 全新上线 AI 生图功能,该功能基于LongCat系列模型「LongCat-Image」打造而成。不仅在文生图任务中实现了“快、真、准” :出图快速响应、达到摄影棚拍摄质感、中文渲染精准度高;更在图像编辑任务上做到了精准便捷,无需复杂指令,可以用自然语言对图像进行二次编辑。
无论是追求高效出图的普通用户,还是需要精准落地创意的专业创作者,LongCat 都以 “轻量化模型 + 流畅体验” ,让 AI 生图真正成为人人可用的创作工具。目前,AI 生图功能已在LongCat APP和 https://longcat.ai/ 同步上线,轻松解锁高效创作新方式。(阅读全文)




















 原来,视频生成卷到极致,就是突破大脑和视觉的边界,让想象力进入 AI 构建的虚拟空间。
原来,视频生成卷到极致,就是突破大脑和视觉的边界,让想象力进入 AI 构建的虚拟空间。










































 还记得那个穿着「Lululemon」紧身衣、主打温柔陪伴的
还记得那个穿着「Lululemon」紧身衣、主打温柔陪伴的