一个 3T 大小却包含 4.75 亿 PDF 的数据集 - FinePDFs
FinePDFs 是一个专案
主要是爬了 2013 至 2025 这几年间的 pdf 文档,经过数据清洗与标记后,归纳成为一个包含 1733 种语言在内的 4.75 亿 pdf 文档数据库。
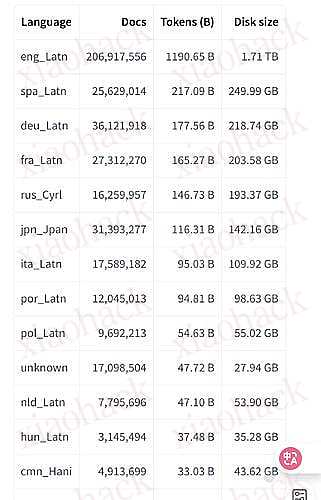
之所以要做这个是因为团队发现大部分模型训练内容几乎不包含 pdf 档(仅占 0.6% 左右),但其实许多的技术文件以及理论文档都是以 pdf 格式存在,因此他们团队才决定朝这个方向前进。
有兴趣的可以看看以下的技术说明及数据库
主要会对模型训练有帮助