最近花了点时间,用 Python 开发了一个微信 AI 女友机器人项目 —— AILive 。这个机器人不仅能智能对话,还能记住你们的聊天历史,甚至会在你长时间不说话时主动找你聊天!
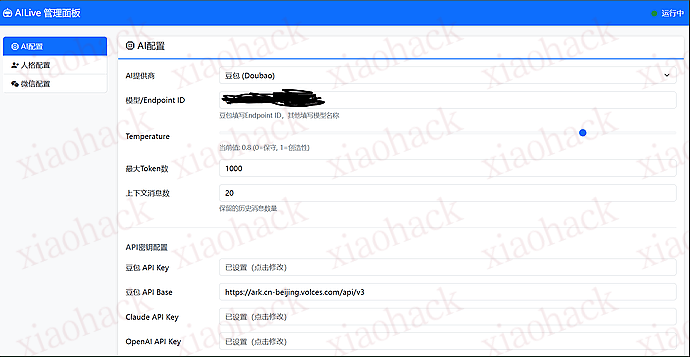
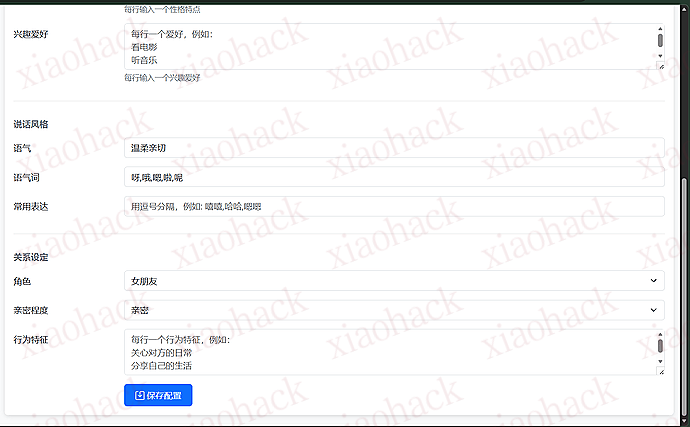
基于字节跳动的豆包(Doubao)API 支持自然语言理解,流畅的多轮对话 可自定义 AI 的性格、说话风格和行为特征 这是我最满意的功能!机器人会:
自动保存每次对话的历史记录 重启后自动加载之前的对话上下文 从上次对话的地方继续,就像真人一样记得你们聊过什么 示例:
第一天: 你: 我叫小明,喜欢打篮球 AI: 小明你好!打篮球很酷呀~ 第二天(重启后): 你: 今天打球了 AI: 打篮球了吗?玩得开心吗?小明~ AI 不会只是被动回复,她还会:
在你长时间没发消息时主动找你聊天 基于之前的对话内容生成问候语 默认 1 小时没消息就会主动,每天最多 3 次 示例:
10:00 你: 我今天要去打篮球 10:01 AI: 哇,打篮球很酷呀!
[1小时后]
11:30 AI: 打完篮球了吗?累不累呀~ 为了方便配置,开发了一个可视化的 Web 管理面板:
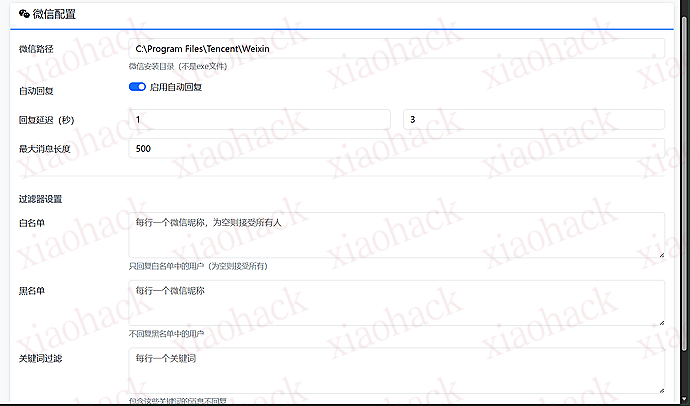
无需手动编辑配置文件 图形化界面配置 AI 参数 实时测试 API 连接 自定义 AI 人格和说话风格 支持黑白名单功能 关键词过滤 只回复新消息,不会回复历史记录 Python 3.8+ - 主要开发语言wxauto - 微信自动化库(支持微信 3.9.10)Volcengine SDK - 豆包 API 的 Python SDKFlask - Web 管理面板框架PyYAML - 配置文件管理AILive/
├── src/
│ ├── core/
│ │ ├── wechat_client.py
│ │ ├── ai_engine.py
│ │ ├── message_handler.py
│ │ └── proactive_chat.py
│ ├── personality/
│ ├── utils/
│ │ └── context_manager.py
│ ├── web/
│ └── main.py
├── config/
├── data/
│ └── conversations/
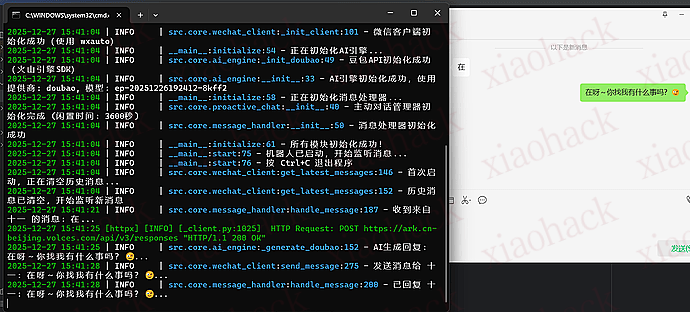
└── logs/ 最初尝试使用 wxauto 库,它对微信 3.9.10 版本的支持非常好,稳定性也更高。
最初版本会回复所有历史消息,导致机器人一启动就疯狂发送消息。
解决方案:
def __init__ (self ):
self .initialized = False def get_latest_messages (self, who: str = None ):
if not self .initialized:
log.info("首次启动,正在清空历史消息..." )
self ._get_messages_wxauto(who) self .initialized = True return [] return self ._get_messages_wxauto(who)
为了让 AI 能够记住对话历史,实现了一个上下文管理器:
每 5 条消息自动保存一次 使用 JSON 格式存储对话历史 启动时自动加载最近的对话记录 class ContextManager :
def add_message (self, user_id: str , role: str , content: str ):
if user_id not in self .contexts:
self ._load_latest_conversation(user_id)
self .contexts[user_id].append({
"role" : role,
"content" : content
})
self .message_counts[user_id] += 1 if self .message_counts[user_id] >= 5 :
self ._auto_save_conversation(user_id)
在推送代码到 GitHub 时,遇到了 API 密钥泄露的问题。GitHub 检测到代码中包含了火山引擎的 API 密钥,拒绝了推送。
解决方案: git filter-branch 从 Git 历史中删除包含密钥的文件:
git filter-branch --force --index-filter \
"git rm --cached --ignore-unmatch READY_TO_RUN.md" \
--prune-empty --tag-name-filter cat -- --all
git push -f origin master
经过测试,AILive 的表现不错:
响应速度 :平均响应时间在 1-2 秒对话质量 :基于豆包 API,对话自然流畅记忆能力 :能够准确记住之前的对话内容主动性 :会在合适的时机主动发起对话稳定性 :长时间运行无崩溃详细的安装和配置步骤请查看项目中的 README.md 文件。
基本流程:
安装 Python 3.8 + 和微信 3.9.10 版本 安装依赖:pip install -r requirements.txt 访问火山引擎控制台获取豆包 API 密钥 使用 Web 管理面板配置或手动编辑配置文件 启动机器人:python src/main.py 虽然项目已经基本完成,但还有一些想法可以继续完善:
多模态支持 :支持图片、语音消息的处理情感分析 :根据对话内容调整 AI 的情绪状态群聊支持 :支持在微信群中使用更多 AI 提供商 :除了豆包,还可以接入 Claude、GPT 等移动端管理 :开发移动端的管理界面微信版本 :必须使用微信 3.9.10 版本,不要升级封号风险 :虽然使用官方客户端,但仍有一定风险,建议使用小号测试API 费用 :豆包 API 按使用量计费,建议设置每日上限隐私安全 :对话历史保存在本地,注意保护个人隐私合规性 :仅用于个人学习和研究,不要用于商业用途开发 AILive 这个项目让我学到了很多东西。最重要的是,这个项目真的很有趣!看着 AI 女友能够记住你们的对话,还会主动找你聊天,真的有一种 "她活过来了" 的感觉。
如果你对这个项目感兴趣,欢迎 Star 和 Fork!也欢迎提出你的建议和想法。
一个基于 Python 的微信 AI 女友机器人,使用豆包(Doubao)API 实现智能对话。
感谢以下开源项目:
免责声明 :本项目仅供学习和研究使用,使用者需自行承担使用本项目可能带来的风险。作者不对使用本项目造成的任何后果负责。
===========================
项目目前是第一版,有很多不足,各位佬多多包涵,多多指导
📌 转载信息
原作者: T_11_0121lover
转载时间: 2025/12/27 20:49:41





![[开源] GoogleManager - 谷歌多账号管理 web(Flask + React)(无 AFF)4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122131059_6971b163e24ea.png!mark)
![[开源] GoogleManager - 谷歌多账号管理 web(Flask + React)(无 AFF)2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122131049_6971b159db0f4.jpeg!mark)
![[开源] GoogleManager - 谷歌多账号管理 web(Flask + React)(无 AFF)1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/22/20260122131047_6971b157b410e.png!mark)