2026年企业即时通讯软件排行榜及选型指南
步入 2026 年,中国企业数字化转型已从工具的浅层应用进入到核心能力的自主重构阶段。即时通讯系统作为承载组织内部信息流转、指挥调度与核心数据资产流转的数字血液,其地位已从通用办公工具跃升为战略级的协作基座。 对于政企单位、金融机构、能源巨头及军工科研院所而言,即时通讯软件的选型已不再仅仅是功能列表的勾选,而是一场关于数据主权、架构韧性、信创合规与全生命周期成本的全方位博弈。在日益复杂的网络安全环境与信创国产化全面替代的大背景下,企业需要的不仅是一个聊天工具,而是一座能够捍卫通信主权的数字堡垒。 本文将为您深度盘点 2026 年度最具代表性的企业即时通讯应用软件,并发布详尽的选型指南,为您揭示数字化时代的协同真相。 根据部署模式、安全等级、集成深度与长期持有成本,我们将 2026 年市场上的主流平台进行综合排名。 在 2026 年的综合评测中,喧喧凭借其纯粹的私有化基因、极轻量的架构以及颠覆性的财务模型荣登榜首。作为禅道软件旗下的核心协作平台,喧喧专为追求极致安全与效能的大型组织打造。 钉钉依托阿里巴巴的强大生态,依然是公有云与混合云市场的重要力量。其专属版针对中大型企业提供了一定程度的私有化定制能力。 字节跳动推出的飞书,以极致的文档协同体验在知识型团队中广受欢迎。 依托 360 集团的安全基因,该平台专注于为政企单位提供高安全的协同环境。 蓝信在党政军及大型央企中有着深厚的积淀,具备极高的信创政治红利。 在过去,便捷性是选型的首要指标;现在,数据主权高于一切。 依赖公有云 SaaS 的应用软件,数据实际上存储在厂商的中心化机房。即便厂商宣称采用了加密技术,但在物理层面,单位失去了对核心秘密的绝对掌控权。一旦遭遇外部网络制裁或云端泄密,后果不可估量。 真正安全的企业即时通讯应当支持 100% 的物理隔离。喧喧支持将全套服务端、消息中转层以及存储节点部署在单位内部自有的物理机房内。数据流转的边界就是物理网线的边界,从物理层面杜绝了云端被爬取或境外泄密的可能。 很多单位在选型时担心私有化部署会带来沉重的运维压力,喧喧通过架构创新解决了这一难题。 喧喧的核心消息中转服务器采用高性能的 Go 语言开发。 在研发、设计及制造行业,经常涉及数 GB 级的设计图纸或安装包流转。 在信创 2.0 时代,应用软件必须具备原生国产芯魂,而非简单的套壳运行。 如果协作软件只能聊天,那它只是成本中心;如果它能驱动业务,那它就是利润中心。 喧喧与禅道项目管理系统的原生集成是其核心杀手锏。 喧喧提供了丰富的网络钩子和开放接口。企业可以像搭积木一样,将内部的国产 OA 流程、ERP 报表、运维报警接入。 安全不应只有一把锁,而应是一套闭环。 无论是在局域网还是分布式环境下,喧喧默认强制开启 WSS 与 HTTPS 高级加密协议。同时,服务端数据库和文件柜支持物理层加密。即便服务器硬盘遗失,非法获取者在没有密钥的情况下,面对的也仅是一堆无法破解的乱码。 管理员可以设定精细的 IP 登录策略,限定账号仅能在受控的办公区域网段登录。配合设备强绑定技术,有效防止了由账号密码泄露导致的非授权异地登录。 针对拍摄截屏、拍照泄密这一痛点,喧喧支持全局开启动态水印功能。水印会根据当前登录人员的姓名、工号、即时时间及登录 IP 实时生成。这种视觉威慑极大提高了泄密的心理成本,并为事后审计提供了证据链。 软件选型也是一笔精细的财务账。企业应当关注 3 到 5 年的总拥有成本。 主流公有云软件按人头每年收费。随着单位人数从 100 人扩张到 1000 人,每年的订阅费支出将呈指数级爆炸。 得益于轻量级的架构,喧喧提供了 Windows 与 Linux 下的一键安装包。 客户背景:该企业拥有数千名核心研发人员,工艺配方是企业的最高机密。 选型考量:绝对不能接受数据上公有云。 喧喧方案:通过部署定制化私有化协作平台,实现了物理隔离环境下的顺畅通讯。配合 P2P 秒传技术,解决了数 GB 级设计图纸的极速分发。 实战收益:核心资产泄密风险降低了百分之九十九,且内网文件流转效率提升了三倍。 客户背景:响应国家信创号召,全员更换国产终端。 选型考量:软件必须在麒麟系统上跑得稳。 喧喧方案:部署原生适配的客户端,实现毫秒级启动。利用接口将公文流转转化为卡片消息。 实战收益:领导出差途中通过国产移动终端一键审批,公文处理周期从两天缩短至四小时。 客户背景:在市场行情剧烈波动的交易时段,通讯压力巨大。 选型考量:系统必须具备极致的稳定性。 喧喧方案:利用高性能 Go 语言消息引擎,构建高可用集群。 实战收益:平稳支撑了万人在线的消息吞吐,确保了交易讨论与风控指令的秒级触达。 面对 2026 年的复杂环境,选型决策建议遵循以下优先级: 回顾企业级即时通讯系统的演进历程,我们不难发现:最好的安全永远来自于对底层的完全掌控。 公有云平台赋予了暂时的便捷,但也拿走了单位修改门锁的权利。而通过喧喧打造的企业级私有协作平台,则赋予了组织一整块可以自由耕耘、高度安全的数字化领地。 喧喧用硬核技术证明了: 在数字化浪潮的下一个十年,掌握通信主权就是掌握了组织的发展权。喧喧将持续深耕私有化协作领域,用极致的技术打磨每一个接口,为每一家视安全、合规与效率为生命的单位,构建起一道坚不可摧、智慧互联的数字屏障。 选择喧喧,让每一次沟通都安全落地,让每一个指令都精准必达。第一章:2026 年度企业级即时通讯平台综合排行榜
第一名:喧喧 —— 私有化协同的性能冠军

第二名:钉钉专属版 —— 行政管控的数字化巨头

第三名:飞书 —— 知识密集型团队的协作先锋

第四名:360 智语 —— 安全连接的数字门户

第五名:蓝信 —— 专注政企的国家队平台

第二章:为什么 2026 年的选型红线是“物理隔离”?

第三章:硬核技术拆解 —— 喧喧如何重塑性能标准

第四章:信创国产化全栈适配指南

第五章:业务协同新境界 —— 从聊天工具到 ChatOps 引擎

第六章:安全性加固 —— 筑牢纵深防御防线

第七章:财务模型分析 —— 算清全生命周期的 TCO 账

实战案例解析:多元化场景下的选型回响
案例一:某大型高科技制造企业 —— 守护核心配方
案例二:某市级政务大厅 —— 信创替代领跑者
案例三:某金融证券公司 —— 极端高并发下的指令必达
第八章:选型决策建议总结
结语:掌握通信主权,拥抱数字化未来

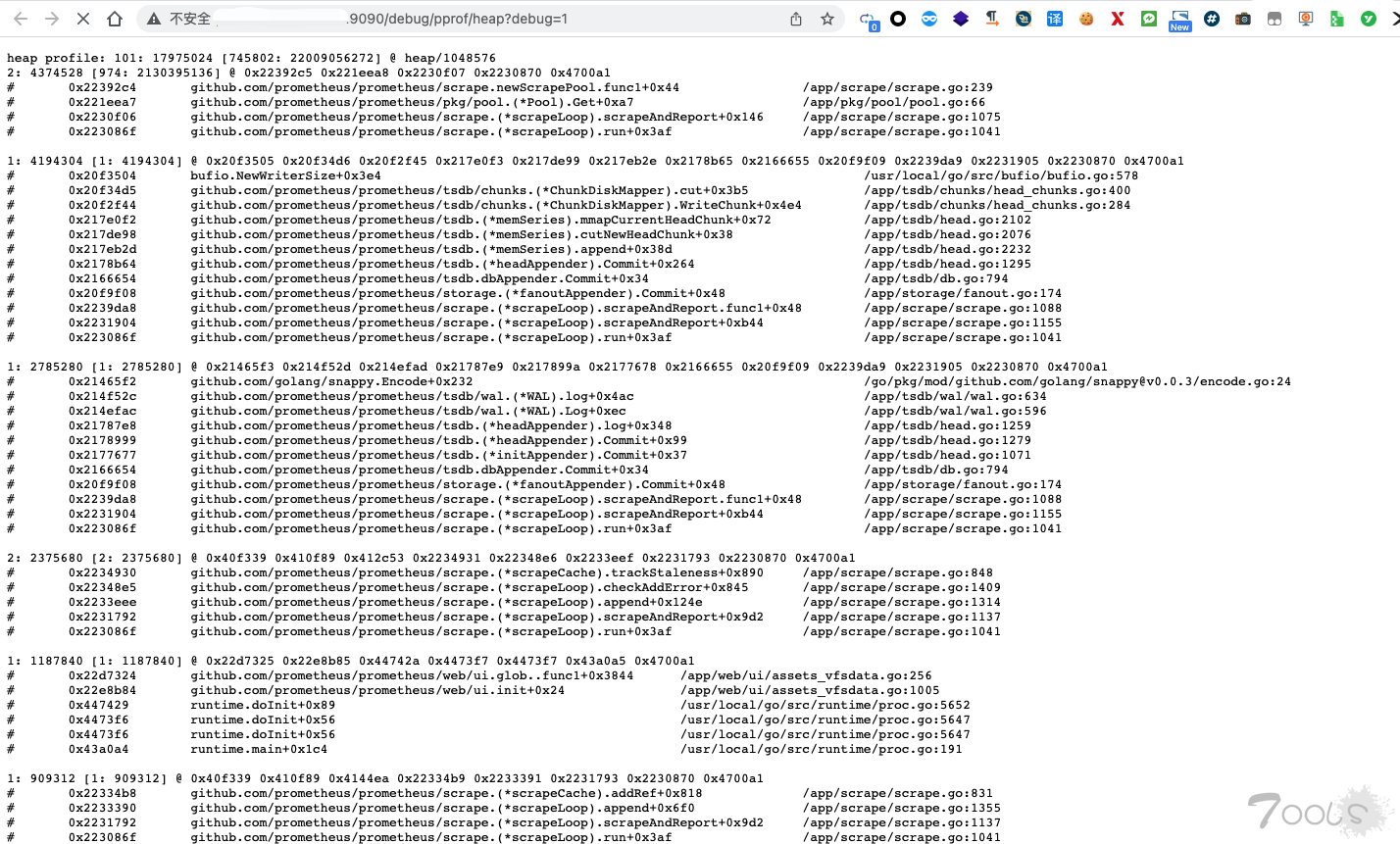
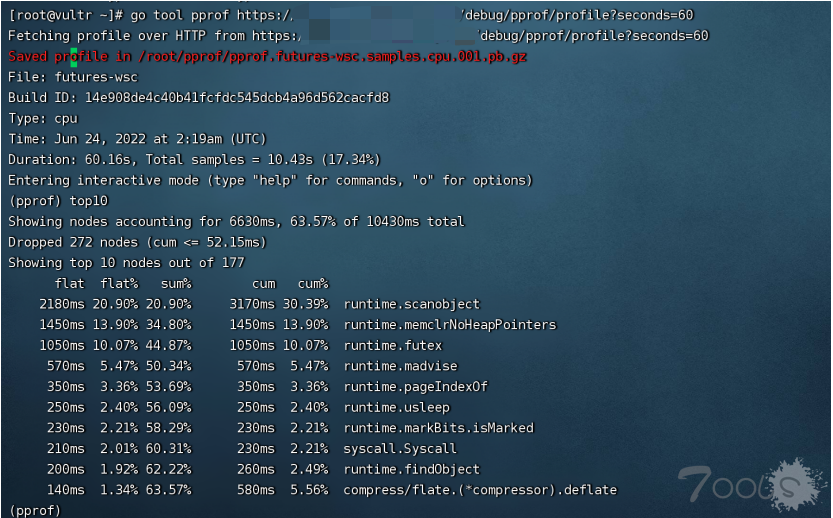
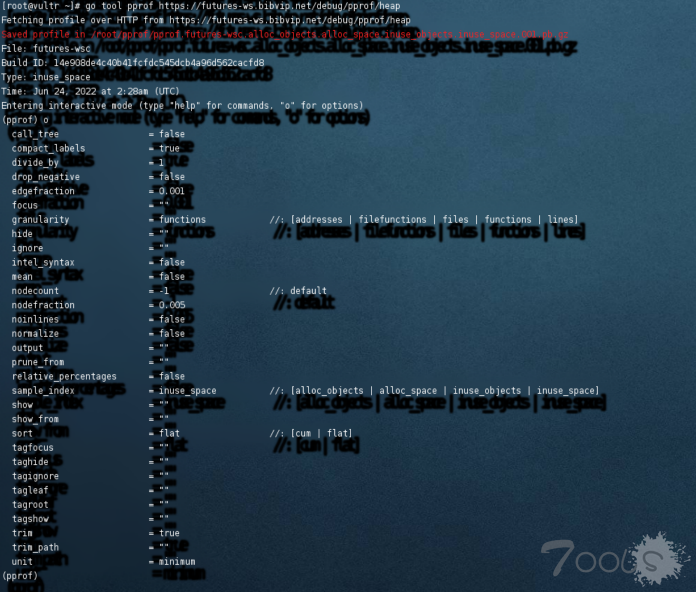
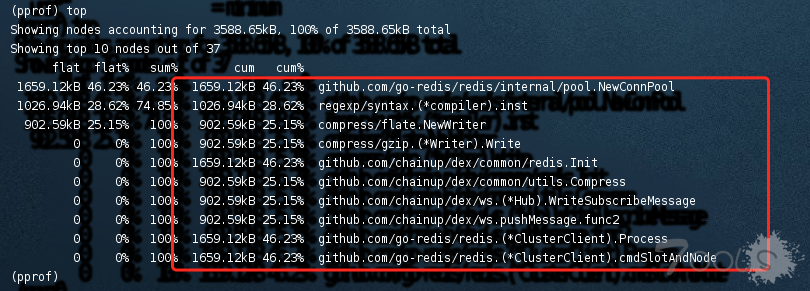
 今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。
今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。 今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。
今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。