今天 GEMINI 网页版本长度 6 万左右就报限制.有没同款的?
之前可以搞几十万的..官方的网页版本来的.
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
之前可以搞几十万的..官方的网页版本来的.
目前一键注册的用户头像存的是第三方 Google 或 Github 的头像 url,这会导致正常访问无法直接显示出 Google 的头像,所以做了一个迁移计划,在今天的合适实际会执行自动迁移,若迁移的头像出现问题可及时和我反馈,迁移前我会记录原头像 url 避免出现错误无法回退。
另外一些优化更新:

各位更新有问题可及时反馈
我这几个月主力一直用 DuckDuckGo,备用是 Google。
最近感觉 DuckDuckGo 太慢了,速度和 Google 差距有点大了。
想问问大家现在主力都在用什么搜索引擎 :D
 这个不适用 yu 于 tun 模式啊
这个不适用 yu 于 tun 模式啊所以,基于上面这两个点认识,以发展的眼光来看问题,我觉得 ChatGPT 这类的 AI 可以成为一个小助理,他的确可以干掉那些初级的脑力工作者,但是,还干不掉专业的人士,这个我估计未来也很难,不过,这也很帅了,因为大量普通的工作的确也很让人费时间和精力,但是有个前提条件——就是ChatGPT所产生的内容必需是真实可靠的,没有这个前提条件的话,那就什么用也没有了。 今天,我想从另外一个角度来谈谈 ChatGPT,尤其是我在Youtube上看完了微软的发布会《Introducing your copilot for the web: AI-powered Bing and Microsoft Edge 》,才真正意识到Google 的市值为什么会掉了1000亿美元,是的,谷歌的搜索引擎的霸主位置受到了前所未有的挑战…… 我们先来分析一下搜索引擎解决了什么样的用户问题,在我看来搜索引擎解决了如下的问题: 基本上就是上面这几个,搜索引擎在上面这几件事上作的很好,但是,还是有一些东西搜索引擎做的并不好,如: 好了,我们知道,ChatGPT 这类的技术主要是用来根据用户的需求来按一定的套路来“生成内容”的,只是其中的内容并不怎么可靠,那么,如果把搜索引擎里靠谱的内容交给 ChatGPT 呢?那么,这会是一个多么强大的搜索引擎啊,完全就是下一代的搜索引擎,上面的那些问题完全都可以解决了: 一旦 ChatGPT 利用上了搜索引擎内容准确和靠谱的优势,那么,ChatGPT 的能力就完全被释放出来了,所以,带 ChatGPT 的搜索引擎,就是真正的“如虎添翼”! 因此,微软的 Bing + ChatGPT,成为了 Google 有史以来最大的挑战者,我感觉——所有跟信息或是文字处理相关的软件应用和服务,都会因为 ChatGPT 而且全部重新洗一次牌的,这应该会是新一轮的技术革命……Copilot 一定会成为下一代软件和应用的标配! 两个月前,我试着想用 ChatGPT 帮我写篇文章《eBPF 介绍》,结果错误百出,导致我又要从头改一遍,从那天我觉得 ChatGPT 生成的内容完全不靠谱,所以,从那天开始我说我不会再用 ChatGPT 来写文章(这篇文章不是由 ChatGPT 生成),因为,在试过一段时间后,我对 ChatGTP 有基于如下的认识:
两个月前,我试着想用 ChatGPT 帮我写篇文章《eBPF 介绍》,结果错误百出,导致我又要从头改一遍,从那天我觉得 ChatGPT 生成的内容完全不靠谱,所以,从那天开始我说我不会再用 ChatGPT 来写文章(这篇文章不是由 ChatGPT 生成),因为,在试过一段时间后,我对 ChatGTP 有基于如下的认识:

Google 正式发布 Universal Commerce Protocol(UCP,通用商业协议),这是一项开放标准,旨在支持“代理式商业”,也就是由 AI 驱动的购物代理可完成从商品发现、下单结算到售后管理的全流程任务。UCP 同时兼顾零售商与消费者需求,在整个购物旅程中始终以“客户关系”为核心,从最初的商品发现到购买决策乃至购买之后。 UCP 在美国全国零售联合会(National Retail Federation,NRF)年度大会上正式公布。该协议为 AI 代理与商业生态中的后台系统建立了一种安全、标准化的连接方式。企业可以通过 UCP 对外暴露自身能力,并在此基础上扩展诸如折扣等功能;AI 代理则可以通过企业资料动态发现可用服务与支付选项。 在支付设计上,UCP 将支付工具与支付处理方进行解耦,支持多个支付服务提供商。通信层面,协议支持标准 API、Agent2Agent 以及 Model Context Protocol 绑定。Google 还提供了示例实现,包括一个 Python 服务器以及包含商品数据的软件开发工具包,用于展示 AI 代理如何发现商业能力并执行结算流程。 American Express 在 LinkedIn 上发文,强调了该协议在简化商业流程方面的潜力: Google 推出的 Universal Commerce Protocol(UCP)是一项面向代理式商业的全新开放标准,想减少支离破碎的购物体验,帮零售商与消费者建立更顺畅的连接。UCP 很快将为 Google 搜索的 AI Mode 以及 Gemini 应用中的全新结算体验提供支持。像这样的开放标准,对于构建更安全、更可信的商业体系至关重要。 正如 Google 在一篇深入解析的技术博客中所介绍的,UCP 定义了一系列核心商业能力,包括商品发现、购物车管理、结算流程以及售后工作流。AI 代理可通过查询企业资料来识别可用服务并协商支持的功能,从而减少定制化集成的需求。这种方式既能让企业继续掌控价格、库存和履约逻辑,又能让 AI 代理实现更高程度的自主运行。 UCP 高层架构示意图 在安全架构方面,UCP 通过凭证提供方对支付和身份信息进行令牌化处理,而具体的交易处理则由支付服务提供商完成。这种分离设计使 AI 代理在无需接触原始支付信息或个人数据的情况下即可完成交易。 此外,UCP 具备传输层无关性,既支持标准 API 交互,也支持面向代理的绑定形式,适用于对话式界面、AI 助手和自动化工作流。目前,UCP 的早期实现已出现在 AI 驱动的搜索与助理平台中,符合条件的零售商可以在不跳转至外部网站的情况下,直接向用户提供结算体验。 基于 AI 代理的购买流程演示 UCP 由 Google 与 Shopify、Etsy、Wayfair、Target、Walmart 共同开发,并获得了来自商业生态中 20 多家合作伙伴的支持与背书,其中包括 Adyen、American Express、Best Buy、Flipkart、Macy’s、Mastercard、Stripe、The Home Depot、Visa 以及 Zalando。 在未来规划方面,UCP 的路线图着眼于构建一个覆盖全球、超越单笔交易的统一商业标准。相关计划包括多商品结算、购物车管理、会员与忠诚度计划、订单后流程,以及个性化的交叉销售与追加销售能力,同时继续确保核心商业逻辑掌握在企业自身手中。 目前,UCP 的早期版本已支持美国部分符合条件的零售商在 Google 产品界面内直接完成结算。接下来,该协议还将拓展至印度、印度尼西亚以及拉丁美洲等市场。Google 与合作伙伴也正在广泛征求反馈,以不断完善这一协议,共同塑造可互操作、由 AI 驱动的未来商业形态。 原文链接: https://www.infoq.com/news/2026/01/google-agentic-commerce-ucp/ 相关报道: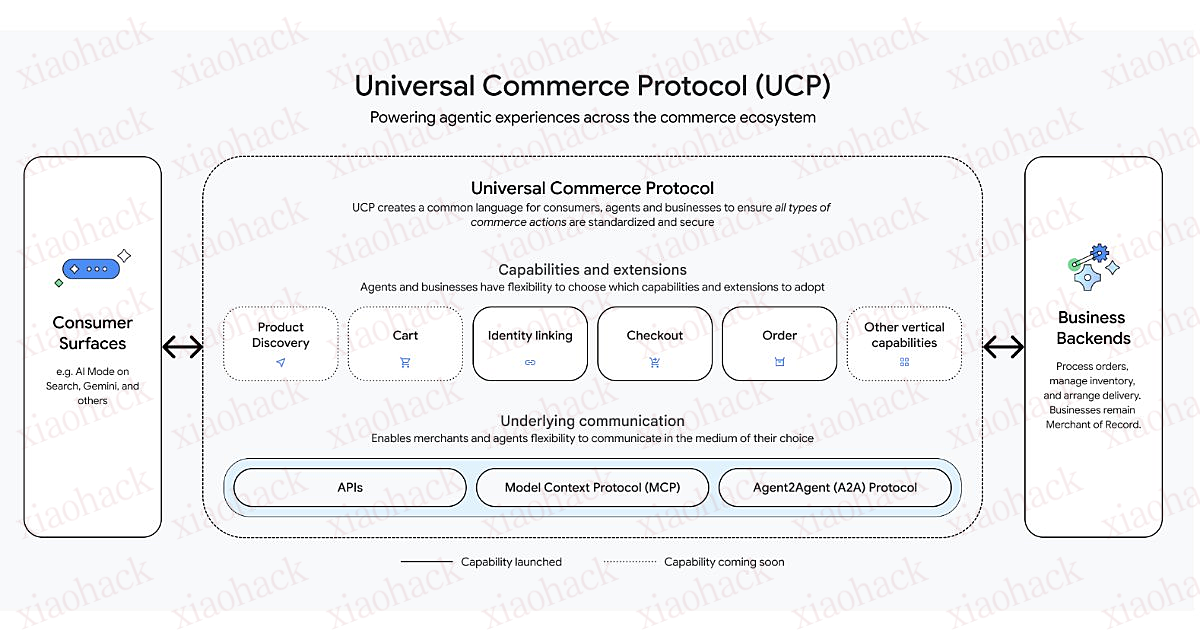

实际上,不应该只在反重力上写代码
这里可选的,使用 Stitch 进行风格设计,但是 Stitch 同一个画布的多次对话,其实不完全遵守指令,所以只能进行 "风格" 设计,确定什么提示词能稳定产出什么风格,在这一步没办法明确你的 UI 具体布局,除非你已经有非常详细的腹稿,可以让它一次性生成完全部页面。我的开发习惯是,先有一个灵感,然后在开发迭代中明确 UI 和功能到底如何实现.
采用 sdd+tdd 规范
然后开始根据文档写原型.
它会审查结果,本地运行看效果,合并分支,再设计,规划,分配任务进行迭代.
这样的情况下,对我来说反重力的额度是够用的,而且 jules 一次性可以执行很多任务,不会像反重力这样频繁的中断,或者偷懒.
我在反重力里面,大部分时间使用 opus.
notebook, 则是在讨论出蓝图后,让它生成一些问答或者思维导图,博客,来加深印象.
但是 notebook 的智力水平很低,只能用来 "辅助学习", 不能用来深度思考.
这一切,只需要你拥有一个谷歌学生号,充分利用套餐内容,以及谷歌生态内各个产品的优势.
而且也解放了自己的时间,真正做到了在关键节点进行审查,设计,而无需处理迭代过程中琐碎的审批和中断.
以下步骤强烈建议在windows虚拟机中配置
且保持nessus默认安装目录
先使用Nessus-x64.msi安装
安装好后浏览器打开https://127.0.0.1:8834
按照常规安装方法先走完步骤,进入到正常web页面
这里不再赘述步骤(百度上一堆)
然后回到文件夹下管理员执行crack_mht.bat
过程较长,等待完成后
再次打开web界面https://127.0.0.1:8834
登陆进去后右上角会有一长串英文提示
意思是插件正在编译
等待编译完成就好了
此次编译插件无需再限制cpu
耐心等待即可
右上角有个圆圈,鼠标悬停可以查看进度
编译完成后如图所示
前台转不出来请换google浏览器打开
edge浏览器就是一直转圈圈不知道为啥
下载链接:https://pan.quark.cn/s/a8aa4b23cda2
解压密码:mht
生活号
https://github.com/cqkenuo/appinfoscanner
https://www.qcc.com/
https://www.tianyancha.com/
https://aiqicha.baidu.com/
google.com \ baidu.com \ bing.cn收集目标子域名信息
https://x.threatbook.cn/
https://github.com/shmilylty/OneForAll
Layer子域名挖掘机
https://github.com/lijiejie/subDomainsBrute
https://github.com/Jewel591/SubDomainFinder
https://github.com/aboul3la/Sublist3r
https://github.com/knownsec/ksubdomain
https://github.com/Threezh1/JSFinder
google.com \ baidu.com \ bing.cn
http://tool.chinaz.com/dns
https://www.dnsdb.io
https://fofa.so/
https://www.zoomeye.org/
https://www.shodan.io/
https://censys.io/
DNSenum
nslookup
https://www.isc.org/download/
https://code.google.com/archive/p/dnsmap/
https://github.com/0x727/ShuiZe_0x727对上面收集到的域名进行识别
https://github.com/EdgeSecurityTeam/EHole
https://github.com/al0ne/Vxscan
https://github.com/EASY233/Finger
https://github.com/TideSec/TideFinger
https://github.com/urbanadventurer/WhatWeb
https://gobies.org/
https://www.yunsee.cn/
https://github.com/s7ckTeam/Glass
https://github.com/TideSec/TideFinger
https://scan.dyboy.cn/web/
https://fp.shuziguanxing.com/#/
https://builtwith.com/zh/
https://github.com/FortyNorthSecurity/EyeWitness
https://www.yunsee.cn/
https://www.wappalyzer.com/
https://github.com/0x727/ObserverWard
https://github.com/0x727/ShuiZe_0x727
https://github.com/P1-Team/AlliN
https://github.com/dr0op/bufferfly根据域名收集对应的IP
如果遇到CDN可以考虑以下方法:
查看dns解析记录
https://dnsdb.io/zh-cn/ ###DNS查询
https://x.threatbook.cn/ ###微步在线
http://toolbar.netcraft.com/site_report?url= ###在线域名信息查询
http://viewdns.info/ ###DNS、IP等查询
https://tools.ipip.net/cdn.php ###CDN查询IP找子域名的IP
- xxxx.com.cn type:A
子域名扫描器
网络空间搜索引擎
- shodan
- fofa
- zoomeye
- 全球鹰
- quake
网站漏洞
- phpinfo
- xss
- ssrf
如果没有CDN就直接扫
nmap
masscan
https://github.com/EdgeSecurityTeam/Eeyes
https://github.com/shadow1ng/fscan
https://github.com/Adminisme/ServerScan
https://github.com/EdgeSecurityTeam/EHolehttps://github.com/maurosoria/dirsearch
dirbuster
gobuster
dirb
https://github.com/xmendez/wfuzz
https://github.com/foryujian/yjdirscan
https://github.com/H4ckForJob/dirmapnessus
wavs
https://github.com/H4ckForJob/dirmap
https://github.com/chaitin/xray
https://github.com/wgpsec/DBJ
https://github.com/sullo/nikto
https://github.com/zhzyker/vulmap/
https://github.com/projectdiscovery/nuclei
https://github.com/greenbone/openvas-scanner
https://github.com/wpscanteam/wpscan
http://www.encoreconsulting.com/3-10-AppScan.html
https://github.com/78778443/QingScanhttps://github.com/projectdiscovery/nuclei/blob/master/README_CN.md
https://github.com/smicallef/spiderfoothttps://github.com/Threezh1/JSFinder
https://github.com/GerbenJavado/LinkFinder
https://github.com/rtcatc/Packer-Fuzzer (webpack)
https://github.com/momosecurity/FindSomething