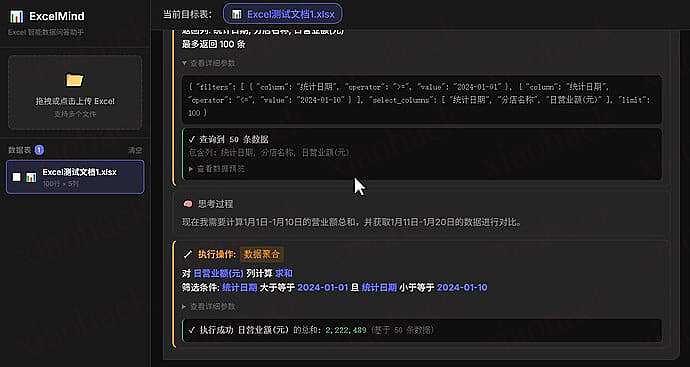
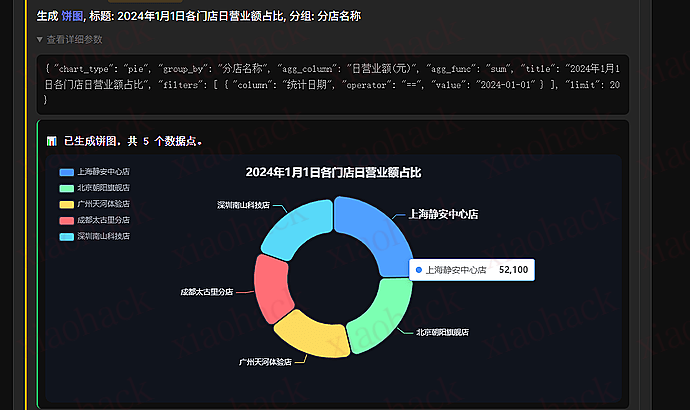
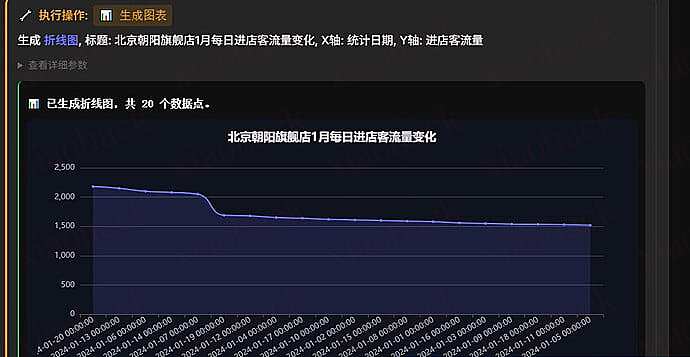
前言
在过去一年里,我们见证了LLM (大语言模型) 爆发式的增长,LLM的能力有了质的飞跃,也颠覆了所有开发者对“软件能力边界”的认知。只需要几行代码,调用一次LLM api接口,模型就能帮你写一段看起来像模像样的代码、总结一份结构清晰的文档或者回答一些“看起来很聪明”的问题。但当你试图想构建一个稳定、可复用、复杂的生产级别的AI应用时就会遇到
Prompt 失控
一开始只是几行提示词,后来变成了几百行规则说明。你不断往 Prompt 里“打补丁”,但模型依然会在某个边缘场景下给你一个完全不可用的结果。
结果不可预测(Non-deterministic)
LLM 是概率模型,而业务系统追求的是确定性。
“大概率对”在 Demo 阶段可以接受,但在审批、风控、数据查询这类场景中,等同于事故隐患。
AI应用开发周期长,不能复用
新做一个 AI 应用,往往要重新写一套流程代码,反复的在从零开始造轮子。
调试困难
当用户反馈“刚刚还能用,现在不行了”,你却无法复现。
你不知道当时:
- Prompt 最终渲染成了什么
- 模型具体返回了哪一步异常
- 是模型波动,还是上下游数据变化
这些问题叠加在一起,会把一个原本看起来“很有前途”的 AI 项目,迅速拖入不可维护的深渊。这也是AIWorks平台诞生的初衷,AIWorks不仅仅是一个简单的低代码开发工具,它是一个确定性的编排系统。本文将从工程师的角度带你了解一下AIWorks平台中workflow的设计与实现。
核心设计哲学
我们将Workflow引擎的设计,收敛为四个核心原则
DAG为骨架
复杂的业务逻辑,如果不加整理,往往是一团乱麻的代码(Spaghetti Code)。我们将业务逻辑抽象为数学上的 DAG(有向无环图)。
- Node(节点):代表一个原子的计算单元。它可能是一次 LLM 的推理,也可以是一段 Python 代码的执行,或者是一次 HTTP 请求。
- Edge(边):代表数据的流向和执行的顺序。
这种设计使得业务逻辑可视化。前端拖拽生成 JSON,后端解析执行 JSON。所见即所得,对非技术人员来说非常的友好。
状态机为灵魂
很多工作流系统,本质上只是任务编排器,节点按顺序执行,执行完就结束。但AI Workflow的行为模式具备以下特征:
- 多轮交互
- 上下文强依赖
- 当前行为取决于“之前发生了什么”
这就要求AI Workflow不是一个简单的线性流程,而是一个状态不断迁移的系统。因此,在 AIWorks 中,我们将工作流视为一个状态机(State Machine),每一次节点执行都会引起 Graph State 的变化,下一步的走向,取决于当前的状态。
一切皆节点
在AIWorks的workflow设计中,节点作为最小执行单元,无论是调用LLM,还是执行一段简单的Python代码,还是调用高德地图API,它们都被抽象成节点。所有节点都继承自同一个基类 BaseNode,Workflow执行引擎不关心节点“做了什么”,只关心节点是否成功,产出了什么结果。这样可以极大的提高系统的扩展能力,如果需要新增一种新能力(比如给飞书发消息),那么你只需要继承BaseNode,然后实现其中对应的方法就能无缝接入到现有的系统中,享受工作流引擎提供的所有能力(重试、 日志、变量注入等)。
可观测性优先
不是“出问题了再加日志”,而是“天生可被回放”。为了让AI Workflow系统不再是“黑盒”,我们将可观测性作为核心设计原则之一。
引擎会自动记录工作流中每一个节点(Node)的完整执行快照,包括:
- 输入(Inputs):节点接收到的变量和参数。
- 输出(Outputs):节点运行后的产出结果。
- 状态变化(Status Changes):从开始、运行中到结束的每一刻。
这种精细粒度的记录,使得开发者可以在工作流执行完成后,像看“即时回放”一样,逐帧查看执行过程。一旦出现问题,通过回溯输入输出,就能迅速定位是哪个环节的 Prompt 写得不对,还是哪个 Tool 调用参数传错了,真正做到“有迹可查”。
Workflow引擎架构解析
整体分层
AIWorks 工作流引擎采用了经典的分层架构:
应用层(Application Layer)
↓
图引擎层(Graph Engine Layer)
↓
节点层(Node System Layer)
↓
基础设施层(Infrastructure Layer)
每一层的职责都很明确:
- 应用层:提供 API 接口,处理用户请求
- 图引擎层:负责工作流的编排和执行
- 节点层:实现各种能力单元(LLM、工具、知识检索等)
- 基础设施层:提供底层服务(模型调用、向量检索、工具运行时等)
这样分层的好处是关注点分离。比如你要换个 LLM 提供商,只需要改基础设施层;要加个新节点类型,只需要在节点层扩展,不会影响引擎核心逻辑。
Graph Engine:整个系统的“心脏”
GraphEngine是 AIWorks 工作流引擎的核心调度器,它的职责可以概括为三件事:
- 解析前端传入的工作流JSON
- 将其编译为可执行的 Graph App
- 驱动整个执行生命周期(初始化状态、执行Graph、输出结果并保存状态)
1. 静态图构建:业务逻辑的“蓝图”
前端通过拖拽或配置生成的流程,本质上是一份 JSON 描述的 DAG。在 AIWorks中,我们并不会直接将这份 JSON 交给执行引擎,而是定义类Graph对其进行装载和校验,并解析JSON中的节点(Node)和边(Edge)。GraphEngine使用LangGraph作为工作流的执行引擎,GraphEngine将 Graph 对象转换为 LangGraph 提供的 StateGraph,并将Graph中的节点(Node)和边(Edge)动态设置到StateGraph中。
简化后的核心逻辑如下:
# 伪代码示意
class GraphEngine:
def __init__(self, ..., graph: Graph):
self._graph = graph
...
def _build_graph_app(self, state_context):
workflow = StateGraph(GraphRuntimeState)
node_id_config_mapping = self._graph.node_id_config_mapping
# 1. 动态添加节点
for node_id, node_data in node_config_mapping.items():
wrapper_node = self._create_command_node(node_id, node_data, state_context)
workflow.add_node(node_id, wrapper_node)
# 2. 动态添加边
for edge in edges:
workflow.add_edge(edge.source, edge.target)
return workflow.compile()
StateGraph设置完成后,会调用compile()进行编译,在这个阶段会对整个图进行结构校验,包括是否存在环、是否有孤立节点或不可达节点和节点和边的引用是否完整等。
2. 异步调度与事件流
GraphEngine的执行核心并非简单的循环,而是基于 LangGraph 提供的 astream 接口实现的异步事件流处理。事件类型包括FLOW_START、NODE_START、NODE_END、FLOW_END。
# 伪代码示意
async def _run_workflow(self, inputs: GraphGenerateEntity, enable_run_log: bool):
graph_app = self._build_graph_app(state_context)
state = self._init_graph_state(inputs)
# ... 初始化状态 ...
yield GraphEvent(event=GraphEventEnum.FLOW_START, run_id=run_id)
# 订阅 LangGraph 的流式输出,关注 "custom" (自定义事件) 和 "tasks" (节点状态)
event_stream = graph_app.astream(state, stream_mode=["custom", "tasks"])
async for event_tuple in event_stream:
stream_mode, event_message = event_tuple
# 将 LangGraph 的内部事件转换为 aiworks 的标准 GraphEvent
if stream_mode == "tasks":
# 处理节点启动/结束
yield GraphEvent(event=GraphEventEnum.NODE_START, ...)
else:
# 透传自定义事件 (如 LLM Token)
yield GraphEvent(**event_message)
yield GraphEvent(event=GraphEventEnum.FLOW_END, ...)
3. 状态持久化
在工作流执行结束后,引擎会自动进行“快照存档”。这种设计不仅仅是保存 Log,它保存了完整的运行时状态(GraphRuntimeState)。这意味着:
- 可溯源:你可以随时打开一个历史运行记录,看到当时图的结构(哪怕现在的图已经改了)以及每个节点的输入输出。
- 可恢复(未来及展望):这种结构为未来的“断点续跑”和“人工介入”功能打下了数据基础。
状态管理(State):可观测的执行过程
工作流执行过程中,最重要的就是状态管理。我们设计了三层状态结构:
1. 变量池(VariablePool)
这是整个工作流的"记忆",存储所有变量:
class VariablePool(BaseModel):
user_inputs: dict # 用户输入的变量
system_inputs: dict # 系统变量(如 conversation_id)
pool: dict # 节点执行过程中产生的变量
节点执行时,可以从pool中读取前置节点的输出,也可以把自己的输出写入pool,供后续节点使用。
2. 节点状态(NodeState)
记录每个节点的执行状态:
class NodeState(BaseModel):
id: str
status: NodeStatus # pending/running/succeeded/failed
inputs: dict # 节点输入
result: dict # 节点输出
start_at: datetime
finished_at: datetime
error_msg: str
这里有个细节:我们会完整记录节点的输入和输出。这样做的好处是:
- 执行回放:根据
inputs 可以重新执行节点,复现问题 - 调试:可以清楚看到每个节点的输入输出,快速定位问题
- 性能分析:通过
start_at 和 finished_at 计算耗时,找出瓶颈
3. 工作流运行时状态(GraphRuntimeState)
整个工作流的全局状态:
classGraphRuntimeState(BaseModel):
query:str
variable_pool: VariablePool
node_state_mapping: dict[str, NodeState] # 所有节点状态
routes: dict[str, list[str]] # 实际执行路径
status: GraphStatus # running/succeeded/failed
output:str|dict # 最终输出
执行完成后,我们会把GraphRuntimeState 序列化成 JSON,存储到数据库。这样就有了完整的执行记录,方便后续分析和优化。
节点系统:可扩展的能力单元
如果说图引擎是工作流的"大脑",那节点系统就是"四肢"——具体干活的地方。
1. 节点抽象:模板方法模式的实践
所有节点都继承自BaseNode,它定义了节点的生命周期:
class BaseNode:
def __init__(self, node_id, node_data, user_id, tenant_id, graph):
self.node_id = node_id
self.node_data = node_data
self.init_node()
def init_node(self):
config = self.resolve_node_data()
self.init_node_config(config)
@abstractmethod
def _run(self, state) -> NodeResult:
raise NotImplementedError
async def run(self, state):
return await self._run(state)
这是典型的模板方法模式:
- init_node() 定义了初始化流程
- 子类只需要实现 init_node_config() 和 _run() 两个方法
这样做的好处是统一了节点的初始化流程,子类只需要关注自己的核心逻辑。
2. 节点概览:工作流的能力单元
Start 节点:工作流的入口节点,标识整个流程的起点,每个工作流都必须有一个 Start 节点,它负责接收用户的输入变量,并将它们传递给后续节点。
LLM 节点:调用大语言模型进行文本生成、对话、摘要等任务。这是使用最频繁的节点,支持友好的提示词管理、记忆管理、多种LLM提供商等。
Knowledge Retrieval 节点:从向量数据库中检索相关知识文档。典型应用场景是 RAG(检索增强生成),先检索相关知识,再传给 LLM 节点进行回答。
Tool 节点:工具节点是与外部环境交互的接口,支持内置工具、API工具和自定义工具。
IF-Else 节点:根据条件动态选择执行路径, 是实现复杂业务逻辑的关键。支持:
- 多种比较操作符(等于、包含、为空等)
- AND / OR 逻辑组合
- 多分支(IF / ELIF / ELSE)
- 基于变量池中的任意变量做判断
Code 节点:执行用户自定义的代码逻辑。适合处理复杂的数据转换、计算逻辑等 LLM 不擅长的任务。
HTTP 节点:发起 HTTP 请求,调用外部 API。
Answer 节点:格式化最终输出,返回给用户。
3. 扩展新节点:三步走
当我们需要新增节点类型时, 流程很简单:
1)定义配置类:继承类BaseNodeConfig
lass MyNodeConfig(BaseNodeConfig):
param1: str
param2: int
2)实现节点类:继承BaseNode
class MyNode(BaseNode):
_node_type = NodeType.MY_NODE
def init_node_config(self, valid_config):
self.node_config = MyNodeConfig(**valid_config)
def _run(self, state):
# 实现具体逻辑
return NodeResult(result={...})
3)注册节点类型:在 NodeType 枚举和工厂方法中注册
这个设计让节点系统具备了很强的扩展性,每个节点并遵守单一原则,这样就能保证新增节点时效率高,还能保持引擎代码的稳定。
总结
回顾整个工作流引擎的开发过程,最大的感受是:好的架构设计真的能事半功倍。
我们在 AIWorks 中遵循的几个核心理念:
- 分层解耦:图定义、执行引擎、节点实现各自独立
- 抽象优先:基于接口编程,易于扩展
- 可观测性:完整记录执行链路,方便调试和优化
- 异步流式:提升用户体验和系统吞吐
目前这套系统已经在生产环境中稳定运行,支撑了多个企业级应用。当然,还有很多可以优化的地方:
- 可视化调试器:图形化展示执行流程和状态变化
- 分布式执行:支持大规模工作流的分布式调度
- 智能优化:基于历史数据,自动优化节点配置
希望这篇文章能对正在做类似系统的同学有所帮助。如果你有任何问题或建议,欢迎留言交流!