一年前,MCP 还只是一个“把模型连到工具”的开源协议;一年后,它已经冲进了一个很少有协议能抵达的位置:事实标准。
在这场一年狂飙的亲历者之一——MCP 联合创作者、核心维护者 David Soria Parrra 看来,最戏剧性的分水岭发生在四月前后:当 Sam Altman、Satya Nadella、Sundar Pichai 先后公开表态,Microsoft、Google、OpenAI 都将采用 MCP,“大客户”突然从 Cursor、VS Code 扩散到整个行业。
这一年,MCP 从本地 “桌面玩具”,一路演进到远程 server、认证机制、面向企业可用的 OAuth 重构,再到 11 月引入 long-running tasks,把深度研究、甚至 agent-to-agent 交互变成协议的一等公民。David 的总结很直接:“这一年真的非常疯狂。”
这段对谈里,David 也很坦率地复盘了 MCP 这一年的取舍:做对的,是死磕标准 HTTP;踩坑的,是把关键能力做成了‘可选项’,结果客户端大多不实现,双向能力被削掉。
更现实的问题是扩展性:规模一上来,多实例、多 Pod 下同一段交互可能打到不同机器,不得不用 Redis 之类的共享存储来“拼状态”,请求量到百万级就开始吃力:“当规模一上来,这件事一点都不好玩。”“一些公司——比如 Google、Microsoft——他们在用 MCP 的时候,规模已经大到我不能公开具体数字,但可以说是百万级请求。到了这个量级,这就真的成了一个问题。”
以下是播客内容整理,略有删节:
MCP 的一年:从发布到行业事实标准
主持人:要不你先简单讲讲 MCP 的发展情况,以及之前为什么决定把它捐赠给基金会?接下来我们再系统回顾 MCP 这一年的演进,然后再请基金会的其他负责人加入,聊一些更宏观的内容。
David Soria Parrra(MCP Co-creator):如果回到一年前,MCP 刚发布的时候,其实谁都没想到它会在这一年里迎来如此疯狂的增长。
老实说,这一年感觉像过了一个世纪。一开始是在感恩节和圣诞节前后,很多开发者开始自发地用 MCP 搭东西。随后,像 Cursor、VS Code 这样的“大客户”开始出现。
真正的拐点出现在四月左右——当时 Sam Altman、Satya Nadella、Sundar Pichai 等人陆续公开表示,Microsoft、Google、OpenAI 都会采用 MCP。那是一个非常明显的“分水岭”。
与此同时,我们也一直在推进协议本身的演进。
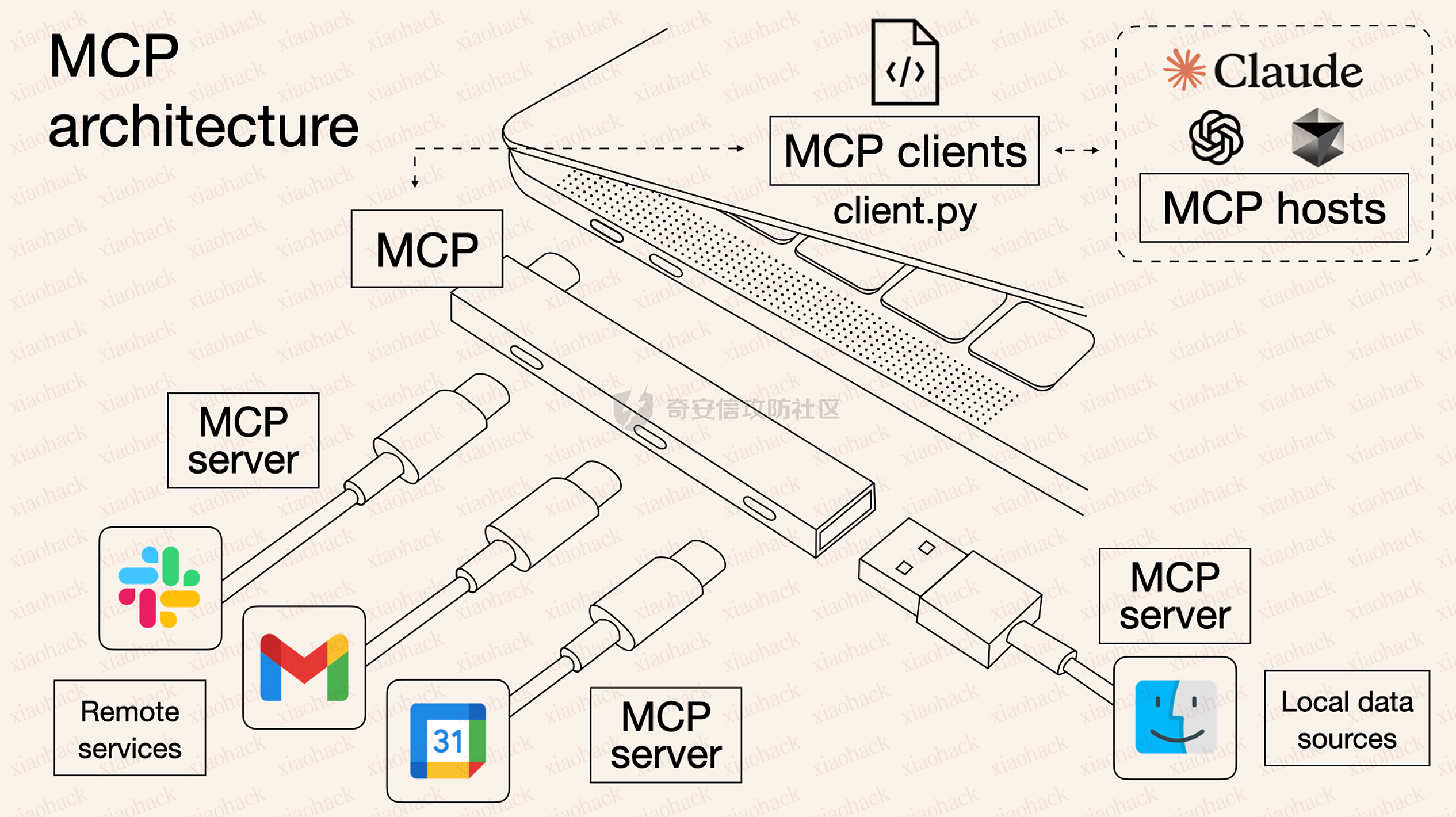
最初,MCP 几乎只支持本地使用:你在桌面上跑一个 MCP server,通过本地 stdio 和客户端通信。但到了今年三月,我们开始推进“远程 MCP server”——也就是如何通过网络连接 MCP,并且第一次引入了认证机制。到了六月,我们又对这套认证方案进行了比较大的修订,尤其是为了让它真正适用于企业场景。
我们非常幸运,在三月到六月这段时间里,有真正做 OAuth 标准的行业专家,直接参与进来,帮我们把一些关键细节“拉正”。我们也在这段时间里大量投入在安全最佳实践上。
到了 11 月底,我们发布了新一轮重要版本,引入了长时间运行任务(long-running tasks)这一关键原语,用来支持深度研究类任务,甚至是 agent-to-agent 的交互。
现在的感觉是:MCP 的基础已经非常扎实了。接下来还有一两个关键原语和可扩展性问题需要解决,然后协议整体会进入一个相对稳定的阶段。
说实话,这一年真的非常疯狂。
主持人:你刚刚提到 agent-to-agent,那是不是也涉及 A2A 协议?在 Agentic AI Foundation 成立时,有没有讨论过把其他协议也纳入进来?
David:老实说,这几乎是必然会发生的讨论。我们当然讨论过市场上其他协议,比如一些支付协议之类的东西。但在决定成立基金会时,我们有两个非常明确的原则:
第一,我们想从小开始。这是 Anthropic 第一次参与开放源代码基金会,一切都是新的。我们希望先在一个相对可控的范围内学习如何把这件事做好,并且和 OpenAI、Block 一起,把基金会的节奏掌控住。
第二,在协议层面,我们非常在意“事实标准(de facto standard)”。目前来看,真正已经具备广泛采用度的协议,只有 MCP。其他协议还没有“走到那一步”。当然,如果未来某个协议发展到那个阶段,并且在功能上是互补的,我们是完全开放的。
在应用层,我们会更灵活;但在协议层,我们不希望一个基金会里同时维护五个做同一件事的通信协议。
主持人:你现在在基金会和 MCP 之间,是不是有点“戴两顶帽子”?
David:确实如此,但我主要精力仍然在 MCP 上。基金会本质上是一个“保护伞”,它最重要的作用是保证项目的中立性。至于基金会预算怎么用、办什么活动,这些相对来说反而是“比较枯燥”的部分。
在 MCP 的技术治理上,其实并没有发生本质变化。我依然是核心维护者,继续推动协议演进。
另外,我也会参与基金会的技术指导委员会(TSC),负责判断:哪些项目适合进入基金会?它们是否被良好维护?是否有真实采用?是否具备长期价值?
我们不希望基金会变成一个“项目垃圾场”。我知道有些基金会最终会落得什么下场。
主持人:这一年 MCP 发布了四次规范更新,节奏非常快。尤其是三月和五月那次,引入了 HTTP Streaming 和认证。要不要给大家系统梳理一下?
David:HTTP Streaming 那次更新非常关键,也是用户呼声最高的一次。我们在 11、12 月就已经意识到:下一步一定是远程 MCP,而远程就绕不开认证。
MCP 的一个特点是:它在每一层都非常“有主见(prescriptive)”。比如,在客户端和服务端互不认识的情况下,认证该怎么做,我们希望只有“一种正确方式”。
三月版本里,我们做了一版认证方案。现在回头看,它“还行”,但确实有问题。说白了,是我对企业认证场景理解不够。MCP 的一个核心优势,是它的社区:当我不懂的时候,会有真正懂的人站出来帮我。
主持人:三月那版认证,主要问题出在哪?
David:OAuth 里有两个核心角色:
在第一版 MCP 认证规范里,我们把这两个角色合并进了 MCP server。对于创业公司来说,这没问题:你自己有账号体系,把 MCP server 直接绑在用户账号上,完全可用。但在企业环境里,这根本行不通。企业几乎总是有一个中央身份系统(比如 Google 登录、企业 SSO),用户每天早上只感知到“我登录了一次”,但背后其实是 IdP 在工作。
所以在六月的规范中,我们做了一个关键调整:明确把 MCP server 定义为资源服务器,和身份系统解耦。我们对“怎么拿 token”依然有建议,但不再强行绑定在 MCP server 里。同时,也补齐了动态客户端注册等细节。
主持人:那 agent 代表用户去操作,比如帮我用 Linear、Slack,这个问题现在解决了吗?
David:OAuth 本身是一个非常“以人为中心”的协议。它只定义:如果你没有 token,该怎么拿 token。一旦你有 token,后面就只是把它放进 Bearer Token 里而已。
我们目前并没有对 agent-to-agent 或 agent 代表用户的认证方式做强约束。在企业内网、封闭环境里,大家已经可以通过 workload identity 等方式做到。但如果客户端和服务端彼此不认识,我们目前还没有一个“完美方案”。
主持人:你们从本地服务器(比如基于 stdio 的方案),一路演进到可流式的 HTTP。在这个过程中,有哪些经验教训值得分享?有没有什么后悔的地方,或者对其他人有什么建议?
David:关于传输层这件事,其实有一个讨论,从过去几年一开始就从未停过。
就在最近两天,我们还在 Google 的办公室里,和一群来自 Google、Microsoft、AWS、Anthropic、OpenAI 的资深工程师坐在一起,专门讨论:到底需要做什么,才能把这件事真正、彻底地打牢?
回到今年三月,当时我们希望引入一种新的传输方式,它能够尽量保留我们在标准 IO(stdio)里拥有的很多特性。因为我们当时——而且直到今天我依然坚信——MCP 不只是为了简单的请求-响应,它还应该支持 Agent。而 Agent 天生就是某种程度上“有状态”的,它需要在客户端和服务器之间进行一种长期存在的通信。
所以,我们一直在寻找一种具备这些特性的方案。我们当然也研究过一些替代方案,比如 WebSocket。但在实践中,我们发现,要真正把一个可靠的双向流(bidirectional stream)做好,其实会遇到很多问题。
于是我们就在思考:有没有一种“中间态”?这种中间态需要满足两个条件:一方面,它要足够简单,适合那些最基础的使用场景——比如用户只是想提供一个工具;另一方面,它又必须能够在需要的时候,升级成一个完整的双向流,因为你可能真的会遇到那种复杂的 Agent 之间相互通信的场景。正是在这样的背景下,可流式 HTTP(streamable HTTP)诞生了。
事后回看,我觉得我们有些地方做对了,也有些地方做错了。
做对的地方在于:我们非常坚定地只依赖标准 HTTP。但做错的地方在于:我们让太多事情对客户端来说是“可选的”。比如,客户端可以连接服务器,并打开一个从服务器返回的流,但它并不是必须这么做。而现实情况是——几乎没有客户端会这么做,因为这是可选的。结果就是,很多双向能力实际上被“抹掉”了。
于是,一些功能,比如elicitation(征询)和sampling(采样),对服务器来说就变得不可用。原因很简单:服务器没有一个打开的返回流;而客户端在实现时会想,“这已经满足我产品的最小可用版本(MVP)了,我没必要再多做这些。”
这最终成了一个问题。我觉得这是一个非常明确的教训。
第二个教训来自于协议设计本身。
我们设计的这套传输协议,要求服务器端持有一定的状态。如果你只有一台服务器,这当然没问题。但一旦你要做水平扩展——比如跑在多个 Pod、多个容器里——问题就来了。
设想这样一个流程:一次 tool call,然后是一次 elicitation,再接着是 elicitation 的结果返回。很可能,这几个请求会打到不同的服务器实例上。那你就必须想办法,让这几台服务器把这些信息“拼”在一起。现实中,这往往意味着你需要某种共享状态机制:Redis、Memcached,或者别的什么共享存储,总之你需要一个地方,能够让这些服务器共享状态。
从技术上说,这当然是可行的。我们在 PHP 应用、Python 应用里早就见过类似的模式。但说实话,当规模一上来,这件事一点都不好玩。
而且我们也知道,一些公司——比如 Google、Microsoft——他们在用 MCP 的时候,规模已经大到我不能公开具体数字,但可以说是百万级请求。到了这个量级,这就真的成了一个问题。
于是我们现在坐在这里,不断地问自己:如何在协议的下一次演进中,做到这几件事?
我觉得,我们正在逐步找到正确的解法,但这件事本身真的很复杂。
因为今天的大多数技术选择,其实都非常极端:要么你做一个很简单的东西,比如 REST;要么你直接上“全双工”的方案,比如 WebSocket、gRPC。而我们需要的,其实是两者同时存在。
在巨头之间“做标准”是什么体验?
主持人:和这么多顶级公司一起做标准,是什么感觉?在那样的场合,大家都是资深人士,每个人都有自己的观点。谁来做最终决定?
David:真的太有意思了。我能和业内最顶级的工程师一起工作。通常我们的目标是尽量达成共识。现实情况是,从技术角度讲,最终拍板的人是我,但说实话,这更多是一种形式上的存在。
真正重要的事情在于:我们努力把讨论不断收敛,明确哪些是真正大家都认可的问题,哪些是暂时还存在分歧的问题,然后在这些边界之内,去构建我们能做到的最佳解决方案。
这个过程需要时间,需要大量迭代,但说真的,这件事本身非常有意思。因为你能看到来自不同公司的、非常独特的问题形态。你甚至能从问题本身,看出一家公司的“性格”——比如 Google 面临的问题和 Microsoft 就完全不同,而这些差异,很大程度上来自他们各自构建系统的方式。同样,Anthropic 的问题看起来也和 OpenAI 的问题不一样。
但我最喜欢的一点在于:有时候你会突然意识到,自己正坐在一个房间里,周围全是彼此竞争的公司,但大家却在一起构建同一件东西。
我在开源世界已经待了大概 25 年了,我真的非常热爱这种状态。当一个标准真正运转起来时,这就是理想状态。而且这些人都非常优秀,我从每一位同行身上都学到了很多。所以我非常感激,自己能处在这样的位置。
主持人:这听起来有点像 IETF 的标准制定流程?你们有没有讨论过,这种“私下的小圈子”运作方式,和更传统的标准组织之间的差异?
David:这是个很有意思的问题。某种程度上,它确实有点像 IETF,但也有明显不同。
IETF 是一个完全开放的论坛,任何人都可以参与。它的结果是——不是因为刻意如此,而是“偶然地”——整个流程非常依赖共识,因此速度也相对较慢。
但这种慢,在很多方面其实是优点。因为一旦标准定下来,基本上是不可逆的。比如你看看 OS 2.1 规范,它已经制定了三四年,到现在都还没完全结束。这就是 IETF 标准化的节奏:这些事情本来就会花非常非常长的时间。
我认为这对某些领域是好事,但在 AI 领域,目前的变化实在太快了,你几乎被迫要选择一个更小的核心群体。因此我们选择把 MCP 运作成一个非常传统的开源项目:有一个大约 8 人的核心维护者小组,基本上由他们来做最终决策;其他人可以提供输入、提出建议,而且很多变更并不是来自核心维护者,但决定权在他们手里。
这是一种折中方案:一部分是共识驱动,一部分则是带有一点“技术独裁”的意味。如果你想要快速前进,这种模式在当前阶段对 MCP 来说是合理的。
主持人:那你们是如何平衡模型能力演进与协议设计之间的关系的?毕竟 Anthropic 和 OpenAI 都在做大量后训练(post-training),让模型更擅长工具调用;这会不会影响你们对协议形态的偏好?反过来,协议是否也会反向影响模型训练?
David:老实说,我不敢说自己对研究侧的所有事情都 100% 熟悉——我更多是产品背景。但从我了解的情况来看,协议确实会在一定程度上影响后训练,比如我们在模型卡中会使用MCP Atlas,确保模型在面对真实世界中大量存在的工具时,能正常工作。
但从另一个角度讲,协议的底层原语,其实很少直接被模型能力的提升所驱动。我们更像是在预期模型能力将会呈指数级增长,因此在协议中,依赖了一些你可以通过训练不断强化的机制。
举个更具体的例子。很多人都讨论过 MCP Server 的上下文构建问题。因为 MCP 打开了通往大量工具的大门,如果你天真地把所有工具一次性塞进上下文窗口,那只会造成严重的膨胀。
这就好比把所有技能、所有 Markdown 文件一次性丢进上下文里,结果当然会一团糟。
但我们其实从一开始就知道,可以采用一种叫做渐进式发现(progressive discovery)的方式:先给模型一小部分信息,让模型在需要的时候,再主动请求更多信息。
这本质上是一个通用原则。
而这里正是我们这些“大模型公司”具备的一点前瞻性所在——我们知道,如果愿意,是完全可以通过训练,把这种能力系统性地强化出来的。模型在原理上已经能做到这些事情了,训练只是让它做得更好。任何支持工具调用的模型,都可以做到这一点;只是如果你专门为此训练过,它的表现会更好。所以在这个层面上,协议设计和模型训练是相互配合的。
但归根结底,渐进式发现这种机制,本身就内生于任何具备工具调用能力的模型之中。
主持人:这也引出了“上下文腐烂(context rot)”的问题。还有 MCP 和所谓 “code mode” 的讨论——比如有人会说,“Anthropic 提倡 code mode,而 MCP 又是 Anthropic 做的,那是不是说明 code mode 才是正确方向?”
David:首先澄清一下,官方博客其实从来没用过 “code mode” 这个词,那是大家后来叫出来的。我们内部更常说的是 “programmatic MCP”,但本质上讨论的是同一件事。
关键在于:MCP 是应用和服务器之间的协议,模型本身在技术上并不直接参与 MCP。所以问题其实变成了:应用拿到一堆工具之后,该怎么用?你可以用最朴素的方式:把工具直接暴露给模型,让模型逐个调用。但你也可以更“创造性”一点:模型非常擅长写代码,那如果我们把这些工具当成 API,交给模型生成一段代码,让它提前把多个调用组合好,再在一个 sandbox 里执行呢?
本质上,模型原本就会做这样的组合:调用 A → 拿结果 → 回到推理 → 调用 B → 再组合成 C。你只是让模型提前优化了这个过程,把它编译成一段可执行代码而已。
而 MCP 的价值并没有因此消失:
这些能力依然存在。你只是换了一种使用方式而已。所以当有人说,“那 MCP 是不是就没用了?”我其实挺困惑的。它不是没用,而是被用在了不同的层次上。
随着模型和基础设施逐渐成熟——比如你可以默认 AI 应用都有 sandbox 执行环境——你确实可以玩出更多有意思的花样。但这并不意味着,一个把模型连接到外部世界的协议就失去了价值。
我个人更愿意把这种变化,看作一种优化,说得直白一点,就是token 级别的优化。
MCP 有没有竞争对手
主持人:这正好可以引出 skills。skills 是一个相对较新的概念。我之所以提到它,是因为在我脑子里,它和渐进式发现、预置代码脚本这些概念是连在一起的。而且 skills 还能生成 skills,本身就很有意思。很多人试图把 MCP 和 skills 放在对立面来比较,显然它们并不重叠,但你是怎么看待这个问题的?
David:是的,我同意。我觉得有意思的点就在于:它们并不重叠。它们解决的是不同的问题。
我觉得 skills 非常棒,而且你知道的,我认为 skills 最核心的出发点之一,就是渐进式发现(progressive discovery)这个原则。但我也认为,“渐进式发现”这种机制,其实是通用于你能用模型做的几乎任何事情的——它不是 skills 独有的。
那 skills 到底提供什么?它提供的是某一类任务的领域知识(domain knowledge):比如你应该如何做事、如何表现,模型应该如何扮演一个数据科学家,或者如何扮演一个会计之类的角色。
但 MCP 提供的,是你能对外部世界采取的真实动作的连接性(connectiveness)——也就是你能执行哪些实际操作、如何把这些操作真正连到外部系统上。
所以我认为它们在某种意义上是正交的(orthogonal):skills 给你的是更“纵向”的能力——偏领域、偏角色、偏方法论;而 MCP 给你的是更“横向”的能力——偏连接、偏动作、偏“给我那个具体操作”。
当然,skills 也可以执行动作。它能执行动作,是因为你可以在里面放代码和脚本,这当然很棒。但这里有两个关键点,我觉得很多人容易忽略。
第一,你需要一个执行环境(execution environment)——也就是你需要一台机器来跑这些代码。是的,你需要“机器”。这在很多场景下完全没问题:比如你在本地跑一个东西(像 Cloud Code 之类),那我们就可以讨论 CLI;在这种你确实拥有执行环境的场景里,这套方式就非常合理,也很好用。
或者,如果你有一个远程执行环境,那同样也说得通。但即便如此,你在这条路径上仍然得不到认证(authentication)这一块能力。所以我认为 MCP 带来的关键价值之一,就是它把认证这件事补齐了——这是 skills 本身不提供的那部分。
第二个点是:你不必去处理“外部方的持续变化”。举个例子,如果你接的是一个 Linear 的 MCP server,那么对方可以持续改进它,而你不需要在自己的 skill 里去处理这些变化——它不是被“固定在某个时间点”的。
第三个点是:你其实不一定需要一个本地的执行环境,因为执行环境在某种意义上是“在别处”的——它在服务器端。也就是说,执行发生在 MCP server 那边。
因此,如果你在构建的是一个 Web 应用,或者一个移动应用,这些特性在某些方面会更契合、更好用。
所以整体来看,我认为它们大多数时候都是正交的。并且我确实看到过一些很酷的落地方式:人们用 skills 去探索不同的功能、不同的角色(比如会计、工程师、数据科学家),然后再用 MCP servers 把这些 skills 连接到公司内部真正的数据源上。我觉得这是一个非常有趣的模型,也最接近我理解和看待它们关系的方式。
主持人:所以 MCP 是连接层?
David:我会说是通信层。是的,通信层。
主持人:从架构上讲我很好奇:MCP client 是放在每个 skill 里面,还是大家共享一个 client?比如共享 client 还能发现 skills 之类的。
David:我们是共享的方式。我觉得从技术上你确实更想走“共享更多”的方向——共享越多,你能做的事情就越多:比如做 discovery(发现)、做连接池(connection pooling)、做自动发现,甚至你可以让 skill 只用很“松散”的方式描述它想要什么,然后系统去你有权限访问的 registry 里帮你找一个合适的 MCP server。
这些能力只有在 shared 的架构里更容易做出来。当然,最终两种方式都能工作,只是这仍然是一个值得继续实验的方向。
Anthropic 怎么用 MCP?
主持人:我想强调一下,可能很多人都没意识到——你刚才一直说“我们怎么做怎么做”,但实际上我觉得外界并不理解 Anthropic 内部到底 有多大规模地在 dogfood MCP。我也是看了 John Welsh 的演讲才真正理解,他说:“我们有一个 MCP gateway,一切都要走这个 gateway。”你能多讲讲这个吗?
David:当然。我们内部两种都用:skills 用得很多,MCP servers 也用得很多。因为你要让大家很容易部署 MCP,你需要和公司内部的 IdP(身份系统)打通之类的东西。所以我们为自己定制开发了一个 gateway。
你只需要把 MCP server 部署起来,剩下的都是内部应用、内部系统在用。有些东西“技术上”算外部系统,但因为它们没有提供第一方 MCP server,我们就自己做了。比如我们有一个 Slack 的 MCP server——我特别爱用。它可以让 Claude 帮我总结 Slack。
我们内部还有很多类似的用法:例如我们每半年(或者一年两次)会做一次员工调查,问大家对公司、对未来、对 AI、对安全等议题的感受。我们也有一个 MCP server 支持这件事,然后你可以围绕结果问很多问题,这非常有趣。
主持人:这些都是你们团队维护的吗?
David:不是。我们维护的是 gateway。但有意思的地方在于:MCP 从一开始的想法就是——在我们开源之前,它源自一个很现实的困境:公司增长太快了。我在研发工具、开发者工具这一侧,增长速度一定跟不上业务扩张。那我怎么做一个东西,让大家能“自己为自己构建工具”?
这就是 MCP 的起源故事。
所以你现在回头看,一年之后发生的事情,正好就是我们当初想要的:大家真的在为自己构建 MCP servers。
我甚至可能完全不知道 Anthropic 内部 90% 的 MCP servers,因为它们可能在研究团队里,我看不到;或者人们就是自己做给自己用,我也不会被同步到。
主持人:那它们是自己 host 吗?还是有远程托管?
David:基本上大家只需要一条命令启动,它就会在一个 Kubernetes 集群里跑起来。算是“半托管”的形态。对任何大公司来说,这类平台基础设施都很重要。外部也有一些平台会帮你做这件事,但从安全角度,我们倾向于自己做。
不过外界也有类似的产品。比如有人做了一个叫 fast MCP 的东西——Jeremiah 他们做的 fast MCP cloud,有点像这样:两条命令,你就能跑起一个 MCP server 实例,支持 HTTP 流式传输。
很多企业还会用类似 LiteLLM 这样的东西做 gateway:你甚至可以启动标准 IO 的 server,把它接到 gateway 上,然后由 gateway 来处理认证等“所有麻烦的部分”。所以落地路径其实很多。
但我认为你真正想要的“理想基础设施”是:让部署变得极其琐碎、极其简单——比如“一条命令”启动一个原本只是 stdio 的 MCP server,然后它瞬间变成一个带有 HTTP streaming、并且集成了认证的远程 MCP server。最终开发者只需要做“标准部分”,其他复杂部分都由平台替你完成。
主持人:我很喜欢你把这个点讲出来,因为很多人会直接把这套思路拿回公司里落地。否则替代方案就是:混乱、重复造轮子、各自重建一遍。顺便 shout out Jeremiah——我还邀请他来我在纽约的峰会做一个 fast MCP 的 workshop。他写过一篇很棒的博客,说我们看到的 MCP 使用,很大一部分其实都发生在企业内部。
David:是的,我们也观察到同样的现象:在大型企业内部,你几乎到处都能看到 MCP。它的增长速度,比你想象得快得多——因为它多数都在企业内部发生,外界根本看不见。
Registry 怎么演化?
主持人:说到 discovery,你们推出了官方 registry。然后又出现了各种 registry 公司、gateway 公司。现在官方 registry 里甚至出现了“自动把自己的 MCP server 放进官方 registry”的子 registry。你们是不是需要更多 registry?你从推出 registry 这件事上学到了什么?你觉得未来会怎么演化?
David:我们看到很多不同的 registry 冒出来。我们一直觉得,生态确实需要一种类似npm / PyPI(MPM)的模式:有一个更中心化的地方,任何人都可以把 MCP server 发布上去。
这就是官方 registry 最初的出发点。
但我们同时也想推动:至少整个生态要有一个共同的标准,让不同 registry 之间能“说同一种语言”。因为我们真正想实现的世界是:模型可以从 registry 里自动选择一个 MCP server,安装它,用在当前任务上——像魔法一样。
要做到这一点,你需要一个标准化接口。我们很早就开始和 GitHub 团队合作(大概四月份),但后来我被别的事情分走了注意力,比如认证,去集中解决那块了。
我希望看到的方向是:未来会有一个“官方 registry”,任何人都可以往里放 MCP server。它的角色就像 npm ——而 npm 也有完全相同的问题:任何人都能发布,你并不知道该信谁、不该信谁;会有供应链攻击。这是公共 registry 的基本属性。
所以我们才提出了子 registry(sub-registries)的概念:像 Smithery 这类服务可以在官方 registry 之上做过滤、做精选、做策展(curate)。我们希望生态最终能形成这样的结构。
我们现在还没完全到那个状态,但正在往那个方向走。比如 GitHub 的 registry 是“策展式”的,同时它和官方 registry 讲的是同一种格式。
最终我们想要的是:作为一家企业,你可以有一个内部 registry——它基于官方 registry 的镜像,再加上你自己的私有 MCP servers;它是你信任的来源,同时它暴露的 API 和官方 registry 一样。这样无论是 VS Code 还是其他客户端,只要指向你的内部 registry,就可以顺畅工作。
主持人:这很有意思,因为 npm 在某种意义上更像一个“下载网关”。我其实不太会去 npm 做发现,我更多是在别处看到包,然后再去 npm 安装。你觉得 registry 的核心是 discovery 吗?还是 agent 会用别的方式完成发现?
David:我认为 discovery 在模型世界里会更重要。这里和 npm 的差别在于:
我们是在做一个AI-first的东西,我们可以假设:有一个聪明的模型,它“知道自己想要什么”。
这在过去是不存在的。如果你今天重新设计现代包管理系统,并且把模型当作核心,你可能会做出类似的交互:“这是我想做的事,你自己决定装哪些包,我不在乎,反正把事情做成就行。”这就是它的类比。
但再次强调:公共 registry 不应该直接让模型这么做,因为公共 registry 很容易变成一个“垃圾场”。你应该在一个可信、被策展过的 registry 上做这种自动化选择。
主持人:我很喜欢你那句话——模型知道自己想要什么。因为现在很多人都有一个梦想:agent 能用 MCP 目录去发现新的 server,自己安装自己使用。这听起来非常 AGI。如果真能跑通当然很牛,但也可能跑不通。要做到这一点,到底需要什么?
David:我觉得需要两件事:
第一,你需要一个好的 registry 接口。
第二,你需要真的去为这个目标做工程、做实验,看看什么可行、什么不可行。
你肯定需要信任等级(trust levels)。你可能还需要签名(signatures)。我有一个想法——不确定会不会真的做——比如:你可以附带来自不同模型提供商的签名,表示他们扫描过这个 MCP server,并且愿意为它背书:
然后你就可以基于这些签名自行决策。这有点像分布式代码签名——不过也不完全分布式,本质上可能还是中心化的。但我认为这是你最终会需要的一类机制。
不过最先跑通的场景,可能反而是企业内部:企业会用私有 registry,本身就带有隐含信任。就像他们今天已经在用私有 npm / 私有 PyPI 一样,他们也会用私有 MCP registry。在这种环境里,你天然有 trust,然后就可以开始做搜索和自动选择。我们自己其实就有内部 registry:当你通过 John 那套基础设施启动一个 MCP server,它就会被注册进去。所以我们也需要在内部继续做实验。
Sampling:理想很美,但客户端不配合
主持人:你今年在伦敦办了一些活动,你看到什么好的 sampling 用例了吗?
David:还没有特别多。我从 sampling 这件事学到的一点是:人们想在 sampling 的过程中使用一些“只在 sampling 时出现”的工具——这些工具并不是 MCP server 暴露出来的那套工具。但我们之前没有能力做到这一点。在这次迭代里我们刚修复了这个问题,所以我们希望未来能看到更多 sampling 用例。偶尔会有一些 MCP server 在用 sampling,但不多。
尤其是当 MCP servers 从“本地为主”走向“远程为主”,在远程场景里,通常更好的选择可能是直接提供 SDK:你完全控制它、自己部署,甚至还可以收费。
而在本地场景里,sampling 的价值更大:因为你是在给很多人分发一个东西,你并不知道他们用的是哪个模型、哪个应用(可能是 VS Code,也可能是 Claude Desktop),这种情况下 sampling 才更有意义。
但现在的问题是:客户端基本都不支持 sampling。所以 sampling 这件事让我挺沮丧的——我仍然觉得这是个很强的想法,但你知道的,有时候你总得赢一些、也得输一些。
主持人:但你们也在升级它,我还是很期待。有点奇怪——如果采样这件事做对了,它某种意义上会变成真正的 agent-to-agent 协议。
David:是的。
主持人:你看到的大多数用例还是偏“数据消费”吗?我自己的 MCP 用法也 mostly 是拿上下文、拿数据。最多的 action 可能就是更新一下 Linear 任务状态。你见过很复杂的“用 MCP 做动作的工作流”吗?还是大家基本都在用它做上下文?
David:大多数人确实是用它做上下文,这占了绝大多数。毕竟它的名字就叫 Model Context(模型上下文)。顺便说一句,OpenAI 的 Nick Cooper 经常跟我说——而且他说得对——MCP 这个名字可能取错了,它确实会让人感觉用途被“限制”了。
我看到的主要还是数据用例。也有人把它用于 deep research,一些更复杂的 agent 暴露出来,但并不普遍。deep research 这种自定义研究用例不算罕见,但除此之外,大多数还是数据、以及围绕数据的深度研究。
现在你还会看到一个新方向:通过 MCP UI(未来我们可能叫 MCP Apps / MCPI)暴露 UI 组件。我觉得这非常有前景,也非常有意思。现在在一些 chat apps 里已经能看到不少类似实践。
Tasks:为长时间、异步 agent 操作而生的新原语
主持人:我很好奇,因为如果大多数用例是“上下文”,你们做 tasks 这个原语,就好像大家暂时还没怎么用它。你们设计 tasks 的出发点是什么?你期待它怎么被用起来?
David:我们做 tasks,是因为很多人来找我们说:“我们真的需要长时间运行的操作——也就是 agents。”
他们想要那种“深度研究任务”,可能一小时才完成;甚至可能一天都跑不完。过去人们会很别扭地用 tools 去实现这类事情——工具本质上就是 RPC 接口,理论上你能凑出来,但很快就会变得别扭:模型需要理解“我得去轮询、我得去拉取”,体验很差,也不是一等公民(first-class primitive),限制很多。
但这类诉求太普遍了:大家都想要长时间运行的 agents。GitHub issue 里,大公司也一直在说“我们需要 long-running operations”。所以我们觉得必须做点什么。
现在 tasks 刚刚落地到 SDK,还需要落地到客户端,然后我们才会看到更广泛的使用。但我非常确信:自定义研究类任务会大量用上它,其他场景也会逐步跟进。
主持人:我对 tasks 非常看好。我觉得任何编排系统或协议都得有 sync 版本和 async 版本。
David:完全同意。
主持人:在 tasks 的设计上,有没有哪些重要分岔点?比如本来有两条路,你们选了其中一条。
David:讨论非常多。有人提议:tasks 其实就是“异步 tools”,做成一个新的 tool primitive 就行。
但对我来说,我的试金石(litmus test)一直是:如果未来我想把 Claude Code 或任何 coding agent 当作一个 MCP server 暴露出来,那么 tasks 必须能支撑这种形态。
纯粹的异步工具调用做不到这一点。你需要一种操作方式:它能够在长时间运行的过程中返回中间结果。理想状态下,你会想暴露这样的东西:“我通过调用这个工具、那个工具、还有那个输入,得到中间产物……最后得到结果。”这才是你希望一个长任务能够表达的。
tasks 现在还没完全做到这一步,但它的设计是“足够通用”的,未来可以支持这种更丰富的表达——这就是最核心的约束。
另一个关键约束是:我们不希望 tasks 成为 tools 的复制品 ——只是语义稍有不同。我们希望它是一个更抽象的概念:你通过一次带元数据的 tool call 来创建一个 task,然后系统自动创建并管理这个 task。所以task 更像一个“容器(container)”:它描述了一段从开始到结束的异步过程,而我们当前用 tool call 作为触发方式。
这样的抽象会打开很多未来可能性。所以我觉得,真正的设计目的是让实现变得更抽象。(虽然)实现起来很复杂,但也最终被解决了,因为复杂性会被 SDK 吞掉:SDK 会帮你实现细节,在开发者视角里,它就是一个 async 调用,然后返回结果。
主持人:听起来会和很多异步 RPC 框架有点重叠,比如 JS 世界的 tRPC、或者各种 protobuf 体系。
David:是的。从接口风格来说,它很像经典的操作系统接口:你创建一个 task,然后不断 pull(轮询)直到它完成。
然后我们下一轮会做一个优化——这次没来得及做:你不用每隔几分钟/几小时去 pull,server 可以回调你(发事件、webhook 之类的)告诉你“我完成了”。
这是优化,但核心接口始终是:客户端可以 pull。这也很像操作系统里的一些文件系统操作:客户端轮询是一种最通用、最可靠的基线能力……
你可以一直 pull(轮询):文件变了吗、文件变了吗……但你也可以用现代一些的内核接口,比如 inotify 之类的通知机制,或者 io_uring 之类的方式,它会告诉你:哦,我完成了——很好,文件变了。
主持人:我学到一个“骚操作”——server 可以一直把 HTTP 连接挂着,等它做完了再断开;连接断开本身就成了一个信号,告诉后端“完成了”。
David:对,但我们不一定想这么做。因为它可能要跑几天,我也不知道别人会怎么处理这种连接。
主持人:这其实挺不负责任的,但确实很酷。老实说,tasks 真的很有意思——我们在做 Devin API、以及 Cognition 那些东西时,也基本被迫“重新发明”过类似机制。这也很有代表性:每个人最终都会需要某种 long-running operation。而当你在调用一个 agent 时,你同样需要这个能力。
David:是的。但对我们来说,有一个有意思的点是:MCP 一直在做的事情,是把大家“此刻正在尝试做的东西”封装起来;我们并不想强行规定一年后大家“应该怎么做”。因为我们不知道,我们不预测未来。
我们做 tasks,是因为大家说:我们现在就需要它。实际上我们六个月前就需要它了。于是我们说,好吧,那现在就是动手的时候了。
我们不想做那种“预测未来”的协议,所以才努力让协议保持相对最小化。虽然也有人会觉得:现在协议里的 primitive 已经太多了。
超长任务与上下文压缩
主持人:一个小问题。假设是超级长的任务,过程中会来回传很多消息。Anthropic 在上下文压缩(或者叫 compaction)这件事上算是领先者之一,其他实验室也在做类似事情。那这种场景怎么处理?我们是不是就无状态地把上下文截断也没关系?你需要保留“全过程完整日志”吗?还是说删掉就删掉了?
David:不需要。你看,我们现在这个行业还是非常早期,我们一直在学习:模型到底需要什么、不需要什么。
甚至到今天,有些 agent 已经开始在跑了几轮之后丢弃 tool call 的结果,因为它不再需要了。我觉得这非常好。所以除了 compaction 之外,我觉得你还会看到更好的机制:更清楚地理解“该保留什么、不该保留什么”。比如对一个长时间异步任务,你可能会这样:某段时间模型确实需要看到全部过程,但当你拿到最终结果之后,你就把其他东西都丢掉。
你甚至可以调用一个更小的模型——比如 Haiku ——让它来判断:这些内容里哪些该保留?告诉我。也可能最“AGI build”的方式就是:让模型自己决定它需要保留什么。所以你会看到两种世界并存。
我们现在还没有唯一答案,因为大家仍在摸索。compaction 是一个很好的阶段性方法,但它也不会是最后一步。
实际上,如果你更认真地思考:你能训练模型在这里做什么,我觉得会有更好的方式。但这些都和“你如何获取上下文”是相互独立的。
我一直把 MCP 看作一个应用层协议:它只负责“你如何获得上下文”。至于“你如何选择上下文”,那是应用层问题——所有 agent 应用最终都会面对。
未来会有很多技术路径。一年前所有人都会说:RAG 才是答案;现在大家又说 RAG 好像“死了”。我们开始用模型、用 compaction。至于一年后会怎样,我也不知道。
主持人:我还有个问题:你怎么看 MCP servers 在未来的定位——它们是给开发者用来构建 AI 应用的?还是一个面向 AI 消费者、让他们把各种服务“插上就能用”的协议?我觉得很多人会把它理解错:他们说“我有 REST API,为什么还需要 MCP?”在我看来,MCP 可能并不是“给开发者用的”,而是给使用 AI 工具的人,用来把东西插进去的。
David:我经常被拿来和 REST API 比。这个对比挺有意思的,因为这里其实有两个问题:第一,REST 并不告诉你认证该怎么做。第二,你们已经在跟我抱怨 “tool bloat(工具膨胀)” 了,但你们有没有看过平均一个 OpenAPI spec 有多长?你把那个塞进模型里,膨胀只会更严重——实际上会糟得多。
更有意思的是,当人们尝试一比一映射时,模型经常会有点迷糊:你会有“按名字搜索、按 ID 搜索、按某字段搜索”等等,突然冒出五个长得很像的工具,模型就会问:你到底要用哪个?我也不知道了。所以这是个关于 REST vs MCP 的小插曲。
但我确实希望 MCP 生活在一个更“消费者导向”的世界:这是使用者应该知道的能力。我想要的世界是:你打开应用,直接说“做这件事”,它就把事情做完——它在底下自动连到合适的服务。MCP 是幕后细节;开发者需要知道它,因为这是通信通道;但对最终用户来说,你只需要拿到结果、把任务完成。
坦白讲,我更喜欢一个世界:没人需要知道 MCP 是什么。比如我妈如果要用 Claude,她不应该知道 MCP 是啥。但我认为 MCP 的重点确实是:让外部服务“可插拔”。在这个意义上,它更偏消费者侧。当然开发者也有用例:他们作为 builder 要构建这些东西;而且我也仍然很爱我的 Playwright MCP server。
主持人:我很好奇你说的 MCP Apps / UI。现在每个客户端——比如 ChatGPT——都有自己的一套渲染方式。所以如果我习惯了某个产品的 MCP app,但换到另一个地方,它可能就是另一个版本、另一种策展方式,体验会很不一样。我想知道你怎么看:尤其现在 OpenAI 也进了基金会,你觉得会不会形成统一结构?让大家按同一个标准来?
David:这里有两个影响源:一方面,MCP UI(或者 MCPY)作为项目本身已经存在一段时间了,它有很多很好的想法。OpenAI 也吸收了其中一些想法,并做了不少改进。更重要的是:我们三周前在 MCP 博客上刚宣布——我们正在和他们一起做一个共同标准。
我们的目标是回到一个世界:你为一个平台开发一次,就可以在所有平台用;或者说“一次构建,到处运行”——你在 ChatGPT 里能用,也可能在 Claude、在 Goose、或任何实现了该标准的程序里用。
而这件事的核心驱动力是:现代 AI 应用几乎一切都是文本交互,这没问题,也挺好;但有些事情,人类就是更擅长用视觉来做。
最典型的例子:选飞机座位。如果让你用纯文本选——“这里有 25 个座位可选”——谁愿意这么干?你根本不知道这些座位在机舱图上是哪里。你当然想要一个 UI:你能点着选;而模型也能在这个 UI 上导航、交互;并且你作为人类也能同时交互。这就是我们想要的方向:做更丰富的界面。纯文本界面确实有天然限制。
你会在音乐制作等场景看到这种需求;你也会看到品牌方非常在意界面呈现。购物也是一个极好的例子:购物行业 20 年的 A/B 测试,研究“怎么把东西卖给你”最有效——购物界面其实非常复杂。所以我们需要一种方式,把这些熟悉的复杂 UI 展示给用户,让用户能交互。这就是 MCP Apps 最终要做的事。
主持人:技术方向上是 iframe?
David:对,是 iframe。本质上你通过 MCP resource 提供原始 HTML,把它放进一个 iframe,然后通过一个明确的接口用 postMessage 和外部通信。
因为是 raw HTML,而且不是加载外部内容,你如果愿意,理论上可以提前做安全分析。同时 iframe 也天然能提供比较清晰的隔离边界,让外部应用在一个安全边界内与之交互。
主持人:iframe 在浏览器里用了很多年。我唯一担心的是 CORS……我太讨厌 CORS 了,而 iframe 总会遇到 CORS 问题。
David:是的,但这里理论上不加载任何外部内容——至少我们不希望它这么做。当然,未来我们可能会不停迭代,五年后可能会出现一堆 CORS header 之类的复杂东西。但现在我们还是从小做起:纯 raw HTML,最好不要有外部引用,这样就不会碰到那些问题。
主持人:那能继承宿主应用的样式吗?
David:不能。iframe 里你得把样式内联进去。
主持人:这听起来很小,但 UI 团队会非常在意。大家会希望它看起来像 ChatGPT。
David:完全同意。品牌方和设计师会非常非常在意。这也是我们需要解决的问题:先把东西推出去,让大家用起来,然后基于真实使用方式迭代。这也正是为什么我觉得长期来看它不应该一直是 iframe。我不知道最终解决方案是什么,但我们可能需要一种“新的 iframe”,它允许一定的“渗透性/可融合性”。
主持人:我觉得这挺合理。另一条路可能就是“AGI build”的方式:给它一个 tool 说“给我样式”,模型再去问宿主应用“我应该长什么样”。
主持人:那 MCP app 应不应该知道自己被嵌在哪个父应用里?比如父应用也暴露工具给模型调用,对吧?那是不是需要一个标准接口让父应用把样式传下去?
David:可能是。这个问题很大。我得去问问团队。我自己并不在最底层细节里,我更多是站在整体方向上。
主持人:这对我来说有点意外。我以前从没关注 MCP UI,结果你们突然都采纳了。我就想:好吧,那看来它已经是 MCP 的一部分了——它让 MCP 从纯后端议题,变成了前端议题。
David:需要说明的是:技术上它是 MCP 的一个扩展(extension),它不是 MCP 核心的一部分。这更多是治理层面的区分。
如果你是一个能渲染 HTML 的客户端,你可以考虑实现它;但就算你不实现,你仍然是一个 MCP client。现实是:很多 CLI agent 根本渲染不了 HTML,所以它们永远不会实现。这没问题。
主持人:还有其他类似的扩展吗?
David:我们可能会在金融服务方向做一些扩展。比如一年后,你可能会看到这样的世界:客户端会有某种“认证/资质”,并得到一个签名——证明它是“金融服务 MCP 客户端”,然后向 server 出示这个证明,server 才允许连接,因为它知道客户端会遵守归因(attribution)等法律合同要求。
类似的机制也会出现在 HIPAA(医疗健康数据)这类场景:当你面对公共 server 和公共 client,同时还要处理敏感数据时,你必须提供一些保证。
主持人:这不是 OAuth 的一部分吗?
David:不一定。举个例子:假设客户端同时装了五个 MCP servers,其中有一个是医疗 server。这个医疗 server 可能会要求:在这个 session 里,你不允许使用其他 MCP servers,因为我给你的数据不能泄露到任何地方。你必须保证它不会跑出去——因为这是 HIPAA 数据、或者金融数据。这是一个很典型的约束:你不希望自己的社保号、健康数据不小心出现在别的地方。
加入 Linux 基金会会不会分心?
主持人:我们接下来会切到 AAIF ,最后,有没有什么行动号召?比如招人、或者呼吁大家参与 MCP spec?
David:最重要的还是——每天都去用 MCP 去构建:去做真正好的 MCP servers。我们看到很多很一般的 MCP servers,也看到一些非常非常优秀的。把 server 做好、把用法做扎实,这很关键。
第二点,我们是一个相当开放的社区,按传统开源方式运作:本质上取决于大家愿意投入多少时间和精力。所以你可以通过很多方式参与:给反馈、在 Discord 里交流、给点子;也可以帮我们做 SDK,比如 TypeScript SDK、Python SDK。我们也一直在找新的 SDK——比如我们有 Go SDK 在推进,但我们没有 Haskell SDK。如果你是 Haskell 开发者,你也许可以来写一个(笑)。
总之,可以做的事情很多。不要低估“参与社区”本身的价值。当然也别忘了去构建:现在机会太多了,尤其是我们对 progressive discovery 的理解更成熟了,对 code mode 的理解也更成熟了——接下来会出现一代新的客户端、一代新的 server,我非常期待大家去做出来。
主持人:我最后一个问题,是想让大家直接听你说。我能感受到你的能量,我也对你们做的事情非常兴奋。但很多人对 MCP 加入 Linux 基金会有点焦虑:他们会说,“这是不是意味着 Anthropic 分心了?”你能回应一下吗?
David:我很喜欢你问这个问题。我完全理解大家为什么会这么想,但事实恰恰相反。Anthropic 的投入和承诺没有变:我们还是同一批人在做 SDK,我们的产品仍然高度依赖 MCP。我还是 MCP 的核心维护者。技术上什么都没变。
基金会真正带来的核心变化只有两点:第一,它让整个行业确信:MCP 会永远开放,永远不会被拿走。历史上确实有公司把开源项目又变回专有。协议领域也有很多专有例子——比如 HDMI。你看 HDMI 在 Linux 上的那些问题。HDMI 2.1 的 HDMI Forum 不愿意让 AMD 开发 HDMI 2.1 的开源 Linux 驱动——真的,有些资料你可以去查。
所以行业里很多人会盯着这些风险。基金会的意义就是:现在 MCP 归属一个中立实体,它会一直开放。你可以使用 “MCP” 这个名字,也不会有人因为商标去起诉你。这会给生态巨大的信心:它是中立的、可持续的。
第二点,如果说我最骄傲的是什么:我觉得我们已经在行业里为“开放标准”定下了基调。现在我们可以利用这个势能,在一个中立空间里建立社区:让大家把真正做得好、维护得好、长期可靠的项目放进来,成为基金会的一部分。
而且我们的门槛会很高:项目必须维护得很好。我们不想、也不会把基金会做成“分心”或“甩包袱”的地方。对我们来说,MCP 仍然是产品核心、仍然超级重要;Anthropic 的承诺和投入一如既往。
参考链接:
https://www.youtube.com/watch?v=z6XWYCM3Q8s