飞猪 AI 测试新范式:维护降 70%、漏测减半、死循环归零
以飞猪为例,生活服务类应用的 C 端的业务质量保障,往往面临业务快速迭代、技术架构复杂,多端场景覆盖难等多重挑战: 业务层面:受旅行行业“七节两促”特性的影响,在高频营销活动驱动下,往往伴随着较为快速的发布节奏;如何在快节奏中构建稳定的 C 端质量保障体系,与安全生产能力成为关键问题。 技术层面:C 端系统采用 Native、Flutter、Weex、DX、H5 等多技术栈混合架构;同时,测试回归需覆盖飞猪 App、手淘飞猪 Tab,及淘、支、微、红等多平台小程序入口,这导致测试回归复杂度指数级上升;此外,功能回归与用户体验提升需协同产研推进,进一步加剧了发布小窗口期下的质量保障难度。 UI 自动化作为 C 端质量保障的切口之一,而 AI 能够在现有场景下,为自动化赋予新的机遇,解决业界 UI 自动化的普遍挑战与共性问题: 用例维护成本高:业务快速变更导致失效率持续攀升,人工投入占比过大; 断言有效性不足:多端入口交互逻辑差异使覆盖不全,问题漏检风险存在; 多端兼容性问题突出:多端差异和逻辑定制,易引发测试盲区,易触发线上故障; 针对这些痛点,我们计划通过 AI 技术,结合并优化现有自动化测试体系:降低用例腐化率以减少人工成本,提升断言精准度以增强问题发现能力,从而在保障质量的同时提效。 图 1:飞猪多端 - 流量入口示意图 在“AI + X”的落地实践中,应用的技术演进大多遵循一条较为清晰的技术路径:从基础提示工程(Prompt Engineering)起步,到检索增强生成(RAG)、记忆体(Mem)、智能体技能(Agent Skills)和多智能体系统(Multi-agent Systems / Sub-agents),最终监督微调(SFT)、GPO/GRPO 等模型层的策略优化方法。 然而当时,我们在技术调研时发现,AI 自动化领域在当时深入借鉴的参考标杆偏少。在开源技术论坛中的技术分享,大多数文章仍聚焦于 0-1 阶段的试用与调研,缺乏对成熟技术路径的规模化应用验证。同时,外部的开源范例(如:阿里 Mobile-agent、微软 playwright-mcp、字节 midscene.js)也都是更聚焦模型 / 框架层面的基础能力建设,而缺少整体的能力串联、使用效果、演进路线上的实践范式。 如何将 “凭借 AI 可以快速入门的能用” 变成 “可支持月均 10 万 + 构建,稳定、快速运行的好用、易用” 是我们在这个技术演进路线上的最大挑战。 核心原则:在 AI 自动化开发启动阶段,即需要同步建立与目标对齐的效果评测体系,将效果验证从“事后补救”前置为“设计输入”,确保技术演进始终服务于质量保障目标,避免因缺乏量化依据导致的无效迭代。 行业验证与内部实践依据: Gartner AI 的研究报告指出,73% 的 AI+X 项目因评测体系缺失而无法规模化落地,表现为技术优化与业务效果脱节。 AI 自动化的前期探索中,常见的技术挑战,往往会遇到的典型问题: 提示工程(PE)优化后:执行效果异常,AI 幻觉问题频发,导致 PE 紧急回滚; RAG 知识库迭代后,关键业务数据召回率显著下降; 模型切换后:本地调试结果与线上实际效果存在偏差,导致整体效果质量下滑,case 失败率增高。 实施要点: 我们从应用 workflow Benchmark 评测集建设、“渐进式消融评测机制”:基座模型 → Prompt → RAG → Agent 分阶段验证效果等方式作为评测体系的基准,每次技术调整(提示工程优化、知识库更新、模型切换)均需通过真实业务数据验证端到端效果,结合自动化测试数据与人工路径验证,确保评测结果反映真实用户体验。 价值体现:先行评测体系为 AI+X 实践提供客观决策依据,有效规避“技术优化但业务效果下降”的风险。为实现从“能用”到“可靠规模化”的关键跨越提供了数据支撑。 核心原则:在 AI 工作流设计中嵌入防死循环机制与故障恢复路径,确保系统在异常情况下能主动退出无效循环、回退至安全状态,而非陷入无限尝试。聚焦业务连续性保障,避免因局部故障导致整体流程失效。 问题依据与内部实践痛点: 行业共性问题:多智能体系统普遍存在流程死循环风险(如 Cursor 等工具中模型反复执行相同操作),在 AI 自动化场景中尤为突出。例如,当用户未填写必选 SKU 时,系统通常触发 toast 提示,但 AI 在截图 / 操作过程中可能无法捕获此类信息,导致模型陷入“尝试 - 失败 - 重试”的无限循环。 动态死循环检测机制: 基于 History 和 Memory 设计算法,实时分析操作序列相似度(如连续 3 次相同点击指令,及相似参数返回,即触发预警); 设定阈值规则:当操作重复率≥60% 或单节点耗时超时,自动判定进入死循环。 分层恢复路径设计: 一级自检:轻量级模型(如 Qwen3-VL-7B)快速扫描历史操作,通过 ReAct 逻辑判断根本原因(例:识别“未捕获 toast”后触发跳过指令); 二级升级:对复杂循环(如多端交互差异),临时调用高参数模型(qwen3-vl-235b-a22b-thinking)进行深度推理,结合 RAG 补充行业知识库(如“下单页 SKU 选择死循环通用处理方案”)检测到连续 N 次无效点击,workflow 自动调用 RAG 获取“必填项缺失”处理方案;; 安全回退:强制回退至最近稳定检查点(如“度假搜索 Listing 页”),避免全流程重启。 价值体现:工作流设计的本质是赋予 AI 系统“自省能力”——通过防死循环机制与分层恢复策略,将故障转化为可自动修复的常规操作,使技术演进真正服务于业务稳定性目标。 核心原则:将业务垂类知识深度嵌入 AI 工作流,确保模型理解真实用户行为路径与行业术语逻辑,使测试覆盖严格对齐核心业务流目标,避免因知识缺失导致的路径偏差与漏检风险。 问题依据与内部实践痛点: 用户路径覆盖失准:模型对业务高频路径的理解存在偏差。例如,当指令为“订北京中关村附近,500 元预算,下个月 1 号大床房”时,实际用户 90% 通过“酒店金刚”或“猪搜”入口操作,但自动化测试常误判至其他资源位(如活动页),导致核心 UV 页面链路覆盖准确率不足,无法有效验证真实用户高频场景。 行业术语理解缺失:模型对垂类术语(如“交通 OD”指交通出行数据、“OTA 页面”指在线旅游平台)存在歧义,引发测试用例生成逻辑错误。例如,在航班测试中,“OD”被误识别为“订单”,导致关键流程验证失效。 实施策略: RAG 业务知识库定制: 构建飞猪专属知识库,整合用户行为热力图(如酒店金刚点击路径)、行业术语词典(如“OD=Origin-Destination”),在 Prompt 生成前动态注入上下文。 例如,当检测到“订酒店”指令,且无其他特殊要求时,RAG 自动匹配“酒店金刚”作为首选入口,确保测试路径与真实用户行为一致。 记忆体(Mem)动态优化: 设计短期记忆模块,实时记录用户历史操作特征(如连续 3 次从“搜索模块”进入酒店列表),在决策时应该优先调用高频路径逻辑。 针对大促营销活动期,记忆体自动识别新增入口(如“双 11 特惠”标签),动态调整测试优先级。 子智能体(sub-Agent)分工协同: 路由 Agent:专责解析指令并匹配高频用户路径(如识别“订酒店”自动路由至酒店金刚); 术语 Agent:实时校正行业黑话(如将“交通 OD”映射为交通数据模块),确保测试逻辑无歧义; 验证 Agent:在关键节点(如支付前)交叉校验路径是否覆盖核心 UV 页面,触发偏差预警。 价值体现:业务垂类知识是 AI 自动化测试的“导航仪”——通过 RAG、记忆体与子智能体的协同设计,将抽象指令转化为精准的业务路径验证,确保技术服务于核心用户场景的质量保障目标。 核心原则:将技术演进,视为应用体系的有机组成部分,通过持续跟踪 AI 能力边界拓展与生态创新,实现测试链路与业务复杂度的动态适配,避免技术滞后成为效果瓶颈。 问题依据与内部实践痛点: AI 技术的演化迭代速度日新月异,在 AI 自动化的基座模型下,我们从最初 gpt3.5 只能写文字、到 gpt4 可以多模态传图片,到 qwen-vl-max-latest 能够在点击、滑动时,精准给到像素级别的操作 的 pixel point,都表明了技术能力的演进速度,已经远远超越我们去思考如何 fix issue 的迭代速度了。 通过建立与 AI 技术发展同频的升级机制,技术底座持续吸收 AI 的开源演化成果,并高效整合开源生态创新,使测试体系始终具备精准匹配业务迭代的适应性。 核心原则:突破操作意图识别的局限,将 AI 能力延伸至对视觉界面的动态理解与泛化校验,使测试体系从“执行动作”转向“结果验证”,确保系统能自主感知 UI 状态变化并判断业务逻辑一致性。 问题依据与内部实践痛点:现有测试过度依赖操作指令解析与“编码形式的断言”,难以应对多端 UI 差异场景下的隐性问题。例如,小程序中优惠券弹窗样式,可能只断言了弹出是否弹出,或者弹窗文案是否正常展示,但是如果弹窗局部出现了空坑,或者渲染异常,通过 “编码形式的传统断言” 是无法及时感知与相应的,如此就产生了漏测的可能。 而 AI 本身的图片解析与研判能力,就可以很好的处理这些问题,即可以判断单张图片上的泛化异常问题,也可以在多张图片的链路上,去分析判断一致性等相关问题。又或者结合实事、工单、可诉等相关外部数据,给出非逻辑 BUG 的风险提醒。 价值体现:AI 泛化检查是质量保障的“视觉神经”——让测试能力从机械执行转向智能感知,确保技术演进始终服务于用户体验的核心目标。 从几个橱窗场景,进行 AI 智能化效果展示。 AI 技术的深度引入,有效解决了 C 端 UI 自动化质量保障体系普遍存在的通用问题,推动测试能力实现较大的提升: 用例维护成本显著降低通过 AI 语义化改造,系统能够动态理解业务变更逻辑(如营销活动入口调整),自动适配用例,大幅减少因业务快速迭代导致的人工维护投入,使团队精力从重复性调整转向测试策略优化。 测试覆盖深度切实提升泛化检查能力突破了传统编码断言的局限,使验证从操作指令延伸至结果状态。系统可自主识别多端 UI 差异中的隐性问题(如弹窗渲染异常、元素空坑等),有效弥补了人工难以覆盖的视觉类风险盲区。 多端兼容性问题系统性改善基于 RAG、记忆体与子智能体的协同设计,AI 深度融入业务垂类逻辑(如高频用户路径、行业术语校正),确保测试流严格对齐真实用户行为,显著降低了因端侧差异引发的漏检风险。 本质价值:AI 不是简单替代人工,而是将测试工程师从机械执行中解放,使其聚焦于质量策略设计与业务风险预判。当系统能自主完成弹窗处理、像素级操作及死循环脱困时,质量保障真正实现了从“执行工具”到“智能伙伴”的转变——技术价值的体现,在于让专业能力更高效地服务于用户体验本质。一、背景与愿景

二、挑战
三、策略与思路
3.1、做好评测体系的先行建设,用数据指引应用迭代效果
3.2、通过工作流设计,避免模型流程死循环(break cycle),提升故障恢复与自检能力
3.3、通过 RAG、记忆体与子智能体补充业务垂类知识,保障高 UV 页面路径的精准覆盖
3.4、持续跟进前沿技术,动态演进应用能力,优化整体链路效果
3.5、拓展 AI 泛化检查能力,加强视觉智能感知与断言,降低漏测概率
四、效果展示
4.1、对于异常弹窗的静默处理

4.2、对于异形元素(无文字)的像素级坐标感知
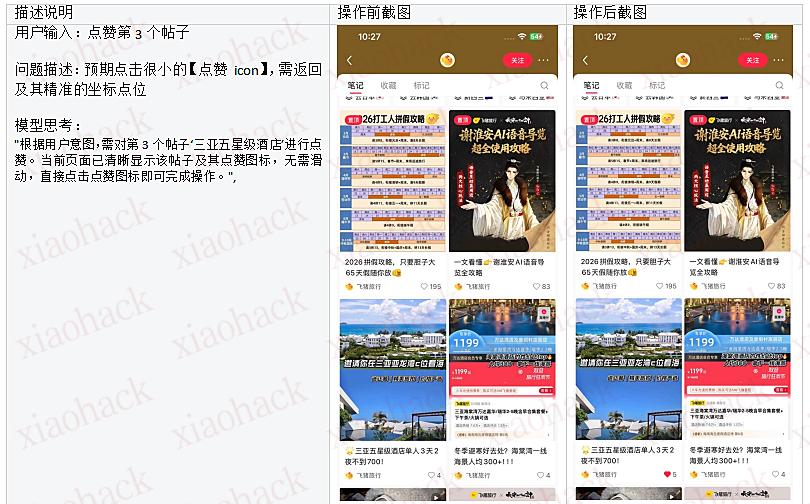
4.3、对于连续逻辑的动态自检与判断能力

4.4 对于循环操作的短期记忆
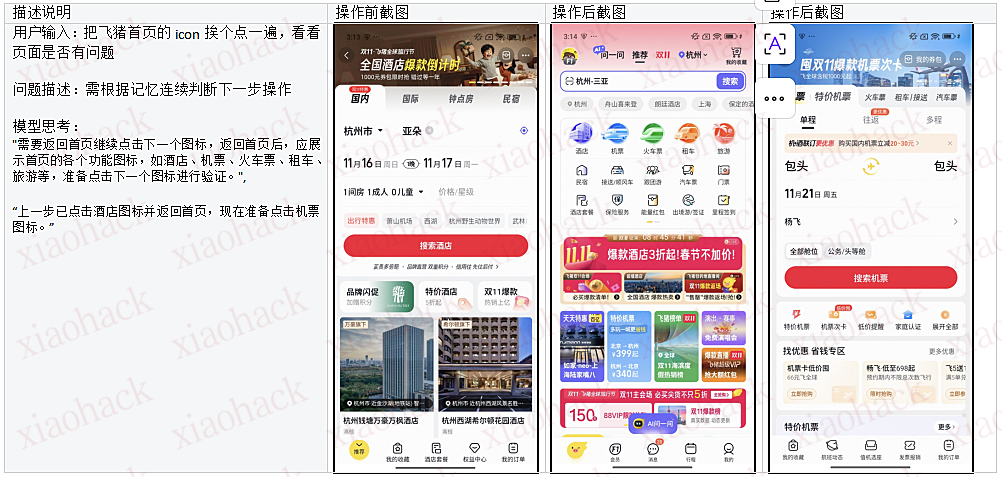
4.5 对于死循环场景的脱困能力

4.6 对于截图的泛化检查能

五、思考总结



