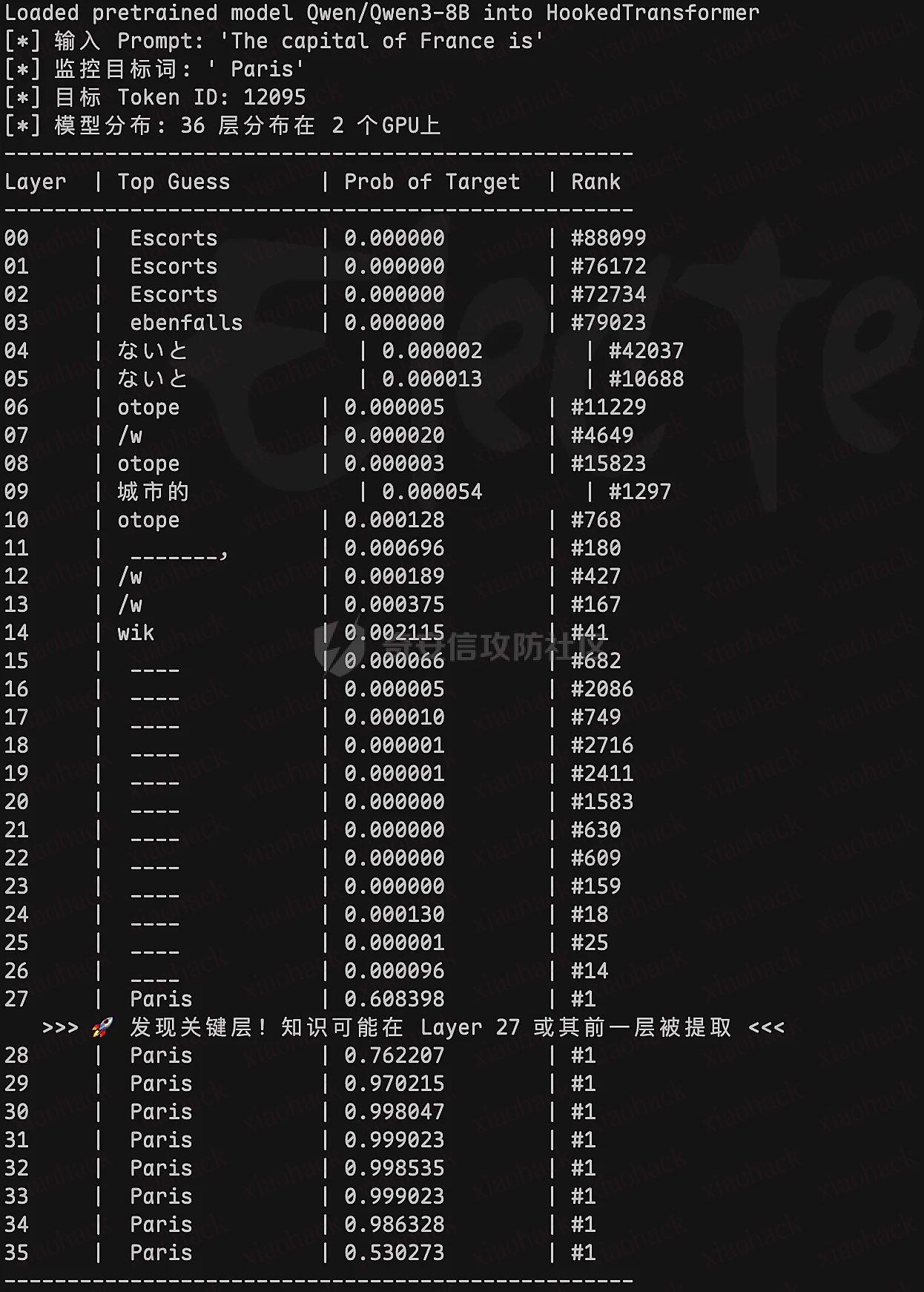
DQN 用
max Q(s',a')
计算目标值,等于在挑 Q 值最高的动作,但是这些动作中包括了那些因为估计噪声而被高估的动作,素以就会产生过估计偏差,直接后果是训练不稳定、策略次优。
这篇文章要解决的就是这个问题,内容包括:DQN 为什么会过估计、Double DQN 怎么把动作选择和评估拆开、Dueling DQN 怎么分离状态值和动作优势、优先经验回放如何让采样更聪明,以及用 PyTorch 从头实现这些改进。最后还会介绍一个 CleanRL 的专业实现。

过估计问题
DQN 的目标值如下:
y = r + γ·maxₐ' Q(s', a'; θ⁻)
问题就在于,同一个网络既负责选动作(a* = argmax Q),又负责评估这个动作的价值。Q 值本身是带噪声的估计所以有时候噪声会让差动作的 Q 值偏高,取 max 操作天然偏向选那些被高估的动作。
数学上有个直观的解释:
E[max(X₁, X₂, ..., Xₙ)] ≥ max(E[X₁], E[X₂], ..., E[Xₙ])
最大值的期望总是大于等于期望的最大值,这是凸函数的 Jensen 不等式。
过估计会导致收敛变慢,智能体把时间浪费在探索那些被高估的动作上。其次是策略质量打折扣,高噪声的动作可能比真正好的动作更受青睐。更糟的是过估计会不断累积,导致训练发散。泛化能力也会受损——在状态空间的噪声区域,智能体会表现得过于自信。
Double DQN:把选择和评估拆开
标准 DQN 一个网络干两件事:
a* = argmaxₐ' Q(s', a'; θ⁻) # 选最佳动作
y = r + γ · Q(s', a*; θ⁻) # 评估这个动作(同一个网络)
Double DQN 用两个网络,各管一件:
a* = argmaxₐ' Q(s', a'; θ) # 用当前网络选
y = r + γ · Q(s', a*; θ⁻) # 用目标网络评估
当前网络(θ)选动作,目标网络(θ⁻)评估。两个网络的误差不相关这样最大化偏差就被打破了。
为什么有效呢?
假设当前网络把动作 a 的价值估高了,目标网络(参数不同)大概率不会犯同样的错。误差相互独立,倾向于抵消而非累加。
最通俗的解释就是DQN 像是自己给菜打分、自己挑菜吃,这样烂菜可能就混进来了,而Double DQN 让朋友打分、你来挑,两边的误差对冲掉了。
Standard DQN: E[Q(s, argmaxₐ Q(s,a))] ≥ maxₐ E[Q(s,a)] (有偏)
Double DQN: E[Q₂(s, argmaxₐ Q₁(s,a))] ≈ maxₐ E[Q(s,a)] (无偏)
从 DQN 到 Double DQN,只需要改一行:
# DQN 目标
next_q_values=target_network(next_states).max(1)[0]
target=rewards+gamma*next_q_values* (1-dones)
# Double DQN 目标
next_actions=current_network(next_states).argmax(1) # <- 用当前网络选
next_q_values=target_network(next_states).gather(1, next_actions.unsqueeze(1)) # <- 用目标网络评估
target=rewards+gamma*next_q_values.squeeze() * (1-dones)
就这一行改动极小,效果却很明显。
实现:Double DQN
扩展 DQN Agent
classDoubleDQNAgent(DQNAgent):
"""
Double DQN: 通过解耦动作选择和评估来减少过估计偏差。
"""
def__init__(self, *args, **kwargs):
"""
初始化 Double DQN agent。
从 DQN 继承所有内容,只改变目标计算。
"""
super().__init__(*args, **kwargs)
defupdate(self) ->Dict[str, float]:
"""
执行 Double DQN 更新。
Returns:
metrics: 训练指标
"""
iflen(self.replay_buffer) <self.batch_size:
return {}
# 采样批次
states, actions, rewards, next_states, dones=self.replay_buffer.sample(
self.batch_size
)
states=states.to(self.device)
actions=actions.to(self.device)
rewards=rewards.to(self.device)
next_states=next_states.to(self.device)
dones=dones.to(self.device)
# 当前 Q 值 Q(s,a;θ)
current_q_values=self.q_network(states).gather(1, actions.unsqueeze(1))
# Double DQN 目标计算
withtorch.no_grad():
# 使用当前网络选择动作
next_actions=self.q_network(next_states).argmax(1)
# 使用目标网络评估动作
next_q_values=self.target_network(next_states).gather(
1, next_actions.unsqueeze(1)
).squeeze()
# 计算目标
target_q_values=rewards+ (1-dones) *self.gamma*next_q_values
# 计算损失
loss=F.mse_loss(current_q_values.squeeze(), target_q_values)
# 梯度下降
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.q_network.parameters(), max_norm=10.0)
self.optimizer.step()
self.training_step+=1
return {
'loss': loss.item(),
'q_mean': current_q_values.mean().item(),
'q_std': current_q_values.std().item(),
'target_q_mean': target_q_values.mean().item()
}
训练函数:
deftrain_double_dqn(
env_name: str,
n_episodes: int=1000,
max_steps: int=500,
train_freq: int=1,
eval_frequency: int=50,
eval_episodes: int=10,
verbose: bool=True,
**kwargs
) ->Tuple:
"""
训练 Double DQN agent(使用 DoubleDQNAgent 而不是 DQNAgent)。
"""
# 与 train_dqn 相同但使用 DoubleDQNAgent
env=gym.make(env_name)
eval_env=gym.make(env_name)
state_dim=env.observation_space.shape[0]
action_dim=env.action_space.n
# 使用 DoubleDQNAgent
agent=DoubleDQNAgent(
state_dim=state_dim,
action_dim=action_dim,
**kwargs
)
# 训练循环(与 DQN 相同)
stats= {
'episode_rewards': [],
'episode_lengths': [],
'losses': [],
'q_values': [],
'target_q_values': [],
'eval_rewards': [],
'eval_episodes': [],
'epsilons': []
}
print(f"Training Double DQN on {env_name}")
print(f"State dim: {state_dim}, Action dim: {action_dim}")
print("="*70)
forepisodeinrange(n_episodes):
state, _=env.reset()
episode_reward=0
episode_length=0
episode_metrics= []
forstepinrange(max_steps):
action=agent.select_action(state, training=True)
next_state, reward, terminated, truncated, _=env.step(action)
done=terminatedortruncated
agent.store_transition(state, action, reward, next_state, done)
ifstep%train_freq==0:
metrics=agent.update()
ifmetrics:
episode_metrics.append(metrics)
episode_reward+=reward
episode_length+=1
state=next_state
ifdone:
break
# 更新目标网络
if (episode+1) %kwargs.get('target_update_freq', 10) ==0:
agent.update_target_network()
agent.decay_epsilon()
# 存储统计信息
stats['episode_rewards'].append(episode_reward)
stats['episode_lengths'].append(episode_length)
stats['epsilons'].append(agent.epsilon)
ifepisode_metrics:
stats['losses'].append(np.mean([m['loss'] forminepisode_metrics]))
stats['q_values'].append(np.mean([m['q_mean'] forminepisode_metrics]))
stats['target_q_values'].append(np.mean([m['target_q_mean'] forminepisode_metrics]))
# 评估
if (episode+1) %eval_frequency==0:
eval_reward=evaluate_dqn(eval_env, agent, eval_episodes)
stats['eval_rewards'].append(eval_reward)
stats['eval_episodes'].append(episode+1)
ifverbose:
avg_reward=np.mean(stats['episode_rewards'][-50:])
avg_loss=np.mean(stats['losses'][-50:]) ifstats['losses'] else0
avg_q=np.mean(stats['q_values'][-50:]) ifstats['q_values'] else0
print(f"Episode {episode+1:4d} | "
f"Reward: {avg_reward:7.2f} | "
f"Eval: {eval_reward:7.2f} | "
f"Loss: {avg_loss:7.4f} | "
f"Q: {avg_q:6.2f} | "
f"ε: {agent.epsilon:.3f}")
env.close()
eval_env.close()
print("="*70)
print("Training complete!")
returnagent, stats
LunarLander-v3
# 训练 Double DQN
if__name__=="__main__":
device='cuda'iftorch.cuda.is_available() else'cpu'
agent_ddqn, stats_ddqn=train_double_dqn(
env_name='LunarLander-v3',
n_episodes=4000,
max_steps=1000,
learning_rate=5e-4,
gamma=0.99,
epsilon_start=1.0,
epsilon_end=0.01,
epsilon_decay=0.9995,
buffer_capacity=100000,
batch_size=128,
target_update_freq=20,
train_freq=4,
eval_frequency=100,
eval_episodes=10,
hidden_dims=[256, 256],
device=device,
verbose=True
)
# 保存模型
agent_ddqn.save('doubledqn_lunar_lander.pth')
输出:
Training Double DQN on LunarLander-v3
State dim: 8, Action dim: 4
======================================================================
Episode 100 | Reward: -155.24 | Eval: -885.72 | Loss: 52.9057 | Q: 0.20 | ε: 0.951
Episode 200 | Reward: -148.85 | Eval: -85.94 | Loss: 37.2449 | Q: 2.14 | ε: 0.905
Episode 300 | Reward: -111.61 | Eval: -172.48 | Loss: 37.4279 | Q: 3.52 | ε: 0.861
Episode 400 | Reward: -99.21 | Eval: -198.43 | Loss: 41.5296 | Q: 8.15 | ε: 0.819
Episode 500 | Reward: -80.75 | Eval: -103.26 | Loss: 56.2701 | Q: 11.70 | ε: 0.779
...
Episode 3200 | Reward: 102.04 | Eval: 159.71 | Loss: 16.5263 | Q: 27.94 | ε: 0.202
Episode 3300 | Reward: 140.37 | Eval: 191.79 | Loss: 22.5564 | Q: 29.81 | ε: 0.192
Episode 3400 | Reward: 114.08 | Eval: 269.40 | Loss: 23.2846 | Q: 32.40 | ε: 0.183
Episode 3500 | Reward: 166.33 | Eval: 244.32 | Loss: 21.8558 | Q: 32.51 | ε: 0.174
Episode 3600 | Reward: 150.80 | Eval: 265.42 | Loss: 21.6430 | Q: 33.18 | ε: 0.165
Episode 3700 | Reward: 148.59 | Eval: 239.56 | Loss: 23.8328 | Q: 34.65 | ε: 0.157
Episode 3800 | Reward: 162.82 | Eval: 233.36 | Loss: 28.3445 | Q: 37.46 | ε: 0.149
Episode 3900 | Reward: 177.70 | Eval: 259.99 | Loss: 36.2971 | Q: 40.22 | ε: 0.142
Episode 4000 | Reward: 156.60 | Eval: 251.17 | Loss: 46.7266 | Q: 42.15 | ε: 0.135
======================================================================
Training complete!
Dueling DQN:分离值和优势
很多状态下,选哪个动作其实差别不大。CartPole 里杆子刚好平衡时,向左向右都行;开车走直线方向盘微调的结果差不多;LunarLander 离地面还远的时候,引擎怎么喷影响也有限。
标准 DQN 对每个动作单独学 Q(s,a),把网络容量浪费在冗余信息上。Dueling DQN 的思路是把 Q 拆成两部分:V(s) 表示"这个状态本身值多少",A(s,a) 表示"这个动作比平均水平好多少"。
架构如下
标准 DQN:
Input -> Hidden Layers -> Q(s,a₁), Q(s,a₂), ..., Q(s,aₙ)
Dueling DQN:
|-> Value Stream -> V(s)
Input -> Shared Layers |
|-> Advantage Stream -> A(s,a₁), A(s,a₂), ..., A(s,aₙ)
Q(s,a) = V(s) + (A(s,a) - mean(A(s,·)))
为什么要减去均值?不减的话,任何常数加到 V 再从 A 减掉,得到的 Q 完全一样,网络学不出唯一解。
数学表达如下:
Q(s,a) = V(s) + A(s,a) - (1/|A|)·Σₐ' A(s,a')
也可以用 max 代替 mean:
Q(s,a) = V(s) + A(s,a) - maxₐ' A(s,a')
实践中 max 版本有时效果更好。
举个例子:V(s) = 10,好动作的 A 是 +5,差动作的 A 是 -3,平均优势 = (+5-3)/2 = +1。那么 Q(s, 好动作) = 10 + 5 - 1 = 14,Q(s, 差动作) = 10 - 3 - 1 = 6。
实现
classDuelingQNetwork(nn.Module):
"""
Dueling DQN 架构,分离值和优势。
理论: Q(s,a) = V(s) + A(s,a) - mean(A(s,·))
"""
def__init__(
self,
state_dim: int,
action_dim: int,
hidden_dims: List[int] = [128, 128]
):
"""
初始化 Dueling Q 网络。
Args:
state_dim: 状态空间维度
action_dim: 动作数量
hidden_dims: 共享层大小
"""
super(DuelingQNetwork, self).__init__()
self.state_dim=state_dim
self.action_dim=action_dim
# 共享特征提取器
shared_layers= []
input_dim=state_dim
forhidden_diminhidden_dims:
shared_layers.append(nn.Linear(input_dim, hidden_dim))
shared_layers.append(nn.ReLU())
input_dim=hidden_dim
self.shared_network=nn.Sequential(*shared_layers)
# 值流: V(s) = 状态的标量值
self.value_stream=nn.Sequential(
nn.Linear(hidden_dims[-1], 128),
nn.ReLU(),
nn.Linear(128, 1)
)
# 优势流: A(s,a) = 每个动作的优势
self.advantage_stream=nn.Sequential(
nn.Linear(hidden_dims[-1], 128),
nn.ReLU(),
nn.Linear(128, action_dim)
)
# 初始化权重
self.apply(self._init_weights)
def_init_weights(self, module):
"""初始化网络权重。"""
ifisinstance(module, nn.Linear):
nn.init.kaiming_normal_(module.weight, nonlinearity='relu')
nn.init.constant_(module.bias, 0.0)
defforward(self, state: torch.Tensor) ->torch.Tensor:
"""
通过 dueling 架构的前向传播。
Args:
state: 状态批次, 形状 (batch_size, state_dim)
Returns:
q_values: 所有动作的 Q(s,a), 形状 (batch_size, action_dim)
"""
# 共享特征
features=self.shared_network(state)
# 值: V(s) -> 形状 (batch_size, 1)
value=self.value_stream(features)
# 优势: A(s,a) -> 形状 (batch_size, action_dim)
advantages=self.advantage_stream(features)
# 组合: Q(s,a) = V(s) + A(s,a) - mean(A(s,·))
q_values=value+advantages-advantages.mean(dim=1, keepdim=True)
returnq_values
defget_action(self, state: np.ndarray, epsilon: float=0.0) ->int:
"""
使用 ε-greedy 策略选择动作。
"""
ifrandom.random() <epsilon:
returnrandom.randint(0, self.action_dim-1)
else:
withtorch.no_grad():
state_tensor=torch.FloatTensor(state).unsqueeze(0).to(
next(self.parameters()).device
)
q_values=self.forward(state_tensor)
returnq_values.argmax(dim=1).item()
Dueling 架构的好处:在动作影响不大的状态下学得更好,梯度流动更通畅所以收敛更快,值估计也更稳健。
还可以把两种改进叠在一起,做成Double Dueling DQN
classDoubleDuelingDQNAgent(DoubleDQNAgent):
"""
结合 Double DQN 和 Dueling DQN 的智能体。
"""
def__init__(
self,
state_dim: int,
action_dim: int,
hidden_dims: List[int] = [128, 128],
**kwargs
):
"""
初始化 Double Dueling DQN 智能体。
使用 DuelingQNetwork 而不是标准 QNetwork。
"""
# 暂不调用 super().__init__()
# 我们需要以不同方式设置网络
self.state_dim=state_dim
self.action_dim=action_dim
self.gamma=kwargs.get('gamma', 0.99)
self.batch_size=kwargs.get('batch_size', 64)
self.target_update_freq=kwargs.get('target_update_freq', 10)
self.device=torch.device(kwargs.get('device', 'cpu'))
# 探索
self.epsilon=kwargs.get('epsilon_start', 1.0)
self.epsilon_end=kwargs.get('epsilon_end', 0.01)
self.epsilon_decay=kwargs.get('epsilon_decay', 0.995)
# 使用 Dueling 架构
self.q_network=DuelingQNetwork(
state_dim, action_dim, hidden_dims
).to(self.device)
self.target_network=DuelingQNetwork(
state_dim, action_dim, hidden_dims
).to(self.device)
self.target_network.load_state_dict(self.q_network.state_dict())
self.target_network.eval()
# 优化器
learning_rate=kwargs.get('learning_rate', 1e-3)
self.optimizer=torch.optim.Adam(self.q_network.parameters(), lr=learning_rate)
# 回放缓冲区
buffer_capacity=kwargs.get('buffer_capacity', 100000)
self.replay_buffer=ReplayBuffer(buffer_capacity)
# 统计
self.episode_count=0
self.training_step=0
# update() 方法继承自 DoubleDQNAgent
优先经验回放
不是所有经验都同等有价值。TD 误差大的转换说明预测偏离现实,能学到东西;TD 误差小的转换说明已经学得差不多了再采到也没多大用。
均匀采样把所有转换一视同仁,浪费了学习机会。优先经验回放的思路是:让重要的转换被采到的概率更高。
优先级怎么算
pᵢ = |δᵢ| + ε
其中:
δᵢ = r + γ·max Q(s',a') - Q(s,a) (TD 误差)
ε = 小常数,保证所有转换都有被采到的可能
采样概率:
P(i) = pᵢ^α / Σⱼ pⱼ^α
α 控制优先化程度:
α = 0 -> 退化成均匀采样
α = 1 -> 完全按优先级比例采样
优先采样改了数据分布,会引入偏差。所以解决办法是用重要性采样比率来加权更新:
wᵢ = (N · P(i))^(-β)
β 控制校正力度:
β = 0 -> 不校正
β = 1 -> 完全校正
通常 β 从 0.4 开始,随训练逐渐增大到 1.0。
实现
classPrioritizedReplayBuffer:
"""
优先经验回放缓冲区。
理论: 按 TD 误差比例采样转换。
我们可以从中学到更多的转换会被更频繁地采样。
"""
def__init__(self, capacity: int, alpha: float=0.6, beta: float=0.4):
"""
Args:
capacity: 缓冲区最大容量
alpha: 优先化指数(0=均匀, 1=比例)
beta: 重要性采样指数(退火到 1.0)
"""
self.capacity=capacity
self.alpha=alpha
self.beta=beta
self.beta_increment=0.001 # 随时间退火 beta
self.buffer= []
self.priorities=np.zeros(capacity, dtype=np.float32)
self.position=0
defpush(self, state, action, reward, next_state, done):
"""
以最大优先级添加转换。
理论: 新转换获得最大优先级(会很快被采样)。
它们的实际优先级在首次 TD 误差计算后更新。
"""
max_priority=self.priorities.max() ifself.bufferelse1.0
iflen(self.buffer) <self.capacity:
self.buffer.append((state, action, reward, next_state, done))
else:
self.buffer[self.position] = (state, action, reward, next_state, done)
self.priorities[self.position] =max_priority
self.position= (self.position+1) %self.capacity
defsample(self, batch_size: int):
"""
按优先级比例采样批次。
Returns:
batch: 采样的转换
indices: 采样转换的索引(用于优先级更新)
weights: 重要性采样权重
"""
iflen(self.buffer) ==self.capacity:
priorities=self.priorities
else:
priorities=self.priorities[:len(self.buffer)]
# 计算采样概率
probs=priorities**self.alpha
probs/=probs.sum()
# 采样索引
indices=np.random.choice(len(self.buffer), batch_size, p=probs, replace=False)
# 获取转换
batch= [self.buffer[idx] foridxinindices]
# 计算重要性采样权重
total=len(self.buffer)
weights= (total*probs[indices]) ** (-self.beta)
weights/=weights.max() # 归一化以保持稳定性
# 退火 beta
self.beta=min(1.0, self.beta+self.beta_increment)
# 转换为 tensor
states, actions, rewards, next_states, dones=zip(*batch)
states=torch.FloatTensor(np.array(states))
actions=torch.LongTensor(actions)
rewards=torch.FloatTensor(rewards)
next_states=torch.FloatTensor(np.array(next_states))
dones=torch.FloatTensor(dones)
weights=torch.FloatTensor(weights)
return (states, actions, rewards, next_states, dones), indices, weights
defupdate_priorities(self, indices, td_errors):
"""
根据 TD 误差更新优先级。
Args:
indices: 采样转换的索引
td_errors: 那些转换的 TD 误差
"""
foridx, td_errorinzip(indices, td_errors):
self.priorities[idx] =abs(td_error) +1e-6
def__len__(self):
returnlen(self.buffer)
生产环境会用 sum-tree 数据结构,采样复杂度是 O(log N) 而不是这里的 O(N)。这个简化版本以可读性为优先。
DQN 变体对比
几个变体各自解决什么问题呢?
DQN 是基线,用单一网络选动作、评估动作。它引入了目标网络来稳定"移动目标"问题,但容易过估计 Q 值,噪声让智能体去追逐根本不存在的"幽灵奖励"。
Double DQN 把选和评拆开。在线网络选动作,目标网络评估价值。实测下来能有效压低不切实际的 Q 值,学习曲线明显更平滑。
Dueling DQN 换了网络架构,单独学 V(s) 和 A(s,a)。它的核心认知是:很多状态下具体动作的影响不大。在 LunarLander 这种存在大量"冗余动作"的环境里,样本效率提升明显——不用为每次引擎脉冲都重新学状态值。
Double Dueling DQN 把两边的好处结合起来,既减少估计噪声,又提高表示效率。实测中这个组合最稳健,达到峰值性能的速度和可靠性都优于单一改进。
实践建议
变体选择对比

Double DQN 跑得比 DQN 还差?可能是训练不够长(Double DQN 起步偶尔慢一点),或者目标网络更新太频繁,或者学习率偏高。这时可以将训练时间翻倍,target_update_freq 调大,学习率砍 2-5 倍。
Dueling 架构没带来改善?可能是环境本身不适合(所有状态都很关键),或者网络太小,或者值流/优势流太浅。需要对网络加宽加深,确认环境里确实有"中性"状态。
PER 导致不稳定?可能是 β 退火太快、α 设太高、重要性采样权重没归一化。可以减慢 β 增量、α 降到 0.4-0.6、确认权重做了归一化。
首选 Double DQN 起步,代码改动极小,收益明确,没有额外复杂度。
什么时候加 Dueling:状态值比动作优势更重要的环境,大量状态下动作值差不多,需要更快收敛。
什么时候加 PER:样本效率至关重要,有算力预算(PER 比均匀采样慢),奖励稀疏(帮助关注少见的成功经验)。
最后Rainbow 把六项改进叠在一起:Double DQN、Dueling DQN、优先经验回放、多步学习(n-step returns)、分布式 RL(C51)、噪声网络(参数空间探索)。
多步学习把 1-step TD 换成 n-step 回报:
# 1-step TD:
y = rₜ + γ·max Q(sₜ₊₁, a)
# n-step:
y = rₜ + γ·rₜ₊₁ + γ²·rₜ₊₂ + ... + γⁿ·max Q(sₜ₊ₙ, a)
好处是信用分配更清晰,学习更快。
小结
这篇文章从 DQN 的过估计问题讲起,沿着 Double DQN、Dueling 架构、优先经验回放等等介绍下来,每种改进对应一个具体的失败模式:max 算子的偏差、低效的状态-动作表示、浪费的均匀采样。
从头实现这些方法,能搞清楚它们为什么有效;很多"高级" RL 算法不过是简单想法的组合,理解这些想法本身才是真正可扩展的东西。
https://avoid.overfit.cn/post/4c5835f419d840b0acb0a1eb72f92b6f
作者: Jugal Gajjar