作者:辰泉
提示:本文是 AgentRun Browser Sandbox 快速上手实践指南的姊妹篇,专注于高级集成方案、生产环境的最佳实践、性能优化和部署策略。如果您还没有完成基础学习,请先阅读《快速上手:LangChain + AgentRun 浏览器沙箱极简集成指南》。
前言
在完成了 Browser Sandbox 的基础集成之后,本文将介绍高级集成方案(如 BrowserUse 框架)以及生产环境部署需要考虑的因素:如何管理 Sandbox 生命周期?如何优化性能和成本?如何保证系统的安全性和可观测性?本文将为您提供全面的高级应用和生产环境最佳实践指南。
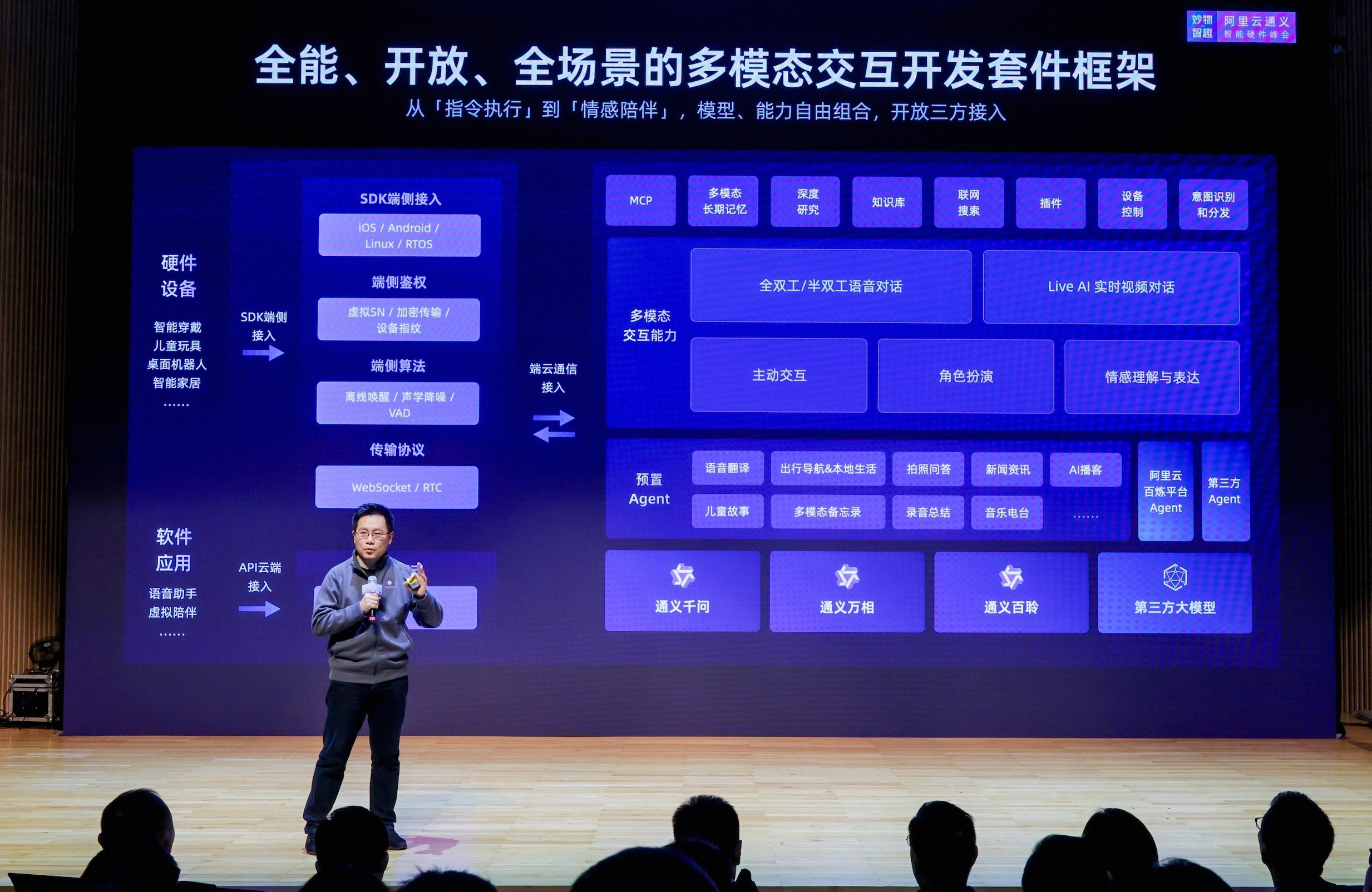
基于 BrowserUse 集成 Browser Sandbox

效果截图
BrowserUse 是一个专门为 AI Agent 设计的浏览器自动化框架,支持视觉理解和智能决策。通过 AgentRun Browser Sandbox,您可以让 BrowserUse 在云端运行,享受 Serverless 架构的优势。
BrowserUse 架构概览
下图展示了 BrowserUse 与 Browser Sandbox 的集成架构:

架构特点:
- 智能决策循环: Agent 通过 LLM 分析页面截图,基于视觉理解生成操作指令,执行操作后继续循环,直到任务完成
- 无头浏览器控制: 通过 CDP 协议远程控制云端浏览器,Playwright 作为底层驱动,所有操作在云端执行
- 实时可视化: VNC 提供实时画面监控,方便调试和验证 Agent 行为
快速开始
安装依赖
pip install browser-use python-dotenv agentrun-sdk[playwright,server]
主要依赖说明:
browser-use:BrowserUse 核心库,支持多模态 LLMagentrun-sdk[playwright,server]:AgentRun SDK,用于创建 Sandboxpython-dotenv:环境变量管理
配置环境变量
创建 .env 文件:
# DashScope API Key(用于 Qwen 模型)
DASHSCOPE_API_KEY=sk-your-dashscope-api-key
# AgentRun 认证信息
AGENTRUN_ACCOUNT_ID=your-account-id
ALIBABA_CLOUD_ACCESS_KEY_ID=your-access-key-id
ALIBABA_CLOUD_ACCESS_KEY_SECRET=your-access-key-secret
# Browser Sandbox 模板名称
BROWSER_TEMPLATE_NAME=sandbox-browser-demo
创建 Sandbox 并使用 BrowserUse
import asyncio
import os
from agentrun.sandbox import Sandbox, TemplateType
from browser_use import Agent, BrowserSession, ChatOpenAI
from browser_use.browser import BrowserProfile
from dotenv import load_dotenv
load_dotenv()
async def main():
# 创建 Browser Sandbox
sandbox = Sandbox.create(
template_type=TemplateType.BROWSER,
template_name=os.getenv("BROWSER_TEMPLATE_NAME"),
sandbox_idle_timeout_seconds=3000
)
# 配置 Qwen 多模态模型
llm = ChatOpenAI(
model='qwen-vl-max',
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 创建浏览器会话
browser_session = BrowserSession(
cdp_url=sandbox.get_cdp_url(),
browser_profile=BrowserProfile(
headless=False,
timeout=3000000,
keep_alive=True
)
)
# 创建 Agent 并执行任务
agent = Agent(
task="访问阿里云官网并总结主要产品分类",
llm=llm,
browser_session=browser_session,
use_vision=True
)
result = await agent.run()
print(f"任务结果: {result.final_result()}")
# 清理资源
await browser_session.stop()
sandbox.delete()
if __name__ == "__main__":
asyncio.run(main())
BrowserUse 高级配置
自定义浏览器行为
browser_profile = BrowserProfile(
timeout=3000000, # 超时时间(毫秒)
keep_alive=True, # 保持会话活跃
)
多步骤任务编排
async def complex_task():
"""复杂的多步骤任务"""
sandbox = Sandbox.create(
template_type=TemplateType.BROWSER,
template_name=os.getenv("BROWSER_TEMPLATE_NAME"),
sandbox_idle_timeout_seconds=3000
)
llm = ChatOpenAI(
model='qwen-vl-max',
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
browser_session = BrowserSession(
cdp_url=sandbox.cdp_url,
browser_profile=BrowserProfile(keep_alive=True)
)
# 任务 1:信息收集
agent1 = Agent(
task="访问阿里云官网,收集产品分类信息",
llm=llm,
browser_session=browser_session,
use_vision=True
)
result1 = await agent1.run()
# 任务 2:基于第一步结果继续操作
agent2 = Agent(
task=f"基于以下信息:{result1.final_result()},访问每个产品分类并提取关键特性",
llm=llm,
browser_session=browser_session,
use_vision=True
)
result2 = await agent2.run()
# 清理资源
await browser_session.stop()
sandbox.delete()
return result2.final_result()
集成 VNC 实时监控
import webbrowser
import urllib.parse
async def run_with_vnc_monitoring():
"""运行 BrowserUse 并启用 VNC 监控"""
sandbox = Sandbox.create(
template_type=TemplateType.BROWSER,
template_name=os.getenv("BROWSER_TEMPLATE_NAME"),
sandbox_idle_timeout_seconds=3000
)
# 获取 VNC URL 并打开查看器
vnc_url = sandbox.get_vnc_url(),
if vnc_url:
# 修复 VNC URL 路径
if vnc_url.endswith('/vnc'):
vnc_url = vnc_url[:-4] + '/ws/livestream'
# 在浏览器中打开 VNC 查看器
encoded_url = urllib.parse.quote(vnc_url, safe='')
viewer_url = f"file://path/to/vnc-viewer.html?url={encoded_url}"
webbrowser.open(viewer_url)
print(f"VNC 查看器已打开,可实时监控浏览器操作")
# 创建并运行 Agent
llm = ChatOpenAI(
model='qwen-vl-max',
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
browser_session = BrowserSession(
cdp_url=sandbox.get_cdp_url(),
browser_profile=BrowserProfile(headless=False, keep_alive=True)
)
agent = Agent(
task="访问淘宝首页并搜索商品",
llm=llm,
browser_session=browser_session,
use_vision=True
)
result = await agent.run()
# 清理资源
await browser_session.stop()
sandbox.delete()
return result.final_result()
BrowserUse 最佳实践
- 启用视觉理解: 对于复杂页面,使用
use_vision=True 让 LLM 分析页面截图 - 保持会话活跃: 使用
keep_alive=True 避免频繁重建连接 - 合理设置超时: 根据任务复杂度调整
timeout 参数 - 复用 BrowserSession: 对于多步骤任务,复用同一个 BrowserSession 提高效率
- 结合 VNC 调试: 开发阶段启用 VNC 实时查看 Agent 行为
获取完整示例代码
本文中的所有示例代码都可以在以下仓库中找到:
# 克隆示例代码仓库
git clone https://github.com/devsapp/agentrun-sandbox-demos.git
# 进入项目目录
cd agentrun-browseruse-wth-sandbox-demo
# 安装依赖(注意需要安装 server 扩展)
pip install -r requirements.txt
配置环境变量
# 复制环境变量模板
cp env.example .env
# 编辑 .env 文件,填入您的配置信息
# 必需配置项:
# - DASHSCOPE_API_KEY: DashScope API Key(用于 Qwen 模型)
# - AGENTRUN_ACCOUNT_ID: AgentRun 账号 ID
# - ALIBABA_CLOUD_ACCESS_KEY_ID: 阿里云访问密钥 ID
# - ALIBABA_CLOUD_ACCESS_KEY_SECRET: 阿里云访问密钥 Secret
# - BROWSER_TEMPLATE_NAME: Browser Sandbox 模板名称
运行示例(两步运行设计)
本项目采用服务器-客户端的架构设计,需要分两步运行:
第一步:启动 VNC 查看器服务
# 在终端 1 中启动 VNC Web 服务器
python main.py
# 服务启动后会显示:
# VNC 查看器服务已启动: http://localhost:8000
# 访问 http://localhost:8000 可以实时查看浏览器操作
main.py 的作用:
- 启动本地 Web 服务器,提供 VNC 实时查看界面
- 提供 WebSocket 代理,连接 AgentRun Sandbox 的 VNC 服务
- 允许您在浏览器中实时监控 Agent 的操作过程
第二步:运行 BrowserUse 示例
# 在终端 2 中运行示例代码
python examples/01_browseruse_basic.py
# 运行高级示例
python examples/02_browseruse_advanced.py
为什么需要两步运行?
- 实时监控: main.py 提供 VNC 查看器,可以实时看到 Agent 在浏览器中的操作
- 调试友好: 通过可视化界面,更容易理解 Agent 的决策过程和行为
- 服务解耦: VNC 服务和业务逻辑分离,可以同时运行多个示例而共用同一个查看器
运行流程图:

仓库内容包括:
main.py:VNC Web 服务器,用于实时监控examples/01_browseruse_basic.py:基础集成示例examples/02_browseruse_advanced.py:高级配置示例examples/sandbox_manager.py:Sandbox 生命周期管理vncviewer/:VNC 查看器前端和后端代码- 完整的环境配置和最佳实践代码
Sandbox 生命周期管理最佳实践
三种管理模式
根据不同的应用场景,我们推荐三种 Sandbox 管理模式:

方案对比:

单例模式实现
适合开发调试和多轮对话场景:
class SandboxManager:
"""单例模式 Sandbox 管理器"""
_instance = None
_sandbox = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
return cls._instance
def get_or_create(self):
"""获取或创建 Sandbox"""
if self._sandbox is None:
self._sandbox = Sandbox.create(
template_type=TemplateType.BROWSER,
template_name=os.getenv("BROWSER_TEMPLATE_NAME"),
sandbox_idle_timeout_seconds=3000
)
return self._sandbox
def destroy(self):
"""销毁 Sandbox"""
if self._sandbox:
self._sandbox.delete()
self._sandbox = None
# 使用
manager = SandboxManager()
sandbox = manager.get_or_create() # 首次创建
sandbox = manager.get_or_create() # 复用现有实例
连接池模式实现
适合高并发生产环境:
from queue import Queue
from threading import Lock
class SandboxPool:
"""Sandbox 连接池"""
def __init__(self, pool_size=5, max_idle_time=300):
self.pool_size = pool_size
self.max_idle_time = max_idle_time
self.pool = Queue(maxsize=pool_size)
self.lock = Lock()
self._initialize_pool()
def _initialize_pool(self):
"""初始化连接池"""
for _ in range(self.pool_size):
sandbox = self._create_sandbox()
self.pool.put(sandbox)
def _create_sandbox(self):
"""创建 Sandbox 实例"""
return Sandbox.create(
template_type=TemplateType.BROWSER,
template_name=os.getenv("BROWSER_TEMPLATE_NAME"),
sandbox_idle_timeout_seconds=self.max_idle_time
)
def acquire(self, timeout=30):
"""获取 Sandbox 实例"""
try:
sandbox = self.pool.get(timeout=timeout)
if not self._is_alive(sandbox):
sandbox = self._create_sandbox()
return sandbox
except:
raise RuntimeError("获取 Sandbox 超时")
def release(self, sandbox):
"""归还 Sandbox 实例"""
if self._is_alive(sandbox):
self.pool.put(sandbox)
else:
new_sandbox = self._create_sandbox()
self.pool.put(new_sandbox)
def _is_alive(self, sandbox):
"""检查 Sandbox 是否存活"""
try:
return hasattr(sandbox, 'sandbox_id')
except:
return False
# 使用
pool = SandboxPool(pool_size=5)
sandbox = pool.acquire()
try:
# 使用 sandbox 执行任务
pass
finally:
pool.release(sandbox)
会话状态管理
支持多用户多会话场景:
import time
class SessionManager:
"""会话状态管理"""
def __init__(self):
self.sessions = {} # session_id -> sandbox
def create_session(self, session_id: str):
"""创建会话"""
if session_id not in self.sessions:
sandbox = Sandbox.create(
template_type=TemplateType.BROWSER,
template_name=os.getenv("BROWSER_TEMPLATE_NAME"),
sandbox_idle_timeout_seconds=1800
)
self.sessions[session_id] = {
'sandbox': sandbox,
'created_at': time.time(),
'last_used': time.time()
}
return self.sessions[session_id]['sandbox']
def get_session(self, session_id: str):
"""获取会话"""
if session_id in self.sessions:
session = self.sessions[session_id]
session['last_used'] = time.time()
return session['sandbox']
return None
def cleanup_expired_sessions(self, max_idle_time=1800):
"""清理过期会话"""
current_time = time.time()
expired_sessions = []
for session_id, session in self.sessions.items():
if current_time - session['last_used'] > max_idle_time:
expired_sessions.append(session_id)
for session_id in expired_sessions:
self.destroy_session(session_id)
def destroy_session(self, session_id: str):
"""销毁会话"""
if session_id in self.sessions:
self.sessions[session_id]['sandbox'].delete()
del self.sessions[session_id]
性能优化
超时时间配置
合理设置超时时间是平衡性能和成本的关键:
# 开发环境(调试用)
sandbox = Sandbox.create(
template_name="dev-template",
sandbox_idle_timeout_seconds=7200 # 2 小时
)
# 生产环境(单次任务)
sandbox = Sandbox.create(
template_name="prod-template",
sandbox_idle_timeout_seconds=300 # 5 分钟
)
# 长时间任务
sandbox = Sandbox.create(
template_name="long-task-template",
sandbox_idle_timeout_seconds=10800 # 3 小时
)
超时策略推荐:

Sandbox 复用策略
class SmartSandboxManager:
"""智能 Sandbox 复用管理器"""
def __init__(self):
self.sandboxes = {} # key -> sandbox
self.usage_count = {} # key -> count
def get_sandbox(self, user_id: str, session_id: str):
"""获取或创建 Sandbox(支持复用)"""
key = f"{user_id}:{session_id}"
if key not in self.sandboxes:
self.sandboxes[key] = Sandbox.create(
template_type=TemplateType.BROWSER,
template_name=os.getenv("BROWSER_TEMPLATE_NAME"),
sandbox_idle_timeout_seconds=1800
)
self.usage_count[key] = 0
self.usage_count[key] += 1
return self.sandboxes[key]
def should_recreate(self, key: str, max_reuse=50):
"""判断是否需要重建(防止状态累积)"""
return self.usage_count.get(key, 0) >= max_reuse
def recreate_if_needed(self, key: str):
"""按需重建 Sandbox"""
if self.should_recreate(key):
if key in self.sandboxes:
self.sandboxes[key].delete()
del self.sandboxes[key]
self.usage_count[key] = 0
错误处理和重试机制
使用 tenacity 库实现智能重试:
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception_type
class SandboxError(Exception):
"""Sandbox 操作异常"""
pass
@retry(
retry=retry_if_exception_type(SandboxError),
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=2, max=10)
)
def execute_with_retry(sandbox, operation):
"""带重试的操作执行"""
try:
return operation(sandbox)
except ConnectionError:
raise SandboxError("连接失败")
except TimeoutError:
raise SandboxError("操作超时")
except Exception as e:
print(f"操作失败: {e}")
raise SandboxError(f"操作失败: {e}")
# 使用示例
def navigate_page(sandbox):
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(sandbox.cdp_url)
page = browser.contexts[0].pages[0]
page.goto("https://example.com", timeout=30000)
return page.title()
result = execute_with_retry(sandbox, navigate_page)
安全性最佳实践
环境变量保护
import os
from dotenv import load_dotenv
load_dotenv()
# 验证必需的环境变量
required_vars = ["DASHSCOPE_API_KEY", "AGENTRUN_ACCOUNT_ID"]
missing_vars = [var for var in required_vars if not os.getenv(var)]
if missing_vars:
raise ValueError(f"缺少必需的环境变量: {', '.join(missing_vars)}")
# 敏感信息不要硬编码
API_KEY = os.getenv("DASHSCOPE_API_KEY")
ACCESS_KEY_ID = os.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID")
ACCESS_KEY_SECRET = os.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET")
URL 白名单
ALLOWED_DOMAINS = [
'example.com',
'aliyun.com',
'alibaba.com'
]
def is_url_allowed(url: str) -> bool:
"""检查 URL 是否在白名单中"""
from urllib.parse import urlparse
domain = urlparse(url).netloc
return any(allowed in domain for allowed in ALLOWED_DOMAINS)
def safe_navigate(page, url: str):
"""安全导航"""
if not is_url_allowed(url):
raise ValueError(f"URL 不在白名单中: {url}")
page.goto(url)
日志脱敏
import re
def sanitize_log(log_text: str) -> str:
"""日志脱敏"""
# 脱敏 API Key
log_text = re.sub(r'sk-[a-zA-Z0-9]{20,}', 'sk-***', log_text)
# 脱敏 Access Key
log_text = re.sub(r'LTAI[a-zA-Z0-9]{12,}', 'LTAI***', log_text)
# 脱敏密码
log_text = re.sub(r'password["\s:=]+[^"\s,}]+', 'password: ***', log_text, flags=re.IGNORECASE)
return log_text
# 使用
print(sanitize_log(f"使用 API Key: {API_KEY}"))
可观测性与监控
日志记录最佳实践
import logging
from datetime import datetime
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(f'sandbox_{datetime.now().strftime("%Y%m%d")}.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
class MonitoredSandboxManager:
"""带监控的 Sandbox 管理器"""
def create_sandbox(self, **kwargs):
"""创建 Sandbox(带日志)"""
start_time = time.time()
logger.info(f"开始创建 Sandbox: {kwargs}")
try:
sandbox = Sandbox.create(**kwargs)
duration = time.time() - start_time
logger.info(f"Sandbox 创建成功: {sandbox.sandbox_id}, 耗时: {duration:.2f}s")
return sandbox
except Exception as e:
duration = time.time() - start_time
logger.error(f"Sandbox 创建失败: {e}, 耗时: {duration:.2f}s")
raise
def execute_task(self, sandbox, task_name: str, operation):
"""执行任务(带日志)"""
start_time = time.time()
logger.info(f"开始执行任务: {task_name}, Sandbox: {sandbox.sandbox_id}")
try:
result = operation(sandbox)
duration = time.time() - start_time
logger.info(f"任务执行成功: {task_name}, 耗时: {duration:.2f}s")
return result
except Exception as e:
duration = time.time() - start_time
logger.error(f"任务执行失败: {task_name}, 错误: {e}, 耗时: {duration:.2f}s")
raise
指标收集
from dataclasses import dataclass
from typing import Dict, List
import json
@dataclass
class SandboxMetrics:
"""Sandbox 指标"""
sandbox_id: str
create_time: float
destroy_time: float = None
total_requests: int = 0
failed_requests: int = 0
total_duration: float = 0.0
class MetricsCollector:
"""指标收集器"""
def __init__(self):
self.metrics: Dict[str, SandboxMetrics] = {}
def record_creation(self, sandbox_id: str):
"""记录创建"""
self.metrics[sandbox_id] = SandboxMetrics(
sandbox_id=sandbox_id,
create_time=time.time()
)
def record_request(self, sandbox_id: str, duration: float, success: bool):
"""记录请求"""
if sandbox_id in self.metrics:
metric = self.metrics[sandbox_id]
metric.total_requests += 1
metric.total_duration += duration
if not success:
metric.failed_requests += 1
def record_destruction(self, sandbox_id: str):
"""记录销毁"""
if sandbox_id in self.metrics:
self.metrics[sandbox_id].destroy_time = time.time()
def export_metrics(self, filepath: str):
"""导出指标"""
metrics_data = [
{
'sandbox_id': m.sandbox_id,
'create_time': m.create_time,
'destroy_time': m.destroy_time,
'total_requests': m.total_requests,
'failed_requests': m.failed_requests,
'success_rate': (m.total_requests - m.failed_requests) / m.total_requests if m.total_requests > 0 else 0,
'avg_duration': m.total_duration / m.total_requests if m.total_requests > 0 else 0,
'lifetime': m.destroy_time - m.create_time if m.destroy_time else time.time() - m.create_time
}
for m in self.metrics.values()
]
with open(filepath, 'w') as f:
json.dump(metrics_data, f, indent=2)
# 使用
collector = MetricsCollector()
collector.record_creation(sandbox.sandbox_id)
# ... 执行任务 ...
collector.export_metrics('metrics.json')
成本优化
按需创建与销毁
class CostOptimizedManager:
"""成本优化的管理器"""
def __init__(self, idle_threshold=300):
self.idle_threshold = idle_threshold
self.sandboxes = {}
self.last_used = {}
def get_sandbox(self, key: str):
"""获取 Sandbox(懒加载)"""
if key not in self.sandboxes:
self.sandboxes[key] = Sandbox.create(
template_type=TemplateType.BROWSER,
template_name=os.getenv("BROWSER_TEMPLATE_NAME"),
sandbox_idle_timeout_seconds=self.idle_threshold
)
self.last_used[key] = time.time()
return self.sandboxes[key]
def cleanup_idle(self):
"""清理闲置 Sandbox"""
current_time = time.time()
to_remove = []
for key, last_time in self.last_used.items():
if current_time - last_time > self.idle_threshold:
to_remove.append(key)
for key in to_remove:
if key in self.sandboxes:
self.sandboxes[key].delete()
del self.sandboxes[key]
del self.last_used[key]
logger.info(f"清理闲置 Sandbox: {key}")
批量任务处理
async def batch_process_tasks(tasks: List[str], pool_size: int = 5):
"""批量处理任务(复用 Sandbox)"""
pool = SandboxPool(pool_size=pool_size)
results = []
for task in tasks:
sandbox = pool.acquire()
try:
# 处理任务
result = await process_task(sandbox, task)
results.append(result)
finally:
pool.release(sandbox)
return results
生产环境部署
环境配置
开发环境 (.env.dev):
# 开发环境配置
BROWSER_TEMPLATE_NAME=dev-browser-template
SANDBOX_IDLE_TIMEOUT=7200
POOL_SIZE=2
LOG_LEVEL=DEBUG
生产环境 (.env.prod):
# 生产环境配置
BROWSER_TEMPLATE_NAME=prod-browser-template
SANDBOX_IDLE_TIMEOUT=300
POOL_SIZE=10
LOG_LEVEL=INFO
ENABLE_METRICS=true
METRICS_EXPORT_INTERVAL=300
高可用架构

健康检查
from flask import Flask, jsonify
app = Flask(__name__)
manager = SandboxManager()
@app.route('/health')
def health_check():
"""健康检查端点"""
try:
# 检查 Sandbox 是否可用
sandbox = manager.get_or_create()
# 简单的健康检查
is_healthy = hasattr(sandbox, 'sandbox_id')
if is_healthy:
return jsonify({
'status': 'healthy',
'sandbox_id': sandbox.sandbox_id,
'timestamp': time.time()
}), 200
else:
return jsonify({
'status': 'unhealthy',
'error': 'Sandbox not available'
}), 503
except Exception as e:
return jsonify({
'status': 'unhealthy',
'error': str(e)
}), 503
@app.route('/metrics')
def metrics():
"""指标端点"""
collector = MetricsCollector()
# 返回当前指标
return jsonify({
'total_sandboxes': len(collector.metrics),
'timestamp': time.time()
})
故障排查与常见问题
连接问题
问题:无法连接到 Sandbox
排查步骤:
def diagnose_connection(sandbox):
"""诊断连接问题"""
print(f"1. 检查 Sandbox ID: {sandbox.sandbox_id}")
print(f"2. 检查 CDP URL: {sandbox.cdp_url}")
# 测试 CDP 连接
try:
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(sandbox.cdp_url)
print("✓ CDP 连接成功")
browser.close()
except Exception as e:
print(f"✗ CDP 连接失败: {e}")
# 测试 VNC 连接
print(f"3. VNC URL: {sandbox.vnc_url}")
print("提示: 可以在浏览器中打开 VNC URL 测试连接")
超时问题
问题:任务执行超时
解决方案:
def handle_timeout(sandbox, operation, max_retries=3):
"""处理超时(带重试)"""
for attempt in range(max_retries):
try:
return operation(sandbox, timeout=30000)
except TimeoutError:
logger.warning(f"任务超时(尝试 {attempt + 1}/{max_retries})")
if attempt == max_retries - 1:
# 最后一次尝试失败,重建 Sandbox
logger.error("多次超时,重建 Sandbox")
sandbox.delete()
sandbox = Sandbox.create(
template_type=TemplateType.BROWSER,
template_name=os.getenv("BROWSER_TEMPLATE_NAME")
)
return operation(sandbox, timeout=60000)
性能问题
问题:响应速度慢
优化建议:
- 使用连接池:预先创建多个 Sandbox 实例
- 启用 keep_alive:保持浏览器会话,避免重复建立连接
- 合理设置超时:根据任务复杂度调整超时时间
- 并发控制:限制并发请求数,避免资源竞争
# 性能优化配置示例
browser_session = BrowserSession(
cdp_url=sandbox.cdp_url,
browser_profile=BrowserProfile(
timeout=30000, # 30秒超时
keep_alive=True, # 保持连接
disable_security=False # 保持安全检查
)
)
错误码参考

总结
通过本指南,您已经掌握了:
- BrowserUse 集成: 如何使用 BrowserUse 框架实现智能浏览器自动化
- 生命周期管理: 三种 Sandbox 管理模式的选择和实现
- 性能优化: 超时配置、复用策略、错误重试机制
- 安全实践: 环境变量保护、URL 白名单、日志脱敏
- 可观测性: 日志记录、指标收集、监控告警
- 成本优化: 按需创建、闲置清理、批量处理
- 生产部署: 高可用架构、健康检查、故障排查
关注「阿里云云原生」公众号,后台回复:BrowserUse
获取参考代码
立即体验函数计算 AgentRun
函数计算 AgentRun 的无代码到高代码演进能力,现已开放体验:
- 快速创建:访问控制台(https://functionai.console.aliyun.com/cn-hangzhou/agent/explore),60 秒创建你的第一个 Agent
- 深度定制:当需要更复杂功能时,一键转换为高代码
- 持续演进:利用函数计算 AgentRun 的基础设施能力,持续优化你的 Agent
从想法到上线,从原型到生产,函数计算 AgentRun 始终是你最好的伙伴。欢迎加入“函数计算 AgentRun 客户群”,钉钉群号: 134570017218 。
快速了解函数计算 AgentRun:
一句话介绍:函数计算 AgentRun 是一个以高代码为核心的一站式 Agentic AI 基础设施平台。秉持生态开放和灵活组装的理念,为企业级 Agent 应用提供从开发、部署到运维的全生命周期管理。

函数计算 AgentRun 架构图
AgentRun 运行时基于阿里云函数计算 FC 构建,继承了 Serverless 计算极致弹性、按量付费、零运维的核心优势。通过深度集成 AgentScope、LangChain、RAGFlow、Mem0 等主流开源生态。函数计算 AgentRun 将 Serverless 的极致弹性、零运维和按量付费的特性与 AI 原生应用场景深度融合,助力企业实现成本与效率的极致优化,平均 TCO 降低 60% 。
让开发者只需专注于 Agent 的业务逻辑创新,无需关心底层基础设施,让 Agentic AI 真正进入企业生产环境。
推荐阅读: