大模型剪枝新范式:先浓缩,再剪枝——DenoiseRotator技术解读
- 论文原文:https://arxiv.org/abs/2505.23049
- 项目地址:https://github.com/Axel-gu/DenoiseRotator
- 视频解读(B 站):https://www.bilibili.com/video/BV1XDUYBTEjr
在大语言模型(LLM)快速发展的今天,庞大的参数规模带来高昂的推理存储成本和回复时延,已成为实际应用中的关键挑战。特别是在面向人机对话的应用场景,模型推理效率直接影响到对话体验。在推理优化方法中,参数剪枝作为一项经典的模型压缩技术,旨在通过剔除模型中“不重要”的权重来实现参数量的显著降低与计算效率的提升。然而,传统的“剪枝-微调”范式或直接的后训练剪枝方法,往往带来明显的模型性能损失,特别是在硬件友好的半结构化稀疏(如 2:4 稀疏)场景下,该问题尤为突出。这使得应用中的模型效果和推理效率,呈现一个“鱼和熊掌”的两难局面。
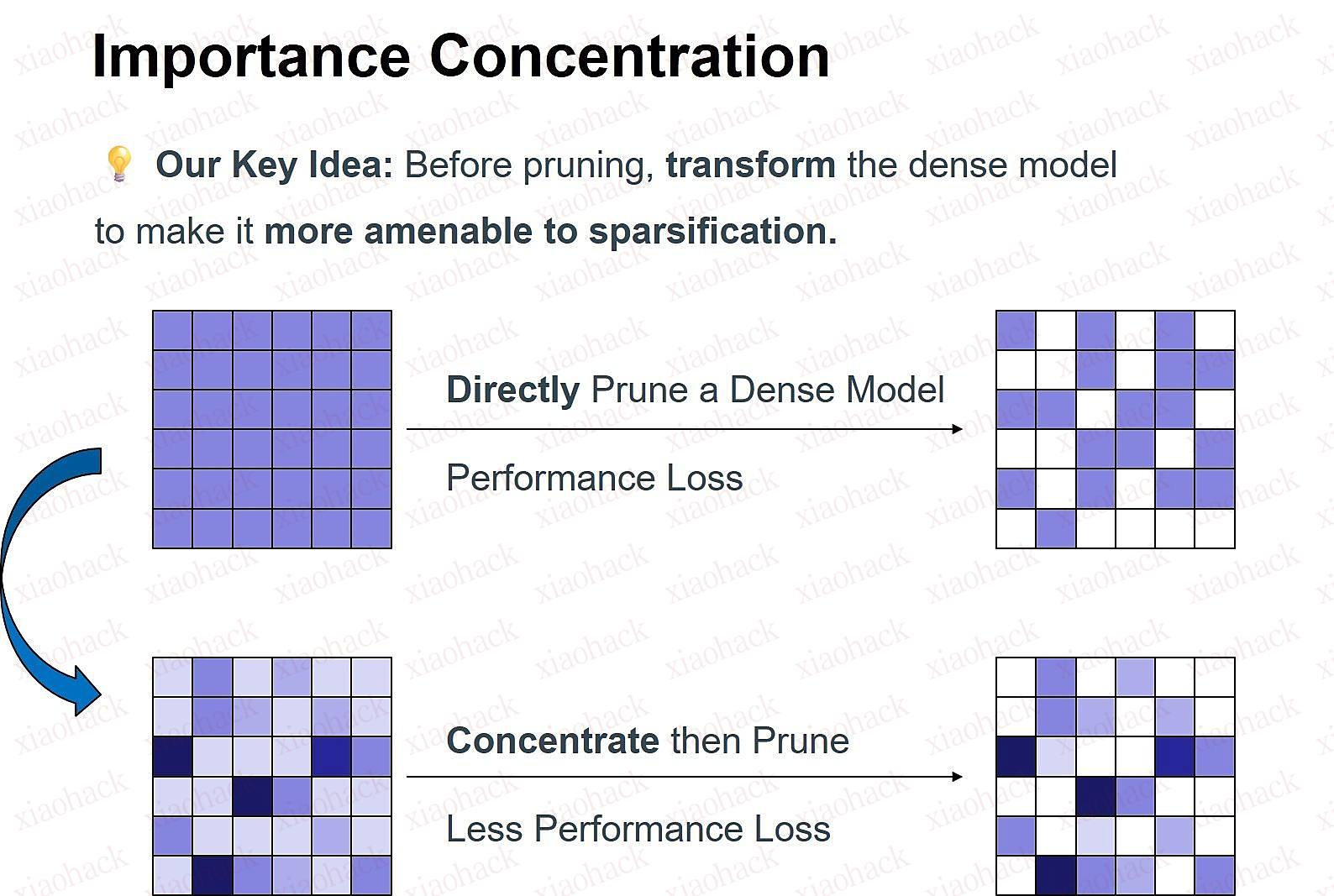
面对这项挑战,美团 LongCat Interaction 团队联合上海交通大学听觉认知与计算声学实验室,以及香港科技大学的研究者,共同完成了大模型剪枝方法的创新研究,提出了名为 DenoiseRotator 的新技术。通过首先对参数矩阵进行变换,“浓缩”对结果有影响力的参数,再对重要性最低的参数进行剪枝,实现了大模型剪枝的新范式。DenoiseRotator 能够与现有的剪枝算法快速集成,有效缓解模型压缩带来的性能损失。这一研究成果已在 2025 年的 NeurIPS 会议上发表。
01 动机:传统剪枝的局限性——密集训练与稀疏推理的隐式冲突
传统后训练剪枝的一般流程可概括为:对一个已训练好的 稠密模型,基于某种启发式准则(如权重幅值或 Wanda、SparseGPT 等算法)为每个参数赋予“重要性分数”,随后根据预设的稀疏度阈值,移除分数较低的一部分权重。 尽管流程清晰,该方法存在一个本质局限:其整个剪枝过程建立在 固定不变的参数空间 上,本质上是一种 被动的筛选机制。这进一步凸显了以下深层冲突:
密集训练 的本质是隐式地激励模型 充分利用每一个参数。每个参数都承载了一定的知识或推理能力,并通过参数间的协同工作共同支撑模型的整体表达能力。
稀疏推理 则要求模型仅基于 被保留的部分参数 完成推理任务,并保持高性能。
这种训练目标与推理机制之间的内在不一致,意味着 直接裁剪必然会导致部分知识或推理能力的丢失,从而破坏原有参数间协同工作的平衡,引发性能下降。
02 技术方案:DenoiseRotator——从“被动筛选”到“主动优化”的范式转变
针对上述挑战,我们重新思考剪枝范式:能否在剪枝前先对模型进行 稀疏性引导的优化,使其 自身结构更易于被剪枝?基于此,我们提出了“重要性浓缩”的全新思路,并开发了 DenoiseRotator 框架予以实现。
2.1 核心思想:重要性浓缩
我们的核心目标是在执行剪枝 之前,将原本分散在众多参数上的重要性,尽可能地 集中到一个较小的参数子集中。这样,在后续剪枝过程中,被移除权重所包含的关键信息将大幅减少,从而显著增强剪枝的鲁棒性。
为量化并优化“浓缩”效果,我们引入了 信息熵 作为衡量指标。通过将参数重要性分数归一化为概率分布,其熵值直接反映了重要性的集中程度:熵越低,表明重要性越集中于少数参数。因此,我们的优化目标明确为 最小化归一化重要性分布的熵。
2.2 实现机制:可学习的正交变换
DenoiseRotator 通过向 Transformer 层中引入 可学习的正交矩阵,实现重要性分布的熵减与浓缩。

如上图所示,我们在 Transformer 层的特定位置(例如 Attention 模块的 Value 和 Output 投影层前后)插入正交矩阵。这些矩阵对原始权重进行“旋转”变换,在 保持模型输出完全不变(得益于正交变换的计算不变性)的前提下,重新分配参数的重要性。
2.3 关键优势
训练与剪枝解耦:DenoiseRotator 采用 模块化设计,正交矩阵的优化与具体剪枝方法完全独立。我们首先利用校准数据,以最小化重要性熵为目标训练这些正交矩阵;训练完成后,将其合并回原始权重。此时,我们获得了一个“易于剪枝”的优化版稠密模型,可 无缝对接 任何现有剪枝工具(如 SparseGPT、Wanda)进行后续操作。
优化过程稳定:正交变换具有保范数特性,确保在重新分布重要性时,既不会人为引入也不会丢失总重要性量,从而保证了优化过程的稳定性,不影响原始模型性能。
下图直观展示了 DenoiseRotator 的有效性。以 LLaMA-3-8B 模型首层输出投影层为例,经我们的方法变换后,参数重要性分布从分散趋于高度集中,为后续剪枝奠定了坚实基础。

03 实验验证
在前文中,我们介绍了 DenoiseRotator 的核心思想——通过重要性浓缩提升剪枝鲁棒性。那么,这一方法在实际效果上表现如何?我们针对多个主流开源大模型进行了全面评测,涵盖语言建模和零样本推理任务,并与现有剪枝方法进行了对比。
3.1 实验设置:覆盖多模型、多任务、多剪枝方法
为全面评估 DenoiseRotator 的有效性,我们在多样化的实验设置下进行了系统性验证。实验覆盖了从 Mistral-7B、LLaMA3(8B/70B)到 Qwen2.5(7B/14B/32B/72B)等多个主流开源大模型,评测任务包括语言建模(使用 WikiText-2 验证集的困惑度 PPL 作为指标)和零样本推理(在 PIQA、WinoGrande、HellaSwag、ARC-e 和 ARC-c 五个基准任务上评估平均准确率)。在基线方法方面,我们将 DenoiseRotator 与三类剪枝方法结合:经典方法 Magnitude,以及先进方法 Wanda 和 SparseGPT,并在非结构化(50%稀疏)和半结构化(2:4 稀疏)两种稀疏模式下进行对比评测。
3.2 主要结果:语言建模与零样本推理全面提升
下表展示了不同模型在剪枝前后的困惑度(衡量语言建模能力)与零样本任务表现。DenoiseRotator 在所有模型和稀疏模式下均显著降低剪枝造成的性能下降,尤其在 2:4 稀疏下提升更为明显。


3.3 深入分析:熵减如何驱动剪枝鲁棒性?
我们通过消融实验验证了 重要性熵与剪枝效果的直接关联。以 LLaMA3-8B 为例,记录不同训练步数下的熵值变化与模型性能:

熵减少 13%(步数 100)即可带来零样本任务准确率提升 3.66%(66.88%➡70.54%),困惑度降低 19.5%(9.567➡7.701)。进一步优化可继续降低困惑度,验证了 重要性集中度与剪枝鲁棒性的正相关。
3.4 部署效率:轻量开销,显著收益

参数增量:每层新增一个(hidden_size, hidden_size)正交矩阵。以 LLaMA3-8B 为例,总参数量增加约 0.5B(占原模型 6.7%)。通过分块对角矩阵(见论文附录)可进一步降低开销,适合资源受限场景。
推理耗时:单层 Transformer 的 2:4 稀疏计算耗时 4.37ms,加入正交矩阵后仅增加 0.32ms(1.24× 加速比 vs 稠密层)。
04 总结
DenoiseRotator 提出了一种创新的剪枝视角:将模型准备(重要性浓缩)与模型压缩(剪枝)两个阶段解耦。通过可学习的正交变换,主动实现参数重要性的浓缩,从而显著提升后续剪枝的鲁棒性。该方法具备 即插即用 的特性,为大规模语言模型的高效、高性能压缩提供了新的技术路径。
项目地址:https://github.com/Axel-gu/DenoiseRotator
希望跟大家一起学习交流。如果大家对这项工作感兴趣,欢迎在 GitHub 上 Star、Fork 并参与讨论!









