科普 | 高帧率、好画质的「光追」是如何实现的?
除了与赛博朋克、公司殖民主义、边缘行者等名词高度绑定,现在当我们提起《赛博朋克 2077》这款游戏,出现在很多人还脑海里的自然也有 CDPR 借助光线追踪、DLSS 等技术在其 RED 引擎中所打造的未来城市「夜之城」。

在 RTX 50 系列显卡推出后,《赛博朋克 2077》也带来了支持最新的 DLSS 技术的 2.21 版本。从一卡难求到如今支持最新技术的游戏作品井喷,「光追」也从早年少数游戏和玩家才能享受的前沿体验变成了 3A 大作不可或缺的「点睛之笔」。那光追、DLSS、帧生成等技术是如何提升游戏体验的?它的出现改变了什么,又解决了哪些问题?
注:本文为《升级「真香」的 RTX 30 系显卡后,你能得到什么?》一文的更新内容,原文部分信息已过时。
传统游戏的光照如何实现
我们所能看见的、五彩斑斓的世界,本质上是因为光在传播中遇到了组成这个世界的、不同材质的物体。光线在这些物体上反射、折射、漫反射、散射……经过不同的光学现象加工之后,特定的光线最终到达人眼,经视网膜感光细胞的处理,我们才得以看到不同颜色的物体。这种原理会带来一些很有意思的变化,比如不同材质的物体从相同角度来看观感不同,相同材质从不同角度看过去的感觉也不一样;在光线很暗的时候,我们自然也很难看清东西。
但同样的「观感」放在游戏世界,所采取的呈现方式则截然不同。在光线追踪技术出现之前,传统的游戏设计在重现光照效果时往往只能从「最终效果」出发,为玩家呈现不同光照环境下,游戏世界所呈现出来的最终效果。
具体的实现原理很好理解:
首先,现代 3D 模型实际上都是通过三角形构成的1,三角形的面数决定了模型的精细程度,模型精度越高,三角形数目也就越多,性能开销也就越大。
这些三角形要显示在我们的电脑屏幕上,还需要经过「光栅化」,即先将三角形用近似连点描边的方式转化成屏幕上的像素2,然后对三角形内部的像素进行上色,同时判断三角形哪些部分被前面其他三角形遮挡了,被遮挡的部分也无需上色,减少不必要的性能开销。
游戏里的光照效果实现,也是在「光栅化」这个过程里完成的——只需要对三角形内部的像素进行额外的上色步骤即可:模型的三角形都有对应的固有颜色(皮肤有固有的肤色、头发有固有的发色),所以将模型转化到二维像素以后,可以通过每个三角形的颜色为每个屏幕上的像素分配一个初始颜色值。接下来要根据场景里的其他光源来进一步的像素处理来改变像素的颜色,最后还需要根据纹理(皮革有皮革的纹理,布料有不同的材质)对像素做最后的处理,进而生成应用于像素的最终颜色。
所以基于光栅化的游戏光线处理,更像是一种对光照结果的「描绘」而非对光照过程的还原。你看到的画面可以被理解为在自行发光,而不是和生活中一样通过折射、反射等手段传递光线。这也就是我们在上面所说的以渲染「最终效果」为主要手段。
光栅化的优点在于可以足够快,程序员可以预先写好光线的程序来处理小面积的光线,还可以制作光照贴图,在需要的时候和环境再进行渲染呈现(静态光照效果)来减少处理压力;但是缺点也很明显:不够真实,比方说游戏中的物体投影大部分时候都是一整块颜色相同的区域(阴影贴图),但是我们仔细观察生活会发现由于光的复杂性实际上的投影由近到远是越来越浅的。
更多关于光栅化不够真实的更多例子可以看这里。
光线追踪提供的逆向解法
相比之下,实时光线追踪可以营造更加真实的光照效果,它通过逆向「追踪」与假想照相机镜头(也就是玩家的「眼睛」或者观察点位置)相交的光作为工作原理,来实现对光线的实时追踪。
之所以反其道而行之,除了光沿直线传播、入射角等于反射角等基本光学原理外,更重要的原因是逆向追踪比真实地模拟光线相互作用的效率要高很多——大部分的光经过多次反射会逐渐消失,最后也不会进入眼睛。减少不必要的模拟会让最后的计算压力小很多。
实时光线追踪技术最终的产物,大家或多或少早在游戏内容外也都接触过了:电影院里的好莱坞大片在特效制作过程中经常会用到光线追踪技术来生成以假乱真的特效场景,这背后往往需要以亿为单位的庞大运算量,每一帧的画面都需要高性能计算机花费数小时的运算——而这还是在提前设计好了场景和环境光线的前提下,游戏的随机性更大,实时光线追踪的实现难度自然也更高。
所以该如何把光线追踪引入到游戏中呢?
2018 年,英伟达发布了第一张支持光线追踪技术 RTX 20 系列显卡,RTX 20 系列中搭载了几组专门的 RT Core 来加速逆向追踪光线的过程,比起 GTX 10 系列,RT Core 在实时光线追踪这件事情上拥有更好的性能,在游戏中开启实时光线追踪后平均帧数也更高。
而 RTX 显卡发展到今天,游戏中的光线追踪也经历了多种实现方式的变迁。其中玩家感受最直观的几种按实现难度来排序分别是:
- 阴影
- 高级反射
- 全局光照
- 全景光线追踪
阴影
阴影的代表游戏就是《古墓丽影》,这也是实时光线追踪最简单的实现方式。只需要确定动态光源的数量和位置就可以给游戏带去动态阴影的效果,在任何的表面和环境下都能获得逼真自然的阴影效果。
高级反射
高级反射的代表游戏是《战地 5》,光线需要实时追踪场景里的所有物体才能正确精准地表现出反射效果,所以很多时候会造成很大的计算压力,因此这里往往还会引入传统的反射处理方法:屏幕空间法,只要画面中你能看到的物件不出现、被遮挡或是不可见,就不会产生反射。这也是为什么有些游戏中镜子看不见背后的人的原因。
在高级反射中后续还引入了,光线可以在所有表面形成反射进一步增强真实感的光线追踪不透明反射,可以在透明表面实现不同亮度反射的光线追踪透明反射,独立光源照亮周围细节或是天空的照明照亮表面的光线追踪漫反射照明等一系列细节更新。


全局光照
最复杂的实时光线追踪方式则是实现全局光照,《地铁:离去》和《控制》都利用了实时光线追踪去实现全局光照。无论是光源、反射还是投影都是实时光线追踪计算得到的,这可以进一步提高光照的准确度,更好地烘托游戏场景和氛围。
全局光照后续还改善了环境光遮蔽会生成的阴影,确保每个角落和裂缝都有正确的阴影投射,从而进一步改善图像质量和沉浸感。不过实现全局光照的压力真的是太大了:在没有 RT Core 的 GTX 系列的显卡上打开《地铁:离去》的实时光线追踪,1080Ti 的表现直接从「高刷模式」掉到了「电影级画质」,帧率从 149 掉到了 38。
全景光线追踪
不难发现,之前提到的阴影、高级反射又或是全局光照,三者在实现上都是针对特定区域或场景内的光源追踪方式。这些实现方式只追踪一部分光源,需要处理的数据相对较少,对应的计算需求自然更低。在过去显卡光追性能较弱的时候,也可以很好地平衡画面效果和显卡价格。
而在《赛博朋克:2077》这类五光十色的游戏世界中,大量使用这类部分光线追踪方式虽然可以塑造一个充满氛围感的赛博朋克世界,但仔细观察仍然能发现光影交错中视觉上不够真实的地方,比如较远距离的建筑投影闪烁、镜面和水面的投影模糊等等。显然,覆盖范围有限的光源追踪无法完全捕获场景中所有的光线轨迹,从远距离的角度观察也一定会遗漏一些微妙的光照变化和阴影效果。
所以随着显卡性能的提升,英伟达在今年也引入了一套新的全景光线追踪实现3。
全景光线追踪可对几乎不限数量的自发光光源的光线特性进行建模,构造出物理意义上更加精准的阴影、反射和全局照明。所以无论场景中光源的数量、方向、或强度如何变化,全景光线追踪均能准确捕捉并在各物体上造成正确的阴影及照明效果,最终提供极其精美的画面质量。

另外,得益于全景光线追踪,来自天空和大气间接光照效果也可以很好得融入到整个游戏画面中。而且相比于分模块实现,整体的光追反倒可以降低开发适配成本,整合多个光源追踪方式提高性能。所以只要游戏支持,比如 2077 中的「光线追踪:超速模式」,对玩家来说游戏画面的效果一定会更好。
至此,摆在游戏光线追踪面前的就只剩下了最后一个问题:性能。正如前面提到的电影工业里的实时光线追踪十分考验计算能力一样,即便有 RT Core 这样的计算核心进行加速,在原生分辨率下开启实时光线追踪也会带来非常严重的帧率下滑;受限于成本,英伟达也不可能无限制地堆砌 RT Core 数量(不然就真的没几个人买得起了)。
有没有什么办法在不降低分辨率的情况下仍能获得稳定的帧率呢?
让高分、高帧率成为可能
既然高分辨率不能达到稳定的帧率,那不如先降低分辨率渲染,再用算法提升到较高的分辨率,这样不就高分辨率和稳定帧率兼得了嘛。
这其实也是目前大部分游戏机的处理 4K 画面输出的办法。但是用什么算法提升分辨率呢?很多人会想到的第一个方法可能是插值。借助插值,我们可以很轻松地将 1080P 画面提升至 4K 分辨率,但简单插值效果并不好,对游戏这种特殊的渲染内容而言,还会带来额外的锯齿。
英伟达最终选择的方案是深度学习,用算法去计算画面,即我们接下来要展开的 DLSS 技术。DLSS 全称 Deep Learning Super Sampling(深度学习超采样),它主要通过 RTX 20 系列引入的 Tensor Core 硬件来加速深度学习,来对实时渲染的图片进行非常高质量的超分辨率。
DLSS 2
在 RTX 30 系列发布前上线的 DLSS 2.0 对比第一代 DLSS 进一步带来了如下改进:
- 4 倍的实时超采样
- 2 倍的处理速度
- 通用模型
- 媲美甚至超越原生分辨率的画面
其中,4 倍的实时超采样足以让我们在一个极低的渲染分辨率下获得一个高分辨率超采样结果,比如游戏只需要渲染一个 540P 的画面,即可生成一个 1080P 的最终画面,大幅度减少显卡压力。加上一点新算法的「调味」,我们最后获得甚至可以超越原生 1080P 的画面。

处理速度方面的提升,主要体现在一段时间内可以处理的帧数会更多了,搭配 4 倍的实时超采样,最后的结果就是渲染性能的暴涨以及游戏帧率的直线上升。以《控制》为例,4K 分辨率下光追效果全开(全局光照),直接把 2060 的 8 FPS 提升到了 36 FPS,让 PPT 有了可玩性,堪称魔法。
而使用通用模型可以快速在多个完全不同的场景、引擎和风格的游戏中部署 DLSS,让所有的游戏利用同一个神经网络实现高质量的超采样。
本来在游戏图形领域,性能和画质绝对是成反比的,要想要更好的画质就一定要牺牲性能。而通过 DLSS 2.0 这种鱼和熊掌兼得的技术,原生分辨率渲染输出很快就变成了过去式。超采样的画面不仅不差,反而可能会更好。
DLSS 3:不仅要高分辨率也要高帧率
虽然大多数的电影还是 24 帧,但在游戏这一场景下,更高的帧率和更稳定的帧速率自然更好。尤其是对一些快节奏的游戏来说,高帧率也能给我们更多的时间来反应并作出更准确的操作。
因此在全景光线追踪对显卡性能提出新要求的同一时间,主攻高帧率的 DLSS 3 多帧生成技术也应运而生。

传统意义上的多帧生成技术分为以下 3 种:
- 帧融合(Frame Blending):最为基础的插帧技术,其工作原理是通过对比两个连续帧之间像素的差异,生成一帧「过渡」图像,这也是很多智能手机、电视上 MEMC 补帧功能的实现方式。这种技术比较简单,适用于简单的场景,但对于复杂的运动和细节可能处理不太好,可能会出现「模糊」的新帧。
- 帧采样(Frame Sampling):一种算法更为复杂的插帧技术,它首先通过一个方式4挑选出一部分帧,再从这些帧生成新的、需要被插入的帧,来提高帧率。这种方法可以处理复杂的运动变化,但依赖于原始画面的质量和内容。
- 光流法(Optical Flow):目前算法最为复杂的插帧技术,通过估计每个像素点在图像序列中的运动,可以生成更精确的新帧。这种技术可以处理更复杂的运动变化,它基于对光的流动进行计算,可以更准确地插值新帧的位置。但这种方法计算复杂,对硬件要求较高,且有的时候也不能达到预期的效果。
然而这 3 种技术在游戏中的应用效果都不一定好,帧融合容易头晕、帧采样可能丢失重要帧,而光流法最后生成的画面不可控。
既然在生成帧结束后再插帧效果都不好,那么为什么不在生成每一帧的时候就针对性地插帧呢?DLSS 3 的帧生成技术采用的正是这种方法:在渲染游戏画面时就生成额外的帧来补齐画面。从实现原理上来说,在对画面完成 DLSS 2 的超分辨率环节以后,DLSS 3 就要开始生成额外的帧了。想要生成额外的帧需要当前游戏帧、前一游戏帧、Ada 光流加速器生成的光流场,以及游戏引擎数据(例如运动矢量和深度)——这里我打算先举一个不算特别恰当的例子辅助大家进行理解。我们可以把 DLSS 3 的所做的事情想象成我们在走路,我们会不断地根据已经走过和看到的路,大概估计下一步脚下的地面会是什么情况。

DLSS 3 也是如此,它会分析当前游戏帧、前一游戏帧,就像我们走路时分析之前已经脚下的路和已经走过的路一样,进而理解像素从第一帧图像到第二帧图像中间发生了什么。
不过如果只看脚下的路,那么走路不是会掉坑里就是会走歪;反映在帧生成的环节里,DLSS 只使用之前的画面来生成帧可能会导致视觉效果异常。我们的大脑会通过已经走过的路面、当前的步伐和方向、我们看到的路的情况,来决定我们接下来一步会走到哪里——要不要避开前面的坑、是不是需要停下或者改变方向。比如前面有个坑,我们就知道要避开它;前面有个台阶,我们就知道要抬高脚步。这个过程,就是我们在根据已经观察到的信息,预测下一步要发生什么,以便做出正确的反应。

这里游戏引擎数据所扮演的角色就像是我们的大脑:除了提前告诉 DLSS 3 一些必要的数据,DLSS 3 也会自行决定如何用上之前的帧、游戏引擎数据、光流法算法,来有的放矢地预测到每个像素在下一帧中的位置,用尽可能少的资源算出更多的画面。

这种级别的图像和引擎数据分析,自然也少不了显卡计算能力的加持,英伟达表示第四代 Tensor Core 推理相比于上一代最高可以提升 4 倍,加上新的光流运算单元,这也使得 DLSS 3 目前只有 RTX 支持这项功能。

不过有利自然也有弊,虽然帧生成技术可以快速产生更多的帧,但这个过程仍然需要额外的时间。所以,帧生成技术可能会导致用户输入延迟增加。简单地讲,当你在游戏中执行一个动作,这个动作的结果(例如角色的移动、环境的变化等)需要在画面中表现出来,正常情况下显卡会立即计算并生成这个结果然后展示在你的屏幕上,这个过程通常是非常快速的;但在使用当使用帧生成技术时,假设用户在第 3 帧的时候按下了一个按钮,根据第 1、2 帧以及游戏引擎数据,在用户的操作输入抵达 GPU 时,可能画面已经预先渲染到了第 4 甚至 5 帧了,真的开始渲染至少要到第 6 帧,最后就多了 3 帧延迟。这对于我们来说最直观的感觉就是不跟手,而对于竞技游戏来说额外的延迟会更加致命。

英伟达在这个问题上的解决思路则很简单:尽可能降低系统延迟,也就是使用 RTX Reflex 技术。这项功能于 2020 年正式发布,但放在 DLSS 3 的环节中,RTX Reflex 可以有效降低 DLSS 3 帧生成技术带来的延迟。


RTX Reflex 的实现原理一方面是减少队列深度,以为后续输入做准备;另一方面则是就是检测到输入时,及时将命令发送到 GPU。我们依然可以用走路来举例:如果我们走在繁忙的街道上,如果提前计划好下面几步的走法(不开启 RTX Reflex 时),那么遇到情况时,比如一个人突然从旁边的小巷走出来,那你即使反应过来了也很有可能撞上那个人,因为你的脚步(GPU 渲染好的画面)已经落后于你的大脑已经做出的决定(我们的输入)。
所以正常情况下,我们的每一走出一步都会有大脑参与,并且任何突发事件都能使我们的行动即刻响应大脑的决策,无需等待之前行动的完成。

RTX Reflex 开启时也是如此,它会尽可能得将用户操作优先传递给 GPU,来让 GPU 生成新的画面。这样既降低了延迟,又能享受帧生成带来的更多画面。
DLSS 3.5:为光线追踪引入深度学习
在 DLSS 3.5 得到应用之前,光线追踪的效果生成一般是放在材质和几何体载入完毕后进行的,此时的游戏世界就像一块没有上色的画布,光线追踪根据游戏内不同类型的模型、材质,计算并模拟反射光、散射光和全局光照在画布中不同位置的呈现效果。

但问题在于,戏内场景千变万化、不同材质对光线的传递效果也各不相同。即便是上面提到的全景光线追踪——因为其实现方式的特殊性(由结果逆推光源和路径)——也无法保证正确判断并渲染画面中的每一个细节。
因此无论是游戏还是上面提到的特效电影,都会在光线追踪效果渲染之前引入一个人为设计的、用于效果优化的降噪器。
这些降噪器以往通常采用时域累积、空间插值两种方法,比如时域累积会选择多个连续帧中质量较高的像素点进行合成,此法能有效减噪并提高像素填充效果;空间插值则是在单一帧内,通过插值相邻像素点的灰度值,产生平滑的图像效果。

但无论哪种降噪方案都有其弊端,时域积累会合成不正确的画面、空间插值则会影响全局光照和反射效果……人工设计的降噪器在设计和实际应用中也有诸多难以应对实际状况的地方。
要解决这些局部细节上的「不对劲」,担任调色板和笔刷角色的降噪器就必须更加高效且更加聪明,足以在瞬息万变的游戏环境中决定画面中每个细节应该如何修改和调整。于是便有了 DLSS 3.5 光线重建(Ray Reconstruction/RR)的引入。
前面提到 DLSS 的全称是 Deep Learning Super Sampling(深度学习的超采样),9 月上线的《赛博朋克 2077》 2.0 版本更新中所搭载的 DLSS 3.5,则将这项超采样能力扩展到了提高分辨率、帧率之外——让深度学习参与光线追踪最终呈现效果的生成环节。
光线重建的核心理念在于,将光线追踪光照处理流程中的人工设计组件,改为效率更高、由深度学习驱动的 AI 模型。在大量训练素材的积累下,光线重建就像经验丰富的画家,不仅有更优质的工具,对游戏内的环境和世界也有更独特、更专业的看法和理解;他知道如何融合不同的颜色、纹理和运动,他熟知如何尽可能保留细腻的光照效果,并能善用各种手法来呈现各种光照效果。


最终,在《赛博朋克 2077》的世界中,原本就已经足够惊艳的夜之城在视觉上也更能经得起眼尖玩家的鉴赏了。在我们的实际测试中,远处建筑的阴影几乎没有以往频繁出现的闪烁、跳动问题,地面倒影中的霓虹灯广告牌细节清晰可见……无论是近景还是远眺,都几乎不会发现那些原本会打破游戏世界沉浸感的小问题了。

DLSS 4:能「理解」画面的超分辨率模型、渲染 1 帧得 4 帧的多帧生成
在详细介绍 DLSS 4 之前,我们先要简单介绍一下 DLSS 4 包含了哪些新功能:一个是大多数老显卡都能得到的升级,光线重建、画面超分辨率、深度学习抗锯齿换用了新的 Transformer 模型;一个则是 RTX 50 系列独占的渲染 1 帧得 4 帧的多帧生成功能;以及配合新的渲染延迟降低算法 Reflex 2。

Transformer 模型和之前 DLSS 模型普遍采用的 CNN 模型一样,都是深度学习模型,他们最终达成的目的也很相似——处理数据、提取特征。
CNN 从原理上来说擅长提取局部信息,但对容易处理了新的数据就忘记旧的数据。更形象点地说,基于 CNN 的 DLSS 就像是一个放大镜。它会先从照片的一个小区域开始观察,然后逐渐移动到其他区域,每次都专注于那些局部细节(比如一个物体的边缘或颜色)。最后再像拼图游戏一样,把每块都都拼凑起来变成一个完整的图像。

由于每个小区域的特征都用了相同的放大方式(无论图中物体出现在什么位置),所以这种方法很高效、参数少,也很擅长识别局部特征再放大出来。CNN 的短处就是依赖小块的信息,会错失整体关系。举个游戏里最常见的例子来说,电线被基于 CNN 的 DLSS 放大以后,电线变成「锯齿形」了,在一些极端的运动场景里,甚至还会让电线不停「闪烁」。

随着大语言模型 LLM 的各种营销,相信不少人对 Transformer 模型也略有耳闻,受限于篇幅我们这里也不展开介绍 Transformer 的细节了,具体细节可以一步这篇文章。在这里我们只需要知道,Transformer 模型会捕捉全局特征、会通过上下文信息推断依赖关系。

这样基于 Transformer 模型的 DLSS 就像是一个导演,他不会只看一张图片里的某一小部分,而是结合之前渲染好的画面一起考虑。通过分析画面中的元素、元素的前后遮挡关系,Transformer 模型能更准确地理解整体场景和具体的模型。换句话来说 DLSS 4 能「理解」3D 模型具体是什么,过去的画面里和将要渲染出来的画面里这个 3D 模型长什么样。再根据不同的放大方式放大对应的物体,这样不仅传统的画面会更稳定,重影、运动模糊会更少,而且在光线重建的过程中光源的闪烁问题也变得更少见了。这里依然以 CNN 做不好的电线为例,在换用 DLSS 4 以后明显就顺滑很多。

Transformer 模型唯一的问题就是资源开销会比 CNN 高得多,在 4080 上打开最新的 DLSS 4 以后显卡计算占用和显存占用明显会高于之前的 DLSS 版本。

RTX 50 系列显卡的多帧生成技术则是 DLSS 3 插帧技术的的进一步升级。DLSS 3 插帧技术需要在渲染游戏画面时,就需要当前游戏帧、前一游戏帧、光流场、游戏引擎数据(例如运动矢量和深度) 等等众多的数据一同参与运算,才能生成额外的帧。

只生成一帧可能看起来还好,但想要生成更多的帧,就需要那么嵌套计算这些数据,显卡自然也需要在硬件上有额外的处理单元。对于老黄这样的「刀法大成」的成本控制专家来说是不能用这个方案的,即使真的用了售价上天我们也不会买账。

RTX 50 系列则从软件和硬件两方面入手解决了多帧生成的问题。首先是软件上,提升了 40% 的帧生成模型的速度,帧生成所需要的显存也减少了 30%,为多帧生成打下了基础,这个基础 40 系列也能享受到。
在硬件上,RTX 50 系列砍掉了一直以来 RTX 上的光流加速单元,这个单元主要通过计算图像连续帧之间的亮度变化来估计每个像素的运动。换用通过人工智能模型来估计每个像素的运动,加上通用的计算单元来减少额外的帧生成所需要的成本,多帧生成的计算量也就下来了。

但是 120Hz 的屏幕两次刷新间隔是 8.33ms。所以显卡需要用更短的时间完成:画面超分辨率、光线重建以及多帧生成这样多个步骤,每个步骤内还有一个甚至多个 AI 模型要跑。所以 RTX 50 系列也升级到了第 5 代张量核心(Tensor),NVIDIA 表示相比于上一代有 2.5 倍的 AI 处理性能的提升,这样满足多帧生成的硬件也有了。
但生成帧除了生成,还要保证帧与帧间隔均匀,帧间隔不均匀即是帧率再高人看起来也会卡顿。过去 DLSS 3 主要依赖于 CPU 控制,但是 CPU 调度本身存在的不确定性,额外生成的帧可能无法严格遵循固定的时间间隔同步到显示器上,帧间节奏的不一致性,视觉上的流畅度就变差了。
RTX 50 在生成多个帧以后,会用显卡内部的 Flip Metering 硬件将控制帧同步的逻辑交给显示引擎,作为显卡自然能更精准地把画面同步到显示器上,加上提高了两倍的像素处理能力的显示引擎。在画面性能模式下,DLSS 4 的多帧生成最多可以只用 1 个像素渲染额外 15 个像素。高帧率畅玩带有光线跟踪的 3A 游戏或许真不远了。

有了新的多帧生成,降低渲染的 Reflex 技术也迭代到了 2 代。Reflex 2 在 1 代的基础上引入了新的「Frame Warp」(帧扭曲)的功能。当 GPU 渲染某一帧时,CPU 会根据最新的鼠标或手柄输入计算下一帧的视角位置。而 Frame Warp 会立即从 CPU 采样新的视角位置,并将 GPU 刚刚渲染的帧调整至最新视角。在渲染帧被发送到显示器之前,尽可能最新的视角数据扭转渲染好画面,确保屏幕上呈现最新的鼠标输入的画面。

为了配合 Frame Warp 功能导致的图像出现撕裂或缝隙、以及出现的新场景,NVIDIA 也配套开发了一个延迟的预测渲染算法,该算法会使用来自先前帧的视角、颜色和深度数据,对这些撕裂准确修复图像。NVIDIA 还表示,Reflex 2 未来还会下放给其他的 RTX GPU 显卡。

DLSS 4.5:「力大砖飞」带来更原生的画面、支持 6 倍多帧生成
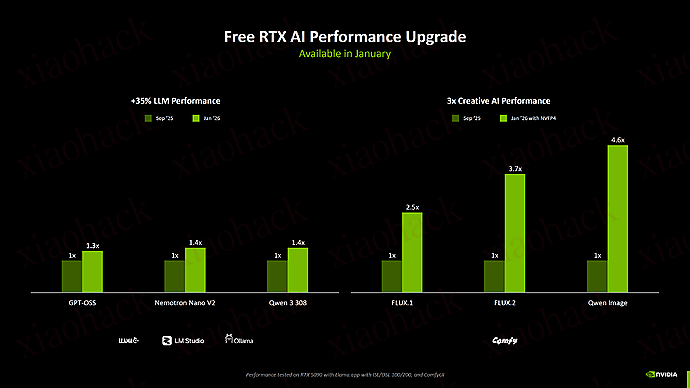
不出意外,在 2026 年 CES 首日老黄端出了最新的 DLSS 4.5 技术,看名字就知道这是 2025 年 DLSS 4 的「升级版」。DLSS 4.5 主要升级了 DLSS 模型、支持在 RTX 50 系列的显卡上生成 6 倍帧,并将在未来支持动态多帧⽣成技术。
全新 DLSS 模型:更接近原生渲染
DLSS 4.5 延续了 DLSS 4 上使用的Transformer 模型的思路,只不过新的模型采用了更大的 Transformer 模型。
Transformer 模型的大小我们可以简单理解成:「这个模型可以支持多复杂的情况」。想要支持更复杂的情况,Transformer 模型也就需要越大,自然能做到的事情也就越多。举个可能更易懂的情况,就好比 OpenAI、Google 商业公司在经历多年的迭代以后,模型已经从从原来基本只能拿来聊天、做一些简单的问答与改写,到现在已经能稳定完成规划、撰写代码这样的需要更长链路推理的情景了。
不过「更大」不意味着「一定更好」,参数量上去之后会有明显的边际递减效应,而且更大的 Transformer 也代表着不管是训练还是后面使用,都需要占用更高的算力和更大的显存。
有了这个基本的认识以后,我们再来看 DLSS 4.5 里这个新模型,NVIDIA 表示这个新模型是在一个「⼤幅扩展的⾼保真数据集上完成训练」,而结果则是:
……对每个场景都有更深⼊的理解,并能更智能地利⽤游戏引擎的像素采样和动态数据,从⽽呈现具有更佳光照、更精细边缘和动态清晰度的图像。

在我看来,NVDIA 的 DLSS 4.5 走的是「力大砖飞」的思路:通过显著提升模型容量,来覆盖更复杂、更多的渲染场景,尤其是以往基于 CNN 或较小模型难以稳定处理的情况,例如透明或半透明材质中常见的鬼影与闪烁问题。
所以 DLSS 4.5 在整体稳定性和细节一致性上都有明显改善,最终呈现出的画面观感也更接近原生渲染。
不再糊成一团的高频细节
除了让画面效果更接近原生渲染,DLSS 4.5 还对游戏中降噪方式和高频细节保留的方式做了优化。许多人可能认为,只要角色保持静止,屏幕上所有的像素亮度就自然保持不变。
但在游戏这种实时 3D 渲染的场景里,画面是一个随时间持续变化的窗口。每一帧都会重复回答同一个问题:每个像素此刻应当有多亮。即使角色没有任何主动操作,游戏中依然会通过多种细节变化来增强沉浸感,从而影响最终画面的渲染过程,比如:
- 角色的呼吸模拟
- 角色的待机动作
- 周围环境的细微变化
这些因素都会导致 3D 模型在映射到 2D 屏幕时落在不同的屏幕像素上,这样每一帧在渲染时每个像素点亮度都不一样,因为屏幕上每个像素都应该反应实时变化。

更不用说,在游戏画面渲染中还存在着大量的浮点运算,浮点数小数点后面的 N 位发生一点变化,也可能会导致渲染的分支路径不同,让实际像素的亮度发生变化。
而且哪怕是来了什么外星科技,也不存在让渲染像素出现亮度不变的情况,同时性对比效应也会影响视觉观感。下面我们举一个比较极端的例子:如果有一簇像素在上一帧大部分覆盖比较明亮物体,而在这一帧又覆盖了比较暗淡的背景。哪怕这簇像素本身的亮度也没变化,给我们的带来的视觉亮度也一直在改变。

而人眼人眼对亮度变化的敏感度,又远高于色彩变化。不管是这个像素亮度真的发生了变化,还是同时性对比效应导致的亮度感知变化,即使变化幅度很小,但只要出现得足够频繁,就会被我们感知到。从我们的视角来看,就是游戏画面里有很多闪烁的噪点,比如模型边缘的锯齿,看着毛毛躁躁的很不舒服。
要让画面舒服起来,就要减少画面里这些闪烁的噪点。这个逻辑也自然影响到了后续各种抗锯齿算法以及早期 DLSS 画面超分技术的设计取向:稳定但稍微模糊的画面远好于清晰但不断闪烁的画面。早期 DLSS 在设计上也是这样做的:只有跨帧一致的像素才是可信的真像素,才能在这个基础上超分、补帧;宁可抹掉不确定信息、尽量减少变化,让画面稳定,至于细节是可以被牺牲的。

很不幸的是,像是铁丝网、屋檐、玻璃纹理、武器边缘花纹这样的高对比度,也被称为高频细节也一样会被各种抗锯齿算法或者早期 DLSS 画面超分技术误认为是闪烁,而被压到没有。反映到游戏里一些原本真实存在、且在物理上完全合理的高频细节,会直接糊成一团。比如原本应该清晰的物体边缘,在移动时反而变得更糊了;又或者角色或镜头一移动,远处细节立刻丢失。

相比于过去简单粗暴地抹掉细节,DLSS 4.5 选了另一条简单粗暴的路:拿到数据硬算,从而知道哪些是真噪点,哪些是细节。因为在渲染画面时,游戏引擎本来就在计算各种光照的具体情况,那 DLSS 4.5 不如就对着这个数据算。更形象得说就是,DLSS 4.5 就是通过理解光,来分辨哪些是真的细节,哪些是噪点。
这种变化在 DLSS 4.5 加持的游戏画面中的体现非常直观,比如:强反射表面和亮部能够保留完整的亮度层次与色域信息,不再发灰;暗部与阴影也不必再为整体观感,而牺牲细节的清晰度。


更大的资源占用
前面我也提到过,更大的 Transformer 也代表着更高的算力占用。在显卡上主要就体现在,渲染延迟和游戏时的显存占用。根据《NVIDIA DLSS Super Resolution (version 310.5.0)》里提供的数据:
其中,模型 J, K 是 DLSS 4 相关的两个模型;预设 M 是标准的 DLSS 4.5 超分模型,也是 NVIDIA app 中最新(Lastest)选项使用的模型;而预设 L 是针 4K 分辨率下的超⾼性能模式优化的模型。
| RTX 50/40 系列 | 预设 | 1080P | 2K | 4K |
| [显存占用] | J, K | 85.77MB | 143.54MB | 307.37MB |
| L | 118.36MB | 207.97MB | 464MB | |
| M | 120.27MB | 211.42MB | 471.84MB |
| RTX 30/20 系列 | 预设 | 1080P | 2K | 4K |
| [显存占用] | J, K | 85.77MB | 143.54MB | 307.37MB |
| L | 159.24MB | 279.28MB | 618.43MB | |
| M | 161.10MB | 282.67MB | 626.2MB |
| 2080Ti | 预设 | 1080P | 2K | 4K |
| [渲染延迟(DLSS 性能模式)] | J, K | 1.16ms | 1.80ms | 3.5ms |
| L | 3.51ms | 5.45ms | 10.60ms | |
| M | 1.95ms | 3.41ms | 7.51ms |
| 3080Ti | 预设 | 1080P | 2K | 4K |
| [渲染延迟(DLSS 性能模式)] | J, K | 0.65ms | 1.02ms | 2.06ms |
| L | 1.67ms | 2.63ms | 5.32ms | |
| M | 1.19ms | 2.04ms | 4.35ms |
| 4080 | 预设 | 1080P | 2K | 4K |
| [渲染延迟(DLSS 性能模式)] | J, K | 0.47ms | 0.71ms | 1.49ms |
| L | 0.79ms | 1.19ms | 2.51ms | |
| M | 0.54ms | 0.92ms | 2.08ms |
| 5080 | 预设 | 1080P | 2K | 4K |
| [渲染延迟(DLSS 性能模式)] | J, K | 0.46ms | 0.68ms | 1.31ms |
| L | 0.78ms | 1.16ms | 2.24ms | |
| M | 0.49ms | 0.80ms | 1.74ms |
可以看到 DLSS 4.5 模型,不管是需要的显存和帧生成所需要的时间都显著高于 DLSS 4 模型所需要的量。而且相比于 RTX 50/40 系列,RTX 30/20 系列在使用 DLSS 4.5 时所需要的显存和帧生成延迟还会更高。
背后的道理也很好理解,比较在同样分辨率、同样 DLSS 档位下,每帧 DLSS 推理要算的东西更多了,自然 Tensor Core 的压力更大。而 RTX 40 系列开始,NVIDIA 给显卡配备了更快的、更先进、支持FP8 精度计算的 Tensor Core,通过更高等级的运算单元来让第二代 Transformer 的性能代价变小,也不失为一个解决方案。通俗地说,就是 RTX 40/50 在 DLSS 4.5 上有硬件红利。
但这不意味着 RTX 30/20 就不适合用 DLSS 4.5 了,在相对没那么极限的游戏场景中(比如《古墓丽影:暗影》这类相对较老、但支持 DLSS 特性的游戏),牺牲一点点帧率或者降低一档 DLSS 档位就能获得远胜于 DLSS 4 技术的画面,何乐而不为呢?
多帧生成:高达 6 倍的多帧生成、静态元素优化以及动态多帧生成
RTX 50 系列显卡的多帧生成技术在 DLSS 4.5 以后,从原先的 4 倍多帧生成升级到了 6 倍。
这个提升我认为是 DLSS 4.5 帧生成模型变得更高效了,生成 5 个额外帧的过程不需要额外推理 5 次,每个真渲染帧只需要运行一次推理,接着使用来自游戏引擎的后续物理数据,就能直接生成 5 个、额外的、符合画面运动效果的额外帧。

而且得益于 DLSS 4.5 针对画面放大也变得更稳定、更真实了,这样多帧生成时所依赖的参考帧可信度也明显提升,自然多帧生成导致的画面鬼影、抖动的情况自然也变少了。所以 2026 年打开路径光追的 3A 游戏也能有高刷体验。

DLSS 4.5 的帧生成模型还针对游戏中的界面元素(UI)做出的优化,因为 UI 通常不遵循世界运动矢量规律,这种「静态」元素也是最容易在生成帧里出现抖动/重影现象的元素。DLSS 4.5 选择将游戏引擎数据融合进模型,这样不管是准星还是迷你地图,DLSS 4.5 多帧生成出来的静态元素也变稳定了。

由于 DLSS 4.5 支持了 6 倍帧生成,不过这就引出了另一个问题,我们真的时时刻刻需要那么多帧吗?毕竟站在 2026 年年初的这个时间点,大多数的显示器「电竞」(高刷新率)属性和「专业」(高分辨率、HDR)属性通常只会二选一,那怕是两者兼得的显示器一般也要切换模式,更别说 360Hz 刷新率的显示器价格也不便宜了。

所以我的观点是,有 6 倍的帧生成可以,但没必要时时刻刻生成超过显示器刷新率的帧,只需要游戏画面不卡顿不撕裂就可以了。而 NVIDIA 给出的解决方案是动态多帧生成,从今年春季开始 RTX50 系列的多帧生成不会采用固定的帧率倍数,而是根据显示器刷新率或游戏设置的目标帧率,自动在在不同的帧率倍数之间切换。
这样在图形密集的场景里 DLSS 就能拉高生成倍率,补足更多的帧;而在渲染压力没那么大的场景就能降低生成倍率,只生成需要的帧,来降低功耗和风扇噪音。
怎么用
想要用上 DLSS 4.5,还有些额外的细节值得注意。首先是软件上的细节,我们要把 NVIDIAapp 升级到 11.0.6 版本以上,并升级到最新的 NVIDIA 显卡驱动。

而在最新的 NVIDIA app 中,原先的 Latest(最新)选项被移除了,转而引入了新的 Recommended(推荐)选项。在推荐模式下,NVIDIA 表示:如果你在游戏中 DLSS 选项选择了「性能模式」将会调用预设 M、「超级性能模式」则会调用预设 L,其他模式则继续使用 K。但预设 M 和 L 也都支持 DLSS 超分辨率质量和平衡模式以及 DLAA 抗锯齿。
所以想要用上 DLSS 4.5,也是有那么一点点门槛的。但大致分为两个方法:
- 在游戏中,DLSS 选项设置为「性能模式」或「超级性能模式」档;
- 在 NVIDIA app 中,针对全局或者单个游戏设置 DLSS 覆盖模式,Super Resolution(超分辨率)设置为预设 M 或预设 L。

要确认是不是用上了 DLSS 4.5 也很简单,可以在游戏中,按下 Alt+ Z ,选择「统计(Statistics)」-「统计视图 (Statistics View) 」,切换到 DLSS 打开 NVIDIA App 浮窗统计信息视图,查看当前使用的模型即可。

参考链接:
- NVIDIADLSS 4 支持多帧生成,并可为全套 DLSS 技术带来提升
- 采用全新 Frame Warp 技术的NVIDIAReflex 2 降低高达 75%的游戏延迟
- NVIDIADLSS 3.5:借助 AI 提升光线追踪;“心灵杀手 2 (Alan Wake 2)”、“赛博朋克 2077:往日之影 (Cyberpunk 2077: Phantom Liberty)”、“传送门 RTX 版 (Portal with RTX)”等游戏将于今年秋季支持 DLSS 3.5
- “赛博朋克 2077:往日之影 (Cyberpunk 2077:Phantom Liberty)”现已支持NVIDIADLSS 3.5 和全景光线追踪技术
- 升级「真香」的 RTX 30 系显卡后,你能得到什么?
> 关注 少数派公众号,解锁全新阅读体验 📰
> 实用、好用的 正版软件,少数派为你呈现 🚀