Skills 与延迟加载工具定义的 MCP,目前哪个更高效、稳定和可控?
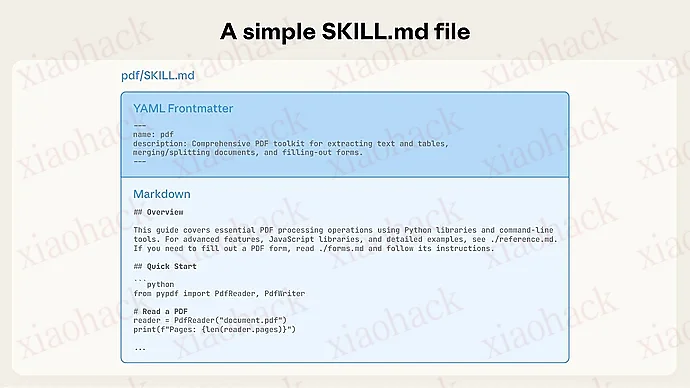
编者按: 我们今天为大家带来的这篇文章,作者的核心观点是:相较于依赖复杂且高成本的动态 MCP 工具加载机制,以 Skills 为核心的能力摘要与自维护模式,在当前阶段反而更加高效、稳定且可控。 文章系统梳理了延迟工具加载(deferred tool loading)的工程现实与限制,指出即便工具可以延后注入,对话级别的工具集合仍然是静态的,且发现机制高度依赖正则匹配,收益并不如预期。作者进一步深入分析了 MCP 在上下文占用、API 稳定性、缓存失效与推理轨迹丢失等方面带来的隐性成本,并结合 Sentry MCP、Playwright 等实践案例,说明为何将 MCP 转换为 Skills,反而能让 Agent 更好地发挥既有工具的能力。文章最后还探讨了 MCP 是否可能完全转化为 Skills 的可行性,并坦率指出当前协议与生态在稳定性与摘要机制上的不足。 作者 | Armin Ronacher (作者为 Flask、Jinja2 等开源项目的创建者) 编译 | 岳扬 我正把所有的 MCP 都迁移到 Skills 上,包括之前还在使用的最后一个:Sentry MCP(译者注:Sentry 是流行的应用监控与错误追踪平台)。早前我就已经完全弃用 Playwright(译者注:由 Microsoft 开发的现代 Web 自动化测试和浏览器自动化框架),转向使用 Playwright Skill。 过去一个月左右,关于使用“动态工具配置(dynamic tool loadouts)[1]”来推迟工具定义的加载的讨论一直不少。Anthropic 也在探索通过代码来串联 MCP 调用的思路,这一点我也尝试过[2]。 我想分享一下自己在这方面的最新心得,以及为什么 Anthropic 提出的“延迟工具加载方案(deferred tool loading)”并未改变我对 MCP 的看法。或许这些内容对他人会有所帮助。 当 Agent 通过强化学习或其他方式接触到工具定义时,它会被鼓励在遇到适合使用该工具的场景时,通过特殊的 token 输出工具调用。实际上,工具定义只能出现在系统提示词(system prompt)中特定的工具定义 token 之间。从历史经验来看,这意味着我们无法在对话状态的中途动态发出新的工具定义。因此,唯一的现实选择是在对话开始时就将工具加载好。 在智能体应用场景中,我们当然可以随时压缩对话状态,或更改系统消息中的工具定义。但这样做的后果是,我们会丢失推理轨迹(reasoning traces)以及缓存(cache)。以 Anthropic 为例,这将大幅增加对话成本:基本上就是从头开始,相比于缓存读取,需要支付完整的 token 费用,外加缓存写入成本。 Anthropic 最近的一项创新是“延迟工具加载”(deferred tool loading)。我们仍然需要提前在系统提示词(system message)中声明工具,但这些工具不会在系统提示词发出时就注入到对话中,而是会稍后才出现。不过据我所知,这些工具定义在整个对话过程中仍必须是静态的 —— 也就是说,哪些工具可能存在,是在对话开始时就确定好的。 Anthropic 发现这些工具的方式,纯粹是通过正则表达式(regex)搜索实现的。 尽管带延迟加载的 MCP 感觉上应该表现更优,实际上却需要在 LLM API 端做不少工程化工作。而 Skills 系统完全不需要这些,至少从我的经验来看,其表现依然更胜一筹。 Skills 实质上只是对现有能力及其说明文件位置的简短摘要。这些信息会被主动加载到上下文中。 因此,智能体能在系统上下文里(或上下文的其他位置)知晓自己具备哪些能力,并获知如何使用这些能力的“手册链接”。 关键在于,Skills 并不会真正把工具定义加载到上下文中。 可用工具保持不变:bash 以及智能体已有的其他工具。Skills 所能提供的,只是如何更高效使用这些工具的技巧和方法。 由于 Skills 主要教的是如何使用其他命令行工具和类似实用程序,因此组合与协调这些工具的基本方式其实并未改变。让 Claude 系列模型成为优秀工具调用者的强化学习机制,恰好能帮助处理这些新发现的工具。 这自然引出了一个问题:既然 Skills 效果这么好,我能不能把 MCP 完全移出上下文,转而像 Anthropic 提议的那样,通过 CLI 来调用它?答案是:可以,但效果并不好。Peter Steinberger 的 mcporter[3] 就是其中一种方案。简单来说,它会读取 .mcp.json 文件,并将背后的 MCP 暴露为可调用的工具: 确实,它看起来非常像一个 LLM 可以调用的命令行工具。但问题在于,LLM 根本不知道有哪些工具可用 —— 现在你得专门教它。于是你可能会想:那为什么不创建一些 Skills,来教 LLM 了解这些 MCP 呢?对我而言,这里的问题在于:MCP 服务器根本没有维持 API 稳定性的意愿。它们越来越倾向于将工具定义精简到极致,只为节省 token。 这种做法有其道理,但对 Skills 模式来说却适得其反。举个例子,Sentry MCP 服务器曾彻底将查询语法切换为自然语言。这对 Agent 来说是一次重大改进,但我之前关于如何使用它的建议反而成了障碍,而且我没能第一时间发现问题。 这其实和 Anthropic 的“延迟工具加载方案”非常相似:上下文中完全没有任何关于该工具的信息,我们必须手动创建一份摘要。我们过去对 MCP 工具采用的预加载(eager loading)方式,如今陷入了一个尴尬的局面:描述既太长,不便预加载;又太短,无法真正教会 Agent 如何使用它们。 因此,至少从我的经验来看,你最终还是得为通过 mcporter 或类似方式暴露出来的 MCP 工具,手动维护这些 Skills 摘要。 这让我得出了目前的结论:我倾向于选择最省事的方式,也就是让 Agent 自己以“Skills”的形式编写所需的工具。 这样做不仅耗时不多,最大的好处还在于工具基本处于我的掌控之中。每当它出问题或需要新增功能时,我就让 Agent 去调整它。Sentry MCP 就是个很好的例子 —— 我认为它可能是目前设计得最好的 MCP 之一,但我已经不再使用它了。一方面是因为一旦在上下文中立即加载它,就会直接消耗约 8k 个 token;另一方面,我也一直没能通过 mcporter 让它正常工作。现在我让 Claude 为我维护一个对应的 Skill。没错,这个 Skill 可能有不少 bug,也需要不断更新,但由于是 Agent 自己维护的,整体效果反而更好。 当然,这一切很可能在未来发生变化。但就目前而言,手动维护的 Skills,以及让 Agent 自行编写工具,已成为我的首选方式。我推测,基于 MCP 的动态工具加载终将成为主流,但要实现这一点,可能还需要一系列协议层面的改进,以便引入类似 Skills 的摘要机制,以及为工具内置使用手册。 我也认为,MCP 如果能具备更强的协议稳定性,将大有裨益。目前 MCP 服务器随意更改工具描述的做法,与那些已经固化下来的调用方式(materialized calls)以及在 README 和技能文件中编写的外部工具说明很难兼容。 END 本期互动内容 🍻 ❓抛开现有方案,你理想中的AI工具调用范式应该长什么样?用一句话描述你最核心的需求。 文中链接 [1]https://www.anthropic.com/engineering/advanced-tool-use [2]https://lucumr.pocoo.org/2025/7/3/tools/ [3]https://github.com/steipete/mcporter 原文链接:01 什么是工具(Tool)?
02 与 Skills 的对比
03 MCP 能否转换为 Skills?
npx mcporter call 'linear.create_comment(issueId: "ENG-123", body: "Looks good!")'04 最省事的路线