trump 搞事
川普表示,美军已摧毁伊朗最重要的石油出口枢纽——哈尔克岛( Kharg Island )上的所有军事目标。他称自己“出于克制”暂未攻击石油基础设施,但警告称:如果伊朗继续干扰霍尔木兹海峡航运,美国将“立即重新考虑”这一决定。
哈尔克岛承担着伊朗约 90%的石油出口。一旦其石油设施被摧毁,不仅会重创伊朗经济,还可能使伊朗原油基本退出全球市场,推动国际油价大幅飙升。
同时,川普已批准对俄罗斯石油采购的 30 天豁免,美国也正在向中东增派军事力量,地区局势进一步升级
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
川普表示,美军已摧毁伊朗最重要的石油出口枢纽——哈尔克岛( Kharg Island )上的所有军事目标。他称自己“出于克制”暂未攻击石油基础设施,但警告称:如果伊朗继续干扰霍尔木兹海峡航运,美国将“立即重新考虑”这一决定。
哈尔克岛承担着伊朗约 90%的石油出口。一旦其石油设施被摧毁,不仅会重创伊朗经济,还可能使伊朗原油基本退出全球市场,推动国际油价大幅飙升。
同时,川普已批准对俄罗斯石油采购的 30 天豁免,美国也正在向中东增派军事力量,地区局势进一步升级
找工作,要把握好。
开发者朋友们大家好: 这里是 「RTE 开发者日报」,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的技术」、「有亮点的产品」、「有思考的文章」、「有态度的观点」、「有看点的活动」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。 本期编辑:@koki、@鲍勃 1、微信被曝自有独立 AI 模型,计划年内落地 据报道,腾讯正在打造一款「绝密级」AI 智能体,它直接内嵌进微信,能够帮你打车、买菜、订机票、是一个全程代劳的「真·生活管家」。 值得一提的是,腾讯曾经也把旗下独立 AI APP 元宝塞进了微信,但本质上它只是个聊天助手,离真正的 AI 智能体仍有一定差距。 而微信在 AI 进展缓慢的原因,一定程度上是基于战略上的谨慎。 微信有 14 亿月活,任何一个不成熟的功能,都可能引发大规模负面体验。据了解腾讯高管想法的人士透露,正是这种顾虑,让微信团队一直没敢轻举妄动。 这个项目从去年上半年就开始酝酿,内部被列为「最高优先级绝密项目」。 核心思路只有一个:把 AI 智能体接入微信生态里的百万小程序。 这个项目另一个值得关注的细节是:微信团队目前没有使用腾讯自研的混元(Hunyuan)模型,而是在测试智谱、阿里、DeepSeek,甚至微信自己开发的小型模型。原因很直接,混元的综合性能还没达到业内顶尖水平。 诚然,阿里和字节的优势在于服务生态的深度整合,但它们的核心产品(通义、豆包)本质上都是用户需要主动打开的独立 App。 微信不一样。微信是中国人手机上卸载不了的应用,是社交关系的承载体,是日常生活的操作系统。当 AI 智能体内嵌进微信,它不需要教育用户「去用一个新 App」,用户本来就在这里,每天都在这里。 这是微信做 AI 智能体最深的护城河,也是阿里和字节最难复制的壁垒。而按腾讯这次的准备力度来看,他们显然不打算再用半成品去赌这个答案。一旦出手,很有可能就是降维打击。 (@APPSO) 2、Kaltura 发布 Agentic Avatars:支持 SDK 嵌入的生产级实时多模态对话智能体 数字体验平台 Kaltura 宣布正式推出 Agentic Avatars,这是一类集成了组织智力与业务意图的实时视频 AI 智能体。该系统不仅作为独立应用,更以 Conversational Agents SDK 形式开放,允许开发者将支持多模态感知的虚拟人交互深度集成至自有 App、工作流及企业数据系统(CRM/ERP)中。 技术特性与交互架构 通过 Conversational Agents SDK,开发者可获得对虚拟人行为的底层控制权,从而做到自主定义对话状态机、知识库访问权限及不同输入信号的触发逻辑。通过 API 与企业后端系统实时同步,实现如自动创建支持工单或实时资格审查(Qualification)等闭环操作。 适用于金融服务,技术营销,教育和人力资源等多个行业,多种场景。 ( @Kaltura\@GlobeNewswire) 1、高通 Arduino 发布 Ventuno Q:集成 40 TOPs 算力与 STM32H5 实时控制的机器人开发板 Qualcomm(高通)联合旗下 Arduino 发布单板计算机 Ventuno Q。该硬件采用高通 Dragonwing IQ8 处理器协同 STM32H5 低延迟微控制器(MCU)的双芯架构,核心定位于需高算力视觉处理与确定性电机控制相结合的边缘侧机器人及 AI 系统。 核心处理器搭载 Dragonwing IQ8,集成 8 核 ARM Cortex CPU、Adreno A623 GPU 以及 Hexagon Tensor NPU,AI 推理算力达 40 TOPs。同时,在实时层有独立的 STM32H5 MCU 负责处理高精度的物理运动反馈与低延迟传感器数据,实现视觉感知与机械操作的同步对齐。 软件栈与 AI 应用能力 该平台旨在通过单板集成感知、决策与行动链路,将 AI 推理从云端迁移至物理执行层。其算力储备满足了对隐私性、实时性要求极高的工业巡检、医疗机器人及高性能边缘视觉感知系统的开发需求。 ( @Steve Dent\@engadget) 2、微软推出 AI 健康平台 Copilot Health:能查化验结果、找医生,还能答疑 3 月 12 日,微软宣布推出「独立健康空间」Copilot Health,用户可以查询化验结果、查看医疗记录、搜索医生或医疗机构,并分析来自可穿戴设备的数据,还可完成各种健康相关问答。 微软表示,Copilot Health 不会取代医生,也不会提供诊断或治疗建议。其定位是帮助用户理解个人健康数据,用户可以通过 HealthEx 从美国超过 50000 家医院和医疗机构导入医疗记录,也可以导入化验结果。 其还支持苹果、Oura 和 Fitbit 等厂商的 50 多种可穿戴设备。系统主页可以显示步数等实时数据,也可以提醒用户即将到来的医疗预约,具体取决于用户愿意共享的数据。 用户还可以通过 Copilot Health 寻找医生。系统连接美国实时医疗服务提供者数据库,用户可以按照专科领域、地理位置、使用语言以及保险计划筛选医疗机构或医生。 微软表示,Copilot Health 通过优先引用来自全球 50 个国家权威医疗机构的信息,提高回答的质量和可靠性。Copilot Health 的回答会附带来源链接,同时还会提供来自哈佛健康出版的专家解答卡片。 (@IT 之家) 3、美国智能婴儿监测公司 Owlet Baby Care 靠「硬件+订阅」模式,2025 年营收破 7 亿元 美国智能婴儿监测公司 Owlet Baby Care 近日发布财报,显示其2025 全年营收 1.057 亿美元(约合 7.3 亿元),同比增长 35.4% Owlet 是一家创立于 2013 年的消费者健康科技公司,专注于智能婴儿监测产品的设计和制造,采用「硬件+订阅」的商业模式。 其核心产品是 Smart Sock(智能袜子)是一款可穿戴监测器,可追踪新生儿的心率和血氧饱和度水平,并将实时数据传送到 App。2021 年该产品升级为 Dream Sock,并获得 FDA(美国食品药品监督管理局)批准,成为一款正规的医疗产品;此后,Owlet 扩展了产品线,还推出高清视频监控设备 Owlet Sight。 婴幼儿睡眠中潜在风险高,父母或者其他看护人员照料压力大。智能袜子精准解决家长对婴儿安全的焦虑,满足实时监护的刚性需求,产品一经推出即获市场认可。 截至 2025 年底,Owlet 全球活跃设备已超过 65 万台。 针对 25 年营收的强势表现,Owlet 总裁兼首席执行官哈里斯强调,2025 年 1 月推出的 Owlet360 订阅服务是一个核心战略转变。 Owlet360 不同于 Owlet Dream App,它是一个高级订阅功能。除了实时监测外,高级订阅还能解锁专属功能,例如每日健康概览、每周健康趋势分析以及包含详细睡眠模式分析的个性化晨间报告。Owlet360 还提供舒适体温监测、与同龄宝宝的对比数据、运动分析,以及持续更新和新功能。 公司表示,截至 3 月初,已拥有超过 11 万付费订阅用户,管理层指出,最近已在国际上推出订阅服务,称这开启了新的高利润率收入来源。 (@多知) 4、iQIBLA 推出高频交互的宗教助手 Zikr Ring(赞念戒指)四年狂卖 400 万只 在巨头环伺的穿戴市场,iQIBLA 放弃了步数、心率等通用的健康监测逻辑,转而深耕全球 20 亿穆斯林用户的精神刚需。自 2021 年品牌正式推出以来,核心单品 Zikr Ring 在短短约四年时间里,于中东及全球穆斯林市场创下了累计出货400 万只的惊人战绩。 它将穆斯林传承千年的宗教器物——念珠、指南针、祈祷提醒器,集成进了一枚小小的智能戒指和一套云端系统里。Zikr Ring 看起来像一枚极简的科技饰品,但其本质是一个高频交互的宗教助手。 它解决了三个核心问题: 对于身处异地或频繁旅行的用户而言,精准定位克尔白的方向是每日礼拜的首要前提。iQIBLA 集成了高精度的地磁传感器,通过软硬一体的校准算法,解决了传统手机指南针易受电磁干扰、指向不稳的痛点。用户只需抬手或查看戒指屏幕,即可在几秒钟内获得精准的空间坐标导航。 传统的计数方式往往依赖物理念珠或机械计数器,难以记录复杂的修行计划。Custom Tasbih 功能允许用户在 App 中根据个人或导师的建议,灵活设定不同经文的计数目标,当用户通过戒指上的物理按键完成预设目标时,硬件会通过特定的震动频率进行反馈。这种逻辑将模糊的修行转化为精确的进度管理,让每一次按压都成为可感知的精神积累。 由于礼拜时间随太阳运行角度每日微变,精准的时间控制是穆斯林生活的底层刚需。Time Reminders 结合用户实时经纬度,通过天文算法自动更新每日五次礼拜的精准时刻。相比于手机闹钟的嘈杂,戒指的指间震动更加私密且庄重,避免了在工作会议或公共场合产生不必要的打扰,确保用户在忙碌的现代生活中依然能保持与宗教节律的同步。 但 iQIBLA 的志向从未止步于单纯的硬件制造,其核心逻辑是试图通过这些硬件切入,为全球穆斯林用户建立一个无缝连接的数字交互系统。 目前,iQIBLA 的产品矩阵已从智能戒指延伸至智能手表、高精度电子计数器,甚至是专用智能设备。这些产品高度统一地围绕着指向、提醒、记录这三大核心逻辑展开。 这种从工具向生态、从硬件向精神系统的跃迁,正是 iQIBLA 在出海浪潮中能够后发先至的野心所在。 ( @Z Potentials) 1、Neuralink 联合创始人:第一批能活到 1000 岁的人或已出生 Neuralink 联合创始人马克斯·霍达克(Max Hodak)近日在多场公开访谈与播客中提出激进预测,称「第一批能活到 1000 岁的人,现在可能已经出生了」。 霍达克认为,2035 年将成为技术发展的「事件视界」,人工智能与脑机接口(BCI)的协同突破,将在此后重塑人类生命状态。 他指出,大脑本质上是一台被头骨包裹的精密计算机,而当前 AI 模型的潜空间结构与人类大脑处理信息的方式高度相似,这意味着神经科学正逼近大脑的底层「API」。 霍达克在访谈中进一步描绘了未来 5 至 10 年的技术路径,包括: (@APPSO) 招聘、项目分享、求助……任何你想和社区分享的信息,请联系我们投稿。(加微信 creators2022,备注「社区黑板报」) 1、Physical AI 系列活动硅谷站!探讨和上手全模态与硬件智能丨 Meetup+Workshop,3 月 19 日 湾区硅谷的开发者和创业者们,3 月 19 日见! GTC 期间,来一场动脑又动手的 Physical AI 全天候嘉年华!同一场地,两场硬核活动无缝衔接: 🌅 上午 09:30|Meetup:对话真实世界 Agora | RiseLink | MiniMax | HumanTouch | EverMind | Resonance Ventures 等大咖齐聚,拆解全模态与端侧智能的机会与未来。 🛠 下午 13:30|Workshop:手搓语音 AI 硬件 基于 TEN 框架,实操接通语音 AI Agent。重点来了👉现场备有 40 套 Agora R1 开发板,代码跑通直接把硬件带回家! 上下午活动需分开独立报名,名额有限,拼手速: 上午 Meetup 报名: 下午 Workshop 报名: 地点:Sunnyvale (审核后发具体定位) 阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么 写在最后: 我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。 对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。 作者提示: 个人观点,仅供参考
01 有话题的技术


02 有亮点的产品





03 有态度的观点
04 社区黑板报





不装 omo 插件,一句 hi 消耗 12042token 占用 7%
安装 omo 插件,一句 hi 消耗 23985token 占用 12%
差不多是一倍,后续的操作都更加消耗 token
首先这不是标题党,这是今天早上刚刚发生的真实的,
我最近认识了一个女人,他和前夫离异半年了,自己带一个 5 岁的孩子,
我们在网上认识就直接打了视频,聊了一个小时,感觉都挺聊得来的,我马上开车半个小时去找她,顺路带了两杯奶茶,
到了城郊,见到真人后边走边聊,吹了 2 个小时,基本印象是双方都对彼此满意,
当天回到城里后我立马去花店买了一束花,晚上 9 点左右到她楼下,把鲜花送给她,在她车里和她一起聊了一个多小时,亲嘴的时候她突然流了很多鼻血,开始她让我上楼,后来她感觉自己有些冲动,我们都需要冷静冷静,我就走了。我到家以后我们又聊了一会,估计是有些上头了,她叫我过去,这时候是凌晨一点左右,我到了她在电梯口等我,我们一起滚床单,
第二天她早起送孩子去幼儿园,睡到中午我们起来,我给她做了早餐,然后我去上班。我们有种相见恨晚的感觉,在一起有聊不完的话题,后来遇见孩子我带他去超市买玩具,陪孩子下五子棋,然后她哄孩子睡觉,她孩子见着我在她家是有两次。
昨天周六,这是我们认识的第七天,她前夫把孩子接走,晚上我们一起在她家边看电影边聊天,凌晨 12 点我给她做了宵夜,一直在沙发上聊到凌晨 2 点才睡觉。
今天早上 8 点左右,我突然听到开门的声音(孩子有指纹锁),我叫她赶紧穿衣服,她孩子来敲门,她去开门(卧室门有反锁),接着门一下子被推开,一个穿着美团外卖黄色衣服的人冲进来,拿着我的鞋子朝我扔来,此时我正全裸,一下子懵逼了,男人用少数民族方言一顿臭骂,我虽听不懂 那肯定骂声,男人出去了边走边骂,女人随后跟着出去直到电梯,
Geek Uninstaller 是一款免费、轻量的专业软件卸载工具,主打“深度清理+极简操作”,非常适合想要彻底移除电脑软件、清理残留的用户。 安装包下载:https://pan.quark.cn/s/f7a0ae886615 ,先下载好 Geek Uninstaller 压缩包(内含可执行程序),保存到电脑本地。 解压安装包: 找到下载的 以管理员身份运行: 打开解压后的【Geek Uninstaller】文件夹,右键 成功打开 Geek Uninstaller 主界面,即可开始使用软件卸载与清理功能。 一、准备工作
二、启动 Geek Uninstaller
Geek Uninstaller压缩包,右键点击 → 选择【解压到“Geek Uninstaller”】。Geek程序 →【以管理员身份运行】(避免权限不足导致功能受限)。三、验证安装
大家的虾,养了多久了? 这一次,我们想认真把大家聚在一起,在3月19日(周四)晚上19点,在北京朝阳·望京,办一届「养虾故事大会」。 带上你的虾,show 出你做了什么,聊聊一路养下来的心得、脑洞和奇怪进展。这不是入门局,是一场属于 OpenClaw 玩家、创作者和高阶养虾人的 Demo Night。 讲出你的养虾故事,由现场观众投票——全场最佳逮虾户,带走 Mac mini M4 一台。 👉 立即报名:luma.com/dgq4wlv8 19:00 - 19:10|开场 19:10 - 20:40|Demo 现场开麦 20:40 - 20:50|现场投票 20:50 - 21:00|公布结果 + 颁奖 21:00 - 21:30|自由交流 这一批开麦的人—— 有人把 OpenClaw 装进 Cardputer,做成了能养的拓麻歌子;有人让虾直接上岗管理公司,升职加薪当 CEO;有人通过硬件采集上下文,把虾喂得比任何人都聪明;有人给虾配上了川普的声线,每天早上亢奋地替你播报;还有人不止做桌宠,把虾开进了电商,认真跑商业化。 大家的背景横跨产品、技术、运营、KOL——唯一的共同点是,他们都把 OpenClaw 玩出了点不一样的东西。 本届开麦嘉宾 ... Demo 环节持续开放,欢迎带着你的虾来报名。 Demo 报名要求 Demo 报名截止:3月17日 20:00, 报名请提前联系小助手「Creators2022」,备注「我要开麦」逾期不候。 奖项 🏆 最佳逮虾户:Mac mini M4 一台 🎁 所有上台 Demo 的参与者:MiniMax Coding Plan 现场投票,现场唱票,结果当晚公布。 👉 扫码报名:luma.com/dgq4wlv8 欢迎大家来现场开麦、投票、交流,一起把这届虾养得热闹一点。 阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么活动日程
Demo 现场开麦· 寻找最佳逮虾户
报名方式





根据 GitLab 最新发布的一篇博文,AI 正快速改变软件漏洞的检测方式,但“谁来负责治理 AI 所暴露的风险”以及“如何应对这些风险”等问题已变得日益紧迫。GitLab 认为,尽管静态扫描器、生成式模型等 AI 工具在识别潜在安全问题并给出修复建议方面效率远高于传统工具,但仅靠检测无法解决风险管理的全部问题。这也促使开发者与安全团队重新思考在现代开发生命周期中应如何构建治理、问责与执行机制。 文章强调,随着 AI 驱动工具可发现漏洞并提出整改方案等相关成果公布,行业思路正在发生转变。尽管这些创新体现了 AI 在加速检测方面的价值,但 GitLab 的文章指出,发现漏洞本身并不等同于降低风险。企业安全负责人愈发关注漏洞是否真正依据业务风险完成分类、定级与修复,相关决策是否有明确的责任主体。如果团队缺少策略约束、场景化风险评分与治理机制来明确哪些问题必须在发布前修复、哪些可以接受或延后处理,那么单纯发现更多漏洞只会产生无效信息,形成干扰噪音。 为解决这一问题,GitLab 主张将 AI 驱动的检测嵌入到更广泛的、基于策略的 DevSecOps 框架中,推荐的最佳实践包括:在组织层面定义风险容忍阈值;设置与漏洞严重性、可利用性及合规要求相关的合并与部署门禁;在风险接受时保留可审计的审批流程;随着代码、依赖项与威胁情报的变化持续重新评估风险。文章强调,在从代码、流水线到生产环境的整个软件生命周期中保持统一可视性至关重要,从而将 AI 发现的问题与资产重要性、运行时暴露情况相结合。在此模式下,AI 成为安全开发的效能倍增器,而通过平台级管控、可审计性与可量化策略执行实现的治理仍是将检测结果转化为可问责、基于风险的决策的核心机制。 开发者与安全工程师不应将 AI 当作风险治理的替代品,而应将其视为加速器,并与严格的监督流程和清晰的问责机制相结合。行业趋势显示,这种平衡理念正得到越来越多的认同:近期围绕容器安全与威胁事件的讨论凸显了大规模场景下软件风险的复杂性——AI 驱动的扫描与自动化手段正与日趋复杂的供应链攻击、运行时漏洞并存。 整个行业内,众多组织已就 AI 风险治理原则形成共识,强调检测能力必须与结构化的监督和问责机制相结合。美国国家标准与技术研究院(NIST)凭借被广泛采用的AI风险管理框架(AI RMF),提出以治理、风险映射、度量与持续管理为核心的全生命周期管理思路。关键实践包括:明确问责角色、留存审计轨迹、针对公平性与安全标准验证模型,以及将 AI 风险纳入更全面的企业风险管理体系,而非将其视作孤立的技术问题。这些建议与 GitLab 的观点高度契合:只有将 AI 检测结果融入可落地的治理流程与部署管控中,其价值才能真正体现。 科技公司与行业框架也呼应了这种“治理优先”的思路。例如,微软已建立规范的负责任 AI 治理体系,包括内部审查委员会、高风险系统的定义与审批流程,以及对模型偏见或不安全输出的持续监控。同时,IBM强调透明度、可解释性与问责制是构建信任的基础。此外,ISO/IEC 42001等国际标准及欧盟 AI 法案相关的新兴监管规范都倡导持续审计、AI 使用过程可视化,以及与生产环境中的模型同步迭代的策略化管控。从这些实践中可以形成明确共识:有效的 AI 治理并非更依赖检测工具的复杂度,而是依托监控、人工审核、可量化的风险阈值,以及贯穿 AI 全生命周期的持续合规校验等运营实践。 【声明:本文由 InfoQ 翻译,未经许可禁止转载。】 查看英文原文:https://www.infoq.com/news/2026/03/gitlab-ai-governance/
I've developed a new fear of my 2025 desktop PC being damaged by a power surge or something, because it would cost at least $2K more to replace than I paid for it, assuming I can even find parts now. Compared to the rest of my adult life when I used to secretly pray for something to fail so I would have a reason to upgrade.
https://news.ycombinator.com/item?id=47368494
我现在对 2025 款台式机被电源浪涌之类的弄坏产生了新的恐惧,因为想要更换的话,成本至少比我买的时候多花 2000 美元,而且就算现在能找到配件也未必行。这和我成年后其他时候太不一样了,以前我总是暗自祈祷出点毛病,好给自己一个升级的理由。
我现在也是同样的想法,内存太贵了啊!
有推荐周边城市的吗?
主材、辅材、窗户、全屋定制,加起来 十多万了。真贵啊。
考虑去周边二三线城市的建材城转一转,本地材料相对于老家 6 线真贵不少。麻了
我爸和众多中国老年人一样,其实已经是豆包的忠实用户了。 但作为一个 AI 博主,我内心总是想让老父亲知道 OpenClaw 的牛逼之处,让他开开眼。在家里给他演示一通后,他得出了个结论,软件不错,能控制很多东西,相当于有手脚了,但是就是不好用。 “啥不好用,最近不知道有多火!!” “我都老花眼了,还要打字,人家豆包说说话就行了。你不是程序员吗?干嘛不做一个。” 这话我一听就来气,所以这两天我就一直研究,如何给OpenClaw 套上通话功能。 现在先给大家看看实际的使用情况: 你可能以为我要短期内 vibecoding OpenClaw的插件之类的,但在这个普通人30 分钟都能写一个项目的年代。我估计这个功能早就实现了。 问题是如何找到这些代码呢? 第一是靠搜索:先随便搜搜,openclaw+voice,就会发现很多项目。 第二是靠积累:由于对架构的理解,我很早就知道有不少做 voice AI agents 接下来就是翻翻代码库,看看有没有上 OpenClaw 了。经过一番搜索,我选择了star 比较多,比较眼熟的ten-framework。 为什么这么选择呢? 首先他的文档比较完善,部署流程清晰了,我几乎不用写任何代码 还有个重要的原因,就是 OpenClaw 更新频繁,可能几天前的代码就变得老旧了,我还认识开发者,到时候督促他修修 bug。 为了让整个项目运行起来,你需要注册 4 个免费的服务,其中除了 DeepSeek,其他都不需要付费。 国内直连,OpenAI 兼容接口,价格极低(约 OpenAI 的 1/50)。 注册步骤 充值 获取 API Key 用于将用户语音实时转为文字。 注册步骤 获取 API Key 免费额度 新账号赠送 $200 免费额度,不需要绑信用卡,个人测试用很久。 用于将 AI 回复文字转为语音播报。 注册步骤 获取 API Key 免费额度 免费计划每月 10,000 字符的语音合成额度,包含 API 访问权限,测试够用。 用于浏览器与 AI 助手之间的实时音视频通信。 注册步骤 创建项目 获取 App ID 和 Certificate 信令服务rtm开启 免费额度 每月 10,000 分钟免费使用,个人测试完全够用。 将项目整体克隆下来: https://github.com/TEN-framework/ten-framework 环境变量配置 参考ai_agents/agents/examples/openclaw-example里面的 readme。 我们在ai_agents/下创建 .env文件,内容具体如下: OpenClaw配置 首先将 OpenClaw 的网关改成密码模式,具体步骤 然后为了安全,需要配置Control UI Allowed Origins ,具体步骤如下图 在 OpenClaw 的 Settings → Gateway → Control UI Allowed Origins 中添加: http\://host.docker.internal:18789 这个值必须与 .env 中的 OPENCLAW\_GATEWAY\_ORIGIN 完全一致(包括协议 http\:// 不能写成 wss\://,不能带路径)。如果不匹配,Gateway 会拒绝连接并返回 origin not allowed。 修改代码扩展功能 实际使用下来,为了方便中国人使用,需要对配置进行更改,具体如下 ai\_agents/agents/examples/openclaw-example/tenapp/property.json — 4 行改动 LLM base\_url 从硬编码 https\://api.openai.com/v1 → ${env:OPENAI\_API\_BASE} 上面主要是让 ASR 能转录中文,还有去除硬编码的环境变量,方便配置国内的模型。 mac arm 架构下部署注意事项: 由于这个项目不支持arm64 架构,你需要在 docker开启虚拟化,具体步骤如下 然后运行如下命令 首先保持 OpenClaw 开启,想看到网关的日志的话,推荐使用 * 然后运行容器 登录到http\://localhost:3000,会看到如下所示界面,我们复制这个命令运行,进行配对 具体如下图所示 现在开始就可以愉快对话了。 要求他创建在桌面创建一个文件,如下图所示,口喷就行: 很快就创建好了 接入语音对话功能后,OpenClaw 开始有能力给不懂技术的普通人使用。 普通人估计都没有接触过开口就能干活,不废话的 AI 我给我爸的 OpenClaw 套上了个修复图片的 skill,他就乐呵呵地年轻时候的照片进行修复了。 普通人其实对 AI 产品只有两个要求:好用,能干活。 这篇文章希望对你有帮助!! 喜欢我的文章可以关注我的公众号 阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么架构选择

基本服务购买
DeepSeek(国内替代推荐)

Deepgram(语音识别 STT)

ElevenLabs(语音合成 TTS)

Agora(实时音视频 RTC)

项目配置
克隆项目
配置
# --- 服务配置 ---LOG_PATH=/tmp/ten_agentLOG_STDOUT=trueGRAPH_DESIGNER_SERVER_PORT=49483SERVER_PORT=8080WORKERS_MAX=100WORKER_QUIT_TIMEOUT_SECONDS=60# --- 前端 ---AGENT_SERVER_URL=http://localhost:8080TEN_DEV_SERVER_URL=http://localhost:49483NEXT_PUBLIC_EDIT_GRAPH_MODE=false# --- Agora RTC/RTM ---AGORA_APP_ID=<你的 Agora App ID>AGORA_APP_CERTIFICATE=<你的 Agora App Certificate># --- LLM (DeepSeek) ---OPENAI_API_BASE=https://api.deepseek.comOPENAI_API_KEY=<你的 DeepSeek API Key>OPENAI_MODEL=deepseek-chat# OPENAI_PROXY_URL=# --- STT (Deepgram) ---DEEPGRAM_API_KEY=<你的 Deepgram API Key># --- TTS (ElevenLabs) ---ELEVENLABS_TTS_KEY=<你的 ElevenLabs API Key># --- OpenClaw Gateway ---OPENCLAW_GATEWAY_URL=ws://host.docker.internal:18789OPENCLAW_GATEWAY_PASSWORD=<你的 Gateway 密码>OPENCLAW_GATEWAY_ORIGIN=http://host.docker.internal:18789OPENCLAW_GATEWAY_SCOPES=operator.writeOPENCLAW_GATEWAY_DEVICE_IDENTITY_PATH=/data/openclaw/device_identity.jsopenclaw config set gateway.auth.mode password openclaw config set gateway.auth.password lxfater 

构建容器

# 1. 构建镜像 cd <项目所在目录>/ten-framework/ai_agents # 强制build amd64 版本 docker build --platform linux/amd64 -f agents/examples/openclaw-example/Dockerfile -t openclaw-example-app . 运行项目
openclaw gateway --force# 要在cd <项目所在目录>/ten-framework/ai_agents目录下
docker run --rm -it --env-file .env -p 8080:8080 -p 3000:3000 openclaw-example-app
使用项目



结束



使用 antigravity
因为模型冷却时间必须中途进行更换
我在更换到其他模型时
需要给新的模型说下上下文吗?
还是他自己会去读取和理解?
如果每换一次模型,模型会重新读取和理解上下文
那是不是频繁切换模型,token 消耗会比一个模型更多?
大陆用户注册教程| 50% 手续费返佣
(邀请码 146364 )
注册链接:partner.bybit.com/b/146364
扶墙 选 日本韩国台湾 Gmail/Outlook 注册
KYC 选中国身份证 + 人脸| 5 分钟过 LV1
全球第二大衍生品交易所|极端行情不宕机
弹出“非服务地区” → 选 否
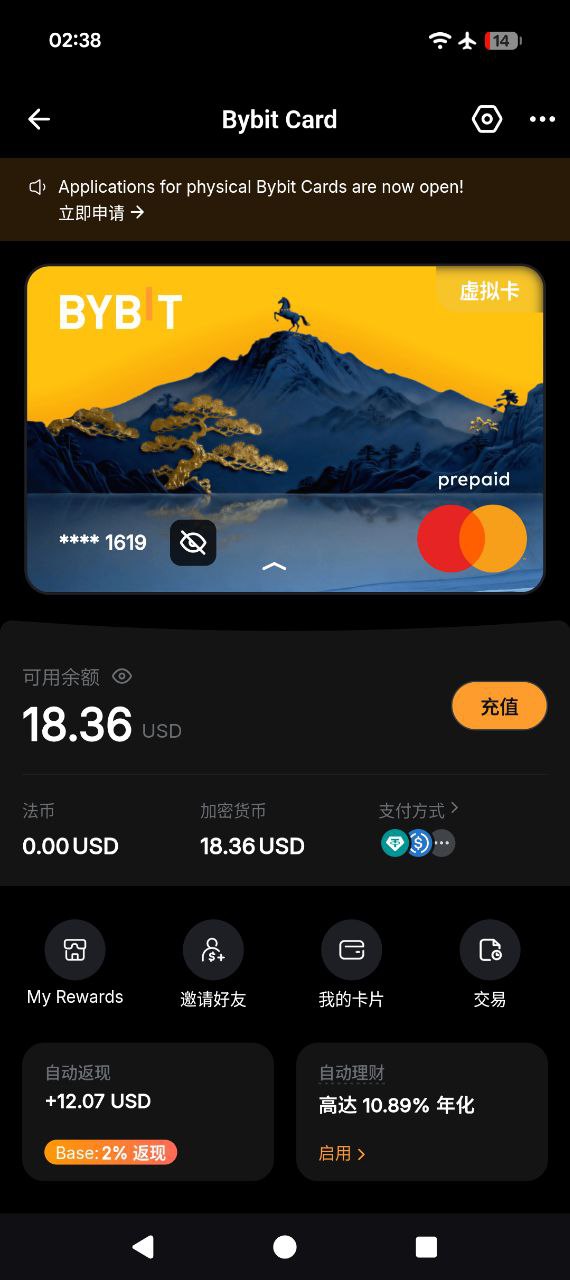
Bybit 卡邀请码:MANMOV
币安手续费贵 OKX 穿仓平仓 ,Bybit 有 VIP 等级平移政策,跳槽到 Bybit 不仅能拿 VIP1 还送 VIP3 待遇试用卡一个月,Bybit 高级客户经理专门对接,taker 仅 0.035%甚至更低,Bybit 没币安那么挤 API 响应更快
 。
。
 。
。
 。
。
 。
。
 。
。
这篇只讲这个工具的功能 JS。整体基于 Vue 组合式 API,核心流程是: 随机数工具看起来简单,但可变项不少:数字类型、是否去重、小数位、排序、分隔符、数量、范围、结果文本、结果数组。实现里把这些都放在响应式状态里,保证按钮点击、统计卡片、结果区同步更新。 生成动作入口先做三层校验: 第三条是关键,区间容量通过 整数模式采用左闭右开区间 小数模式先算随机值,再按用户设定小数位做舍入: 这样一来,小数展示和复制结果保持一致,不会出现界面显示 2 位、复制出去是长小数的问题。 去重模式使用 这个上限是防护措施,避免极端参数下死循环,保证函数一定能结束。 生成完数组后按选项排序,再用分隔符拼接成文本: 分隔符支持预设和自定义,并把 统计信息不单独存储,而是由 这部分是工具可用性的最后一环: 到这里,这个随机数工具的核心 JS 就完整了:先校验参数,再稳定生成,最后把结果以“可读、可复制、可下载”的形式交付给用户。参数输入 -> 参数校验 -> 生成随机数 -> 排序与拼接 -> 统计/复制/下载在线工具网址:https://see-tool.com/random-number-generator
工具截图:
1)状态建模:先把可变参数拆清楚
const numberType = ref("integer");
const uniqueNumbers = ref("false");
const decimalPlaces = ref(2);
const sortOrder = ref("none");
const separatorSelect = ref("\\n");
const customSeparator = ref("");
const count = ref(10);
const minValue = ref(0);
const maxValue = ref(100);
const result = ref("");
const generatedNumbers = ref([]);2)参数校验:先拦截,再计算
min < max,否则区间无效。count 限制在 1 ~ 10000。Math.floor(max) - Math.ceil(min) 计算,避免出现“要求不重复但可选值不够”的情况。if (minValue.value >= maxValue.value) return;
if (count.value <= 0 || count.value > 10000) return;
if (isUnique && numberType.value === "integer") {
const range = Math.floor(maxValue.value) - Math.ceil(minValue.value);
if (count.value > range) return;
}3)随机生成核心:整数与小数两套逻辑
[min, max):randomNum =
Math.floor(Math.random() * (maxValue.value - minValue.value)) +
minValue.value;randomNum = Math.random() * (maxValue.value - minValue.value) + minValue.value;
randomNum = parseFloat(randomNum.toFixed(decimalPlaces.value));4)去重实现:Set + 重试上限
Set 记录已出现数字。每次生成如果命中重复就继续抽,直到拿到新值或达到重试上限。const usedNumbers = new Set();
let attempts = 0;
const maxAttempts = 10000;
do {
// 生成 randomNum
attempts++;
} while (isUnique && usedNumbers.has(randomNum) && attempts < maxAttempts);5)结果整理:排序、分隔符、文本输出一次完成
if (sortOrder.value === "asc") numbers.sort((a, b) => a - b);
else if (sortOrder.value === "desc") numbers.sort((a, b) => b - a);
generatedNumbers.value = numbers;
result.value = numbers.join(separator);\n、\t 转为真实换行和制表符,方便直接导出到文档或表格。6)统计计算:基于结果数组实时派生
generatedNumbers 计算得到,包含数量、最小值、最大值、平均值。平均值通过 reduce 计算,展示前统一走格式化函数,避免浮点尾数影响阅读。const avg = numbers.reduce((sum, num) => sum + num, 0) / numbers.length;
const formatNumber = (num) => {
if (Number.isInteger(num)) return num.toString();
return parseFloat(num.toFixed(6)).toString();
};7)交互闭环:复制、下载、清空
navigator.clipboard.writeText(result)。Blob,生成临时链接触发下载。const blob = new Blob([result.value], { type: "text/plain;charset=utf-8" });
const url = URL.createObjectURL(blob);
距离苹果2026年全球开发者大会(WWDC)仅剩三个月,关于iOS 27的爆料已然漫天飞舞。海外科技媒体Macrumors的最新汇总显示,这款新系统将承担两大历史级重任:为苹果首款折叠屏“iPhone Fold”铺路,以及完成iOS 26未能实现的AI(Apple Intelligence)深度重构。 苹果终于要在今年9月推出首款可折叠设备“iPhone Fold”了。据悉,该设备折叠状态下为5.5英寸,展开后则为7.8英寸,屏幕比例接近4:3。为了适配这一形态,iOS 27将引入分屏多任务处理,原生应用也会增设侧边栏。 令人瞩目的是,iPhone Fold尽管展开后尺寸逼近iPad Mini,但它运行的依然是iOS,且完全不支持iPad应用。 Apple Intelligence版Siri曾是画下的大饼,如今要在iOS 27上强制兑现。新版Siri不仅具备个人情境感知、屏幕内容识别能力,更可怕的是实现了“跨应用操作”(例如:让Siri把刚才修好的照片直接通过邮件发给某人)。 同时,苹果正与谷歌紧密合作,计划在iOS 27中引入类似ChatGPT的聊天机器人版Siri,底层甚至动用了Google Gemini团队联合开发的定制AI模型。 除了前台功能的炫技,iOS 27的底层变动同样剧烈。苹果将推出全新的Core AI框架,全面取代现有的Core ML。 此外,彭博社马克·古尔曼将iOS 27描述为一次“雪豹式”(Snow Leopard)更新,意味着苹果正投入巨大精力清理iOS的陈年冗余代码,重写老旧功能,以换取极端的性能提升和流畅度。 在硬件协同上,iOS 27还准备解锁更高级的卫星通信能力,包括卫星版苹果地图、发照片甚至5G网络卫星连接。而在健康领域,原本完全由AI驱动的Health+订阅服务虽然规模缩水,但仍有部分功能植入系统。 总结: 👇 欢迎关注我的公众号 在 AI 爆发的深水区,我们一起探索真正能穿越周期的技术价值。
【笔者观点】
库克的“挤牙膏”神话,正在被AI时代的狂飙突进无情打破。由于全新版Siri的难产,iOS 27与其说是按部就班的迭代,不如说是苹果为了掩盖iOS 26在AI布局上“全面脱节”而不得不打出的一张底牌。在微软和谷歌步步紧逼的当下,iOS 27已经没有任何试错的空间,这是一场不折不扣的生态保卫战。一、 迟到的折叠屏,与苹果精准的“生态刀法”
【笔者观点】
折叠屏在安卓阵营早已杀成红海,苹果迟到至今才交卷,本质上是对现有硬件利润盘的极度保守。但最反常识的设定在于:一台展开近8英寸的设备,苹果居然死死掐住不让它兼容iPadOS。
这绝非技术瓶颈,而是苹果深思熟虑的商业精算——既要收割折叠屏带来的超高硬件溢价,又绝不允许这款设备蚕食掉iPad的任何一点生存空间。这种为了保护多条产品线销量而人为制造的“软件割裂”,或许会让iPhone Fold的用户体验变得极度别扭。二、 Siri的“基因突变”与大模型主权让渡
【笔者观点】
请认清一个残酷的现实:苹果选择与谷歌合作接入Gemini模型,等同于在底层大模型能力上承认了阶段性败北。把Siri硬改成Chatbot不是自然进化,而是迫于无奈的“基因突变”。
但千万不要因此看轻苹果。苹果真正的恐怖护城河不在于AI模型本身有多聪明,而在于“系统最高控制权”。当Siri能够直接读取屏幕信息,并越过App围墙进行跨应用操作时,第三方App的入口价值将被瞬间抽干。这意味着,微信、支付宝等超级App在iOS生态内可能被降维打击,沦为苹果AI底层的“工具人组件”。三、 Core AI与“雪豹式”重构:底层的彻底洗牌
【笔者观点】
所谓“雪豹式”更新,说穿了就是一块遮羞布,掩盖了iOS十几年祖传代码在AI时代已经臃肿不堪、运行效率低下的事实。不把这栋危楼的承重墙打掉重塑,根本跑不动未来的端侧大模型。
而强制用Core AI替换Core ML,则是苹果向全球千万开发者下达的最后通牒:在苹果的生态里玩AI,就必须臣服于苹果的新规矩。通过这种底层框架的裹挟,苹果正在不动声色地夺回AI应用生态的绝对定义权。四、 卫星连接与被砍掉的Health+:生态扩张的暗战
【笔者观点】
别把卫星通信只看作“荒野求生”的噱头。让iPhone无需对准天空就能直连卫星网络,这背后潜藏着苹果试图逐渐摆脱对传统电信运营商依赖,构建属于自己“空天地一体”私域网络的巨大野心。
至于Health+订阅服务的缩水,反而证明了当前的AI能力在严肃医疗健康领域的无力感。在没有达到绝对精准之前,强行推出AI医疗诊断就是给苹果的法务部找麻烦。
iOS 27、macOS及其他新系统将在今年6月正式预览。这不再是一次简单的UI换肤或小修小补,而是苹果在AI落后焦虑与硬件创新瓶颈的双重重压下,进行的一次“刮骨疗毒”。至于市场买不买单,9月的折叠屏销量将给出最残酷的答案。
微信搜索 【睿见新世界】 或扫描下方二维码,获取每周硬核技术推文:
欢迎关注【睿见新世界】
据Anthropic公司周四(2026年3月13日)最新宣布,Claude正式推出了一项颠覆性的新功能:直接在聊天中生成交互式图表、图解和可视化内容。 值得注意的是,这绝不是Midjourney或DALL-E那种传统的AI图像生成器。当系统判断视觉呈现比长篇大论更有效,或者在用户的明确要求下,Claude会直接从零开始编写并即时渲染交互式的HTML和SVG文件。Anthropic官方将这一功能精准地比作:给Claude配备了一块“按需唤醒的智能白板”。 在实际测试中,这项功能展现出了惊人的实用性。当测试者要求Claude展示“如何换轮胎”时,它没有像传统AI那样吐出上千字的说明书,而是在几秒钟内生成了一个包含7个步骤、附带所需工具和关键步骤说明的交互式流程图。 更硬核的应用场景在于复杂信息的拆解。测试者要求Claude为一本小说中描述的房屋构建视觉呈现,Claude不仅准确还原了房屋结构,还将其做成了“全图可点击”的交互界面——点击窗户或门,就会弹出相应的隐藏信息。此外,Anthropic官方还展示了“可点击的交互式元素周期表”以及“纸飞机折叠动态教程”等案例。生成的图解甚至可以下载,或保存为工件(Artifacts)以便日后复用。 与很多AI厂商将核心能力封装在“Pro版”中不同,Anthropic宣布该功能将默认开启,且向所有计划类型(包括免费用户)全面开放。用户无需在设置中手动切换,系统会自动判断对话上下文,在最合适的时机直接抛出可视化内容。目前该功能已在网页和桌面版本上线,移动版也已在规划之中。 Anthropic的野心昭然若揭:他们要让Claude成为一个“能够自主选择最佳传递媒介的动态AI工具”。 👇 欢迎关注我的公众号 在 AI 爆发的深水区,我们一起探索真正能穿越周期的技术价值。
一、 不是图像生成,而是“按需定制的交互代码白板”
【笔者观点】
当所有大模型都在死磕“谁生成的像素画更逼真”时,Claude却悄悄偷了塔。 这是一个极其反常识的战略选择:像素级图像解决的是“娱乐与审美”问题,而基于HTML/SVG的交互式图表解决的是“认知与生产力”问题。Claude不仅是在提供一个新功能,它是在重新定义AI的输出媒介——从单向的“文本输出器”,进化成了能即时生成微型应用程序的“超级编译器”。如果你还在用大模型写干瘪的文章,那你已经被这个时代抛弃了一半。二、 从“换轮胎”到“建筑解析”:AI终于学会了“用工具沟通”
【笔者观点】
大段文字正在成为过去式,我们正在见证“静态长文”的消亡。 以前我们认为AI的终局是“极其聪明的对答机器”,但Claude这一手证明了:最高效的信息传递,永远是交互式可视化。这给所有内容创作者、教育工作者甚至UI设计师敲响了警钟——当一个免费的大模型能在3秒内生成一套可点击的交互式信息图表时,那些依靠制作静态PPT、繁琐说明书和基础前端展示吃饭的岗位,生存倒计时已经开始。三、 跨越付费墙:无差别的降维打击
【笔者观点】
免费且默认开启,这是Anthropic最犀利的一招阳谋。 为什么不收费?因为底层逻辑是“用户习惯的绑架”。一旦用户习惯了在提问后得到一个可以直接点击、拖拽、查看详情的交互式UI界面,他们就再也无法忍受其他竞品那种“干巴巴吐字”的便秘感了。ChatGPT等竞品如果不能迅速在“多模态交互渲染”上跟进,其在职场生产力领域的护城河将被彻底撕裂。对于普通用户而言,紧迫感同样存在:不再是“你会不会用AI提问”,而是“你会不会用AI的交互白板来重塑你的工作流”。
微信搜索 【睿见新世界】 或扫描下方二维码,获取每周硬核技术推文:
欢迎关注【睿见新世界】
最近几周我用 Claude Code 写了很多代码。 下面是一些随手记下来的想法。 因为最近一波 LLM 写代码的能力又提升了。和很多人一样,我在 11 月的时候,大概是:80% 靠自己手敲 + IDE 自动补全,20% 现在网上有两种吹法:“IDE 以后都不需要了”和“Agent 群自己协作就能搞定一切”。我个人觉得,现在这个阶段,这两种说法都吹得太过了。 看一个 Agent 死磕一个问题,其实挺有意思的。它不会累。不会心态崩。人早就会说“算了,改天再战”的地方,它还能一直试、一直试。 LLM 帮你提速,到底是快了几倍,其实很难量化。我确实感觉,在我原本就要做的那些事上,整体是快了很多。但更大的变化是:我现在会做更多事情。 LLM 有一个特别厉害的地方:它很会一遍遍循环尝试,直到满足你设定的具体目标。很多“有 AGI 味道”的体验,就是在这里出现的。 我原本没想到,有了 Agent 之后,写代码反而会“更好玩”。很多枯燥的“填空题式”的工作被它接过去了。留下来的更多是有创意的部分。 我已经能感觉到:自己“手写代码”的能力在慢慢退化。在大脑里,“生成”(自己写代码)和“辨别”(看懂、审代码)其实是两种不同的能力。因为写代码要记一堆细碎的语法细节。而看代码主要是理解思路和结构。所以就算你已经有点写不动了,你仍然可以很好地审查代码,看哪里怪怪的、哪里有 所谓“10 倍工程师”会变成什么样? 未来用 LLM 写代码,会是什么感觉? LLM 的 Agent 能力(尤其是 Claude Code),在 2025 年 12 月左右,感觉是跨过了某个“整体连贯性”的门槛。这在软件工程和相关领域里,引发了一次“相变”。也就是,做事的方式突然变了一个层级。来自 Andrej Karpathy 的提醒:未来的程序员分两种:会用 AI 写代码的,和被淘汰的
以下的博文的作者是 Andrej Karpathy。他是 AI 领域公认的大神。曾经在特斯拉当 AI 总监,负责自动驾驶的核心系统。他也是 OpenAI 的早期成员,参与过 ChatGPT 这类技术的基础工作。还在美国斯坦福大学教过著名的计算机视觉课。现在他在创业做 AI 教育。
他从学术界到大厂,从研究到产品,经历特别全。所以,他不是站在圈外“聊概念”的人。他是从最早一批深度学习,到自动驾驶,再到现在大模型和写代码的 AI 工具,都亲自冲在一线的人。他自己写了很多年代码,也亲手带过大团队。
因此,他对“AI 怎么改变写代码这件事”的感受和判断,非常值得参考。
Karpathy 用亲身实践证明,用 Claude Code 这类工具,不是简单的"自动补全",而是给开发效率加杠杆。同样的时间,你能搞定以前十倍的工作量,甚至敢碰以前不敢做的复杂项目。当然 AI 也会犯错、会把代码写复杂,需要你盯着,但总体是质的飞跃。
无论是资深程序开发专家,还是准备学编程的小白,Karpathy 都建议 尽早开始用 Claude Code 这类工具。这不是锦上添花,而是给自己的开发能力加杠杆。同样的时间,你能做以前十倍的事,甚至能挑战以前完全不敢碰的项目。 AI年代的开发流程已经完全进化了,越早适应,优势越大。Coding workflow(写代码的流程)
用代码助手(Agent)。到了 12 月,已经完全反过来了:80% 是让 Agent 写代码,20% 是我自己改一改、修修补补。
也就是说,现在我其实主要是在用英文“说话写代码”。我一边有点不好意思,一边跟 LLM 讲:“你帮我写一段这样的代码”,全是用文字描述。
这对程序员自尊心确实有点打击。但它能一次性对一大块软件做“大号代码操作”,整体效率实在太香了。尤其是当你适应了它,把配置调好,学会怎么用,搞清楚它能做什么、不能做什么之后。
对我来说,这已经是我差不多 20 年写代码生涯里,对“开发工作流”影响最大的一次变化。而且就只是在短短几周内发生。我猜,现在已经有不少工程师(两位数百分比那种)在经历类似的变化。但在普通人那里,对这件事的认知,感觉还停留在很低的个位数百分比。IDEs / Agent 群 / 会犯错这件事
模型还是会犯错的。如果这份代码是你真正关心的项目,我建议你一定要盯紧。最好旁边开一个窗口,用一个大的 IDE 看着,就像老鹰盯猎物那样。
错误的类型已经变了。不再是那种简单的语法错误。而是一些比较细、比较隐蔽的概念错误。就好像一个有点毛躁、赶时间的初级工程师可能会犯的那种错。
最常见的一类问题:模型会替你“脑补”一些前提。但它脑补错了,也不会回头确认。它就直接在这个错误前提上继续一路写下去。
它们也不会好好管理自己的“困惑”。不会主动问你:“这地方你到底想要 A 还是 B?”不会主动帮你指出前后不一致的地方。不会帮你列清楚不同方案的取舍。该反驳你的时候,它也不怎么反驳。整体还是有点“太会附和人”的那种感觉。但如果让它先写一个“计划”,再按计划执行,情况会好不少。不过我觉得还挺需要一种“轻量的、嵌在代码里的计划模式”。它们还特别喜欢把代码和 API 写得过于复杂。抽象层级越叠越厚,变得很臃肿。写完之后也不主动清理自己制造出来的“死代码”。
有时候它能写出一坨一千多行的实现。又慢、又复杂、又脆弱,到处是绕路。
然后你轻轻问一句:“我们能不能直接用这个更简单的写法?”它立刻说:“当然可以!”然后马上给你缩成一百来行。
有时它还会顺手改掉,甚至删掉一些注释和代码。只因为它“不喜欢”或者没完全看懂。哪怕这些东西和当前任务完全没关系。这些问题,哪怕我已经在
CLAUDE.md
里写了一些使用说明,提醒它注意这些点,还是会时不时出现。即便如此,从整体效果看,还是提升巨大。现在真的很难想象再完全回到纯手写代码的时代。
简单说,每个人都有自己的开发节奏。我现在的做法是:左边在 Ghostty 里开几个 Claude Code 会话,右边开 IDE,用来看代码和手动修改。Tenacity(韧性 / 耐力)
有时候你看着它挣扎了很久。结果 30 分钟后,它终于搞定了。那一刻会有点“哇,真的有点 AGI 味道”的感觉。
你会突然意识到:原来“体力和精力”真的是工作里的一个核心瓶颈。而有了 LLM,这方面的上限被拉高了很多。Speedups(提速)
原因大概有两点:
所以,这当然是加速。但可能更重要的是,它让“我能做的事的范围”扩大了很多。Leverage(杠杆感)
关键点是:不要一条一条命令它怎么做。而是告诉它:“什么样算成功。”然后看它自己去折腾。
比如,你可以让它先写测试。然后再让它去通过自己写的这些测试。或者,把它和浏览器之类的工具(通过 MCP 接起来)放在一个循环里。再比如,你先写一个非常朴素、但几乎肯定正确的算法。然后让它在保证结果不变的前提下,帮你优化性能和结构。
整体思路,可以从“命令式”变成“声明式”:不再是“你先做 A,再做 B,再做 C”,而是“我要的结果长这样”。这样 Agent 会自己多迭代几轮,你就多拿了一层“杠杆”。Fun(好不好玩)
我也没那么容易卡死在一个地方。被卡住一点都不好玩。现在往往总能找到一种:“我和它一起合作,至少往前挪一点点”的方式。这会让人更有勇气开工。
当然,我也看到过完全相反的感受。有些人觉得 LLM 写代码让他们更不开心。
长期来看,这件事可能会把工程师分成两类:一类是主要喜欢“写代码这件事本身”的人。另一类是主要喜欢“把东西做出来”的人。Atrophy(能力退化)
bug。Questions(一些我在想的问题)
也就是:普通工程师和最强工程师之间的效率差距,会变得更大吗?非常有可能,会变得大很多。
有了 LLM 之后,“通才”会不会越来越能干过“专才”?
因为 LLM 在“补细节、填空白”(微观)方面特别强,但在“大局观、长期策略”(宏观)上就没那么厉害。
像在打《星际争霸》?像在玩《Factorio》(异星工厂)?还是更像在演奏一段音乐?
整个社会里,有多少东西,其实都卡在“数字化知识工作”的瓶颈上?总结:这把我们带到什么位置?
现在的感觉是:在“智能”这一块,它已经明显走在其它配套东西前面了。
比如:
工具和知识库的集成还没完全跟上。
团队内部需要新的工作流和协作方式。
整个行业对这些东西的消化和扩散,还在路上。
2026 年会是一个“能量很高”的年份。
整个行业都在努力消化、吸收这项新能力。
我们平常在微信应用上会看到有很多的公众号,但是各自并不一样,公众号也分很多种类型,不过最常见的就是服务号和订阅号了。下面我们来看一下他们的区别: 订阅号和服务号有一个比较明显的区别就是:订阅号都是存放在一个名叫订阅号的文件夹中,点开才能看到所有关注过的订阅号,但是服务号却和好友一样直接就显示在聊天列表中。这个大家打开微信客户端便能看到 以注册订阅号为例,访问注册地址:https://mp.weixin.qq.com/cgi-bin/registermidpage?action=index...\_CN&token= 填写基本信息,验证邮箱 选择账号类型 账号主体类型选择个人,填写信息 填写公众号信息 创建成功后,可以进入公众号的管理界面 主要针对非编程人员及信息发布类公众帐号 使用 。开启该模式后,可以方便地通过界面配置“自定义菜单”和“自动回复的消息”。好处是可视化界面配置,操作简单,快捷,但是功能有限 我们可以给自己的公众号设置关键词回复,收到已关注用户发送的消息,匹配到你好时回复一个你好~~ 主要针对具备开发能力的人使用。开启该模式后,能够使用微信公众平台开放的接口,但是编辑模式的设置会失效,比如“自定义菜单”和“自动回复的消息”功能。通过编程方式可以实现更多复杂的功能,提供个性化服务。 总的来说,编辑模式就是为所有人提供的,如果你的需求仅仅只是最常见的菜单,自动回复等,使用编辑模式已经满足,但是如果你需求的功能比较复杂,比如需要从自己的业务系统数据库中查询数据返回给微信用户,就需要使用到开发模式。 接下来我们介绍开发模式的各种功能使用步骤。出于安全考虑,普通的订阅号权限非常有限,可以调用的接口非常有限,不便于测试 所以,为了帮助开发者快速了解和上手微信公众号开发,熟悉各个接口的调用,微信推出了公众帐号测试号,无需公众帐号、快速申请接口测试号,通过手机微信扫描 二维码 即可获得,利用测试号我们可以体验和测试更多高级功能。测试号申请地址:https://mp.weixin.qq.com/debug/cgi-bin/sandbox?t=sandbox/login 我们首先了解下微信与我们的服务器交互的过程: 当我们在微信app上,给公众号发送一条内容的时候,实际会发送到微信的服务器上,此时微信的服务器就会对内容进行封装成某种格式的数据比如xml格式,再转发到我们配置好的某个URL上,所以该URL实际就是我们处理数据的一个请求路径。所以该URL必须是能暴露给外界访问的一个公网地址,不能使用内网地址,生产环境可以申请腾讯云,阿里云服务器等,但是在开发环境中可以暂时利用一些软件来完成内网穿透 在进行和微信公众号服务器交互之前,需要进行接入验证。接入验证涉及的2个关键参数如下: 接入验证的大致流程如下: 开发者通过检验signature对请求进行校验(下面有校验方式)。若确认此次GET请求来自微信服务器,请原样返回echostr参数内容,则接入生效,成为开发者成功,否则接入失败。加密/校验流程如下: 根据上述验证流程,我们创建一个Springboot应用,编写验证接口 利用内网穿透工具,将我们的本地应用地址映射到公网域名 然后在测试号页面填写回调url和正确的token,即可接入成功。如果token填错,将接入失败 特别注意: 接入成功以后,我们就可以利用微信提供的接口实现各种功能。首先来看一下基本的消息接收和回复,官方文档位置如下 当关注了公众号的用户向公众号发送消息时,微信服务器将POST消息的XML数据包到开发者填写的URL上。所以我们要在Controller中新建一个处理方法 微信会将用户发送的消息信息封装到请求体的xml中,根据消息类型的不同,xml的格式也有所不同: 我们对比一下不同类型的xml数据包中的参数, 接下来,我们可以创建一个封装消息的 实体类 ,把所有可接收到的参数都放进入,其他类型的暂时不演示,所以只在最后加入了文本和图片的参数。 这时候大家可能会有个疑问,为什么字段名称都是大写开头呢?因为微信服务器传过来的xml数据包中的xml元素都是大写开头的,如下所示: 因为xml解析是大小写敏感的,所以为了方便封装,我直接把字段名设置为大写开头。当然,如果还是想要小写开头的字段,也是可以的,我们待会再说处理方式。 实体已经建好之后,我们就可以开始接收微信传过来的xml数据了。 第1步:在handleMessage方法的形参上添加消息实体类型的参数: 第2步:需要配合JAXB的注解来解析xml。在消息实体类上添加以下两个注解: 这2个注解的含义如下: 之前我们为了方便解析,将消息实体类的属性命名成和xml中的节点一样都是大写开头,现在我们优化一下,按照java规范命名属性小写开头,然后利用 然后我们在Controller接收消息的方法中设置断点,关注测试公众号,给它发送一个文本消息"你好",就可以接收到了 官方文档:https://developers.weixin.qq.com/ doc /offiaccount/Message\_Management/Passive\_user\_reply\_message.html 当用户发送消息给公众号时(或某些特定的用户操作引发的 事件 推送时),会产生一个POST请求,开发者可以在响应包(Get)中返回特定XML结构,来对该消息进行响应(现支持回复文本、图片、图文、语音、视频、音乐)。严格来说,发送被动响应消息其实并不是一种接口,而是对微信服务器发过来消息的一次回复。 微信服务器在将用户的消息发给公众号的开发者服务器地址(开发者中心处配置)后,微信服务器在五秒内收不到响应会断掉连接,并且重新发起请求,总共重试三次,如果在调试中,发现用户无法收到响应的消息,可以检查是否消息处理超时。关于重试的消息排重,有msgid的消息推荐使用msgid排重。事件类型消息推荐使用FromUserName + CreateTime 排重。 如果开发者希望增强安全性,可以在开发者中心处开启消息加密,这样,用户发给公众号的消息以及公众号被动回复用户消息都会继续加密。 假如服务器无法保证在五秒内处理并回复,必须做出下述回复,这样微信服务器才不会对此作任何处理,并且不会发起重试(这种情况下,可以使用客服消息接口进行异步回复),否则,将出现严重的错误提示: 一旦遇到以下情况,微信都会在公众号会话中,向用户下发系统提示“该公众号暂时无法提供服务,请稍后再试”: 另外,请注意,回复图片(不支持gif动图)等多媒体消息时需要预先通过素材管理接口上传临时素材到微信服务器,可以使用素材管理中的临时素材,也可以使用永久素材。 各种类型的响应消息格式如下: 我们可以看到回复的格式中除了都没有MsgId,只有普通文本和接收的格式基本是一样的,图片消息或其他类型的消息与接收到的格式相比,多了xml元素的嵌套,所以原先定义的接收消息实体类无法复用,我们再封装一个响应消息的实体类,这里暂时只考虑文本和图片类型 现在我们来实现一下简单的回复消息:用户给我们发什么,我们就回复什么,只需要把接收到 测试效果如下 在开发模式下要实现关键字回复非常简单,只要判断发送过来的文本消息中是否包含关键字,然后给予相应的回复即可 官方文档:https://developers.weixin.qq.com/doc/offiaccount/Message\_Management/Receiving\_event\_pushes.html 我们之前的案例都是用户发送信息过来,我们才回复的。但是,如果是关注的时候需要马上回复,就要使用到事件消息,实际上,微信已经提供给我们很多的事件 在微信用户和公众号产生交互的过程中,用户的某些操作会使得微信服务器通过事件推送的形式通知到开发者在开发者中心处设置的服务器地址,从而开发者可以获取到该信息。其中,某些事件推送在发生后,是允许开发者回复用户的,某些则不允许 用户在关注与取消关注公众号时,微信会把这个事件推送到开发者填写的URL。方便开发者给用户下发欢迎消息或者做帐号的解绑。为保护用户数据隐私,开发者收到用户取消关注事件时需要删除该用户的所有信息。 微信服务器在五秒内收不到响应会断掉连接,并且重新发起请求,总共重试三次。 关于重试的消息排重,推荐使用FromUserName + CreateTime 排重。 假如服务器无法保证在五秒内处理并回复,可以直接回复空串,微信服务器不会对此作任何处理,并且不会发起重试。 推送XML数据包示例: 用户扫描带场景值二维码时,可能推送以下两种事件: 这个事件仅用于服务号,订阅号不行。用户同意上报地理位置后,每次进入公众号会话时,都会在进入时上报地理位置,或在进入会话后每5秒上报一次地理位置,公众号可以在公众平台网站中修改以上设置。上报地理位置时,微信会将上报地理位置事件推送到开发者填写的URL。 推送XML数据包示例: 用户点击自定义菜单后,微信会把点击事件推送给开发者,请注意,点击菜单弹出子菜单,不会产生上报。 点击菜单拉取消息时的事件推送 点击菜单跳转链接时的事件推送 我们来实现一下用户关注公众号时接收推送消息并自动回复的功能 事件和消息都是推送到我们的URL上,怎么区分他们也很简单,通过 然后在Controller处理方法中添加对应逻辑 然后取消关注后再关注,即可展现效果 官方文档:https://developers.weixin.qq.com/doc/offiaccount/Custom\_Menus/Creating\_Custom-Defined\_Menu.html 自定义菜单能够帮助公众号丰富界面,让用户更好更快地理解公众号的功能。开启自定义菜单后,公众号界面如图所示: 请注意: 自定义菜单接口可实现多种类型按钮,如下: 如果我们要给公众号创建自定义菜单,需要发送下列请求 http请求方式:POST(请使用https协议) https://api.weixin.qq.com/cgi-bin/menu/create?access\_token=ACCESS\_TOKEN 请求体示例如下: 正确时的返回 JSON 数据包如下: 错误时的返回JSON数据包如下(示例为无效菜单名长度): 其他类型的菜单示例如下 在我们调用创建菜单接口之前,必须先获取调用微信接口的 公众平台的API调用所需的access\_token的使用及生成方式说明: 公众号和小程序均可以使用AppID和AppSecret调用本接口来获取access\_token。AppID和AppSecret可在“微信公众平台-开发-基本配置”页中获得(需要已经成为开发者,且帐号没有异常状态)。**调用接口时,请登录“微信公众平台-开发-基本配置”提前将服务器IP地址添加到IP白名单中,否则将无法调用成功。**小程序无需配置IP白名单。 获取 https请求方式: GET https://api.weixin.qq.com/cgi-bin/token?grant\_type=client\_credential&appid=APPID&secret=APPSECRET 正常情况下,微信会返回下述JSON数据包给公众号: 错误时微信会返回错误码等信息,JSON数据包示例如下(该示例为AppID无效错误): 在Controller中创建获取 在Controller中新增方法,发送创建菜单的请求 发送请求后返回结果 创建菜单后效果如下 官方文档:https://developers.weixin.qq.com/doc/offiaccount/Message\_Management/Template\_Message\_Interface.html 在我们的生活中,无论是微商城消费,还是日常生活消费,都可能收到这种提示,比如订单通知,快递状态通知,银行卡支付通知,都属于业务通知,很多公众号也都实现了这种功能,当触发了某种行为或状态改变,就会发送这么一个消息给你,因为这种消息都是按照一定的的格式来编辑,所以也叫模板消息 我们要发送模板消息,第一步是需要创建一个模板,有了模板之后,我们才能填充内容来进行发送。创建模板不需要调用接口,在公众号后台即可设置 现在我们来按照下面案例来新建一个模板。但是模板的内容是有一定的规则的,不能随便添加: 保存之后,微信会给该模板分配一个ID,待我们要发送模板消息的时候就需要用到这个ID了 发送模板消息需要如下请求: http请求方式: POST https://api.weixin.qq.com/cgi-bin/message/template/send?access\_token=ACCESS\_TOKEN 请求体示例如下 在调用模板消息接口后,会返回JSON数据包。正常时的返回JSON数据包示例:微信公众号介绍
1.公众号的分类


2.公众号注册流程







3.公众号的管理模式
3.1 编辑模式


编辑模式只能预先自定义一些固定的规则和数据,这些数据会保存在微信服务器,只能完成一些简单的功能。如果要完成更复杂的功能,比如根据用户输入信息动态获取数据返回,则需要使用开发模式
3.2 开发模式



但测试号也不是万能的,部分高级功能,如微信支付,卡券功能等也是不开放的。如果要实现支付功能还是得去注册个正式的公众号。本文后续所有测试都基于测试公众号
接入开发模式


参数 描述 signature 微信加密签名,signature结合了开发者填写的token参数和请求中的timestamp参数、nonce参数。 timestamp 时间戳 nonce 随机数 echostr 随机字符串 注意到微信发送的GET请求中并没有携带我们填写的token,而签名
signature的生成过程中token是一个入参,所以我们填写的url处理程序中,校验signature时也需要token,这就要求我们在url对应的后端程序中定义token,要和通过微信页面填写的token一致。这样做是为了安全性,只有知道token才可以接入成功,避免了他人盗用公众号做操作
@RestController
@RequestMapping("wechat/publicAccount")
public class WechatPublicAccountController {
// 微信页面填写的token,必须保密
private static final String TOKEN = "";
@GetMapping("validate")
public String validate(String signature,String timestamp,String nonce,String echostr){
// 1. 将token、timestamp、nonce三个参数进行字典序排序
String[] arr = {timestamp, nonce, TOKEN};
Arrays.sort(arr);
// 2. 将三个参数字符串拼接成一个字符串进行sha1加密
StringBuilder sb = new StringBuilder();
for (String temp : arr) {
sb.append(temp);
}
// 这里利用了hutool的加密工具类
String sha1 = SecureUtil.sha1(sb.toString());
// 3. 加密后的字符串与signature对比,如果相同则该请求来源于微信,原样返回echostr
if (sha1.equals(signature)){
return echostr;
}
// 接入失败
return null;
}
}

signature、timestamp、nonce这3个参数,我们每次接收微信消息时都要跟初始接入一样去校验signature,以确保接收到的消息是微信发过来的,而不是其他人发过来的echostr,后续所有微信发过来的消息不会携带echostr,所以可以根据请求是否携带了echostr来判断是否是接入消息。接入消息除了校验signature外要原样返回echostr,其他后续消息只需校验signature即可消息接收与响应
1.接收消息


<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[this is a test]]></Content>
<MsgId>1234567890123456</MsgId>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 消息类型,文本为text Content 文本消息内容 MsgId 消息id,64位整型 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<PicUrl><![CDATA[this is a url]]></PicUrl>
<MediaId><![CDATA[media_id]]></MediaId>
<MsgId>1234567890123456</MsgId>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 消息类型,图片为image PicUrl 图片链接(由系统生成) MediaId 图片消息媒体id,可以调用获取临时素材接口拉取数据。 MsgId 消息id,64位整型 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1357290913</CreateTime>
<MsgType><![CDATA[voice]]></MsgType>
<MediaId><![CDATA[media_id]]></MediaId>
<Format><![CDATA[Format]]></Format>
<MsgId>1234567890123456</MsgId>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 语音为voice MediaId 语音消息媒体id,可以调用获取临时素材接口拉取数据。 Format 语音格式,如amr,speex等 MsgId 消息id,64位整型 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1357290913</CreateTime>
<MsgType><![CDATA[video]]></MsgType>
<MediaId><![CDATA[media_id]]></MediaId>
<ThumbMediaId><![CDATA[thumb_media_id]]></ThumbMediaId>
<MsgId>1234567890123456</MsgId>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 视频为video MediaId 视频消息媒体id,可以调用获取临时素材接口拉取数据。 ThumbMediaId 视频消息缩略图的媒体id,可以调用多媒体文件下载接口拉取数据。 MsgId 消息id,64位整型 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1357290913</CreateTime>
<MsgType><![CDATA[shortvideo]]></MsgType>
<MediaId><![CDATA[media_id]]></MediaId>
<ThumbMediaId><![CDATA[thumb_media_id]]></ThumbMediaId>
<MsgId>1234567890123456</MsgId>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 小视频为shortvideo MediaId 视频消息媒体id,可以调用获取临时素材接口拉取数据。 ThumbMediaId 视频消息缩略图的媒体id,可以调用获取临时素材接口拉取数据。 MsgId 消息id,64位整型 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1351776360</CreateTime>
<MsgType><![CDATA[location]]></MsgType>
<Location_X>23.134521</Location_X>
<Location_Y>113.358803</Location_Y>
<Scale>20</Scale>
<Label><![CDATA[位置信息]]></Label>
<MsgId>1234567890123456</MsgId>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 消息类型,地理位置为location Location\_X 地理位置纬度 Location\_Y 地理位置经度 Scale 地图缩放大小 Label 地理位置信息 MsgId 消息id,64位整型 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1351776360</CreateTime>
<MsgType><![CDATA[link]]></MsgType>
<Title><![CDATA[公众平台官网链接]]></Title>
<Description><![CDATA[公众平台官网链接]]></Description>
<Url><![CDATA[url]]></Url>
<MsgId>1234567890123456</MsgId>
</xml>参数 描述 ToUserName 接收方微信号 FromUserName 发送方微信号,若为普通用户,则是一个OpenID CreateTime 消息创建时间 MsgType 消息类型,链接为link Title 消息标题 Description 消息描述 Url 消息链接 MsgId 消息id,64位整型 ToUserName,FromUserName,CreateTime,MsgType,MsgId这五个是公共的,所有类型都会带上这些参数。接下来,我们需要来了解这5个参数的具体意义:ToUserName:文档上描述的是开发者微信号,实际上,直接把它当做你的公众号的微信号即可,表示的是发到那个公众号的意思。FromUserName:与ToUserName相反,这是代表是由哪个用户发过来的,同一个用户发多条信息过来,FromUserName都是不变的。但这并不是用户的微信号,而是一个OpenID。那什么是OpenID呢:当用户和公众号发生了交互,微信服务器会为每个用户针对每个公众号产生一个OpenID(也就是指该OpenID是利用两个因素:用户和公众号来产生的,也就意味着如果该用户跟另外一个公众号交互,产生的OpenID也是不同的,这样安全性会比较高),如果一个公司有多个公众号,并且需要在多公众号、移动应用之间做用户共通,则需要使用UnionID,前往微信开放平台,将这些公众号和应用绑定到一个开放平台账号下,绑定后,一个用户虽然对多个公众号和应用有多个不同的OpenID,但他对所有这些同一开放平台账号下的公众号和应用,只有一个UnionID,可以在用户管理-获取用户基本信息(UnionID机制)文档了解详情。CreateTime:消息创建时间MsgType:用户发送的消息的类型,如text代表文本消息,image代表图片消息等。MsgId:用户发送的每个消息都有自己的id,可以用于消息排重,比如微信服务器把xml消息包发送到URL了,但是五秒内微信服务器没有收到我们的响应,则会重新发起请求,总共重试三次。如果不做消息排重,那么用户可能就收到多条相同的响应消息了。微信服务器在五秒内收不到响应会断掉连接,并且重新发起请求,总共重试三次。假如服务器无法保证在五秒内处理并回复,可以直接回复空串,微信服务器不会对此作任何处理,并且不会发起重试
@Data
@AllArgsConstructor
@NoArgsConstructor
public class InMessage {
// 开发者微信号
protected String FromUserName;
// 发送方帐号(一个OpenID)
protected String ToUserName;
// 消息创建时间
protected Long CreateTime;
/**
* 消息类型
* text 文本消息
* image 图片消息
* voice 语音消息
* video 视频消息
* music 音乐消息
*/
protected String MsgType;
// 消息id
protected Long MsgId;
// 文本内容
private String Content;
// 图片链接(由系统生成)
private String PicUrl;
// 图片消息媒体id,可以调用多媒体文件下载接口拉取数据
private String MediaId;
}<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[this is a test]]></Content>
<MsgId>1234567890123456</MsgId>
</xml>

@XmlRootElement:是一个类级别注解,主要属性为name,意为指定根节点的名字。往上面看前面举了个微信传过来的xml数据的例子里,里面的根节点就是"xml",所以这里就直接设置name=“xml”@XmlAccessorType:用于定义这个类中的何种类型需要映射到XML中XmlAccessType.PROPERTY:代表映射这个类中的属性(get/set方法)到XMLXmlAccessType.FIELD:代表映射这个类中的所有字段到XML@XmlElement给每个属性标注对应的xml节点名称@Data
@AllArgsConstructor
@NoArgsConstructor
@XmlRootElement(name = "xml")
@XmlAccessorType(XmlAccessType.FIELD)
public class InMessage {
/**
* 开发者微信号
*/
@XmlElement(name="FromUserName")
protected String fromUserName;
/**
* 发送方帐号(一个OpenID)
*/
@XmlElement(name="ToUserName")
protected String toUserName;
/**
* 消息创建时间
*/
@XmlElement(name="CreateTime")
protected Long createTime;
/**
* 消息类型
* text 文本消息
* image 图片消息
* voice 语音消息
* video 视频消息
* music 音乐消息
*/
@XmlElement(name="MsgType")
protected String msgType;
/**
* 消息id
*/
@XmlElement(name="MsgId")
protected Long msgId;
/**
* 文本内容
*/
@XmlElement(name="Content")
private String content;
/**
* 图片链接(由系统生成)
*/
@XmlElement(name="PicUrl")
private String picUrl;
/**
* 图片消息媒体id,可以调用多媒体文件下载接口拉取数据
*/
@XmlElement(name="MediaId")
private String mediaId;
}
2.响应消息
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>12345678</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[你好]]></Content>
</xml>参数 是否必须 描述 ToUserName 是 接收方帐号(收到的OpenID) FromUserName 是 开发者微信号 CreateTime 是 消息创建时间 (整型) MsgType 是 消息类型,文本为text Content 是 回复的消息内容(换行:在content中能够换行,微信客户端就支持换行显示) <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>12345678</CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<Image>
<MediaId><![CDATA[media_id]]></MediaId>
</Image>
</xml>参数 是否必须 说明 ToUserName 是 接收方帐号(收到的OpenID) FromUserName 是 开发者微信号 CreateTime 是 消息创建时间 (整型) MsgType 是 消息类型,图片为image MediaId 是 通过素材管理中的接口上传多媒体文件,得到的id。 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>12345678</CreateTime>
<MsgType><![CDATA[voice]]></MsgType>
<Voice>
<MediaId><![CDATA[media_id]]></MediaId>
</Voice>
</xml>参数 是否必须 说明 ToUserName 是 接收方帐号(收到的OpenID) FromUserName 是 开发者微信号 CreateTime 是 消息创建时间戳 (整型) MsgType 是 消息类型,语音为voice MediaId 是 通过素材管理中的接口上传多媒体文件,得到的id <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>12345678</CreateTime>
<MsgType><![CDATA[video]]></MsgType>
<Video>
<MediaId><![CDATA[media_id]]></MediaId>
<Title><![CDATA[title]]></Title>
<Description><![CDATA[description]]></Description>
</Video>
</xml>参数 是否必须 说明 ToUserName 是 接收方帐号(收到的OpenID) FromUserName 是 开发者微信号 CreateTime 是 消息创建时间 (整型) MsgType 是 消息类型,视频为video MediaId 是 通过素材管理中的接口上传多媒体文件,得到的id Title 否 视频消息的标题 Description 否 视频消息的描述 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>12345678</CreateTime>
<MsgType><![CDATA[music]]></MsgType>
<Music>
<Title><![CDATA[TITLE]]></Title>
<Description><![CDATA[DESCRIPTION]]></Description>
<MusicUrl><![CDATA[MUSIC_Url]]></MusicUrl>
<HQMusicUrl><![CDATA[HQ_MUSIC_Url]]></HQMusicUrl>
<ThumbMediaId><![CDATA[media_id]]></ThumbMediaId>
</Music>
</xml>参数 是否必须 说明 ToUserName 是 接收方帐号(收到的OpenID) FromUserName 是 开发者微信号 CreateTime 是 消息创建时间 (整型) MsgType 是 消息类型,音乐为music Title 否 音乐标题 Description 否 音乐描述 MusicURL 否 音乐链接 HQMusicUrl 否 高质量音乐链接,WIFI环境优先使用该链接播放音乐 ThumbMediaId 是 缩略图的媒体id,通过素材管理中的接口上传多媒体文件,得到的id <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>12345678</CreateTime>
<MsgType><![CDATA[news]]></MsgType>
<ArticleCount>1</ArticleCount>
<Articles>
<item>
<Title><![CDATA[title1]]></Title>
<Description><![CDATA[description1]]></Description>
<PicUrl><![CDATA[picurl]]></PicUrl>
<Url><![CDATA[url]]></Url>
</item>
</Articles>
</xml>参数 是否必须 说明 ToUserName 是 接收方帐号(收到的OpenID) FromUserName 是 开发者微信号 CreateTime 是 消息创建时间 (整型) MsgType 是 消息类型,图文为news ArticleCount 是 图文消息个数;当用户发送文本、图片、语音、视频、图文、地理位置这六种消息时,开发者只能回复1条图文消息;其余场景最多可回复8条图文消息 Articles 是 图文消息信息,注意,如果图文数超过限制,则将只发限制内的条数 Title 是 图文消息标题 Description 是 图文消息描述 PicUrl 是 图片链接,支持JPG、PNG格式,较好的效果为大图360*200,小图200*200 Url 是 点击图文消息跳转链接 @Data
@AllArgsConstructor
@NoArgsConstructor
@XmlRootElement(name = "xml")
@XmlAccessorType(XmlAccessType.FIELD)
public class OutMessage {
/**
* 开发者微信号
*/
@XmlElement(name="FromUserName")
protected String fromUserName;
/**
* 发送方帐号(一个OpenID)
*/
@XmlElement(name="ToUserName")
protected String toUserName;
/**
* 消息创建时间
*/
@XmlElement(name="CreateTime")
protected Long createTime;
/**
* 消息类型
* text 文本消息
* image 图片消息
* voice 语音消息
* video 视频消息
* music 音乐消息
*/
@XmlElement(name="MsgType")
protected String msgType;
/**
* 文本内容
*/
@XmlElement(name="Content")
private String content;
/**
* 图片的媒体id列表
*/
@XmlElementWrapper(name="Image") // 表示MediaId属性内嵌于<Image>标签
@XmlElement(name = "MediaId")
private String[] mediaId;
}@XmlElementWrapper注解可以在原xml结点上再包装一层xml,但仅允许出现在数组或集合属性上InMessage的内容设置到OutMessage上,并且把ToUserName与FromUserName的值设置为相反即可@PostMapping(value = "validate", produces = "application/xml;charset=UTF-8")
public Object handleMessage(@RequestBody InMessage inMessage){
// 创建响应消息实体对象
OutMessage outMessage = new OutMessage();
// 把原来的接收方设置为发送方
outMessage.setFromUserName(inMessage.getToUserName());
// 把原来的发送方设置为接收方
outMessage.setToUserName(inMessage.getFromUserName());
// 设置消息类型
outMessage.setMsgType(inMessage.getMsgType());
// 设置消息时间
outMessage.setCreateTime(System.currentTimeMillis());
// 根据接收到消息类型,响应对应的消息内容
if ("text".equals(inMessage.getMsgType())){
// 文本
outMessage.setContent(inMessage.getContent());
}else if ("image".equals(inMessage.getMsgType())){
// 图片
outMessage.setMediaId(new String[]{inMessage.getMediaId()});
}
return outMessage;
}注意:这里要在接口的
@PostMapping中指定produces = "application/xml;charset=UTF-8",表示返回的数据格式是xml,否则将默认以json格式返回
关键字回复
@PostMapping(value = "validate", produces = "application/xml;charset=UTF-8")
public Object handleMessage(@RequestBody InMessage inMessage){
// 创建响应消息实体对象
OutMessage outMessage = new OutMessage();
// 把原来的接收方设置为发送方
outMessage.setFromUserName(inMessage.getToUserName());
// 把原来的发送方设置为接收方
outMessage.setToUserName(inMessage.getFromUserName());
// 设置消息类型
outMessage.setMsgType(inMessage.getMsgType());
// 设置消息时间
outMessage.setCreateTime(System.currentTimeMillis() / 1000);
// 根据接收到消息类型,响应对应的消息内容
if ("text".equals(inMessage.getMsgType())){
// 根据不同的关键字回复消息
String inContent = inMessage.getContent();
if (inContent.contains("游戏")){
outMessage.setContent("仙剑");
}else if (inContent.contains("动漫")){
outMessage.setContent("进击的巨人");
}else {
outMessage.setContent(inContent);
}
}else if ("image".equals(inMessage.getMsgType())){
// 图片
outMessage.setMediaId(new String[]{inMessage.getMediaId()});
}
return outMessage;
}
事件推送
1.关注/取消关注事件
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[FromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[subscribe]]></Event>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 消息类型,event Event 事件类型,subscribe(订阅)、unsubscribe(取消订阅) 2.扫描带参数二维码事件
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[FromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[subscribe]]></Event>
<EventKey><![CDATA[qrscene_123123]]></EventKey>
<Ticket><![CDATA[TICKET]]></Ticket>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 消息类型,event Event 事件类型,subscribe EventKey 事件KEY值,qrscene\_为前缀,后面为二维码的参数值 Ticket 二维码的ticket,可用来换取二维码图片 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[FromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[SCAN]]></Event>
<EventKey><![CDATA[SCENE_VALUE]]></EventKey>
<Ticket><![CDATA[TICKET]]></Ticket>
</xml> 参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 消息类型,event Event 事件类型,SCAN EventKey 事件KEY值,是一个32位无符号整数,即创建二维码时的二维码scene\_id Ticket 二维码的ticket,可用来换取二维码图片 3.上报地理位置事件
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[LOCATION]]></Event>
<Latitude>23.137466</Latitude>
<Longitude>113.352425</Longitude>
<Precision>119.385040</Precision>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 消息类型,event Event 事件类型,LOCATION Latitude 地理位置纬度 Longitude 地理位置经度 Precision 地理位置精度 4.自定义菜单事件
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[FromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[CLICK]]></Event>
<EventKey><![CDATA[EVENTKEY]]></EventKey>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 消息类型,event Event 事件类型,CLICK EventKey 事件KEY值,与自定义菜单接口中KEY值对应 <xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[FromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[VIEW]]></Event>
<EventKey><![CDATA[www.qq.com]]></EventKey>
</xml>参数 描述 ToUserName 开发者微信号 FromUserName 发送方帐号(一个OpenID) CreateTime 消息创建时间 (整型) MsgType 消息类型,event Event 事件类型,VIEW EventKey 事件KEY值,设置的跳转URL 事件推送案例演示
MsgType这个属性,那么进一步再区分是关注还是取消关注,根据Event属性即可。所以,我们在原来的InMessage类,再添加一个Event属性


自定义菜单
1.自定义菜单简介

请注意,3到8的所有事件,仅支持微信iPhone5.4.1以上版本,和Android5.4以上版本的微信用户,旧版本微信用户点击后将没有回应,开发者也不能正常接收到事件推送。9和10,是专门给第三方平台旗下未微信认证(具体而言,是资质认证未通过)的订阅号准备的事件类型,它们是没有事件推送的,能力相对受限,其他类型的公众号不必使用。
{
"button":[
{
"type":"click",
"name":"今日歌曲",
"key":"V1001_TODAY_MUSIC"
},
{
"name":"菜单",
"sub_button":[
{
"type":"view",
"name":"搜索",
"url":"http://www.soso.com/"
},
{
"type":"miniprogram",
"name":"wxa",
"url":"http://mp.weixin.qq.com",
"appid":"wx286b93c14bbf93aa",
"pagepath":"pages/lunar/index"
},
{
"type":"click",
"name":"赞一下我们",
"key":"V1001_GOOD"
}]
}]
}参数 是否必须 说明 button 是 一级菜单数组,个数应为1~3个 sub\_button 否 二级菜单数组,个数应为1~5个 type 是 菜单的响应动作类型,view表示网页类型,click表示点击类型,miniprogram表示小程序类型 name 是 菜单标题,不超过16个字节,子菜单不超过60个字节 key click等点击类型必须 菜单KEY值,用于消息接口推送,不超过128字节 url view、miniprogram类型必须 网页 链接,用户点击菜单可打开链接,不超过1024字节。 type为miniprogram时,不支持小程序的老版本客户端将打开本url。 media\_id media\_id类型和view\_limited类型必须 调用新增永久素材接口返回的合法media\_id appid miniprogram类型必须 小程序的appid(仅认证公众号可配置) pagepath miniprogram类型必须 小程序的页面路径 {"errcode":0,"errmsg":"ok"}{"errcode":40018,"errmsg":"invalid button name size"}{
"button": [
{
"name": "扫码",
"sub_button": [
{
"type": "scancode_waitmsg",
"name": "扫码带提示",
"key": "rselfmenu_0_0",
"sub_button": [ ]
},
{
"type": "scancode_push",
"name": "扫码推事件",
"key": "rselfmenu_0_1",
"sub_button": [ ]
}
]
},
{
"name": "发图",
"sub_button": [
{
"type": "pic_sysphoto",
"name": "系统拍照发图",
"key": "rselfmenu_1_0",
"sub_button": [ ]
},
{
"type": "pic_photo_or_album",
"name": "拍照或者相册发图",
"key": "rselfmenu_1_1",
"sub_button": [ ]
},
{
"type": "pic_weixin",
"name": "微信相册发图",
"key": "rselfmenu_1_2",
"sub_button": [ ]
}
]
},
{
"name": "发送位置",
"type": "location_select",
"key": "rselfmenu_2_0"
},
{
"type": "media_id",
"name": "图片",
"media_id": "MEDIA_ID1"
},
{
"type": "view_limited",
"name": "图文消息",
"media_id": "MEDIA_ID2"
}
]
}2.获取access\_token
access_token。access_token是公众号的全局唯一接口调用凭据,公众号调用各接口时都需使用access_token。开发者需要进行妥善保存。access\_token的存储至少要保留512个字符空间。access\_token的有效期目前为2个小时,需定时刷新,重复获取将导致上次获取的access\_token失效。access_token需要调用的接口如下参数 是否必须 说明 grant\_type 是 获取access\_token填写client\_credential appid 是 公众号唯一凭证,注册成功后由微信提供 secret 是 公众号唯一凭证密钥,注册成功后由微信提供 {"access_token":"ACCESS_TOKEN","expires_in":7200}参数 说明 access\_token 获取到的凭证 expires\_in 凭证有效时间,单位:秒 {"errcode":40013,"errmsg":"invalid appid"}返回码 说明 -1 系统繁忙,此时请开发者稍候再试 0 请求成功 40001 AppSecret错误或者AppSecret不属于这个公众号,请开发者确认AppSecret的正确性 40002 请确保grant\_type字段值为client\_credential 40164 调用接口的IP地址不在白名单中,请在接口IP白名单中进行设置。(小程序及小游戏调用不要求IP地址在白名单内。) 89503 此IP调用需要管理员确认,请联系管理员 89501 此IP正在等待管理员确认,请联系管理员 89506 24小时内该IP被管理员拒绝调用两次,24小时内不可再使用该IP调用 89507 1小时内该IP被管理员拒绝调用一次,1小时内不可再使用该IP调用 access_token的方法,获取成功后将其保存到redis中@GetMapping("getAccessToken")
public String getAccessToken(){
String url = "https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=" + APPID +
"&secret=" + APPSECRET;
// 利用hutool的http工具类请求获取access_token
String result = HttpUtil.get(url);
// 将结果解析为json
JSONObject jsonObject = JSONUtil.parseObj(result);
// 获取access_token
String accessToken = jsonObject.getStr("access_token");
if (!StringUtils.isEmpty(accessToken)){
// 将access_token存入redis
stringRedisTemplate.opsForValue().set("access_token", accessToken);
}
return accessToken;
}3.创建自定义菜单
@GetMapping("createMenu")
public String createMenu(){
// 从redis中取出access_token
String accessToken = stringRedisTemplate.opsForValue().get("access_token");
String url = "https://api.weixin.qq.com/cgi-bin/menu/create?access_token=" + accessToken;
// 创建菜单的请求体
String body = "{\n" +
" \"button\":[\n" +
" {\t\n" +
" \"type\":\"click\",\n" +
" \"name\":\"位置\",\n" +
" \"key\":\"button_location\"\n" +
" }]}";
return HttpUtil.post(url, body);
}{"errcode":0,"errmsg":"ok"}
发送模板消息

认证后的服务号才可以申请模板消息的使用权限并获得该权限,否则就只能使用测试号


{
"touser":"OPENID",
"template_id":"ngqIpbwh8bUfcSsECmogfXcV14J0tQlEpBO27izEYtY",
"url":"http://weixin.qq.com/download",
"miniprogram":{
"appid":"xiaochengxuappid12345",
"pagepath":"index?foo=bar"
},
"data":{
"goodsName":{
"value":"巧克力",
"color":"#173177"
},
"price": {
"value":"39.8元",
"color":"#173177"
},
"time": {
"value":"2014年9月22日",
"color":"#173177"
},
"remark":{
"value":"欢迎再次购买!",
"color":"#173177"
}
}
}参数 是否必填 说明 touser 是 接收者openid template\_id 是 模板ID url 否 模板跳转链接(海外帐号没有跳转能力) miniprogram 否 跳小程序所需数据,不需跳小程序可不用传该数据 appid 是 所需跳转到的小程序appid(该小程序appid必须与发模板消息的公众号是绑定关联关系,暂不支持小游戏) pagepath 否 所需跳转到小程序的具体页面路径,支持带参数,(示例index?foo=bar),要求该小程序已发布,暂不支持小游戏 data 是 模板数据 color 否 模板内容字体颜色,不填默认为黑色 {
"errcode":0,
"errmsg":"ok",
"msgid":200228332
}
OpenClaw(曾用名 Clawdbot、Moltbot)是一款本地优先、可自托管的AI自动化代理工具,由开发者 Peter Steinberger 于2025年底创建。核心理念是:“The AI that actually does things”——真正能做事的AI。 与传统聊天机器人不同,OpenClaw 不仅能理解自然语言,还能主动规划任务、调用工具、执行操作并反馈结果,形成“需求解析 → 任务规划 → 工具调用 → 结果反馈”的完整闭环。 OpenCode 与 Claude Code 聚焦开发者,OpenWork 与 Claude Cowork 服务办公人群,而OpenClaw 则是面向个人的全场景自动化中枢。 确认机器环境,需要符合如下要求。 通过 npm 全局安装 openclaw 并运行新手引导。 初始化配置与验证:安装完成后,自动启动配置向导(或手动执行命令);向导将引导完成以下配置: 更多参考:Link 云服务快速安装:针对希望快速上线、免本地环境折腾的受众,建议进行云端安装。可提供更稳定的公网访问能力,服务可持续运行、随时随地都能连接使用。如 阿里云、腾讯云 等。 更多可参考各云厂商文档,比如:Link 在上述配置完成后,需重启OpenClaw服务使配置生效,OpenClaw将加载新配置的百炼模型,然后可进行后续的验证操作。 前往腾讯QQ开放平台官网,在龙虾专用入口单击创建机器人,生成新的QQ机器人,并获取机器人的AppID和AppSecret。 安装QQ Channel,然后登录 OpenClaw 控制台进行QQ渠道配置;填入上文获取的App ID和App Secret,并单击应用生效。 依次完成OpenClaw安装、模型配置、QQ Channel配置后,可对话体验OpenClaw:养虾成功,更多Skills及价值研究挖掘中~1、OpenClaw介绍
2、AI代理工具对比
工具 归属类别 开源/闭源 核心载体 目标用户 核心优势 OpenCode 编程专用 AI 代理 开源(MIT) 终端优先,支持 IDE / 桌面 终端开发者、极客、小团队 多模型兼容、本地优先、高度可定制 Claude Code 编程专用 AI 代理 闭源 终端 / IDE / 桌面 专业开发者、企业团队 模型强、稳定性高、企业级安全 OpenWork 通用办公 AI 代理 开源(MIT) 桌面 GUI(基于 OpenCode) 非技术员工、混合团队 可视化工作流、低门槛、本地可控 Claude Cowork 通用办公 AI 代理 闭源 桌面应用 全岗位办公人群、企业 开箱即用、跨工具联动、沙盒安全 OpenClaw 全场景本地自动化AI 代理 开源(MIT) 本地网关(CLI) 个人 / 轻量团队、自动化需求者 跨渠道控制、持久记忆、完全自托管 3、OpenClaw部署
3.1、安装系统要求
1、Node >=22
2、macOS、Linux 或通过 WSL2 的 Windows
3、pnpm 仅在从源代码构建时需要3.2、OpenClaw安装
方式1、本机安装
curl -fsSL https://openclaw.ai/install.sh | bashopenclaw onboard方式2、云服务快速安装
4、OpenClaw体验

5、QQ Channel集成
5.1、QQ机器人创建

5.2、OpenClaw配置集成:
// 安装 QQ Bot 插件(云服务版默认集成QQ插件、且提供工作台设置AppID等信息,可跳过该配置)
openclaw plugins install @sliverp/qqbot
// 执行命令添加账号凭证(将 你的AppID 和 你的AppSecret 替换为真实值):
openclaw channels add --channel qqbot --token "你的AppID:你的AppSecret"6、OpenClaw体验

IObit Uninstaller 是一款功能强大的卸载软件,旨在帮助用户轻松、快速、彻底地卸载他们计算机上的软件程序。 安装 包下载:https://pan.quark.cn/s/f8d9785c2eb8 ,先下载好 IObit Uninstaller Pro v13.1.0.3 安装包(压缩包形式),保存到电脑本地。 解压安装包: 找到下载的 运行软件: 打开解压后的文件夹,双击 成功打开 IObit Uninstaller Pro 主界面,说明安装完成! 一、准备工作
二、安装 IObit Uninstaller Pro v13.1.0.3
IObitUninstaller-Pro-v13.1.0.3压缩包,右键点击 → 选择【解压到 IObitUninstaller-Pro-v13.1.0.3】。IObitUninstaller-Pro-v13.1.0.3可执行文件,即可启动软件。三、验证安装