Vibe coding 有什么意义?
除了做 demo ,任何一个需要稳定性的系统都不应该使用 vibe coding 实现。全黑盒,完全不可控。
之前的一家公司,PM 开始自己 vibe coding ,推到上线后结果完全不可维护,到最后还是研发来擦屁股。产品爽了,最后烂摊子研发全接走?
之前的一家公司,PM 开始自己 vibe coding ,推到上线后结果完全不可维护,到最后还是研发来擦屁股。产品爽了,最后烂摊子研发全接走?
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
https://developers.openai.com/api/docs/pricing?latest-pricing=standard
| Model | Input Credits | Output Credits |
|---|---|---|
| GPT-5.3-Codex | 43.75 | 350 |
| GPT-5.4 | 62.50 | 375 |
| GPT-5.5 | 125 | 750 |
天塌了啊,最新 openai 的模型越来越贵,穷人要用不起了啊
看 gpt5.5 的 token 价格翻倍了感觉不妙,结果一看 codex 消耗果然相比 5.4 也翻倍了
本来 codex 的 credit 计算规则改了后就明显消耗量加快了,结果现在 5.5 用量还翻倍了
然后 codex 中 5.5 默认的推理强度还是 extra high 。。。。。
当作和 opus 一样的高级模型好了。。。。

各位Cder好,我是长期混迹在金融系统开发前线的一名后端工程师。最近在帮业务线排查一个网络IO问题时,我发现了一个非常有意思的现象:每逢法定长假,我们接入的A股实时行情服务就会大量爆出超时日志,甚至引发上游服务的雪崩。经过深入的源码级排查,我意识到这不仅仅是简单的网络问题,而是业务场景与网络协议之间的碰撞。今天就来和大家硬核分享一下。 在我们这套架构里,我们需要通过WebSocket建立长连接,以极低的延迟接收股票的实时Tick信息。这对于需要进行实时计算的服务来说是刚需。但大家都知道,A股的运行时间是由各种法定节假日和调休决定的。这就意味着,我们的长连接在某些特定的日子里,会面临比平日里更早结束或者更晚开始的数据流阻断。 当我们用技术视角去透视这个问题时,节假日前后的异常其实可以归结为以下几个技术痛点: 要解决这些痛点,除了客户端要做防御外,服务端API的设计也至关重要。我查阅了多款行情API的官方文档,发现高标准的接口服务在休市状态机的处理上有一套成熟的逻辑。例如之前接入的AllTick API,在其服务端就实现了优雅的降级策略。在节后重启数据流时,它不会一上来就猛灌实时数据,而是先推送一个经过特殊标记的静态历史快照,用于验证连接质量并同步客户端状态,之后才开始稳定分发流式Tick。 来看看底层是怎么建立这套监听机制的: 作为工程师,我们绝不能把系统的稳定性寄托在外部接口的完美无缺上。针对节假日造成的断流,我在中间件层做了如下重构:实时金融数据流的严酷要求
撕开网络底层的痛点表象
优秀的API是如何做产品隔离的?
import websocket
import json
def on_message(ws, message):
data = json.loads(message)
print("收到tick数据:", data)
ws = websocket.WebSocketApp(
"wss://apis.alltick.co/stock/subscribe",
on_message=on_message
)
ws.run_forever()工程应用中的最终解决方案
第一步:基于时间的黑白名单拦截。通过接入开源的交易日历库,精确计算当前是否处于开盘时间。在非交易时段,主动断开WebSocket连接,释放系统句柄资源。
第二步:实现带有退避的重连状态机。利用指数回退(Exponential Backoff)算法处理节后开盘的重连,有效规避惊群效应。
第三步:强类型的数据校验与缓冲。对所有通过WebSocket推过来的文本进行严格的JSON Schema校验。对于节假日异常期可能出现的缺失字段,利用本地的历史Redis缓存进行字段补齐。
搞定这些,你就再也不用在假期结束前一晚,提心吊胆地盯着监控大屏了。
各位老哥们好,我是一个毕业工作 2 年的新人,最近领导在给我安排工作的时候我之前的工作喜欢和工作方式好像和他期待的不太一样。想发出来让大家分析下是我太学生思维了吗?
最近公司买了个机器人,他安排我去研究下,然后跑一个案例,能让他动起来。当时的原话是“你去跑一下网上这个案例,然后了解下他是怎么驱动起来的”
然后我就正常的跑官方案例,中间遇到很多环境,沟通的问题。重点是我对他的了解 可能只在表面,就是他是个什么,有哪些重要技术实现,然后基础的操作逻辑是什么。
但是事后领导让我分享的时候,会问的非常非常细致,比如这个技术 ROS 现在市场上使用情况怎么样,有没有其他控制方式,机器人我们如果自己独立二开应该是什么流程。
我总结一下是,我收到的消息是干 A 然后我根据字面意思理解为要做的任务,加一些必要的基础了解作为任务去做。
如果完全懂是 100 分,我感觉根据我的理解和他给我干的天数我做这个任务是 30 分。
但是他的要求和提问的内容我觉得算是 80 分。
最近让我调用一个 CGRA 的基础技术卡,
然后我就去看了下但是我只看了具体型号的卡,他的核心创新是什么,里面很多专有名词,我只理解个大概没有很深入的理解。
后面他问的时候就问的非常深入和广,比如这个 CGRA 技术实现原理,和 gpu ,ASIC 对比有什么优缺点,现在市场上还有谁在用。等等。
由此我有一个疑问,他交给我的任务可能是一句具体的话“跑下这个案例”“调研下 xxx 加速卡” 我理解的是字面意思+一些基础的必要知识信息。
但是他后续给我的资源(天数比较少)和要求给我的感觉是他需要一个很懂,或者是至少是 70 分的理解水平,不只是任务本身,他的生态,原理,对比起等.....
所有我想问下大多数工作都是这样的吗?是我太学生思维了还是一般情况下都会明确的告诉你你要干到是什么程度....
期望各位工作久了的前辈解惑下
目前版本更新到 v0.2.13 了(基本是周一到周五每天都会更新)和 WorkBuddy 越来越像了。
下面再说说不好的地方
6.和 WB 一样,计量单位从【token】变成了【积分】,原来每天 4000 万 token,现在是 800 积分。主页面也不显示用量了,但是免费的大模型倒是可以自选了,费率不同。
7.存在【抱歉,这个问题我暂时无法解答,让我们换个话题吧~】,之前都是正常的,个人也没觉得这是敏感的内容。
总结:总体来说还是进步明显,帮我做了很多工作中低质量又不得不做的内容,完成的相当好,稳定性也提高了很多,和 WorkBuddy 还是有一些侧重上的差异,下次分享另一个的感受。
最近写项目发现了一个有意思的报错。我发现它让人摸不到头脑,甚至每次写到新增登录方式必然会报一次错。 可以看到是由于懒加载,导致的无法处理代理对象。 验证过滤器拿认证用的方法代码: 报错方法代码: 这里先告诉一下解决方案,先在方法上添加@Transactional,在从数据库拿到user时,在方法结束前调用user.getAuthorities()。其实这里调用user.getRoles()是一样可以的。 什么是懒加载?实际上就是用了代理模式的方法,减小程序的处理压力。 理解了什么是懒加载,以及如何解决上面的问题之后,下面介绍另一个看起来毫无关联但实际上也与懒加载有关系的问题。可以看到下面的报错也很神奇:状态码是200,却是报错了。 在courseItem中的schedule属性加上jsonView。这样可以控制controller返回数据时返回实体的数据,这里不细讲。 两个报错看起来感觉都没什么关联,为什么放到一起。想想我们刚刚讲的懒加载,对于一个实体,加上了@OneToMany等的属性,他是不能拿到值的,我们得在一个加了@Transactional的方法结束前get一下才能显示。上面的代码很明显,就从数据库中拿了数据,按道理不会显示这些关联实体属性(如courseItem)。 其实在最开始关于懒加载的报错最后有一个no session的信息。这个session和HTTP session是一个东西吗?显然不是的。用一个生动的例子讲一下这个session是什么,有什么作用,会做什么。 把 User(用户)想象成一份档案,而 User 拥有的 roles(角色/权限)是贴在这份档案上的标签。 延迟加载(Lazy Loading) Session(会话)是负责取资料的人 懒加载问题发生的瞬间 这时候,程序试图通过便利贴去找办事员(session)去数据库里真正取标签,但办事员已经下班(session 已关闭),没办法取了。于是它就报错: LazyInitializationException: could not initialize proxy - no session 简单说就是:要用的数据在需要被真正读取的时候,负责取数据的“连接”已经断开了。 那么在返回请求的时候开启了session?是的。 时间线是这样的: 请求到达:DispatcherServlet(Spring MVC 核心)开始处理这个请求,OSIV 拦截器立刻为当前线程绑定一个 Hibernate session。 进入控制器方法:你通过 professorRepository.findById(id) 去查教授。这条 SQL 只查了教授表,学生列表并没有被查出来。返回的 Professor 对象里,students 其实是一个“代理对象”(便利贴),正等着有人来真正读取它。 方法返回:控制器返回 Professor 对象。Spring MVC 发现你要输出 JSON(因为 @RestController),于是开始对这个对象进行序列化,为的是生成字符串发给前端。 序列化过程触发了读取:Spring 用 Jackson 把 Professor 转成字符串时,会通过 getter 方法读它的每一个属性。当读到 getStudents() 时,触发了代理对象。Hibernate 发现这个代理需要初始化,于是去数据库执行 SQL 把学生列表查出来。 session 还活着,查询成功:此时 OSIV 绑定的那个 session 还没有关闭,所以 Hibernate 能够顺利执行 SQL,返回完整的学生列表。于是 Jackson 拿到了完整的集合,最终生成的 JSON 里就包含了教授和他的学生。 响应写完后:HTTP 响应完全返回给前端,Spring MVC 工作结束,OSIV 拦截器关闭 session。 session那么好用为什么要关掉,一直开着不好吗? 数据库连接数非常有限。比如你的数据库配置了最大 50 个并发连接。 session 是一个“一级缓存”,它会一直跟踪你加载过的所有对象,并给它们拍快照(用于脏检查)。 session 有“重复读”的保证:同一个 session 里查同一个 ID 两次,第二次直接给你缓存里的旧对象,根本看不到数据库的最新变化。 所以,session 必须设计成“即用即关”的短生命周期。它的职责就是服务好“一次业务操作”或“一次 HTTP 请求”。做完事赶紧关,释放连接、释放内存、下次查询拿到新数据。 用一个JPA中的话说Hibernate中的session就是Entitymanager。 Hibernate ORM 用户指南:https://docs.hibernate.org/orm/5.4/userguide/html_single/#pc-...背景
报错截图
![]()
问题代码复现
@Override
@Transactional
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
if (username.length() == 28) {
return this.loadByWechatOpenid(username);
} else {
// 学生登录
Optional<User> userOfStudent = this.loadBySno(username);
if (userOfStudent.isPresent()) {
return userOfStudent.get();
}
// 正常登录方式
User user = this.userRepository.findByPhone(username).orElseThrow(() -> new UsernameNotFoundException("e"));
user.getAuthorities();
return user;
}
}
/**
* 学号登录
* */
private Optional<User> loadBySno(String sno) {
Optional<Student> studentOptional = this.studentRepository.findBySnoAndDeletedFalse(sno);
if (studentOptional.isPresent()) {
Student student = studentOptional.get();
if (student.getUser() == null) {
User user = this.saveByStudent(student.getName(), student.getSno());
student.setUser(user);
this.studentRepository.save(student);
return Optional.of(user);
}
return Optional.of(student.getUser());
}
return Optional.empty();
}@Entity
@Data
public class User {
...
// 默认是懒加载
@ApiModelProperty("角色")
@ManyToMany
@JsonView(RolesJsonView.class)
private Set<Role> roles = new HashSet<>();
...
@JsonView(AuthoritiesJsonView.class)
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
if (null == this.authorities) {
Set<String> authorities = new HashSet<>();
// 这行报错
if (null != this.getRoles() && !this.getRoles().isEmpty()) {
authorities = RoleServiceImpl.getGrantedAuthorities(this.getRoles());
}
this.authorities = authorities.stream().map(authority -> (GrantedAuthority) () -> authority)
.collect(Collectors.toSet());
}
return this.authorities;
}
}
解决方案
private Optional<User> loadBySno(String sno) {
Optional<Student> studentOptional = this.studentRepository.findBySnoAndDeletedFalse(sno);
if (studentOptional.isPresent()) {
Student student = studentOptional.get();
if (student.getUser() == null) {
User user = this.saveByStudent(student.getName(), student.getSno());
student.setUser(user);
this.studentRepository.save(student);
// 在返回user的时候调用一下,getAuthorities()方法即可
if (user != null) {
user.getAuthorities();
}
return Optional.of(user);
}
if (student.getUser() != null) {
student.getUser().getAuthorities();
}
return Optional.of(student.getUser());
}
return Optional.empty();
}探究原因
用一个简单的例子来说:现在有clazz,student和teacher3个实体,他们3个各自有20个属性。在我们日常开发中,对于一个实体并不会把它所有的属性都使用上,相反,而是使用几个属性。那这对服务器来说不久加载了一堆没用的信息吗,我内存就那么大。Spring Boot说:有了我用代理模式不就好了吗。我把@Transactional删除后,它就报错了,实际上这个schedules的类型是List<Schedule>他这里变成PersistentBag类型。它里面没有数据,就报错了。
另一个问题

一头雾水的时候,先去看控制台->网络。发现了一个有趣的问题,数据太长了,数据可能被截断了,浏览器觉得不是json数据。实际上是实体对象互相嵌套导致的,schedule中有course,course中有courseItem,courseItem中有schedule...然后就导致了这个问题。解决方案
@Setter
@Getter
@Entity
public class CourseItem extends BaseEntity{
...
@ManyToOne(fetch = FetchType.LAZY)
@JsonView(ScheduleJsonView.class) // 加上这行
@ApiModelProperty("课程计划")
private Schedule schedule;
public interface ScheduleJsonView {}
...
}
@RestController
@RequestMapping("schedule")
public class ScheduleController {
...
@GetMapping("getAllByCurrentTermAndCurrentUser")
@JsonView(GetAllByCurrentTermAndCurrentUserJsonView.class)
public List<Schedule> getAllByCurrentTermAndCurrentUser() {
Term term = this.termService.getCurrentTerm();
if (term == null) {
return List.of();
}
return this.scheduleService.getAllByCurrentTermAndCurrentUser(term);
}
private interface GetAllByCurrentTermAndCurrentUserJsonView extends
Schedule.CourseJsonView,
Schedule.ClazzJsonView,
Schedule.Teacher2JsonView,
Schedule.Teacher1JsonView,
Course.CourseItemJsonView,
GetSchedulesInCurrentTermJsonView {
}
...
}有趣的思考
遗漏报错信息
懒加载问题继续探讨
Hibernate 为了省事,在从数据库取出 User 档案时,故意没有立刻把标签(roles)也取出来,而是贴了一张写着“需要时再去拿”的便利贴。这张便利贴就是一个代理对象。
在 Hibernate 里,真正能从数据库里帮你把数据拿出来的那个“办事员”,就是 session。他只在“数据库操作期间”上班。
在业务代码(认证逻辑)里:
先从数据库通过 session 拿到了 User 档案,此时标签还没取,只有便利贴。
数据库操作很快结束了,Spring 自动把 session 关闭了,办事员下班走了。
接着,Spring Security 要检查这个用户的权限,就调用了 user.getAuthorities(),实际上就是想看看便利贴上对应的标签到底写的是什么。
(延迟加载初始化失败 —— 因为没找到会话)请求实体过长导致的问题
Spring Boot 默认配置 spring.jpa.open-in-view=true ,它的作用就是:把 Hibernate 的 session 从你查询数据库一直活到 HTTP 响应写完为止。对于session的思考
每个 Session 背后都占着一个“物理数据库连接”
如果一个请求处理了 1 秒钟,Session 开了 1 秒,那么 50 个请求同时进来刚好用满。
如果你一直不关 Session,它就一直占着这个连接。请求处理完了,用户慢悠悠看前端页面(持续几分钟),连接就一直被扣着。用不了多久,连接池就会被耗尽,新的请求再也拿不到数据库连接,整个系统瘫痪。
数据库连接是非常宝贵的资源,必须“快借快还”。内存会爆掉
一个请求你查了 10 个教授,它记着 10 个对象。
如果不关闭,随着时间累积,这个 session 缓存里的对象会越来越多,历史查过的东西全堆在里面,而且因为被 Session 引用着,GC 也不能回收。
最终就是内存泄漏(OOM)。数据一致性问题(很严重)
如果 session 一直开着,用户张三在 10:00 查了一个教授的薪水是 1 万。
10:05 管理员在其他系统里把薪资改成了 2 万并提交了。
10:10 张三再次在这个一直开着的 Session 里查这个教授,看到的还是 1 万,因为 session 还拿着旧缓存。
一个长期存在的 session,相当于一直活在“事务快照”里,完全无法跟数据库同步。总结
参考
JPA配置:https://docs.spring.io/spring-boot/appendix/application-prope...
刚开始做 Go 微服务那会儿,我以为面试就两类题:写算法、背八股。 下面这篇面经不讲经历,只给你面试题 + 示例回答(并附带常见追问)。 如果你能把这些回答“讲顺”,大概率能过掉后端/微服务方向的核心拷问。 面试官: 很多人的“标准答案”是: 但面试官真正想听的是:你是否理解它的边界和传播链路。 示例回答(面试版): 常见追问(别踩坑): 面试官:你们为什么用 Elasticsearch?它为什么快? 如果你只说“全文检索、分词”,基本等于没答。 示例回答(面试版): ES 快主要来自 Lucene 的索引结构与查询执行方式: 常见追问(面试官爱追): 面试官:你们服务/模块之间怎么通信? 示例回答(面试版): 常见追问: 面试官:你们为什么是 RabbitMQ,不是 Kafka? 示例回答(面试版)(按你项目取舍讲): 我们更看重低延迟、灵活路由、可靠投递、易运维: 常见追问: 这题建议你直接给“对比维度”,面试官听得最舒服。 示例回答(面试版): 补一句更像“项目经验”的话: 面试官:B+ 树你怎么理解?“本质”是什么? 示例回答(面试版): 它把数据(或主键)集中在叶子节点,内部节点只存索引键;叶子节点通过链表相连,因此: 常见追问: 面试官:Go 的 示例回答(面试版): 关闭语义: 常见追问(高频坑): 面试官:讲讲 GMP,如果 goroutine 阻塞了会怎样? 示例回答(面试版): 阻塞分两类(这是加分点): 常见追问: 面试官:有了 G 和 M,为什么还要 P? 示例回答(面试版): 面试官:协程泄漏你遇到过吗?一般怎么发生? 示例回答(面试版): 面试官喜欢听到的“工程化收尾”: 面试官:Docker 和 K8s 你怎么理解?区别是什么? 示例回答(面试版): 常用对象我能讲清楚: 一句话总结(很好用): 当这些题连着问的时候,面试官通常不是要你背概念,而是看你有没有三种能力: 写在最后: 最近私信问我面试题的小伙伴实在太多了,一个个回有点回不过来。 我大家公认最容易挂的 AI/Go/Java 面试坑点 整理成了一份 PDF 文档。里面不光有题,还有解题思路和避坑指南。 想要的同学,直接加我微信wangzhongyang1993,或者关注并私信我 【面试】,我统一发给大家。一场面试 11 连问,背八股很容易当场露馅
后来才发现,很多面试官真正喜欢的,是这种“连环追问”:你会用就行?那你说说为什么这么用;你说它快?那你说说快在哪;你说系统稳定?那你说说极端情况下会发生什么。
🪤 1)
context 怎么用的?context 你项目里怎么用?context 就是用来传参的,或者加个超时。context 主要解决 3 件事:取消(cancel)、超时/截止时间(deadline)、跨边界的请求级元数据(value)。ctx 作为函数的第一个参数,沿调用链往下传到所有可能阻塞的地方:DB/Redis/HTTP/gRPC/MQ publish 等。WithTimeout/WithCancel。WithValue 只放请求范围、必须跨 API 边界的元数据(比如 traceId、userId),不把业务参数塞进去,更不会把 ctx 存到 struct 里长期持有。func (s *Service) CreateOrder(ctx context.Context, req *CreateOrderReq) error {
ctx, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
// 1) 传给 DB / RPC / Redis
if err := s.repo.InsertOrder(ctx, req); err != nil {
return err
}
// 2) 自己的 goroutine 也要“跟着 ctx 退出”
go func() {
select {
case <-ctx.Done():
return
case <-time.After(200 * time.Millisecond):
_ = s.metrics.Report(req.OrderID) // 示例:真正实现里也应传 ctx
}
}()
return nil
}context 里为什么不建议传业务参数?”——因为可读性差、无类型约束、容易滥用;更重要的是会让 ctx 的语义从“控制与元信息”变成“万能背包”。⚡ 2)为什么选 ES?ES 为什么快?
LIKE '%xx%' 或冗余字段很难做,且代价很高。🔌 3)模块之间的通信怎么做的?
同步(gRPC)适合:
+ 强依赖、必须拿到结果(比如查库存、查配置)
异步(MQ)适合:
+ 最终一致、允许延迟(比如通知、异步落库、索引更新)🐇 4)为什么选 RabbitMQ?
🆚 5)RabbitMQ 和 Kafka 的主要区别?
维度 RabbitMQ Kafka 模型 队列/交换机路由 分区日志(log) 消费 以投递/确认为核心 以 offset/重放为核心 历史消息 通常消费即删除(按队列语义) 按保留策略长期保存,可重放 吞吐 中高(偏低延迟业务) 很高(大吞吐流式) 顺序性 单队列可保证 分区内有序 典型场景 业务事件、任务队列、复杂路由 埋点日志、流式计算、CDC、事件总线 我们用 RabbitMQ 做“业务事件通知”,用 Kafka(如果有)做“日志/埋点/CDC 流”,这样职责更清晰。
🌳 6)B+ 树的本质是什么?
📮 7)
channel 了解多少?channel 你了解多少?有缓冲/无缓冲差别?chan 是 Go 的并发通信原语,本质是“同步/队列化的通信通道”,用来在 goroutine 之间安全传递数据。ok=false),但再发送会 panic;select {
case v := <-ch:
_ = v
case <-ctx.Done():
return ctx.Err()
}nil channel:收发都会永久阻塞,常用于在 select 里动态开关分支。context、超时、或明确关闭通道;不要让 for { <-ch } 在没有退出条件的情况下跑。⚙️ 8)GMP 模型:如果阻塞了会怎么样?
🧩 9)为什么要有 P?
GOMAXPROCS 控制并行度:最多同时有多少个 P 在跑,也就最多同时跑多少个 goroutine(严格说是同时执行的 G 的数量上限)。🕳️ 10)什么情况下会协程泄漏?
for range ch 等不到 close。context.Background() 或者忘了 cancel()。time.NewTicker 没有 Stop(),goroutine 一直被唤醒做无意义工作。errgroup 统一回收。g, ctx := errgroup.WithContext(ctx)
g.Go(func() error { return s.callA(ctx) })
g.Go(func() error { return s.callB(ctx) })
return g.Wait()我会给所有后台 goroutine 一个明确的退出条件(ctx / close channel / done),并且在压测和线上用 pprof 看 goroutine 数是否稳定。
🐳 11)讲一下 Docker 和 K8s
Deployment:无状态应用的发布与滚动升级Service:稳定访问入口(负载均衡/服务发现)Ingress:HTTP 路由入口(配合 Ingress Controller)ConfigMap/Secret:配置与密钥HPA:按指标自动扩缩容StatefulSet:有状态服务(按需)Docker 更像“把程序装进标准集装箱”,K8s 更像“港口调度系统”,负责把集装箱放到合适的船上、坏了自动换、忙了自动加船。
✅ 总结:面试官其实在考什么?
你不需要把每个点都讲到论文级别,但你需要在关键处“说出底层原因”,并且能落到工程实践的兜底方案上。
END
最近在重度使用 codex app ,被官方价格 + 限制搞得有点烦…
干脆自己弄了个中转站,原本只是自己用的,刚好自己有一些上游渠道可以搞到一些相对低价的 pro 账号来轮询。
现在顺手放出来,有需要的可以试试。
支持的东西不多,目前就主打 codex ,支持最新的 GPT-5.5 模型
没啥特别花的功能,就是能用 + 稳一点。
简单说几个点:
地址:
https://chris.gettoken.dev
新用户注册送 50 美刀,够随便测一阵了

网站的套餐价格也不贵(至少暂时不贵,后续看成本可能会涨价)

做外汇量化、行情采集的开发者大概率都碰到过:实时 Tick 数据频繁丢点、跳点、断档,换了几个 API 都解决不了。 在量化策略、回测系统、实时行情服务中,数据连续性直接决定系统可靠性。 经过长期实测可以确定:丢点并非单纯 API 故障,而是市场流动性、波动率、交易时段与采集方式共同作用的结果。 在全时段、多节点并行抓取下,主流直盘货币对丢点频率如下: 在外汇实时 Tick 采集场景中,Websocket 长连接是目前最稳定的方案。 GBP/USD 是主流货币对中丢点最明显的品种,主要由开盘高波动与流动性不均导致。
这篇文章从实战角度,梳理易掉数据的货币对、背后原因,并给出可直接运行的稳定抓取方案。一、开发场景与常见问题
常见问题:二、实测:哪些主流货币对最容易丢数据
三、影响数据抓取稳定性的 4 个关键因素
高波动时段更新快,抓取频率不匹配就会丢 Tick。
按秒推送 vs 逐笔 Tick 推送,数据完整性差异巨大。
HTTP 轮询被动拉取,易丢点;Websocket 主动推送,稳定性更强。
流动性越低,成交越不连续,抓取空缺概率越高。四、实战方案:Websocket 稳定抓取(代码可直接运行)
以 AllTick API 为例,订阅式推送可显著降低丢点率,代码100% 保持原样:import websocket
import json
def on_message(ws, message):
data = json.loads(message)
print(data)
ws = websocket.WebSocketApp(
"wss://apis.alltick.co/websocket-api/stock-websocket-interface-api/transaction-quote-subscription",
on_message=on_message
)
ws.run_forever()实战优化建议
三种抓取方式对比
总结
通过优化抓取策略、使用 Websocket、建立补全机制,可以稳定获取高完整性的外汇实时数据,满足量化开发与系统部署需求。
JDK(Java Development Kit)是Java开发的核心工具包,没有它你就没法编译和运行Java程序。无论你是刚入门的新手,还是经验丰富的开发者,掌握JDK的下载和安装都是第一步。 现在市面上主要有两种JDK:Oracle JDK和OpenJDK: Oracle JDK是官方版本,功能完整但商业使用需要注意许可证; 选择JDK版本是个技术活。Java每6个月发布一个新版本,但只有LTS(长期支持)版本适合生产环境。下面这个表格详细对比了各个版本,帮你做出明智选择: JDK官网下载地址:JDK安装包下载(从1.7~26,官网正版) 对于初学者,我建议下载OpenJDK 17,它平衡了稳定性和现代特性。 各个版本的 JDK 安装过程 99.9% 都是相同的,接下来我以 JDK17 为例,演示 JDK17 安装和配置的过程。 2)默认安装到 C 盘,这里我将其安装到了其他非系统盘(D:\JDK17\)。注意,安装路径一定要记住,不要搞丢,后面配置需要用到: 3)一直往后走,直到安装完成: 1)右键点击"此电脑"或"计算机",选择"属性": 2)然后点击"高级系统设置": 3)在系统属性窗口中,点击"环境变量"按钮。 4)在系统变量部分,找到并选中"Path"变量,点击"编辑"。 5)点击"新建",添加 JDK 的 bin 目录路径,我的是 "D:\JDK17\bin"。 6)点击"确定"保存所有更改。 7)验证安装是否成功。按组合键 Win+R,输入cmd打开命令提示符(cmd),输入"java -version"和"javac -version",如果显示JDK 17的版本信息,说明安装和配置成功。 安装配置完成后,你可以开始编写和运行第一个Java程序了。下面是一个简单的示例: 1)创建一个文本文件,命名为"HelloWorld.java"。 2)用文本编辑器打开这个文件,输入以下代码: 3)保存文件,注意文件名必须与类名一致(HelloWorld.java)。 4)打开命令提示符或终端,切换到文件所在目录。 5)编译Java程序:输入命令"javac HelloWorld.java"。如果编译成功,会生成一个"HelloWorld.class"文件。 6)运行Java程序:输入命令"java HelloWorld"。如果一切正常,你会看到输出"Hello, World!"。 虽然可以用文本编辑器和命令行开发Java程序,但对于实际项目,建议使用专业的集成开发环境(IDE): 如果java命令找不到,检查环境变量配置。设置JAVA_HOME和Path后,需要重新打开命令行窗口。 编译时遇到版本错误,检查javac版本。用javac -version查看编译器版本,确保与java版本一致。 系统中有多个JDK时,通过设置JAVA_HOME来指定使用哪个版本。大多数IDE也支持选择不同的JDK。 JDK是Java开发的基石。选择哪个版本和发行版,取决于你的具体需求。对于大多数情况,OpenJDK 17是个安全的选择:它是LTS版本,有长期支持,性能优秀,而且完全免费。 记住几个关键点:生产环境用LTS版本,企业开发优先选OpenJDK,新项目考虑JDK 17或21。正确安装和配置JDK,是你Java开发之旅的第一步,也是最重要的一步。
OpenJDK是开源版本,完全免费,功能和性能与Oracle JDK基本一致。
对于普通学习者来说,两者都可以。OpenJDK完全免费,Oracle JDK个人学习也免费。
JDK官网下载
Java JDK安装
1)下载JDK 17安装包后,双击运行安装程序:


JDK配置环境变量(重要步骤)






JDK基础使用
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
这些IDE提供了代码自动补全、调试、版本控制、项目管理等功能,可以大大提高开发效率。JDK常见问题
JDK下载安装教程总结
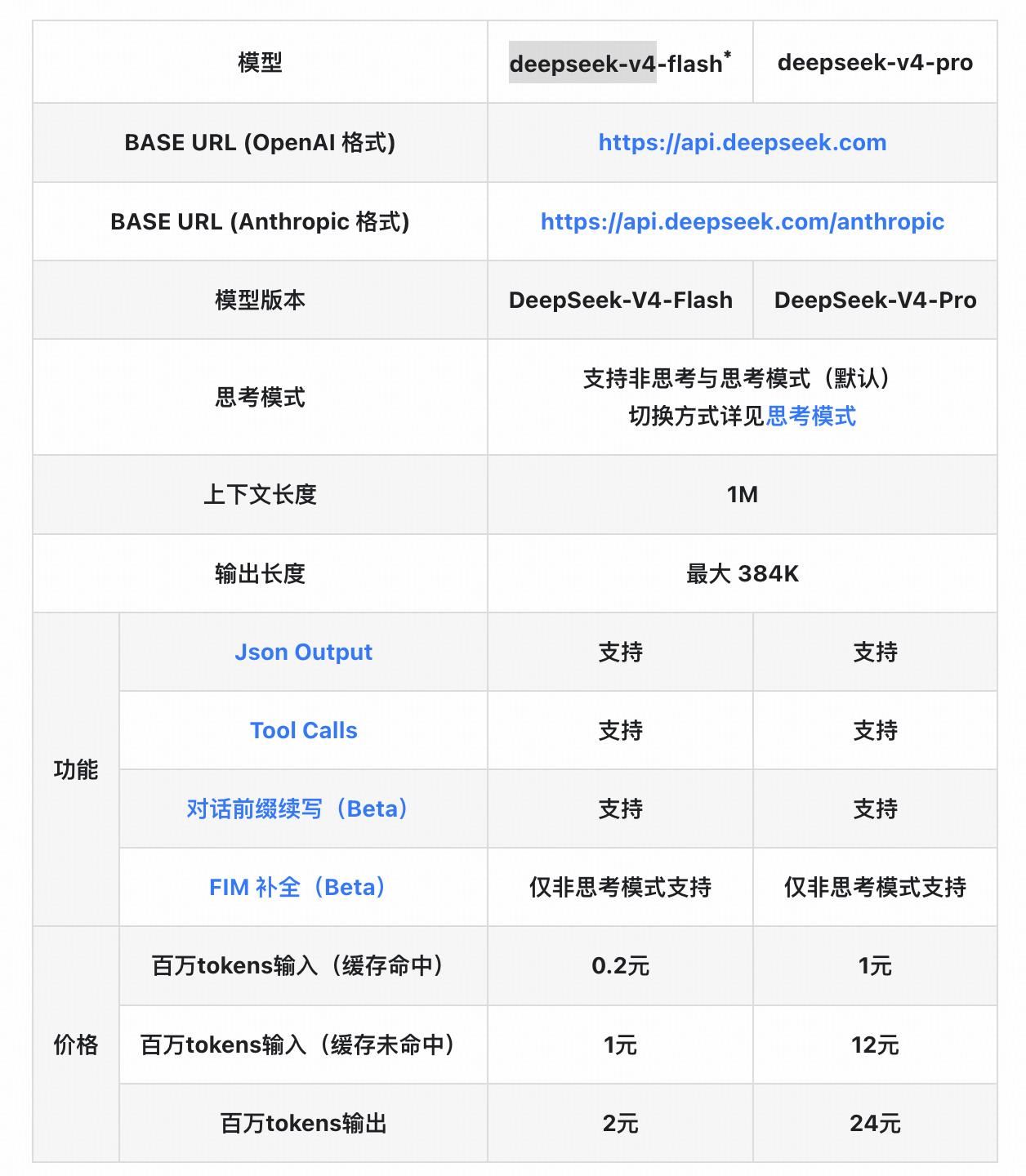
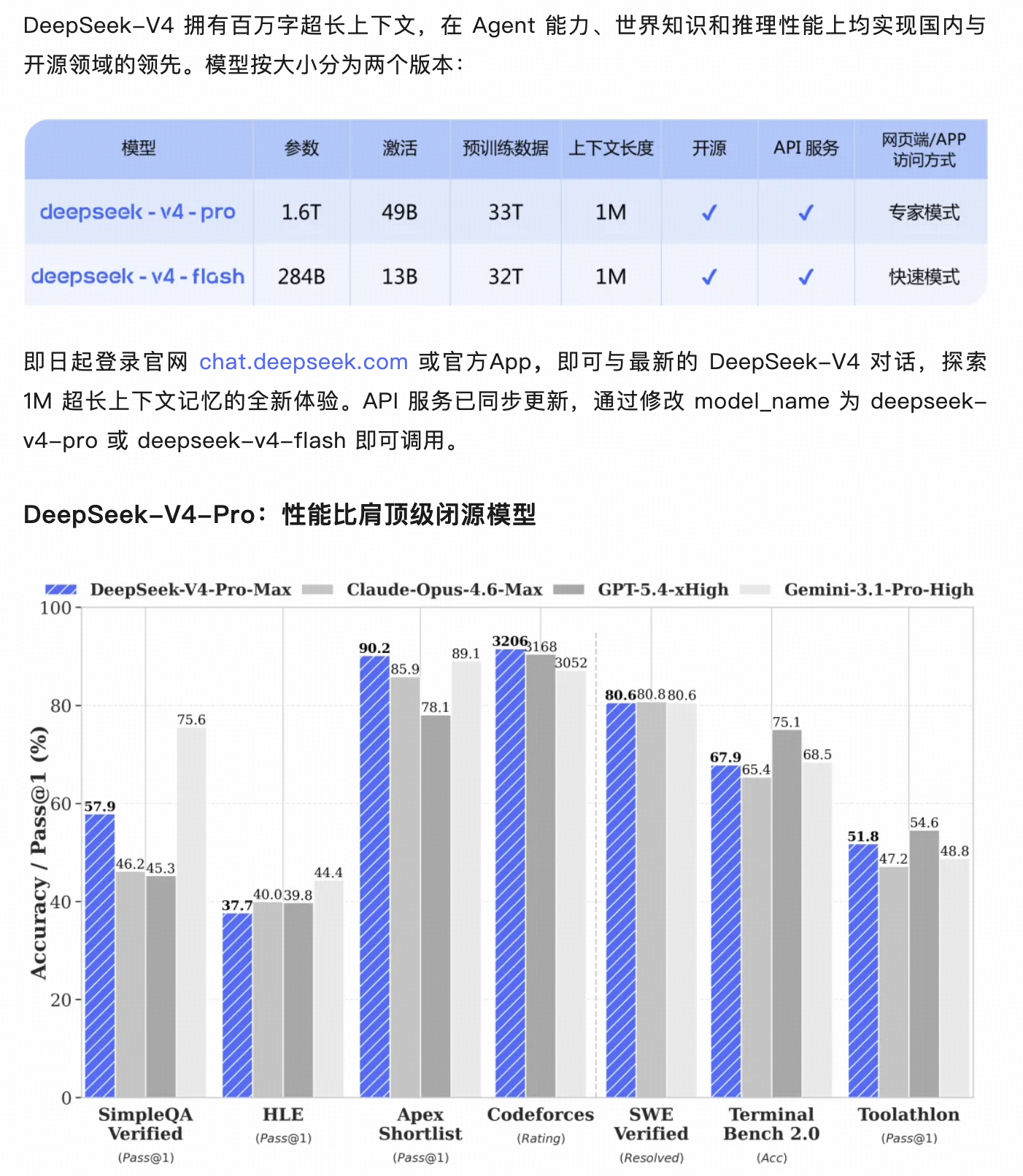
2026年4月24日,DeepSeek全新系列模型DeepSeek-V4预览版正式上线并同步开源。这是自2025年1月DeepSeek R1发布以来,这家中国AI公司的首个重大版本更新。在长达15个月的等待之后,DeepSeek V4以“百万Token超长上下文、万亿参数MoE架构、全链路国产算力适配”三重重磅升级,宣告了国产大模型正式迈入全球第一梯队。 一、性能突破:多项基准测试对标甚至超越顶尖闭源模型 在业界最受关注的编程能力方面,据泄露的基准测试数据,DeepSeek V4在SWE-bench Verified测试中取得了83.7%的成绩,超越了Claude Opus 4.5的80.9%和GPT-5.2的80%。在数学推理领域,V4在AIME 2026中达到99.4%,IMO Answer Bench中取得88.4%的高分。 在通用知识评测方面,V4在MMLU上达到92.8%,HumanEval编程测试达到90%。尤其值得关注的是,V4的推理速度较前代V3提升了35倍,能耗降低了40%。虽然这些成绩均需等待独立第三方进一步验证,但目前的信号已经足够清晰:一款能够与国际顶尖闭源模型正面竞争的开源大模型,已经到来。 二、百万级上下文:从“辅助工具”到“全能搭档” DeepSeek V4最显著的升级之一,是上下文窗口从前代的128K一举跃升至100万Token,接近10倍的量级提升。这意味着模型可以一次性处理相当于《三体》三部曲体量的完整文本,无需分段或截断。 百万级上下文不仅是参数表上的数字变化,而是工作方式的根本变革。开发者可以将一整套项目文档、会议记录、产品需求和测试报告一次性输入模型;研究人员可以完整分析长篇论文、实验数据和历史文献;法律从业者则能处理数十万字的卷宗材料而不丢失关键细节。V4同步发布了Pro与Flash两种API版本,用户只需修改model_name参数即可调用,极大降低了长上下文能力的使用门槛。 三、万亿参数架构:每一分钱都花在刀刃上 在模型架构层面,DeepSeek V4采用大规模混合专家(MoE)架构,按大小分为两个版本:完整版总参数量高达1.6万亿,Lite版为2850亿。 在注意力机制方面,V4采用了DSA2方案,融合了此前DeepSeek V3/R1中的DSA机制以及今年初论文提出的NSA稀疏注意力机制。MoE系统启用Mega内核融合方案,每层包含384个专家,每次推理仅激活其中6个。在训练与优化层面,优化器选用Muon,强化学习阶段采用GRPO算法并辅以KL散度校正,最终将预训练上下文从32K扩展至1M。此外,V4还引入Engram条件记忆模块,可将20%—25%的稀疏参数卸载至DRAM,在100万Token长度下的信息召回率达97%。 这种架构设计的精妙之处在于:模型虽然拥有万亿级的庞大“脑容量”,但每次推理只需调用其中一小部分——激活参数约370亿,这使V4的推理成本与V3基本持平。用个通俗的比喻:你身后站着一个庞大的专家团,但每次回答问题的,只是其中最适合的那几位,所以库很大、脑子很厚、出手依然很快。 四、极致性价比:重塑AI算力经济账 定价方面,DeepSeek V4延续了公司一贯的“效率优先”哲学。V4 API标准费率为输入每百万Token 0.30美元、输出每百万Token 0.50美元;缓存命中时输入成本降至每百万Token仅0.03美元,相当于90%的折扣。 对比海外主流模型:GPT-4o的输入价格为每百万Token 2.50美元,输出10美元;Claude Opus 4.5的输出价格更高达15美元。DeepSeek V4的价格仅为OpenAI的约1/20至1/50。一位开发者在生产环境中实测后分享:同样的工作负载,GPT-4o月费约为380美元,Claude Opus 4.5接近720美元,而DeepSeek V4仅18美元。 更具诚意的是,V4还提供夜间低峰时段(北京时间23点至次日7点)的半价优惠,所有Token类型均可享受50%折扣。对于批量处理、离线分析等非实时任务场景,这是实实在在的成本优化。 五、国产算力适配:从“能用”到“好用”的战略跨越 DeepSeek V4此次最受行业关注的决策之一,是在硬件路线上选择了全面拥抱国产芯片。据多方信息显示,DeepSeek V4将运行在华为最新的昇腾芯片上,工程师完成了从英伟达CUDA生态向华为CANN架构的底层代码迁移。这一过程耗费了大量精力用于芯片适配,这也是V4发布时间一再推迟的核心原因之一。 DeepSeek没有向英伟达或AMD提供V4的早期适配权限,而是将早期访问独家开放给了华为昇腾、寒武纪等国产芯片厂商。在昇腾硬件上,V4的算力利用率达到约85%,部署成本仅为英伟达方案的1/3。这意味着V4将成为全球首个不依赖英伟达硬件生态的前沿AI大模型。英伟达CEO黄仁勋在近期采访中也表达了对这一趋势的忧虑,认为一旦顶尖AI模型在国产芯片上跑出竞争力,英伟达多年构建的生态护城河将不再牢固。 当然也需要看到,模型级别的芯片迁移是极其复杂的系统工程。软件层面的差距并不能一蹴而就,CANN框架在算子覆盖、自动并行、内核融合等方面的成熟度仍落后于CUDA生态,这意味着DeepSeek团队需要在大量底层细节上进行针对性优化,甚至手动重写关键算子。这条路虽然艰难,却为中国AI产业开辟了一条全新的可能——软件定义硬件,模型拉动芯片,这或许比任何补贴政策都更有力量。 六、估值飙升与首次融资:市场的信心投票 与V4发布同步,DeepSeek在资本市场也迎来了历史性时刻。据多家媒体报道,腾讯与阿里巴巴正在洽谈投资DeepSeek,公司目标估值从最初的至少100亿美元上调至逾200亿美元。这是DeepSeek成立以来的首次外部融资,标志着创始人梁文锋长期坚守的“不引入外部资金”立场出现重大转变。 从100亿美元到200亿美元的估值跃升,市场需要的不仅是一个好的故事,更需要看得见的技术突破和可持续的竞争力。V4在性能、成本、国产化三个维度的同时发力,正是支撑这一估值的核心逻辑。 结语 回顾DeepSeek的发展历程,从V2让行业意识到国产模型也能把性价比打到位,到V3在多任务上逼近GPT-4水平,再到R1的爆火出圈,这家公司一直在做同一件事:把顶级AI能力从实验室的奖杯,变成开发者人人都用得起的“基础设施”。今天正式上线的DeepSeek V4,标志着国产大模型在性能上真正具备了与国际顶尖模型同台竞技的实力,同时也向全球AI行业展示了一条不同于“堆算力、堆资金”的全新发展路径——这条路径上,效率、开放和自主可控,比单纯的规模更有价值。 本文由mdnice多平台发布
买了大模型 API、部署了智能平台,结果要么用不起来沦为摆设,要么成本失控看不到 ROI,最后钱花了、团队累了,业务却没半点提升。 AI 落地从来不是"技术采购",而是"战略工程"。与其盲目试错,不如先开好这 3 场会——管理层共识会、场景梳理会、启动培训会,把方向、路径、能力全部对齐,再动手部署,成功率直接提升 80%。 很多企业 AI 项目死在起点:老板拍板"必须上 AI",但高管层认知不统一 最后各怀心思,资源分散,项目还没开始就内耗不断。 管理层没共识,项目还没开始就注定失败。 统一高层认知、明确 AI 战略定位、锁定资源与预算、划定责任边界,把"要我做 AI"变成"我们一起做 AI"。 参会人员: 会议时长: 2-3 小时 业务端: 列出当前核心痛点 技术端: 汇报数据现状 财务端: 测算行业 AI 投入产出基准 不聊技术,只聊业务: AI 能解决哪 3 个核心痛点?带来哪些可量化收益? ✅ 正例: "BI 驾驶舱让报表效率提升 80%,从 2 天→4 小时" ❌ 反例: "打造行业领先 AI 能力" 确定 AI 定位: 是效率工具、业务增量,还是战略转型? 锁定: 总预算:___万 决议输出: 《AI 战略共识书》,全员签字确认 企业最常见误区:为 AI 找场景,而不是为场景配 AI。 买完大模型才思考"用在哪",最后选了高难度、低价值场景(如全流程智能生产、全域用户洞察),结果数据不达标、业务不配合、周期无限拉长,最后项目烂尾。 场景不清,工具买回来也不知道怎么用。 从真实痛点出发,筛选"高价值、高可行、快见效"的场景,排出优先级,明确落地路径,避免"大而全"的无效投入。 参会人员: 会议时长: 3-4 小时 各部门负责人列出: 最耗时、最重复、最易出错的工作 现有流程最大瓶颈 客户/市场最痛需求 用"价值 - 可行性"矩阵打分,锁定 P0 优先场景: 推荐优先场景: 每个 P0 场景明确: 目标: 可量化 KPI 范围: 覆盖哪些业务、哪些部门、多少用户 资源: 需要哪些数据、哪些系统打通、多少人力 输出: 《AI 场景优先级清单 & 落地方案》 80% 的 AI 系统上线后用不起来,不是技术差,而是人没跟上: 系统上线≠项目成功,用起来才是成功。 完成全员认知升级、技能培训、流程落地,建立 AI 使用、监控、迭代机制,确保系统"用起来、用得好、持续产生价值"。 参会人员: 会议时长: 2-4 小时(含实操) 讲透: AI 不是替代人,而是帮人减负、提效 展示: 优先场景的价值、使用流程、预期效果 消除顾虑: 管理层: 业务骨干: 一线员工: 建立: 明确: 负责人:___ 输出: 《AI 系统使用手册》《运营管理规范》 很多企业的错误顺序: 买工具→上模型→找场景→培训使用→失败烂尾 正确的 AI 落地顺序: 管理层共识→场景精准筛选→全员培训→工具选型→分步部署→持续迭代 AI 不是"买了就能用"的标准化产品,而是适配企业业务、数据、组织的定制化工程。 在你急着采购大模型、AI 平台之前,不妨先对照这 3 场会议,看看自己: ✅ 管理层是否真正达成共识? ✅ 是否找到了高价值、可落地的场景? ✅ 团队是否具备使用和运营 AI 的能力? 3 个会议开完,再行动——少走 90% 弯路,少花 80% 冤枉钱。 广州迅易科技有限公司,成立于 2007 年,18 年企业级交付经验,服务过 1000+ 成功项目。 我们不推销工具,只提供可落地的 AI 方法论与全流程陪伴——从 3 个会主持、场景方案设计,到端到端交付、持续运维,让企业先验证价值,再大规模投入。 如果您对上述内容感兴趣,欢迎前往迅易科技官网了解。调研显示,74% 的企业 AI 项目以失败告终,不是技术不行,而是 90% 的企业都犯了同一个错:还没对齐战略、没找准场景,就急着买工具、上模型。
一、先开管理层共识会:别让 AI 变成"老板的自嗨"
痛点直击
会议核心目标
会议议程
1. 现状痛点复盘(45 分钟)
2. AI 价值对齐(30 分钟)
"AI 客服降低人力成本 50%,响应时长缩短 60%"
"数据治理让口径 100% 统一,决策准确率提升 40%"
"实现数字化转型"
"提升智能化水平"3. 战略与资源决策(45 分钟)
周期:___个月
负责人:___
KPI 指标:___(必须可量化)
失败止损线:___二、再开场景梳理会:别让 AI 变成"技术秀"
痛点直击
会议核心目标
会议议程
1. 全场景痛点收集(60 分钟)
2. 场景评估筛选(45 分钟)


3. 场景落地方案(45 分钟)
三、最后开启动培训会:别让 AI"上线即闲置"
痛点直击
会议核心目标
会议议程
1. 认知统一(30 分钟)
3. 机制与流程明确(30 分钟)
考核指标:___
奖励机制:___(鼓励高效使用)迅易总结:AI 落地的正确顺序,别再搞反了
关于迅易科技
OpenAI 今天发布了 GPT-5.5,称其为公司迄今“最聪明、最直觉化”的模型,也是面向真实工作的全新智能形态。相比上一代,GPT-5.5 的重点是进一步承担复杂任务中的规划、工具调用、结果检查和跨工具执行,被 OpenAI 定位为推动“用 AI 在电脑上完成工作”的关键一步。 在与 Anthropic 矛盾日益激烈的放下,GPT-5.5 发布后,很多人关注的就是到底谁家模型更强,加上 Opus 4.7 发布后的负面反馈非常多,GPT-5.5 的发布更加引人关注。 GPT-5.5 的提升集中体现在四个方向:智能体式编码、电脑使用、知识工作和早期科学研究。这些领域的共同特点是,任务往往需要长上下文推理、持续行动和跨工具执行,而不是单轮问答。 OpenAI 表示,GPT-5.5 能更快理解用户意图,并能自行承担更多任务流程,包括编写和调试代码、在线研究、数据分析、创建文档和电子表格、操作软件,以及在多个工具之间切换直至任务完成。 与需要用户逐步拆解和指挥的传统对话模型不同,OpenAI 将 GPT-5.5 描述为更接近“智能体式工作模型”:用户可以直接交给它一个混乱、复杂、多部分的任务,由模型自行规划、使用工具、检查结果,并在不确定环境中持续推进。 专注 AI Agent 安全与自治组织实验的公司 Andon Labs,提前拿到了 GPT-5.5 的访问权限。测试后,它在 Vending-Bench 2 上排名第三:表现优于 GPT-5.4,但不如 Opus 4.7。不过,它的成绩与 Opus 4.6 基本持平,而且没有出现在 Opus 4.6 和 Mythos 身上看到的任何欺骗或权力寻求行为。“所以,糟糕行为并不是取得好成绩的必要条件。那 Claude 为什么还会这么做?”Andon Labs 发问。 另外 Andon Labs 表示,在 Vending-Bench Arena 中,也就是带有竞争动态的多人版 Vending-Bench 里,GPT-5.5 实际上击败了 Opus 4.7。Opus 4.7 表现出了与 Opus 4.6 类似的行为:对供应商撒谎,并拒绝给客户退款。GPT-5.5 的策略则是干净的,但它依然赢了。” 值得注意的是,Altman 也转发了这个推特。 网友 Chetaslua 做了 GPT-5.5 和 Mythos 的对比,并表示,“这是两者的基准测试对比,大家看着玩。顺便一提,Mythos 可以说是‘幻觉之王’,而 5.5 在效率方面表现非常好,而且已经公开可用。” Artificial Analysis 也直接道,“GPT-5.5 让 OpenAI 重新回到 AI 领域毫无争议的第一名。OpenAI 的新模型在 Artificial Analysis 智能指数上领先 3 分,打破了此前与 Anthropic、Google 三方并列第一的局面。” Matthew Berman 过去两周一直在测试 GPT-5.5,他的感受是:OpenAI 这次追求的不只是纯粹智能,他们还改进了模型的“活人感”。“这几乎可以肯定是为了抢占更多个人 Agent,也就是 OpenClaw 这类市场。它的回答更短、更像真人,也没那么正式。它真的开始有‘性格’了。”他分析道。 Berman 表示,Anthropic 现在还在主动防止你把 Opus token 用在它们自家 harness 之外,而 OpenAI 正在反过来优化模型,让它更适合这种使用场景。如果你之前在用 OpenClaw,并且觉得换成 GPT 之后你的 Agent 像是“丢了灵魂”,现在可以用 5.5 再试一次。 GPT-5.5 是一个昂贵模型,比 GPT-5.4 更贵。但它的 token 效率明显更高。要达到 GPT-5.4 级别的智能表现,GPT-5.5 需要的 token 少得多。所以整体跑下来,5.5 的运行成本应该更低。这件事可能比大多数人意识到的更重要。 但它到底好不好?Berman 给出了肯定的回答,“好,而且非常强。” GPT-5.5 有两种使用形态:Codex 和 Pro。Berman 表示,在 Codex 里,它代表了当前智能体式编码能力的绝对前沿。它能发现并解决复杂 bug,能构建完整应用,也能轻松理解大型代码库。它在后端能力上强过 Opus,但在前端设计上仍然不如 Opus。 Berman 自己主要使用 medium 和 high thinking 设置。“extra high 实在太慢了,而且我不觉得额外的“思考量”值得为此付出代价。Opus,尤其是 4.6 fast,仍然比任何 GPT 模型都快得多。我是一个极度重视速度的人,所以这一点对我很重要。” “而在 Codex 里,它就是会一直往前推进。我给它一个正在做的新项目 PRD,只说了一句‘开始做吧’。我完全相信它能把整个项目搭出来,结果它也确实做到了。让 GPT-5.5 Codex 连续跑几个小时去构建一个东西,不是什么问题。它在视觉检查方面也自成一档,是我在其他模型上没见过的水平。它能够通过“构建 → 视觉复查 → 继续构建”的方式反复迭代,这种感觉比任何其他模型都更自主。” Berman 继续道,“在 ChatGPT 里使用 5.5 Pro 的感觉更夸张。它真的会让人觉得什么问题都能解决。说实话,我甚至想不出足够难的问题来考它。而且它可以连续工作 30 分钟、60 分钟、90 分钟甚至更久。它似乎也专门针对 OpenAI 的插件做了优化,比如 Google Docs、Microsoft Word 等,可以轻松创建一份 60 页、逻辑连贯且设计良好的文档。” “GPT-5.5 现在就是新的标杆。它就是前沿。除了速度之外,它已经和任何 Opus 模型一样强,甚至在很多任务上更强。”Berman 最后总结道。 不过,OpenAI 此前有强调 GPT-5.5 在能力提升的同时没有牺牲速度。该公司称,在真实服务场景中,GPT-5.5 的单 token 延迟与 GPT-5.4 持平,但智能水平显著提升;在完成相同 Codex 任务时,GPT-5.5 使用的 token 也明显更少。 据悉,GPT-5.5 与 NVIDIA GB200 和 GB300 NVL72 系统共同设计、训练并部署。 OpenAI 表示,模型帮助改进了服务模型自身的基础设施。一个典型例子是负载均衡和分区启发式算法。此前,OpenAI 会将加速器上的请求拆分成固定数量的块,以平衡计算核心之间的工作负载。但静态分块并不适合所有流量形态。OpenAI 称,Codex 分析了数周的生产流量模式,并编写自定义启发式算法优化分区和负载均衡,使 token 生成速度提升超过 20%。 “恰好”,Sam Altman 在推特上分享了他与黄仁勋发的邮件往来。黄仁勋在给 Altman 的邮件中写道(此前,Altman 发邮件称“由 GPT-5.5 驱动的 OpenAI Codex 已经发布,并且现在每一位 NVIDIA 员工都可以使用!”): 我刚刚把这封邮件发给了 NVIDIA 员工。 非常兴奋,我们所有人都将使用 Codex 来加速工作,并完成以前不可能完成的事情。请代我向你的团队表示祝贺,他们再次向世界展示了前沿所在。 也请再次感谢他们发明了 GPT,它给了我们一个跳板,让我们能够推理、规划、使用工具,并走向更远的地方。 开动那些 Blackwell 吧。我们需要更多 token! 但无论如何,从社区反馈看,GPT-5.5 的认可度非常高 当前,GPT-5.5、GPT-5.5 Pro、GPT-5.5 Thinking 面向付费用户开放: GPT-5.5 面向 ChatGPT 和 Codex 中的 Plus、Pro、Business、Enterprise 用户推出;GPT-5.5 Pro 面向 ChatGPT 的 Pro、Business、Enterprise 用户开放;GPT-5.5 Thinking 面向 Plus、Pro、Business 和 Enterprise 用户。 在 Codex 中,GPT-5.5 面向 Plus、Pro、Business、Enterprise、Edu 和 Go 计划开放,上下文窗口为 400K。GPT-5.5 也提供 Fast 模式,生成 token 速度提升 1.5 倍,但成本为 2.5 倍。 API 版本尚未同步上线,但应该很快。OpenAI 表示 GPT-5.5 很快将在 Responses API 和 Chat Completions API 中开放,定价为 5 美元 / 百万输入 token、30 美元/百万输出 token ,上下文窗口为 100 万。Batch 和 Flex 价格为标准 API 价格的一半,Priority 处理为标准价格的 2.5 倍。Pro 版本的定价为 30 美元 / 百万输入 token;180 美元/百万输出 token。 OpenAI 承认,GPT-5.5 的价格高于 GPT-5.4,但强调其更智能且更节省 token。在 Codex 场景中,公司称 GPT-5.5 对多数用户来说能用更少 token 交付更好结果。 Aakash Gupta 则分析认为,OpenAI 找到了自己的商业模式,而且看起来很像那个让微软成为 3 万亿美元公司的模式。他解释道: 如果你认真算一笔账,GPT-5.5 的定价其实已经说明了一切。 GPT-5 在 8 月发布时,价格是 0.63 美元 / 百万输入 token。GPT-5.4 在 3 月推出时,涨到了 2.50 美元 / 百万输入 token。仅仅七周后,GPT-5.5 的价格来到 5.00 美元 / 百万输入 token。也就是说,8 个月里,输入价格涨了 8 倍,而每一代模型的提升更多是渐进式的。 Nvidia 表示,其最新芯片可以将每 token 推理成本最高降低约 97%。OpenAI 的成本基础正在快速下探,但价格却在上涨。这里发生的利润率扩张,在企业软件历史上几乎前所未见。 9 亿周活用户,5000 万订阅用户,900 万付费企业客户。仅按每月 20 美元计算,订阅用户本身就能带来约 120 亿美元年化收入。而 API 涨价瞄准的,则是在 OpenAI 基础设施之上构建 Agent 的开发者。每一家为 GPT-5.5 推理支付 2 倍成本的 AI 初创公司,实际上都在为 OpenAI 自己的竞争产品提供资金。 Brockman 把不能明说的话说出来了:他们正在打造一个把 ChatGPT、Codex 和浏览器整合到同一平台里的“超级 App”。每一个基于 GPT-5.5 构建 Agent 的开发者,都是在付钱给 OpenAI,让它打造那个最终可能取代自己的东西。 7 周一次的发布节奏,会以竞争对手难以追上的速度不断叠加切换成本。只要发布得足够快,让客户不断围绕你的格式重建提示词和工作流管线,之后每一轮再涨价,因为他们已经很难离开。 下面,我们具体看下官方给出的模型测评情况。 在 OpenAI 公布的评测中,GPT-5.5 在智能体式编码方面取得明显提升。 在 Terminal-Bench 2.0 上,GPT-5.5 得分为 82.7%,高于 GPT-5.4 的 75.1%,也高于 Claude Opus 4.7 的 69.4% 和 Gemini 3.1 Pro 的 68.5%。该评测主要考察模型在复杂命令行工作流中的规划、迭代和工具协作能力。 在 SWE-Bench Pro 上,GPT-5.5 得分为 58.6%,略高于 GPT-5.4 的 57.7%,但低于 Claude Opus 4.7 的 64.3%。OpenAI 同时指出,已有实验室认为该评测存在记忆化风险。 在 OpenAI 内部的 Expert-SWE 评测中,GPT-5.5 得分为 73.1%,高于 GPT-5.4 的 68.5%。该评测面向更长周期的前沿编码任务,任务预估人类完成时间中位数为 20 小时。 OpenAI 称,GPT-5.5 在 Codex 中尤其适合承担实现、重构、调试、测试和验证等真实工程任务。早期测试显示,它更擅长在大型系统中保持上下文,推理模糊故障,用工具检查假设,并将变更贯穿到周边代码库中。 多位早期测试者也为 GPT-5.5 的编码能力背书。Every 创始人兼 CEO Dan Shipper 称其为“第一个真正具备严肃概念清晰度的编码模型”。Cursor 联合创始人兼 CEO Michael Truell 表示,GPT-5.5 比 GPT-5.4 “明显更聪明、更持久”,工具使用更可靠,能够在复杂长任务中更长时间保持推进。 除了编码,OpenAI 将 GPT-5.5 的另一个重点放在知识工作上。公司称,GPT-5.5 能更自然地完成寻找信息、理解重点、使用工具、检查输出、生成成果这一完整工作闭环。 在 Codex 中,GPT-5.5 相比 GPT-5.4 更擅长生成文档、电子表格和幻灯片。OpenAI 表示,Alpha 测试用户认为它在运营研究、表格建模、将混乱商业输入转化为计划等任务上超过此前模型。结合 Codex 的电脑使用能力后,GPT-5.5 可以看到屏幕内容、点击、输入、导航界面,并在工具之间切换。 OpenAI 还披露了内部使用情况:目前公司超过 85% 的员工每周都在使用 Codex,覆盖软件工程、财务、传播、市场、数据科学和产品管理等部门。 比如财务团队用 Codex 审查了 24,771 份 K-1 税务表格,总计 71,637 页,并通过排除个人信息的工作流,比上一年提前两周完成任务。Go-to-Market 团队中,也有员工用其自动生成每周业务报告,每周节省 5 到 10 小时。 在专业工作评测中,GPT-5.5 在 GDPval 上得分 84.9%,高于 GPT-5.4 的 83.0%、Claude Opus 4.7 的 80.3% 和 Gemini 3.1 Pro 的 67.3%。在 OSWorld-Verified 上,GPT-5.5 得分为 78.7%,略高于 GPT-5.4 的 75.0%,也略高于 Claude Opus 4.7 的 78.0%。在 Tau2-bench Telecom 上,GPT-5.5 在没有提示词调优的情况下达到 98.0%。 OpenAI 还将 GPT-5.5 描述为科研工作流中的重要进展。公司认为,科学研究不只是回答难题,还包括探索想法、收集证据、测试假设、解释结果,并决定下一步实验方向,而 GPT-5.5 在这一循环中的持续推进能力更强。 在 GeneBench 上,GPT-5.5 得分 25.0%,高于 GPT-5.4 的 19.0%;GPT-5.5 Pro 得分 33.2%,高于 GPT-5.4 Pro 的 25.6%。GeneBench 聚焦遗传学和定量生物学中的多阶段科学数据分析,要求模型处理不完整、有噪声甚至存在隐藏混杂因素的数据。 在 BixBench 上,GPT-5.5 得分为 80.5%,高于 GPT-5.4 的 74.0%。OpenAI 称,这表明 GPT-5.5 已经能够在生物信息学和数据分析任务中提供有意义帮助,成为科研人员的“共同科学家”。 OpenAI 还提到,一个搭配自定义 harness 的 GPT-5.5 内部版本,帮助发现了关于 Ramsey 数的新证明,并最终在 Lean 中得到验证。OpenAI 将其视为 GPT-5.5 不只生成代码或解释,而是能够贡献数学论证的案例。 早期测试者中,Jackson Laboratory for Genomic Medicine 的免疫学教授 Derya Unutmaz 使用 GPT-5.5 Pro 分析了一个包含 62 个样本、近 28,000 个基因的基因表达数据集,并生成详细研究报告。他表示,这项工作原本可能需要团队花费数月时间。 基因检测 在安全方面,OpenAI 表示,GPT-5.5 配套了公司迄今最强的一组安全防护措施。发布前,模型经过完整的安全和治理流程,包括准备度评估、领域专项测试、针对高级生物与网络安全能力的新评估,以及外部专家测试。 OpenAI 将 GPT-5.5 的生物/化学能力和网络安全能力在 Preparedness Framework 下评为 High。公司强调,GPT-5.5 尚未达到 Critical 网络安全能力等级,但评测显示其网络安全能力相比 GPT-5.4 有明显提升。 在 CyberGym 上,GPT-5.5 得分为 81.8%,高于 GPT-5.4 的 79.0% 和 Claude Opus 4.7 的 73.1%。在内部 CTF 挑战任务中,GPT-5.5 得分为 88.1%,高于 GPT-5.4 的 83.7%。 OpenAI 表示,将对 GPT-5.5 部署更严格的潜在网络风险分类器,部分用户初期可能会感觉拒答更多或更“烦人”,但公司会持续调优。同时,OpenAI 也将通过 Trusted Access for Cyber 为经过验证的防御者提供更少限制的访问权限,首先从 Codex 开始,支持合法网络防御工作。 参考链接:赢了 Opus 4.7 和 Mythos?






类微软的商业模式?
四大能力提升

编程能力继续强化

知识工作

科学研究

网络安全能力增强,安全等级被列为 High
Nonce 是⾯向 Bitcoin Mining 场景的监控、分析、⾃动化的 SaaS 服务,主要服务北美上市企业。
40K/mo * 14 薪 + 奖金
30 - 40K/mo * 14 薪 + 奖金
30 - 40K/mo * 14 薪 + 奖金
注:我们的面试流程简单,因为候选人的简历和 Github 已提供充足的信息。我们主要关注项目实践中展现的工程能力和协作能力。因此,我们会根据候选人的薪酬预期,提供为期 2 周左右的付费项目实践,候选人可自愿参与。
昨天中午点了一个外卖,不是小作坊,是一个连锁饭店。
因为公司写字楼不让外卖员进来,外卖一般都是放后门外卖柜,所以全程和外卖员没有接触。
午休时间到了,我下楼取了外卖上来吃,打开外卖包装发现最顶上的饭盒盖子上有一些烟灰,虽然迟疑了一下,但是回忆了一下拆包装的时候,包装是完整的,商家订的订书针也没有拆开过的痕迹,加上饿的不行了,就没多想,把灰吹掉就打开盒子开始吃了。
等我吃的差不多了,拿起盒子准备收尾的时候,才发现,哪里是一点烟灰啊,盒子底下全是烟灰,再一看,洒的我桌子上也是一堆烟灰。
顿时就觉得很恶心,谁知道这烟灰究竟是只有外面有还是饭菜里面也有。
忍者恶心把东西收拾扔了,才想起来自己居然忘记拍!照!了!
但是越想越恶心,于是给了商家一个差评。
今天早上商家就打电话来了,态度倒是非常好,他们表示他们厨房全程监控,没有发现有厨师抽烟,他们怀疑是外卖员弄的。
我表示我发现烟灰后特意检查过包装,没有被拆开过的痕迹。我怀疑如果不是厨师弄的话,大概率是厨师出菜后负责打包的人弄得吧。
但是他也否认了,表示打包的服务员都是女性,没有人抽烟。
最后他表示可以帮我把这单退了,然后他们也会继续调查这个烟灰哪里来的,顺便加了我微信,有后续结果微信发给我。
此时我开始纠结了,他说的这么滴水不漏,大概率是不会承认的了。
我一边觉得发生这个事真的恶心,想让他们付出应有的代价。
一边也知道自己非常被动,毕竟我完全没有留下任何照片或者视频,在任何人看来都是我的一面之词。
于是尽管他在微信上让我把订单退了,并且让我下次点外卖的时候备注一下,他们送我点东西,我还是拒绝了,表示退款就不用了,查清楚原因告诉我就行了。
说完这句话之后,商家果然图穷匕见了,让我帮忙把评论删除了。
我想了下,这种完全没有图片只有文字的评论,就算我不删,他申诉到美团也大概率是会被删的。
所以就算很烦,还是主动去删除了。
最后,删除评论的时候才发现,昨天中午发的评论,到我删的时候,浏览量还是只有 1……
从去年 12 月就开始,营销号就各种“即将发布”,折腾了小半年,听都听吐了,终于要正式发布了。
前几周的官方 Web 版本的体验来看,绝对性能是没期待了,希望价格便宜或者有其他亮眼特性吧。
随着“中国制造2025”与工业4.0的深度融合,制造业正经历从“自动化”向“数智化”的深刻转型。对于制造业的自动化部门而言,他们不仅是产线控制系统的中枢,更是工业核心数据(CAD图纸、PLC程序、工艺参数等)的集散地。然而,在实际运作中,自动化部门往往面临着明显的协同困境:动辄几GB的UG三维模型在庞杂的业务网中缓慢传输;核心图纸在传统的Windows 共享文件夹 中面临权限失控与被误删误改的风险。 作为自2011年上线、稳定运营已超过15年的企业级文档管理解决方案,坚果云针对复杂网络环境与非结构化数据痛点,为制造企业自动化部门构建了一套集高效传输、金融级 加密 与全场景适配于一体的数据协同底座。目前,坚果云已成功服务超千万用户及10万家知名机构,包括中国石油、郑州日产等头部制造与能源巨头。 01 深度适配大文件与复杂网络,破解图纸传输魔咒 在自动化产线设计与改造项目中, 工程师 们常与CAD、SolidWorks、UG/NX等专业工程软件打交道。完整的产线三维装配体往往高达数GB,且包含海量的零部件引用文件(海量小文件)。传统Windows共享或普通 网盘 在面对此类场景时,传输卡顿、上传中断是家常便饭。针对上述痛点,坚果云在底层传输上实现了极具针对性的技术突破: 02 重构权限体系,终结Windows共享的“裸奔”时代 传统的Windows域共享文件夹只能实现极其基础的读写分配,无法精细到“谁能看、谁能改、谁能下载、谁能截屏”。为契合制造业复杂的组织 架构 要求,坚果云引入了一套远超常规网盘的精细化权限管控体系。 03 军工级合规背书,夯实工业资产安全护城河 制造业的核心图纸即企业的生命线。在安全合规层面,坚果云构建了真正的壁垒:坚果云已通过公安部信息系统安全等级保护三级备案(该认证为最高级别非银行机构认证),同时具备ISO27001、ISO27701等多重国际标准资质。 底层数据采用AES-256金融级加密算法与SSL/TLS全链路加密传输技术。数据存储采用高冗余的分布式存储架构,配名单向哈希计算密钥机制,通过严密的物理与网络隔离,确保哪怕是系统管理员也无法获取企业的核心图纸数据。对于企业日常防灾防勒索,使用内置的坚果时光机也能对全电脑任意路径(含桌面、下载目录或微信文件)进行无死角备份及时间轴溯源,提供全方位保护。 04 丰富的生态矩阵,无感融入现有IT系统 制造企业的IT环境相对复杂,为了不打破工程师的既有工作习惯,坚果云致力于打造“无感跨区协作”。除无缝兼容Windows、Mac与移动端全平台外,系统也高度开放,能够整合企业现有的办公流程。无论是对日常文档处理所需的专注环境(如支持大纲笔记与思维导图的怡氧生态)、专业的文献笔记同步(Zotero与Obsidian插件适配),还是高强度的纸质图纸入档(坚果云扫描),坚果云始终将工具价值回归于生产力本身。无论企业规模如何,均能零学习成本切入“云端制造”。 **现在坚果云团队版还有免费试用20天:坚果云团队版官网 —— 制造业常见问题精选 —— Q:制造业有非常多零散的小批量图纸和零部件文件,用坚果云同步会卡顿吗? A:不会。针对制造业常见的“海量小文件”痛点,坚果云对底层索引引擎进行了特殊优化,针对大量多层级文件夹和碎片化KB级小图纸,同样能够保持极高的扫描验证速度并稳健同步,大幅优于普通的云储存管理软件。 Q:自动化团队成员由于经常在不同车间移动,网络很差,如何保障文件获取? A:坚果云采用本地无感同步机制。只要在有网络的区域文件会自动同步至设备终端的实体文件夹中;即使进入无信号深井车间,依然可像访问本地C盘、D盘一样快速查阅庞大图纸,网络恢复后再静默上传差异部分。 结语 在从自动化向数智化演进的深水区,数据不应当是死锁在各种孤岛中的静态资产,而是贯穿产业链协同流转的血液。坚果云凭借稳健十五年的行业积淀、高强度的合规安全体系、智能传输与精细化的多端生态体验,无论是高效协作的百人团队,还是看重数据防泄密的大中型制造生产线,都是极其理想的解决方案。让工程师们不再将精力损耗在传输卡顿中,而是真正聚焦于工艺的革新。
坚果云专为复杂网络环境设计,免费与付费用户均不设置传输限速。对于频繁修改的大型图纸,坚果云支持智能增量同步技术并支持局域网同步加速。当工程师修改了一处零部件时,系统仅上传文件发生修改的极小部分数据,而非数GB的完整重传,这使同步速度实现了质的飞跃。
无需在出差设备的本地强行安装庞大的工业软件,坚果云支持超100种格式的直接在线预览。面对繁杂的产线迭代方案,坚果云不仅支持两人以上的实时共享与多人在线编辑协作,强大的文件历史版本功能更支持差异对比与一键恢复,帮助自动化部门精准回溯每一次的参数变更,彻底告别“最终版.dwg”、“绝对不改版.dwg”的版本混乱灾难。
2026年4月22日,由温州市委、市政府主办的“天下浙商家乡行·走进温州交流座谈会”在温州市人民大会堂隆重举行。浙江省委常委、温州市委书记张振丰,温州市委副书记、市长张文杰,省人民政府驻上海办事处党组书记、主任李雄伟,上海市浙江商会会长、上海均瑶(集团)有限公司董事长王均金等领导与上海市浙江商会企业家代表共聚一堂。拓数派董事长兼CEO冯雷受邀出席会议,并作为金种子企业代表分享了拓数派以“可信Data+零代码智能体AI”深入温州实业,配合国家顶层数据基础设施设计,支持数据节点要素流通。 面对席卷全球的大模型浪潮,冯雷在发言中抛出了一个生动的行业论断:“如果智能体是战斗机,模型是发动机,那么数据就是燃料。” 拓数派敏锐地指出,随着公域高质量公开数据的日益枯竭,未来AI竞争的胜负手(Key)已不在于通用数据的堆砌,而在于如何挖掘、激活和利用那些安全、可信的私有化数据。这正是拓数派坚定不移的技术护城河。 为了攻克AI落地场景的“最后一公里”,拓数派凭借旗舰产品大模型数据计算系统πDataCS,提供坚实的可信“Data+AI”底座,让私域数据与大模型的安全耦合,从五百强大型企业到OPC场景都能零代码构建智能体,实现业务从自动化向智能化的跨越式升级。针对产业集群的复杂需求,拓数派提供专业的、端到端的「Data+AI」解决方案。拓数派致力于助力各行业的“链主企业”构建可信数据空间与数据本体,实现行业智能体AI。 作为杭州“AI十八罗汉”,拓数派与温州近年来结下了深厚合作缘分。自2024年起,拓数派便以技术赋能者的身份深度参与温州的数智化建设,率先助力苍南县成功打造了“社会治理智能体”,为基层治理插上AI的翅膀。随着合作的深入,拓数派在2025年进一步开展了教育实训与“OPC(一人公司)”赋能计划,致力于通过零代码智能体培养新一代超级个体。步入近期,这份合作再度开花结果,拓数派正为苍南县倾力打造的“南哥AI教育平台”提供坚实的底层技术支撑,持续推动地方教育公平与智能化转型。这一系列扎实的落地成果,不仅是拓数派技术实力的缩影,更是对温州持续优化营商环境、拥抱数智经济的最有力回应。 展望未来,作为浙商“金种子企业”,拓数派将继续秉持初心,为温州乃至全国的数字经济高质量发展注入不竭动力。

