各位对于花钱是如何控制的
先说背景,家里经济一直不太行,小时候甚至还有拿低保的时候,在这种情况下,我老是想买一些其实可以完全没必要买的东西,比如手机电脑各种小东西,前些年因为这个吃了大亏,负债十几万,今年还完了。
最近不知道是因为什么,又开始想换手机,想买 pad,在年前还想换 mac,但是我也深知这些都是非必要的,而且这两年身体也亮了红灯,想想父母都没用过很好的手机啥的,深感愧疚。
之前有人说我这是小时候身边人太容易得到想要的东西被影响了,现在冷静下来后我只感觉自己脑子有点不正常
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
先说背景,家里经济一直不太行,小时候甚至还有拿低保的时候,在这种情况下,我老是想买一些其实可以完全没必要买的东西,比如手机电脑各种小东西,前些年因为这个吃了大亏,负债十几万,今年还完了。
最近不知道是因为什么,又开始想换手机,想买 pad,在年前还想换 mac,但是我也深知这些都是非必要的,而且这两年身体也亮了红灯,想想父母都没用过很好的手机啥的,深感愧疚。
之前有人说我这是小时候身边人太容易得到想要的东西被影响了,现在冷静下来后我只感觉自己脑子有点不正常
当工具行业还在 “功能内卷” 时,我们在思考:真正的高端工具,能否成为 “技术图腾”,“审美符号” 与 “体验革命” 的三位一体?当工具不再是简单的 “劳作器具”,而是科技与匠心的结晶,它能迸发怎样的能量? S40/S40P 电动螺丝刀给出了答案 — 它不是一款工具的迭代,而是一次对 “精密拆装领域” 的行业话语权重构:以大师级工艺为骨,以智能黑科技为魂,以用户极致体验为核,以 “重新定义精密拆装” 的姿态,宣告工具行业的高端革命正式开启! 全铝机身采用顶级 CNC 一体化加工,每一寸肌理都镌刻着精密制造的态度;防滑设计并非简单的功能叠加,而是在人机工程学与美学之间的精妙妥协 —— 握持时,是扎实可靠的工具质感;静置时,是可赏可玩的工业艺术品。 1、OLED 数显黑科技 定制化 OLED 屏实时呈现参考扭力、旋转方向、作业进度,“精密” 不再是抽象概念,而是一目了然的数字标尺。 2、3D 体感控制 突破性 3D 体感技术,手势轻转即可实现角度精准调控,告别传统操作的笨拙感,拆装动作如行云流水般优雅。 1、强磁高速电机 S40 峰值转速 180RPM,S40P 直接拉满 260RPM,转速三档可调,动力输出 “收放自如”; 2、高性能齿轮箱 合金齿轮精密咬合,不仅能迸发澎湃大扭力(S40 达 0.2N・m,S40P 飙升至 0.26N・m),更实现 “长寿命” 承诺 —— 反复作业不易磨损,堪称 “性能与耐用的双向奔赴”。 1、光明之眼:前置 LED 照明 六颗高亮 LED 灯珠,明暗自由调节,哪怕在黑暗狭小的作业空间(如手机内部、精密仪器腔体内),也能照亮每一处细节; 2、批头自由:H4/800 全兼容 标配六大类 19 枚精密批头,从十字、一字到五星、三角,覆盖电子维修、模型组装、家居拆装等全场景,真正实现 “一枚工具,万种可能”; 3、扭力校准:精准到毫厘 专业级扭力校准功能,让 “力道把控” 从 “经验主义” 升级为 “数据驱动”,杜绝过拧 / 欠拧风险。 历经长时间的研发攻坚,每一台的螺丝刀,都是 “可靠” 与 “创新” 的具象化表达。它不是一款普通工具,而是专业人士的 “战力放大器”,是极客玩家的 “收藏级装备”,更是行业从 “将就” 到 “讲究” 的里程碑之作!电动螺丝刀,S40/S40P双版本可选!硬核性能加持,多档位可调,精密拆装新纪元
一、工艺之巅:在 “工业艺术品” 与 “专业工具” 间找到完美平衡
二、智能内核:让 “精密” 可视化,让 “操作” 优雅化
三、性能猛兽:大扭力与长寿命的 “黄金契约”
四、细节满满:把 “用户痛点” 变成 “行业亮点”
五、品质背书:权威认证的 “信任票”
GPT-5.5 是 OpenAI 于 2026 年 4 月 23 日发布的新一代旗舰大语言模型,定位"真实工作的新型智能",是自 GPT-4.5 以来首个从零重新训练的基础模型。它在 Agent 编码、计算机操控和深度研究三个方向实现了显著跨越,API 定价从 GPT-5.4 的 $2.50/$15 翻倍至 $5.00/$30(每百万 token 输入/输出)。对企业 IT 负责人和开发者来说,核心问题只有一个:额外的成本能否换来足够的业务价值? GPT-5.5 以内部代号"Spud"(土豆)预热,是 GPT-5.x 系列中首个完整重新训练的基础模型,而非对上一代的微调改进。这一架构起点意味着性能跨越幅度大于此前历次更新。 三个发布版本: 核心能力对比: GPT-5.5 的 Agent 能力核心突破在三点:多步自主循环、计算机操控达生产可用水平、MCP 工具命中精度大幅提升。 在 Terminal-Bench 2.0(测试需要规划、迭代和工具协调的复杂命令行工作流)中,GPT-5.5 以 82.7% 位列行业第一,分别领先: 根据 OpenAI 官方发布数据(2026 年 4 月 23 日),GPT-5.5 在 Codex 相同任务上输出 token 消耗更低——这是历史上首次旗舰模型在性能提升的同时减少了 token 使用量。 OSWorld-Verified(衡量自主桌面任务完成度)中,GPT-5.5 得分 78.7%,高于 GPT-5.4(75.0%)和 Claude Opus 4.7(78.0%)。OpenAI 将此描述为"可以真正和你一起使用电脑":模型能看到屏幕内容、点击按钮、跨应用导航,无需定制工具链即可完成跨系统工作流。 在 MCP Atlas 工具调度基准上,GPT-5.5 得分 75.3%(GPT-5.4:67.2%,+8.1pp)。对构建多工具编排 Agent 的开发者而言,这一提升直接降低工具调用出错率。开发者通过标准 OpenAI SDK 格式即可接入;支持 OpenAI 接口的 MCP 编排平台(如七牛云的 MCP 服务)无需修改 SDK 层代码即可切换到 GPT-5.5。 传统提示词工程是在单次对话中最大化输出质量;Agent 模式是让模型在多步循环中自主规划、执行、验证和纠错。 以代码调试为例: Expert-SWE 内部基准(任务中位数人工完成时间为 20 小时)中,GPT-5.5 得分 73.1%(GPT-5.4:68.5%),支撑了其在长周期工程任务上的实际能力。 GPT-5.5 定价相比 GPT-5.4 恰好翻倍,但 OpenAI 明确声明"每项任务实际消耗的 token 更少"——价格涨幅需结合 token 效率综合评估。 数据来源:OpenAI 官方 API 定价页面、Appwrite 技术博客,2026 年 4 月 23 日。 三条降本路径: 根据 LLM Stats(2026 年 4 月)实测升级建议: 推荐升级至 GPT-5.5: 建议继续使用 GPT-5.4: 对成本敏感型企业,最实用的架构是双模型路由: GPT-5.5 在 Agent 编码和计算机操控两项上建立明显领先,但在纯代码补全(SWE-Bench Pro)上仍落后 Claude Opus 4.7。 SWE-Bench Pro(公开版)中,Claude Opus 4.7 以 64.3% 领先 GPT-5.5 的 58.6%。但 OpenAI 在官方发布页中注明:Anthropic 自报存在部分题目记忆化迹象。 这是 OpenAI 措辞最直接的竞品质疑,独立机构尚未复现验证,评估结果可比性存疑。 综合对比表(2026 年 4 月): 2026 年 4 月,企业 IT 负责人评估 GPT-5.5 时,应围绕"工作流自动化密度"而非"基准分"做决策。 适合优先升级的企业类型: 持观望态度的场景: API 访问现状(截至 2026 年 4 月 24 日): GPT-5.5 当前已开放 ChatGPT(付费计划)和 Codex,API 正式端点"即将推出(coming very soon)",尚未全量上线。企业 IT 团队可提前预构建集成,无需等待公告后再行动。 Q:GPT-5.5 和 GPT-5.4 可以同时使用吗? 可以。OpenAI 未下线 GPT-5.4,两者可在同一项目中并行调用。建议将 5.4 保留用于成本敏感型高频任务(摘要、分类),5.5 仅用于真正需要 Agent 推理或超长上下文的工作流,避免全量切换带来的预算冲击。 Q:GPT-5.5 的"幻觉率降低 60%"可信吗? 这是 OpenAI 官方发布声明中的数据(来源:openai.com,2026 年 4 月 23 日),对比基准为 GPT-5.4,具体测评方法未完整披露。目前尚无独立机构复现验证,企业在高风险输出场景中仍建议保留人工核查流程。 Q:SWE-Bench Pro 上 Claude Opus 4.7 领先,是否意味着纯代码任务应该选 Claude? 对于以 SWE-bench 为代理指标的纯代码补全任务,Opus 4.7 在基准上确实更强。但 OpenAI 指出 Anthropic 报告了记忆化迹象,建议在自己的私有代码库上实测后再做迁移决策,不要仅凭公开基准分。 Q:GPT-5.5 Pro 对普通开发者值得购买吗? GPT-5.5 Pro 输出定价约为 $180/百万 token(约 6× 标准),适合"第一次回答必须正确"的高精度关键决策场景。对大多数开发者而言,Standard + Thinking 版本已能覆盖 90% 以上的生产需求。 Q:国内企业通过第三方 API 中间层接入 GPT-5.5 时需注意什么? 核心是确认中间层是否支持 GPT-5.5 的新参数(如 Thinking 模式的推理预算控制)和 Computer Use API。标准 OpenAI SDK 接口(Chat Completions 和 Responses API)均保持向后兼容,现有代码迁移成本低。 GPT-5.5 是 2026 年 4 月 AI 模型竞赛中一个真实的质量跃升。 Terminal-Bench +7.6pp、MCP Atlas +8.1pp、幻觉率 -60% 的组合,对于以 Agent 工作流为核心的开发团队,完全可以抵消 2× 的定价增幅。但对于高吞吐量、低复杂度场景,GPT-5.4 仍是更明智的选择。 正如 LLM Stats(2026 年 4 月)所总结:核心问题不是"GPT-5.5 好不好",而是"你的工作流是否真正在消耗额外的推理能力"。 据 OpenAI 官方博客(April 23, 2026)描述,GPT-5.5 代表"一种新型智能"——从当前基准数据看,这一定位在 Agent 编码和计算机操控两个垂直领域得到了实质支撑。 延伸资源: 本文内容基于 2026 年 4 月 24 日公开数据。GPT-5.5 API 端点当前处于"即将推出"状态,访问时间可能在本文发布后短期内更新;所有基准数据均来自 OpenAI 官方发布及 Appwrite、LLM Stats、Apidog 等独立技术博客交叉核实。建议定期查阅 OpenAI 官方文档获取最新状态。
一、GPT-5.5 是什么:架构与版本全解
能力维度 GPT-5.4 GPT-5.5 上下文窗口 1.05M tokens 1M tokens(Codex: 400K) 多模态 文本+图像+音频 原生全模态(含视频) 计算机操控 改善中 生产可用级 多步工具链 偏好单次触发 全自主循环 幻觉率 基线 -60%(OpenAI 自测) MMLU 91.1% 92.4% 二、Agent 能力全面解析:这次不一样在哪里

2.1 命令行 Agent:Terminal-Bench 2.0 领先 7.6 个百分点
2.2 计算机操控:OSWorld-Verified 78.7%
2.3 MCP 工具调度:MCP Atlas +8.1pp
2.4 Agent 与传统提示词工程的本质差异
三、价格翻倍后怎么算账:成本分析与降本策略
3.1 官方定价对比(2026 年 4 月)
模型 输入($/百万 token) 输出($/百万 token) GPT-5.5 $5.00 $30.00 GPT-5.4 $2.50 $15.00 Claude Opus 4.7 $5.00 $25.00 Gemini 3.1 Pro $2.00 $12.00 3.2 升级 vs 不升级决策矩阵
3.3 混合路由架构:用 5.5 规划、5.4 执行
四、与竞品关键对比:GPT-5.5 的优势与短板

SWE-Bench Pro 的重要注脚
维度 GPT-5.5 Claude Opus 4.7 Gemini 3.1 Pro Terminal-Bench 2.0 82.7% 69.4% 68.5% SWE-Bench Pro 58.6% 64.3%(存疑) 54.2% OSWorld 计算机操控 78.7% 78.0% — ARC-AGI-2 85.0% 75.8% 77.1% API 价格(输入/输出) $5/$30 $5/$25 $2/$12 幻觉率改善 -60% — — 五、企业 IT 采购与升级决策指南
常见问题
结语
DuckDB-paimon 是由 PolarDB 团队开发的一款 DuckDB 扩展插件,允许通过 SQL 直接查询 Apache Paimon 表,无需任何 ETL 搬运,无需 Flink/Spark 集群,打开 DuckDB Shell 即可对 Paimon 表执行 SQL 分析。 近期发布 v0.0.3-variegata 版本带来了一项系统性的改进:谓词下推(Predicate Pushdown)能力的全面覆盖。 "谓词"这个词听起来有些学术,其实就是 SQL 中 WHERE 后面的那些过滤条件,比如 WHERE age > 18 或 WHERE region = 'cn-hangzhou'。 当 DuckDB 通过 duckdb-paimon 查询一张 Paimon 表时,有两种处理方式: 方式一(没有谓词下推):DuckDB 向 Paimon 发起请求,Paimon 把表里所有的数据都从数据湖存储层读出来,通过网络传给 DuckDB,再由 DuckDB 的执行器在内存里逐行检查哪些符合 WHERE 条件。如果这张表有 1 亿行,哪怕最终只需要 1000 行,也得先把 1 亿行全部搬过来。 方式二(有谓词下推):DuckDB 在发起请求的同时,把 WHERE 条件也一并告知 Paimon。Paimon 在自己的存储层读取文件时,就能利用列式存储的文件级统计信息(比如每个文件中某列的最小值/最大值),直接跳过那些肯定不包含目标数据的文件,甚至在行组(row group)级别提前过滤,只把可能命中的数据传出来。 Paimon 的数据通常存放在对象存储(如阿里云 OSS、AWS S3)上,每次 I/O 都有网络开销。谓词下推减少的不只是计算量,更是从 Paimon 数据湖存储层实际读出的数据量本身。对于存储在对象存储上的大表,这个差别非常明显——扫描 1 TB 和扫描 100 GB,不只是速度上的区别,也是存储读取成本上的区别。 v0.0.2 已经具备了基本的扫描能力,但谓词下推覆盖还不完整。v0.0.3 把这部分补全,覆盖了日常 SQL 里最常见的那几类过滤条件。 比较运算符 NULL 判断 BETWEEN NOT BETWEEN 同样支持。 IN / NOT IN LIKE AND / OR 逻辑组合 多个条件组合后整体下推,DuckDB 解析出的谓词树按原结构传递给 Paimon: AND 和 OR 的嵌套组合均支持。 ** DuckDB 升级:底层 DuckDB 从 v1.5.1 升级至 v1.5.2。 点击下方阅读原文,从 [GitHub Releases] 下载 Linux amd64 或 arm64 预编译包。也可参考项目 README 从源码构建。本期互动评论区分享您的应用场景和使用体验,截至4月28日(含),留言且留言处点赞数前三,随机赠送社区礼品。谓词下推意味着什么
谓词下推意味着什么新增支持的谓词类型
=、!=、<、>、<=、>= 这几个基础运算符现在都能下推。这是最高频的过滤场景,比如:SELECT * FROM paimon_table WHERE age > 18;
SELECT * FROM paimon_table WHERE status != 'deleted';SELECT * FROM paimon_table WHERE email IS NULL;
SELECT * FROM paimon_table WHERE phone IS NOT NULL;
范围查询是时序数据和日志表里最常见的过滤方式:SELECT * FROM paimon_table WHERE event_time BETWEEN '2026-01-01' AND '2026-04-01';
SELECT * FROM paimon_table WHERE region IN ('cn-hangzhou', 'cn-shanghai');
SELECT * FROM paimon_table WHERE category NOT IN ('test', 'demo');
字符串前缀、后缀、模糊匹配:SELECT * FROM paimon_table WHERE name LIKE 'Zhang%';SELECT * FROM paimon_table
WHERE region = 'cn-hangzhou'
AND event_time >= '2026-04-01'
AND status IN ('active', 'pending');
其他改动
安全修复**:Paimon secret 中的 key_id 字段现在会在日志和错误信息中自动脱敏,避免敏感凭据被意外打印。获取方式

今天看到一条新闻,让我愣了好久。 谷歌在Cloud Next '26上宣布:他们内部75%的新代码已经由AI生成,再由工程师审核确认。 75%。 这个数字比去年秋天的50%又涨了,现在已经超过三分之二。 说实话,刚看到这个数字的时候,我心里有点不是滋味。 我是2018年入职的,在谷歌写代码已经快8年了。 刚入职那会儿,写代码是核心工作。每天早上来,打开IDE,开始敲代码——写业务逻辑、优化性能、设计架构、改bug,一行一行敲,忙到下班。 那时候我觉得,代码行数就是我的KPI,写得多=干得好。 但这两年,情况完全变了。 去年团队引入AI编程工具之后,我的工作方式彻底不一样了。 早上来了,先想清楚今天要做什么功能,然后把需求描述给AI,它直接给我生成代码框架。我再去看代码对不对、有没有漏洞、符不符合架构设计,审核通过之后提交。 一个功能,以前我可能要写一天;现在半天就能搞定,剩下的时间干嘛? 去做那些AI做不了的事:和产品经理撕需求、review架构方案、和别的团队对齐技术标准…… 有人问我:那你是不是觉得自己被AI替代了? 我觉得这个问题本身就有点问题。 不是"替代",是"升级"。 以前我花大量时间在"怎么写"上;现在我更多在思考"写什么"和"为什么写"。 就像计算器发明之后,数学家没有被淘汰——反而因为计算负担减轻,可以去研究更深的问题。 AI让写代码变快了,但系统设计、业务理解、技术判断……这些能力反而更重要了。 <<<对了。顺嘴提一句,技术大厂,前后端-测试机会,全国一线及双一线城市均有坑位,待遇和稳定性还不错,感兴趣看看。 当然,我也承认,这个转变不容易。 身边有同事确实有点跟不上——习惯了埋头写代码,突然要他去做架构判断、做技术决策,他反而不知道该干嘛。 这种感觉就像从"执行者"变成"管理者",需要完全不同的思维方式。 但我觉得,这才是未来程序员的方向。 会写代码只是基础;能驾驭AI、能做技术决策、能解决复杂问题,才是真正的竞争力。 现在我每天的工作流程大概是: 比以前写代码忙多了,但有意思多了。 因为以前我是个"码农",现在我更像个"技术导演"——AI是我手下的演员,我来决定演什么、怎么演。 所以,回到那个问题:AI会不会取代程序员? 我的答案是:会取代"只会写代码"的程序员,但不会取代"能用AI创造价值"的程序员。 关键是,你愿不愿意迈出那一步,从"敲代码"变成"指挥AI"?
上午:和产品经理对齐需求,确定今天要做的事
下午:用AI生成代码,自己做审核和架构调整
晚上:看技术文档、学新技术、做技术方案
2026 年的 Go 语言开发已经进入了深度工程化阶段。开发者在构建现代化应用时,不再仅仅关注语法逻辑,而是将目光投向了系统的可观测性、API 的标准化以及长期维护的稳定性。以下是目前在 Go 生态中表现突出的几个库,它们代表了当前后端开发的技术趋势。 在追求低延迟的微服务场景中,Echo 凭借其极致的路由匹配性能和极简的API设计,依然占据着统治地位。它避开了过度封装的陷阱,让开发者能直观地掌控请求处理的每一个环节。 Huma 彻底终结了代码写完还要手动更新Swagger的痛苦。它通过声明式的结构体定义,将业务逻辑与 OpenAPI 3.1 规范深度绑定。只要程序能编译通过,对外提供的API文档就一定是准确的。 Ent 改变了传统ORM依赖字符串拼接和反射的弊端。它通过代码生成技术,将数据库表关系转化为强类型的Go代码。开发者在编写查询逻辑时,可以享受到完整的IDE补全和编译期检查。 slog 已经成为Go应用日志处理的通用语言。作为标准库的一部分,它提供了高性能的 JSON 输出能力,能够无缝对接各类日志采集系统,解决了过去各个库之间日志格式不统一的难题。 你不会还在手动埋点吧?基于 eBPF 技术的自动仪表工具,可以在不侵入业务逻辑的前提下,自动捕获系统的调用链数据。这种零代码侵入的监控方式,极大地提升了复杂分布式系统的排障效率。 Koanf 解决了配置来源多样化的问题。无论是本地 YAML 文件、环境变量还是远程配置中心,Koanf 都能以极低的资源占用完成加载与合并,是构建云原生应用时管理动态参数的利器。 随着安全合规要求的提升,Sigstore 已经成为发布流程中的必选项。它让开发者能方便地对二进制文件进行数字签名,确保代码从编译、分发到部署的整个生命周期都真实可信。 对于涉及多步调用、且每一步都可能失败的复杂业务,Temporal 提供了近乎完美的解决方案。它通过持久化工作流状态,确保了业务逻辑在遇到网络波动或服务宕机时能够自动恢复。 不管是Go的新手,还是资深的Go程序员,部署Go开发环境都是比较繁琐的,得考虑各种变量,还要处理依赖冲突。 而 ServBay 支持一键部署 Go 环境,就省了不少配置 PATH 路径和处理依赖冲突的时间。而且它还支持多个版本的 Go 同时并存,开发者可以为不同的项目指定不同的运行版本,并实现版本间的一键平滑切换。 这种灵活性确保了在尝试上述新技术栈时,不会对现有的稳定环境造成任何冲击。 现代 Go 开发的重心已经向稳定性倾斜。Echo 和 Huma 负责构建稳健的接口,Ent 处理复杂的数据关联,slog 和 OpenTelemetry 保证了系统的透明度。结合 Koanf 的灵活配置与 Temporal 的流程编排,一套成熟、可扩展的后端架构便初具规模。开发者应根据项目的实际需求,在这些优秀的工具中选择合适的组合。
Echo:高性能Web服务首选
package main
import (
"net/http"
"github.com/labstack/echo/v4"
)
func main() {
app := echo.New()
// 简单的健康检查接口
app.GET("/health", func(c echo.Context) error {
return c.JSON(http.StatusOK, map[string]string{"status": "alive"})
})
app.Start(":8080")
}Huma:强类型API文档化的方案
package main
import (
"context"
"github.com/danielgtaylor/huma/v2"
"github.com/danielgtaylor/huma/v2/adapters/humaecho"
"github.com/labstack/echo/v4"
)
type ProfileResponse struct {
Body struct {
Username string `json:"username"`
}
}
func main() {
e := echo.New()
config := huma.DefaultConfig("User Service", "1.0.0")
api := humaecho.New(e, config)
huma.Register(api, huma.Operation{
Method: "GET",
Path: "/profile/{id}",
}, func(ctx context.Context, input *struct{ ID string `path:"id"` }) (*ProfileResponse, error) {
res := &ProfileResponse{}
res.Body.Username = "dev_user_" + input.ID
return res, nil
})
e.Start(":8080")
}Ent:彻底告别反射的图论ORM
// 使用生成的代码进行流式查询
func GetActiveUsers(ctx context.Context, client *ent.Client) ([]*ent.User, error) {
return client.User.
Query().
Where(user.StatusEQ("active")).
Order(ent.Desc(user.FieldCreatedAt)).
All(ctx)
}slog:结构化日志的标准答案
package main
import (
"log/slog"
"os"
)
func main() {
// 全局配置结构化日志
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
slog.SetDefault(logger)
slog.Info("支付网关启动",
slog.String("env", "production"),
slog.Int("retry_limit", 3),
)
}OpenTelemetry Go Auto Instrumentation (eBPF):可观测性的降维打击
// 业务代码无需任何 OTEL 埋点
// 仅需标准的 HTTP 处理逻辑,eBPF 代理会自动捕获 Trace ID 和耗时
package main
import (
"net/http"
"log"
)
func main() {
http.HandleFunc("/data", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("自动追踪测试"))
})
// 运行时通过外部 otel-go-instrumentation 代理启动即可
log.Fatal(http.ListenAndServe(":8080", nil))
}Koanf:轻量级配置管理的标配
package main
import (
"github.com/knadh/koanf/providers/env"
"github.com/knadh/koanf/v2"
)
var k = koanf.New(".")
func main() {
// 仅加载前缀为 APP_ 的环境变量
k.Load(env.Provider("APP_", ".", func(s string) string {
return s
}), nil)
apiToken := k.String("APP_API_TOKEN")
println("已加载Token长度: ", len(apiToken))
}Sigstore:构建不可篡改的供应链安全
package main
import (
"github.com/sigstore/sigstore-go/pkg/verify"
)
func VerifyBinary(artifactPath string, signature []byte) error {
// 使用 Sigstore 库校验二进制文件的合法性
// 此处演示初始化验证器的逻辑概念
policy := verify.NewPolicy()
_, err := verify.VerifyArtifact(artifactPath, signature, policy)
return err
}Temporal:长事务与分布式流转的救星
// 工作流定义示例
func RefundWorkflow(ctx workflow.Context, transferID string) error {
policy := workflow.RetryPolicy{
InitialInterval: time.Second,
MaximumAttempts: 5,
}
ao := workflow.ActivityOptions{
StartToCloseTimeout: 10 * time.Second,
RetryPolicy: &policy,
}
ctx = workflow.WithActivityOptions(ctx, ao)
return workflow.ExecuteActivity(ctx, ExecuteRefund, transferID).Get(ctx, nil)
}
总结
Victoria是一款专业的硬盘诊断、测试和修复工具,由俄罗斯开发者Sergey Kazansky开发。它能对HDD机械硬盘、SSD固态硬盘、甚至NVMe、SAS/SCSI等各种存储设备进行全面检测。 如果你需要检测硬盘健康状况、修复坏道、或者测试存储设备性能,那Victoria绝对是你的首选工具。 这款软件在数据恢复和硬件维护领域有着极高的声誉,因为它不仅功能强大,而且是完全免费的。对于经常处理硬盘问题、购买二手硬盘、或者需要维护服务器的人来说,Victoria能帮你避免数据丢失的风险。 Victoria主要针对Windows平台,支持多种语言界面。下面这个表格帮你了解Victoria与其他硬盘工具的区别: 截止到发文,Victoria 的最新版本是 5.37,也是目前最稳定的版本。下面我就手把手教你如何下载和安装它。 Victoria安装包(官网中文版)下载地址: Victoria不需要复杂的安装过程,解压即用,这大大降低了使用门槛。以Windows系统为例: 2)双击运行Victoria.exe: 3)如果需要创建桌面快捷方式,可以右键点击Victoria.exe,选择"发送到"→"桌面快捷方式"。 打开Victoria后,主界面分为几个主要区域。最上面是菜单栏,左侧是硬盘列表,右侧是功能选项卡。 首先在硬盘列表中选择你要检测的硬盘。Victoria支持检测所有连接到电脑的存储设备,包括内置硬盘、外置硬盘、U盘等。 选择硬盘后,点击"测试"选项卡,这里有几个关键功能:"读取"测试可以检测硬盘的读取速度,"写入"测试可以检测写入速度,"擦除"功能可以安全擦除硬盘数据。 在"S.M.A.R.T."选项卡里,你可以查看硬盘的健康状态。S.M.A.R.T.是硬盘自我监测、分析和报告技术,能提前预警硬盘可能出现的故障。 除了基础检测,Victoria还有一些高级功能值得一试。在"测试"选项卡里,选择"读取"模式,然后点击"Scan开始",Victoria会对硬盘进行全面扫描。 扫描过程中,你会看到不同颜色的方块:绿色表示正常区域,橙色表示读取较慢的区域,红色表示坏道。如果发现坏道,Victoria可以尝试修复。 修复坏道有两种方法:一种是"重映射",将坏道标记为不可用,用备用扇区替换;另一种是"擦除",尝试强制写入数据来恢复坏道。 对于NVMe固态硬盘,Victoria 5.37版本新增了专门的支持。在"NVMe"选项卡里,你可以查看NVMe硬盘的详细信息,包括温度、健康状态、剩余寿命等。 Victoria还支持SAS/SCSI接口的硬盘,这在服务器维护中特别有用。最新版本增加了对SAS/SCSI硬盘的完整支持,包括温度监控、启停控制等功能。 Victoria检测不到我的硬盘怎么办?首先确保硬盘已正确连接,然后在Victoria里点击"刷新"按钮。如果还是检测不到,可能是硬盘接口驱动问题,可以尝试更新主板芯片组驱动。 扫描过程中程序卡住了怎么办?Victoria扫描大型硬盘可能需要很长时间,特别是全盘扫描。如果程序完全无响应,可以尝试停止扫描,然后重新开始。建议先进行快速扫描,了解硬盘大致状况。 修复坏道会丢失数据吗?是的,修复坏道的过程可能会破坏该区域的数据。所以在修复前,一定要先备份重要数据。如果硬盘上有重要文件,建议先尝试恢复数据,再考虑修复。 Victoria支持哪些操作系统?Victoria主要支持Windows系统,从Windows XP到Windows 11都能正常运行。 Victoria是一款功能强大、完全免费的硬盘检测和修复工具,无论是普通用户还是专业技术人员都能从中受益。它能帮你全面检测硬盘健康状况,修复坏道,测试性能,避免数据丢失风险。 如果你经常处理硬盘相关问题,或者需要购买二手硬盘,我强烈建议你下载Victoria试试。它的便携特性让你无需安装就能使用,强大的功能足以应对大多数硬盘问题。相信用过之后你也会像我一样,把它列为硬盘维护的必备工具。
Victoria下载
https://pan.quark.cn/s/995d2ff26df3
https://pan.xunlei.com/s/VOqQPNTEVqBVUEQP4rgk58EkA1?pwd=e7pu#Victoria安装
1)下载Victoria的ZIP压缩包,解压到任意文件夹。建议解压到D盘或其他非系统盘。进入解压后的文件夹,找到"Victoria.exe"主程序文件。

Victoria基础使用



Victoria常见使用问题
Victoria总结
Matrix 首页推荐
Matrix 是少数派的写作社区,我们主张分享真实的产品体验,有实用价值的经验与思考。我们会不定期挑选 Matrix 最优质的文章,展示来自用户的最真实的体验和观点。
文章代表作者个人观点,少数派仅对标题和排版略作修改。
换新显示器或者新笔记本之后,验屏几乎是每个数码爱好者的保留节目。
回想一下以前的做法,通常是关灯拉上窗帘,调出纯黑背景看四角有没有漏光;然后再去各大网站搜刮红绿蓝纯色图,全屏来回切换着死盯有没有坏点。加上我现在日常在 Mac 和 Windows 之间双修,有时候换个设备又要重新找一遍测试资源。网页端好用的检测工具不多,有些满屏都是广告,有些界面极其简陋,用起来毫无体验可言。如果是电视验屏,甚至还得提前拿 U 盘拷好测试视频。
折腾了几次之后,我决定自己动手填坑,把所有屏幕测试项整合在一起,做了一个纯浏览器端的验屏工具:视觉族。
作为一个独立开发者,我其实不太喜欢那些冷冰冰、毫无美感的传统硬件测试页面。
视觉族的界面设计并没有走那种硬核极客或者赛博朋克风,而是采用了一套充满温度的奶白色调。配合圆角元素和规整的便当盒布局,我希望它首先是一个让人看着舒服的网页。很多数码玩家本身对审美就有要求,我希望通过这种干净、微透的视觉语言,把原本枯燥的硬件排查过程变得有亲和力一些。
大部分工具类产品容易犯的毛病是功能入口藏得很深。视觉族的首页设计得非常克制,那就是把大家用得最高频的「纯色验屏」直接作为默认状态。

你不需要去层层菜单里找入口,打开网页,按下键盘的 F 键进入全屏,检测就已经开始了。配合方向键快速切换纯色背景,几秒钟就能排查完坏点、亮点和暗点,这也是我自己验屏时最顺手的方式。
很多时候屏幕没有硬伤,但看着就是不舒服,总觉得偏冷或者偏暖。为此我在色彩校准模块加入了更直观的参考标准。

大家可以直接对照 D50 印刷级到 D65 标准中性白的参考色块,配合白平衡对照卡,方便快速调整显示器的 OSD 设置,直至肉眼感观达到最佳状态。
另外,考虑到现在 OLED 面板越来越普及,烧屏和残影成了很多人的心病。

所以我在检测模块里加入了针对性的排查工具,包括纯色轮播、色条滑动和棋盘反转等模式,你可以自己控制播放速度,用来检查屏幕是否存在不可逆的衰变或者图像残留。
现在的显示设备几乎普及了高刷,但一块静态看起来完美的屏幕,动起来可能就会露馅。

在拖影测试模块,屏幕上会有不同速度的色块移动,并提供黑底、灰底、白底等不同对比度环境。你可以很容易地观察方块后方是否有拖尾或者光晕,以此来评估显示器的真实响应速度,这对于调校电竞显示器的 OD 加速档位非常有帮助。
至于刷新率,很多设备标称 144Hz 甚至更高,但实际输出往往有水分。

这里的刷新率模块不仅仅显示当前帧率,还引入了帧时间波动的实时图表,最高、最低、平均帧率一目了然。到底是不是屏幕在稳定输出,还是系统卡顿掉帧,看图表走势就能马上判断。
前面提到的几项核心功能,其实只是视觉族的冰山一角。对于有更深层次或者特定需求的硬核玩家,我在「更多」页面里,准备了一个完备的工具箱。

这里涵盖了 20 多项细分测试:从硬核的 HDR 检测、PWM 频闪、Gamma 曲线,到非常实用的 PPI 计算器、触控检测和分辨率查询。所有的功能卡片都规整地排列着,需要什么直接点开就行。
但我最想和大家分享的,其实是页面底部的「验机专题指南」。

在做这个网站的过程中我发现,很多数码小白面临的最大阻碍并不是「找不到测试工具」,而是「我根本不知道这台新设备应该测哪些项目」。
所以,我没有选择把一堆生涩的名词丢给用户,而是按大家最常见的购买场景做了打包。不管你是刚换了一台 OLED 材质的旗舰手机、买了一台打游戏用的高刷笔记本,还是给客厅添置了 Mini-LED 电视,你只需要在指南里点击对应的设备类型,它就会告诉你这块特定的面板最容易出现什么问题,并直接带你进行针对性的测试。工具的意义不仅在于提供功能,更在于降低使用的门槛。
纯网页端工具最大的优势就是跨平台。这个工具从一开始就做好了全设备适配:
其实在开发视觉族之前,我已经作为独立开发者陆续写过包括键盘、鼠标、手柄等在内的一系列硬件在线测试工具,也因此慢慢积累了不少有同样需求的朋友。对我来说,把这些零散、繁琐的硬件诊断需求,用现代 Web 技术重新打磨整理,是一件非常有成就感的事情。
视觉族没有什么高深的技术壁垒,它解决的就是一个很具体的痛点:不用到处找图,不用下载软件,打开网页就能把屏幕检查得明明白白。
如果你最近刚好买了新手机、新显示器或者新电视,不妨顺手存一下这个工具备用,希望它能帮你省下一点折腾的时间:
> 关注 少数派小红书,感受精彩数字生活 🍃
> 实用、好用的 正版软件,少数派为你呈现 🚀


官网 DS4 专家模式,问题:如何只用一刀把四个一模一样的橘子:平均分给四个小朋友
看有人发小红书,我还以为 P 的,没想到自己上去试一下居然是真的
猜测用了贴吧的数据没处理好: https://tieba.baidu.com/p/8116300941
本来应该是下面那一个样子的,不知怎的变成上面那样了,新特性?
设备是一加 ACE5
👤 个人简介
29 岁,7 年开发经验,技术栈不设限( react vue nodejs java 都可),具备丰富的跨端开发经验,有鸿蒙产品 0-1 经验和原生 ios 开发经验也有 RN 开发经验,在日常开发和个人项目中,将 ClaudeCode 、Cursor 、Codex 等 AI 工具融入研发流程,覆盖需求分析、代码生成、问题定位和重构优化等环节,有效提升开发效率。能够快速将想法落地为 MVP ,具备独立从 0 到 1 构建复杂业务系统的能力,并在性能、交互体验和可维护性之间取得平衡。
🚀 项目经历
📱 Remy App (鸿蒙原生应用)
最近一家公司做的产品是 C 端的鸿蒙原生应用 Remy App ,目前用户量百万,负责了大部分功能的开发,相关链接:
[ HDC2025 华为开发者大会 - Remy 3D 空间记忆 App 全球发布]
https://www.bilibili.com/video/BV1QCKPzcEQ2/?share_source=copy_web&vd_source=e96f18a0e4ab0a8a92fbcc6a79b8f69a
🧪 个人项目
失业期间 自己 AI Coding 了一个小产品,手帐式周历界面,主要是看到好的设计 UI 图,不知道怎么描述。让 LLM 来生成 5-10 关键词,再用这些关键词喂给大模型帮我生成对应的界面或者组件
🔗 相关链接
在线简历(有过往项目截图): https://resume.xiangshu233.cn
Roo code 宣布 5 月中旬结束官方的支持。官方转向做 Roomote ,后续的 Roo code 可能交由社区维护或者直接关停。有啥平替推荐吗?
Hooks刚出的时候,大家都觉得是“黑魔法”:一个函数组件,居然能记住自己的状态?还能模拟生命周期?很多人用了很久,却不知道原理。导致遇到奇怪的问题(比如无限循环、状态不更新)时,只能靠试。 今天我们不背源码,用最简单的代码模拟React Hooks的核心机制。学完你不仅能解释“为什么不能在条件语句里调用Hook”,还能自己手写一个迷你 类组件有 每个函数组件对应一个“虚拟节点”(Fiber节点),它上面有个 我们先不管React的实现细节,用纯JS模拟一个最简单的 关键点: 假设第一次渲染时,你在 React团队之所以这样设计,是为了在保证性能的同时简化实现。用数组/链表存储,比用Map key查找快得多。 React实际用的是单向链表,每个Hook节点有 每次渲染,React根据上次的链表和本次调用的顺序,把新状态赋给对应的Hook。 跟 它们也存储在Hook链表里,只是 自定义Hook只是调用了内置Hook的普通函数,它不会新增链表节点,只是把调用的内置Hook顺序归入组件的链表。所以自定义Hook的规则也遵循“只在顶层调用”。 理解了这个原理,你再也不会害怕Hooks的诡异报错。下次同事问“为什么不能if里写useState”,你可以拍拍他肩膀:“因为React用数组存状态,你跳过一个,后面的全对不上了。”前言
useState。一、函数组件为啥需要Hooks?
this.state和生命周期,但函数组件每次渲染都会重新执行,里面的变量都会重新创建。那怎么保存状态?React用了闭包 + 链表。memoizedState属性,用来保存该组件的Hooks链表。二、模拟React Hooks:手写迷你
useStateuseState。let hooks = null; // 当前组件的hooks链表
let currentHook = 0; // 当前正在执行的hook索引
function useState(initialValue) {
// 如果是第一次渲染,初始化这个hook的值
if (!hooks[currentHook]) {
hooks[currentHook] = { state: initialValue };
}
const hook = hooks[currentHook];
const setState = (newValue) => {
hook.state = newValue;
scheduleRender(); // 触发重新渲染(伪代码)
};
currentHook++;
return [hook.state, setState];
}
function render(component) {
hooks = []; // 重置hooks链表
currentHook = 0; // 重置索引
const vdom = component(); // 执行组件,收集hooks
// 渲染vdom...
}hooks数组按调用顺序存储每个useState的状态。currentHook重置为0,依次取出对应的状态。if或循环里调用的根本原因。三、为什么顺序必须不变?
if里调用了useState,第二次渲染时条件不成立,那个Hook被跳过了。那么后续Hook的对应关系就会错位:本来应该取第二个状态,结果取了第三个的。React就会报错。// 错误示例
function MyComponent({ flag }) {
if (flag) {
const [a, setA] = useState(1); // 第一次有,第二次没有
}
const [b, setB] = useState(2); // 第一次是第二个hook,第二次变成了第一个
}四、多个Hook是怎么串联的?
next指针指向下一个。这样即使组件不渲染,链表也保留在Fiber节点上。// 简化的链表结构
const hook = {
memoizedState: null, // 当前状态
next: null, // 下一个hook
// 还有queue等用于更新的字段
};五、
useEffect的原理:等渲染完再执行useEffect的回调不会阻塞浏览器绘制,它是在渲染提交到屏幕之后异步执行的。它的存储也类似,但多了清除函数的管理。function useEffect(callback, deps) {
const hook = hooks[currentHook];
const prevDeps = hook?.deps;
const hasChanged = !prevDeps || deps.some((dep, i) => dep !== prevDeps[i]);
if (hasChanged) {
// 将callback放到待执行队列,等渲染完成后执行
scheduleEffect(callback);
}
hook.deps = deps;
currentHook++;
}六、为什么不能在循环里调用Hook?
if同理:循环次数变了,Hook的顺序就变了。即使你保证循环次数不变,也没法阻止以后的维护者改代码。所以React直接禁止这种写法。七、
useCallback和useMemo本质是缓存memoizedState里存的是缓存的值和依赖。function useMemo(factory, deps) {
const hook = hooks[currentHook];
const prevDeps = hook?.deps;
const hasChanged = !prevDeps || deps.some((d, i) => d !== prevDeps[i]);
if (hasChanged) {
hook.value = factory();
hook.deps = deps;
}
currentHook++;
return hook.value;
}八、自定义Hook为什么没有特殊待遇?
九、总结:Hooks的“交通规则”
useState返回的setter之所以能拿到最新值,是因为闭包引用了Hook对象,而Hook对象上的状态会被更新。
AnLink是一款免费的Android手机投屏和控制软件,通过USB或Wi-Fi连接,延迟低,画面清晰,操作流畅,能让你的安卓手机屏幕实时显示在电脑上,并且可以用鼠标键盘直接操作手机。 这款软件在手机投屏领域有着不错的口碑,因为它不仅功能实用,而且是完全免费的。对于那些需要在电脑上操作手机、录制手机屏幕、或者进行手机应用测试的人来说,AnLink能大大提高工作效率。 AnLink支持Windows和macOS系统,兼容大多数Android手机。下面这个表格帮你了解它与同类工具的区别: 截止到发文,AnLink的最新版本提供了丰富的功能,包括文件传输、屏幕录制、键盘映射等。下面我就手把手教你如何下载和安装这个实用的投屏工具。 AnLink安装包(官网正版)下载地址: AnLink的安装非常简单,下载AnLink安装压缩包,解压后得到“AnLinkSetup.exe”安装程序,双击运行: 2)勾选“Custom installation”,选择安装位置,建议安装到D盘或其他非系统盘,避免占用C盘空间: 3)等待安装完成,这个过程通常很快。 4) 界面默认是英文的,可以参考下图将其设置为中文: 设置好中文后,重新启动才会生效: 首先确保你的安卓手机和电脑在同一个Wi-Fi网络下,或者用USB数据线连接。 在手机上,需要开启"开发者选项"和"USB调试"功能。不同手机开启方法略有不同,一般在"关于手机"里连续点击"版本号"7次,就能开启开发者选项。可以在 AnLink 里挑选你自己的手机型号: 相应地 AnLink 会给出详尽的连接操作步骤: AnLink软件的界面简洁明了。如果是USB连接,直接用数据线连接手机和电脑,AnLink会自动检测并连接。如果是Wi-Fi连接,需要在手机上安装AnLink的配套应用,然后在电脑上输入手机上显示的连接码。 经实际测试,我的手机是 ViVo 的,但开发者选项在系统设置里,和 AnLink 提示的不同,所以如果大家根据图示没有找到,那就自己去别的设置里找找。下图是我采用 USB 成功连接的截图: 连接成功后,你的手机屏幕就会显示在电脑上。你可以用鼠标点击手机屏幕上的任何位置,用键盘输入文字,就像直接操作手机一样。 结合我连接成功的截图,在AnLink的工具栏上,你可以找到"文件传输"功能,这个功能可以在电脑和手机之间快速传输文件,比用数据线更方便。 "屏幕录制"功能可以录制手机屏幕的操作过程,适合制作教程视频或记录游戏精彩时刻。录制质量可以调整,支持多种分辨率和帧率。 "键盘映射"功能是游戏玩家的最爱。你可以将手机游戏的操作按键映射到电脑键盘上,用键盘玩手机游戏,操作更精准。 "多设备管理"功能可以同时连接多台安卓设备,在电脑上切换管理,适合应用测试人员或数码爱好者。 "屏幕截图"功能可以快速截取手机屏幕,保存到电脑上。截图质量高,支持多种格式。 AnLink连接不上手机怎么办?首先检查USB数据线是否正常,或者Wi-Fi网络是否稳定。然后确保手机已开启USB调试模式。有些手机需要选择"文件传输"模式而不是仅充电。 投屏画面有延迟怎么办?USB连接的延迟通常比Wi-Fi低。如果使用Wi-Fi,确保手机和电脑在同一个网络下,并且网络信号良好。关闭其他占用网络的应用程序也能改善延迟。 AnLink支持哪些安卓版本?AnLink支持Android 5.0及以上版本,兼容大多数现代安卓手机。对于较旧的安卓版本,可能部分功能无法使用。 需要root权限吗?AnLink不需要root权限,普通用户就能正常使用所有功能。这大大降低了使用门槛。 AnLink收费吗?AnLink是完全免费的软件,没有功能限制,也没有广告。这是它最大的优势之一。 AnLink是一款功能实用、完全免费的安卓投屏工具,无论是普通用户还是专业人士都能从中受益。它能让你在电脑上方便地操作手机,提高工作和娱乐效率。 如果你经常需要在电脑上操作手机,或者想用键鼠玩手机游戏,我强烈建议你下载AnLink试试。它的简单易用和免费特性让它成为投屏工具中的优秀选择。相信用过之后你也会像我一样,把它列为手机投屏的必备工具。
AnLink下载
https://pan.quark.cn/s/a45e7d0c4fa9
https://pan.xunlei.com/s/VOqtPMDl6npYgMejZ6ekOJaxA1?pwd=p2ct#AnLink安装





AnLink基础使用



AnLink高级用法
AnLink常见使用问题
AnLink总结
在工业自动化系统中,调节阀作为流体控制的核心执行元件,其性能直接影响生产过程的稳定性与调节精度。阀门选型需要综合考虑工况条件、介质特性及控制要求,而调节阀的流量特性分析则关乎系统设计的合理性。美国米勒(MILLER)阀门推出的EC10T电动套筒调节阀,基于平衡式套筒结构设计,为用户在高压差、大流量及严苛工况下提供了一种工程选型方案。 美国MILLER阀门创立于1984年,总部位于美国特拉华州,初期专注于石油炼化阀门维修服务,逐步发展为集自主研发、设计与制造于一体的专业阀门企业,目前已服务全球120多个国家和地区。米勒在中国深圳设有全资子公司——米勒阀门(广东)有限公司,提供本土化生产、技术支持与快速响应服务,建立覆盖全国的72小时应急服务网络。 EC10T电动套筒调节阀是米勒调节阀系列中的代表性产品。该产品由电动执行机构和直通低流阻平衡型套筒阀两部分组成,电动执行机构为电子式一体化结构,内置伺服放大器,输入4-20mA DC或1-5V DC等控制信号及电源即可控制阀门开度,实现对压力、流量、液位、温度等工艺参数的调节。 平衡式套筒结构。 EC10T采用套筒导向平衡式阀芯结构,阀芯为圆柱型,由套筒内圆导向和顶导向协同定位,阀杆上不平衡力较小。相比传统的单座调节阀,平衡式结构允许阀门在更高压差工况下稳定工作,同时所需执行机构推力较小,有助于降低系统整体能耗。套筒设计还有助于抑制气蚀、振动和噪音。 模块化阀盖设计。 产品提供标准型、伸长型、低温型、波纹管密封型及保温夹套型等多种阀盖形式,以适应不同介质温度和应用场景的密封要求。其中波纹管密封型适用于不允许外泄漏的严格场合,阀杆移动过程中可形成双重密封保障。 多种密封材质组合。 EC10T提供聚四氟乙烯(PTFE)、金属硬密封、硬质合金等多种密封材质选项。当介质温度低于200℃时可选用PTFE填料,温度高于200℃时可选用石墨填料。调节切断型采用软密封结构阀芯时,泄漏等级可达VI级标准。 电动驱动与控制精度。 产品采用电动执行机构,无需气源即可运行,控制精度可达±0.1%。电动执行机构支持4-20mA输入信号和4-20mA输出信号,方便接入各类工业自动化控制系统。防护等级为IP65,隔爆等级可选ExdⅡBT4或ExdⅡBT6,适用于具有一定的粉尘或气体防爆要求的工业环境。 调节阀的流量特性,是指在阀两端压差保持恒定的条件下,介质流经调节阀的相对流量与阀门开度之间的关系。流量特性分析是阀门选型的重要依据,直接影响系统调节品质和运行效率。 EC10T套筒调节阀通过套筒上的节流窗口形状来控制流量特性,其节流窗口型线依据流体力学和流量特性理论进行参数化设计。该产品可提供两种主要的流量特性: 线性特性。 流量与阀门开度近似呈线性关系,即阀门开度每增加一个单位,流量相应增加一个固定量值。线性特性适用于压差变化较小的场合,以及系统负荷相对稳定的工况。 等百分比特性(对数特性)。 在等百分比特性的调节阀中,阀门开度每变化相同的幅度,所引起的流量变化百分比保持恒定。这意味着在小开度时流量变化较为平缓,大开度时流量变化较为显著。等百分比特性适用于负荷变化幅度大、调节范围较宽的系统,常见于需要兼顾小流量精密调节和大流量快速响应的场合。 阀塞上设有上、下方均压孔,有助于降低不平衡力,维持阀门操作稳定;额定流量系数相较于传统设计可增大30%,固有可调比为50,在流量调节范围内提供更多的调节分段。 套筒调节阀的流量特性还会受到流体性质、阀门尺寸、阀前后压降等因素的影响。高粘度流体可能导致流量特性曲线偏移,气体介质受温度、压力变化的影响更为显著。在不同工况条件下,套筒调节阀原结构的流量特性曲线可能存在斜率偏差,需经过结构优化使其符合等百分比特性的设计要求。 EC10T电动套筒调节阀可适配多种工业场景下的流体控制需求。 石油化工领域。 适用于石油、天然气、炼油等工艺系统中的流量和压力控制。阀体可选Inconel、Monel、Hastelloy等特种合金材质,可应对含腐蚀性介质的工况。 电力与热力系统。 可用于锅炉给水调节、蒸汽压力控制等场景。产品支持中温型配置(散热片式,230℃~450℃),适用于蒸汽介质的自动调节。 冶金与轻工行业。 在冶金、轻纺、造纸等工业部门中,电动套筒调节阀可用于工艺参数的自动化调节和远程控制。 暖通空调与制药行业。 可用于空调系统中的冷热水流量调节。对于洁净要求较高的制药行业,可选配卫生级材质和相应的密封结构。 此外,EC10T还支持多种工况扩展配置。低温型阀盖可满足-196℃的深冷工况要求;保温夹套型适用于需伴热保温的易结晶介质;波纹管密封型用于挥发性或有毒介质的泄漏防控场合。 为满足不同自动化控制系统的配套需求,EC10T可配置多种阀门附件,包括:定位器(支持远程调节精度优化)、空气过滤减压器(保证气源信号清洁稳定)、保位阀(故障时保持阀位)、行程开关(提供开关到位信号反馈)、阀位传送器(实时传输阀位数值)和手轮装置(便于现场手动操作)。 在选型过程中需关注以下方面:确定公称压力时需综合考虑温度、压力、材质三个条件;泄漏量应满足工艺要求;工作压差应小于阀门允许压差;介质温度应在阀门工作温度范围内;根据介质特性评估腐蚀和冲蚀影响。 MILLER阀门已取得多项国际认证: 在服务保障方面,米勒构建了全球化制造网络,设立四大核心制造基地(美国加州、德国威斯巴登、马来西亚雪兰莪、中国深圳),建立覆盖全国的服务网络。米勒阀门(广东)有限公司作为中国全资子公司,为用户提供技术支持与售后保障。一、产品概述
二、设计特点
三、流量特性分析
四、技术规格
参数项 规格 产品型号 EC10T 公称通径 NPS 1½"~24"(DN40~DN600) 公称压力 Class300~Class600(PN50~PN100) 阀体材质 碳钢、304不锈钢、316不锈钢、Inconel、Monel、Hastelloy、Ti等 密封材质 聚四氟乙烯、金属硬密封、硬质合金 泄漏等级 ANSI Ⅳ级、Ⅴ级 介质温度 -196℃~230℃ 连接方式 卡套、螺纹、焊接、对夹、法兰 阀芯形式 套筒调节阀 控制精度 ±0.1% 供电电压 24V、110V、220V、380V 输入信号 4-20mA或1-5V DC 输出信号 4-20mA DC 防护等级 IP65 隔爆等级 ExdⅡBT4、ExdⅡBT6 环境温度 -25~+70℃、-40~+70℃ 五、应用领域
六、产品附件与选型配置
七、品牌背景与服务网络
说明:本文基于米勒EC10T产品的公开技术资料编制。阀门选型应以实际工况参数为依据,建议在正式选型前咨询厂商技术部门确认适用性。
之前在 V2EX 发过几次帖子分享我在开发开源项目 Chorus,一个给 Claude Code 用的 Harness 时的经验和教训。简单说就是让 Agent 不只是写代码,而是自己管整个项目:领需求、出方案、拆任务、写代码、提交审查,从 Idea 到交付走完一条流水线。中间有独立的 Reviewer Agent 自动审方案和代码,审不过打回重做,不用你盯着,把我们从无限的 Agent Review 地狱里解救出来。
上次发帖之后老哥们反应挺热烈,Issues 里提了不少实际问题。有说装 Docker 门槛太高的,有说生成的文档导不出来没法给客户看的,有说 Onboarding 走一半卡住了的。我挨个看了,这次 v0.6.6 基本都回应了。
最大的变化现在一行命令就能启动:
npx @chorus-aidlc/chorus
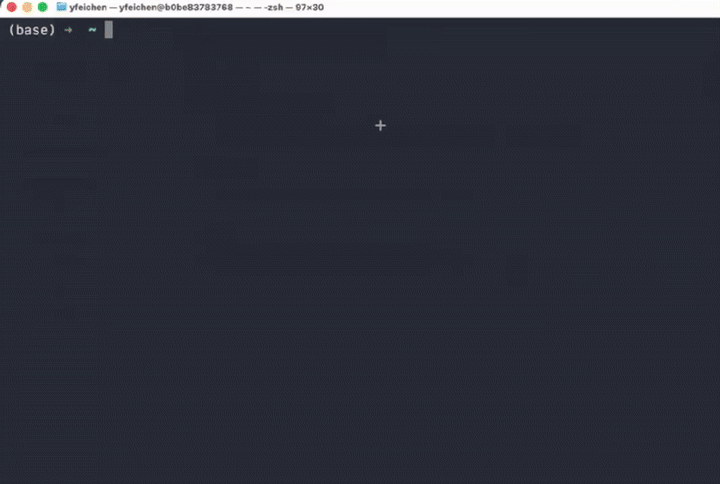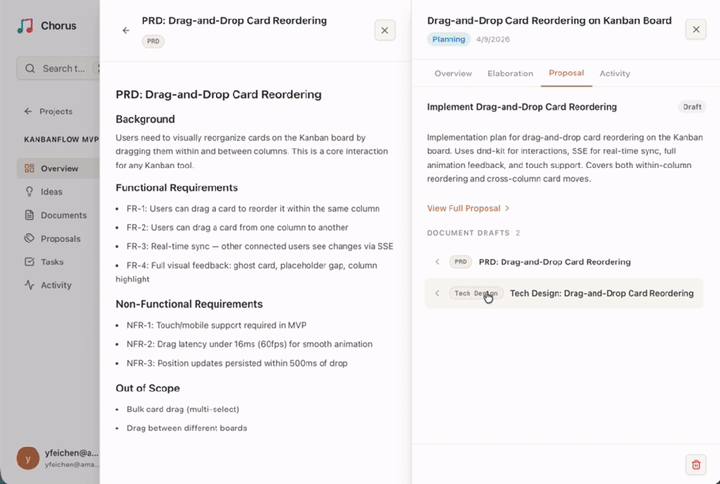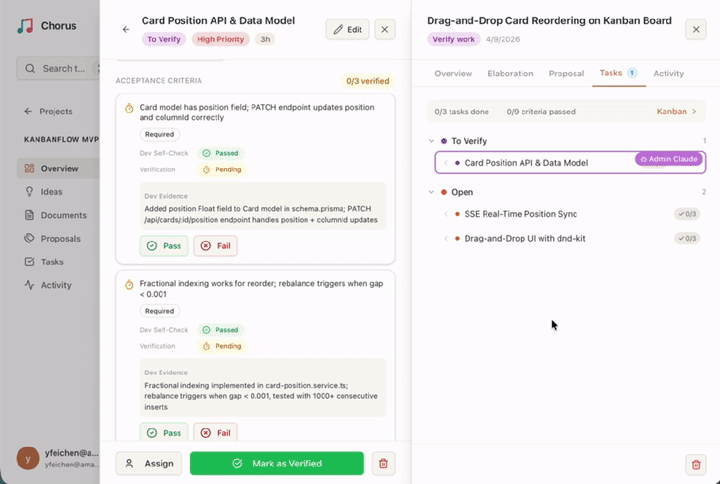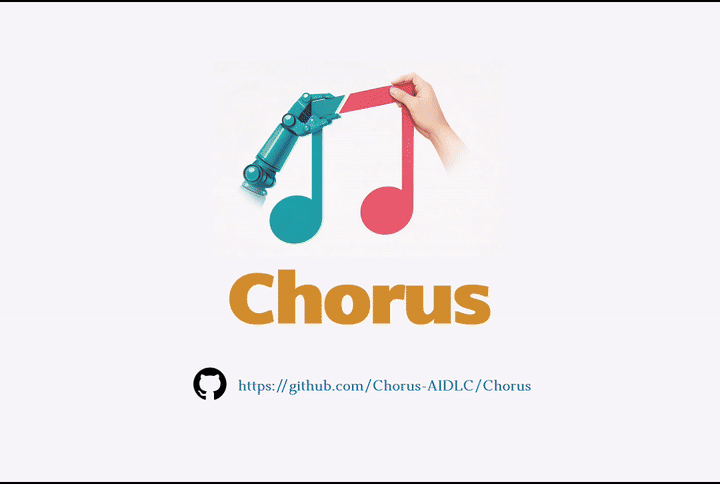
跑完打开 http://localhost:8637 配合 Claude Code 插件就能用,不用配数据库,不用写 compose 文件。全栈纯 JS 实现,macOS 和 Linux 都能直接跑。
另外根据 Issue 里的反馈加了文档导出,Markdown 、PDF 、Word 三种格式。有老哥说项目交付要给客户看文档,之前只能在 Chorus 里看确实不方便,现在 Proposal 草稿阶段就能导出预览。
其他比如 Proposal 审批了发现方向不对可以撤回重来,Onboarding 不会再卡死,Agent 上线一次调用拿到所有状态接着干活,就不展开了。
详细的看博客: https://chorus-ai.dev/zh/blog/chorus-v0.6.6-release/
GitHub: https://github.com/Chorus-AIDLC/Chorus
感谢之前提 Issue 和反馈的各位,有问题继续拍砖。我的目标是让 Claude Code 自己推项目给我们省点力。
已经 26 了,还从来没谈过 呜呜呜。
好想色色。
我喜欢 coding、游戏、 极限运动(滑板 轮滑 小轮车 滑雪)、摩托车、养小鸟。
怎么就是一个女朋友都没有呢!!!
教教我
救救我
最近给 Casdoor 加了一块新能力,专门针对 LLM/AI Agent 场景的安全防护,想在这里分享一下,顺便听听大家的意见。
自从 MCP 协议流行起来之后,越来越多的 AI Agent 开始直接调用外部工具和 API 。但这带来了一个问题:Agent 在干什么,你根本看不见。它调了哪些工具、传了什么参数、有没有越权操作——全是黑盒。
Casdoor 本身已经支持 MCP Server 和 OAuth 2.1 鉴权,解决了「谁能调」的问题。但「调了什么」这一层一直缺个方案。
OpenClaw 是一个开源的自主 AI agent 平台,运行在用户本地,通过 WhatsApp/Telegram 等聊天应用控制,能真实执行任务(管文件、控制浏览器、发邮件等)。Casdoor 做的是给它加安全护栏。Casdoor 现在可以作为 OpenClaw 的接收后端,把每一条信号存成 Entry 记录,并在 UI 里渲染成结构化的 span 树。
整个链路:OpenClaw Agent → OTLP over HTTP → Casdoor → Entries 页面
第一步:在 Casdoor 创建 Log Provider
Providers → Add ,Category 选 Log,Type 选 Agent (OpenClaw),Host 填 OpenClaw agent 的 IP (留空则允许任意 IP )。
第二步:配置 OpenClaw
exporters:
otlphttp:
endpoint: https://your-casdoor.com
headers:
Content-Type: application/x-protobuf
保存后数据就开始流入,在 Casdoor 的 Entries 页面可以直接看 trace 树。
Casdoor 的 MCP 鉴权( OAuth 2.1 + PKCE + 细粒度 scope )管的是「谁有权调哪个工具」。OpenClaw 管的是「实际调了什么」。两者配合,覆盖 AI Agent 的事前授权和事后审计。
相关文档:
目前这块功能还比较新,欢迎有 AI Agent 相关项目的同学来试用,有问题直接开 Issue 或者在这里留言。
我手上有些 SAS 碟一直没有用。加上之前是用 HPE SmartArry P420 组成 RAID 6 ,这些阵列的 host 机器坏掉了,一直没有修复。
这次想买入那些被淘汰的服务器,一个来做 JBOD ,外接出 SFF 接口,再接入一台二手的服务器的 RAID 卡,拿来组成阵列。
操作系统我是要自己装 Linux (估计是 Debian),不需要用那些成品 nas 系统。
目前对于做 RAID 卡的那台机器,是打算买 AMD 的搭配 DDR4 的机型,就是 JBOD 好像市面上二手的不太多?
比较多的是拿旧服务器机箱改的,搭配不知道哪里的背板,这种机器大概 1000 块好像就能搞定。只是不知道是否可靠?
市面上有比较便宜的二手 JBOD 也请推荐一下。谢谢
我的硬盘都是 3.5 英寸的,就阵列有 SATA 盘,新的硬盘都是 SAS 的。
这是原视频,因为基本没有效的声音信息,就转 gif 了

(标题:能不能保持安全距离,害人害己啊)
就这一个 7s 的视频,不提供其他任何信息的情况下,各位可以猜一下播放量
一些数据截图


这个视频给我的频道带来了太多噪声,偏离频道初衷,虽然流量大,但是还是先下架降温了
就像 GPT 说的
最后一句话
流量不是资产,匹配的流量才是。
你现在这波,更像是:
👉 “把一群不对的人请进了家里,还很吵”
你不需要对他们负责。
这个视频后续我甚至做了一个新的视频来解释前因后果,但是基本无济于事,就像看不懂中文一样
任何外语建议都行。
该系统基于微擎系统交付。微擎是一款由宿州市微擎云计算有限公司研发的免费开源的公众号、小程序管理系统,基于目前流行的WEB2.0架构(PHP+MySQL),拥有成熟、稳定的技术解决方案。微擎系统源码透明、开放,所有数据及资源都架设在用户自己的服务器上,保证了系统的独立性、安全性与可控性。作为一个开放的应用生态系统,微擎连接了海量的第三方开发者与用户,其应用市场提供了超过2600款插件,覆盖零售、教育等40余个行业场景,为像“在线报名缴费”这样的垂直应用提供了强大的底层支撑和扩展可能。 成熟专业的报名缴费流程 开源性与易于扩展 持续迭代与更新 微擎生态集成 教育机构 行业价值: 提升运营效率与管理水平 通过数字化的报名缴费流程,将传统线下或半人工的报名方式标准化、自动化,极大地减少了信息登记、费用核对、通知发放等环节的人力成本与出错率,使管理更加精细高效。 优化用户体验 为参与者提供了7x24小时在线的报名入口,支持通过微信小程序等便捷方式快速完成报名和支付,流程简洁,体验流畅,提升了服务满意度。 助力机构数字化转型 该系统是机构实现服务线上化、管理数字化的重要工具。借助微擎系统快速搭建和部署应用的能力,机构能够以较低的成本引入专业的报名管理系统,加速其整体数字化转型进程。 创造可持续的商业生态 对于系统购买者而言,不仅可以自用,还可以利用微擎平台的多用户和分权功能,将系统作为一项服务提供给其他有需求的机构,从而构建自己的小型SaaS平台或代理体系,拓展业务渠道。 问答环节 问:该系统主要适用于哪些类型的机构? 问:系统的交付方式和源码情况如何? 问:除了直接使用,购买者还能如何利用这个系统?
“在线报名缴费”系统是部署于微擎平台的一款成熟、专业的数字化解决方案,专为学校、事业单位等机构设计,用于处理各类活动的报名与缴费流程1。该系统自2016年3月发布以来,凭借其稳定性和专业性,获得了行业内人士的广泛赞誉。
“在线报名缴费”系统核心功能是为客户提供报名全流程的综合解决方案,其设计注重管理精细、行业特征和用户体验。具体功能亮点包括:
系统为学校、事业单位提供了成熟、专业、安全的报名缴费解决方案,能够有效解决机构在组织活动、考试、会议时面临的繁琐事宜。
该系统基于PHP+MYSQL进行开源性开发,易于扩展。这得益于微擎系统本身百分百开源、支持二次开发的特性,官方提供开发文档,开发者可以根据具体需求进行定制化功能拓展。
开发团队在15年的发展过程中,认真吸取客户建议与经验,结合主流需求,承诺将一如既往地提供版本与系统升级工作1。系统后期计划增加自定义表单、个性化模板等多个功能,以满足更个性化的需求。
作为微擎应用市场的一员,该系统能够无缝接入微擎的整个生态系统。购买者可以利用微擎系统的分权功能,搭建自己的服务平台,无限发展代理或用户,并进行精细化的权限分配,从而实现商业运营。同时,系统支持微信小程序,用户无需代码操作即可一键生成报名缴费小程序,便捷触达微信用户。
适用场景:
该系统主要适用于所有需要组织在线报名并收取费用的场景,特别是:
学校的课程报名、课外活动报名、考试报名等。
事业单位与政府机关
会议报名、培训报名、赛事活动报名等。
各类社会团体与商业机构
研讨会、展会、线下体验活动等的报名与收费。
问:这个“在线报名缴费”系统是基于什么平台或系统运行的?
答:该系统基于微擎系统交付。微擎是一款基于PHP开发的开源应用生态系统,主要用于快速搭建微信公众号、小程序等应用,同时支持Web系统开发与部署,为各类应用提供稳定高效的技术支撑。
答:主要适用于学校、事业单位等需要经常组织各类活动、考试、培训并进行收费的机构,为其提供成熟、专业、安全的报名缴费解决方案。
答:该商品在微擎应用市场的标注为“在线交付”,源码状态为“已加密”。但根据产品介绍,其基于PHP+MYSQL进行开源性开发,易于扩展。需要注意的是,微擎核心系统本身是开源透明的,但上架的应用市场插件可能根据开发者策略进行不同程度的加密。
答:得益于微擎系统的多用户和分权功能,购买者不仅可以自己使用,还可以搭建一个平台,邀请其他机构作为子用户入驻,并为他们分配使用权限,从而将这套报名缴费系统作为一项服务进行运营和销售,实现商业价值的延伸。








