摘要
检索增强生成(RAG)可以有效将大语言模型的输出与外部知识对齐,但它并不会建模运行时上下文,例如用户身份、会话状态或业务约束,而这些正是企业应用所依赖的关键要素。
上下文增强生成(CAG)是在现有 RAG 流程之上的扩展,通过引入一个显式的上下文管理器,在不需要重新训练模型或改动检索基础设施的前提下,对运行时上下文进行组装和规范化。
在基于 Java 的系统中,这种模式可以通过 Spring Boot 清晰地实现:在现有的检索器和 LLM 服务之上增加一层上下文编排逻辑,从而保持既有的应用结构和部署方式不变。
将“上下文”视为一等架构要素,有助于提升系统的可追踪性和可复现性,使得在受监管或多租户环境中可以清晰解释 AI 响应的生成过程。
CAG 模式为以文档为中心的 RAG 原型提供了一条渐进式演进路径,使其发展为具备上下文感知能力的企业级 AI 服务,同时保留已有投入和系统稳定性。
检索增强生成(RAG)已经迅速成为企业系统中集成大语言模型的一种基础模式。通过将语义检索与基于提示的生成结合起来,RAG 可以在不重新训练底层模型的情况下,让应用基于领域知识和最新数据生成更可靠的回答。因此,它已广泛应用于知识助手、内部搜索工具以及客户支持系统等生产场景。
随着企业级应用的深入落地,一个反复出现的架构问题逐渐显现:虽然 RAG 能提升事实准确性,但它并不会自动处理企业软件所依赖的运行时上下文,例如用户身份、会话历史、流程状态以及领域约束。这类问题在真实部署中越来越明显,尤其是在受监管或多租户环境中,不同用户和不同情境下,系统必须给出差异化的响应。
因此,很多生产系统并不是替代 RAG,而是在其基础上叠加上下文信息,对检索和生成过程进行扩展。本文将这种实践称为“上下文增强生成”(CAG),并介绍 Java 团队如何基于 Spring Boot 对其进行清晰的结构设计与实现。文章重点放在系统设计和生产落地,而不是模型训练或实验性机器学习流程。
什么是 RAG,以及它在企业系统中的局限
RAG 已成为将大语言模型与企业数据结合的一种实用基础方案。它通过从外部知识库中检索相关文档,并将其注入到模型提示中,使应用能够生成比仅依赖训练数据更准确、更及时的回答。因此,RAG 已被广泛应用于知识助手、内部搜索工具以及面向客户的支持系统。
但在生产环境中,团队逐渐发现,仅靠检索并不能解决 AI 系统嵌入真实业务流程后遇到的诸多问题。尽管 RAG 提升了信息准确性,但它通常将每一次请求视为相对独立的处理单元,并未考虑企业系统所依赖的运行时上下文。
一个典型的 RAG 流程包括三个阶段:检索、增强和生成。在检索阶段,向量数据库或搜索引擎返回与查询语义相关的文档;在增强阶段,这些文档会与用户输入组合;最终将构造好的提示传递给语言模型生成结果。
这种架构在以文档为中心的场景中表现良好,但企业应用往往需要更多上下文信息,而这些信息并不是单纯通过检索就能获得。即使在查询相同的情况下,运行条件不同,合理的回答也可能不同。
例如,回答可能因用户身份和角色的不同而不同,因为信息访问通常受权限控制;也可能依赖会话连续性,即后续问题需要基于前文上下文理解;在很多场景中,领域规则和策略(如合规要求、审批流程或访问控制)也必须参与决策;甚至时间或流程状态也会影响结果,因为在不同阶段,正确答案可能不同。
这些问题本质上并不属于“检索”范畴。即使检索结果完全相关,RAG 系统也无法理解答案适用于谁、在什么条件下应该给出,或企业规则应如何影响输出。
因此,一旦 RAG 从原型走向生产,团队往往会遇到一类典型问题:回答在事实层面正确,但在上下文上不合适,例如忽略用户角色或流程状态;对于类似问题,不同用户或不同会话之间的回答可能不一致;同时,也很难解释或审计某个回答为何产生。随着时间推移,如果仅通过 prompt 逻辑来强行嵌入业务规则,会不断增加复杂度,但无法真正解决架构层面的缺口。
这些局限并不否定 RAG 的价值,而是界定了它的适用范围。RAG 擅长解决“找什么信息”的问题,但并不负责建模企业系统运行所需的上下文。要弥补这一点,需要将“上下文”提升为一等架构要素,而不是简单作为 prompt 的附加信息。
CAG 架构模式的组织方式
当团队逐渐意识到“仅靠检索”无法满足需求时,一种更完整的架构模式开始形成:在应用层显式管理运行时上下文,对 RAG 进行扩展。与其将每个请求视为独立的检索问题,不如在调用语言模型之前,将用户、会话和策略等信号与检索结果一起统一组织起来。
尽管不同组织的术语有所不同,但在大规模企业系统中,“文档检索”和“上下文编排”之间的分层已经逐渐清晰。例如,DoorDash 在其基于大语言模型的客服自动化系统中,就明确区分了检索组件和更高层的上下文模块,后者负责整合骑手状态、流程上下文以及业务约束。类似地,微软在 Copilot 的语义索引中,也强调不仅要基于内容进行检索,还要结合组织上下文、权限以及用户特征来生成响应。
与此同时,在DZone、Meilisearch等工程社区的讨论中,这种方式通常被称为“上下文增强生成(CAG)”,强调生成效果不仅取决于检索到的文档,还取决于“是谁在问、在什么场景下问,以及受到哪些约束”。不过,这类讨论往往停留在概念层面,缺乏一个可以在企业中稳定落地的架构结构。尤其是在 Java 系统中,状态管理、治理能力和可追踪性本身就是一等需求,更需要清晰的实现方式。
本文将 CAG 视为一种架构层面的演进,而不是新的检索技术。实际上,大多数企业系统已经在以非正式的方式使用上下文信息:例如将用户属性拼接到 prompt 中、手动加入对话历史,或通过零散逻辑注入策略文本。CAG 的价值在于将这些做法规范化,使“上下文组装”成为系统中一个明确且可复用的能力。从本质上看,两者的区别可以概括为:RAG 关注“哪些信息相关”,而 CAG 关注“这些信息对谁相关、在什么情境下相关,以及受到哪些约束”。
在具体实现上,CAG 并不会替代检索或生成,而是在其旁边引入一个独立的上下文管理器。这个组件负责在构建 prompt 或调度检索之前,收集并规范化运行时信号,例如用户身份、会话历史和领域策略。
这种设计会带来重要的架构收益。通过将上下文处理集中在一个组件中,系统可以更清晰地实现关注点分离:检索质量、模型行为和上下文影响可以分别分析,从而提升测试性、可审计性以及后续演进能力。
对于企业级 Java 应用而言,这种方式也与既有设计原则天然契合。用户上下文、授权状态以及流程元数据本来就存在于应用层,而不是机器学习基础设施中。CAG 的做法,是将上下文能力保留在业务逻辑附近,由应用架构进行治理,而不依赖具体的 LLM 或向量数据库。
在 CAG 架构下,RAG 的核心组件(检索器、向量存储和 LLM 服务)本身并不发生变化。不同之处在于,请求在进入这些组件之前的准备方式。通过在上游引入上下文管理器,团队可以在保持现有 RAG 投入和运行稳定性的前提下,为 AI 交互引入企业级的上下文能力。
在 Spring Boot 中实现上下文管理器(企业场景)
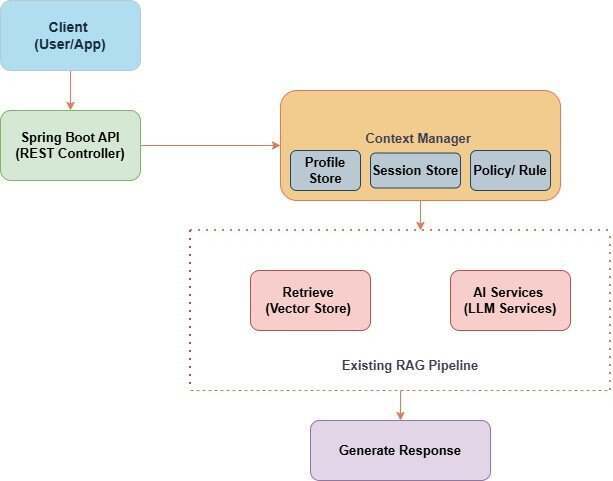
图一:在传统 RAG 流程之上叠加的 CAG 架构
图一展示了在 Spring Boot 应用中,CAG 如何扩展现有的 RAG 流程。虚线区域表示未发生变化的 RAG 组件(检索器和 LLM 服务),而上下文管理器层则在调用 RAG 流程之前,为请求补充用户、会话和策略等上下文信息。
本节说明如何在现有基于 Spring Boot 的 RAG 应用中,通过引入一个轻量级的上下文管理器层来集成 CAG。目标并不是构建完整的演示系统,而是展示企业团队如何在不改变现有检索与生成组件的前提下,为标准 RAG 架构增加显式的上下文处理能力。
基于 Spring 的 RAG 系统通常遵循一种成熟结构:文档先被处理并嵌入向量库,在查询时由检索器将相关内容注入到 prompt 中,再发送给 LLM 生成结果。这种架构在使用 Spring AI 构建的生产系统中较为常见,也可以参考InfoQ 关于 Spring Boot + MongoDB + OpenAI 构建 RAG 应用的文章。本文后续均以这一典型流程作为基础假设。
CAG 的做法并不是修改该流程,而是在其之上增加一层。
企业场景示例
设想一个企业内部的政策助手,供多个部门使用。虽然政策文档是统一的,但具体回答往往需要根据用户角色或部门、当前会话上下文,以及组织内部的信息披露规则进行调整。
传统的 RAG 流程可以检索相关政策并生成回答,但不会显式建模这些运行时因素。因此,即便查询相同,在不同上下文下也可能需要不同答案,而这正是企业系统的常见要求。CAG 通过上下文管理器,在调用既有 RAG 流程之前,将用户、会话和策略信息统一组织起来,以满足这一需求。
架构说明
如图一所示,在基于 Spring Boot 的应用中,整体结构依然保持清晰。Spring Boot API 继续作为入口,对外接口和交互方式与传统 RAG 系统一致。
在应用层中,引入上下文管理器作为独立组件,负责收集运行时信号,包括用户信息、会话历史和策略约束。其职责仅限于对这些上下文进行整理和规范化,然后传递给下游。
现有的 RAG 流程(检索器、向量存储和 LLM 服务)保持不变,在图中以虚线区域表示。上下文会影响检索方式和 prompt 构建,但不会改变底层组件本身。
这种结构与常见的 Spring RAG 实现方式保持一致,也使得 CAG 更像是一种渐进式扩展,而不是整体重构。
上下文管理器的角色
上下文管理器将企业系统中原本分散存在的职责进行了显式化。相比于将上下文逻辑散落在控制器或临时 prompt 模板中,CAG 将其集中在一个独立组件中统一处理。
从功能上看,它负责收集用户属性(如角色、部门)、整合会话历史,并应用领域策略或业务约束,最终生成一个统一的上下文对象,在检索和生成阶段一致使用。
通过将上下文处理与检索、生成解耦,系统在理解、审计和演进上都会更加清晰。
在 Spring Boot 中的集成方式
下面的示例展示了上下文管理器在典型 Spring Boot 请求流程中的位置。作者有意简化了这些示例,并假设系统中已经有一个类似 Spring AI 架构的 RAG 服务。
@RestControllerpublic class AiController{private final ContextManager contextManager; private final RagService ragService;public AiController(ContextManager contextManager, RagService ragService) { this.contextManager = contextManager; this.ragService = ragService; }@PostMapping("/ask") public String ask(QueryRequest request) { Context context = contextManager.buildContext(request); return ragService.generateResponse(request.getQuery(), context); }}The context manager focuses solely on assembling runtime context: public interface ContextManager{ Context buildContext(QueryRequest request);}
复制代码
一个简化的上下文对象通常会包含:
public class Context{ private final UserProfile profile; private final SessionState session; private final PolicyConstraints policies;}
复制代码
RAG 服务本身的行为不会改变,仍然负责检索和生成。唯一的不同是,在构建 prompt 或执行检索调度时,可以显式使用上下文信息。
CAG 作为 RAG 的扩展
需要强调的是,CAG 并不是对 RAG 的替代。检索器、向量存储和 LLM 服务仍按原方式在基于 Spring 的 RAG 应用中运行。上下文管理器只是作为一个附加层,在请求进入 RAG 流程之前进行增强。
这种设计带来几个实际好处:现有 RAG 实现无需改动,可以直接复用;由于核心的检索生成组件不变,因此引入过程可以渐进推进,风险较低;同时,上下文逻辑被显式化,更容易测试、审计和分析系统行为。
通过将“上下文”提升为一等架构要素,基于 Spring Boot 的系统可以在不大规模改造的前提下,从以文档为中心的 AI 助手演进为具备上下文感知能力的企业服务。
最佳实践与注意事项:让 CAG 可用于生产环境
将上下文作为明确的约束
引入上下文管理器可以让上下文处理变得显式,但同时也带来了一个新的架构约束。在生产环境中,上下文不应被当作随意拼接的一组属性来处理。用户身份、会话状态和业务约束各自承担不同作用,其变化节奏也不相同。通过清晰的结构划分和责任归属,将这些差异明确下来,有助于避免无意间的耦合,也能让系统在需求不断变化的情况下依然保持可维护性。
控制上下文的范围
上下文越多并不一定越好。过多的历史或业务相关元数据会增加延迟、提高推理成本,还可能稀释关键信息。实践中,应优先保留最关键的内容,如近期会话信息、标准化用户属性,以及确实影响结果的业务约束。
保持现有 RAG 流程的稳定性
CAG 的一个核心优势在于,它不会改变原有的检索和生成流程。这种分离关系需要被有意识地保留下来。具体来说,上下文相关的逻辑应当只存在于上下文管理器中,而不应该被嵌入到检索器或 LLM 的封装层里。如果将上下文处理分散到这些组件中,不仅会增加系统复杂度,也会模糊不同模块的职责边界。
让上下文具备可观测性
一旦上下文开始影响系统行为,可观测性就变成了必需,而不是可选项。如果无法清楚地看到系统在某次请求中实际使用了哪些上下文信息,那么无论是问题排查还是系统治理,都会变得非常困难。
在实践中,合理范围控制和脱敏处理后的元数据记录可以用来解决这个问题,帮助团队理解“为什么会生成这个结果”,同时也为审计、合规等场景提供支持。CAG 的价值,很大一部分正体现在让上下文从“隐式存在”变为“显式可见”。
针对上下文缺失或不完整的情况进行设计
在企业系统中,数据不完整几乎是常态,而不是例外。用户信息可能缺失,会话历史可能已经过期,策略服务也可能在某些时刻不可用。因此,一个健壮的上下文管理器不应假设所有信息都是齐全的,而应该具备良好的降级能力。例如,在必要时使用默认值,或者在不影响核心逻辑的前提下忽略部分非关键上下文,而不是直接导致整个请求失败。如果设计得当,CAG 不仅不会降低系统稳定性,反而可以提升整体可靠性;反之,如果对上下文依赖过强且缺乏容错机制,就可能引入新的故障点。
避免让上下文管理器“过载”
随着 CAG 系统不断演进,一个常见的问题是:上下文管理器逐渐承担越来越多的职责。一旦 CAG 开始包含业务逻辑甚至决策逻辑,上下文管理器就有可能演变为系统瓶颈。更合理的做法是,将其职责限制在“编排和整理上下文”这一层面,也就是负责收集、聚合和规范化数据,而不是对这些数据做业务层面的解释或决策。这样可以保持系统结构的清晰性,同时也有利于测试和长期维护。
安全与隐私方面的考虑
上下文中往往包含用户或组织层面的敏感信息,因此安全问题应作为显式设计的一部分。在将上下文信息注入 prompt 之前,应当先进行访问控制、数据最小化处理以及必要的脱敏。CAG 应该强化企业已有的安全与治理机制,而不是绕开这些机制。
以渐进方式引入 CAG
在实际落地中,成熟的团队通常不会一次性全面引入 CAG,而是选择分阶段推进。可以先从一个最小化的上下文层开始,只引入少量关键上下文信息,再根据实际效果逐步扩展。这样的方式可以在不影响现有 RAG 系统运行的前提下,对设计假设进行验证,并根据反馈不断调整实现策略。随着系统逐步演进,这种有节奏的推进方式能够帮助团队从以文档为中心的 AI 助手,平滑过渡到具备上下文感知能力的企业级服务。
从整体来看,让 CAG 具备生产可用性,关键不在于具体工具的选择,而在于是否具备良好的架构约束。只有在上下文被清晰定义、边界明确、具备可观测性,并且与底层 RAG 流程保持解耦的前提下,团队才能在扩展系统上下文能力的同时,维持既有系统的稳定性和可控性。
总结
RAG 已成为将大语言模型与企业数据结合的一种实用基础方案。但随着 AI 系统从原型走向生产,我们可以看到,仅靠检索并不足以满足需求。企业软件本质上是有状态的,受到用户角色、会话连续性和业务约束的影响,而这些因素并未在传统 RAG 中显式建模。
CAG 通过引入一个专门的上下文管理层来弥补这一缺口。它并不替代现有的检索器或 LLM 服务,而是在应用层将上下文处理能力显式化——也正是企业上下文本来就存在的地方。这种分层方式既保留了已有的 RAG 投入,又让系统在行为一致性、可追踪性以及 AI 行为和业务契合度方面得到提升。
对于使用 Java 和 Spring Boot 的团队来说,CAG 与现有架构模式天然契合。通过明确划分职责——应用层负责上下文组装,RAG 流程负责检索与生成——团队可以以较低成本、较小风险逐步引入 CAG。
作者说明:本文基于作者个人的技术研究整理,仅代表个人观点,不对应任何具体组织的实际架构实现。







 ~ 被展开为家目录" title="PowerShell 波浪号陷阱:引号并不能阻止
~ 被展开为家目录" title="PowerShell 波浪号陷阱:引号并不能阻止 















