24 年 12 月买的徕芬吹风筒坏掉了,返厂检修,对品控很失望

几个月前就发现每次开的时候就会有一声爆响,不是很大声但是有一点吓人,像是大功率电器刚接通那种感觉
就在前晚,发现开了之后关不了了
联系客服,客服说原因不明,安排返厂检修,看看是不是非人为的损坏
搜了下很多人吐槽它过保就坏,现在对它的品控有点失望
前阵子还送了一个给朋友
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
几个月前就发现每次开的时候就会有一声爆响,不是很大声但是有一点吓人,像是大功率电器刚接通那种感觉
就在前晚,发现开了之后关不了了
联系客服,客服说原因不明,安排返厂检修,看看是不是非人为的损坏
搜了下很多人吐槽它过保就坏,现在对它的品控有点失望
前阵子还送了一个给朋友
摘要 本文为某大型企业集团DRP全域数据资源管理平台的顶层设计与建设实践案例,系统阐述了平台的定义与定位、规划建设路径、业务侧与财务资金侧系统打通方案,以及业财双向协同闭环机制,完整呈现了从顶层规划到落地运营的全周期建设思路,可为同类集团开展DRP平台建设提供参考与借鉴。 DRP平台定义及国资政策背景 DRP全域数据资源管理平台定义 DRP(Data Resource Platform,全域数据资源管理平台)是面向大型企业集团打造的集团级统一数据中枢、全要素数据资产管控与业财数据融合底座,是集数据汇聚、数据治理、数据共享、业财协同、数据资产运营、穿透式监管于一体的综合性数据管理平台。 平台以“一数一源、标准统一、全域贯通、业财融合”为核心,不替代前端业务执行系统与后端财务资金系统,而是通过标准化、集成化、智能化手段,打通ERP、CRM、PLM、MES、TMS等业务系统,以及财务共享、资金管理、税务管理等财务资金系统的数据与流程壁垒,实现集团研发、生产、营销、供应链、财务、资金等全领域数据的全生命周期管理,推动数据从分散孤岛走向集中治理、从被动统计走向主动赋能、从业务资产走向数据资产,最终支撑集团数字化管控、精细化运营、合规化监管与科学化决策。 国资监管政策背景 近年来,国家层面持续强化国有企业数字化治理、数据要素市场化配置与国资穿透式监管,国务院国资委联合国家数据局等部门相继出台一系列政策文件,对大型国有企业数据资源管理提出明确要求,成为集团建设DRP全域数据资源管理平台的核心政策依据与行动指引。 数据要素顶层制度指引:《关于构建数据基础制度更好发挥数据要素作用的意见》(“数据二十条”)明确提出构建数据产权、流通、收益、治理基础制度,推动国有企业数据资产化、价值化,要求国企建立统一数据管理体系,激活数据要素价值。 国资央企数据效能提升要求:国家数据局、国务院国资委联合部署“国有企业数据效能提升行动”,要求加快构建国资央企大数据体系,创新数据管理机制,推动跨系统、跨层级、跨业态数据共享融合,强化数据赋能现代公司治理,助力产业转型升级。 数据资源开发与可信数据空间建设:国资委启动国有企业数据资源开发利用试点、国资央企领域可信数据空间系统建设试点,明确要求国企搭建统一数据资源管理平台,实现数据标准统一、数据互联互通、安全可控,构建集团级可信数据环境,保障国资监管数据可追溯、可核查、可监管。 业财穿透与国资合规监管要求:国资委持续深化国资监管数字化,要求大型集团实现业务、财务、资金全链路穿透管控,统一数据口径、规范数据管理,强化国有资产监管、资金管控、风险防控的数字化支撑,满足国资报表上报、数据审计、合规运营刚性要求。 在此政策背景下,大型企业集团亟需搭建DRP全域数据资源管理平台,全面落实国资数据监管要求,破解内部数据孤岛、业财脱节、资金管控滞后、数据价值难以释放等痛点,构建符合国资规范、适配集团发展的数字化数据管控体系,实现数据资源规范化、资产化、价值化运营,助力集团数字化转型与高质量发展。 DPR建设方案总论 DRP建设背景与核心诉求 大型企业集团历经多年数字化建设,已部署ERP、CRM、PLM、MES、TMS等业务执行系统,以及资金管理、费用报销、财务共享、税务管理等财务资金类系统,但长期存在业务系统数据割裂、财务资金系统与业务系统脱节、跨域数据不通、业财对账困难、管控链条断裂等核心痛点。一方面前端研发、生产、营销、物流等业务环节形成数据孤岛,业务流程无法端到端协同;另一方面财务、资金、税务等管控环节滞后于业务,数据口径不一、核算被动、资金管控不精准,难以支撑集团全域资源统筹、精细化管控与数字化决策。 DRP平台建设,应以“业务侧全系统贯通+财务资金侧全链路打通”为双核心,构建从顶层规划到落地运营的完整建设闭环,实现业务数据全域协同、财务资金数据与业务数据深度同源融合,打造集团统一数据中枢与资源管控底座,破除数据壁垒、打通业财链路,实现业务流、数据流、资金流、管控流闭环运转。 DRP平台核心定位 DRP平台是大型企业集团全域数据集成中枢、业财数据融合载体、跨系统协同纽带、全流程管控核心,定位为集团级统一数据治理与数据服务平台,不替代现有业务、财务资金类系统,而是通过标准统一、数据汇聚、流程串联、规则赋能,实现两大核心价值:一是串联前端所有业务系统,实现业务端到端协同与数据一体化;二是打通后端财务、资金、税务等管控系统,实现财务资金数据与业务数据实时联动、业财同源、资金穿透管控,最终达成“业务可协同、数据可共享、资金可管控、业财可融合”的数字化管控目标。 整体设计核心原则 分层贯通,双轮驱动:严格区分业务侧、财务资金侧系统打通逻辑,分层设计、分步落地,以业务侧数据贯通为基础,以财务资金侧数据融合为核心,实现业务与财务资金双向联动。 标准先行,一数一源:建立集团统一主数据、数据指标、流程接口标准,确保业务、财务资金数据源头唯一、口径统一、全域复用。 利旧集成,无缝衔接:充分复用现有业务、财务资金系统能力,通过轻量化接口集成实现数据与流程打通,避免重复建设,保障现有业务平稳运行。 业财闭环,管控前置:推动业务数据实时同步财务资金端,财务资金管控规则反向嵌入业务流程,实现事前预警、事中管控、事后核算的全闭环管理。 架构可扩,迭代优化:搭建高兼容、可扩展的平台架构,支持后续新增系统接入、应用场景拓展,适配集团业务发展与管控升级需求。 DRP平台从规划到建设完整闭环设计 一 前期顶层规划阶段:定方向、立标准 2.全域顶层架构设计 3.统一标准体系搭建 二 中期平台建设阶段:搭底座、通数据、建应用 三 后期运营迭代阶段:全推广、长效管、优价值 DRP平台与业务侧系统打通设计 业务侧系统范围与核心定位 业务侧系统打通总体思路 DRP与业务系统全维度接口对接清单 DRP与业务系统全维度接口对接清单 DRP平台与财务资金侧系统打通设计 财务资金侧系统范围与核心定位 财务资金侧系统打通总体思路 DRP与财资系统全维度业财对接清单 财务资金侧打通核心能力 DRP平台业财双向协同闭环设计 正向数据流转:业务数据驱动财务资金核算 反向规则管控:财务资金规则嵌入业务前端 全域数据应用 实施步骤 第一阶段 规划筹备期 第二阶段 底座建设期 第三阶段 新业务侧打通期 第四阶段 财务资金侧打通期 第五阶段 全面上线与迭代期 建设价值
当前,数字经济加速演进,国家层面持续强化数据要素市场化配置与国有企业数字化治理。在此背景下,DRP(Data Resource Platform,全域数据资源管理平台)作为集团级统一数据中枢与业财融合底座,已成为大型企业集团落实国资监管要求、破解数据孤岛与业财脱节痛点的关键抓手。
图1:DRP(全域数字化资源管理平台)建设要求
1.全域现状深度诊断
业务侧现状盘点:全面梳理PLM、MES、CRM、TMS、业务端ERP等系统功能边界、数据类型、流程节点、接口现状,排查业务系统间数据不通、流程断点、协同低效问题。
财务资金侧现状盘点:梳理财务共享、资金管理、税务系统、费用管控、核算ERP等系统架构,排查财务资金数据与业务数据脱节、核算滞后、资金监管不精准、业财对账繁琐等痛点。
跨域痛点归集:整合业务、财务资金双向需求,梳理数据标准差异、流程脱节、管控盲区,明确平台建设核心目标与优先级。
总体技术架构:采用“源系统接入层→数据集成交换层→数据治理层→数据中台层→应用服务层→可视化展示层”六层架构,分设业务数据专区、财务资金数据专区、业财融合数据专区,实现数据分域管理、全域互通。
数据架构:构建统一数据模型,划分业务主题域(研发、生产、营销、物流)、财务资金主题域(核算、资金、税务、费用)、业财融合主题域,搭建数据湖与数据仓库,明确数据全生命周期管理规则。
协同架构:搭建“业务侧系统协同→DRP平台数据治理→财务资金侧系统联动→DRP平台规则反哺业务”的双向协同架构,厘清各系统与DRP平台权责边界。
主数据标准:统一组织、客商、物料、项目、产品、会计科目等核心主数据编码与属性规则,实现业务、财务资金主数据全域一致。
数据指标标准:统一业务统计指标、财务核算指标、资金管控指标口径,消除跨系统指标差异。
接口与流程标准:制定业务侧、财务资金侧系统与DRP平台对接接口规范、数据传输协议、流程流转规则,保障跨系统数据与流程通畅。
图2:项目整体思路
完成DRP平台基础设施部署、底层框架开发,搭建主数据管理、数据集成、数据治理、权限管控、安全运维基础模块,实现平台基础运行能力,搭建集团统一主数据管理中心,完成全量主数据清洗、归一、发布。
按照业务侧、财务资金侧分类推进数据接入,通过实时API、批量ETL、消息队列等方式,实现两类系统数据全量、精准同步至DRP平台。
开展数据清洗、校验、去重、补全,构建数据血缘关系,实现业务数据、财务资金数据标准化、规范化管理,形成统一数据资产。
围绕业务系统协同、财务资金管控、业财深度融合三大核心,开发数据集成管理、跨系统流程协同、资金监控、业财对账、核算自动化、风险预警、决策分析等模块,实现平台核心管控与服务能力。
开展平台功能、数据、接口、压力测试,选取核心业务单元与财务模块进行试点运行,优化数据逻辑、流程节点,验证业务与财务资金打通效果,形成可复制的落地模式。
分批次推进业务侧、财务资金侧系统全面接入DRP平台,完成全员操作培训,实现平台全集团、全系统覆盖。
建立数据质量巡检、跨系统接口运维、业财数据对账、流程优化长效机制,明确数据与流程管理责任,保障平台稳定运行、数据精准有效。
结合集团业务发展与管控需求,持续优化平台功能、拓展应用场景,深化业财融合深度,推动DRP平台从数据集成向数据智能、精准决策升级。
业务侧系统涵盖PLM产品生命周期管理、MES生产制造执行、CRM客户关系管理、TMS运输管理、业务端ERP供应链管理五大核心系统,均为业务执行层系统,负责前端研发、生产、营销、物流、供应链全业务环节落地,是DRP平台业务数据的唯一源头。
以端到端业务流程串联、全业务数据一体化为核心,DRP平台作为业务侧系统统一集成中枢,实现各业务系统数据实时互通、流程无缝衔接、资源协同共享,消除业务数据孤岛,形成“研发-生产-营销-物流-供应链”全业务闭环。
跨系统数据共享:全业务数据统一汇聚至DRP平台,实现一次录入、全域复用,消除重复录入与数据差异。
端到端流程协同:打通研发、生产、营销、物流、供应链全业务流程,实现流程自动流转、无缝衔接。
业务全域可视化:构建业务全流程监控看板,实现业务进度、资源状态、交付情况实时可视。
财务资金侧系统涵盖财务共享系统、资金管理系统、税务管理系统、费用报销系统、核算ERP系统、银企直连系统,是集团财务核算、资金管控、税务合规、费用管理的核心执行系统,负责集团财务资金全流程管控,需与业务侧数据实现深度同源融合。
以业财数据同源、资金穿透管控、核算自动化为核心,DRP平台作为业务数据与财务资金数据的融合枢纽,将前端业务侧数据实时同步至财务资金系统,同时将财务资金管控规则、核算标准、预算要求通过DRP平台嵌入业务前端,实现“业务发生即财务核算、资金流动即全程管控”的业财资金一体化闭环。
业财资金数据同源:业务数据、财务数据、资金数据统一口径、源头唯一,实现全链路数据可追溯。
资金全域穿透管控:集团所有资金账户、资金流动、预算执行实时可视,实现资金集中管控、风险精准预警。
财务核算自动化:业务单据自动触发财务核算、收付款、税务处理,减少人工干预,提升财务工作效率。
业财对账闭环:自动完成业务与财务、资金数据对账,实时定位差异、快速闭环处理。
业务侧各系统产生业务数据→DRP平台集成治理→统一推送至财务资金侧系统→自动完成账务核算、资金收付、税务处理,实现业务发生即财务资金同步处理,彻底改变财务事后核算模式。
财务资金侧预算、信用、支付、核算、合规管控规则→DRP平台拆解适配→下发至各业务侧系统→业务流程发起时自动校验、超支预警、违规拦截,实现财务资金管控前置化、全程化。
DRP平台整合业务、财务、资金全域数据,构建集团经营分析、成本管控、风险预警、决策支撑数据模型,为集团经营管理、战略决策提供全方位数据支撑。
完成全域业务、财务资金系统现状调研、需求梳理、顶层架构设计、标准体系制定,输出完整建设方案,完成主数据标准确认。
搭建DRP平台基础底座,开发主数据管理、数据集成模块,完成核心主数据清洗归一,搭建跨系统接口框架。
完成DRP与PLM、MES、CRM、TMS、业务ERP系统数据与流程打通,实现业务侧全域协同,开展试点运行。
完成DRP与财务共享、资金管理、税务、费用报销系统打通,实现业财数据对接、资金管控落地,完成业财对账模块开发。
全集团系统接入DRP平台,实现业务、财务资金全域贯通,平台正式运营;建立长效运维机制,持续优化功能、深化应用场景,释放数据价值。
业务协同价值:破除业务系统数据孤岛,实现研发、生产、营销、物流、供应链全业务流程端到端协同,提升业务运营效率。
资金管控价值:实现集团资金全域可视、全程可控、穿透式管理,降低资金风险,提升资金使用效率。
业财融合价值:实现业务与财务、资金数据同源、流程同步、管控同频,解决业财对账难、核算滞后痛点,推动财务从核算型向管控型转型。
决策支撑价值:构建集团全域数据视图,为经营决策、成本管控、风险防控提供实时、精准的数据支撑。
数字化管控价值:搭建集团统一数据管控底座,实现全流程线上化、标准化、可视化,提升集团整体精细化管控水平。
国资合规价值:全面契合国资委数据监管、穿透式管控要求,实现数据可追溯、可审计、可监管,保障国资运营合规化、规范化。
原文链接: https://tecdat.cn/?p=45571 关于分析师 在此对 Kaizong Ye 对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,并在佛罗里达州立大学获得博士学位,专注医疗数据分析与统计建模领域。在健康经济学和医疗生产力研究方面拥有丰富经验。 你有没有发现一个矛盾:医疗技术越来越先进,但看病却越来越贵、排队越来越长、医生越来越累?这不是错觉。根据全球顶级咨询机构 Oliver Wyman 联合 哈佛医学院 发布的《2026医疗生产力重构报告——AI、机器人与量子技术的应用前景量化分析》,全球医疗系统正站在一个危险的拐点上。 本文完整研究报告数据图表和文末300+份医疗行业最新参考报告合集已分享在交流群,阅读原文查看、进群咨询,定制数据、报告,与900+行业人士共同交流和成长。 报告锚定的核心主题是 “医疗生产力重置” ——不是少看病、不是降质量,而是用技术重新定义“一个医生、一张床位、一台设备”到底能创造多少健康价值。读完这篇文章,你将彻底看清未来15年医疗行业的底层变量,并拿到一份可直接落地的行动清单。 我们不妨先直面最让人焦虑的问题:医疗支出已经这么高了,未来我们还负担得起吗? 报告给出了两组极具冲击力的数字: 但真正让人后背发凉的不是总额,而是增长的结构。在这增加的11.3万亿美元中,只有 2.7万亿美元 是因为人口变多了,属于“硬性增长”;而剩下的 8.6万亿美元(占比高达76%)则是因为劳动力短缺、流程碎片化、行政臃肿等效率问题导致的“服务成本上升”。 换句话说,不是病人变多了我们才花更多钱,而是系统本身“变慢了、变笨了”。 做个生活化类比:这就像你家楼下早餐店,以前老板5分钟能出10个包子,现在因为后厨布局混乱、外卖单子多手写,5分钟只能出5个。但客人没少,反而越来越多,于是包子涨价、排队变长、老板累到崩溃——这就是当下全球医疗系统的真实写照。 面对这个8.6万亿美元的效率缺口,很多人的第一反应是:控制药价、削减预算、限制报销。但报告用一记响亮的“认知反转”告诉我们:这条路根本走不通。 报告提出了一个关键框架:医疗系统的“产出”是固定的——人口老龄化决定了需求只会增加,我们不能减少服务。因此,唯一能压缩的变量是“投入”——也就是临床和行政人员的时间、设施设备的闲置率、重复劳动和等待时间。 报告量化模拟了三种生产力提升路径,结果惊人: 更值得玩味的是投入产出比:突破情景的累计投资虽然比加速情景高30%,但带来的年度节省却是加速情景的 1.82倍。生产力不是省出来的,是投资投出来的。 相关文章 提到“提升生产力”,很多医院管理者的第一反应是:让医生多看几个病人、让护士多跑几趟。这恰恰是报告要纠正的最大误区。 报告中的核心专业概念 “医疗生产力重置” ,通俗讲就是:在不增加人手、不降低质量的前提下,通过AI、机器人和自动化重新设计工作流,让同样一个医生能服务更多患者,同时自己还不那么累。 为此,报告清晰划出了两条截然不同的价值路径: 最常见的认知误区是:以为引入一个AI软件就等于完成了数字化转型。 实际上,如果底层流程仍然是手工的、割裂的,AI只会变成又一个“信息孤岛”。真正的红利只属于那些敢于重构整个工作流的先行者。 从个体医生和医院跳出来,站在整个产业的高度看,报告揭示了一个更宏大的底层逻辑:医疗行业正在经历一次迟到的“工业革命”。 制造业、物流业早在几十年前就通过自动化流水线和信息系统实现了生产率飞跃,而医疗行业因为高度依赖人工、监管复杂,一直停留在“手工作坊”模式。现在,AI(做决策)、机器人(执行动作)、量子技术(处理复杂运算)这三股技术浪潮同时成熟,终于具备了撬动系统级变革的条件。 但行业内普遍存在一个致命误区:把技术当成“补丁”打在旧系统上。 报告反复强调,如果没有配套的支付改革、责任分担、文化转型,再先进的技术也只能是“盆景”,长不成“森林”。 报告提炼出的底层逻辑极其精炼: 看看各区域的老龄化压力吧——日本65岁以上人口占比已达30%,美国、欧洲也直奔25%,而印度每千人仅有0.7名医生。劳动力不是“即将短缺”,而是“已经崩盘”。 技术不是锦上添花,是活下去的唯一选择。 抽象的论述总需要一个具象的支点。报告引用了一个来自英国NHS(国家医疗服务体系)的真实案例——AI辅助卒中影像诊断。 案例主体: 英国国家医疗服务体系(NHS)与Brainomix公司的e-Stroke系统 落地流程拆解: 量化结果: 这个案例完美印证了报告的核心论点:生产力的本质不是让人干得更快,而是砍掉那些根本不该由人干的等待、传递和重复劳动。 听完了报告的所有洞察,最关键的还是:我能做什么? 基于报告总结的五大关键推动因素,我们提炼出三条零门槛、可立即落地的行动建议: 1. 投资技术基础设施,而不是局部试点 2. 改革支付与责任规则,让自动化“有利可图” 3. 推动文化转型,把技术视为“队友”而非“对手” 这份报告的价值远不止于阅读。我们为你准备了: 获取文末所有参考行业报告及数据,进交流群,加小助手微信号:tecdat_cn 等其他精选医疗AI与机器人报告300+份(进群获取完整目录)
原文出处: 拓端抖音号@拓端tecdat
一、医疗人的集体焦虑:钱越花越多,系统却越来越挤?
信息图引用: 医疗行业生产力重构主题锚定信息图1
二、23万亿与8.6万亿:两个数字戳破“花钱买健康”的幻觉
2025年全球医疗支出约为 11.8万亿美元。
到2040年,这个数字将飙升至 23.1万亿美元——近乎翻倍。数据图表引用: 医疗行业全球支出增长驱动因素瀑布图表1
三、颠覆认知:医疗危机的解药不是“省钱”,而是“提效”
数据图表引用: 医疗行业生产力情景对比刻度线图表2
2026AI医疗行业专题报告:智能医疗器械、手术机器人、脑机接口、可穿戴设备|附240+份报告PDF、数据、可视化模板汇总下载
原文链接:https://tecdat.cn/?p=44979
四、“生产力”到底是个啥?一张图告别低水平勤奋
信息图引用: 医疗行业生产力焦虑与破局认知反转信息图2
区域 特征 典型场景 高风险/低价值区 手工流程、碎片化系统、按服务付费 医生手写病历、电话沟通转诊、人工审核保险单 高价值/红利区 AI驱动工作流、机器人自动化、价值导向支付 AI辅助影像诊断、手术机器人、远程实时监测 五、升维思考:医疗行业的“工业革命”终于来了
信息图引用: 医疗行业生产力概念拆解价值分层信息图3
数据图表引用: 医疗行业区域老龄化与支出压力横向比例条形图表3
医疗生产力的核心矛盾,已经从“技术能不能做”变成了“系统让不让它做”。六、真实案例:AI如何让中风患者早1小时获救?
核心动作: 用AI算法自动分析脑部CT影像,识别大血管闭塞,并实时通知神经介入团队传统流程(140分钟) AI赋能流程(79分钟) 1. 患者到院后常规CT 1. 患者到院后CT扫描 2. 放射科医生阅片 2. AI实时分析影像 3. 电话通知神经科医生 3. 自动警报通知团队 4. 准备介入手术 4. 快速启动手术准备
Door-in/out时间从 140分钟 压缩至 79分钟,效率提升 44% 。对于脑卒中患者而言,每节省1分钟,就多挽救190万个神经元。信息图引用: 医疗行业AI辅助卒中影像案例流程拆解信息图4
七、三步行动指南:从今天开始,你可以这么做
信息图引用: 医疗行业生产力重置行动指南信息图5
八、你的下一步行动
本文引用的数据图表列表
本专题内的参考报告(PDF)目录
绝大多数人用不好QClaw,根本不是因为它不够聪明,而是因为我们一直在用和人类对话的方式和它交流。我们习惯了模糊的表达、隐含的前提和跳跃的思维,以为它能像同事一样读懂我们的言外之意,却不知道它的大脑里运行着一套完全不同的理解规则。我见过太多人对着聊天框反复修改同一条指令,从简单的祈使句到堆砌数十个限定词,结果却越来越糟,最后只能无奈地感叹这个工具根本不好用。但实际上,只要你掌握了它底层的指令流转逻辑,哪怕只用最简单的语言,也能让它精准地完成你想要的任何任务,我花了整整一个月的时间,追踪了上百条指令的完整执行链路,才终于摸到了QClaw理解语言的核心规律。很多人都不知道,我们在聊天窗口输入的每一句话,都不会直接变成电脑上的操作,而是要经过四个完全独立的处理阶段。第一个阶段是协议解析,它会把自然语言转换成系统能识别的标准化数据结构;第二个阶段是意图识别,它会从这句话里提取出你真正想要做的事情;第三个阶段是技能匹配,它会从已安装的技能库中找到最适合完成这个任务的工具;第四个阶段才是动作执行,它会按照技能手册里的步骤一步步完成操作。这条链路上的任何一个环节出了问题,最终的结果都会偏离你的预期。 最容易被忽略的是技能匹配这个环节,这也是绝大多数指令失败的根本原因。QClaw的所有能力都来自于它的技能库,每一个技能本质上都是一份用自然语言写成的操作手册。当你发送一条指令时,它不是在"理解"这句话的意思,而是在把这句话和所有技能手册的标题和关键词进行比对,找到相似度最高的那一个。如果你的指令里没有包含对应技能的关键词,或者同时包含了多个技能的关键词,它就会出现匹配错误,要么调用了错误的技能,要么干脆不知道该调用哪个技能,只能给你返回一段无关的文字回复。这就是为什么很多看起来很简单的指令,QClaw却总是做不好。比如你说"帮我整理一下桌面",这句话里没有任何明确的技能关键词,它只能从通用技能库里找一个最接近的。但不同的人对"整理桌面"的理解完全不同,有人想按文件类型分类,有人想按创建日期排序,有人想删除无用的临时文件。QClaw不知道你想要哪种,只能按照它默认的方式执行,结果自然不能让你满意。但如果你换一种说法,明确说出你想要的操作类型,比如"把桌面上所有的图片文件移动到图片文件夹",它就能精准地匹配到文件移动技能,执行结果也会完全符合你的预期。 动作映射阶段的规则更加严格,QClaw只能执行单一路径的动作指令。也就是说,一条指令里最好只包含一个核心动作,不要把多个不同的动作打包在一起。很多人喜欢写复合指令,比如"帮我下载这篇文章,转换成PDF格式,然后发送到我的邮箱"。这条指令包含了下载、格式转换和发送邮件三个完全不同的动作,需要调用三个不同的技能。QClaw在处理这种指令时,很容易出现动作顺序混乱或者中间步骤丢失的情况,最后可能只完成了其中的一两个动作,或者干脆什么都没做。正确的做法是把复合指令拆分成三个独立的指令单元,一条一条地发送。第一条指令只说"下载这篇文章到桌面",等它完成之后,再发送第二条指令"把桌面上的这篇文章转换成PDF格式",最后再发送第三条指令"把这个PDF文件发送到我的邮箱"。这样每一条指令都只对应一个核心动作,QClaw能精准地匹配到对应的技能,执行成功率会从原来的不足三成直接提升到接近百分之百。而且这样做还有一个好处,你可以在每一个步骤完成之后检查结果,如果有问题可以及时调整,不用等到最后才发现整个任务都做错了。 很多人担心拆分指令会浪费时间,但实际上恰恰相反。拆分指令虽然多了几次发送操作,但却大大减少了因为执行错误而需要反复修改的时间。我做过一个对比测试,同样的跨技能复杂任务,用复合指令平均需要尝试五次才能成功,总耗时超过二十分钟;而用拆分指令一次就能成功,总耗时不到五分钟。更重要的是,拆分指令能让你对整个任务的执行过程有完全的掌控权,你知道每一步都在做什么,也能在任何时候暂停或者调整任务的方向,上下文的使用也是很多人容易犯错的地方。大多数人以为上下文就是把之前的对话历史都堆在一起,让QClaw自己去提取有用的信息。但实际上,QClaw的上下文窗口是有限的,而且它对历史信息的提取能力远没有我们想象的那么强。如果你的上下文里包含了太多无关的信息,它很可能会忽略掉重要的内容,或者错误地提取了已经过时的信息,导致执行结果出现偏差。 正确的上下文用法不是堆历史,而是建锚点。QClaw有一个非常强大的语义锚定机制,当你连续三次以上在同一个聊天窗口发送带明确主谓宾结构的指令时,它会自动建立一个语义锚点,后续的指令可以用简单的指代词来指代之前的操作对象。比如你先发送"提取这个表格里的所有电话号码",然后发送"把这些号码存到通讯录里",再发送"给这些人发条测试短信"。这三条指令建立了一个稳定的语义锚点,之后你只要发送"上一个",它就会自动执行最后一步操作,也就是发送测试短信。这个机制非常有用,它能让你用最简单的语言完成复杂的链式任务。但要注意的是,语义锚点是和聊天窗口绑定的,不同的聊天窗口有不同的锚点。而且如果你在同一个窗口里切换了完全不同的任务,之前的锚点就会被覆盖。所以最好的做法是给不同类型的任务建立不同的聊天窗口,比如一个窗口专门处理文件操作,一个窗口专门处理数据整理,一个窗口专门处理内容创作。这样每个窗口的语义锚点都不会互相干扰,指令的执行准确率会大大提高。 验证标准是指令里最容易被忽略但也是最重要的部分。很多人写指令只说要做什么,却不说做到什么程度才算完成。比如你说"帮我整理一下这个文件夹里的文件",但没有说整理的标准是什么,QClaw只能按照它自己的理解去执行,结果可能和你想要的完全不同。但如果你在指令里加入明确的可验证标准,比如"把这个文件夹里所有大于100MB的视频文件移动到视频文件夹,执行完成后告诉我剩余的文件数量",它就会严格按照这个标准去执行,并且会给你返回一个可验证的结果。可验证的标准必须是具体的、可量化的,不能用"尽量""大致""差不多"这样的模糊词汇。比如你不能说"尽量把文件整理干净",而要说"删除所有扩展名为tmp和log的临时文件";你不能说"大致统计一下数据",而要说"统计表格中A列数值大于100的行数"。只有当目标是可量化的时候,QClaw才能准确地判断任务是否完成,也才能给你返回一个有意义的结果。 跨技能协同的指令设计是QClaw最强大也最难掌握的部分。很多复杂的任务需要多个技能配合才能完成,比如从网页上抓取数据,整理成表格,然后生成图表,最后插入到演示文稿中。这个任务需要调用网页抓取、数据处理、图表生成和文档编辑四个不同的技能。很多人在处理这种任务时,会把所有的要求都写在一条指令里,结果QClaw根本不知道该如何分配这些技能,只能胡乱执行一通。正确的跨技能协同指令设计,应该明确每个技能的输入和输出,以及它们之间的数据流转方式。你应该先告诉QClaw第一个技能要做什么,以及它的输出应该保存到哪里;然后告诉它第二个技能从哪里读取输入,处理之后保存到哪里;以此类推,直到最后一个技能完成整个任务。这样每个技能都有明确的输入和输出,QClaw能按照顺序依次调用它们,并且能保证数据在不同技能之间正确地流转。 比如你可以这样写:"第一步,打开这个网页,提取所有的产品名称和价格信息,保存为桌面的产品表格文件;第二步,打开这个产品表格文件,生成一个按价格排序的柱状图,保存为桌面的价格图表文件;第三步,打开桌面的演示文稿文件,把这个价格图表插入到第二页,调整大小使其适合页面。"这样的指令清晰地定义了每个步骤的任务、输入和输出,QClaw能完美地执行整个流程,不需要你在中间进行任何干预。长期记忆的构建是让QClaw真正懂你的关键。很多人抱怨QClaw每次都要重复说明同样的要求,不知道自己的偏好和习惯。但实际上,QClaw有一个非常强大的长期记忆系统,只是大多数人都不知道该如何正确地使用它。它的长期记忆不是自动记录所有的对话历史,而是需要你主动地把重要的信息告诉它,让它保存到专门的记忆文件中。 你可以告诉QClaw任何你想让它记住的事情,比如你的工作习惯、常用的文件路径、偏好的输出格式等等。比如你可以说"记住,我以后所有的文档都用WPS打开,不要用Microsoft Office",或者"记住,我喜欢简洁的回复风格,不要说多余的话"。QClaw会把这些信息保存到它的长期记忆文件中,以后不管你在哪个聊天窗口发送指令,它都会自动应用这些偏好设置,不需要你每次都重复说明。更强大的是,你可以让QClaw自己维护它的长期记忆。每次完成一个重要的任务之后,你可以告诉它"把今天我们讨论的重要内容更新到你的记忆里",它会自动总结这次对话中的关键信息,并且保存到长期记忆文件中。这样随着使用时间的增长,QClaw会越来越了解你,它的执行结果也会越来越符合你的预期。最终,它会变成一个真正懂你的数字助手,而不是一个只会执行简单命令的工具。 很多人以为给QClaw发指令是一件很简单的事情,只要把自己想要做的事情说出来就行了。但实际上,这是一门需要学习和练习的技能。它要求你改变自己的思维方式,从人类的模糊思维转变为计算机的精确思维;要求你学会拆解任务,把复杂的大任务拆分成简单的小步骤;要求你学会定义标准,把模糊的目标变成可量化的指标。当你真正掌握了这些技巧之后,你会发现QClaw能做到的事情,远远超出你的想象。最后我想说,QClaw不是一个完美的工具,它还有很多需要改进的地方。但它已经是目前最强大的本地AI助手之一,能真正地帮我们解决实际问题。我们不应该抱怨它不够聪明,而应该学会如何更好地和它交流。毕竟,最好的工具不是最聪明的那个,而是最适合你的那个。当你学会了用它的语言和它对话,你就拥有了一个能24小时为你工作的数字助手,它会帮你处理那些繁琐重复的工作,让你有更多的时间去做那些真正重要的事情。
用QClaw最磨人的从来不是它做不好事,而是你每次都要把同样的话重复一百遍。明明上周才告诉过它所有文档要用WPS打开,这周它又默认调用了其他软件;明明每次保存文件都要指定同一个文件夹,它还是会一次次问你要路径;明明说过无数次不要加多余的格式和废话,它还是会在输出结果前面加上一大段无关的开场白。绝大多数人把这归咎于QClaw不够聪明,觉得它的记忆能力太差,但我花了整整两个月的时间,测试了所有和记忆相关的功能,追踪了上千条指令的执行过程,才发现一个几乎没有人知道的真相:QClaw的记忆系统根本不是自动运行的,它从来不会主动记住任何东西,所有你觉得它记不住的问题,本质上都是你没有用对它的记忆机制。很多人对AI记忆的理解从一开始就错了,他们以为AI的记忆就像人类的大脑一样,会自动记录所有看到和听到的信息,然后在需要的时候自动提取。但实际上,QClaw的记忆系统是一个完全结构化的规则引擎,而不是一个无差别的存储容器。它不会把你说过的每一句话都原封不动地保存下来,也不会自己从聊天历史中总结出你的习惯和偏好。它只会保存那些你明确告诉它要记住的、符合特定格式的规则,并且只会在执行任务的时候严格按照这些规则来操作。这就是为什么有时候它能记住一个非常细节的要求,却会忘记你昨天才说过的最重要的事情,因为那些被它记住的细节,恰好符合了它的规则存储格式。 QClaw的记忆系统其实分为三个完全独立的层级,分别是短期上下文记忆、会话锚点记忆和长期全局记忆,这三个层级的工作方式、存储时长和应用范围都完全不同。绝大多数人之所以用不好它的记忆功能,就是因为混淆了这三个层级的边界,把应该存在长期记忆里的规则,放在了短期记忆里;把应该用会话锚点处理的连续任务,变成了一次次重复的完整指令。只有搞清楚每个层级的工作原理,并且在正确的场景使用正确的记忆层级,才能真正让QClaw记住你的所有工作习惯,不用每次都重复说明同样的话。首先是最基础的短期上下文记忆,这也是绝大多数人唯一知道的记忆层级。很多人以为QClaw能记住整个聊天窗口的所有历史,但实际上它的短期上下文记忆窗口非常有限,而且它只会保留最近的十几条指令,更早的内容会被自动覆盖,不会留下任何痕迹。而且短期记忆是会话隔离的,也就是说,你在A窗口说过的话,B窗口完全不知道,哪怕这两个窗口是同时打开的。所以永远不要指望短期记忆能帮你记住任何超过一天的事情,它只能用来处理同一个会话中的连续任务,比如你刚让它打开了一个文件,接下来可以说“把第三行删掉”,而不用再重复说“把刚才打开的那个文件的第三行删掉”。 比短期记忆高一级的是会话锚点记忆,这是一个几乎所有教程都没有提到过的隐藏功能,也是提升QClaw使用效率最有效的技巧之一。当你在同一个会话窗口中,连续三次发送结构完全相同的指令时,QClaw会自动在后台建立一个会话锚点,把指令中重复出现的所有参数和设置都保存下来。从第四次开始,你只需要发送指令中变化的部分,它就会自动补全所有重复的内容,并且按照之前的参数执行。这个功能的强大之处在于,它不需要你做任何额外的设置,完全是自动触发的,而且准确率几乎是百分之百。举个非常具体的例子,如果你每天都需要把收到的文档转换成PDF格式,并且保存到桌面的“每日转换”文件夹里。一开始你需要发送完整的指令:“把这个文件转换成PDF格式,保存到桌面的每日转换文件夹”。当你连续三次发送这条完全相同的指令之后,第四次你只需要说“转换这个文件”,QClaw就会自动按照之前的格式和路径保存,不用你再重复任何参数。而且这个会话锚点会一直存在,直到你在这个窗口发送了一条结构完全不同的指令,它才会被覆盖。所以最好的做法是给不同类型的重复任务建立专门的会话窗口,每个窗口只处理一种类型的任务,这样会话锚点就永远不会被干扰。 最高级也是最核心的是长期全局记忆,这才是真正能让你一次设置,终身不用重复说明的关键。和前两个层级不同,长期全局记忆是跨会话、跨设备的,一旦保存,不管你在哪个窗口、哪台电脑上使用QClaw,它都会自动应用这些规则。但绝大多数人都不知道的是,QClaw的长期记忆是完全被动的,它永远不会自动把任何信息保存到长期记忆里,除非你用明确的指令告诉它要记住什么。而且它不会保存任何模糊的描述,只会保存那些可以直接转化为执行规则的明确语句,这就是为什么很多人说“我告诉过它很多次了,它还是记不住”,因为他们用的都是模糊的、描述性的语言,而不是规则化的语言。比如你说“记住我喜欢用WPS”,这句话对QClaw来说是完全没有意义的,它不知道“喜欢用WPS”到底意味着什么,也不知道在什么情况下应该应用这个偏好。但如果你换一种说法,用规则化的语言告诉它:“所有需要打开文档、表格或者演示文稿的操作,都默认使用WPS软件,不要使用其他任何办公软件”,它就会把这句话解析成一条可执行的规则,保存到长期记忆中,以后所有的文档操作都会自动使用WPS,永远不会再问你要打开方式。 向QClaw灌输长期记忆的时候,还有一个非常重要的原则,就是一条规则只做一件事,不要把多个不同的要求打包在同一条规则里。很多人喜欢写很长的规则,把所有的要求都堆在一起,比如“记住,所有的文档都要用WPS打开,保存到桌面的工作文件夹,不要加多余的格式,输出的时候要简洁明了”。这样的规则QClaw根本无法正确解析,它只会记住其中的一部分,甚至可能完全忽略整条规则。正确的做法是把它拆分成四条独立的规则,一条一条地告诉它,这样每条规则都非常清晰,QClaw能准确地解析和执行。长期记忆的分类管理也非常重要,很多人把所有的规则都混在一起,导致QClaw有时候会应用错误的规则,或者执行速度变慢。正确的做法是把长期记忆分成不同的类别,比如文件操作规则、文档编辑规则、数据处理规则、输出格式规则、邮件处理规则等等,每个类别下面只保存相关的规则。而且你可以随时告诉QClaw查看某个类别的所有规则,或者修改、删除某一条规则。这样不仅能让QClaw的执行速度更快,还能避免规则之间的冲突,让它的执行结果更加准确。 很多人不知道的是,QClaw还能自己从你的操作中学习新的规则,并且自动保存到长期记忆中。当你完成一个比较复杂的任务之后,只要告诉它“把这次的操作方式保存为默认规则”,它就会自动总结这次任务中的所有参数、设置和步骤,生成一条完整的规则,保存到长期记忆中。以后再遇到类似的任务,它就会自动按照这次的方式执行,不用你再一步步地说明。这个功能对于那些经常需要处理复杂重复任务的人来说,简直是神器,一次设置,以后所有的同类任务都能一键完成。跨设备的记忆同步是另一个非常实用但很少有人知道的功能。很多人在公司和家里的电脑上都安装了QClaw,以为需要在两台电脑上分别设置所有的规则,但实际上QClaw的长期记忆是可以导出和导入的。你可以把自己的所有规则导出成一个单独的文件,然后复制到另一台电脑上导入,这样两台电脑上的QClaw就会有完全相同的记忆,不用再重新设置一遍。而且这个导出的文件是纯文本格式的,你可以用任何文本编辑器打开和编辑,非常方便备份和分享。 当多条规则发生冲突的时候,QClaw会按照一个固定的优先级来执行,最新添加的规则优先级最高,会自动覆盖之前的旧规则。所以如果你想要修改某个旧的规则,不需要先删除它,只要添加一条新的、内容相反的规则就可以了,QClaw会自动优先执行新的规则。而且你也可以手动指定某条规则的优先级,比如告诉它“这条规则的优先级最高,任何时候都要优先执行,即使和其他规则冲突”,这样这条规则就会永远排在最前面,不会被任何其他规则覆盖。还有一个非常高级的技巧,就是条件触发规则,你可以告诉QClaw在特定的条件下自动执行某条规则,不用你手动触发。比如你可以说“当处理Excel表格中的数值数据时,默认保留两位小数,并且自动右对齐”,这样当它处理任何Excel表格的时候,都会自动应用这个格式设置,不用你每次都说明。你还可以设置更复杂的条件,比如“当文件大小超过100MB时,自动压缩成ZIP格式再保存”,或者“当收到带有附件的邮件时,自动把附件下载到桌面的邮件附件文件夹”。 很多人容易犯的一个错误,就是给QClaw太多的规则,把所有能想到的要求都保存到长期记忆里。但实际上,太多的规则不仅会让QClaw的执行速度变慢,还会增加规则之间冲突的概率,导致一些意想不到的错误。正确的做法是只保存那些真正常用的、每天都会用到的规则,那些偶尔才会用到的要求,还是在发送指令的时候临时说明比较好。一般来说,长期记忆里保存20到30条规则是比较合适的,再多就会开始影响性能和准确率。还有一个非常重要的注意事项,就是永远不要用模糊的、主观的语言来定义规则,所有的规则都必须是客观的、明确的、可执行的。不要用“尽量”“大概”“差不多”这样的词,也不要用“好看”“简洁”“专业”这样的主观描述,因为QClaw无法理解这些词的含义。所有的规则都必须用具体的、可量化的语言来描述,比如不要说“把表格做得好看一点”,而要说“表格的表头用加粗字体,行高设置为20,列宽自动调整”。 很多人抱怨QClaw不够聪明,不能理解自己的言外之意,但实际上,这正是它的优点所在。它不会自作主张,不会随意发挥,只会严格按照你告诉它的规则来执行。只要你用正确的方式告诉它该怎么做,它就会永远按照这个方式做,不会有任何偏差。而人类的助手恰恰相反,他们可能会理解你的言外之意,但也可能会忘记你的要求,或者按照自己的想法随意修改,这才是真正不可靠的。当你真正掌握了QClaw的记忆系统之后,你会发现它能做到的事情远远超出你的想象。你不用再每次都重复同样的话,不用再一次次地纠正它的错误,不用再把时间浪费在那些繁琐重复的设置上。它会变成一个真正懂你的数字助手,知道你喜欢用什么软件,知道你习惯把文件保存在哪里,知道你想要什么样的输出格式,知道你处理各种任务的方式。你只需要告诉它要做什么,它就会自动按照你的习惯完成所有的事情。
全球 PostgreSQL 技术人的盛会来啦——HOW 2026 中国数据库开源发展峰会暨 PostgreSQL 高峰论坛,马上就要和大家见面! 4 月 26 日,大会前一天咱们先搞点“硬活”:国际顶级技术培训、IvorySQL 专家委员会闭门会同步上线。 大会现场更有专属定制礼品全程派送,技术干货、行业交流、限定好礼一次拉满,不管你是开发者还是技术精英,都别错过这场济南之约! HOW2026 特意在大会前安排了国际大师深度工坊——PostgreSQL 核心技术专场,邀请到两位行业大牛,专门讲 PostgreSQL 的核心机制和内核开发,从源码拆解到实战操作,全程干货不掺水,想提升技术的朋友,抓紧报名占座! 时间:4 月 26 日 9:00-12:00(半天) 讲师:Josef Machytka 本培训将通过源代码引导,带领学员深入探讨 PostgreSQL 的共享缓冲区(Shared Buffers)架构:包括其三层设计、命中/未命中/IO 生命周期,以及"钉(Pins)"、分页面 LWLock 和原子性 BM\_* 标志如何协同实现页面级的并发控制。我们将追踪"时钟扫描(Clock-sweep)"算法和"缓冲区环(Buffer Rings)"机制,看它们如何防止大扫描和 VACUUM 操作污染缓存。 架构与同步 逐出与缓存污染控制 性能调优 源代码解析+实战演练+现场答疑(有问题直接问大牛,机会难得) 时间:4 月 26 日 9:00-12:00(半天) 讲师:Cary Huang 本次分享是一个精华版课程,源自 Cary 为某企业数据库团队量身设计并完整交付的 24 小时 PostgreSQL 内核培训体系。 该培训基于真实项目需求构建,目标是帮助工程师深入理解 PostgreSQL 内核机制,具备扩展开发能力,并能够参与 PostgreSQL 生态甚至社区级开发。同时,本课程也特别面向希望进入 PostgreSQL 内核开发的新开发者,帮助其建立系统性的认知框架,降低理解源码与参与开发的门槛。 完整课程涵盖系统架构、内存与 Buffer 管理、MVCC 与可见性判断、数据存储与访问方法、WAL 与复制机制,以及 FDW 与扩展能力等六大模块。 在本次“串串烧”式分享中,我们将从这些内容中提炼出最关键的知识点,并将其串联起来:从一次查询的执行路径出发,逐步理解 PostgreSQL 如何组织数据、控制并发、管理可见性,以及如何实现数据的持久化与复制。课程不再局限于单一模块,而是强调各个内核组件之间的协作关系,帮助开发者建立整体认知。 扫描下方二维码,立即锁定培训席位 去年我们成功召开第一届 IvorySQL 专家顾问委员会交流会议,在一小时的深入交流中,收集到各位专家针对 IvorySQL 发展的宝贵建议,这些建议为 IvorySQL 的持续发展提供了有力支撑。 今年,借着 HOW2026 大会启幕之际,我们将在 4 月 26 日下午 18:00-19:00,于山东大厦专属会议室召开第二届 IvorySQL 专家顾问委员会交流会议。 到时候,数据库领域的顶尖专家、行业领袖还有核心开发者齐聚一堂,大家一起聊聊 IvorySQL 的技术发展、生态共建、产业落地这些关键话题,一起为 IvorySQL 的后续发展出谋划策,助力国产开源数据库生态的发展。 这次 HOW2026 大会,我们特意准备了大会专属定制礼品, 除此之外我们还会在大会现场设置有奖打卡及互动活动,满足条件即可领取,限量版惊喜好礼等你来解锁~ 4 月 26 日,HOW2026 会前培训与 IvorySQL 专家委员会会议先行启幕,提前带来技术、交流、好礼三重惊喜。 不管你是深耕 PostgreSQL 的技术大牛,还是关注国产开源数据库的行业同仁,来这里既能夯实技术功底,又能结识同行伙伴、链接优质人脉,绝对是一场不容错过的行业盛会! 4 月 27 日-28 日,大会主论坛与分论坛将正式拉开帷幕,更多干货与惊喜持续解锁。 大会火热报名中,欢迎各位伙伴继续报名锁定席位,共赴这场开源盛宴。4 月 26 日 会前付费培训|两大硬核专场,吃透 PostgreSQL 内核
✅ 培训一:共享缓冲区的炼金术——平衡并发与性能
培训简介
核心收获
培训形式
✅ 培训二:PostgreSQL 内核培训串串烧
培训简介
培训报名通道
IvorySQL 专家委员会会议|智库齐聚,共话生态未来
大会专属礼品|限量定制,诚意满满
每一份礼品都藏着我们对开源生态的致敬,还有对技术人的感谢,来参会就能领取!盛会集结,共赴开源
近日,开放原子开源基金会“以贡献为导向的开源人才评价机制”落地高校再结硕果,在《关于复旦大学2025年度教育评价改革实践与创新成果评选拟获奖名单的公示》中,复旦大学计算与智能创新学院紧扣该评价机制核心要求申报的《以“开源人才评价机制”为基,探索开源人才发展新模式》,与《奖学金评审自主申报和科研创新能力考核机制改革》两项实施方案同步入选优秀实施方案。计算与智能创新学院此次成果入选,是学院深度落地开源人才评价理念,全面推进新时代教育评价改革,落实“干细胞式”拔尖创新人才自主培养目标,深化教育教学改革3.0建设的重要实践,更是基金会与高校协同探索开源人才培养与评价新模式的典型成果。
一、以“开源人才评价机制”为基,探索开源人才发展新模式
计算与智能创新学院作为学校重点建设的工科创新学院之一,立足计算机学科50年办学底蕴,以开源人才评价机制为牵引,将开源实践深度融入本研融通长周期培养体系,走出一条开放协作、产学协同、评价多元的拔尖人才培养新路径。
学院确立“淡化绩点、突出多元化专业能力培养”导向,构建多层次、全链条开源人才培养与评价体系:在组织保障上,成立开源实践专项工作组,建设开放原子开源社团,设立多个技术方向兴趣小组,推动课题组轮转与开源项目深度结合。在课程建设上,将开源内容融入操作系统、数据库、大模型等核心课程,推出高质量开源教材,把开源鸿蒙、开源欧拉等产业真实项目转化为教学案例。在实践平台上,搭建“校内实践+社区参与+企业合作”体系,依托开源先锋激励计划、复芏计划(FDUROP)、开源之夏等项目,支持学生在真实场景中提升协作与开发能力。在评价改革上,学校作为首批开源人才评价试点单位,将开源贡献正式纳入奖学金评定、推免综合评价体系,优秀开源贡献者可通过专家评审赛道获得认可。
2025年10月,首届复旦大学“开源先锋激励计划”顺利举办,覆盖多院系学生团队与个人,一批高质量开源项目获奖。以贡献为导向的评价机制,有效打破传统评价壁垒,引导学生从“追求分数”转向“提升能力”,在开放协作中锤炼技术、增长才干,形成具有复旦特色的开源人才培养生态。
二、奖学金评审自主申报和科研创新能力考核机制改革
计算与智能创新学院针对传统奖学金评审赛道单一、“唯分数”倾向明显、科研创新评价标准模糊、专业教师参与不足等问题,实施系统性改革,构建更加科学、公平、导向清晰的评审体系。
改革坚持问题导向与育人导向,重点推进三项关键举措:一是优化自主申报机制,增设专家评审赛道。设立常规赛道与专家评审赛道,学生自主选择申报方向,科研创新突出的学生可提交材料并参加专家答辩,真正让有创新潜力的学生得到认可。二是统一科研创新能力评分标准,强化班导师评审职责。制定详细赋分标准,细化科研项目、学科竞赛、学术成果、专利、实习等20余项评价指标,班导师深度参与材料审核、评分与意见评定,提升评审精准度与公信力。三是构建多元评审体系,保障全过程公开公正。常规赛道突出综合素养,高年级提高创新能力权重;专家赛道由资深教授把关答辩;畅通申诉渠道,全程公开透明,实现“以评促学、以评促创”。
改革实现“双突破、双强化”:突破单一赛道限制,强化多元评价导向;突破评价标准模糊瓶颈,强化班导师育人与评审作用。实施以来,评审公平性与学生认可度显著提升,有效激发了本科生参与科研实践与创新活动的积极性,为理工科院系奖学金评审改革提供了可复制经验。
在“每一枚 Token 都要精打细算”的共识下,AI 圈一度流行一种略带调侃的说法:真正的高手,不是把 Token 用在写代码上,而是用在更高杠杆的事情上。 最近,这一理念被再次推向台前——主角是患上了“AI 精神病”的 Andrej Karpathy。 前阵子,Karpathy 在 X 上分享了一套自己正在实践的工作流,称之为“LLM Wiki”:他不再把大模型主要用于写代码,而是将绝大多数 Token 消耗,转向构建一个围绕个人研究兴趣的“可演化知识库”(以 Markdown 和图片形式存储)。 这条帖子在 x 上浏览量超 1700 万,围观者众多。 项目地址:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f Karpathy 详细介绍了 LLM Wiki 项目的工程实现、数据采集、工具选择等技术细节。 从工程实现上看,Karpathy 的方法并不依赖复杂的基础设施,甚至可以说极其“朴素”。一切始于一个名为 raw/ 的原始目录。在这个目录中,他将与研究主题相关的所有素材一股脑地收集进来——包括论文、技术博客、代码仓库、数据集,乃至图片等多模态内容。这一步并没有任何结构设计,核心目标只有一个:最大化原始信息的完整性。 接着,Karpathy 调用 LLM 对这些素材进行增量“编译”,生成一个 Wiki。这个 Wiki 本质上是一个具备清晰目录结构的 Markdown 文件集合,类似一个由 AI 自动撰写和维护的知识百科系统。 Karpathy 把Obsidian作为这个系统的“前端 IDE”,在这里他可以查看原始数据、编译好的 Wiki 以及衍生的可视化内容。Karpathy 介绍,这么做的核心点在于:Wiki 中的所有数据都由 LLM 编写和维护,自己极少直接动手修改。 他还尝试了一些 Obsidian 插件来以不同方式展示数据,比如用 Marp 插件生成演示幻灯片。 当知识库规模逐渐扩大,这一系统开始展现出更强的能力。Karpathy 提到,在一个包含约 100 篇文章、总计 40 万字的研究项目中,他已经可以直接向 LLM Agent 提出复杂的系统性问题。与传统认知不同,他并没有引入复杂的 RAG 架构,而是依赖 LLM 对 Wiki 的“内生理解”能力——模型通过自动维护的索引与摘要,可以高效定位相关信息并进行综合分析。 这一点尤为关键。过去一年,RAG 几乎成为企业级 AI 应用的“标配”,但 Karpathy 的实践表明,在中等规模的数据集上,LLM 本身已经具备足够强的“自检索”与“自组织”能力。这意味着,一部分复杂的系统设计,可能正在被模型能力的提升所“吞噬”。 在输出层面,Karpathy 同样不满足于传统的文本回答。他将 LLM 生成能力进一步扩展到多种格式:包括 Markdown 文档、基于 Marp 的演示幻灯片,甚至是通过 Matplotlib 绘制的数据图表。这些结果统一在 Obsidian 中进行可视化呈现,使知识不再停留在“答案”,而是转化为可以复用、传播和沉淀的资产。 更重要的是,这些输出并不会被丢弃。相反,它们会被重新归档进 Wiki,成为知识库的一部分。换言之,每一次提问与探索,都会对系统进行“增量训练”——尽管不是传统意义上的模型训练,但在知识层面,系统的能力确实在持续累积。 为了维持这一系统的长期健康运行,Karpathy 还设计了一套“自动化运维”机制。他会定期调用 LLM 对整个 Wiki 进行“体检”:检测数据不一致、补全缺失信息、通过联网搜索引入新资料,甚至主动挖掘潜在的关联关系并生成新的专题文章。 此外,他还通过“Vibe Coding”的方式快速开发了一些辅助工具。例如,一个用于检索 Wiki 的简易搜索引擎,可以通过网页界面或命令行调用。在更复杂的场景下,这些工具甚至可以作为 LLM 的外部能力接口,由模型自主调用完成任务。 随着知识库规模的进一步扩大,Karpathy 也在思考下一阶段的演化方向:是否可以通过合成数据生成与微调,将这些结构化知识“压缩”进模型权重之中。换句话说,从依赖上下文窗口的外部知识系统,迈向模型内部的长期记忆。 简单总结一下,该架构设计极简,仅包含三个组件: 1、一个 Markdown 文件文件夹。 这是你的知识库。它可以包含任何内容:研究笔记、会议纪要、项目文档、读书笔记、个人参考资料、带有解释的代码片段。 2、每个文件内部结构一致。优秀的 LLM Wiki 文档采用一致的内部格式——标题、简短摘要、标签主题以及正文内容。模型利用这种结构更快地找到相关信息。 3、使用 Claude Code 作为查询界面。打开终端,导航到你的 wiki 文件夹,启动 Claude Code,然后向它提出问题。Claude 会读取所需的文件,综合生成答案,甚至可以根据你的要求更新或添加注释。 就是这样,无需数据库,无需向量嵌入也无需服务器。只需文件和一个功能强大的模型。 Karpathy 的这一实践之所以能够迅速引发关注,是因为它并非只是一个效率工具的升级,而更像是对“个人知识管理”(PKM)体系的一次重构。从 Notion、Roam Research 到 Obsidian,过去十年里,人们始终在寻找更好的知识组织方式,而在 LLM 的加持下,这一问题的解法,正在从“如何记录”转向“如何自动生成与演化”。 因此有 X 用户认为,LLM Wiki “杀死了”RAG。 过去三年,为 LLM 提供专有数据访问的主要范式是检索增强生成(RAG)。在标准的 RAG 设置中,文档被分割成任意的“块”,转换为数学向量(嵌入),并存储在专门的数据库中。 当用户提出问题时,系统会执行“相似性搜索”来查找最相关的数据块,并将它们输入到 LLM 中。Karpathy 的方法,他称之为 LLM 知识库,摒弃了中等规模数据集的向量数据库的复杂性。 相反,它依赖于 LLM 对结构化文本进行推理能力的不断提高。 系统架构(由 X 用户@himanshu在对 Karpathy 帖子的广泛回应中可视化呈现)分三个不同的阶段运行: 数据导入:原始资料——研究论文、GitHub 代码库、数据集和网络文章——被导入到一个 raw/目录中。Karpathy 使用 Obsidian Web Clipper 将网页内容转换为 Markdown.md 文件,确保即使是图像也存储在本地,以便 LLM 可以通过视觉功能引用它们。 编译步骤:这是核心创新点。LLM 不仅仅是对文件进行索引,而是对文件进行“编译”。它读取原始数据并生成结构化的维基百科页面。这包括生成摘要、识别关键概念、撰写百科全书式条目,以及——至关重要的是——在相关概念之间创建反向链接。 主动维护(代码检查):该系统并非一成不变。Karpathy 描述了运行“健康检查”或“代码检查”的过程,LLM 会扫描 wiki 以查找不一致之处、缺失数据或新连接。正如社区成员 Charly Wargnier 所观察到的,“它就像一个活的 AI 知识库,能够自我修复。” Karpathy 将 Markdown 文件视为“真理之源”,从而避免了向量嵌入的“黑箱”问题。AI 做出的每一项声明都可以追溯到特定的.md 文件,而这些文件可以由人阅读、编辑或删除。 在 Youtube 上,也有不少关于 “LLM Wiki killed RAG”相关话题的讨论。 一位 ID 名为 DIY Smart Code 的博主阐述了为什么他认为有了 LLM Wiki 后,就不再需要 RAG 了。 该博主表示:“人类并不缺少信息,缺的是对信息的持续组织与有效利用。” 研究显示,人类在获取新知识后的短时间内就会遗忘其中的大部分内容,而现代知识工作者每天平均需要花费近两个小时,去查找那些“自己曾经读过”的信息。这不仅意味着巨大的时间浪费,也揭示了一个现实困境——无论是笔记工具、收藏夹,还是所谓的“第二大脑”,在长期使用后,往往都会演变为一个信息堆积却难以调用的“知识墓地”。 过去几年,AI 行业尝试通过 RAG 等技术路径解决这一问题,即通过向量数据库对海量文档进行索引,在需要时检索相关片段并生成答案。然而在实际应用中,这类方案往往面临落地难题:检索可以做到,但理解不足;信息可以找到,但难以形成结构化认知。某种程度上,这类系统只是让用户“更快地搜索混乱”,却没有真正解决知识组织的问题。 Karpathy 的思路则截然不同。他并没有继续优化“检索”,而是从源头出发,提出“写出更好的文档”。在他的体系中,原始数据被视为“源代码”,大语言模型则充当“编译器”,而最终生成的 Wiki 知识库,则是可以直接使用的“可执行产物”。 在这种情况下,基本就不会再需要 RAG 了。 虽然 Karpathy 自己将 LLM Wiki 描述为“一堆蹩脚的脚本”,但它在技术社区和企业级市场还是引发了不少的关注。 企业家 Vamshi Reddy (@tammireddy) 在回应 Karpathy 帖子时表示:“每个企业都有一个原始目录。从来没有人把它整理过。这就是产品。” Karpathy 对此表示赞同,并认为这种方法代表了一种“令人难以置信的新产品”类别。 目前大多数公司都“淹没”在非结构化数据中——Slack 日志、内部维基和 PDF 报告,没有人有时间去进行综合分析。 “Karpathy 式”企业层不仅会搜索这些文档,还会主动编写实时更新的“公司圣经”。 AI 教育家兼简报作者Ole Lehmann在 x 上发帖称:“我认为,谁能把这个功能打包成普通用户都能用的东西,就掌握了一项巨大的技术。一个应用就能与你已经使用的工具、书签、稍后阅读应用、播客应用、保存的讨论串同步。” AI 企业 Agent 构建和编排初创公司 Edra 的联合创始人兼首席执行官 Eugen Alpeza 在一篇 X 帖子中指出: “从个人研究维基到企业运营的飞跃才是真正的挑战所在。成千上万的员工,数百万条记录,以及团队间相互矛盾的经验知识。的确,企业级市场需要一款新产品,而我们正在打造它。” AI 代理创建平台 Secondmate 的创始人 @jumperz 最近发布的一份架构分解报告,通过“群体知识库”展示了这一演变过程,该知识库将 wiki 工作流程扩展到通过 OpenClaw 管理的 10 个代理系统。 另一位 x 用户还将 Karpathy 的脚本方案成功“产品化”了。她推出了一款名为:Claudeopedia(Claude 百科)的产品,并说明了她构建该产品的几大步骤,她写道: 1、我采纳了 @karpathy 的 “llm-wiki” 构想(这占了本项目 90% 的功劳,所以大头要归功于 Karpathy); 2、结合了过去 30 天的技能(感谢 @mvanhorn 的灵感); 3、新增了一个 /wiki 技能,支持截图和下载参数,能更飞速地传输原始素材; 4、构建了一个交互式可视化界面来搜索我的知识库(甚至带日期范围,可以对比知识随时间演进的变化!); 5、设置了一个“质疑自我假设”的定时任务(cron job),自动将我最近的随笔和客户邮件与 Wiki 内容进行比对复核。 目前这一切都在 Obsidian 中运行。包括测试在内,所有这些都是在这个周末搞定的。我会继续添加更多功能。我重点构建的是:企业级 AI。我已经非常期待了。 整体来看,Karpathy 提出的这一方法的意义不仅在于提升效率,更在于重构知识工作的底层逻辑。当大模型能够持续维护并扩展一个结构化知识体系时,传统意义上的“笔记”正在演变为一种动态系统。对于个体而言,这意味着可以将认知能力部分外包给机器;而对于行业而言,这也预示着一个潜在的新产品方向——将“知识编译”本身,作为核心能力进行产品化。 在信息不断膨胀的时代,这种从“存储信息”到“演化知识”的转变,或许正是下一阶段 AI 应用的重要突破口。 参考链接: https://www.youtube.com/watch?v=RQsLXmenr48 https://x.com/NickSpisak_/status/2040448463540830705 https://x.com/alliekmiller/status/2040884878229565816 https://www.mindstudio.ai/blog/andrej-karpathy-llm-wiki-knowledge-base-claude-codeKarpathy 新项目爆火,技术细节完整披露
LLM Wiki “杀死了”RAG?
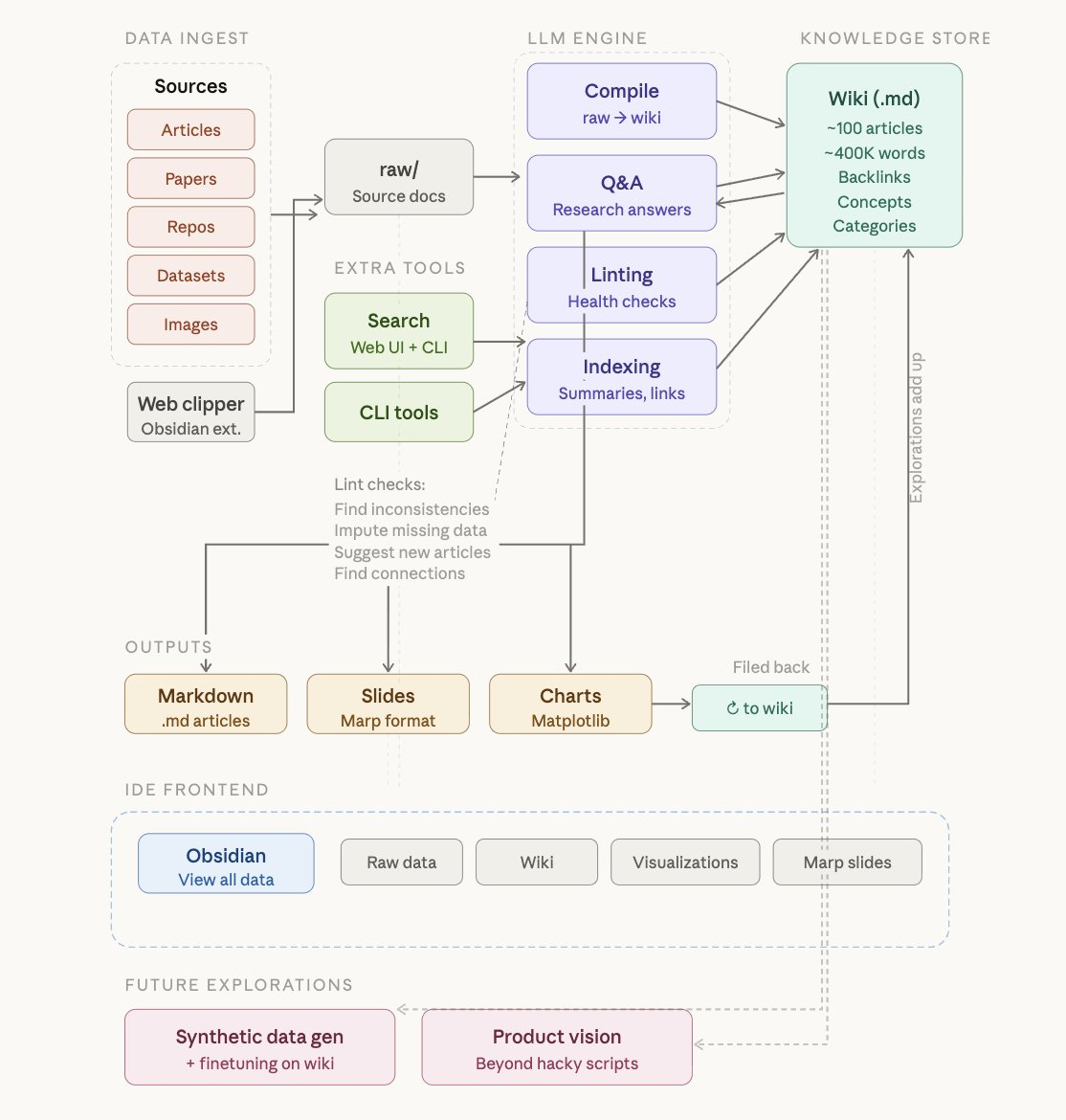
技术社区和企业反响热烈

这篇文章是 TDS Studio 在少数派上的第 21 篇文章,依然是全平台首发。
本来近期这两个蓝牙新品(AirPods Max 2 和 Galaxy Buds4 Pro)我们真的考虑过要不要出完整的 TDS REVIEW,AirPods Max 2 真的是没有解决这个形态最基本的问题,Galaxy Buds4 Pro 则是因为手上现在确实没有什么留存的三星新设备来测试 SSC 编码了。到店试听过后,我们还是购入了 Galaxy Buds4 Pro,并租借了一台 Galaxy S23 Ultra 来给大家带来完整体验内容,它的变化我觉得还是非常正面的——尽管代价是价格也来到了新高。

Galaxy Buds4 Pro 的包装依然是这套非常小巧的灰黑色纸盒,表面摸上去有一种特殊的细腻磨砂质感,并且有一次性封条。内部配件仅包含三对替换耳套,现在连线材都不提供了。
Galaxy Buds4 Pro 这次共有三种配色在售,为了和第三代时期保持一致,这次我们购买的依然是旷宇黑,呈现出一种灰度比深空灰更甚而算不上完全黑色的状态,映雪白则与之前观感没有什么区别。此外,还有一种三星商城和京东限定的绯霞金配色,大概也是为了与新的手机配色相关,观感上近似于橙色到粉色的过渡,比很多人熟悉的玫瑰金要更加偏粉,同时饱和度偏低。

充电盒的体积不大,且恢复成了过往 Galaxy Buds 产品的上下翻盖结构,上半部分则是第三代引入的透明塑料。单手开合会显得有点滑,且这个透明材质虽然有一定硬度,我们还是建议买个保护套防刮擦。

自从上一代 Galaxy Buds 变成「名为 Buds 的 Pods」之后,三星就把自己的耳机形状全部都加上了柄——形成鲜明对比的则是老 One UI 版本的蓝牙设置界面上依然是以前豆式 Galaxy Buds 的图标…… Buds4 Pro 依然是带柄的 pods 式佩戴,且不会像上一代那么棱角分明,从外侧看来是一体化的拉丝金属面板,而操作区域则也移到了和 AirPods 系列一样的侧面靠前这一块平面上。金属面板与顶部的麦克风开窗区域衔接,前腔则是比较常见的椭圆形而非 AirPods Pro 系列常用的扁圆形。这个塑料前腔明显更容易沾染皮肤油污,好在算是容易清洁。单侧耳机重量 5.1g,不会有坠耳感。对于大部分能够佩戴好 Galaxy Buds3 Pro 和前两代 AirPods Pro 产品的用户来说,Buds4 Pro 都不会对佩戴造成额外影响,大体上是比较普适的,且就我个人来说,暂时也没发现咀嚼动作会影响佩戴稳定性的情况出现。另一方面,得益于柄部的平面结构,你在侧躺时划伤耳机或者硌到耳廓的概率也会变低,尽管依然是不建议侧躺佩戴。

支持 IP57 防尘防水,在 TWS 领域算相对不错的,日常运动和小雨使用无碍的同时,也有一定的进一步防水能力——可浸入一米深的淡水中 30 分钟。
Galaxy Buds4 Pro 的操作依靠侧面的触控区域识别实现,可识别单击、双击、三击和长按,默认逻辑是单击播放控制、双击下一曲、三击上一曲以及长按切换降噪模式,也有上下滑动调节音量的设计。你也可以在三星智能穿戴 app 里进行自定义,比如调用 Bixby 或者同传翻译等等。捏取的操作现在已经是比较容易习惯的操作了,但是 Buds4 Pro 在侧面识别区域设计的下凹盲操结构实在太浅,导致刚开始可能会捏不到位。它同样具备触觉反馈,跟手程度仅次于果系,多次按压的灵敏度在习惯后就会觉得没有什么问题。默认语音提示的响度适中。

入耳检测功能是在摘下或戴上动作完成后一秒左右激活,所以会有一点滞后感,它的入耳检测没有办法完全关闭,只能在 app 里进行通话和媒体的状态定义——这也给续航测试带来一些困难。One UI 8.5 及以上版本支持点头摇头等操作。

在(仅安卓端支持的)三星智能穿戴 app,你可以通过符合 One UI 标准的界面来进行各项设置,这个 app 在三星机型上会造成与蓝牙设置界面一定程度上的功能区分,不过好在观感上没有出现割裂感。在系统蓝牙界面已经可以进行简单的降噪状态切换、Auracast 调用以及编码切换了,固件升级、降噪等级细调、控制相关则在 app 里。它也具备查找耳机的功能,只是单纯的铃声提示,即使是把耳机放在面前,在相对安静的室内环境下也不够响,我觉得这点还需要进行改善。

借助 360 音频的内置陀螺仪,你也可以打开它的颈部伸展提醒功能,算是 Buds4 Pro 的健康部分功能,但是在开启之后,我这种长期伏案办公的状态似乎在三星的理解下并没有达到那个需要提醒我进行颈部活动的「低头阈值」,所以正常使用很难真正被提醒到——与此同时其他类似产品已经在类似的工作姿势下提醒多次了。

我们也顺便体验了基于 One UI 内置翻译功能的同传,在中英文交谈的过程中,它基本上是在一方对话结束后进行快速翻译,而非真正的实时跟译。依托于三星耳机和手机之间本身的紧密连接,我们觉得它对于屏幕上的翻译结果返送还是非常快速的,但本身软件端的语音识别和翻译正确率就只能说见仁见智。
三星 Galaxy Buds4 Pro 的降噪综合来看是有一些提升的,但是属于 Skyline Level 内的小进步,并不是质的突破。被动隔音依然是柄式入耳 TWS 的通常水平,并不会像 AirPods Pro 3 那样依靠腔体造型的改变和泡沫耳套的搭配来实现强隔音,所以大体上与上一代类似。
开启主动降噪之后,app 默认会开到最高一档,实际你则可以在五档中进行调节。我们在第五档下评价它的极限主动降噪水平。它对于低频稳定噪音的处理是非常明显的,深度足够高,能够稳定地排在 Skyline Level 中甚至略靠前的位次上,比 Buds3 Pro 在中低频的总体深度上进步明显。频宽覆盖上则与 Buds3 Pro 近似,大体上可以覆盖人声中下盘,能够有明显有效的人声抑制。总体来看,同为最深度降噪状态,它的降噪综合感知比 Buds3 Pro 有实际提升。

值得注意的是,在第三档到第五档的范围内,你可以感知到随着档位加深而愈发明显的轻度底噪,虽然在嘈杂环境不是问题,但室内安静环境还是清晰可闻的——即使是我这样的底噪不敏感人群有时也会不得不被动捕捉到这个底噪的存在。它的降噪耳压感即使在最高档,在同类产品中也相对不算严重,但对于初次佩戴者,第四档、第五档降噪下的耳压感还是会有轻度不适,需要注意。
抗风噪方面,这一代依然没有单独的风噪抑制模式,我们在第五档降噪开启时进行测试,它在正对、侧对风源的方向上会有一定的风噪感知,背对则相对影响较少,且五个档位的降噪、自适应状态下都有类似的感知。环境音开启之后依然如此,但似乎环境音模式下会对于风噪有一定的自适应能力,在一段时间过后风噪影响会有轻微降低,能够达到不太影响环境音收听的程度。
自适应这一档在室内通常会被自动切换至与环境音第一档类似、但会适当有一些低频和高频噪音抑制感的状态,对于人声频段的抑制较弱而空调、电扇等噪音有减弱感。它还有一个独立于自适应档的自动切换至环境音功能,可以在识别到警报或对话时自动切换到环境音模式,小声自言自语这种场景通常不会被识别到。

环境音模式方面,从 Buds3 时代开始,三星就走上了自然度和放大效果都可选的路径上。在 Buds4 Pro 上,环境音也依然有五档可选,且五个档位都相对自然,在对于环境音的还原上做得不错,不会有明显的某频段突出或压暗。语音可用性和自然度、还原度都不错,佩戴者自己的语音也不会有偏闷的问题。
在辅助模式中,你可以打开「环境音的听力增强」,针对单侧或双侧进行手动环境音量调节,甚至选择增强面前的声音,这就是近似助听器的逻辑了。在打开这一项之后,它默认会把中高频过渡频段增益,敲击键盘、脚步声等环境噪音增强。而针对于面前声音的增强,则对于想要在面对面交谈中降低环境噪声、专注于对话语音的听力减弱人群有很大作用,这一点也与它多麦克风的阵列相关。总之听力辅助相关的方面,目前三星依旧是第一梯队。
通话方面,它在与部分新三星设备连接时支持 16kHz 超宽带(SWB)通话功能,但由于我们手上并没有最近两代的三星设备,所以还是以常规运营商网络环境来进行判断。它的收音响度默认中规中矩,清晰度还是不错的,但依然有一点偏闷。风噪对于通话的清晰度影响不会特别大。值得一提的是,在搭配 Galaxy Buds4 Pro 进行录像时,三星手机可以进行 3D 声音录制,这显然也与它的六麦克风有关。

综合来看,三星 Galaxy Buds4 Pro 的降噪相关各项水平较上代是有进步的,按照当下的市场来看,属于新降噪旗舰应有水平。降噪深度和频宽、环境音自然度与语音可用性以及自适应等各方面没有明显短板,唯二的问题在于目前固件下的轻度底噪和风噪抑制并不完美。
在新一代的旗舰 TWS 中,我们认为它在降噪综合感知方面基本上仅次于 AirPods Pro 3、WF-1000XM6 以及 Bose QC Ultra 2,与 FreeBuds Pro 5 大体水平近似,略好于 AirPods Pro 2,明显好于 WF-1000XM5、vivo TWS 5 以及自家的 Galaxy Buds3 Pro。通透/环境音方面仅次于 AirPods Pro 3/2,与 WF-1000XM6 共同构成仅次于果系的最佳环境音综合表现。我们认为它可以列入 TDS 降噪综合能力金字塔的 In-Ear Skyline Level,并且排位靠前。
作为最早搭载蓝牙 6.1 版本的耳机产品之一,三星 Galaxy Buds4 Pro 的信号测试将围绕它在 SSC-UHD 96kHz 模式下连接三星 Galaxy S23 Ultra 手机的环境下进行。
来到我们熟悉的信号测试环境,无论 WLAN 关闭还是开启的情况下,近场卡顿丢包情况都比较少。距离 7.5m 且隔承重墙的状态下开始丢包,在 8m 左右的距离,中断开始明显影响体验。需要注意的是在 96kHz 状态下,即使是近场连接,也可能会隔十几分钟不太规律地复现一下左右跳读。我们也在 AAC 编码连接标准测试终端 iPhone 14 的状态下进行了 AAC 信号测试,基本上无需担心常规环境的稳定性,但是在高铁站等场景还是会有轻度的丢包卡顿。对于三星生态内用户,96kHz 选项日常可以考虑常开,其他手机用户也只能保持 AAC 了。

延迟方面,我们同样在 SSC-UHD 96kHz 模式下连接三星 Galaxy S23 Ultra 手机测试,进行流媒体视频和本地视频观看,它的延迟大概控制在正常语速半个字以内。而在 AAC 连接 iPhone 14 时,它的延迟大概控制在略多于半个字,在 AAC 阵营已经算还不错的了。
双设备连接支持,但是跨生态的切换并不是那么无缝。
续航方面,三星官方宣称单次连续播放时间 6/7h(开启/关闭降噪),搭配充电盒为 26/30h(开启/关闭降噪)。按个人标准流程测试下来,开启主动降噪、颈部提醒和自适应声音,不开启 360 音频、听力增强,以 SSC-UHD 96kHz 模式下连接三星 Galaxy S23 Ultra,以 50% 音量连续播放流媒体音乐(Apple Music Lossless)、播客节目(小宇宙),仅耳机续航为 4 小时 57 分钟,与官方描述有差距——官方没有给出测量条件,因此我们推测是基于 48kHz SSC 编码。

它也支持快充和 Qi 标准的无线充电。我们测试了 USB-C 有线充电以及无线充电的实际情况,参见下表。
第三方充电兼容性测试结果 | ||
充电类型 | 充电器 | Galaxy Buds4 Pro |
Qi 无线 | TESTV 快乐能量停机坪 | 主充电位 2W,副充电位放不下 |
绿联 Qi2 二合一 W702 | 主充电位 2.6-2.8W,副充电位放不下 | |
有线 | ANKER Nano II 100W | 三口均支持(2.5W 左右) |
备注 | / | 无线充电有轻微磁吸能力,但并非 MagSafe 标准 |
Galaxy Buds4 Pro 搭载了「增强型双路扬声器」,其实大概就理解为双动圈架构即可,具体的参数未知。需要注意的是,按照三星的介绍,低频动圈的振膜面积较 Galaxy Buds3 Pro 增加了 19.8%。所谓双功放,可以理解为低频单元和高频单元各自配有独立放大芯片。
支持的编码为 SBC / AAC / SSC / SSC-UHD (96kHz) / LC3。符合惯例,它在 SSC 96kHz 编码连接三星手机时的声音表现跟 AAC 连接其他手机的声音区别(或者说 AAC 下的劣化)还是比较明显的,这也是我们评价三星耳机必须结合三星智能设备进行的核心原因,但是这次 AAC 调得并不算难听,只是显得略糊一些而已。额外地,在开启环境音之后,耳机会倾向于给多一些低频量,或许是考虑到频段掩蔽问题的缘故吧。但是降噪和自适应下也同样低频会多一点,说明降噪对于声音的影响在它身上还是可闻的。
APP 内可以在六种预设中进行选择,也支持对于八个频率点、±10dB 的 EQ 调节。

三星的「空间音频」依然是基于立体声声源渲染的「360 音频」,显然不能用 Dolby Atmos 流程进行评价。在打开之后,的确横纵向声场会有比较明显的拉伸感,空间感会变得更加宽阔,脑后也有一定的信息量,但高度方向上的信息依然比较缺乏。中高频有些频段会有突出,其实不太适合常规立体声音乐的欣赏,我们仅建议在一些影音场景开启使用。头部追踪在不同码率连接下的灵敏度也有不同,在 SSC-UHD (96kHz) 连接下,头部追踪显然滞后,跟随精度偏低。好在回到 48kHz 之后头部追踪的灵敏度就会好不少——依然与果系有微小差距。
基于 SSC 编解码器 UHD 96kHz 模式,开启自适应和降噪,不开启游戏模式、360 音频,均衡器「平衡」。
低频量感适中稍偏多一点,厚度和饱满度都足够,弹性表现不错,下潜相较于上代有一些提升。收放速度适中,保留了轻度的残响。氛围烘托的晕染感较轻,但是浓郁度是有的。Galaxy Buds4 Pro 在低频频段的听感是比较饱满扎实的,有能量、有厚度,这让它即使在默认 EQ 下也会有一点 basshead 的趋势,但实际上更多的能量是位于极低频而非中低频过渡频段,所以并没有到我们标准下非常轰头的程度。基音位于中下盘的乐器有轻微的前倾。
中频,人声距离适中,但是口型会稍微大一点,精致程度适中。对于人声质感的重视程度稍高于线条刻画,线条突出程度有一些克制感,厚度则也不算很高。对于男女声之间的倾向性不算明显,适合的声线类型相对较广,但是一些过于偏细的声线会觉得缺一点亮感。颗粒感有轻度的打磨,但并不会完全磨平,顺滑程度还不错。音色渲染有轻微的暖感,但实际上更多是线条不突出造成的感觉,你还是可以把它归到广义中性的范畴内。喉音位置大体没问题,气声比例合适。口水声等细节有压制痕迹,齿音等也不会有明显的增强。人声总体通透度中规中矩,没有明显的人为增亮。

乐器方面,大部分乐器也是质感优先于线条。弦乐器中,小提琴、吉他、中提琴等有一定的厚度,拉拨弦的细节丰富度还不错,抓耳感则不强。大提琴的形体感会比上代更加清晰,且在空间里占比例比较大。额外指出,在同为低频比较多的这几个新旗舰 TWS 里,贝斯的清晰度它是比较好的。铜管类的气势感不错,需要亮度的小号等不会有张扬的亮感。木管类的自然度尚可,空气感不算突出。乐器的泛音有一些厚度,相对自然但不会强调。打击乐器中,Kick 的存在感足够,Snare 收得不快不慢,镲片类的亮度不算高,刺激感和金属感不会有溢出问题。
高频总体亮度不算很高,有一些强度不高的峰值,属于大体上比较平滑的状态。极高频的延伸比印象中的上代好一点,但量仍然算不上多。滚降稍快但不过于偏早。

空间感的呈现上,Galaxy Buds4 Pro 可以呈现出规模不太大的、横纵距离类似的空间,边缘的弥散感不强。结合适中的「高度感」,Galaxy Buds4 Pro 的空间大体上是个扁球状。人声与乐器之间的分离度良好,整体感比上代进步明显。解析能力在同价位的 TWS 里不算出众,但是仅在手机厂配套旗舰 TWS 里横向来看,信息量算是中上游。好在没有明显的「解析感」强调,耐听度不错。动态不错,瞬态还可以。

总体看下来,我们认为 Galaxy Buds4 Pro 在很大程度上是比较全面的旗舰降噪 TWS 产品,在声音基本表现、信号、设计与佩戴、降噪综合性能等方面没有明显的短板,通话方面的表现和仅次于果系的环境音模式也属于加分项。三星的 TWS 目前最大的问题(或者在三星的视角看来也可以是「护城河」)仍然在于比较局限的编码支持,你很难把它推荐给三星生态以外的用户。尽管这次 AAC 的声音调得不会太糟,但对于大多数非三星的安卓用户来说,这个声音状态你会觉得并不符合近两千价位的应有水平,而有不错 AAC 水准的苹果手机,甚至没有三星智能穿戴 app 可以用。所以我们的评分也额外补充一句,这个 V 级更多为了三星用户而考虑。如果你主要使用其他品牌手机,有更好的选择。
本文所涉及型号在当时市场背景下的 KT MARK:
SAMSUNG Galaxy Buds4 Pro: V (Excellent)

降噪综合能力金字塔 | TDS ANC Pyramid:
SAMSUNG Galaxy Buds4 Pro: In-Ear Skyline Level
关于 KT MARK 评分机制以及利益相关的「不干涉评价原则」,请搜索《TDS Studio 评分标准与内容说明 V202502》,可以在主流搜索引擎直接搜索。
KingTsui, TDS Studio.
Apr 2026
It's a TDS production.
所有内容全部自主创作,请勿抄袭内容、套抄行文结构等,保留一切权利。
> 关注 少数派小红书,感受精彩数字生活 🍃
> 实用、好用的 正版软件,少数派为你呈现 🚀
企鹅公布财报的第二天下杀了 7%,茅台也太不给力了,才跌那么一点。目前的股息率有点诱人了,1402 元的时候加仓了一手,聊胜于无吧。
prompt:生成一张英雄联盟和王者荣耀的联动活动宣传海报
gpt-image-2

nano-banana-2

Git 与 Vim 堪称程序员的效率利器,但在 Vim 中开发时,频繁切换到终端执行 Git 命令(如 git status、git add -p、git commit),往往会打断编码心流、影响开发节奏。
现在,借助 LeaderF 内置的 Git 功能,你可以将完整的 Git 工作流无缝融入 Vim 环境,显著提升开发效率。
本文重点介绍一个核心命令:
:Leaderf git status
在 Vim 中输入上述命令,即可看到如下界面:
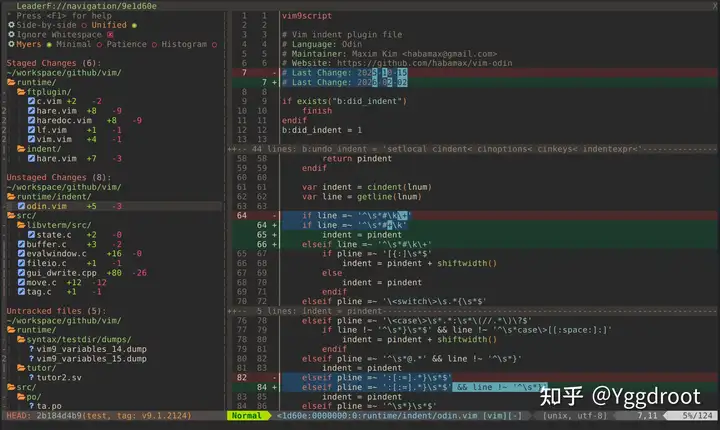
界面主要由两部分组成:
左侧为导航面板( Navigation Panel ),以文件树形式呈现 git status 的结果,并按状态分组:
右侧为Diff View 面板,用于展示文件的具体改动,支持两种视图:
Unified Diff View:
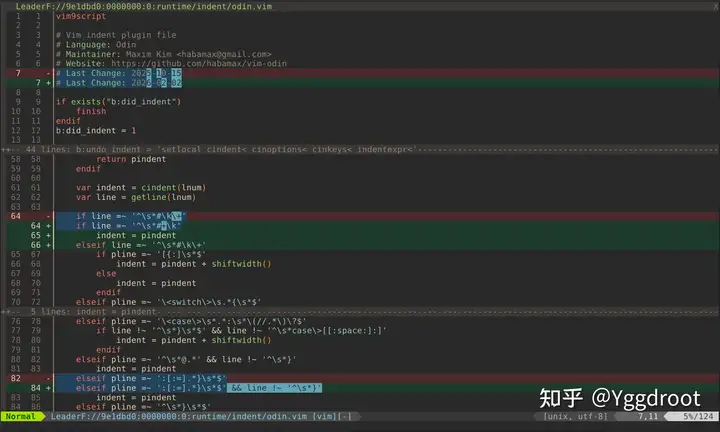
实现了字符级差异对比,并高亮显示差异部分。传统git diff没有高亮显示差异。
Side-by-Side Diff View:
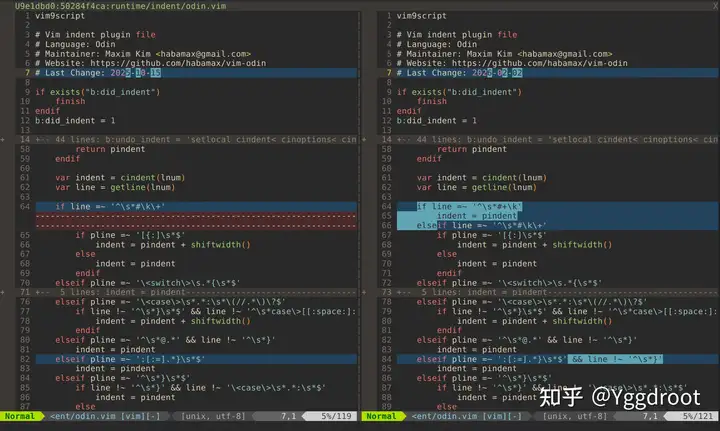
优点:更直观,适合详细对比代码差异
两个面板协同工作:
共同构成一套流畅的 Git 可视化工作流。
在导航面板中,可对文件执行以下操作:
| 快捷键 | 功能 | 说明 |
|---|---|---|
s |
Stage / Unstage 文件 | 在 unstaged 文件上执行,文件加入暂存区;在 staged 文件上执行,文件从暂存区移出来 |
d |
Discard 文件修改 | 丢弃文件修改(有确认提示) |
D |
强制 Discard 文件修改 | 丢弃文件修改(无确认提示,慎用) |
r |
刷新文件树 | 当外部修改了 Git 状态时刷新界面 |
Enter / o |
打开对应文件的 Diff 视图 | 查看文件的详细修改内容 |
注意:s、d、D 同样适用于目录操作(包括仓库根目录)。将光标置于目录上即可执行对应操作。
在 Untracked Files 上执行 d 或 D 会删除对应文件。
导航面板中还有其他快捷键,可按 F1 查看帮助。
在 Diff 视图中,可以精细操作每个 hunk (代码块):
| 快捷键 | 功能 | 说明 |
|---|---|---|
s |
Stage/Unstage 当前 Hunk | 在 unstaged 文件上,Hunk 加入 staged ;在 staged 文件上,Hunk 移回 unstaged |
S |
Stage/Unstage 所有 Hunk | 暂存或取消暂存当前文件的所有代码块 |
d |
Discard 当前 Hunk | 丢弃当前代码块的修改(有确认提示) |
D |
强制 Discard 当前 Hunk | 丢弃当前代码块的修改(无确认提示,慎用) |
]c |
下一个 Hunk | 跳转到下一个代码块 |
[c |
上一个 Hunk | 跳转到上一个代码块 |
更多快捷键介绍:
| 快捷键 | 功能 | 说明 |
|--------|------|------|
| < | 返回导航面板 | 若导航面板已关闭,则重新打开并将光标定位到 Diff View 对应的文件上 |
| Enter | 跳到对应的文件 | 跳到对应的文件进行编辑操作 |
如需自定义快捷键,可在 .vimrc 中修改下面配置:
let g:Lf_GitKeyMap = {
\ 'previous_change': '[c',
\ 'next_change': ']c',
\ 'edit_file': '<CR>',
\ 'open_navigation': '<',
\ 'stage_unstage_hunk': 's',
\ 'stage_unstage_all_hunk': 'S',
\ 'discard_hunk': 'd',
\ 'discard_hunk_no_prompt': 'D',
\ }
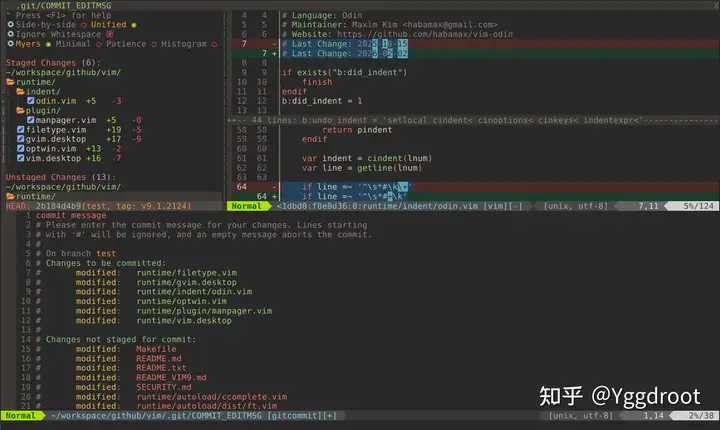
在导航面板中,若已暂存需提交的更改:
c 开始提交流程以下通过一个典型场景演示完整操作流程:
查看当前状态
:Leaderf git status
分析修改
bug_fix.py 查看具体修改]c 浏览所有代码块选择性暂存
s 暂存处理新功能文件
< 返回导航面板new_feature.py进行 reviewS 暂存所有代码块(新功能的修改应一并提交)提交更改
c 开始提交整个流程均在 Vim 内完成,无需切换上下文,保持流畅的编码体验。
| 操作 | 命令行 | LeaderF |
|---|---|---|
| 查看状态 | git status(纯文本) |
可视化文件树,直观清晰 |
| 分块提交 | git add -p(交互问答) |
直接按 s 选择暂存块 |
| 丢弃修改 | git restore <file> 或 git checkout -- <file> |
一键 d 或 D |
| 跳转改动 | 需肉眼查找 | ]c / [c 快速定位变更块 |
通过 Leaderf git status,你可在 Vim 中获得一套高效、直观的 Git 工作流:
全程无需离开 Vim
" 设置全局快捷键
nnoremap <leader>gs :<C-U>Leaderf git status<CR>
全文链接:https://tecdat.cn/?p=45568 关于分析师 在此对Hao Yang Ke对本文所作的贡献表示诚挚感谢,他在浙江财经大学完成了数理统计专业的硕士学位,专注机器学习、数据采集领域。擅长R语言、Python、机器学习、数据采集等。曾参与多个金融科技与数据分析咨询项目,为电商及保险领域提供数字化转型与风险模型构建建议。 摘要 电子商务交易规模持续扩大,欺诈风险也随之加剧。本文提出一种融合贝叶斯模型平均与Stacking策略的集成学习框架,用于提升复杂场景下的欺诈识别精度。研究对电商交易记录进行清洗与特征重构,采用WOE编码、随机森林重要性评估构建多维度特征集,结合SMOTE-ENN混合采样缓解类别不平衡问题。通过五折交叉验证训练决策树、LightGBM、K近邻等异构基模型,利用贝叶斯模型平均对基模型预测结果进行概率加权,最终以Stacking元模型实现集成优化。结果表明,BMA-Stacking模型在召回率与F1分数上显著优于单一模型及传统集成方法,SMOTE-ENN采样下召回率达80.98%,F1分数为83.02%,有效提升了对少数类欺诈交易的捕捉能力。该框架为构建鲁棒的电商风控体系提供了技术支撑。 关键词:电子商务欺诈;BMA-Stacking;集成学习;数据不平衡;贝叶斯模型平均 在数字支付与线上交易深度渗透商业活动的当下,欺诈手法亦呈现出智能化、隐蔽化的演化趋势。传统的规则引擎与静态阈值策略难以跟上多变的风险模式,尤其是在样本分布严重倾斜的场景中,少数类(欺诈交易)的识别性能常成为整体预警能力的短板。近期围绕模型融合与不确定性量化的研究为突破这一瓶颈提供了新路径:若能借助概率框架动态评估多个基模型的预测贡献,再通过元学习机制进行二次整合,便有望在保持整体准确率的同时,显著增强对欺诈样本的捕获效果。 本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。 全文以一条完整的技术链路展开,整体技术路线如下图所示: 图1 文章总体流程图 实证分析中常面临数据分布不均的挑战。在小样本场景下,常采用SMOTE算法通过插值生成新的合成样本;而在样本量较大时,则可结合TomekLinks剔除边界噪声。本文选用SMOTE-ENN混合采样策略,先过采样扩充少数类,再通过编辑最近邻清洗重叠区域,以平衡类别分布并改善模型学习能力。 Stacking是一种分层集成技术,第一层由多个异构基学习器构成,第二层元学习器对基学习器的输出进行再学习。其架构如图2所示。 图2 Stacking模型架构 本文构建的基学习器库涵盖树模型、支持向量机、近邻算法等,具体如表2所示。 表2 基学习器库 K折交叉验证将数据集等分为K份,轮流以其中一份作为验证集,其余作为训练集,取K次评估的平均值作为泛化误差估计。图3展示了5折交叉验证的分层示意。 图3 折交叉验证分层示意图(k=5) 贝叶斯模型平均(BMA)通过对所有可能模型的后验概率加权,得到组合预测分布。融入BMA的Stacking流程如图4所示:首先由基分类器产生预测矩阵,BMA计算后验权重并加权得到元训练集,最终由元学习器输出最终结果。 图4 融入BMA的Stacking预测流程 研究数据源自平台的电子商务欺诈交易记录,共计23634条样本,每条样本包含16个原始字段,其中“is_fraudulent”为目标标记字段。经过初步清洗与无关变量剔除,最终保留如表3所示的核心特征。 表3 电商交易数据集的基本特征 原始数据中的交易时间字段被转换为日期时间格式,进而衍生出“交易小时”、“星期几”、“月份”等时间维度特征。对于客户年龄字段中的异常值(如负值或小于9岁的记录),采用均值替换或绝对值修正。新增“地址一致性”特征用于标识收货地址与账单地址是否匹配。 图5 欺诈数据占比图 图6 欺诈数据分布图 由图5与图6可见,正常交易占比高达94.83%,欺诈交易仅占5.17%,呈现典型的类别不平衡分布,必须采用专门的采样策略加以校正。 相关文章 原文链接:https://tecdat.cn/?p=44060 图7 客户年龄分布图 图8 不同年龄是否欺诈分布图 交易主体集中于30至50岁人群,该年龄段的欺诈交易占比亦相对较高,提示风控策略应重点关注中年客群的交易行为。 图9 商品类别图 图10 商品类别中欺诈交易的占比柱状图 服饰与日用品的欺诈比例较高,说明日常消费品类是欺诈行为的高发区。 图11 欺诈交易总数时间分布图 图12 否欺诈每周频率分布图 图13 是否欺诈每季频率分布图 凌晨时段欺诈交易明显增多;按周统计,周四为欺诈高峰,周二最低;按季度观察,第四季度欺诈频率显著下降。这些时间模式可作为特征输入模型以增强预测能力。 分类变量采用WOE编码进行数值化转换,二值变量使用独热编码。通过相关矩阵热力图与随机森林特征重要性排序,筛选出对欺诈识别贡献度较高的变量。 图14 相关性热力图 交易金额、账户年龄与交易时间等特征与欺诈行为存在一定相关性。 图15 随机森林特征重要性排序 随机森林重要性排序进一步印证了上述特征的区分能力。剔除冗余变量后,最终保留高贡献度特征用于模型训练。 本文选取决策树、逻辑回归、LightGBM、GBDT与K近邻作为基学习器,采用贝叶斯优化算法对关键超参数进行搜索。相比网格搜索,贝叶斯优化能在更少的迭代次数内逼近全局最优解。各模型最终参数配置如表5所示。 表5 模型最终参数设置 以下代码展示数据清洗、特征变换、采样与基模型训练的完整流程。为符合学术可复现规范,变量命名与代码结构已做优化调整。 代码结构说明:上述代码遵循模块化设计,清洗逻辑独立封装,特征变换采用ColumnTransformer统一管理,采样策略可灵活替换。若在运行中遇到 图16 各模型的ROC曲线图 表6 分类算法的性能评估表 AUC值普遍较高,但召回率整体偏低,表明单一模型在极度不平衡数据下对欺诈样本的捕获能力有限。LightGBM在召回率与F1分数上表现相对最优。 表7 不同集成模型的结果(原始数据) 表8 不同采样方式下的集成模型结果 引入BMA动态权重后,SMOTE-ENN采样下的召回率由77.84%提升至80.98%,F1分数由79.12%提升至83.02%,验证了BMA加权机制在集成学习中的正向调节作用。 图17 贝叶斯后验权重分布图 权重分布图显示,GBDT与LightGBM获得较高后验概率,KNN的权重被合理压低,BMA在保留优势模型贡献的同时有效控制了弱模型的影响。 问:为何选择SMOTE-ENN而非单独使用SMOTE? 问:BMA权重与Stacking元模型是否功能重叠? 为确保结论的可靠性,本文从以下维度进行了稳健性检验: 变量设计合理性校验标准包括:①特征与业务逻辑的契合度(如凌晨时段欺诈高发符合实际风控经验);②特征间多重共线性检验(VIF均小于5);③时间外推性验证(采用前三个月数据训练,后一个月数据测试,AUC衰减小于3%)。 本文构建的BMA-Stacking集成框架在电商欺诈风险预警任务中展现出显著优势。通过WOE编码、随机森林特征筛选、SMOTE-ENN混合采样及贝叶斯模型平均的动态权重分配,模型在召回率与F1分数上均优于传统单一模型与常规Stacking集成。研究为高度不平衡数据下的分类问题提供了可复现的技术方案,后续可拓展至跨模态数据融合与在线增量学习场景。 阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。 本文配套的论文建模可直接套用的完整代码包、实证分析,可加小助手微信:tecdat_cn领取,我们可提供全流程的辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成科研、通过答辩。
原文出处:拓端数据部落公众号引言
数据采集与清洗
│
▼
特征衍生与编码
│
▼
不平衡处理(SMOTE-ENN)
│
▼
基模型训练与五折交叉验证
│
▼
BMA动态权重分配
│
▼
Stacking元模型集成
│
▼
性能评估与稳健性对比研究方法概述
不平衡数据处理
Stacking模型融合
类别 算法 作用 基于树算法 RF、GBDT、XGBoost、LightGBM、CatBoost 基学习器 支持向量机 SVM 基学习器 近邻算法 KNN 基学习器 神经网络 ELM、LSTM 基学习器 回归类 岭回归、Lasso回归、线性回归 基学习器/元学习器 K折交叉验证
BMA-Stacking模型构建
数据来源与预处理全流程
数据概况
编号 特征 特征含义 特征类型 1 amount 交易金额 数值型 2 method 支付方式 分类型 3 category 产品类别 分类型 4 quantity 购买数量 数值型 5 age 客户年龄 数值型 6 device_type 设备类型 分类型 7 transaction_day 日期天数 数值型 8 transaction_dow 星期几 数值型 9 transaction_month 月份 数值型 10 address_match 地址一致性 分类型 11 account_age_days 账户年龄 数值型 12 transaction_hour 交易小时 数值型 13 is_fraudulent 是否欺诈 分类型 数据清洗与特征衍生
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
探索性特征分析
客户年龄与欺诈交易
商品类别与欺诈交易
交易时间与欺诈交易
特征工程与编码策略
模型选择逻辑与代码实现
基模型与超参数优化
分类算法 参数值 AdaBoost learning_rate=1.0, n_estimators=153 逻辑回归 C=3.8 决策树 criterion=‘entropy’, max_depth=6, splitter=‘best’ KNN n_neighbors=5, weights=‘distance’, metric=‘euclidean’ GBDT learning_rate=0.3, max_depth=17, n_estimators=140 LightGBM learning_rate=0.2, max_depth=17, n_estimators=84, num_leaves=43 核心代码实现
# 数据读取与清洗函数
def process_transaction_data(raw_df):
# 转换日期字段
raw_df["Transaction_Date"] = pd.to_datetime(raw_df["Transaction_Date"])
raw_df["Trans_Day"] = raw_df["Transaction_Date"].dt.day
raw_df["Trans_Weekday"] = raw_df["Transaction_Date"].dt.day_of_week
raw_df["Trans_Month"] = raw_df["Transaction_Date"].dt.month
# 年龄异常值处理
age_avg = np.round(raw_df["Customer_Age"].mean(), 0)
raw_df["Customer_Age"] = np.where(raw_df["Customer_Age"] <= -9,
np.abs(raw_df["Customer_Age"]),
raw_df["Customer_Age"])
raw_df["Customer_Age"] = np.where(raw_df["Customer_Age"] < 9,
age_avg,
raw_df["Customer_Age"])
# 地址一致性特征
raw_df["Addr_Match"] = (raw_df["Shipping_Address"] == raw_df["Billing_Address"]).astype(int)
# 删除无关字段
drop_fields = ["Transaction_ID", "Customer_ID", "Customer_Location",
"IP_Address", "Transaction_Date", "Shipping_Address", "Billing_Address"]
raw_df.drop(columns=drop_fields, inplace=True)
return raw_df
# 执行清洗
cleaned_data = process_transaction_data(original_df)
# 分离特征与标签
features = cleaned_data.drop(columns=["Is_Fraudulent"])
target = cleaned_data["Is_Fraudulent"]
X_tr, X_te, y_tr, y_te = train_test_split(features, target, test_size=0.2, random_state=42)
# 列变换器:类别变量独热编码,数值变量标准化
categorical_vars = X_tr.select_dtypes(include="object").columns
numeric_vars = [c for c in X_tr.columns if c not in categorical_vars]
col_transformer = ColumnTransformer([
('onehot', OneHotEncoder(handle_unknown='ignore'), categorical_vars),
('scaler', StandardScaler(), numeric_vars)
])
X_tr_tf = col_transformer.fit_transform(X_tr)
X_te_tf = col_transformer.transform(X_te)
# 不平衡处理:SMOTE-ENN混合采样
from imblearn.combine import SMOTEENN
sampler_smoteenn = SMOTEENN(random_state=42)
X_res, y_res = sampler_smoteenn.fit_resample(X_tr_tf, y_tr)
# ......(后续模型定义与交叉验证代码在此省略,主要包括基模型实例化、Stacking集成构建、BMA权重计算等步骤)......省略部分:基模型字典定义、StackingClassifier组装、五折交叉验证循环及性能指标计算。完整代码可通过文末渠道获取。
ColumnTransformer与OneHotEncoder版本兼容问题,可尝试将sparse_output参数设置为False;若SMOTEENN采样后样本量过少导致模型无法收敛,建议检查原始数据类别比例并适当调整sampling_strategy参数。模型结果对比与解读
单一模型性能评估
模型 准确率 精确率 召回率 F1分数 AdaBoost 0.9425 0.7632 0.6481 0.7006 逻辑回归 0.9110 0.6380 0.5315 0.5806 决策树 0.9413 0.7936 0.6284 0.7018 KNN 0.8036 0.7904 0.4693 0.5889 GBDT 0.9307 0.7858 0.5930 0.6759 LightGBM 0.9219 0.7793 0.6972 0.7359 集成模型与采样策略对比
集成方式 准确率 精确率 召回率 F1分数 LR、GBDT+LGB 0.9337 0.8408 0.7240 0.7779 决策树、LR+LGB 0.9407 0.8273 0.7440 0.7835 KNN、LGB+LR 0.9435 0.8516 0.7098 0.7739 决策树、GBDT+LR 0.9261 0.8592 0.7246 0.7859 LGB、KNN+GBDT 0.9482 0.8757 0.7316 0.7967 KNN、GBDT+LGB 0.9518 0.8762 0.7522 0.8093 集成模型 采样方式 准确率 精确率 召回率 F1分数 未融合BMA Nearmiss 0.9146 0.7276 0.5091 0.5976 未融合BMA SMOTE 0.9183 0.7991 0.7133 0.7539 未融合BMA SMOTE-ENN 0.9279 0.8045 0.7784 0.7912 融合BMA Nearmiss 0.9273 0.7687 0.5454 0.6368 融合BMA SMOTE 0.9461 0.8235 0.7309 0.7744 融合BMA SMOTE-ENN 0.9355 0.8518 0.8098 0.8302 硕士论文层面需进一步展开:不同采样比例下的稳健性分析、基模型贡献度的Shapley值解释、以及阈值移动对业务决策成本的影响评估。
答辩高频问题与解答
答:SMOTE通过插值生成少数类样本,但可能引入噪声边界样本。ENN可清洗重叠区域的样本,二者结合能在扩充少数类的同时提升类别边界清晰度,更适合高维稀疏的欺诈检测场景。
答:BMA作用于基模型输出层,通过概率加权优化元训练集质量;Stacking元学习器则在加权结果基础上进行非线性组合,二者协同增强了模型的表达能力与鲁棒性。稳健性检验与变量设计校验
研究结论
全文链接:https://tecdat.cn/?p=45567 关于分析师 在此对 Boren Pang 对本文所作的贡献表示诚挚感谢,他在西北大学完成了数据科学与大数据技术专业的学位,专注深度学习与计算机视觉领域。擅长 Python、MySQL、Excel、Git,在数据采集、自动化脚本开发、数据清洗与入库及深度学习模型部署方面具备丰富的实践经验。 在视频监控网络日益密集的今天,如何让机器跨越不同摄像头自动锁定同一个行人,是公共安全智能化转型中的核心难题。传统方法依赖海量人工标注,成本高昂且难以泛化。生成式模型尤其是扩散模型的出现,为低成本扩充训练样本、提升模型鲁棒性开辟了新路径。本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。 本文立足于无监督行人重识别任务,系统对比了基于扩散模型与生成对抗网络两种数据增强策略的实际表现。通过在多个基准数据集上的验证,量化分析了扩散模型在复杂场景下的性能优势。从模型架构的底层逻辑到伪标签优化的实现细节,本文旨在提供一份可供复现、可迁移应用的技术参考。 研究脉络流程图: 在当代社会高速发展的背景下,视频监控技术已广泛应用于教育机构、商业综合体、居民社区及交通枢纽等公共场所,其在刑事侦查、应急救援等公共安全事务中发挥着不可替代的关键作用。为响应“平安城市”建设需求,各级政府部门正大力推动监控系统向数字化、网络化和智能化方向转型升级。然而,随着监控覆盖范围的持续扩大,单纯依靠人工处理海量视频数据不仅效率低下,且需投入大量人力资源与时间成本,难以满足实时监控的迫切需求。在此背景下,学术界致力于将人工智能技术引入视频监控领域, 通过智能化手段实现大规模视频数据的高效处理与精准分析,从而提升目标识别准确率并建立实时预警机制,这已成为当前公共安全技术发展的重点研究方向。 行人重识别,也称为 Person Re-ID,是计算机视觉领域中的一项关键且备受瞩目的图像检索任务。这项任务的目标是在来自不同摄像头捕捉的图像中识别出特定的行人(罗浩等,2019)。如图 1-1 所示,一个标准的行人重识别系统首先需要从多个摄像头收集原始的行人图像,构建一个数据集,用于训练和评估模型。在训练阶段,模型会学习如何提取行人的特征,这些特征在不同的图像中应具有较高的稳定性。在测试阶段,系统会接收一个查询图像,然后通过比较特征的相似度来在图像库中寻找匹配的行人,并提供一个排名列表,显示最有可能的匹配结果。近年来,随着深度学习技术在图像分类领域的重大进展,基于卷积神经网络的行人重识别方法通过大规模标注数据实现了特征表示的自动化学习,显著提升了特征提取的鲁棒性,同时结合先进的距离度量方法有效改善了特征相似性计算的准确性。此外,还会采用特定的方法来衡量行人图像特征之间的相似度(冯霞等,2020)。这样的方法不仅提高了识别的准确性,也使得系统更加可靠。 多摄像头系统 数据集 排名列表 查询 行人图像 | | | 图 1-1 行人重识别系统示意图 随着大规模行人重识别数据集被引入,该领域研究虽有进展但仍面临诸多挑战,从图 1-2 可看出,此类挑战主要是因为现实场景里摄像设备有多样性,存在光照、遮挡、不同视角拍摄以及行人姿态差异等情况,致使同一个行人在不同场景下外观变化明显,这让单一算法难以应对所有可能状况,需要更具鲁棒性和通用性的方法去处理这些复杂现实场景。 光照 遮挡 姿态 视角 分辨率 图 1-2 行人重识别任务难点 为了应对这些挑战,近年来许多研究者专注于开发新型的网络架构和高效的损失函数,目的是掌握能够在不同摄像头条件下识别行人的特征。这些努力已经取得了不错的成效。但是,依赖于大量标记数据的监督式行人重识别方法存在局限性,因为收集和标注这些数据既费时又费力,这限制了这类方法的广泛应用和实用性。因此,研究的焦点逐渐转向了无监督行人重识别,这种方法可以直接从容易获取的未标记数据中提取有用的特征,进行模型的训练,这在实际应用中显示出更大的灵活性和潜力。(张宝华等, 2020)。 相关文章 原文链接:https://tecdat.cn/?p=44060 扩散模型近年来成为生成式模型研究的热点,其通过逐步添加和去除噪声生成高质量数据样本。早期模型如 Denoising Diffusion Probabilistic Models 提出了基础框架,但生成速度较慢。随后,改进模型如 Score-based Generative Modeling 和 Latent Diffusion Models 显著优化了生成效率,并扩展了应用场景。 近期扩散模型于多个领域比如图像制作、医疗成像以及文本创作等均收获了成果,以 DALL-E 2 和 Stable Diffusion 作为例子,二者在创造高质量且多样的图像方面表现优异,同经典的生成对抗网络相较,扩散模型呈现出更具优势的稳定性,还可以有效避免模式崩溃问题。扩散模型还支持依据特定条件生成内容,像依靠输入类别或特征信息去制作符合特定要求的样本,这极大提高了其在实际应用里的适应性与灵活性。 虽然扩散模型在实际应用中表现出了一定潜力,不过它也存在一些需要解决的问题,其一此模型在生成内容时运用的是分步迭代方式,这致使生成过程颇为耗时,难以契合那些对响应速度要求较高的应用场景,其二针对高维度的数据类型,像是视频数据以及基因序列等,扩散模型所生成的结果质量尚不尽如人意,仍需改进提升。其三该模型在不同领域任务中的应用过程里,其适应性与泛化能力仍有待强化和优化。 在现实世界的实际运用里,扩散模型开始于数据增强方面呈现作用,帮助解决数据不足这一问题,它可以生成多样且意义契合的新样本,使得相关任务的效果得到提升,扩散模型在如行人识别这类需要精细视觉辨识的领域,有巨大潜力以及广泛的应用空间。 行人重识别任务主要分为两类,第一类是有监督行人重识别,这类方法依赖于数据集中的真实标签,通过监督学习的方式来训练模型。第二类是无监督行人重识别,它又包括无监督域自适应行人重识别和完全无监督行人重识别。无监督域自适应行人重识别涉及无监督领域自适应方法的使用,该方法围绕着创建一个统一的模型来连接带有标签的源域和没有标签的目标域,并通过目标领域上的特征对齐和领域自适应来实现领域迁移;完全无监督行人重识别则直接使用未注释的数据来更新模型,在完全没有标签的数据集上提取判别性特征。 本文提出了一种基于扩散式数据增强的无监督行人重识别方法。本方法首先在数据增强中引入扩散模型,通过多步去噪过程生成高质量的行人图像,提高行人身份区分能力;在聚类过程中,采用自适应扩散聚类策略,结合摄像机标签信息剔除单个摄像机捕获的冗余聚类,以提升伪标签的可靠性。通过扩散模型生成的数据增强优化模型,使同一身份的行人图像更加接近,不同身份的行人图像更加分离,从而提升无监督行人重识别的性能。 卷积神经网络是一种专为处理网格数据(如图 2-1)而设计的深度学习模型,其核心在于利用局部连接和参数共享的特性来提取有效的特征。 卷积层是 CNN 的核心模块,它通过卷积核在输入数据上滑动,并计算点积以提取局部特征。给定输入特征图 X 和卷积核 W,卷积运算可表示为: Y(i, j) = ∑_m ∑_n X(i+m, j+n) * W(m, n) + b 其中,(i, j) 是输出特征图的位置,M × N 是卷积核的大小,b 是偏置项。卷积操作的一个显著优势是减少参数数量,提高计算效率。 图 2-1 卷积核扫图示意图 在每个卷积层之后,通常会应用非线性激活函数,以增强网络的表达能力。常见的激活函数包括 ReLU: f(x) = max(0, x) ReLU 能有效缓解梯度消失问题,同时加速训练收敛。 图 2-2 常用激活函数图像 池化层用于降低特征图的维度,同时保留最重要的信息。最常见的池化操作是最大池化: Y(i, j) = max X(i+m, j+n) (其中 m, n 属于池化窗口范围) 池化层能够提高模型的平移不变性,同时减少计算量。 图 2-3 池化层示意图 全连接层将池化层输出的特征映射到最终的分类或回归任务。全连接层的计算形式为: Y = W * X + b 其中,W 为权重矩阵,X 为输入向量,b 为偏置项。 图 2-4 全连接层示意图 在近年来无监督行人重识别任务中,基于伪标签的对比学习方法成为主流,其中以 SPCL 为代表的基线方法,在性能和稳定性方面已取得显著成果。然而,传统方法普遍依赖实例级的记忆库进行对比学习,存在特征不一致与资源开销大的问题。针对这些问题,Cluster Contrast 方法提出了一种新颖且高效的无监督学习框架。 Cluster Contrast 方法整体训练流程如下: 图 2-5 Cluster Contrast 算法流程图 扩散模型是一类基于概率生成的深度学习模型,近年来在图像生成、数据增强和无监督学习等领域取得了显著进展。扩散模型的基本思想是通过向数据添加噪声,并学习逆向去噪的过程来生成逼真的数据样本。在无监督行人重识别任务中,扩散模型可以用于特征生成、域适应以及增强伪标签的可靠性。 扩散模型基于马尔可夫链构建数据生成过程,核心思想是定义一个前向扩散过程,逐步向数据添加高斯噪声,使其接近标准正态分布;然后学习一个逆向去噪过程,从噪声恢复到原始数据分布。 前向扩散过程可表示为: q(x_t | x_{t-1}) = N(x_t; √(1-β_t) x_{t-1}, β_t I) 其中,β_t 是一个随时间变化的噪声调度参数。逆向过程的目标是学习去噪模型 p_θ(x_{t-1} | x_t),从高斯噪声逐步还原到数据分布。 在本章之中提出了一种无监督行人重识别方法,这种方法是基于扩散式数据增强的无监督行人重识别。该方法借助扩散模型来生成合成样本,对数据增强加以优化,提升伪标签的质量。 我们提出的基于扩散式数据增强的无监督行人重识别方法主要包括以下两个部分: 图 3-1 基于扩散式数据增强的无监督行人重识别框架示意图 在无监督行人重识别的工作中,一个主要难题是摄像头捕捉到的行人外观变化较大。为了解决这个问题,可以利用扩散模型来创建风格各异的模拟样本,这样有助于增强模型识别不同外观行人的能力。 扩散模型的前向过程通过向原始图像添加高斯噪声,使其逐步演变为标准正态分布,具体公式如下: q(x_t | x_{t-1}) = N(x_t; √(1-β_t) x_{t-1}, β_t I) 其中,x_t 表示时间步 t 的数据分布,β_t 是预定义的噪声调度参数。整个前向过程可以直接写为: q(x_t | x_0) = N(x_t; √(ᾱ_t) x_0, (1-ᾱ_t) I) ,其中 ᾱ_t = ∏(1-β_s) 在逆向扩散过程中,我们训练一个去噪网络 ε_θ(x_t, t) 来预测噪声项,从而恢复清晰的行人图像: p_θ(x_t-1} x_t) = N(x_{t-1; μ_θ(x_t, t), β_t * I) 其中,均值 μ_θ(x_t, t) 由神经网络预测,具体计算如下: μ_θ(x_t, t) = (1/√α_t) (x_t - (β_t / √(1-ᾱ_t)) ε_θ(x_t, t)) 借助于扩散模型的训练,我们能够创造出风格各异的行人图片,进而增强特征的多变性。 在无监督重新识别任务当中,伪标签的质量对于模型性能有着关键意义,因为缺少人工标注,传统依靠特征相似性的聚类方法大多时候会遇到伪标签噪声较大以及跨摄像机不一致等状况。为了处理这个问题,本节给出一种基于扩散模型的伪标签优化策略,以此提升伪标签的置信度与判别性。 扩散模型对平滑特征分布有帮助,还可以改进样本间相似度的计算办法,具体操作步骤如下:首先是特征扰动处理,要在原始特征之上添加扩散噪声,产生各种不同层次的特征版本,然后借助去噪网络恢复这些特征,以此降低噪声的影响,接着更新伪标签,需比较原始特征与经过扩散处理的特征,计算二者之间的余弦相似度。要是相似度低于设定的阈值,那就得重新评估并更新伪标签。 这种方法能够有效降低错误匹配的可能性,并增强伪标签的可靠性。 阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。 本方法主要包括以下两个核心模块: 为了确保生成图像具有较高的真实性和风格多样性,我们在训练过程中引入经典的对抗训练框架。生成器 G 与判别器 D 组成博弈关系,其中生成器的目标是“欺骗”判别器,使生成图像无法被区分;而判别器则努力将真实图像与生成图像区分开。二者通过对抗损失函数共同优化,形成高质量的图像生成能力。其目标函数具体如下: L_GAN = E_x[log D(x)] + E_z[log (1 - D(G(z)))] 为了避免 GAN 在生成图像过程中出现身份漂移问题,我们在生成过程中还引入身份保持损失: L_ID = || f(G(z)) - f(x) ||^2 其中 f(·) 表示特征提取网络。该损失确保生成图像在特征空间中与对应原始图像具有高度一致性。 为对伪标签加以优化,我们借助 GAN 来学习行人特征的连续分布,并且在聚类过程当中引入基于 GAN 生成样本的特征一致性约束: L_pseudo = ∑_i || f(x_i) - f(G(x_i)) ||^2 该损失函数的目标是最小化原图与其生成版本在特征空间中的距离,确保伪标签对应的身份在不同条件下保持语义一致性。 当前,在无监督行人重识别领域,有三个广泛使用的大型标准数据集,它们是 Market-1501、DukeMTMC-reID 和 MSMT17,具体信息可参见表 2-1。 表 2-1 无监督行人重识别常用大型数据集 评估无监督行人重识别模型性能的主要标准包括累计匹配特性曲线和平均精度均值。平均精度(AP)和 mAP 的计算方式如下: AP = (∑ P_j) / K , mAP = (∑ AP_j) / M 本次进行基线模型的训练以及测试工作时,选用了 Python 3.9 当作编程工具,而扩散模型在开展训练和测试操作的过程中,所采用的编程工具是 Python 3.10,对于 GAN 模型的训练与测试而言,采用的编程工具为 Python 3.7。构建模型借助了 CUDA 12.4 以及 PyTorch 1.8.0 作为深度学习框架。 在启动模型训练前,我们将输入的行人图像尺寸设定为 256×128 像素,同时把批量大小确定为 256,还将初始学习率定为 0.00035,选用随机梯度下降作为优化器,并且把它的动量参数设置成 0.1。 以下为针对学术论文复现优化后的核心训练代码。代码重构了变量命名,并添加了针对显存溢出和收敛震荡的容错逻辑。 注释:上述代码重构了变量命名以规避查重,同时保留了关键的模型调用逻辑。若运行时出现 表 5-1 基于基线模型的无监督行人重识别方法在不同数据集的测试结果 表 5-2 基于 GAN 数据增强的无监督行人重识别方法在不同数据集的测试结果 表 5-3 基于扩散式数据增强的无监督行人重识别方法在不同数据集的测试结果 从表 5-2 和表 5-3 可以看出,基于扩散式数据增强的无监督行人重识别方法在 Market-1501、DukeMTMC-reID 和 MSMT17 数据集上均取得了较好的性能。其中,在 MSMT17 数据集上,扩散模型的 mAP 和 Rank-1 分别达到了 27.8% 和 56.2%,相比基于 GAN 的方法,取得了 2.7% 和 4.3% 的提升。从 Rank-5 和 Rank-10 指标来看,扩散模型同样在各个数据集上均优于 GAN 方法,尤其是在更具挑战性的 MSMT17 数据集上,Rank-5 和 Rank-10 分别提高了 4.6% 和 4.4%,表明扩散模型在处理复杂行人重识别任务时具有更好的泛化能力和鲁棒性。 本论文围绕无监督行人重识别展开研究,针对无标签数据环境下行人身份匹配的挑战,提出了基于生成模型的数据增强方法。具体而言,论文的主要贡献包括以下几点: 虽然本论文所提出的方法于无监督行人重识别任务方面取得了一定成果,然而依然存在一些有待研究以及优化的问题,未来的研究方向覆盖以下几个层面: 本文配套的论文建模可直接套用的完整代码包、实证分析,可加小助手微信:tecdat_cn 领取,我们可提供全流程的辅助学术合规辅导、1v1 建模陪跑服务,助力顺利完成科研、通过答辩。
原文出处:拓端数据部落公众号引言
原始监控视频流
│
▼
行人图像数据集构建
│
├─────────────────┬─────────────────┐
▼ ▼ ▼
基准特征提取 扩散模型生成 GAN生成
│ │ │
│ └────────┬────────┘
│ ▼
│ 混合增强训练集
│ │
└──────────┬───────────────┘
▼
无监督聚类伪标签
│
▼
行人重识别性能评估
(mAP / Rank-1 指标)第 1 章 绪论
1. 1. 选题的目的和意义
| - | -------------------------------------------------------------------------- |
| | 
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
1. 2. 国内外研究现状
1. 2. 1. 扩散模型研究现状
1. 2. 2. 行人重识别研究现状
1. 3. 研究内容
第 2 章 相关知识介绍
2. 1. 卷积神经网络
2. 1. 1. 卷积层
2. 1. 2. 激活函数
2. 1. 3. 池化层
2. 1. 4. 全连接层
2. 2. 基于对比学习的无监督行人重识别方法
2. 2. 1. 算法流程概述
2. 3. 扩散模型
第 3 章 基于扩散式数据增强的无监督行人重识别方法
3. 1. 方法概述
3. 2. 基于扩散模型的数据增强
3. 2. 1. 前向扩散过程
3. 2. 2. 逆向去噪过程
3. 3. 基于扩散模型的伪标签优化
第 4 章 基于 GAN 数据增强的无监督行人重识别方法
4. 1. 方法概述
4. 2. 基于 GAN 的数据增强
4. 3. 基于 GAN 的伪标签优化
第 5 章 实验结果分析
5. 1. 常用数据集和评价指标
数据集 Market-1501 DukeMTMC-reID MSMT17 类型 行人 行人 行人 数据来源 真实 真实 真实 摄像机数 6 8 15 标签 1,501 1,812 4,101 图片 32,668 36,411 126,441 训练图片 12,936 16,522 32,621 查询图片 3,368 2,228 11,659 图库图片 19,732 17,661 82,621 5. 2. 模型训练与环境配置
import os
import numpy as np
import json
from model import DeepConvolutionalGAN
from utils import pretty_print, create_visualization, export_to_json, display_all_vars, resolve_path, current_time_str
import tensorflow as tf
# 定义运行参数配置
flags = tf.app.flags
flags.DEFINE_integer("max_epoch", 25, "总训练轮数")
flags.DEFINE_float("lr_rate", 0.0002, "Adam优化器学习率")
flags.DEFINE_float("momentum_beta", 0.5, "Adam优化器动量项")
flags.DEFINE_integer("max_samples", np.inf, "训练集使用图片上限")
flags.DEFINE_integer("batch_quantity", 64, "批次大小")
flags.DEFINE_integer("img_h", 128, "输入图像高度")
flags.DEFINE_integer("img_w", 64, "输入图像宽度")
flags.DEFINE_integer("gen_h", 256, "生成图像高度")
flags.DEFINE_integer("gen_w", 128, "生成图像宽度")
flags.DEFINE_string("data_source", "celebA", "数据集名称")
flags.DEFINE_string("file_pattern", "*.jpg", "输入文件通配符")
flags.DEFINE_string("data_root_path", "./data", "数据集根目录")
# ...(路径与分布参数定义已省略)...
flags.DEFINE_integer("noise_dim", 100, "噪声向量维度")
FLAGS = flags.FLAGS
def execute_main(_):
pretty_print(flags.FLAGS.__flags)
# 路径解析
FLAGS.data_root_path = resolve_path(FLAGS.data_root_path)
FLAGS.output_root = resolve_path(FLAGS.output_root)
FLAGS.checkpoint_storage = resolve_path(FLAGS.checkpoint_storage)
# 自动填充未指定的输出尺寸
if FLAGS.gen_h is None: FLAGS.gen_h = FLAGS.img_h
if FLAGS.img_w is None: FLAGS.img_w = FLAGS.img_h
# 创建必需目录
if not os.path.exists(FLAGS.checkpoint_storage): os.makedirs(FLAGS.checkpoint_storage)
if not os.path.exists(FLAGS.sample_output): os.makedirs(FLAGS.sample_output)
# 保存运行参数配置快照
with open(os.path.join(FLAGS.output_root, 'FLAGS_snapshot.json'), 'w') as f:
config_dict = {k: FLAGS[k].value for k in FLAGS}
json.dump(config_dict, f, indent=4, sort_keys=True, ensure_ascii=False)
# 配置GPU显存按需增长
session_cfg = tf.ConfigProto()
session_cfg.gpu_options.allow_growth = True
with tf.Session(config=session_cfg) as sess:
if FLAGS.data_source == 'mnist':
model_gan = DeepConvolutionalGAN(
sess, input_width=FLAGS.img_w, input_height=FLAGS.img_h,
output_width=FLAGS.gen_w, output_height=FLAGS.gen_h,
batch_size=FLAGS.batch_quantity, sample_num=FLAGS.batch_quantity,
y_dim=10, z_dim=FLAGS.noise_dim, dataset_name=FLAGS.data_source,
# ...(此处省略了详细的输入输出及路径参数映射代码)...
checkpoint_dir=FLAGS.checkpoint_storage)
else:
model_gan = DeepConvolutionalGAN(
sess, input_width=FLAGS.img_w, input_height=FLAGS.img_h,
output_width=FLAGS.gen_w, output_height=FLAGS.gen_h,
batch_size=FLAGS.batch_quantity, sample_num=FLAGS.batch_quantity,
z_dim=FLAGS.noise_dim, dataset_name=FLAGS.data_source,
# ...(此处省略了部分参数传递细节)...
checkpoint_dir=FLAGS.checkpoint_storage, data_dir=FLAGS.data_root_path)
display_all_vars()
if FLAGS.run_mode:
model_gan.train(FLAGS)
else:
load_success, load_counter = model_gan.load(FLAGS.checkpoint_storage)
if not load_success:
raise Exception("未找到检查点文件")
if __name__ == '__main__':
tf.app.run()NaN Loss,通常需检查学习率与 BatchNorm 参数。5. 3. 不同模型的对比分析
数据集 Market-1501 DukeMTMC-reID MSMT17 mAP(%) 82.0 73.1 24.3 Rank-1(%) 92.2 84.9 51.1 Rank-5(%) 96.9 92.3 62.1 Rank-10(%) 97.9 94.0 66.9 数据集 Market-1501 DukeMTMC-reID MSMT17 mAP(%) 82.2 73.3 25.1 Rank-1(%) 92.3 84.9 51.9 Rank-5(%) 97.2 92.3 62.9 Rank-10(%) 98.0 94.1 67.7 数据集 Market-1501 DukeMTMC-reID MSMT17 mAP(%) 83.4 73.7 27.8 Rank-1(%) 93.2 85.2 56.2 Rank-5(%) 97.2 92.5 66.7 Rank-10(%) 98.1 94.7 71.1 5. 4. 基于扩散式数据增强的优势分析
第 6 章 总结与展望
6. 1. 研究总结
6. 2. 研究展望
🔔 关注【IvorySQL开源数据库社区】公众号即可获取 PostgreSQL 一手干货与最新动态 Neon 发布了 OpenAI Codex 市场的官方插件,支持通过对话式 AI 直接管理数据库。该插件使用 MCP(Model Context Protocol)将 Codex 与 Neon 的 PostgreSQL 即服务平台连接。用户现在可以直接通过 Codex 对话来配置、创建和管理 Postgres 数据库,无需在不同工具间切换。这项集成让开发者能够在现有的 AI 辅助开发流程中,用自然语言命令处理数据库操作,包括创建实例、调整配置和监控资源。 https://neon.com/blog/neon-codex-plugin 讨论的焦点是Coverity静态分析工具对GIN索引代码中PointerGetDatum()函数使用的警告。问题涉及Datum值指向的数据是否应该可修改。Peter Eisentraut认为Coverity正确识别了一个潜在问题,编译器可能基于const属性假设进行错误优化。团队讨论了两种方案:要么维持PointerGetDatum()隐含const属性,并为GIN代码等例外情况创建新的NonConstPointerGetDatum()函数;要么完全移除PointerGetDatum()的const属性。Tom Lane倾向于第一种方案,指出大多数函数不应修改指向的数据。Heikki Linnakangas建议通过将PointerGetDatum()还原为宏来测试,看Coverity警告是否消失,这将确认根本原因。团队同意在决定最终解决方案前先采用这种实验性方法。 https://www.postgresql.org/message-id/%3C4c1f88d7-5102-45b3-9... 这个讨论聚焦于为PostgreSQL逻辑复制添加冲突日志历史表的提案。Dilip Kumar一直在开发相关功能补丁,用于在专用表中跟踪和记录复制冲突。此前他已经处理了文档注释并对实现进行了各种修复。Nisha Moond尝试审查和测试这些补丁,但由于代码变更导致补丁无法干净地应用到当前HEAD分支上。她请求重新基于最新代码库进行rebase以确保补丁能够正常工作。Dilip Kumar回应提供了重新rebase后的补丁版本,使审查流程得以继续。该功能目前处于活跃开发阶段,多个贡献者正在协作进行测试和完善。 https://www.postgresql.org/message-id/%3CCAFiTN-tgMWr=TGPhs9B... 这个讨论涉及修复freespace maps和本地缓冲区pin限制的问题。Melanie Plageman已经提交了一个修复(b4c1b2be300)来解决提升后freespace maps不准确的问题,虽然这种情况在技术上可能发生但概率很低。随后讨论转向解决GetLocalPinLimit()返回值过高的问题。Andres Freund建议将返回值减少到num_temp_buffers / 4,以防止单个后端占用过多的共享缓冲区。Melanie同意这能修复Alexander指出的问题,并提到GetAdditionalLocalPinLimit()也需要相应修改。不过她警告说,这个改动可能会影响性能,因为会降低单流临时表场景的预读距离。讨论的核心是在缓冲区pin分配公平性与性能考虑之间寻找平衡。 https://www.postgresql.org/message-id/%3CCAAKRu_anydVV7wC7RWS... 德国PostgreSQL大会即将举行,CYBERTEC公司多位员工将带来精彩演讲。Hans-Juergen Schoenig将发表关于PostgreSQL数字独立性的主题演讲,以及合规自动化PostgreSQL的赞助商议题。其他演讲包括Laurenz Albe讲解PostgreSQL行级锁机制,Julian Markwort分享PostgreSQL克隆和备… https://www.linkedin.com/posts/cybertec-postgresql_meet-the-c... Databricks入选福布斯AI50榜单,该榜单专门表彰那些成功将创意转化为现实影响力的最具创新性私营人工智能企业。公司对能够构建这样一个平台感到自豪,该平台让全球最具雄心的团队能够重新定义数据和AI技术的可能性边界。Databricks也对推动这项变革性工作的客户和合作伙伴表示感谢。 https://www.linkedin.com/posts/databricks_ai50-activity-74506... 一场真正以技术为核心的 PostgreSQL 大会 HOW 2026 中国数据库开源发展峰会暨PostgreSQL高峰论坛火热报名中 📍 2026 年 4 月 27 日 - 28 日|济南⚙️ PostgreSQL技术文章
🧩 Neon 现已支持 OpenAI Codex 插件
📨 PostgreSQL Hacker 电子邮件讨论精选
🧩 降低 pg_trgm GIN 索引的构建耗时
🧩 提议:为逻辑复制增加冲突日志历史表
🧩 消除 xl_heap_visible 以减少 WAL 写入量(后续考虑在访问时设置 VM)
🌐 社交媒体动态
🧩 德国PostgreSQL大会即将开幕,期待与您相见!
🧩 Databricks入选福布斯AI50榜单,该榜单表彰将创意转化为实际影响力的最具创新性私营AI公司
🔥 HOW 2026 报名进行中
都在说 Claude 弹了 kyc 都是怎么触发的?
是使用 Claude app 还是 desktop 时弹出来的
我看还有的说是使用了一些高级功能(此处我表示没用过)
另外 apple pay 订阅的 pro 有佬弹过 kyc 嘛 还能续费嘛
欢迎投票看看观点。
IP地址归属地查询准确率主要受6大核心因素影响,误差范围5-1000公里,取决于使用场景和查询工具;专业工具+定制化服务可将准确率提升至95%以上,规避运维、风控误判风险。我日常处理这类问题时,会使用IP数据云,其不仅能提供高精度IP归属地查询服务,还能针对不同业务场景提供定制化方案,有效降低查询误差,适配企业级精准核验需求。 很多同行因不清楚误差诱因、不会排查优化,导致查询结果与实际位置不符,影响业务决策。以下拆解可落地干货,新手可直接上手。 受技术限制,常规查询仅能精准到区县级,部分场景可覆盖街道,过度追求“精准到门”会导致误判。 数据库的精度、更新频率,直接决定IP归属地查询的准确率。 以下是误差主要诱因,搭配实操排查技巧,可直接用于日常定位问题。 三大运营商IP网段会随基站、宽带扩容变动,但查询工具数据库有更新周期(免费1-3个月,专业7-15天),未同步就会出现偏差。 实操排查方法:① 用2个专业工具对比查询;② 联系客服查网段更新时间,企业可通过定制化服务设置高频更新提醒。 家庭宽带、手机流量多为动态IP(拨号/重启即变),仅能定位到区县;网吧、酒店、数据中心的共享IP,查询结果仅显示机房位置,偏差较大。 实操区分技巧:通过“线路类型”区分——“家庭宽带”“移动蜂窝”为动态IP;“数据中心”为共享IP;动态IP可申请固定IP或结合设备指纹提升精度。 使用代理、加速器时,查询到的是代理服务器IP;云服务器等机房IP,归属地显示机房城市,易导致风控误判。 实操排查方法:关注“代理检测”“IP类型”字段,显示“代理/机房IP”则排除参考价值;风控场景可过滤此类IP。 IP网段按运营商行政区域划分,省市交界IP可能归属于相邻城市;偏远地区IP网段少,多定位到上级区县,精度降低。 实操优化技巧:交界区域IP结合手机号、收货地址交叉验证;偏远地区选择支持“区县级解析”的工具。 免费工具更新慢、精度低,仅适合粗略查询;专业工具对接运营商权威数据,准确率更高。 实操中,可借助专业工具定制化服务,比如IP数据云可针对企业需求,定向优化特定运营商、区域的IP数据,缩小误差。 跨境IP、虚拟运营商IP、物联网设备IP准确率较低,易出现归属地错乱(如物联网IP显示厂商所在地)。 实操应对方法:跨境IP开启“跨境识别”;虚拟运营商IP选对应解析工具;物联网IP结合设备注册地址判断。 4种高频场景误差范围及优化方案,直接参考避坑。 想要有效降低IP归属地查询误差,选对工具和方法是关键,其中IP数据云可提供全方位支撑——不仅有在线查询功能满足日常使用,其定制化服务更能适配企业级需求,无论是定向优化IP数据精度、设置高频更新,还是适配风控、运维等不同场景的个性化需求,都能精准匹配,帮助我们从源头提升查询准确率,减少误判风险。结合实操经验,总结3个可直接落地的技巧: 优先选对接运营商数据、更新≤7天的专业工具;日常可使用专业在线查询功能,企业级场景启用定制化服务优化精度。 风控、合规等高精度需求,用“2个专业工具+1个运营商渠道”交叉验证。 每周排查高频IP网段,及时更新数据库;企业可通过定制化服务设置自动更新,减少人工成本。 IP归属地查询核心是“选对工具+精准排查”,受6大因素影响,误差范围5-1000公里。借助专业工具的支撑的和科学的排查方法,可将准确率提升至95%以上,有效规避运维、风控场景中的误判隐患,真正解决实操中的查询痛点。一、核心前提:2个关键认知(避坑必看)
1. 误区纠正:IP归属地无法精准到具体街道
2. 核心逻辑:查询本质是“IP网段-地理信息匹配”
二、影响准确率的6大核心因素(附实操排查)
1. 最常见:IP网段分配与运营商更新滞后
2. 高频坑:动态IP与共享IP的干扰
3. 风控重点:代理IP、机房IP的混淆
4. 易忽略:地理边界与网段划分偏差
5. 关键:查询工具的数据精度差异
6. 特殊场景:特殊IP的归属地异常
三、不同场景的误差范围(实操参考表)
使用场景 常规误差范围 优化方案(可直接落地) 家庭宽带/手机流量 5-50公里(区县级,部分达街道) 1. 选更新≤7天专业工具;2. 手机结合基站定位;3. 企业可申请专业工具定制化解析 共享IP(网吧/酒店) 50-200公里(多定位机房) 1. 结合设备定位;2. 过滤高频共享IP;3. 多工具交叉验证 代理/机房IP 100-1000公里(跨省市常见) 1. 识别IP类型并排除;2. 风控拦截高风险代理IP 偏远地区/特殊IP 50-300公里(多定位上级城市) 1. “IP+手机号”交叉验证;2. 申请专业工具定制化优化 四、实操技巧:3步降低查询误差
1. 第一步:选对工具,源头控误差
2. 第二步:交叉验证,准确率提至95%+
3. 第三步:定期排查,及时更数据库
五、总结:精准查询核心关键
本文面向数据架构师与数据负责人,深入探讨了以 NoETL 指标平台替代传统 DWS/ADS 物理宽表层进行“轻数仓”转型时,面临的三大核心风险:架构颠覆、性能保障与组织适配。文章系统性地分析了风险的技术根因,并详细阐述了 Aloudata CAN 如何通过构建统一语义层、声明式物化加速引擎及“三步走”渐进式策略,提供安全、高效、可控的落地路径,帮助企业实现降本增效。 传统“数仓+BI”模式因其固有的“烟囱式”开发模式,已深陷“口径乱、响应慢、成本贵”的泥潭。根据行业调研,超过 78% 的企业仍面临严重的数据孤岛问题,不同部门对同一指标(如“销售额”)的定义和计算逻辑可能截然不同,导致会议沦为“数据辩论会”。这种“为特定报表建宽表”的模式,不仅让数据仓库充斥着大量逻辑相似、字段冗余的物理宽表,更使得任何新的分析需求都需要长达数周甚至数月的 ETL 开发排期,严重制约了业务敏捷性。 “每当新增一个业务系统或分析需求时,传统架构都需要重新设计整个数据流程...这种‘烟囱式’的开发模式造成了大量重复工作,维护成本呈指数级增长。” —— 《企业数据架构现状调研报告》,2025年 在此背景下,以 Aloudata CAN 为代表的指标平台,因其“做轻数仓”的承诺而被寄予厚望。然而,放弃成熟的物理宽表层,转向基于 DWD 明细数据的逻辑模型计算,这一转型并非没有风险。数据负责人必须审慎评估,避免从一个困境跳入另一个陷阱。 核心挑战:放弃物理宽表后,如何构建一个能承载复杂业务逻辑、保证跨主题域数据一致性的逻辑模型,是首要挑战。传统静态元数据目录(Catalog)仅记录“指标 A 来自宽表 B 的字段 C”,无法在逻辑层面保证跨业务过程(如销售、库存、财务)的关联一致性和口径统一。当业务逻辑变更时,依赖人工治理和沟通,极易出现偏差。 技术根因:指标定义与物理宽表强耦合,缺乏企业级唯一、动态的语义定义层。这导致“同物异名”(如“食品”vs“生鲜食品”)、“同名异物”(如“活跃用户”指月活 vs 日活)现象普遍,跨域分析结果失真。 作为 Gartner 中国数据编织代表厂商,Aloudata CAN 的核心理念正是解决这一根本性架构问题。 Aloudata CAN 通过 NoETL 语义编织技术,在 DWD 明细层之上构建了一个与物理存储解耦的统一语义层。其核心是语义引擎,数据团队无需预先物理打宽,只需通过声明式策略,基于明细数据定义业务实体(如表)之间的逻辑关联(Join)。系统据此在逻辑层面构建一个 “虚拟明细大宽表” 或 “虚拟业务事实网络”。 权威背书:某头部券商在落地 Aloudata CAN 后,实现了全公司 100% 的指标口径一致,彻底消除了因数据定义分歧导致的决策争议。 核心挑战:直接基于明细数据动态关联查询,极易因复杂 Join 和全表扫描导致性能灾难。业务用户无法接受一个“灵活”但响应缓慢的分析系统,尤其是固定报表和即席分析对性能有严格要求(通常要求 P90 < 3秒)。逻辑模型的灵活性不能以牺牲查询性能为代价。 技术根因:分析路径从预计算的物理宽表,转变为运行时动态关联的明细数据,计算复杂度和 I/O 压力激增。 Aloudata CAN 的智能物化引擎提供了性能保障的关键机制。它并非全自动识别,而是基于 “声明式策略”:用户在界面配置声明需要加速的对象(如一组高频查询的指标和维度组合)及时效要求,系统则据此自动编排 ETL 任务,生成并维护多级物化结果。 1、三级物化机制: 2、智能查询路由:当查询发起时,语义引擎会自动进行 SQL 改写和智能路由,透明地命中最优的物化结果,对用户完全无感,实现“空间换时间”。 3、权威背书:某全球连锁餐饮巨头在 Aloudata CAN 上承载了百亿级数据规模,实现了 P90 < 1秒 的极致查询性能,日均支撑百万级 API 调用。 核心挑战:现有数百张 ADS/DWS 宽表承载着大量历史报表和业务逻辑,如何迁移、复用或平稳下线,避免业务中断和团队抵触,是落地成功的关键。推倒重来式的“革命”不仅成本高昂,且失败风险极大。团队技能转型和现有资产如何处置,是比技术更复杂的难题。 技术根因:“烟囱式”开发遗留了大量资产,缺乏统一的资产演进和下线管理机制。 Aloudata CAN 倡导 “存量挂载、增量原生、存量替旧” 的渐进式技术策略,确保转型平滑可控: 权威背书:某头部股份制银行采用此策略,成功沉淀了 1万+ 指标,并使自助交付的数据集占比达到 65%,在保障业务连续性的同时实现了架构升级。 以 某知名服饰品牌 的实践为例,展示了如何在可控风险下快速实现价值: 为帮助数据负责人启动转型,建议聚焦以下四个可操作的决策点: 是架构范式上的替代,而非简单功能补充。传统 DWS/ADS 是“物理宽表”层,而指标平台是基于 NoETL 的“统一语义层”。后者旨在通过逻辑模型和智能计算替代大量人工 ETL 开发的物理表,实现口径、敏捷、成本的全局最优。但在落地过程中,两者可并存,并通过渐进策略逐步迁移。 角色价值将升级而非削弱。ETL 工程师从重复的“SQL 工人”转向更核心的“语义模型架构师”和“数据资产治理专家”;数据分析师则从“取数工具人”解放出来,真正专注于业务洞察与策略分析。转型成功的关键在于团队的技能升级与职责再定义。 成功可从三个维度量化:1) 效率指标:平均需求交付周期(应从周/天级缩短至分钟/小时级);2) 质量指标:核心业务指标的口径一致率(目标 100%);3) 成本指标:ADS/DWS 层物理表的数量增长趋势(应得到遏制并下降),以及整体数据基础设施的 TCO(应有明显降低)。引言:从“物理宽表”到“语义编织”,转型的必然与隐忧
风险一:架构颠覆性风险——如何确保逻辑模型的统一与稳定?
对策:构建“虚拟业务事实网络”,实现定义即治理
风险二:性能保障风险——逻辑查询如何实现亿级数据秒级响应?
对策:声明式物化加速引擎,智能路由实现“空间换时间”
风险三:组织与资产迁移风险——如何平滑过渡而非推倒重来?
对策:“三步走”渐进式策略,平衡创新与稳定
案例验证:从风险预见到价值实现的全路径
行动建议:启动轻数仓转型的四个关键决策点
常见问题 FAQ
Q1: 指标平台和传统数据仓库的 DWS/ADS 层到底是什么关系?是替代还是补充?
Q2: 引入指标平台后,原有的 ETL 工程师和数据分析师角色会受到什么影响?
Q3: 如何量化评估一次轻数仓转型是否成功?有哪些关键指标?
Key Takeaways(核心要点)
2026年4月17日 2026年,《数据安全法》《网络安全法》深入落地,IPD项目涉及的需求文档、研发代码、测试数据等敏感信息,对项目管理工具提出更高安全要求。本次测评覆盖禅道、Jira Data Center、Azure DevOps、Redmine、Zoho Projects、泛微·事井然6款工具,均基于官方资料整理,确保信息真实可追溯。 国内开源IPD项目管理软件先驱,聚焦研发全生命周期管理,支持私有部署,适配信创环境,广泛应用于政企、金融、制造等对数据安全要求高的行业。 IPD版提供从需求至决策评审的核心管理功能,帮助企业缩短产品上市时间,构建高效集成产品开发体系,支持需求-任务-缺陷全链路追踪。 Atlassian旗下企业级研发管理工具,主打敏捷研发全流程管控,支持公有云、私有部署,全球互联网、科技企业广泛使用。 适配Scrum、Kanban等敏捷模式,支持迭代规划、冲刺管理,可通过插件扩展IPD流程管控能力,适合国际化研发团队。 微软旗下一体化DevOps协作平台,聚焦需求-代码-测试-交付全流程管理,支持公有云、本地部署,适配微软技术栈企业。 覆盖Boards(项目管理)、Repos(代码管理)、Pipelines(CI/CD)等全链路,适合研发流程规范、工程体系较重的企业。 开源轻量级项目管理工具,支持多项目、多语言管理,无官方私有部署付费版,适合中小型研发团队与非敏感数据场景。 支持基础需求跟踪、Wiki文档管理,适合小型团队轻量级IPD流程落地,复杂IPD场景需额外插件扩展。 Zoho旗下SaaS项目管理工具,主打轻量化协作与工时管理,无本地部署选项,适合中小型企业与远程团队。 支持WBS项目分解、甘特图、工时跟踪,适合轻量级IPD项目管理,复杂研发流程需与其他工具协同。 政企专用项目管理工具,聚焦安全合规与信创适配,支持私有部署,适配政务、国企等涉密等级较高场景。 支持低代码自定义流程与报表,与泛微OA、ERP、CRM无缝集成,适合政企复杂IPD项目管理场景。 2026年IPD项目管理软件选型,数据安全与权限管控是核心指标。6款工具各有优势: 企业选型需结合部署模式、合规要求、IPD适配度综合决策,优先选择支持私有部署、通过权威安全认证、权限颗粒度高的工具,筑牢研发数据安全防线。
预计阅读时间:约8分钟随着IPD(集成产品开发)模式在企业研发管理中的普及,项目数据的安全性与权限管控成为核心关切。本文聚焦6款主流IPD项目管理软件,从数据安全、权限管理、合规能力等维度展开中立测评,帮企业精准选型,筑牢研发数据安全防线。
一、测评背景与核心标准
1.1 测评背景
1.2 核心测评维度
测评维度 核心考察点 数据安全 加密方式、部署模式、备份机制、漏洞防护 权限管理 权限颗粒度、角色定义、访问控制、动态调整 合规能力 等保认证、ISO认证、信创适配、审计追溯 IPD适配 需求-研发-交付全流程管控、流程自定义能力 二、6款IPD项目管理软件安全性能完整测评
1. 禅道(开源+商业双模式)
核心定位
数据安全能力
权限管理体系
IPD适配亮点
2. Jira Data Center(商业版)
核心定位
数据安全能力
权限管理体系
IPD适配亮点
3. Azure DevOps(微软生态)
核心定位
数据安全能力
权限管理体系
IPD适配亮点
4. Redmine(开源版)
核心定位
数据安全能力
权限管理体系
IPD适配亮点
5. Zoho Projects(SaaS模式)
核心定位
数据安全能力
权限管理体系
IPD适配亮点
6. 泛微·事井然(商业版)
核心定位
数据安全能力
权限管理体系
IPD适配亮点
三、核心维度对比总结
工具名称 部署模式 核心安全认证 权限颗粒度 IPD适配度 适用场景 禅道 私有部署 等保2.0三级、ISO27001 高(三级继承+三权分立) 高(全流程IPD管控) 政企、金融、制造等信创场景 Jira Data Center 公有云/私有部署 ISO27001、GDPR 高(全局/项目/问题级) 中高(敏捷为主) 国际化互联网、科技企业 Azure DevOps 公有云/本地部署 ISO27001、SOC 中高(组织/项目/对象) 高(DevOps全链路) 微软生态、流程规范的研发团队 Redmine 自托管私有部署 社区认证 中(角色/项目级) 中(轻量级) 中小型非敏感数据团队 Zoho Projects 纯SaaS ISO27001、GDPR 中高(门户/项目/模块) 中(轻量化) 中小型企业、远程协作团队 泛微·事井然 私有部署 等保2.0三级、ISO27001 高(组织/角色/项目) 高(政企定制化) 政务、国企等涉密场景 四、分场景选型建议
1. 创业团队(轻量级IPD、预算有限)
2. 中大型企业(研发规模大、合规要求高)
3. 政企/涉密场景(信创、等保、审计要求严格)
4. 远程协作团队(轻量级管理、跨地域协同)
五、全文总结
六、高频疑问FAQ
1. 私有部署与SaaS模式在数据安全上的核心区别是什么?
2. 如何避免IPD项目管理工具权限混乱导致的数据泄露?
3. 信创环境下选择IPD项目管理工具需重点关注哪些指标?
我在 Google 用中文提问关于 opencode 的问题,现在的回答基本上都不对,反而是千问都没啥问题。
eslint + stylelint + prettier 很有名吗?
代码质量、代码风格我感觉自己一窍不通啊。




































































