30行代码爬取妹子图整站美女图片
注意:
1.由于是python2.7写的,请不要把文件名字改成中文,否则有可能闪退或执行不成功。
2.由于是python2.7写的,请不要存放在带有中文的路径中,比如桌面,就有可能执行不成功。可以尝试放到任何一个盘的根目录再测试。2017年10月12日更新: (版本号:mztSpider_v1.0.exe)
1.把程序打包成EXE文件.
2.因为scrapy不能打包成单个EXE环境,所以将文件修改成单文件,并采用多线程.
EXE文件下载地址:
链接: https://pan.baidu.com/s/1bpvYlNh 密码: fxn2
2017年10月13日更新: (版本号:mztSpider_v1.1.exe)
1.增加由用户输入起始页.
2.重新引入sys包设置编码,解决部分用户乱码和闪退问题.
3.取页面图片个数规则重新调整,解决部分用户爬取到一半程序会退出问题
EXE文件下载地址:
链接: https://pan.baidu.com/s/1bpvYlNh 密码: fxn2
2017年10月13日更新: (版本号:mmjpgSpider_v1.0.exe)
1.更改爬取链接
2.把爬取代码提取成方法
EXE文件下载地址:
链接: https://pan.baidu.com/s/1bpvYlNh 密码: fxn2
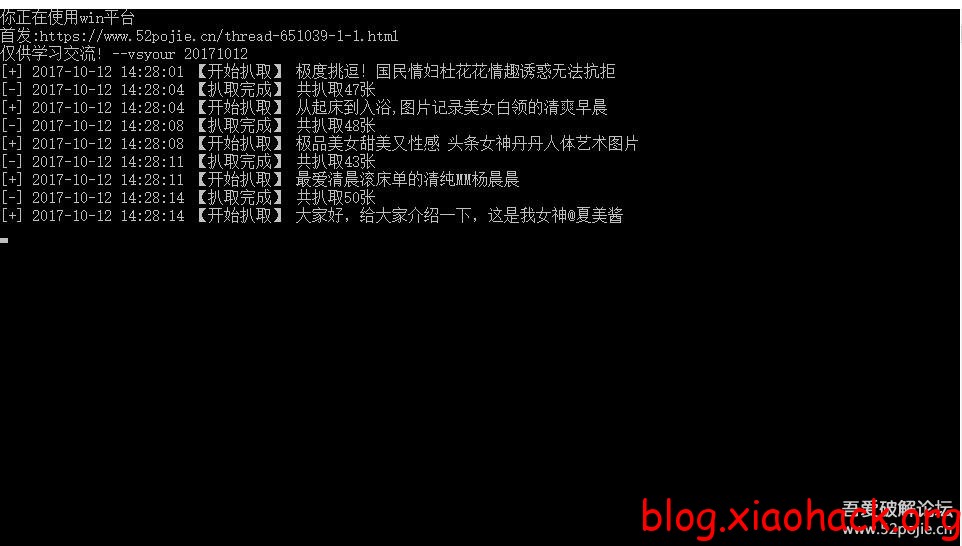
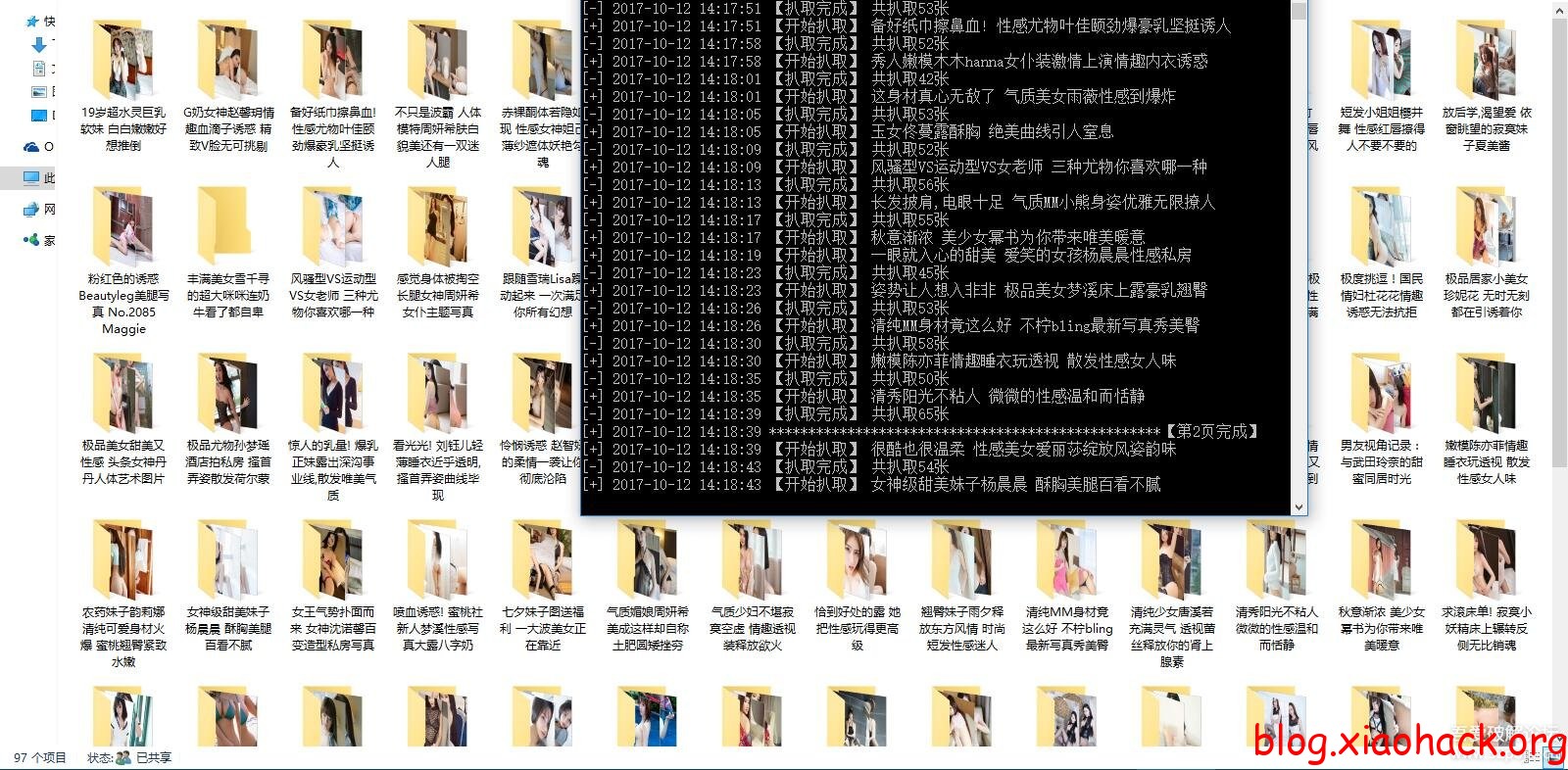
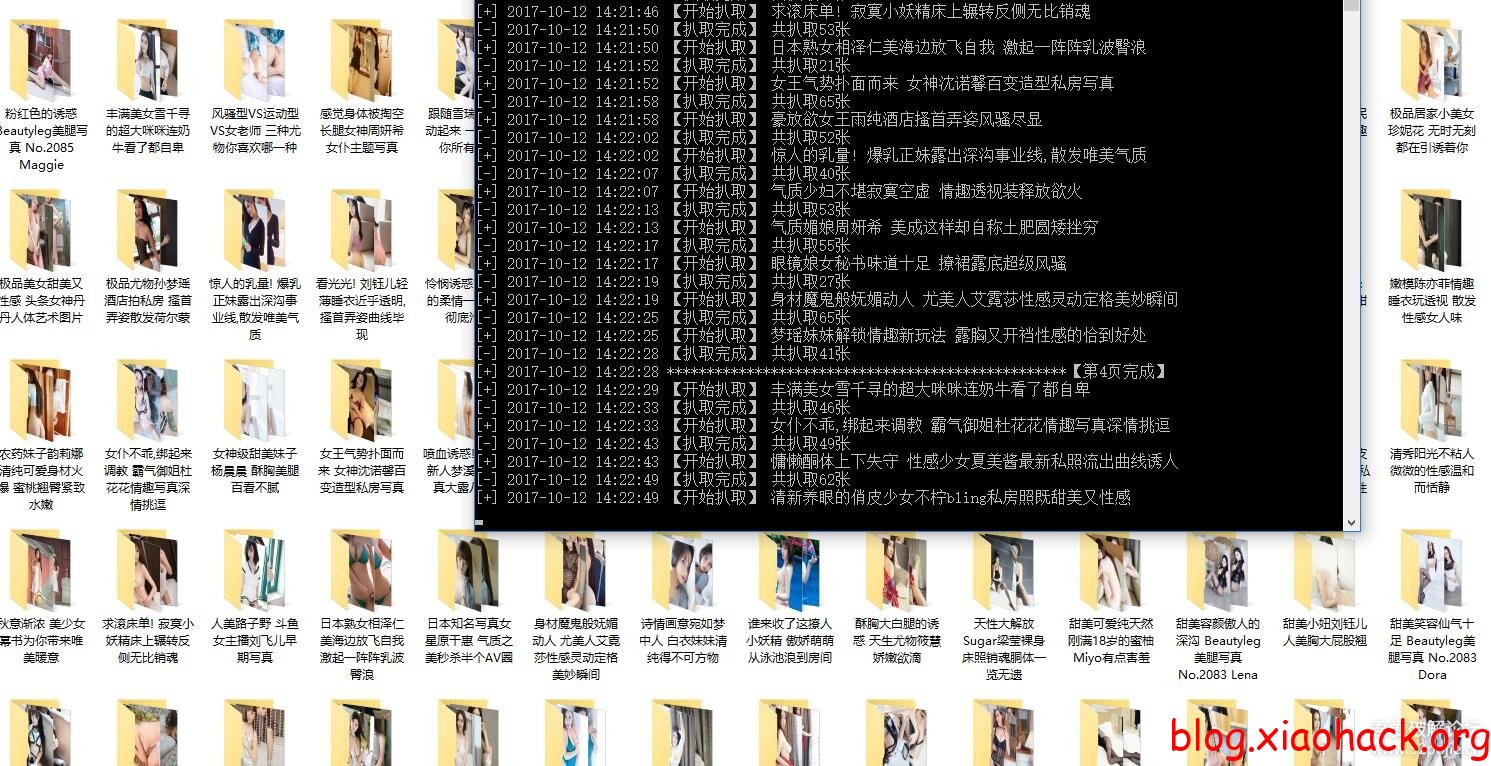
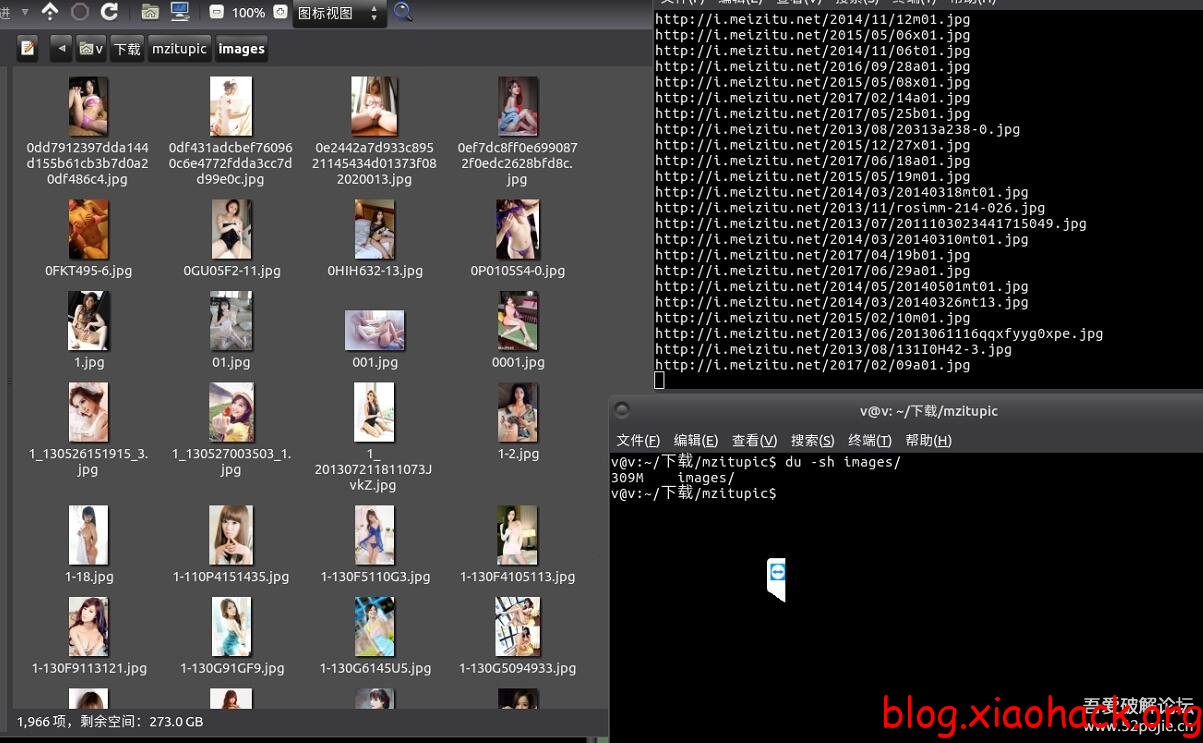
更新后效果图:
 爬行效果图:
爬行效果图:
scrapy Spider完整代码:
# -*- coding: utf-8 -*-
import requests
import os
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MzituSpider(CrawlSpider):
name = 'mzituSpider'
start_urls = ['http://www.mzitu.com/']
rules = (Rule(LinkExtractor(allow=('http://www.mzitu.com/\d{1,6}',), ), callback='parse_item', follow=True),)
def header(self, referer):
headers = {
'Host': 'i.meizitu.net',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
'Accept': 'image/webp,image/apng,image/*,*/*;q=0.8',
'Referer': '{}'.format(referer),
}
return headers
def parse_item(self, response):
imageUrl = response.css(".main-image img ::attr(src)").extract_first()
with open('images' + os.sep + imageUrl.split('/')[-1], "wb+") as jpg:
jpg.write(requests.get(imageUrl, headers=self.header(imageUrl)).content)以下方法不需要了,直接下载EXE文件执行就行了.执行方法:
1.必须安装scrapy。
2.scrapy startproject mzitu
3.cd mzitu
4.scrapy genspider mzituSpider www.mzitu.com
5.在spider下会生成一个mzituSpider.py的文件,把上面的内容替换一下就可以执行了。
6.scrapy crawl mzituSpider
感觉没有点基础的会有点难。我决定折腾下看是不是可以打包成Exe文件,给大家发出来。。。
不过这玩意爬的人多了不知道会不会把人家妹子图站给爬死去。。要是人家用阿里云 ,每个整个5G的上行流量费用也得好几块哈。
补链谢谢
链接挂了