AMD,Yes!搞定 AMD 显卡在 Windows 本地部署 ComfyUI + Z-Image 生图的全流程及踩坑记录
AMD 7800XT 显卡 Windows 本地部署 ComfyUI + Z-Image 保姆级教程
前言
作为一名 AMD Yes! 用户,想在本地跑 AI 生图实在费劲。
网上很多教程推荐使用 WSL(Linux 子系统)或者双系统,我折腾了一圈,全部以失败告终,不仅步骤繁琐,还容易报错。
经过多次尝试,我终于摸索出了一套 在 Windows 下最稳、最简单的方案:利用 秋叶大神的整合包 + ZLUDA。现在我也能愉快地生图了,把踩过的坑分享给大家,希望能帮到同样使用 A 卡的佬友。
第一步:搞定驱动
AMD 跑 AI,驱动是重中之重。这里有两个巨大的坑,请严格按照以下步骤操作:
1. 下载并安装专用驱动
你需要安装特定的 PRO 版本驱动来支持 ROCm/HIP 环境。请按顺序下载:
HIP 支持驱动 (必须安装) :
- 版本:
AMD-Software-PRO-Edition-23.Q4-Win10-Win11-For-HIP - 下载地址:点击下载
- 版本:
显卡核心驱动 (配合使用) :
- 版本:
AMD-Software-PRO-Edition-25.Q3(由于官方链接失效,请使用第三方备份) - 下载地址:DriversCloud 下载
- 版本:
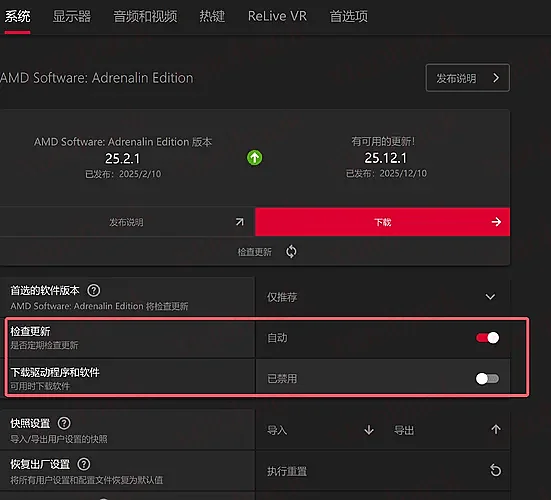
避坑指南 1:禁止驱动自动更新!
非常重要! 安装完上述驱动后,一定要在 AMD 驱动软件设置里,把 “自动更新” 关掉!
如果不关,重启电脑后它会自动更新到最新的游戏驱动,会导致环境失效(比如提示显存不足、报错等),那时候就得全部重来了。
第二步:安装 ComfyUI 整合包
为了省去繁琐的代码部署,我们直接使用 B 站秋叶大佬的整合包,开箱即用。
- 下载地址:夸克网盘
- 解压密码:
bilibili-秋葉aaaki
操作步骤:
- 下载并解压
ComfyUI-aki-v2。 - 点击
启动器运行。
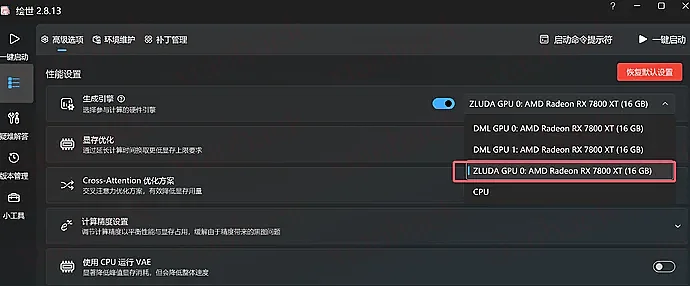
启动器设置(启用 ZLUDA)
进入启动器界面后,不要急着点运行:
- 在启动器设置或内核选择中,找到 ZLUDA 选项并选中它(这是让 A 卡模拟 N 卡环境运行的关键)。
- 确保显卡选项已正确识别你的 7800XT。
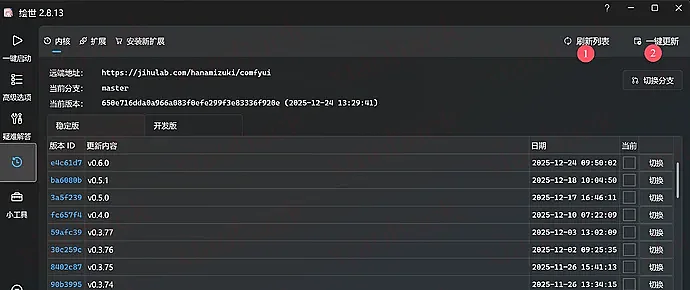
第三步:更新内核(避坑指南 2)
这里是很多人失败的地方。整合包自带的核心可能较旧,直接跑新模型会报错。
操作方法:
在启动器界面,找到 “版本管理” 或 “更新” 选项,选择 “最新代码”,点击 一键更新。
更新完成后,务必 重启软件,否则工作流可能无法正常加载。
第四步:模型选择与配置(性能优化篇)
避坑指南 3:显存不够怎么办?
我的 7800XT 虽然有 16G 显存,但在跑完整版 Z-Image (Flux) 模型时,显存依然捉襟见肘。
- 完整版现状:生一张图需要 500 秒 左右(严重爆显存,速度极慢)。
- 优化方案:使用 FP8 Scala 版本 的模型。
优化后的效果:
- 显存占用:仅需 6-7G。
- 生成速度:缩短至 50 秒 一张图(速度提升 10 倍!)。
- 画质损失:几乎肉眼不可见。
必备模型下载清单
Z-Image Turbo 需要三个核心组件才能运行:主模型、文本模型、VAE。 请按照下面的清单下载,并严格放入对应的文件夹中(找不到文件夹就根据路径自己新建一个,注意文件名不要改动太大)。
提示:由于涉及 HuggingFace 和 Civitai,部分网络可能需要魔法才能打开。
1. 主模型 (Checkpoints)
这是画图的主力核心,我们选用的是针对显存优化的量化版本,非常适合 7800XT 这样的 16G 显卡。
模型名称:
Z-Image-Turbo (Quantized)下载地址:点击前往 Civitai 下载
存放路径:
ComfyUI-aki-v2\models\checkpoints
2. 文本模型 (Text Encoder / CLIP)
这是 AI 的 “耳朵”,用来听懂你的提示词。Z-Image 使用的是 Qwen (通义千问) 的 3.4B 版本作为文本编码器。
模型名称:
qwen_3_4b.safetensors下载地址:点击前往 HuggingFace 下载
存放路径:
ComfyUI-aki-v2\models\clip(注:如果文件夹里没有
clip文件夹,找一下有没有text_encoders,或者直接手动新建一个clip文件夹)
3. VAE 模型 (解码器)
这是 AI 的 “眼睛”,负责将计算好的数据解码成我们在屏幕上看到的像素图片。如果没有它,生成的图可能是一片灰色或彩色噪点。
- 模型名称:
ae.safetensors - 下载地址:点击前往 HuggingFace 下载
- 存放路径:
ComfyUI-aki-v2\models\vae
- 主模型 (Checkpoints) :下载
fp8版本的 Z-Image/Flux 模型。 - 文本编码器 (Text Encoder) :下载
Qwen 8B(或对应的 Clip/T5) 文本模型。没有它,AI 听不懂你的提示词,点击下载。 - VAE 模型:下载对应的 AE/VAE 模型。没有它,生成的图片会是一片灰或者噪点,点击下载。
第五步:愉快生图
将下面的内容保存为 json
{ "2": { "inputs": { "text": "a beautiful landscape, high quality, 8k", "clip": ["16", 0] }, "class_type": "CLIPTextEncode", "_meta": { "title": "正向提示词" } }, "4": { "inputs": { "seed": , "steps": 8, "cfg": 1, "sampler_name": "euler", "scheduler": "simple", "denoise": 1, "model": ["15", 0], "positive": ["2", 0], "negative": ["9", 0], "latent_image": ["5", 0] }, "class_type": "KSampler", "_meta": { "title": "K采样器" } }, "5": { "inputs": { "width": 768, "height": 768, "batch_size": 1 }, "class_type": "EmptyLatentImage", "_meta": { "title": "空Latent图像" } }, "6": { "inputs": { "vae_name": "ae.safetensors" }, "class_type": "VAELoader", "_meta": { "title": "加载VAE" } }, "7": { "inputs": { "samples": ["4", 0], "vae": ["6", 0] }, "class_type": "VAEDecode", "_meta": { "title": "VAE解码" } }, "8": { "inputs": { "filename_prefix": "ComfyUI", "images": ["7", 0] }, "class_type": "SaveImage", "_meta": { "title": "保存图像" } }, "9": { "inputs": { "text": "blurry, ugly, bad, lowres, jpeg artifacts, watermark, distorted, noisy, artifact, glitch, oversaturation, neon tones, harsh contrast or glow, color cast, pixelated, blocky", "clip": ["16", 0] }, "class_type": "CLIPTextEncode", "_meta": { "title": "反向提示词" } }, "15": { "inputs": { "ckpt_name": "zImageTurboQuantized_fp8ScaledE4m3fnKJ.safetensors" }, "class_type": "CheckpointLoaderSimple", "_meta": { "title": "加载主模型" } }, "16": { "inputs": { "clip_name": "qwen_3_4b.safetensors", "type": "stable_diffusion" }, "class_type": "CLIPLoader", "_meta": { "title": "加载CLIP文本编码器" } } } 在工作流界面,按住 Ctrl+O,选择刚才的 json,导入后会形成如下工作流,点击运行即可。
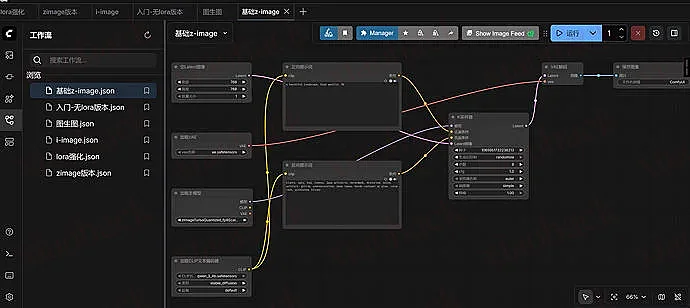
这套工作流非常强大,不仅可以用来提示词生图,还能先炼丹,用 lora 脸模、腿模等配合提示词生图,还能生成视频,不过生成视频的模型需要更高的版本才支持,这属于进阶篇了,我折腾了几天目前这套已经足够使用了。