使用 axonhub 对自己已有的公益 & 2api 进行整合 + 负载均衡
最近自己的 CLIProxyAPI 组上了家庭组,同时站内各位大佬的公益也是囤了不少额度,不过蹬起来还是有时候难免会顶到自己账号的限额或者服务不稳定的情况。之前使用的是 new-api+GPT Load 的方式实现多个渠道模型的整合。不过最近在用站内 佬的 axonhub,感觉用起来差不多可以替代前者两个项目加起来的办法了。写个大概的教程。
第一步:部署 axonhub
从仓库中下载需要的版本,没有服务器的话可以直接下载电脑的版本。有服务器的佬可以直接用 docker compose 进行部署,默认的配置用的就是 postgreSQL,直接 pull 完了就可以 up 了。
打开默认的 8090 端口,如果是电脑的话可以访问
http://localhost:8090
刚开始需要创建一个管理员账号,邮箱和密码随便写。
第二步:添加渠道(即你的 API 来源)
进入左侧栏中的渠道页面,右上角点击添加渠道,然后选择传入的格式。大部分的公益站使用的都是 new-api,所以我们一般选择 openai 的格式即可。这里用 F 佬的公益站举例。
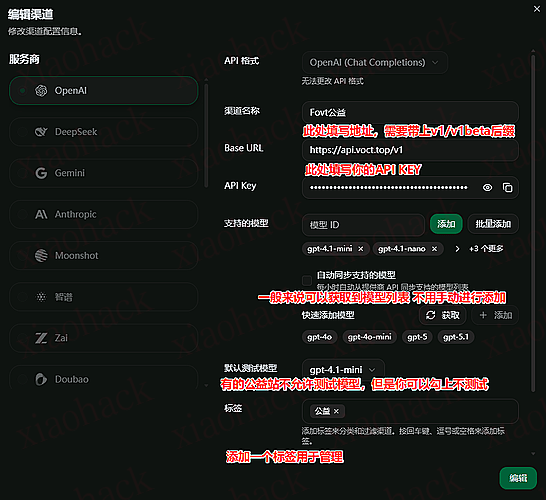
这里需要注意的是,在这个页面是没有办法添加代理地址的,所以如果你的服务器因为网络问题没有办法访问 gemini/cerebras/groq 等等平台的话,需要先手动添加模型然后再去添加代理。
loop 佬这个代理的添加逻辑看看能不能改一下,另外及时添加了代理还是没有办法获取模型列表,看上去只有在调用的时候才使用代理
第三步:添加模型(对外暴露的,也就是你实际调用的)
在添加了若干个渠道之后,我们就可以开始配置我们实际要使用的模型了,也就是我们在各种 cli 工具 / AI 对话客户端中需要使用到的模型。
进入左侧栏的模型,选择添加模型,模型多的话也可以选择使用批量添加模型。
举个例子,假设现在薄荷佬、Fovt 佬、以及我自己的 openrouter 都有 gpt-4.1-mini 这个模型。那么就可以点击批量添加,然后选择好提供商,从模型 ID 里面选择自己需要的模型

目前感觉可以改进的地方:
- Qwen 居然不在提供商列表里
- 若模型 ID 不在提供商列表里,手动输入 - enter 会导致自动添加已有列表中第一个模型。
然后我们库库把自己需要对外暴露的模型选择好了之后,就可以保存了。
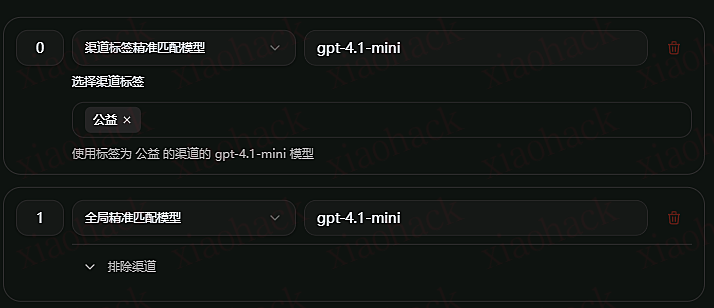
现在已知我有三个来源,都是同一个模型。那么我们可以进行模型的关联。点击对应模型上的符号,即可进行关联。

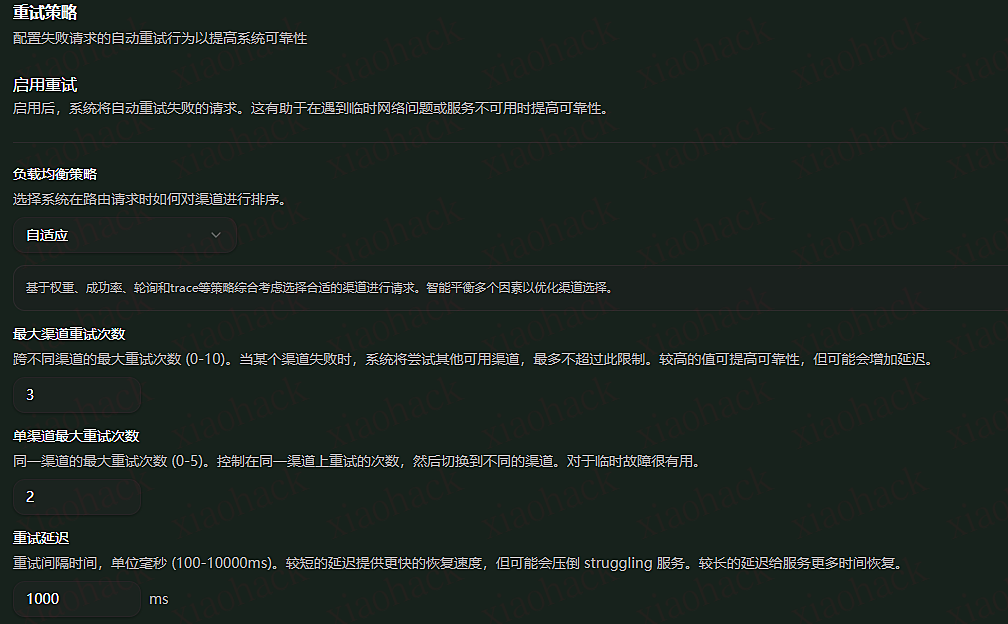
关联规则有很多,可以指定渠道或者全局;可以使用精确匹配或者正则。同时还可以设定权重。比方我想优先使用公益站的模型,那么我只需要设置一个标签的规则,并且把数字放在最小的 0 即可。当然,这一步就需要提前在添加渠道的时候对渠道打好标签。在上图右侧中,从上到下为模型的优先顺序。
若需要对渠道也加上权重,eg. 比方都是公益站,我想先使用 Fovt 佬的,那么我可以在设置渠道的时候就设置好更高的权重。回到渠道标签页,批量排序即可。
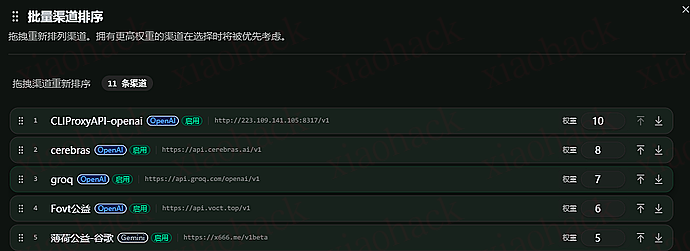
未关联模型页面
不过现在虽然可以查看所有未关联的模型,但是不能批量对未关联的模型进行关联。要是可以在检测未关联渠道的这个页面关联模型就好了。
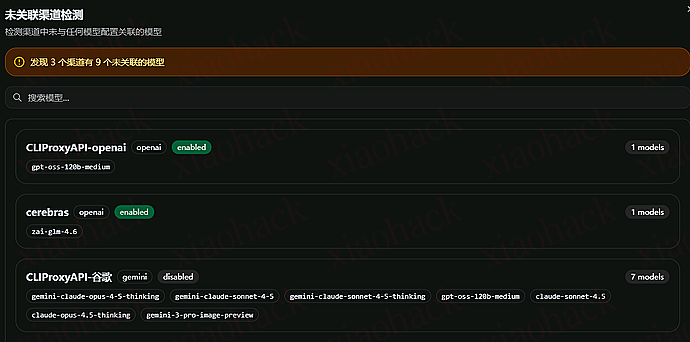
3.1 关闭查询所有渠道模型
我想要对外暴露我自己已经设置了关联的模型,不想要看到我渠道的原始模型,那么需要在模型设置页面关闭下方的这个设置。
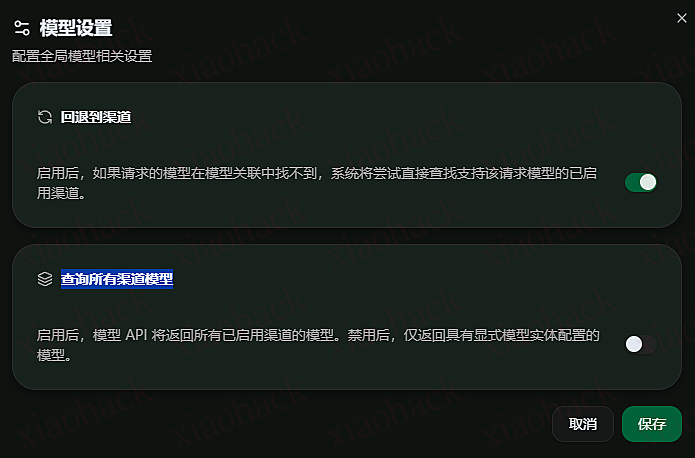
关闭前你的 API 是可以看到已启用渠道的所有模型的,关闭后只能看到你模型页设置的模型。
3.2 模型关联的别的玩法
假设我想对外暴露 gpt-4.1-mini 这个模型,但是其中混用 gpt-oss-120b 或者其他自己想用的模型,那么也可以在关联规则里面直接添加。这样子你的客户端调用的即使是 gpt-4.1-mini,也可以按照自己设置的权重进行分流。
第四步:自用不一定用得上但是很强大的功能
4.1 角色
你可以给你的团队加入其他的成员,可以分配不同的角色。还可以创建多个项目,给不同项目分配不同的成员…… 但是如果只是自用整合的话,这个部分其实不用太怎么折腾。
4.2 追踪和线程
这一部分的配置文档可以在文档中查看,也就是在请求的时候添加两个 headers 就可以追踪。不过这一块我还不知道怎么用,等待大佬解答告诉我应用场景。

第五步:开始使用
当你配置好了之后,就可以开始愉快的使用了。接入的时候使用 /v1 后缀,openai 格式。如果你在前面已经对渠道进行了权重调整、对模型也设置好了有优先等级的关联规则,那么恭喜你,现在你已经将你所有来源的 API 进行了整合,并且以统一的格式进行使用。而且还带上了负载均衡,现在就可以开始愉快的蹬啦!