订阅导致封号问题请教
看到很多 V 友发帖说 claude 账号被封问题,我目前是使用 GooglePlay 订阅的 20 美元的 Pro 套餐,已经稳定订阅一年左右了。
目前感觉额度不够用,想升级到 5X 的 MAX(对应官网是 100 美元的)。
请问下,之前出现封号的都是 MAX 套餐的吗?是 100 美元还是 200 美元的封号概率大些,还是说只要升级到任意 MAX 套餐都会有大概率被封。
目前我使用的是台湾住宅 IP(购买 IP 时人家是这样宣传的)
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
看到很多 V 友发帖说 claude 账号被封问题,我目前是使用 GooglePlay 订阅的 20 美元的 Pro 套餐,已经稳定订阅一年左右了。
目前感觉额度不够用,想升级到 5X 的 MAX(对应官网是 100 美元的)。
请问下,之前出现封号的都是 MAX 套餐的吗?是 100 美元还是 200 美元的封号概率大些,还是说只要升级到任意 MAX 套餐都会有大概率被封。
目前我使用的是台湾住宅 IP(购买 IP 时人家是这样宣传的)
不仅限于打工,还可以是轻创业等。目前我能想到的是:
1 、学做水电工、木工等;
2 、做线上教培;
3 、做上门维修;
https://developers.openai.com/api/docs/pricing?latest-pricing=standard
| Model | Input Credits | Output Credits |
|---|---|---|
| GPT-5.3-Codex | 43.75 | 350 |
| GPT-5.4 | 62.50 | 375 |
| GPT-5.5 | 125 | 750 |
天塌了啊,最新 openai 的模型越来越贵,穷人要用不起了啊
看 gpt5.5 的 token 价格翻倍了感觉不妙,结果一看 codex 消耗果然相比 5.4 也翻倍了
本来 codex 的 credit 计算规则改了后就明显消耗量加快了,结果现在 5.5 用量还翻倍了
然后 codex 中 5.5 默认的推理强度还是 extra high 。。。。。
当作和 opus 一样的高级模型好了。。。。
简单试了下天气卡片,中文英文都试了,太简陋了:

中文:
创建一个包含 CSS 和 JavaScript 的单一 HTML 文件,用于生成动画天气卡片。卡片应该通过不同的动画直观地表示以下天气状况:
风:(例如,移动的云朵、摇摆的树木或风线)
雨:(例如,下落的雨滴、形成的水坑)
阳光:(例如,闪耀的光线、明亮的背景)
雪:(例如,下落的雪花、积累的雪)
所有天气卡片应并排显示,卡片应该有深色背景。
在这个单一文件中提供所有 HTML 、CSS 和 JavaScript 代码。JavaScript 应该包含一种切换不同天气状况的方式(例如,一个函数或一组按钮)以展示每种天气的动画效果。
英文:
Create a single HTML file containing CSS and JavaScript to generate an animated weather card. The card should visually represent the following weather conditions with distinct animations: Wind: (e.g., moving clouds, swaying trees, or wind lines) Rain: (e.g., falling raindrops, puddles forming) Sun: (e.g., shining rays, bright background) Snow: (e.g., falling snowflakes, snow accumulating) Show all the weather card side by side The card should have a dark background. Provide all the HTML, CSS, and JavaScript code within this single file. The JavaScript should include a way to switch between the different weather conditions (e.g., a function or a set of buttons) to demonstrate the animations for each.

现在很多社会现象我觉得不好,但是往往它却很流行很潮流。下面列几个
1 无论男女,裤子前面的绳子,都快拖到地上了,这不是夸张,当然多数没那么长,但是我看起来总有违和感。我也有这样的裤子,每次我都塞到裤子,外面看不到。我依稀记得,在我小时候,村子里的傻子会把裤腰带这么松松垮垮的挂在那里。
2 有的男的跑步,穿紧身裤,胯下之物就那么突兀显现着。虽然女的的漏 b 的没那么违和,但是男的这样我真的不忍直视。
平时有不少,真的行之为文的时候,又想不起来了。 那就这些吧。
最期待的模型之一,希望能把 token 价格打下来
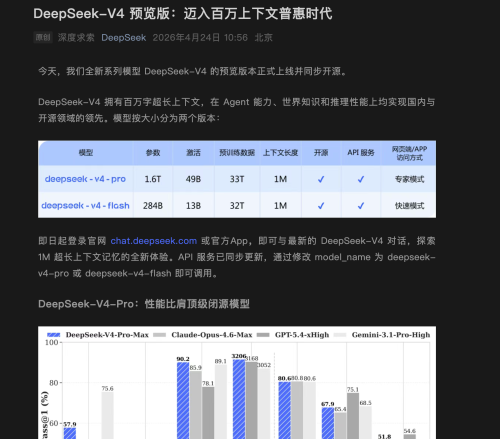
各位老哥们好,我是一个毕业工作 2 年的新人,最近领导在给我安排工作的时候我之前的工作喜欢和工作方式好像和他期待的不太一样。想发出来让大家分析下是我太学生思维了吗?
最近公司买了个机器人,他安排我去研究下,然后跑一个案例,能让他动起来。当时的原话是“你去跑一下网上这个案例,然后了解下他是怎么驱动起来的”
然后我就正常的跑官方案例,中间遇到很多环境,沟通的问题。重点是我对他的了解 可能只在表面,就是他是个什么,有哪些重要技术实现,然后基础的操作逻辑是什么。
但是事后领导让我分享的时候,会问的非常非常细致,比如这个技术 ROS 现在市场上使用情况怎么样,有没有其他控制方式,机器人我们如果自己独立二开应该是什么流程。
我总结一下是,我收到的消息是干 A 然后我根据字面意思理解为要做的任务,加一些必要的基础了解作为任务去做。
如果完全懂是 100 分,我感觉根据我的理解和他给我干的天数我做这个任务是 30 分。
但是他的要求和提问的内容我觉得算是 80 分。
最近让我调用一个 CGRA 的基础技术卡,
然后我就去看了下但是我只看了具体型号的卡,他的核心创新是什么,里面很多专有名词,我只理解个大概没有很深入的理解。
后面他问的时候就问的非常深入和广,比如这个 CGRA 技术实现原理,和 gpu ,ASIC 对比有什么优缺点,现在市场上还有谁在用。等等。
由此我有一个疑问,他交给我的任务可能是一句具体的话“跑下这个案例”“调研下 xxx 加速卡” 我理解的是字面意思+一些基础的必要知识信息。
但是他后续给我的资源(天数比较少)和要求给我的感觉是他需要一个很懂,或者是至少是 70 分的理解水平,不只是任务本身,他的生态,原理,对比起等.....
所有我想问下大多数工作都是这样的吗?是我太学生思维了还是一般情况下都会明确的告诉你你要干到是什么程度....
期望各位工作久了的前辈解惑下
https://developers.openai.com/api/docs/pricing?latest-pricing=standard
| Model | Input Credits | Output Credits |
|---|---|---|
| GPT-5.3-Codex | 43.75 | 350 |
| GPT-5.4 | 62.50 | 375 |
| GPT-5.5 | 125 | 750 |
天塌了啊,最新 openai 的模型越来越贵,穷人要用不起了啊
看 gpt5.5 的 token 价格翻倍了感觉不妙,结果一看 codex 消耗果然相比 5.4 也翻倍了
本来 codex 的 credit 计算规则改了后就明显消耗量加快了,结果现在 5.5 用量还翻倍了
然后 codex 中 5.5 默认的推理强度还是 extra high 。。。。。
当作和 opus 一样的高级模型好了。。。。
各位Cder好,我是长期混迹在金融系统开发前线的一名后端工程师。最近在帮业务线排查一个网络IO问题时,我发现了一个非常有意思的现象:每逢法定长假,我们接入的A股实时行情服务就会大量爆出超时日志,甚至引发上游服务的雪崩。经过深入的源码级排查,我意识到这不仅仅是简单的网络问题,而是业务场景与网络协议之间的碰撞。今天就来和大家硬核分享一下。 在我们这套架构里,我们需要通过WebSocket建立长连接,以极低的延迟接收股票的实时Tick信息。这对于需要进行实时计算的服务来说是刚需。但大家都知道,A股的运行时间是由各种法定节假日和调休决定的。这就意味着,我们的长连接在某些特定的日子里,会面临比平日里更早结束或者更晚开始的数据流阻断。 当我们用技术视角去透视这个问题时,节假日前后的异常其实可以归结为以下几个技术痛点: 要解决这些痛点,除了客户端要做防御外,服务端API的设计也至关重要。我查阅了多款行情API的官方文档,发现高标准的接口服务在休市状态机的处理上有一套成熟的逻辑。例如之前接入的AllTick API,在其服务端就实现了优雅的降级策略。在节后重启数据流时,它不会一上来就猛灌实时数据,而是先推送一个经过特殊标记的静态历史快照,用于验证连接质量并同步客户端状态,之后才开始稳定分发流式Tick。 来看看底层是怎么建立这套监听机制的: 作为工程师,我们绝不能把系统的稳定性寄托在外部接口的完美无缺上。针对节假日造成的断流,我在中间件层做了如下重构:实时金融数据流的严酷要求
撕开网络底层的痛点表象
优秀的API是如何做产品隔离的?
import websocket
import json
def on_message(ws, message):
data = json.loads(message)
print("收到tick数据:", data)
ws = websocket.WebSocketApp(
"wss://apis.alltick.co/stock/subscribe",
on_message=on_message
)
ws.run_forever()工程应用中的最终解决方案
第一步:基于时间的黑白名单拦截。通过接入开源的交易日历库,精确计算当前是否处于开盘时间。在非交易时段,主动断开WebSocket连接,释放系统句柄资源。
第二步:实现带有退避的重连状态机。利用指数回退(Exponential Backoff)算法处理节后开盘的重连,有效规避惊群效应。
第三步:强类型的数据校验与缓冲。对所有通过WebSocket推过来的文本进行严格的JSON Schema校验。对于节假日异常期可能出现的缺失字段,利用本地的历史Redis缓存进行字段补齐。
搞定这些,你就再也不用在假期结束前一晚,提心吊胆地盯着监控大屏了。
各位老哥们好,我是一个毕业工作 2 年的新人,最近领导在给我安排工作的时候我之前的工作喜欢和工作方式好像和他期待的不太一样。想发出来让大家分析下是我太学生思维了吗?
最近公司买了个机器人,他安排我去研究下,然后跑一个案例,能让他动起来。当时的原话是“你去跑一下网上这个案例,然后了解下他是怎么驱动起来的”
然后我就正常的跑官方案例,中间遇到很多环境,沟通的问题。重点是我对他的了解 可能只在表面,就是他是个什么,有哪些重要技术实现,然后基础的操作逻辑是什么。
但是事后领导让我分享的时候,会问的非常非常细致,比如这个技术 ROS 现在市场上使用情况怎么样,有没有其他控制方式,机器人我们如果自己独立二开应该是什么流程。
我总结一下是,我收到的消息是干 A 然后我根据字面意思理解为要做的任务,加一些必要的基础了解作为任务去做。
如果完全懂是 100 分,我感觉根据我的理解和他给我干的天数我做这个任务是 30 分。
但是他的要求和提问的内容我觉得算是 80 分。
最近让我调用一个 CGRA 的基础技术卡,
然后我就去看了下但是我只看了具体型号的卡,他的核心创新是什么,里面很多专有名词,我只理解个大概没有很深入的理解。
后面他问的时候就问的非常深入和广,比如这个 CGRA 技术实现原理,和 gpu ,ASIC 对比有什么优缺点,现在市场上还有谁在用。等等。
由此我有一个疑问,他交给我的任务可能是一句具体的话“跑下这个案例”“调研下 xxx 加速卡” 我理解的是字面意思+一些基础的必要知识信息。
但是他后续给我的资源(天数比较少)和要求给我的感觉是他需要一个很懂,或者是至少是 70 分的理解水平,不只是任务本身,他的生态,原理,对比起等.....
所有我想问下大多数工作都是这样的吗?是我太学生思维了还是一般情况下都会明确的告诉你你要干到是什么程度....
期望各位工作久了的前辈解惑下
目前版本更新到 v0.2.13 了(基本是周一到周五每天都会更新)和 WorkBuddy 越来越像了。
下面再说说不好的地方
6.和 WB 一样,计量单位从【token】变成了【积分】,原来每天 4000 万 token,现在是 800 积分。主页面也不显示用量了,但是免费的大模型倒是可以自选了,费率不同。
7.存在【抱歉,这个问题我暂时无法解答,让我们换个话题吧~】,之前都是正常的,个人也没觉得这是敏感的内容。
总结:总体来说还是进步明显,帮我做了很多工作中低质量又不得不做的内容,完成的相当好,稳定性也提高了很多,和 WorkBuddy 还是有一些侧重上的差异,下次分享另一个的感受。
最近写项目发现了一个有意思的报错。我发现它让人摸不到头脑,甚至每次写到新增登录方式必然会报一次错。 可以看到是由于懒加载,导致的无法处理代理对象。 验证过滤器拿认证用的方法代码: 报错方法代码: 这里先告诉一下解决方案,先在方法上添加@Transactional,在从数据库拿到user时,在方法结束前调用user.getAuthorities()。其实这里调用user.getRoles()是一样可以的。 什么是懒加载?实际上就是用了代理模式的方法,减小程序的处理压力。 理解了什么是懒加载,以及如何解决上面的问题之后,下面介绍另一个看起来毫无关联但实际上也与懒加载有关系的问题。可以看到下面的报错也很神奇:状态码是200,却是报错了。 在courseItem中的schedule属性加上jsonView。这样可以控制controller返回数据时返回实体的数据,这里不细讲。 两个报错看起来感觉都没什么关联,为什么放到一起。想想我们刚刚讲的懒加载,对于一个实体,加上了@OneToMany等的属性,他是不能拿到值的,我们得在一个加了@Transactional的方法结束前get一下才能显示。上面的代码很明显,就从数据库中拿了数据,按道理不会显示这些关联实体属性(如courseItem)。 其实在最开始关于懒加载的报错最后有一个no session的信息。这个session和HTTP session是一个东西吗?显然不是的。用一个生动的例子讲一下这个session是什么,有什么作用,会做什么。 把 User(用户)想象成一份档案,而 User 拥有的 roles(角色/权限)是贴在这份档案上的标签。 延迟加载(Lazy Loading) Session(会话)是负责取资料的人 懒加载问题发生的瞬间 这时候,程序试图通过便利贴去找办事员(session)去数据库里真正取标签,但办事员已经下班(session 已关闭),没办法取了。于是它就报错: LazyInitializationException: could not initialize proxy - no session 简单说就是:要用的数据在需要被真正读取的时候,负责取数据的“连接”已经断开了。 那么在返回请求的时候开启了session?是的。 时间线是这样的: 请求到达:DispatcherServlet(Spring MVC 核心)开始处理这个请求,OSIV 拦截器立刻为当前线程绑定一个 Hibernate session。 进入控制器方法:你通过 professorRepository.findById(id) 去查教授。这条 SQL 只查了教授表,学生列表并没有被查出来。返回的 Professor 对象里,students 其实是一个“代理对象”(便利贴),正等着有人来真正读取它。 方法返回:控制器返回 Professor 对象。Spring MVC 发现你要输出 JSON(因为 @RestController),于是开始对这个对象进行序列化,为的是生成字符串发给前端。 序列化过程触发了读取:Spring 用 Jackson 把 Professor 转成字符串时,会通过 getter 方法读它的每一个属性。当读到 getStudents() 时,触发了代理对象。Hibernate 发现这个代理需要初始化,于是去数据库执行 SQL 把学生列表查出来。 session 还活着,查询成功:此时 OSIV 绑定的那个 session 还没有关闭,所以 Hibernate 能够顺利执行 SQL,返回完整的学生列表。于是 Jackson 拿到了完整的集合,最终生成的 JSON 里就包含了教授和他的学生。 响应写完后:HTTP 响应完全返回给前端,Spring MVC 工作结束,OSIV 拦截器关闭 session。 session那么好用为什么要关掉,一直开着不好吗? 数据库连接数非常有限。比如你的数据库配置了最大 50 个并发连接。 session 是一个“一级缓存”,它会一直跟踪你加载过的所有对象,并给它们拍快照(用于脏检查)。 session 有“重复读”的保证:同一个 session 里查同一个 ID 两次,第二次直接给你缓存里的旧对象,根本看不到数据库的最新变化。 所以,session 必须设计成“即用即关”的短生命周期。它的职责就是服务好“一次业务操作”或“一次 HTTP 请求”。做完事赶紧关,释放连接、释放内存、下次查询拿到新数据。 用一个JPA中的话说Hibernate中的session就是Entitymanager。 Hibernate ORM 用户指南:https://docs.hibernate.org/orm/5.4/userguide/html_single/#pc-...背景
报错截图
![]()
问题代码复现
@Override
@Transactional
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
if (username.length() == 28) {
return this.loadByWechatOpenid(username);
} else {
// 学生登录
Optional<User> userOfStudent = this.loadBySno(username);
if (userOfStudent.isPresent()) {
return userOfStudent.get();
}
// 正常登录方式
User user = this.userRepository.findByPhone(username).orElseThrow(() -> new UsernameNotFoundException("e"));
user.getAuthorities();
return user;
}
}
/**
* 学号登录
* */
private Optional<User> loadBySno(String sno) {
Optional<Student> studentOptional = this.studentRepository.findBySnoAndDeletedFalse(sno);
if (studentOptional.isPresent()) {
Student student = studentOptional.get();
if (student.getUser() == null) {
User user = this.saveByStudent(student.getName(), student.getSno());
student.setUser(user);
this.studentRepository.save(student);
return Optional.of(user);
}
return Optional.of(student.getUser());
}
return Optional.empty();
}@Entity
@Data
public class User {
...
// 默认是懒加载
@ApiModelProperty("角色")
@ManyToMany
@JsonView(RolesJsonView.class)
private Set<Role> roles = new HashSet<>();
...
@JsonView(AuthoritiesJsonView.class)
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
if (null == this.authorities) {
Set<String> authorities = new HashSet<>();
// 这行报错
if (null != this.getRoles() && !this.getRoles().isEmpty()) {
authorities = RoleServiceImpl.getGrantedAuthorities(this.getRoles());
}
this.authorities = authorities.stream().map(authority -> (GrantedAuthority) () -> authority)
.collect(Collectors.toSet());
}
return this.authorities;
}
}
解决方案
private Optional<User> loadBySno(String sno) {
Optional<Student> studentOptional = this.studentRepository.findBySnoAndDeletedFalse(sno);
if (studentOptional.isPresent()) {
Student student = studentOptional.get();
if (student.getUser() == null) {
User user = this.saveByStudent(student.getName(), student.getSno());
student.setUser(user);
this.studentRepository.save(student);
// 在返回user的时候调用一下,getAuthorities()方法即可
if (user != null) {
user.getAuthorities();
}
return Optional.of(user);
}
if (student.getUser() != null) {
student.getUser().getAuthorities();
}
return Optional.of(student.getUser());
}
return Optional.empty();
}探究原因
用一个简单的例子来说:现在有clazz,student和teacher3个实体,他们3个各自有20个属性。在我们日常开发中,对于一个实体并不会把它所有的属性都使用上,相反,而是使用几个属性。那这对服务器来说不久加载了一堆没用的信息吗,我内存就那么大。Spring Boot说:有了我用代理模式不就好了吗。我把@Transactional删除后,它就报错了,实际上这个schedules的类型是List<Schedule>他这里变成PersistentBag类型。它里面没有数据,就报错了。
另一个问题

一头雾水的时候,先去看控制台->网络。发现了一个有趣的问题,数据太长了,数据可能被截断了,浏览器觉得不是json数据。实际上是实体对象互相嵌套导致的,schedule中有course,course中有courseItem,courseItem中有schedule...然后就导致了这个问题。解决方案
@Setter
@Getter
@Entity
public class CourseItem extends BaseEntity{
...
@ManyToOne(fetch = FetchType.LAZY)
@JsonView(ScheduleJsonView.class) // 加上这行
@ApiModelProperty("课程计划")
private Schedule schedule;
public interface ScheduleJsonView {}
...
}
@RestController
@RequestMapping("schedule")
public class ScheduleController {
...
@GetMapping("getAllByCurrentTermAndCurrentUser")
@JsonView(GetAllByCurrentTermAndCurrentUserJsonView.class)
public List<Schedule> getAllByCurrentTermAndCurrentUser() {
Term term = this.termService.getCurrentTerm();
if (term == null) {
return List.of();
}
return this.scheduleService.getAllByCurrentTermAndCurrentUser(term);
}
private interface GetAllByCurrentTermAndCurrentUserJsonView extends
Schedule.CourseJsonView,
Schedule.ClazzJsonView,
Schedule.Teacher2JsonView,
Schedule.Teacher1JsonView,
Course.CourseItemJsonView,
GetSchedulesInCurrentTermJsonView {
}
...
}有趣的思考
遗漏报错信息
懒加载问题继续探讨
Hibernate 为了省事,在从数据库取出 User 档案时,故意没有立刻把标签(roles)也取出来,而是贴了一张写着“需要时再去拿”的便利贴。这张便利贴就是一个代理对象。
在 Hibernate 里,真正能从数据库里帮你把数据拿出来的那个“办事员”,就是 session。他只在“数据库操作期间”上班。
在业务代码(认证逻辑)里:
先从数据库通过 session 拿到了 User 档案,此时标签还没取,只有便利贴。
数据库操作很快结束了,Spring 自动把 session 关闭了,办事员下班走了。
接着,Spring Security 要检查这个用户的权限,就调用了 user.getAuthorities(),实际上就是想看看便利贴上对应的标签到底写的是什么。
(延迟加载初始化失败 —— 因为没找到会话)请求实体过长导致的问题
Spring Boot 默认配置 spring.jpa.open-in-view=true ,它的作用就是:把 Hibernate 的 session 从你查询数据库一直活到 HTTP 响应写完为止。对于session的思考
每个 Session 背后都占着一个“物理数据库连接”
如果一个请求处理了 1 秒钟,Session 开了 1 秒,那么 50 个请求同时进来刚好用满。
如果你一直不关 Session,它就一直占着这个连接。请求处理完了,用户慢悠悠看前端页面(持续几分钟),连接就一直被扣着。用不了多久,连接池就会被耗尽,新的请求再也拿不到数据库连接,整个系统瘫痪。
数据库连接是非常宝贵的资源,必须“快借快还”。内存会爆掉
一个请求你查了 10 个教授,它记着 10 个对象。
如果不关闭,随着时间累积,这个 session 缓存里的对象会越来越多,历史查过的东西全堆在里面,而且因为被 Session 引用着,GC 也不能回收。
最终就是内存泄漏(OOM)。数据一致性问题(很严重)
如果 session 一直开着,用户张三在 10:00 查了一个教授的薪水是 1 万。
10:05 管理员在其他系统里把薪资改成了 2 万并提交了。
10:10 张三再次在这个一直开着的 Session 里查这个教授,看到的还是 1 万,因为 session 还拿着旧缓存。
一个长期存在的 session,相当于一直活在“事务快照”里,完全无法跟数据库同步。总结
参考
JPA配置:https://docs.spring.io/spring-boot/appendix/application-prope...
刚开始做 Go 微服务那会儿,我以为面试就两类题:写算法、背八股。 下面这篇面经不讲经历,只给你面试题 + 示例回答(并附带常见追问)。 如果你能把这些回答“讲顺”,大概率能过掉后端/微服务方向的核心拷问。 面试官: 很多人的“标准答案”是: 但面试官真正想听的是:你是否理解它的边界和传播链路。 示例回答(面试版): 常见追问(别踩坑): 面试官:你们为什么用 Elasticsearch?它为什么快? 如果你只说“全文检索、分词”,基本等于没答。 示例回答(面试版): ES 快主要来自 Lucene 的索引结构与查询执行方式: 常见追问(面试官爱追): 面试官:你们服务/模块之间怎么通信? 示例回答(面试版): 常见追问: 面试官:你们为什么是 RabbitMQ,不是 Kafka? 示例回答(面试版)(按你项目取舍讲): 我们更看重低延迟、灵活路由、可靠投递、易运维: 常见追问: 这题建议你直接给“对比维度”,面试官听得最舒服。 示例回答(面试版): 补一句更像“项目经验”的话: 面试官:B+ 树你怎么理解?“本质”是什么? 示例回答(面试版): 它把数据(或主键)集中在叶子节点,内部节点只存索引键;叶子节点通过链表相连,因此: 常见追问: 面试官:Go 的 示例回答(面试版): 关闭语义: 常见追问(高频坑): 面试官:讲讲 GMP,如果 goroutine 阻塞了会怎样? 示例回答(面试版): 阻塞分两类(这是加分点): 常见追问: 面试官:有了 G 和 M,为什么还要 P? 示例回答(面试版): 面试官:协程泄漏你遇到过吗?一般怎么发生? 示例回答(面试版): 面试官喜欢听到的“工程化收尾”: 面试官:Docker 和 K8s 你怎么理解?区别是什么? 示例回答(面试版): 常用对象我能讲清楚: 一句话总结(很好用): 当这些题连着问的时候,面试官通常不是要你背概念,而是看你有没有三种能力: 写在最后: 最近私信问我面试题的小伙伴实在太多了,一个个回有点回不过来。 我大家公认最容易挂的 AI/Go/Java 面试坑点 整理成了一份 PDF 文档。里面不光有题,还有解题思路和避坑指南。 想要的同学,直接加我微信wangzhongyang1993,或者关注并私信我 【面试】,我统一发给大家。一场面试 11 连问,背八股很容易当场露馅
后来才发现,很多面试官真正喜欢的,是这种“连环追问”:你会用就行?那你说说为什么这么用;你说它快?那你说说快在哪;你说系统稳定?那你说说极端情况下会发生什么。
🪤 1)
context 怎么用的?context 你项目里怎么用?context 就是用来传参的,或者加个超时。context 主要解决 3 件事:取消(cancel)、超时/截止时间(deadline)、跨边界的请求级元数据(value)。ctx 作为函数的第一个参数,沿调用链往下传到所有可能阻塞的地方:DB/Redis/HTTP/gRPC/MQ publish 等。WithTimeout/WithCancel。WithValue 只放请求范围、必须跨 API 边界的元数据(比如 traceId、userId),不把业务参数塞进去,更不会把 ctx 存到 struct 里长期持有。func (s *Service) CreateOrder(ctx context.Context, req *CreateOrderReq) error {
ctx, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
// 1) 传给 DB / RPC / Redis
if err := s.repo.InsertOrder(ctx, req); err != nil {
return err
}
// 2) 自己的 goroutine 也要“跟着 ctx 退出”
go func() {
select {
case <-ctx.Done():
return
case <-time.After(200 * time.Millisecond):
_ = s.metrics.Report(req.OrderID) // 示例:真正实现里也应传 ctx
}
}()
return nil
}context 里为什么不建议传业务参数?”——因为可读性差、无类型约束、容易滥用;更重要的是会让 ctx 的语义从“控制与元信息”变成“万能背包”。⚡ 2)为什么选 ES?ES 为什么快?
LIKE '%xx%' 或冗余字段很难做,且代价很高。🔌 3)模块之间的通信怎么做的?
同步(gRPC)适合:
+ 强依赖、必须拿到结果(比如查库存、查配置)
异步(MQ)适合:
+ 最终一致、允许延迟(比如通知、异步落库、索引更新)🐇 4)为什么选 RabbitMQ?
🆚 5)RabbitMQ 和 Kafka 的主要区别?
维度 RabbitMQ Kafka 模型 队列/交换机路由 分区日志(log) 消费 以投递/确认为核心 以 offset/重放为核心 历史消息 通常消费即删除(按队列语义) 按保留策略长期保存,可重放 吞吐 中高(偏低延迟业务) 很高(大吞吐流式) 顺序性 单队列可保证 分区内有序 典型场景 业务事件、任务队列、复杂路由 埋点日志、流式计算、CDC、事件总线 我们用 RabbitMQ 做“业务事件通知”,用 Kafka(如果有)做“日志/埋点/CDC 流”,这样职责更清晰。
🌳 6)B+ 树的本质是什么?
📮 7)
channel 了解多少?channel 你了解多少?有缓冲/无缓冲差别?chan 是 Go 的并发通信原语,本质是“同步/队列化的通信通道”,用来在 goroutine 之间安全传递数据。ok=false),但再发送会 panic;select {
case v := <-ch:
_ = v
case <-ctx.Done():
return ctx.Err()
}nil channel:收发都会永久阻塞,常用于在 select 里动态开关分支。context、超时、或明确关闭通道;不要让 for { <-ch } 在没有退出条件的情况下跑。⚙️ 8)GMP 模型:如果阻塞了会怎么样?
🧩 9)为什么要有 P?
GOMAXPROCS 控制并行度:最多同时有多少个 P 在跑,也就最多同时跑多少个 goroutine(严格说是同时执行的 G 的数量上限)。🕳️ 10)什么情况下会协程泄漏?
for range ch 等不到 close。context.Background() 或者忘了 cancel()。time.NewTicker 没有 Stop(),goroutine 一直被唤醒做无意义工作。errgroup 统一回收。g, ctx := errgroup.WithContext(ctx)
g.Go(func() error { return s.callA(ctx) })
g.Go(func() error { return s.callB(ctx) })
return g.Wait()我会给所有后台 goroutine 一个明确的退出条件(ctx / close channel / done),并且在压测和线上用 pprof 看 goroutine 数是否稳定。
🐳 11)讲一下 Docker 和 K8s
Deployment:无状态应用的发布与滚动升级Service:稳定访问入口(负载均衡/服务发现)Ingress:HTTP 路由入口(配合 Ingress Controller)ConfigMap/Secret:配置与密钥HPA:按指标自动扩缩容StatefulSet:有状态服务(按需)Docker 更像“把程序装进标准集装箱”,K8s 更像“港口调度系统”,负责把集装箱放到合适的船上、坏了自动换、忙了自动加船。
✅ 总结:面试官其实在考什么?
你不需要把每个点都讲到论文级别,但你需要在关键处“说出底层原因”,并且能落到工程实践的兜底方案上。
END
最近在重度使用 codex app ,被官方价格 + 限制搞得有点烦…
干脆自己弄了个中转站,原本只是自己用的,刚好自己有一些上游渠道可以搞到一些相对低价的 pro 账号来轮询。
现在顺手放出来,有需要的可以试试。
支持的东西不多,目前就主打 codex ,支持最新的 GPT-5.5 模型
没啥特别花的功能,就是能用 + 稳一点。
简单说几个点:
地址:
https://chris.gettoken.dev
新用户注册送 50 美刀,够随便测一阵了

网站的套餐价格也不贵(至少暂时不贵,后续看成本可能会涨价)

做外汇量化、行情采集的开发者大概率都碰到过:实时 Tick 数据频繁丢点、跳点、断档,换了几个 API 都解决不了。 在量化策略、回测系统、实时行情服务中,数据连续性直接决定系统可靠性。 经过长期实测可以确定:丢点并非单纯 API 故障,而是市场流动性、波动率、交易时段与采集方式共同作用的结果。 在全时段、多节点并行抓取下,主流直盘货币对丢点频率如下: 在外汇实时 Tick 采集场景中,Websocket 长连接是目前最稳定的方案。 GBP/USD 是主流货币对中丢点最明显的品种,主要由开盘高波动与流动性不均导致。
这篇文章从实战角度,梳理易掉数据的货币对、背后原因,并给出可直接运行的稳定抓取方案。一、开发场景与常见问题
常见问题:二、实测:哪些主流货币对最容易丢数据
三、影响数据抓取稳定性的 4 个关键因素
高波动时段更新快,抓取频率不匹配就会丢 Tick。
按秒推送 vs 逐笔 Tick 推送,数据完整性差异巨大。
HTTP 轮询被动拉取,易丢点;Websocket 主动推送,稳定性更强。
流动性越低,成交越不连续,抓取空缺概率越高。四、实战方案:Websocket 稳定抓取(代码可直接运行)
以 AllTick API 为例,订阅式推送可显著降低丢点率,代码100% 保持原样:import websocket
import json
def on_message(ws, message):
data = json.loads(message)
print(data)
ws = websocket.WebSocketApp(
"wss://apis.alltick.co/websocket-api/stock-websocket-interface-api/transaction-quote-subscription",
on_message=on_message
)
ws.run_forever()实战优化建议
三种抓取方式对比
总结
通过优化抓取策略、使用 Websocket、建立补全机制,可以稳定获取高完整性的外汇实时数据,满足量化开发与系统部署需求。

