深圳电信移机费能减免吗?
深圳电信六星、七星用户一年免费移机一次,其他用户 100 元 1 次,有办法减免吗?
99 元套餐:20G+300 分钟+100M 宽带
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
深圳电信六星、七星用户一年免费移机一次,其他用户 100 元 1 次,有办法减免吗?
99 元套餐:20G+300 分钟+100M 宽带
在架构设计上, 基于 演示地址:https://v5.catchadmin.com 超管账户 测试账户Laravel12 + Vue3 的免费可商用商业级管理后台 CatchAdmin V5.1.1 发布
介绍
CatchAdmin 是一款基于 Laravel 12.x 与 Vue3 二次开发的 PHP 开源后台管理系统,采用前后端分离架构,面向企业级后台场景提供开箱即用的基础能力与可扩展的模块化框架。系统内置 Token 鉴权、权限管理(菜单/按钮/数据权限)、动态路由、动态表格、分页封装、资源权限控制、上传/下载、代码生成器(支持一键导入/导出)、数据回收站、附件管理等功能,覆盖后台系统从安全、权限到效率开发的常见需求。Laravel 仅作为 API 服务层对外输出,尽可能弱化业务模块之间的耦合关系。每个模块均具备独立的控制器、路由、模型与数据表结构,支持按模块拆分、按需加载与独立演进,从而降低开发复杂度,提高可维护性与迭代效率。同时,项目封装了大量通用能力与开发工具(如统一响应、异常处理、分页与资源封装等),让业务开发更聚焦、更高效。CatchAdmin,你可以快速搭建 CMS、CRM、OA 等各类管理系统,并在稳定的基础设施之上持续扩展业务模块,满足不同规模团队的开发与交付需求。V5.1.1 版本亮点
等等更多...快速开始
# 创建项目
composer create catchadmin/catchadmin
# 安装项目
cd catchadmin && php artisan catch:install
# 启动项目
composer run dev功能清单
在线体验
catch@admin.comcatchadmintest@admin.comTestadmin1项目地址
项目预览








上一篇文章中,我为大家详细介绍了如何在 Windows 上部署 OpenClaw 并接入飞书:【保姆级教程】手把手教你安装 OpenClaw 并接入飞书,让 AI 在聊天软件里帮你干活。 不少朋友询问是否有 Mac 版的部署教程。今天,教程就来啦!其实在 Mac 上部署 OpenClaw 与 Windows 步骤基本一致。 本次教程除了从零完成 OpenClaw 的部署外,最大的不同在于交互平台换成了 Discord。接下来,就跟着我一步步完成部署吧! OpenClaw(原名 ClawdBot)是一个开源的个人 AI 助手平台,运行在你自己的设备上。它支持通过 WhatsApp、Telegram、Slack、Discord、飞书、钉钉、QQ、企业微信等多个平台与你互动。 其特点包括: 打开 终端(Terminal),按 执行以下命令检查 Node.js 版本: 预期输出:显示版本号,只要高于 v22.x.x 即可。 如果未安装 Node.js 或版本过低,请继续下一步。 OpenClaw 需要连接 AI 模型才能工作。国内推荐使用 MiniMax M2.1。 1、注册或登录账号 访问官网:https://platform.minimaxi.com/subscribe/coding-plan?code=FSXN... 2、选择适合的订阅套餐 3、获取API Key 进入 Coding plan 页面,找到 API Key,点击重置并复制。妥善保存复制的 API Key 这是最简单、最标准的安装方式。 运行自动脚本安装完成后,会自动进入配置向导,引导你完成以下设置: 选择 AI 提供商:这里我们选择 MiniMax。 选择模型: 输入 API Key: 选择默认模型: 这里我们先选择跳过。本教程后续将使用 Discord 与 OpenClaw 通信。由于 Discord 配置稍显繁琐,后面会单独用一节详细讲解如何接入 Discord 机器人。你需要提前下载并注册好 Discord。如果觉得困难,也可选择飞书,详细配置可参考我上一篇文章:https://mp.weixin.qq.com/s/JGd4u8g-Fti4sRcJcSiOLQ。 Skills 也先跳过,后续可通过 Web UI 界面配置: Hooks 我们暂不需要配置。使用上下箭头选择 Skip for now,按下 空格键 选中,然后回车。 此时开始自动安装 Gateway 服务: 稍等片刻,Gateway 服务安装完成,开始选择启动机器人的方式: 完成后,OpenClaw 会自动通过默认浏览器打开 Web UI 页面: OpenClaw 支持多种通讯平台,本教程我们选择 Discord。 官方地址:https://discord.com 访问地址:https://discord.com/developers/applications 点击 Bot 菜单,然后点击 重置 Token。 在浏览器中打开刚才复制的链接,选择一个服务器(相当于将创建的机器人加入该服务器),选择前面创建的自定义服务器。 点击“授权”: 授权成功: 现在,你可以在自己创建的服务器中 @ 刚才添加的机器人了: 执行以下命令: 进入设置,选择“本地”: 选择“渠道”: 选择“配置连接”: 选择 Discord: 填入前面获取的 Bot Token: 允许所有频道: 选择“完成”: 访问策略保持默认: 配对模式也保持默认: 执行以下命令启动网关服务: 如果之前已启动过,请先执行 回到 Discord 创建的频道,点击右上角的“显示成员”,可以看到当前频道成员。点击我们添加的 Bot:OpenClaw。 你会看到一个私聊输入框,可以试着发送一句话: 此时会跳转到私信聊天界面,并显示一个配对码。复制这个配对码。 打开一个新的终端窗口,输入以下命令: 将 回到启动网关的命令行窗口,按下 请注意,这个命令行窗口不能关闭,否则服务会停止。如果希望后台静默运行(即使关闭窗口也不受影响),可以执行: 现在回到 Discord 的服务器频道,在频道中 @ 你创建的机器人: 查看桌面文档的实际内容(示例): Discord 拥有多平台客户端,你也可以在手机上安装 Discord,通过手机指挥 OpenClaw 工作。 至此,OpenClaw 已成功与 Discord 打通。现在你可以在 Discord 中通过与 Bot 对话的方式,指挥 OpenClaw 操控你的电脑了! 要想让 OpenClaw 出色地帮我们完成各种任务,还需要为它安装各种 Skills。点击头像关注我,接下来我会逐步分享 OpenClaw 的更多进阶玩法。 也欢迎通过主页找到我,加入 OpenClaw 实战交流群,与更多创作者一起碰撞灵感、探索新奇玩法!一、什么是 OpenClaw
二、基本要求
三、安装前准备
第一步:检查 Node.js 版本
Cmd + Space 输入 “Terminal” 并回车。
node --version
第二步:安装 Node.js(如需)
方法一:使用官方安装包(推荐新手)
.pkg 文件,按提示完成安装node --version 验证
方法二:使用 Homebrew(推荐开发者)
# 安装 Homebrew(如未安装)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 使用 Homebrew 安装 Node.js
brew install node
# 验证安装
node --version
npm --version第三步:准备 AI 模型 API Key
获取 MiniMax API Key:


直达地址:https://platform.minimaxi.com/user-center/payment/coding-plan
四、安装 OpenClaw
一)自动脚本安装(推荐)
# 使用官方脚本安装 OpenClaw
curl -fsSL https://openclaw.ai/install.sh | bash
二)初始化配置
1. 风险告知

2. 引导面板模式:选择“快速开始”

3. 设置 AI 模型




4. 配置与 OpenClaw 通信的渠道

5. 配置 Skills

6. 配置 Hooks




五、配置 Discord 即时通信平台
一)注册账号并登录
注意:你需要自行解决科学上网问题。
二)创建一个服务器
1. 点击“添加服务器”

2. 选择“亲自创建”

3. 选择“仅供我和我的朋友使用”

4. 自定义服务器名称

三)进入开发者后台

四)创建应用
1. 点击“创建应用”

2. 输入应用名称

3. 自动跳转到“通用信息”页面

4. 获取 Token

5. 重置完成后,复制你的 Token

6. 在当前页面继续向下滚动,找到
Message Content Intent 并启用
7. 进入 OAuth2 配置页面,勾选 Bot

8. 继续向下滚动,找到 Bot Permissions,勾选 Send Messages 和 Read Message History

9. 滚动到底部,复制生成的 Bot 链接

10. 将 Bot 加入服务器




五)将 Discord 接入 OpenClaw
1. 进入 OpenClaw 配置
openclaw config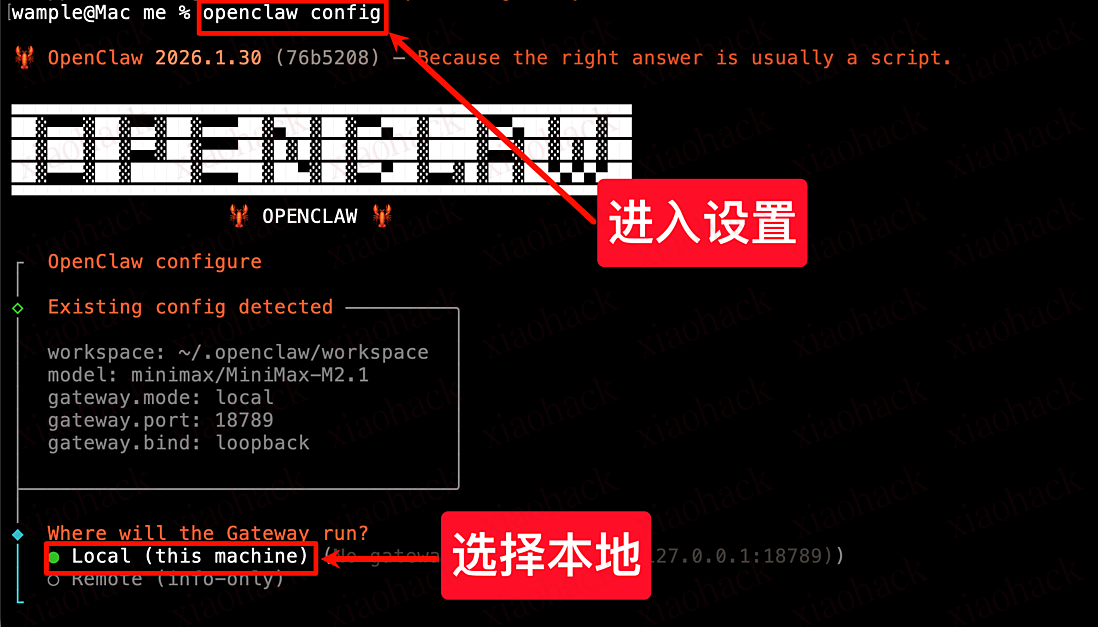








2. 启动网关服务
openclaw gatewayopenclaw gateway stop 停止,再执行以上命令。
3. 将 Discord 与 OpenClaw 配对



openclaw pairing approve discord <Pairing code><Pairing code> 替换为刚才复制的配对码。
4. 重启网关服务
Ctrl + C 停止服务,然后重新启动:openclaw gateway
nohup openclaw gateway --port 18789 --verbose > /dev/null 2>&1 &5. 测试


六、常用命令
Gateway 管理
# 启动 Gateway
openclaw gateway
# 启动并显示详细日志
openclaw gateway --verbose
# 指定端口启动
openclaw gateway --port 18789配置管理
# 运行配置向导
openclaw onboard
# 系统健康检查
openclaw doctor
# 查看配置
cat ~/.openclaw/openclaw.json更新管理
# 更新到最新版本
openclaw update
# 切换到特定频道
openclaw update --channel stable # 稳定版
openclaw update --channel beta # 测试版
openclaw update --channel dev # 开发版结语
🌟 2026-02-03 GitHub Python 热点项目精选(17个)
每日同步 GitHub Trending 趋势,筛选优质 Python 项目,助力开发者快速把握技术风向标~
📋 项目列表(按 Star 数排序)
1. OpenBMB/ChatDev
ChatDev是一个零代码多智能体协作平台,用于开发各种应用。它支持从简单的配置中快速构建和执行定制的多智能体系统,无需编写代码。ChatDev还提供了从文本到代码的转换功能,支持多种编程语言,如Python、Java和C++。
指标 详情 Star 数 🌟 29392(今日+93) Fork 数 🔄 3665 开发语言 🐍 Python 项目地址 https://github.com/OpenBMB/ChatDev 2. VectifyAI/PageIndex
PageIndex是一个向量无关的推理基础架构,用于基于推理的检索增强型语义搜索。它构建了一个层次化的树索引,使用大型语言模型进行基于推理的检索。
指标 详情 Star 数 🌟 12493(今日+793) Fork 数 🔄 891 开发语言 🐍 Python 项目地址 https://github.com/VectifyAI/PageIndex 3. karpathy/nanochat
nanochat是一个用于训练大型语言模型的实验性框架,专为在单个GPU节点上运行而设计。它覆盖了大型语言模型的所有主要阶段,包括标记化、预训练、微调、评估、推理和聊天界面。
指标 详情 Star 数 🌟 41636(今日+254) Fork 数 🔄 5389 开发语言 🐍 Python 项目地址 https://github.com/karpathy/nanochat 4. kovidgoyal/calibre
calibre是一个电子书管理器,支持多种主要的电子书格式。它可以查看、转换、编辑和整理电子书,还可以与电子书阅读设备通信,并从互联网获取元数据。
指标 详情 Star 数 🌟 23794(今日+183) Fork 数 🔄 2542 开发语言 🐍 Python 项目地址 https://github.com/kovidgoyal/calibre 5. microsoft/agent-lightning
Agent Lightning是一个用于训练大型语言模型的工具,支持多种算法,如强化学习、自动提示优化和监督微调。它允许用户在几乎不修改代码的情况下优化智能体。
指标 详情 Star 数 🌟 13295(今日+369) Fork 数 🔄 1098 开发语言 🐍 Python 项目地址 https://github.com/microsoft/agent-lightning 6. EbookFoundation/free-programming-books
这是一个免费编程书籍的列表,按语言和主题分类。它提供了一个易于阅读的网站界面,用户可以通过搜索功能找到所需的书籍。
指标 详情 Star 数 🌟 381931(今日+335) Fork 数 🔄 65880 开发语言 🐍 Python 项目地址 https://github.com/EbookFoundation/free-programming-books 7. microsoft/BitNet
BitNet是1位大型语言模型的官方推理框架,提供了一套优化的内核,支持快速且无损的1.58位模型推理。它支持CPU和GPU(NPU支持即将推出)。
指标 详情 Star 数 🌟 27645(今日+99) Fork 数 🔄 2243 开发语言 🐍 Python 项目地址 https://github.com/microsoft/BitNet 8. davila7/claude-code-templates
这是一个用于配置和监控Claude Code的命令行工具,提供了一系列预定义的配置文件和命令,以简化开发流程。
指标 详情 Star 数 🌟 19284(今日+113) Fork 数 🔄 1795 开发语言 🐍 Python 项目地址 https://github.com/davila7/claude-code-templates 9. lllyasviel/Fooocus
Fooocus是一个基于Gradio的图像生成软件,支持离线使用、开源和免费。它简化了图像生成过程,用户只需关注提示词和图像。
指标 详情 Star 数 🌟 47652(今日+10) Fork 数 🔄 7774 开发语言 🐍 Python 项目地址 https://github.com/lllyasviel/Fooocus 10. GreyDGL/PentestGPT
PentestGPT是一个自动化渗透测试的智能体框架,由大型语言模型驱动。它支持多种攻击类别,如Web、密码学、逆向工程等,并提供实时反馈。
指标 详情 Star 数 🌟 11354(今日+19) Fork 数 🔄 1869 开发语言 🐍 Python 项目地址 https://github.com/GreyDGL/PentestGPT 11. langchain-ai/open_deep_research
这是一个完全开源的深度研究智能体,支持多种模型提供商、搜索工具和MCP服务器。它的性能与许多流行的深度研究智能体相当。
指标 详情 Star 数 🌟 10443(今日+39) Fork 数 🔄 1531 开发语言 🐍 Python 项目地址 https://github.com/langchain-ai/open_deep_research 12. jingyaogong/minimind
MiniMind是一个开源项目,旨在从零开始训练一个仅25.8M参数的小型语言模型。它支持从头开始训练,并且训练成本极低。
指标 详情 Star 数 🌟 38560(今日+136) Fork 数 🔄 4629 开发语言 🐍 Python 项目地址 https://github.com/jingyaogong/minimind 13. yt-dlp/yt-dlp
yt-dlp是一个功能丰富的命令行音频/视频下载器,支持数千个网站。它是youtube-dl的一个分支,基于已停用的youtube-dlc。
指标 详情 Star 数 🌟 145488(今日+183) Fork 数 🔄 11776 开发语言 🐍 Python 项目地址 https://github.com/yt-dlp/yt-dlp 14. home-assistant/core
Home Assistant是一个开源的家庭自动化平台,强调本地控制和隐私保护。它由全球的爱好者社区支持,适合在树莓派或本地服务器上运行。
指标 详情 Star 数 🌟 84549(今日+29) Fork 数 🔄 36673 开发语言 🐍 Python 项目地址 https://github.com/home-assistant/core 15. happycola233/tchMaterial-parser
这是一个用于从国家中小学智慧教育平台下载电子课本的工具,支持批量下载、自动命名文件、添加书签等功能。
指标 详情 Star 数 🌟 4444(今日+34) Fork 数 🔄 535 开发语言 🐍 Python 项目地址 https://github.com/happycola233/tchMaterial-parser 16. Zie619/n8n-workflows
这是一个n8n工作流集合,包含4343个生产就绪的工作流和365个独特集成。它提供了一个快速访问界面,支持智能搜索和多平台部署。
指标 详情 Star 数 🌟 50800(今日+68) Fork 数 🔄 6261 开发语言 🐍 Python 项目地址 https://github.com/Zie619/n8n-workflows 17. serengil/deepface
DeepFace是一个轻量级的面部识别和面部属性分析框架,支持多种模型,如VGG-Face、FaceNet和ArcFace。它提供面部验证、属性分析和实时分析等功能。
指标 详情 Star 数 🌟 22110(今日+36) Fork 数 🔄 3018 开发语言 🐍 Python 项目地址 https://github.com/serengil/deepface 📝 说明
⭐ 推荐理由
<!-- truncate --> 在软件开发中,环境差异化一直是困扰开发团队的难题之一。以我们正在构建的 HagiCode 平台为例,这是一个基于 ASP.NET Core 10 和 React 的 AI 辅助开发系统,内部集成了 Orleans 进行分布式状态管理,技术栈相当现代且复杂。 在项目初期,我们遇到了一个典型的工程痛点:开发人员希望本地环境能够“开箱即用”,不希望安装和配置繁重的 PostgreSQL 数据库;但在生产环境中,我们需要处理高并发写入和复杂的 JSON 查询,这时轻量级的 SQLite 又显得力不从心。 如何在保持代码库统一的前提下,让应用既能像客户端软件一样利用 SQLite 的便携性,又能像企业级服务一样发挥 PostgreSQL 的强悍性能?这就是本文要探讨的核心问题。 本文分享的双数据库适配方案,直接来源于我们在 HagiCode 项目中的实战经验。HagiCode 是一个集成了 AI 提示词管理和 OpenSpec 工作流的下一代开发平台。正是为了兼顾开发者的体验和生产环境的稳定性,我们探索出了这套行之有效的架构模式。 欢迎访问我们的 GitHub 仓库了解项目全貌:HagiCode-org/site。 要在 .NET Core 中实现双数据库支持,核心思想是“依赖抽象而非具体实现”。我们需要把数据库的选择权从业务代码中剥离出来,交给配置层决定。 在 ASP.NET Core 的 首先,定义配置类: 然后,在 PostgreSQL 和 SQLite 虽然都支持 SQL 标准,但在具体特性和行为上存在显著差异。如果不处理好这些差异,很可能会出现“本地跑得通,上线就报错”的尴尬情况。 在 HagiCode 中,我们需要存储大量的提示词和 AI 元数据,这通常涉及 JSON 列。 解决方案: 当使用 SQLite 时,虽然 绝对不要试图让同一套 Migration 脚本同时适配 PG 和 SQLite。由于主键生成策略、索引语法等的不同,这必然会导致失败。 推荐实践: 在将 HagiCode 从单一数据库重构为双数据库支持的过程中,我们踩过一些坑,也总结了一些关键的经验,希望能给大家避坑。 PostgreSQL 是服务端-客户端架构,支持高并发写入,事务隔离级别非常强大。而 SQLite 是文件锁机制,写入操作会锁定整个数据库文件(除非开启 WAL 模式)。 建议: PostgreSQL 的连接建立成本较高,依赖连接池。而 SQLite 连接非常轻量,但如果不及时释放,文件锁可能会导致后续操作超时。 在 很多开发者(包括我们团队早期的成员)容易犯一个错误:只在开发环境(通常是 SQLite)跑单元测试。 我们在 HagiCode 的 CI/CD 流水线中强制加入了 GitHub Action 步骤,确保每次 Pull Request 都要跑过 PostgreSQL 的集成测试。 这帮我们拦截了无数次关于 SQL 语法差异、大小写敏感性的 Bug。 通过引入抽象层和配置驱动的依赖注入,我们在 HagiCode 项目中成功实现了 PostgreSQL 和 SQLite 的“双轨制”运行。这不仅极大降低了新开发者的上手门槛(不需要装 PG),也为生产环境提供了坚实的性能保障。 回顾一下关键点: 这种架构模式不仅适用于 HagiCode,也适用于任何需要在轻量级开发和重量级生产之间寻找平衡的 .NET 项目。 如果本文对你有帮助,欢迎来 GitHub 给个 Star,或者直接体验 HagiCode 带来的高效开发流程: 公测已开始,欢迎安装体验! 感谢您的阅读,如果您觉得本文有用,快点击下方点赞按钮👍,让更多的人看到本文。 本内容采用人工智能辅助协作,经本人审核,符合本人观点与立场。.NET Core 双数据库实战:让 PostgreSQL 与 SQLite 和平共处
在构建现代化应用时,我们经常面临这样的抉择:开发环境渴望轻量便捷,而生产环境则需要高并发与高可用。本文将分享如何在 .NET Core 项目中优雅地同时支持 PostgreSQL 和 SQLite,实现“开发用 SQLite,生产用 PG”的最佳实践。
背景
关于 HagiCode
核心内容一:架构设计与统一抽象
设计思路
DbContext 基类或自定义的接口,而不是具体的 PostgreSqlDbContext。appsettings.json 中的配置项,在应用启动时动态决定加载哪个数据库提供程序。代码实现:动态上下文配置
Program.cs 中,我们不应硬编码 UseNpgsql 或 UseSqlite。相反,我们应该读取配置来动态决定。public class DatabaseSettings
{
public const string SectionName = "Database";
// 数据库类型:PostgreSQL 或 SQLite
public string DbType { get; set; } = "PostgreSQL";
// 连接字符串
public string ConnectionString { get; set; } = string.Empty;
}Program.cs 中根据配置注册服务:// 读取配置
var databaseSettings = builder.Configuration.GetSection(DatabaseSettings.SectionName).Get<DatabaseSettings>();
// 注册 DbContext
builder.Services.AddDbContext<ApplicationDbContext>(options =>
{
if (databaseSettings?.DbType?.ToLower() == "sqlite")
{
// SQLite 配置
options.UseSqlite(databaseSettings.ConnectionString);
// SQLite 的并发写入限制处理
// 注意:在生产环境中建议开启 WAL 模式以提高并发性能
}
else
{
// PostgreSQL 配置(默认)
options.UseNpgsql(databaseSettings.ConnectionString, npgsqlOptions =>
{
// 开启 JSONB 支持,这在处理 AI 对话记录时非常有用
npgsqlOptions.UseJsonNet();
});
// 配置连接池重连策略
options.EnableRetryOnFailure(3);
}
});核心内容二:处理差异性与迁移策略
1. JSON 类型的处理
JSONB 类型,查询性能极佳。
在 EF Core 的实体映射中,我们将其配置为可转换的类型。protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
// 配置实体
modelBuilder.Entity<PromptTemplate>(entity =>
{
entity.Property(e => e.Metadata)
.HasColumnType("jsonb") // PG 使用 jsonb
.HasConversion(
v => JsonSerializer.Serialize(v, (JsonSerializerOptions)null),
v => JsonSerializer.Deserialize<Dictionary<string, object>>(v, (JsonSerializerOptions)null)
);
});
}HasColumnType("jsonb") 会被忽略或产生警告,但由于配置了 HasConversion,数据会被正确地序列化和反序列化为字符串存入 TEXT 字段,从而保证了兼容性。2. 迁移策略的分离
维护两个迁移分支或项目。在 HagiCode 的开发流中,我们是这样处理的:Add-Migration Init_Sqlite -OutputDir Migrations/Sqlite。Add-Migration Init_Postgres -OutputDir Migrations/Postgres。# 简单的部署逻辑伪代码
if [ "$DATABASE_PROVIDER" = "PostgreSQL" ]; then
dotnet ef database update --project Migrations.Postgres
else
dotnet ef database update --project Migrations.Sqlite
fi核心内容三:HagiCode 的实战经验总结
1. 并发与事务的区别
在编写涉及频繁写入的业务逻辑时(例如实时保存用户的编辑状态),一定要考虑到 SQLite 的锁机制。在设计 HagiCode 的 OpenSpec 协作模块时,我们引入了“写前合并”机制,减少数据库的直接写入频率,从而在两种数据库下都能保持高性能。2. 连接字符串的生命周期管理
Program.cs 中,我们可以针对不同数据库做精细化调整:if (databaseSettings?.DbType?.ToLower() == "sqlite")
{
// SQLite:保持连接开启能提升性能,但要注意文件锁
options.UseSqlite(connectionString, sqliteOptions =>
{
// 设置命令超时时间
sqliteOptions.CommandTimeout(30);
});
}
else
{
// PG:利用连接池
options.UseNpgsql(connectionString, npgsqlOptions =>
{
npgsqlOptions.MaxBatchSize(100);
npgsqlOptions.CommandTimeout(30);
});
}3. 测试覆盖的重要性
# .github/workflows/test.yml 示例片段
- name: Run Integration Tests (PostgreSQL)
run: |
docker-compose up -d db_postgres
dotnet test --filter "Category=Integration"总结
appsettings.json。
在局域网或内网环境中使用HTTPS加密通信,可以为内部系统提供更高的安全性。本文将为你详细介绍如何为内网IP地址申请SSL证书。 保护内部通信安全 确认需求:确定需要证书的内网IP地址 一、注册账号 首先,打开浏览器,访问 JoySSL 的官方网站。注册一个账号,在注册中,务必填写注册码230970,这是获取免费测试一年期 IP 地址 SSL 证书的关键步骤,如果不填写该注册码,将无法获得免费测试的资格。 二、测试 IP 地址 SSL 证书,填写相关信息 注册成功后,使用刚刚注册的账号和密码登录 JoySSL 网站。登录成功后,在导航栏中,找到 “SSL 证书” 选项,选择 “IP 地址 SSL 证书”,并填写IP地址、联系人、联系方式等相关申请信息。 三、验证 IP 地址所有权 填写完申请信息后,接下来就是验证 IP 地址所有权的关键步骤。将验证文件上传到服务器上的指定目录。上传完成后,JoySSL 系统会自动检测验证文件的存在,以此来确认您对 IP 地址的管理权。 四、部署证书 下载证书文件后,就需要将其部署到您的服务器上,以使其生效。不同的服务器软件(如 Apache、Nginx、IIS 等)安装 SSL 证书的方法略有不同,具体参考帮助文档。为什么需要内网IP证书?
防止中间人攻击
满足安全合规要求
消除浏览器不安全警告申请前的准备工作
选择证书类型:DV(域名验证)证书即可满足大多数内网需求
准备材料:通常只需要提供IP地址
下面是申请流程:
内网IP证书申请入口
在企业的经营管理体系中,采购管理是控制成本、保障运营与管控风险的核心职能,其质量与效率直接决定了后续招投标、合同履行及供应商管理的成效。北京中烟创新科技有限公司(简称:中烟创新)针对烟草行业采购管理的专业性与合规性要求,推出了“采购文件编制与审核智能体”。深度融合行业规范与管理实践,成功入选“2025AIGC行业创新榜TOP100”,为行业提供了一套高度智能化、标准化的合规高效采购解决方案。 智能体以“全程透明、智能联动”为设计理念,构建了与业务流深度耦合的智能化支撑框架,通过将协同机制与效率优化嵌入采购全周期——从需求发起、文件编制到合同履行与履约跟踪,实现了端到端的闭环管理,推动采购运营向体系化、集成化方向演进。依托结构化流程与智能规则模型,智能体推动管理模式从事后追溯向实时介入转变,从被动响应向主动预警升级,并促进跨角色动态协同。 这一重构不仅提升了采购效率与文件质量,更增强了治理韧性与风险免疫能力,推动采购管理向标准化、智能化、可追溯的新阶段稳步迈进。智能体能够对历史采购数据进行深度挖掘,自动识别潜在瓶颈、优化规则配置,并为管理决策提供预测性建议。每一次文件编制与审核的过程,都同步转化为可复用的规则经验与业务资产,增强采购工作的规范性、效率与决策支持能力。 可直接关联或导入已审批的采购计划与项目方案,自动继承项目名称、预算、采购方式等核心元数据,并予以锁定,确保执行阶段与计划意图的一致性,杜绝了关键信息的重复录入与人为篡改风险。提供多维度的数据看板与可视化甘特图,多视角动态呈现所有采购任务的进展。管理者可借此实时掌控全局,精准调配资源,并对临近节点任务进行系统性预警,保障项目按期推进。采用表单填录与文档自动生成双轨并行的设计,用户在左侧表单区进行结构化数据输入与配置,右侧则同步渲染出格式规范的标准采购文件。 所有修改即时映射并高亮提示,确保了数据源与输出文档的绝对一致,大幅降低了信息错漏的概率。通过内置的规则库与高度灵活的配置界面,在标准化合规与项目个性化需求之间建立了有效平衡,将审核人员从繁重的格式校对、基础条款核验中解放出来,聚焦于更具价值的实质性风险判断与策略分析。 智能体可自动对文件中的关键数据进行跨章节、跨段落的一致性扫描,避免前后矛盾。同时,可将新编制的文件与历史类似项目文件进行智能比对,快速定位差异点,辅助判断其合理性与必要性。在协同工作机制方面,智能体支持实时交互编辑、结构化流程审批及可视化进度监控,确保多角色参与者基于同一数据源高效协同,实现信息无缝流转与任务全过程可追溯,增强了复杂项目下的协作一致性与执行可控性。 从文件创建、编辑、审核、修改到最终定稿,所有操作行为、修改内容、审核意见及审批节点均被完整、加密、时间戳记录,形成不可篡改的电子档案链。这不仅是内部问责与审计巡查的有力证据,更是构建公开、透明、可信采购环境的技术基石,有效防范廉洁风险。采购文件编制与审核智能体成功入选“2025 AIGC创新榜TOP100”,不仅是对中烟创新在人工智能与垂直行业融合领域技术实力的权威认证,更是对其深度理解行业规范与管理痛点的行业洞察力的高度肯定,标志着该系统所引领的专业化、规范化、智能化采购管理新范式获得了业界广泛认同。 智能体的价值根植于一个核心理念:真正的数字化转型必须紧扣业务实质、直击痛点。实践表明,以提升协同效能于强化风险管控为核心路径,能够为各行业领域注入提质增效的合规经营与双重发展动能。 中烟创新将持续以技术创新为驱动,深化系统迭代与业务赋能,为行业的高质量发展提供坚实可靠、智能且具备行业引领价值的数字化支撑体系。
一、概要 二、评估方法 三、厂商推荐 在《数据安全法》《个人信息保护法》《网络数据安全管理条例》等法规持续深化的背景下,数据安全平台已从“合规工具”演进为企业数据治理体系中的核心中枢。2026年的国内市场呈现出三个明确趋势:一是风险识别能力从规则驱动转向“高准确率的智能识别”;二是防护体系从单点工具升级为覆盖数据全生命周期的多层级治理;三是平台价值从“看得见风险”进一步走向“解释得清风险、预判得了趋势”的洞察能力。从落地效果看,领先平台已能够在高并发、复杂业务场景中实现秒级监测与响应,敏感数据识别准确率普遍达到 90% 以上,部分场景下风险拦截率超过 99%,数据安全正逐步从成本项转化为可量化、可评估的治理能力。 为了避免单纯从功能清单或市场声量出发,本文从工程可行性与实战效果出发,构建了三层评估方法。 首先,在准确性维度,重点关注敏感数据识别、异常行为检测和风险判定的真实有效性,包括分类分级准确率、误报率、漏报率以及在复杂业务场景中的稳定表现。其次,在多层级能力维度,评估平台是否具备从数据资产、访问行为、接口调用到跨系统流转的分层治理能力,是否能够将数据库、API、云存储、大数据平台等纳入统一视图,而非割裂管理。最后,在洞察能力维度,考察平台是否能够基于长期数据积累形成风险画像、趋势分析与决策支持,而不仅停留在告警和审计层面。 在方法上,综合参考 IDC、Gartner 的技术评估模型,并结合金融、政务、医疗等行业的真实落地案例,对平台性能、适配度与可持续运营能力进行交叉验证。
TOP1.奇安信数据安全治理平台该平台以体系化能力见长,将数据安全能力与零信任、安全运营体系深度融合,强调数据流动过程的可视化与联动处置。在敏感数据路径追踪和动态脱敏方面表现稳定,适合对合规等级和防护强度要求较高的行业。在实际项目中,其在银行核心系统中实现了对高风险操作的精准拦截,敏感行为识别准确率稳定在 99% 左右,体现出在高安全等级场景下的工程成熟度。
TOP2.启明星辰数据安全平台启明星辰强调数据安全与 SOC、SIEM 等既有安全体系的协同,通过大模型能力提升跨数据库、API 及分析工具的统一审计能力。其优势在于权限管理和风险闭环设计,能够在多部门、多角色环境下实现分级管控。在政务和大型活动保障场景中,该平台通过精细化策略配置,实现了数据访问行为的持续可控,验证了其在复杂组织环境中的稳定适配能力。
TOP3.全知科技数据安全平台全知科技从“API 是数据安全核心关口”的理念出发,将数据安全治理前移至数据流动与调用环节,并参与相关国家标准建设。在技术层面,通过 AI 驱动的多模态识别与动态校准机制,实现了对数据资产、访问行为和接口风险的统一建模。在准确性方面,其敏感数据识别准确率可达 95%,相较人工方式效率提升约 90%;在多层级治理上,通过数据资产地图、数据库风险监测与 API 风险监测的组合,实现从资产发现、行为监测到事件溯源的全链路覆盖;在洞察能力上,平台能够基于历史行为形成风险趋势判断,支持秒级定位与分析。实际案例显示,在金融和医疗场景中,平台可将高风险接口暴露面减少 95% 以上,旧有 API 泄露问题显著收敛,体现出“技术—场景—效果”之间的良性闭环。
TOP4.天融信数据安全治理平台(DSG)天融信在工业互联网和跨网场景中积累较深,其数据流向地图技术能够在复杂网络隔离条件下持续追踪数据交互路径,并与网络与终端安全产品形成联动。在制造业项目中,其对未授权访问的识别与阻断效果稳定,适合对跨域数据流动管控要求较高的企业。
TOP5.阿里云数据安全中心(DSC)阿里云 DSC 深度融入云原生体系,在云数据库与对象存储的敏感数据发现和分类分级方面具备天然优势。通过异常行为建模,可对非正常导出、异常 API 调用进行持续监测。其价值更多体现在多云与跨境合规治理,以及与云生态产品的协同能力,适合互联网及云化程度较高的组织。
TOP6.深信服数据安全中心深信服强调零信任与 SASE 架构下的数据防护,部署方式相对轻量,适合希望快速完成合规建设的教育、医疗等行业。在性能与成本之间取得较好平衡,但在复杂多系统联动与深度洞察方面,更适合与其他安全运营能力协同使用。
四、总结 总体来看,2026 年的数据安全平台竞争已从“功能齐备”转向“能力取舍”。不同厂商在准确性、多层级治理深度与洞察能力上的侧重点各不相同,并不存在绝对优劣。 对于强调合规与安全等级的组织,体系化与联动能力仍是首要考量;对于业务复杂、数据流动频繁的企业,更需要在准确识别与多层级治理之间取得平衡;而希望通过数据安全反哺治理决策的组织,则应重点关注平台的洞察与分析能力。 可以预见,随着标准持续完善,真正具备“可准确识别风险、可分层治理数据、可持续输出洞察”的平台,将在下一阶段竞争中逐步拉开差距。
在信息过载和碎片化成为常态的数字化时代,组织所面临的挑战不仅仅是信息的收集,而是在众多信息源中实现"认知的清晰"。分栏式信息梳理工具不是简单的信息展示媒介,而是一种通过结构化的分栏排列模式,将复杂、异构的业务元素转变为可对齐、可比较、可协同分析的多维信息中枢。 传统线性和单栏信息展示模式常常造成"认知视野受限":单向流动的信息流削弱了多源数据并置分析的能力,关键洞察在大量非结构化内容中被埋没或难以关联。分栏式信息梳理工具的核心价值在于: 二、 分栏式信息梳理工具的技术路径:多维并置框架 构建高效的分栏式信息梳理体系需要遵循"信息单元粒度控制"与"空间关系参数化"的设计原则: 三、 核心技术实现与算法示例 分栏式信息梳理工具的底层逻辑涉及信息关联度评估、栏位空间优化以及认知路径建模。 在分栏结构中,关键信息的展示位置直接影响认知关注度。以下为 JavaScript 实现的信息重要性计算逻辑: JavaScript /** } 利用分栏模型,自动检测信息"逻辑流"与"预设分栏布局"之间的认知偏差,识别信息组织中的混乱风险: Python class ColumnCognitionAuditEngine: 四、 工具分类与选型思路 在实施分栏式信息梳理时,工具的选择应基于对"信息并置能力"的需求: 五、 实施中的风险控制与管理优化 六、 结语 分栏式信息梳理是构建高效认知框架的空间基础。 分栏式信息梳理工具不仅解决了"信息散乱"的问题,更通过严谨的信息并置架构,将每一次信息处理转化为可视化、可对齐、可复用的认知资产。当信息能够以分栏形式精准组织时,团队和个人才能在复杂多变的信息环境中实现"深度理解"与"快速决策"的完美对齐。一、 为什么现代认知工作流亟需"分栏式"信息架构?
1. 基于并置权重的信息重要性与栏位优先级计算
* 计算信息单元在分栏布局中的认知影响权重及其栏位优先级
* @param {Object} infoUnit 信息单元(包含相关因子)
* @returns {number} 该信息单元的综合栏位权重
*/
function calculateInfoColumnImpact(infoUnit) {// 基准情况:如果是独立信息单元,返回其基础认知评分
if (!infoUnit.relatedItems || infoUnit.relatedItems.length === 0) {
return infoUnit.cognitivePriority || 0;
}
// 汇总相关信息的加权影响力,决定其在分栏中的突出程度
const totalImpact = infoUnit.relatedItems.reduce((acc, related) => {
// 根据关联强度决定栏位吸附力权重
const relationStrength = related.relationWeight || (1 / infoUnit.relatedItems.length);
return acc + (calculateInfoColumnImpact(related) * relationStrength);
}, 0);
// 更新该信息在整体分栏结构中的权重得分
infoUnit.columnPositionScore = Math.round(totalImpact);
return infoUnit.columnPositionScore; 2. Python:信息并置冗余的动态认知熵检测模型
def __init__(self):
# 预设标准分栏基准:信息类型 -> 信息密度与对齐标准
self.cognition_benchmarks = {
"Strategic_Analysis": {
"Overview": {"density": 0.8, "alignment": 95},
"Detail": {"density": 0.9, "alignment": 85}
}
}
def verify_column_alignment(self, current_layout, info_type):
"""对比实际信息分栏与标准认知基准,识别信息组织薄弱点"""
base_std = self.cognition_benchmarks.get(info_type)
if not base_std:
return "未找到匹配的信息分栏认知标准"
for section_type, data in current_layout.items():
std = base_std.get(section_type)
if std:
gap = (data['coherence_rate'] - std['alignment']) / std['alignment']
if gap < -0.10:
print(f"[Cognition Alert] '{section_type}' 区域信息并置失序,存在认知负荷风险")
# 触发分栏重组引导机制
self._trigger_cognitive_realignment(section_type)
说一下能我自己感到自洽或者舒服的“活动”吧
1 、每天上下班的路上/楼下停车场里,自己一个人车上听歌或者听播客
2 、有宵夜有肉的话,特别喜欢肉蘸(酱油+辣椒酱),南方人不吃辣椒,但这一刻会希望狠狠的吃一顿肉蘸辣椒(我自己理解就想喜欢喝酒的朋友一样,自己一个人独酌)
在Unity的Shader Graph中,Blackbody节点是一个专门用于模拟黑体辐射物理现象的功能节点。黑体辐射是热力学和量子力学中的重要概念,描述了理想黑体在特定温度下发出的电磁辐射特性。在计算机图形学中,这一物理原理被广泛应用于模拟真实世界中的热发光效果,为游戏和可视化应用增添了更多的物理准确性。 黑体辐射理论源于19世纪末的物理学研究,当时科学家们试图解释物体受热时发出的光色变化规律。一个理想的黑体能够完全吸收所有入射的电磁辐射,同时在热平衡状态下以特定的光谱分布发射辐射。这种光谱分布仅取决于黑体的温度,而与它的形状或组成材料无关。 在Shader Graph中,Blackbody节点正是基于这一物理原理实现的。它通过输入温度值(以开尔文为单位),计算出对应的黑体辐射颜色。这一过程模拟了真实世界中物体随温度升高而改变发光颜色的现象,比如一块金属从暗红色逐渐变为亮白色。 理解Blackbody节点的工作原理对于创建逼真的热发光效果至关重要。它不仅提供了物理准确的颜色计算,还能帮助开发者避免手动调整颜色值的繁琐过程,确保不同温度下的颜色过渡自然且符合物理规律。 Blackbody节点的设计简洁而高效,仅包含两个主要端口,分别负责输入温度数据和输出计算得到的颜色值。 Temperature端口是Blackbody节点的核心输入,它接收一个浮点数值或浮点纹理,表示黑体的绝对温度,单位为开尔文(K)。 Out端口输出一个三维向量(Vector3),表示在给定温度下黑体辐射的RGB颜色值。 Blackbody节点的核心算法基于黑体辐射的物理公式,通过近似计算将温度值转换为对应的RGB颜色。 黑体辐射的光谱分布由普朗克辐射定律描述,该定律给出了在特定温度T下,黑体在波长λ处单位波长间隔内辐射出的能量: B(λ, T) = (2hc²/λ⁵) / (e^(hc/λkT) - 1) 其中h是普朗克常数,c是光速,k是玻尔兹曼常数。虽然完整的普朗克公式计算复杂,但Blackbody节点使用了一种经过优化的近似算法,在保证视觉准确性的同时提高了计算效率。 根据生成的代码示例,我们可以看到Blackbody节点的具体实现方式: 这个算法可以分为几个关键部分: Unity选择这种近似算法而非完整的普朗克公式计算,主要基于实时渲染的性能考虑: Blackbody节点在URP Shader Graph中有着广泛的应用场景,从简单的热发光材质到复杂的热视觉效果都可以通过它实现。 创建基础的热发光材质是Blackbody节点最直接的应用: 这种设置可以用于模拟熔岩、发热的金属、火焰核心等高温物体,通过简单调整温度值即可获得物理正确的发光颜色。 通过将Temperature端口与时间或空间变化的参数相连,可以创建动态的热效果: 这些技术可以用于实现熔岩流动、冷却的锻造金属、或者逐渐加热的物体等动态效果。 Blackbody节点也是创建热视觉或红外视觉效果的理想工具: 这些应用在军事模拟、科幻游戏或特殊视觉效果中尤为有用。 了解常见温度值对应的颜色输出,有助于更有效地使用Blackbody节点。 以下是一些典型温度值与产生的颜色关系: Blackbody节点产生的颜色过渡具有几个重要特性: 理解这些特性有助于创建更自然的热效果动画,避免颜色变化的生硬感。 掌握Blackbody节点的高级使用技巧可以大幅提升效果质量和性能。 在性能敏感的场景中使用Blackbody节点时,可以考虑以下优化: Blackbody节点与其他Shader Graph节点组合可以创造更复杂的效果: 在HDR渲染管线中使用Blackbody节点时需特别注意: 在使用Blackbody节点过程中,开发者可能会遇到一些典型问题。 如果发现Blackbody节点产生的颜色不符合预期: 当使用多个Blackbody节点导致性能下降时: 将Blackbody效果与其他游戏系统集成时可能遇到的挑战:【Unity Shader Graph 使用与特效实现】专栏-直达
Blackbody节点的基本概念
节点端口详解

输入端口:Temperature
输出端口:Out
数学原理与算法实现
普朗克辐射定律基础
节点算法解析
void Unity_Blackbody_float(float Temperature, out float3 Out)
{
float3 color = float3(255.0, 255.0, 255.0);
color.x = 56100000. * pow(Temperature,(-3.0 / 2.0)) + 148.0;
color.y = 100.04 * log(Temperature) - 623.6;
if (Temperature > 6500.0) color.y = 35200000.0 * pow(Temperature,(-3.0 / 2.0)) + 184.0;
color.z = 194.18 * log(Temperature) - 1448.6;
color = clamp(color, 0.0, 255.0)/255.0;
if (Temperature < 1000.0) color *= Temperature/1000.0;
Out = color;
}算法优化考虑
在Shader Graph中的实际应用
基础热发光材质
动态温度效果
热视觉特效
温度值与颜色对应关系
典型温度颜色示例
颜色过渡特性
高级技巧与优化建议
性能优化策略
与其他节点的组合使用
HDR渲染注意事项
常见问题与解决方案
颜色不准确问题
性能问题
与其他系统的集成问题
【Unity Shader Graph 使用与特效实现】专栏-直达
(欢迎
探讨,更多人加入进来能更加完善这个探索的过程,🙏)
开发时想看到DEBUG级别的详细日志排查问题,测试环境却需要INFO级别过滤冗余信息,生产环境更是要严格限制日志输出量——不同环境对日志的需求天差地别,但很多项目还在用一套配置"走天下"。 要么开发时日志太简略查不出问题,要么生产环境日志刷屏占满磁盘,甚至因为日志级别过低泄露敏感信息。本文就带你用SpringBoot的原生能力,零代码侵入实现多环境日志隔离,让开发、测试、生产环境的日志配置各得其所。 在SpringBoot项目中,结合Logback的特性,我们可以通过两种方案实现不同环境的日志配置隔离。两种方案各有侧重,可根据项目规模和环境差异程度选择。 这种方案为每个环境创建独立的日志配置文件,通过主配置文件根据激活的环境动态加载,实现彻底的配置隔离。 在 在 开发环境(logback-dev.xml):需要最详细的日志,方便调试 生产环境(logback-prod.xml):日志精简且持久化,注重性能和安全 通过以下任意方式指定当前环境,SpringBoot会自动加载对应的日志配置: 如果环境间日志配置差异不大,可将所有配置写在一个 日志级别细化到包 敏感信息过滤 结合SpringBoot配置文件 对应的 多环境组合配置 启动时指定: 无论选择哪种方案,核心都是利用SpringBoot的Profile机制,让日志配置能够随环境动态调整。合理的日志隔离策略不仅能提高开发效率,还能减少生产环境的性能损耗和安全风险。 https://github.com/lyb-geek/springboot-learning/tree/master/springboot-logback-env-isolate前言:日志配置的"环境困境"你遇到过吗?
正文:两种方案实现环境日志隔离
方案一:多文件完全隔离(推荐环境差异大的场景)
1. 遵循命名规范创建配置文件
src/main/resources目录下创建以下文件,SpringBoot会根据激活的环境自动识别:logback-spring.xml:主配置文件,负责根据环境引入对应配置logback-dev.xml:开发环境专用配置logback-test.xml:测试环境专用配置logback-prod.xml:生产环境专用配置注意:文件名必须以
logback-spring.xml开头,而非传统的logback.xml,这样才能启用Spring的Profile特性。2. 主配置文件动态引入环境配置
logback-spring.xml中,通过<springProfile>标签指定不同环境加载对应的配置文件:<configuration>
<!-- 引入SpringBoot默认的日志配置(可选) -->
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<!-- 开发环境:加载logback-dev.xml -->
<springProfile name="dev">
<include resource="logback-dev.xml"/>
</springProfile>
<!-- 测试环境:加载logback-test.xml -->
<springProfile name="test">
<include resource="logback-test.xml"/>
</springProfile>
<!-- 生产环境:加载logback-prod.xml -->
<springProfile name="prod">
<include resource="logback-prod.xml"/>
</springProfile>
<!-- 根日志默认配置 -->
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
</configuration>3. 编写环境专属配置
<included>
<!-- 控制台输出(开发必备) -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<!-- 开发环境日志级别设为DEBUG,输出所有细节 -->
<logger name="com.yourpackage" level="DEBUG"/>
<!-- 根日志使用控制台输出 -->
<root level="DEBUG">
<appender-ref ref="CONSOLE"/>
</root>
</included><included>
<!-- 滚动文件输出:按天分割,保留30天 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/yourapp/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/var/log/yourapp/app.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
<!-- 可选:设置总大小限制 -->
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<!-- 错误日志单独输出,方便排查问题 -->
<appender name="ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
<file>/var/log/yourapp/error.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/var/log/yourapp/error.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<!-- 生产环境日志级别设为WARN,减少输出量 -->
<logger name="com.yourpackage" level="WARN"/>
<!-- 第三方框架日志级别控制,避免刷屏 -->
<logger name="org.springframework" level="INFO"/>
<logger name="com.fasterxml.jackson" level="INFO"/>
<!-- 根日志输出到文件 -->
<root level="INFO">
<appender-ref ref="FILE"/>
<appender-ref ref="ERROR_FILE"/>
</root>
</included>4. 激活对应环境的配置
application.properties中配置:spring.profiles.active=devjava -jar yourapp.jar --spring.profiles.active=prodexport SPRING_PROFILES_ACTIVE=test(Linux)或set SPRING_PROFILES_ACTIVE=test(Windows)方案一优势总结
方案二:单文件条件配置(适合环境差异小的场景)
logback-spring.xml中,通过<springProfile>标签区分不同环境的配置。1. 单文件配置实现
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="30 seconds">
<!-- 定义通用变量,减少重复配置 -->
<property name="LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n"/>
<property name="LOG_PATH" value="logs"/>
<!-- 控制台输出(通用配置) -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 开发环境配置 -->
<springProfile name="dev">
<appender name="DEV_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/dev-app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/dev-app.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>7</maxHistory> <!-- 开发环境保留7天日志 -->
</rollingPolicy>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<!-- 开发环境日志级别:DEBUG,输出到控制台和文件 -->
<root level="DEBUG">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="DEV_FILE"/>
</root>
</springProfile>
<!-- 测试环境配置 -->
<springProfile name="test">
<appender name="TEST_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/test-app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/test-app.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>15</maxHistory> <!-- 测试环境保留15天 -->
</rollingPolicy>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<!-- 测试环境日志级别:INFO -->
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="TEST_FILE"/>
</root>
</springProfile>
<!-- 生产环境配置 -->
<springProfile name="prod">
<appender name="PROD_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/prod-app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/prod-app.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory> <!-- 生产环境保留30天 -->
</rollingPolicy>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<!-- 生产环境错误日志单独输出 -->
<appender name="PROD_ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
<file>${LOG_PATH}/prod-error.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/prod-error.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<!-- 生产环境日志级别:WARN,关闭控制台输出 -->
<root level="WARN">
<appender-ref ref="PROD_FILE"/>
<appender-ref ref="PROD_ERROR_FILE"/>
</root>
</springProfile>
</configuration>2. 配置要点说明
<springProfile name="dev,local">:支持逗号分隔多个环境(如同时匹配dev和local环境)scan="true":开启配置文件热更新,修改后30秒内自动生效(无需重启应用)${变量名}引用,减少重复代码方案二优势总结
进阶技巧:让日志配置更实用
可以针对不同包设置不同日志级别,例如让controller层输出DEBUG级别,而service层输出INFO级别:<logger name="com.yourpackage.controller" level="DEBUG"/>
<logger name="com.yourpackage.service" level="INFO"/>
在生产环境日志中过滤密码、token等敏感信息,可通过自定义过滤器实现:<filter class="com.yourpackage.log.SensitiveInfoFilter"/>
日志路径等配置可通过application.properties注入,实现更灵活的配置:<property name="LOG_PATH" value="${logging.path:logs}"/>application.properties配置:logging.path=/var/log/yourapp # 生产环境日志路径
支持"基础环境+扩展环境"的组合,例如dev环境基础上增加dev-mysql配置:<springProfile name="dev-mysql">
<logger name="com.yourpackage.dao" level="DEBUG"/>
</springProfile>--spring.profiles.active=dev,dev-mysql总结:如何选择合适的方案?
场景 推荐方案 理由 大型项目,多团队协作 方案一(多文件隔离) 配置职责清晰,避免多人修改冲突 环境间日志策略差异大 方案一(多文件隔离) 完全隔离便于针对性优化 小型项目,环境差异小 方案二(单文件配置) 维护成本低,配置集中 快速迭代的项目 方案二(单文件配置) 修改便捷,无需切换文件 实战Demo
在日常数据处理中,Excel 文件承载着海量信息。然而,面对包含多工作表、超长行数或需要按特定列进行分类的巨型 Excel 文件时,手动拆分无疑是一场噩梦,效率低下且容易出错。作为开发者,我们追求自动化和效率。本文将深入探讨如何利用 Java 强大的编程能力,结合 Spire.XLS for Java 库,高效、精准地完成 Excel 文件的拆分任务,让数据处理变得轻而易举。无论您是需要将一个 Excel 文件按工作表拆分为多个独立文件,还是需要将一个工作表按行或按列拆分成更小的单元,本教程都将为您提供清晰、可操作的解决方案。 Spire.XLS for Java 是一个功能全面、高性能的 Java Excel API,允许开发者在 Java 应用程序中创建、读取、编辑、转换和打印 Excel 文件。它支持多种 Excel 格式(XLS、XLSX、CSV、ODS 等),提供了丰富的特性,包括但不限于单元格操作、样式设置、图表、数据透视表、公式计算等。对于 Excel 拆分这种常见的自动化需求,Spire.XLS for Java 提供了直观且强大的 API 接口。 要在您的 Java 项目中使用 Spire.XLS for Java,最便捷的方式是通过 Maven 添加其依赖。 Maven: 将上述配置添加到您的 最常见的拆分需求是将一个包含多个工作表的 Excel 文件,拆分成多个独立的 Excel 文件,每个文件只包含原文件中的一个工作表。 关键代码解析: 当单个工作表数据量过大时,我们可能需要将其按行数或特定条件拆分成多个工作表或新的 Excel 文件。这里演示按固定行数拆分。 关键代码解析: 除了按行拆分,有时我们还需要将一个工作表按列拆分成多个文件,例如将原始数据按某些关键列进行分组。这里演示按固定列数拆分。 关键代码解析: 通过本文的详细教程,我们深入了解了如何利用 Spire.XLS for Java 库在 Java 应用程序中高效地拆分 Excel 文件。无论是按工作表、按行还是按列进行拆分,Spire.XLS for Java 都提供了简洁而强大的 API,极大地简化了复杂的 Excel 处理任务。它的高性能和丰富功能使其成为 Java 开发者处理 Excel 文件的理想选择。希望这些示例代码能帮助您在实际项目中实现 Excel 自动化处理,提升工作效率。鼓励大家尝试探索 Spire.XLS for Java 的更多功能,发现它在数据处理领域的无限潜力!一、Spire.XLS for Java 简介与环境配置
1. 安装依赖
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>16.1.3</version>
</dependency>
</dependencies>pom.xml 文件中,然后重新加载项目依赖即可。二、按工作表拆分 Excel 文件
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
public class SplitExcel {
public static void main(String[] args) {
// 创建 Workbook 对象
Workbook wb = new Workbook();
// 加载 Excel 文档
wb.loadFromFile("/input/世界各洲人口前十国家.xlsx");
// 声明 Workbook 变量
Workbook newWb;
// 声明 String 类型变量
String sheetName;
// 指定拆分生成的文档的存放路径
String folderPath = "/output/按表拆分/";
// 遍历所有工作表
for (int i = 0; i < wb.getWorksheets().getCount(); i++) {
// 初始化 Workbook 对象
newWb = new Workbook();
// 删除默认工作表
newWb.getWorksheets().clear();
// 将源文档中的指定工作表复制到新的 Workbook
newWb.getWorksheets().addCopy(wb.getWorksheets().get(i));
// 获取工作表表名
sheetName = wb.getWorksheets().get(i).getName();
// 将新的 Workbook 保存为 Excel 文档
newWb.saveToFile(folderPath + sheetName + ".xlsx", FileFormat.Version2013);
}
}
}workbook.loadFromFile("input.xlsx"):加载待处理的 Excel 文件。workbook.getWorksheets().getCount():获取工作表的总数。workbook.getWorksheets().get(i):获取指定索引的工作表。newWb.getWorksheets().addCopy():将原始工作表复制到新创建的 Workbook 对象中。newWorkbook.saveToFile(outputFileName):将包含单个工作表的新工作簿保存为独立文件。三、按行拆分 Excel 工作表
import com.spire.xls.*;
import java.util.EnumSet;
public class spiltexcel {
public static void main(String[] args) {
// 设置文件的输入和输出路径
String sourceFile = "/input/世界各洲人口前十国家.xlsx";
String folderPath = "/output/";
// 创建一个 Workbook 类的对象并加载 Excel 文件
Workbook workbook = new Workbook();
workbook.loadFromFile(sourceFile);
// 获取源文件的第一个工作表
Worksheet sheet = workbook.getWorksheets().get(0);
// 创建新的工作簿作为目标文件并清除默认工作表
Workbook newWorkbook1 = new Workbook();
newWorkbook1.getWorksheets().clear();
// 在目标文件新增一个工作表
Worksheet newSheet1 = newWorkbook1.getWorksheets().add("Sheet1");
// 将源文件第一个工作表的第1-5行复制到目标文件中
int destRow1 = 1;
for (int i = 0; i < 5; i++) {
sheet.copyRow(sheet.getRows()[i], newSheet1, destRow1++, EnumSet.of(CopyRangeOptions.All));
}
copyColumnWidths(sheet, newSheet1);
newWorkbook1.saveToFile(folderPath + "1-5行.xlsx", ExcelVersion.Version2016);
// 创建新的工作簿作为目标文件 2 并清除默认工作表
Workbook newWorkbook2 = new Workbook();
newWorkbook2.getWorksheets().clear();
// 在目标文件 2 新增一个工作表
Worksheet newSheet2 = newWorkbook2.getWorksheets().add("Sheet1");
int destRow2 = 1;
// 复制表头
sheet.copyRow(sheet.getRows()[0], newSheet2, destRow2++, EnumSet.of(CopyRangeOptions.All));
// 将源文件第一个工作表的第6-10行复制到目标文件中
for (int i = 5; i < 10; i++) {
sheet.copyRow(sheet.getRows()[i], newSheet2, destRow2++, EnumSet.of(CopyRangeOptions.All));
}
copyColumnWidths(sheet, newSheet2);
newWorkbook2.saveToFile(folderPath + "6-10行.xlsx", ExcelVersion.Version2016);
}
private static void copyColumnWidths(Worksheet source, Worksheet dest) {
for (int i = 0; i < source.getColumns().length; i++) {
dest.setColumnWidth(i + 1, source.getColumnWidth(i + 1));
}
}
}sheet.getRows():获取源工作表的指定行。sheet.copyRow():将刚才获取到的行复制到新的工作表中。rowsPerSheet 行的数据(包括标题行)到一个新的工作簿中。saveToFile():保存修改后的 Excel 文件。四、按列拆分 Excel 工作表
import com.spire.xls.*;
import java.util.EnumSet;
public class SplitExcel {
public static void main(String[] args) {
// 创建 Workbook 对象并加载 Excel 文件
Workbook workbook = new Workbook();
workbook.loadFromFile("/input/世界各洲人口前十国家.xlsx");
// 获取原始(第一个)工作表
Worksheet worksheet = workbook.getWorksheets().get(0);
// 指定生成的 Excel 文件的文件夹路径
String folderPath = "/output/";
// 创建新的 Workbook,删除默认工作表并添加新的工作表
Workbook newWorkbook1 = new Workbook();
newWorkbook1.getWorksheets().clear();
Worksheet newWorksheet1 = newWorkbook1.getWorksheets().add("Sheet1");
// 从原始工作表复制第 1-2 列到新工作表
for (int i = 1; i <= 2; i++) {
// 参数:源列,目标表,目标起始列索引,复制选项
worksheet.copyColumn(worksheet.getColumns()[i - 1], newWorksheet1, newWorksheet1.getLastDataColumn() + 1, EnumSet.of(CopyRangeOptions.All));
}
// 复制行高以保持样式一致
for (int i = 0; i < worksheet.getRows().length; i++) {
newWorksheet1.setRowHeight(i + 1, worksheet.getRowHeight(i + 1));
}
newWorkbook1.saveToFile(folderPath + "AB列.xlsx", ExcelVersion.Version2016);
newWorkbook1.dispose();
// 创建新的 Workbook,删除默认工作表并添加新的工作表
Workbook newWorkbook2 = new Workbook();
newWorkbook2.getWorksheets().clear();
Worksheet newWorksheet2 = newWorkbook2.getWorksheets().add("Sheet1");
// 从原始工作表复制第 3-4 列到新工作表
for (int i = 3; i <= 4; i++) {
worksheet.copyColumn(worksheet.getColumns()[i - 1], newWorksheet2, newWorksheet2.getLastDataColumn() + 1, EnumSet.of(CopyRangeOptions.All));
}
// 复制行高
for (int i = 0; i < worksheet.getRows().length; i++) {
newWorksheet2.setRowHeight(i + 1, worksheet.getRowHeight(i + 1));
}
newWorkbook2.saveToFile(folderPath + "CD列.xlsx", ExcelVersion.Version2016);
newWorkbook2.dispose();
}
}worksheet.getColumns():获取源工作表的指定列。 worksheet.copyColumn():将获取到的列复制到新的工作表中。saveToFile() 保存修改后的 Excel 文件。五、结语
在网上找了一圈,没找到合适的方案
能够让 Claude Code 这类 cli 工具,能够和 vscode/Cursor 一样
不在服务器安装 Claude Code ,而是本地安装 cli 工具
远程服务器上的代码进行编程
必须要在远程服务器上安装 Claude code 才能进行 vide coding 吗?
2 月 2 日,SpaceX 宣布收购马斯克的人工智能公司 xAI。该笔交易使 SpaceX 成为市值最高的私营公司,达 12.5 亿美元。马斯克在收购备忘录中表示,SpaceX 的本次收购主要目标是建立天基数据中心,旨在规避大型地面数据中心运行 AI 时产生的电力与制冷问题。来源
2 月 2 日,Adobe 发布公告,自 2026 年 3 月 1 日起停止运营 Adobe Animate,并将从官网下架该程序,用户无法再下单购买。企业用户可在 2029 年 3 月 1 日前使用该应用、下载内容、收到技术支持,其他用户则可在 2027 年 3 月 1 日前继续使用、下载内容与获得技术支持。Adobe Animate 前身为 Adobe Flash Professional / Macromedia Flash,可用于创建矢量图像与动画。Adobe 在公告中称,由于科技进步,新的平台与范式出现,已经有更好的应用来支持用户的创作需求。公告推荐用户使用 After Effects 或 Adobe Express 替代该应用。来源
2 月 1 日,鹰角网络向南方都市报记者回应 1 月 22 日《明日方舟:终末地》上线首日,海外服务器 PayPal 支付接口出现严重错误事件。鹰角方表示支付问题发生时,海外多数地区处于非游戏高峰期,在收到用户反馈后公司便第一时间关闭 PayPal 支付选项,整体处置较及时;最终受影响订单量 3429 单,总金额不超过 8 万美元,受影响用户不超过 1800 人,单个用户最高异常扣费 5289 美元。截至当日,鹰角网络已完成对全部受影响用户的全额退款。来源
据 OpenSourceMalware 报道,自 1 月 27 日至 2 月 1 日,已有两波共计超 230 个恶意技能(skill)被发布至 OpenClaw(前 ClawdBot/MoltBot)技能集合站 ClawHub 与 GitHub。这些恶意技能大多针对加密货币交易者,伪装成正常的加密货币交易自动化工具,并在 Windows / macOS 上盗取传递敏感信息。这些恶意技能均采用同样的内在策略,并使用精巧的社会工程劝说用户执行恶意命令,该命令会偷取用户的交易 API 令牌、钱包私钥、SSH 证书与浏览器密码等。来源
2 月 2 日,ROG Kithara 臻世游戏耳机发布上架。该耳机与音频厂商 HIFIMAN 合作打造,采用 ROG 调校 100 mm HIFIMAN 平板振膜发声单元与开放式设计,配备可换插头平衡耳机线,适配 DAC、功放、游戏主机与 PC,配备全频带线控 MEMS 麦克风,首发价 1999 元。来源


我前后已经尝试了 10 多次连接 telegram 或 whatsapp ,包括不断的重装 openclaw,一次又一次的试。
安装的时候,想连接 whatsapp ,无法生成二维码链接,然后使用的是电话号码+86135xxxxxxxx 这种方式,但无法相互发消息。
telegram 是使用的电话号码,也是一样,虽然安装完成了,但无法发消息。
此时 whatsapp 和 telegram 是可以正常使用的,可以与其他人聊天,我也开了全局代理,却唯独无法与 openclaw 互发消息。
是因为使用的是中国区的手机号码吗?

前几天看到有小伙伴的帖子说他的开源被阮一峰老师的科技爱好者周刊选中了,我上周也去投稿了我的 ApiFlow,很遗憾没被选中。
这是我去年的文章,https://www.v2ex.com/t/1125557
当时准备找个成熟竞品完全复刻下来,搞了快一年,终于看到结果了,v 友们,今年就是我冲击国产第一开源接口工具的元年。
最早评论区有 v 友担心这类项目工程量巨大,可能需要大量打磨时间,最早我也是太低估这个项目了。当时计划的是 6 个月搞定,结果陆陆续续搞了接近一年时间才完成。这还是完全借助大模型才有这个速度。
后续计划
1.继续开发
2.继续推广
3.继续冲榜
各位感兴趣的小伙伴可以关注一下,我会实时更新运营数据。
另外欢迎大家试用这个工具,完全离线,AI First ,docker 部署,目标就是集合所有市面上付费功能全部免费开源出来


今天跟朋友聚会,想玩骰子猜酒,手头没有好工具。
网上搜了一下,发现有一款还可以,里面摇骰子、抛硬币、大转盘、自动分组等聚会时的各种功能都有。网址是: https://funbox.space/
我添加到手机桌面了,感觉挺合适的。不过,只有英文版,有点蛋疼
这种复杂的情绪,好难排解,大家有什么想法?
觉得只要爸妈还在,就很难真的说出口「今年我不回」。
内心也会有愧疚感,春节的氛围和习俗,就很难彻底做那个「过年不回家的人」。
每年都要和自己谈判拉扯,这种无力感好无奈。
最近看到飞牛 NAS爆出的漏洞,路径遍历漏洞,NAS 只要放在 WAF 后面其实不会受到漏洞影响的。于是特来分享这篇 WAF 部署教程。
该文适合有一台小主机,性能还可以,有ipv4/6公网地址,并设置了DDNS。或者有公网 ip的用户
相信大家跟我一样有all in one小主机,家里也部署了几套应用(群晖 NAS、飞牛 NAS、emby等),害怕哪天被黑客入侵了,丢失了数据,损失了时间。
本次部署的 WAF 是使用的长亭家的雷池 WAF,官方推荐使用 docker 安装,所以想使用 WAF 先安装 docker,docker 安装教程请自行百度
下面是我家里的网络拓扑,如果有类似或者一样的可以抄作业了。我的all in one的配置是ESXI+OpenWrt+Windows10+Linux,底层使用的ESXI 系统作为虚拟机,大家也可以使用PVE,这个是不影响的,也不是本次的重点,重点是安装docker的那台Linux。
WAF 是 Web Application Firewall 的缩写,也被称为 Web 应用防火墙。区别于传统防火墙,WAF 工作在应用层,对基于 HTTP/HTTPS 协议的 Web 系统有着更好的防护效果,使其免于受到黑客的攻击。
注:WAF 并不能对非 HTTP 协议的流量进行防护哦,例如 SSH、FTP 等
也就是说如果我们的部署了 web 服务就可以使用 WAF 来拦截非法请求,保护我们的系统,WAF 官网地址是  。
。
Linux 镜像,这里使用的是Debian 系统
爱折腾的你和你的小手
安装 Linux 系统步骤省略,如有不会的可以自行百度即可,配置这块最好是给 2C4G,40G
安装命令,需使用 root 权限安装,这里我的 Linux 的 ip 为10.10.10.164,这台机器只是用户演示怎么安装流程,后续会用我已经使用的机器去配置如何设置 WAF。bash -c "$(curl -fsSLk https://waf-ce.chaitin.cn/release/latest/manager.sh)"

当看到这个的时候雷池就部署好了
访问 https://10.10.10.164:9443 端口进行登录访问
登录后的页面是这样的,后面我就用我现在使用的雷池,用于配置防护
在配置站点防护前,请大家阅读长亭 waf 的配置手册,以下是我的配置流程,如果你们的设置和我一样,可以进行抄作业,如果不一样,请大家结合 配置手册 ,进行配置。
在没有部署 waf 之前我们想要通过公网访问我们内网的应用需要做端口映射(转发),其网络拓扑是这样的

需要在路由器上配置 10.10.10.198 的 5000 端口,进行端口映射(转发),才能访问到我们内网的群晖系统。
注:每个家用路由器配置页面都不一样,请根据自己的路由器型号自行配置,其原理都是一致的。

现在我们给群晖配置 WAF,其工作流程就是先把流量引到 WAF 上检测,然后 WAF 再用 Nginx 将流量转发到群晖上。其网络拓扑如下:

1.了解工作流程后我们来配置 WAF ,首先上传我们的 SSL 证书,不上传证书也可以正常使用,证书上传不是必须。防护站点-证书管理-添加证书

2.添加我们需要防护的站点,比如添加我们的群晖 NAS。防护站点-站点管理-添加站点

上游服务器填写真实群晖 NAS 的访问地址,格式为http://ip+端口或者https://ip+端口
域名填写你的域名即可,这里的端口我们需要记录下来,因为群晖默认端口是 5000,这里我们也使用 5000
如果勾选 SSL 的话,就会出现中间下拉框选中证书,选择你上传后的证书即可。
这样我们就部署好了一个 web 应用的 waf 防护站点。接下来我们还需要设置端口映射(转发)
设置端口转发,在上面我们说了,没有配置 waf 时,我们只需要直接填写 NAS 的地址+ip 就可以直接访问,现在我们部署了 waf,需要更改配置。
只需要更改内网地址为 WAF 的地址即可。其中内部端口要和 WAF 中配置的端口要一致,因为 WAF 上我们配置时使用的是 5000 端口,所以这里我们也是要设置 5000 端口,如果上面设置的是 6000 端口,这里内部端口就要设置为 6000。外部端口可以随便设置,这个端口就是你域名+这个端口,就可以访问到群晖 NAS。
注:每个家用路由器配置页面都不一样,请根据自己的路由器型号自行配置,其原理都是一致的。

现在我们已经配置好了 WAF,我们就去试试有没有效果,在设置之前,我们需要更改一些 WAF 的配置,推荐配置如下,如果不配置的话,WAF 会经常拦截我们正常的应用,导致无法使用。
防护配置-频率设置

访问到这个页面就说明 WAF 已经部署成功,Ps.在部署的时候勾选了 SSL 证书,这里我们也是使用 https 访问的,因为 WAF 的作用类似 Nginx,我们把证书放在 Nginx 上,流量经过 Nginx 就会进行 SSL 证书校验,这样会让我们的 NAS 更加安全。

查看 WAF 面板,可以看到流量请求。

我们测试 WAF 的拦截效果,我们使用 https://xxxxxxx:5000/?id=1 and 1=1 #这个语句进行测试,看到下面这个页面说明 WAF 进行了拦截。

在 WAF 面板上可以看到攻击状态,因为我在内网进行测试,如果所以攻击 ip 显示的是我网关的地址。

这样我们的 WAF 部署就结束了,可以开心的玩耍了,再也不用担心应用被人干了还不知道了。
这个 WAF 也不是那么完美,因为是免费的所以很多功能受限,比如日志功能等,但是他完全可以给我们的应用提供第一道防护,这次的飞牛 NAS 的 0Day 漏洞是完全可以防护的。

在人工智能发展的早期阶段,AI 往往以“创新项目”“试点工程”或“专项研发”的形式存在于企业内部。它通常被视为一种附加能力,用于优化某个局部流程或解决特定问题。 进入 2026 年,这一形态正在系统性消失。 随着算力结构的持续优化、预训练模型泛化能力的显著提升,以及部署与治理体系的标准化成熟,AI 已完成从“技术插件”向“通用基础设施”的转变。它不再以独立项目的方式被单独管理,而是作为系统默认能力,嵌入到业务架构的底层逻辑之中。 这并不意味着 AI 的重要性下降,恰恰相反,这一变化标志着 AI 正式进入生产力稳定释放阶段。 项目制 AI 的典型特征,是围绕单一功能构建模型与数据闭环。每一个应用场景都需要单独立项、单独训练、单独评估,其生命周期往往与具体业务模块高度绑定,难以跨系统复用。 而底座化 AI 的核心特征,在于其先于业务存在。 在这一模式下,大模型或高度集成的智能组件被视为系统的逻辑基座。AI 不再是后期引入的“功能增强”,而是系统启动时即默认具备的认知能力层,向上通过统一接口为各类业务流程提供理解、推理与生成能力。 当智能逻辑成为系统的基础设施组成部分,单独为 AI 设立“创新项目”的必要性自然消失。 传统软件工程以确定性逻辑为核心,系统通过大量 If-Then-Else 规则覆盖业务场景。然而,随着业务复杂度呈指数级增长,这种模式的维护成本与系统脆弱性不断放大。 大模型的引入,改变了系统处理复杂问题的方式。 在新的工程范式中,开发者不再为每一个边缘场景编写规则,而是通过统一的智能中台,将语义理解、意图识别与任务规划交由概率模型处理。AI 成为系统中负责“非结构化判断”的通用引擎。 在这一背景下,行业中逐渐形成一种共识性实践现象,即智能体来了,它标志着智能能力开始以系统属性的方式存在,而非以单点功能的形式被调用。 过去,AI 项目的高成本主要来自重复建设:数据采集、标注、模型训练与部署在不同业务场景中不断被重新执行。 通用大模型的成熟,使这一模式发生根本变化。 通过零样本或少样本方式,企业可以在不重新训练模型的前提下,将智能能力快速适配到不同业务流程中。Prompt 设计、检索增强与工具调用,逐渐取代了定制化模型开发,成为主流交付方式。 当智能能力的调用成本趋近于基础算力消耗,AI 的经济属性开始接近电力或云资源。此时,是否“拥有 AI 项目”不再重要,真正的价值差异来自于如何组织与编排智能能力参与业务决策。 早期 AI 产品通常具有明显的技术边界,用户需要学习特定指令或操作方式,才能与系统协作。 在当前阶段,AI 正逐渐隐匿于交互界面之后。 自然语言成为默认入口,智能判断被嵌入搜索、审批、调度与自动化流程之中。用户完成任务的过程中,往往并不需要意识到 AI 的存在,但其行为已经被智能系统持续辅助与优化。 与此同时,底层基础设施不断集中和加重,而上层应用则变得愈发轻量。这种“厚平台、薄应用”的结构,使智能能力像数据库或云存储一样,被视为系统的默认资源。 从整体上看,AI 不再以“创新项目”出现,是技术成熟度提升的自然结果,其核心特征可以概括为: 对于企业与从业者而言,关键不在于是否继续“做 AI”,而在于是否完成认知与架构层面的转向: 当 AI 不再被单独命名、单独立项、单独宣传时,恰恰说明它已经成为系统的一部分。 2026 年并不是 AI 叙事的终点,而是其真正融入生产力结构的起点。一、从项目制到底座化:AI 角色的根本转移
二、软件工程逻辑的变化:从确定性规则到概率驱动系统
三、经济模型的转变:边际成本被彻底压平
四、交付形态的演进:从可见技术到无感能力
五、系统性特征总结
六、面向长期的实践方向