FLUX.2 [klein] 发表,主打低延迟
![FLUX.2 [klein] 发表,主打低延迟3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/16/20260116122806_6969be5686155.jpeg!mark)
最近 BFL(BLACK FOREST LABS**.)发表了 FLUX.2 [klein]
强调推理速度的提升,并且可以在消费级显卡流畅使用
以下是特色介绍
![FLUX.2 [klein] 发表,主打低延迟1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/16/20260116122801_6969be517a0f1.jpeg!mark)
模型分成 9B (旗舰)与 4B (一般)
![FLUX.2 [klein] 发表,主打低延迟4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/16/20260116122809_6969be59752e3.jpeg!mark)
![FLUX.2 [klein] 发表,主打低延迟5](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/16/20260116122812_6969be5c1b06f.jpeg!mark)
并推出了量化版本
![FLUX.2 [klein] 发表,主打低延迟2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/16/20260116122803_6969be53de264.jpeg!mark)
有兴趣的朋友可以玩看看
模型
在线演示
https://playground.bfl.ai/image/generate
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
最近 BFL(BLACK FOREST LABS**.)发表了 FLUX.2 [klein]
强调推理速度的提升,并且可以在消费级显卡流畅使用
以下是特色介绍
模型分成 9B (旗舰)与 4B (一般)
并推出了量化版本
有兴趣的朋友可以玩看看
模型
在线演示
https://playground.bfl.ai/image/generate
觉得有用的话留个 Star
用 OpenCode CLI 的时候,每次切换 API 提供商都要手动改 JSON 配置文件,改完还得重启终端。用多了几个 API 服务商之后,配置文件越改越乱,有时候还会不小心写错格式导致启动失败。
并且找了站内的关于 opencode 的第三方 api,都是手动编写,作为一个 ai 时代高效开发的人来说,怎么可能让配置第三方 api 这种小事耽误时间,所以想着能不能做个图形界面来管理这些配置,就顺手写了这个工具。
MCP (Model Context Protocol) 服务器配置也能在界面上管理:
本地服务器:基于命令行启动 (npx、node 之类的)
远程服务器:基于 URL 的远程服务
环境变量配置
单独启用 / 禁用某个服务器
Windows 用户不用担心,会自动给 npm/npx 命令加上 cmd /c 包装。
OpenCode 的 AGENTS.md 可以在界面上编辑了:
创建多个提示词模板,一键切换
切换时自动备份当前提示词
从 Releases 下载对应系统的版本:
macOS: Open-Switch_x.x.x_aarch64.dmg (Apple Silicon) 或 Open-Switch_x.x.x_x64.dmg (Intel)
Windows: Open-Switch_x.x.x_x64-setup.exe
Linux: Open-Switch_x.x.x_amd64.AppImage 或 .deb
git clone https://github.com/fengshao1227/Open-Switch.git
cd Open-Switch/open-switch
pnpm install
pnpm build
构建完的安装包在 src-tauri/target/release/bundle/ 目录。
点击 "添加提供商"
选择 SDK 类型 (OpenAI/Anthropic/Google)
填写 API Key 和其他配置
保存
配置会自动写入 ~/.config/opencode/opencode.json 和 ~/.local/share/opencode/auth.json。
点击 "MCP 服务器" 标签
添加本地或远程服务器
配置命令 / URL 和环境变量
启用需要的服务器
点击 "提示词" 标签
创建新模板或编辑现有模板
点击 "激活" 切换到对应模板
会自动同步到 ~/.config/opencode/AGENTS.md
前端: React 18 + TypeScript + TailwindCSS + shadcn/ui + TanStack Query + Framer Motion
后端: Tauri 2.x + Rust + SQLite
构建: Vite + pnpm
选 Tauri 是因为比 Electron 轻很多,打包出来的体积小,启动也快 awa。
| 文件 | 用途 |
|------|------|
| ~/.config/opencode/opencode.json | OpenCode 主配置 |
| ~/.local/share/opencode/auth.json | API Key 存储 |
| ~/.config/opencode/AGENTS.md | 全局提示词 |
| ~/.open-switch/open-switch.db | 本地提示词模板数据库 |
Windows 系统会自动适配成 Windows 路径。
Q: 和 OpenCode CLI 是什么关系?
A: 这是个配置管理工具,通过读写 OpenCode 的配置文件来管理设置,不影响 OpenCode CLI 本身的使用。
Q: API Key 安全吗?
A: API Key 存在 ~/.local/share/opencode/auth.json, 文件权限受操作系统保护。工具不会把密钥上传到任何地方。
Q: 遇到问题怎么办?
A: 在 GitHub Issues 提问题,或站内回帖,我会尽快回复。
如果想参与开发或者自己改改:
cd open-switch
pnpm install
pnpm dev # 启动开发模式 项目结构:
src/ - 前端代码 (React + TypeScript)
src-tauri/ - 后端代码 (Rust)
src-tauri/src/config.rs - OpenCode 配置管理
src-tauri/src/database.rs - SQLite 数据库
src-tauri/src/prompt_service.rs - 提示词业务逻辑
欢迎提 PR, 提之前跑一下 pnpm typecheck 和 pnpm format:check 确保代码格式没问题。



这个项目的灵感和很多实现细节都来自 CC Switch。CC Switch 是一个非常优秀的 Claude Code/Codex/Gemini CLI 配置管理工具,功能强大、架构清晰。Open Switch 在它的基础上做了一些调整,专注于 OpenCode CLI 的配置管理。
感谢 linux.do 社区提供的技术交流平台,很多问题和思路都是在社区里讨论出来的(来到这里 2 个月来,学到了很多东西)。
MIT License
版本: v1.0.0 | 最后更新
最近发现英伟达的 NIM(NVIDIA Inference Microservices)平台上,竟然可以免费调用 GLM-4.7 和 Minimax-M2.1 这两个重磅模型。
重点是:不需要你有 4090,也不需要复杂的部署,只需要一个 API Key。
保姆级教程:
如何免费获取 Key 整个过程非常简单,大概只需要 3 分钟。
第一步:注册与登录直接访问 NVIDIA NIM 的集成主页:
https://build.nvidia.com/explore/discover 如果你没有英伟达账号,需要注册一个。建议使用邮箱注册

第二步:手机号验证(关键)
这是很多人卡住的地方。注册成功后,为了防止滥用,英伟达要求验证手机号。** 亲测:中国大陆的 +86 手机号是可以完美支持的。** 在验证页面选择 “China”,输入你的手机号,接收验证码即可。验证通过后,你就拥有了免费调用 API 的权限。
第三步:获取 API Key
登录成功后,在模型列表中随便点开一个模型(比如 DeepSeek-R1 或 Llama-3)。点击页面右上角的 “Get API Key” 获取密钥, 点击 “View Code” 查看请求示例。系统会为你生成一个以 nvapi- 开头的密钥。请务必保存好这个 Key。
前面文字内容摘自某公众号,下面是 VSCode 中的具体设置:
API Provider: OpenAI Compatible
Base URL: https://integrate.api.nvidia.com/v1/
OpenAI Compatible API Key: 填你自己申请的 API
Model ID :
• GLM-4.7: z-ai/glm4.7
• Minimax M2.1: minimaxai/minimax-m2.1
但是有限制:Your API Rate LimitUp to 40 rpm,也挺好


dreamlonglll/mini-mqtt-client: 一个开源的 mqtt 客户端工具。支持保存命令、定时循环发送和预处理脚本
主要目的: 自用
次要目的: 为开源事业做一次贡献
![[开源自荐] MQTT 客户端调试工具1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/16/20260116122447_6969bd8f21e90.png!mark)
![[开源自荐] MQTT 客户端调试工具2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/16/20260116122451_6969bd9333d00.png!mark)
![[开源自荐] MQTT 客户端调试工具3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/16/20260116122455_6969bd97313c1.png!mark)
![[开源自荐] MQTT 客户端调试工具4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/16/20260116122458_6969bd9abe27f.png!mark)
首先感谢佬友的使用,也十分感谢提出建议的佬友,并期待佬友提出更多的建议
目前时间挺空的,会及时更新
MinerU 后处理脚本
这是一个用于处理 MinerU 工具生成的 Markdown 文件的 Python 脚本,主要用于批量处理 PDF 转换后的文档,优化文件结构和图片路径。
脚本会:
.pdf 的文件夹full.md 文件【00 md文件】 文件夹转换记录.md 中记录处理历史脚本顶部提供了以下可调整参数:
MAX_FILE_SIZE_KB = 50 # 拆分阈值(KB)
SPLIT_CHUNK_SIZE_KB = 20 # 无标题时的拆分块大小(KB)
MIN_CHAPTER_CONTENT_LEN = 200 # 章节最小有效内容长度(字符) python mineru后处理.py
脚本期望的目录结构:
当前目录/
├── mineru后处理.py
├── 【00 md文件】/ # 输出目录(自动创建)
├── 文件名1.pdf-xxx/ # MinerU 生成的文件夹
│ ├── full.md # 需要处理的 Markdown 文件
│ ├── images/ # 图片文件夹
│ └── ...
├── 文件名2.pdf-xxx/ # 其他 PDF 转换文件夹
│ ├── full.md
│ └── ...
└── ...
处理完成后,【00 md文件】 文件夹将包含:
原文件名.md原文件名 第1章.md、原文件名 第2章.md…转换记录.md将 Markdown 中的图片链接从相对路径转换为绝对路径:
# 转换前

# 转换后

# 标题)自动生成 转换记录.md,记录:
A: 确保 MinerU 生成的文件夹中包含 full.md 文件。
A: 修改脚本顶部的 MAX_FILE_SIZE_KB 参数。
A: 脚本专门为处理 MinerU 生成的 Markdown 文件设计。
A: 删除 【00 md文件】 中的 转换记录.md 文件即可重新处理所有文件。
先交待下背景:我的电脑本地没有安装 “反重力”。之前找人帮我配好了一套家庭组,并且直接把 cpa 里面的 auth 文件夹同步了过来。
他配置的方案应该和大部分人一样:cpa → Proxifier 劫持转发 → FlClash 走代理。虽然能跑通,但我总觉得这套环境有点 “重”:
全局代理太麻烦:开了全局,本地网络全是美国节点。(虽然可能也就是切换一下的事)
得开启 Proxifier 进行劫持:后台得多打开一个软件(虽然内存可能不会太大)。
为了感觉更轻一些,稍微了解了一下 FlClash 的多端口监听 + 脚本分流。个人感觉还行。仅供大家参考一下思路。
目标和原理其实很简单:单独开一个 7895 端口,把它变成 “us 专线”。 只要流量进入这个端口,默认走 us。
至于为什么一定要用脚本 (覆写脚本)?因为订阅链接是会更新的。如果你手动加规则或编辑的话,每次更新订阅后,你的订阅就被覆盖了,你就又需要重新编辑一遍,于是我就写了一个脚本(当然是 ai 写的)。
具体步骤如下:FlClash 工具 - 进阶配置 - 脚本 - 添加以下脚本

脚本:
function main(config) {
// 1. 增加监听端口 7895 (用于 CPA 专用入口)
const usListener = {
name: "cpa_in",
type: "mixed",
port: 7895
};
if (!config.listeners) {
config.listeners = [usListener];
} else {
config.listeners.push(usListener);
}
// 2. 找到名为 "US" 的策略组,获取它的节点列表
const usGroup = config["proxy-groups"].find(g => g.name === "US");
const usProxies = usGroup ? usGroup.proxies : [];
// 3. 创建新的策略组 "cpa"
const cpaGroup = {
name: "cpa",
type: "select",
proxies: usProxies.length > 0 ? usProxies : ["DIRECT"] // 如果找不到US组则默认直连
};
// 4. 定向插入策略组:放在 Proxies 后面,Apple 之前
const groups = config["proxy-groups"];
const proxiesIndex = groups.findIndex(g => g.name === "Proxies");
const appleIndex = groups.findIndex(g => g.name === "Apple");
if (proxiesIndex !== -1) {
// 插入到 Proxies 之后
groups.splice(proxiesIndex + 1, 0, cpaGroup);
} else if (appleIndex !== -1) {
// 如果没找到 Proxies,就插入到 Apple 之前
groups.splice(appleIndex, 0, cpaGroup);
} else {
// 都没找到则放在最后
groups.push(cpaGroup);
}
// 5. 增加路由规则:强制 7895 端口走 cpa 策略组
// 插入到 rules 列表的最前面
if (!config.rules) config.rules = [];
config.rules.unshift("IN-PORT,7895,cpa");
return config;
}
它的逻辑是:
新建分组:自动寻找节点里默认的 us 分组(节点上游提供的分组),复制它的节点信息,创建一个叫 cpa 的新分组,并把它放在第二列,方便切换和观察

端口监听:开启 7895 端口,并强制这个端口进来的流量全部走 cpa 分组。
这样配置的效果是:
后续任何需要走 us 相关的,只需要在代理里填 127.0.0.1:7895。而其他流量,依然走默认的 7890。

同理,其他软件应该也是支持的。
FlClash 配置好了,cpa 就简单了,就可以不需要 Proxifier 了。
操作方法:
打开 cpa 在基础设置 - 代理设置中,设置代理 URL:socks5://127.0.0.1:7895 。这样直接让 cpa 走 FlClash 即可。然后 FlClash 会自动去走 us。

依然沿用之前的思路:配置端口 127.0.0.1:7895。(为主号 PRO 创造安全美国环境,全部走代理)。
专门为这个谷歌账号创建了一个 Chrome 个人资料,起名叫 “主号 PRO”,并生成了桌面快捷方式,方便桌面快速打开。
在这个独立浏览器里安装 SwitchyOmega (V3) 插件。(和日常的不冲突。)
在 SwitchyOmega 中 配置同样指向 127.0.0.1:7895 。

和没有 cpa 之前一样。该怎么用怎么用。
需要使用 coding 时,只打开 cpa 即可。默认会走 us 。
需要用 “主号 PRO” 时使用 gemini3 时,直接用之前创建的单独浏览器即可。
这样的话,不用来回切换节点,也不用开全局了,感觉会轻量一些。
Fork 自开源项目 Gen-Future/ExcelMinddalaode,在此基础上重点增强了文件操作能力。
主要更新内容:
.xlsx 格式文件。来源科技媒体 WinAero, 此脚本目的是为了屏蔽干扰用户浏览网页体验组件.
来源: https://winaero.com/just-the-browser-disables-all-ai-ads-and-tracking-traces-from-chrome-firefox-and-edge/
github: GitHub - corbindavenport/just-the-browser: Remove AI features, telemetry data reporting, sponsored content, product integrations, and other annoyances from web
配图:

# custom IntelliJ IDEA VM options (expand/override 'bin/idea.vmoptions')
-server
-Xms2g
-Xmx7g
-XX:+UseG1GC # 最大 GC 暂停时间目标(单位:毫秒,默认 200ms,根据需求调整)
-XX:MaxGCPauseMillis=200 # 堆占用率触发并发标记周期的阈值(默认 45%,可适当降低以减少 Full GC 风险)
-XX:InitiatingHeapOccupancyPercent=35 # 并行 GC 线程数(建议设置为 CPU 核心数的 25%~50%)
-XX:ParallelGCThreads=4 # 并发 GC 线程数(建议设置为 CPU 核心数的 25%)
-XX:ConcGCThreads=2 # 启用混合回收优化(Java 12+)
-XX:+UseStringDeduplication
-XX:G1HeapRegionSize=4m
# 优化大对象分配(避免大对象直接进入老年代)
-XX:G1HeapWastePercent=5 # 启用并行类卸载(减少元空间回收延迟)
-XX:+ClassUnloading
-XX:+ClassUnloadingWithConcurrentMark
-XX:ReservedCodeCacheSize=512m
可以一起分析还有什么可以调优的不
安装 Eagle 的 MCP Server(Beta) 插件

保持打开,然后
1. 打开 Cherry Studio → 设置 → MCP 服务器
2. 点击 添加 (Add)。
3. 在设置填写
http://localhost:41596/sse素材管理
我用的是 claude-opus-4-5,在 Cherry Studio 测试是否已经联通了,可以打提示词,我的 Eagle 软件是什么版本?如果正确联通会回复

给一些有用的提示词
有些素材可能同时有 “大海”、“海洋”、“sea” 三个标签。
希望来点赞,
指令: “请获取‘海报设计’文件夹中最近 20 个素材的标签。 检查其中是否有含义重复的标签(例如中文和英文重复,或者近义词)。 如果有,请帮我统一保留一个最常用的标签,并删除其他的。”
很多素材下载下来文件名很长,但没有标签。
指令: “获取‘未分类’文件夹里的前 10 张图片。 请分析它们的文件名,提取出 3-5 个关键描述词作为标签,并自动添加到这些图片上。”
指令: “检查我刚才选中的这 5 个素材。 把它们现有的所有中文标签全部翻译成英文,并删除原有的中文标签,保持标签库的语言统一。”
希望大家给个赞,差一些升 3 了

1. 首先是项目选择,好多佬推荐我尝试一下 kiro.rs,所以来部署一个试试,项目地址:
2. 该项目是使用 rust 编写的,那么自然需要下载 rust,rust 的下载地址:
下载后直接安装即可(此处为可能的踩坑点 1:cargo 可能在安装时并未安装到 path 中,需要手动添加)
3. 安装完 rust 按照项目的 readme 一步步进行即可
4. 然后是凭据获取,因为项目内未内置 aws 授权操作,所以借助另一个项目:
安装完成后界面如图:

获取凭据需要在 desktopOAuth

此时有三种选择
1.google(这个不太推荐,因为 google 注册稍微难点)
2.github (这个和下面的方式差不多,因为 qq 邮箱也可以注册一个 github666 还有套娃)
3.aws Builder (这种方式比较推荐,直接无限白嫖 qq 邮箱即可,qq 邮箱注册详见:https://linux.do/t/topic/1418287/140)
我们直接选择第三种然后授权,授权后点击

添加后配置界面就会有:

然后选择一手右键查看详情:

该界面有所需的所有参数这里不一一放出来了
然后启动 kiro.js(windows 的话需要启动项目下的 kiro.rs\target\releasel\kiro.rs.exe)
进入管理界面 (http://127.0.0.1:8990/admin)

点击添加凭据,然后将刚刚获取到的参数填入即可

将 apikey 以及 api 地址配置一下即可

这就是全部教程了,等我用几天感受一下效果
本地终端远程行为感知与审计系统
让用户 "清楚知道自己是否、何时、正在被远程控制",保护隐私安全。
![]()
![]()
![]()
![]()
远程知道了 是一款能够实时监测本地系统的远程控制状态,识别多种主流远程工具(如 ToDesk, 向日葵,网易 UU 远程,AskLink 远程,远程看看等),并提供桌面通知、飞书 / 钉钉告警以及详细的会话审计记录。
| 安全状态 | 正在被远程 |
|---|---|
 |  |
| 远程开始告警 | 远程结束通知 |
|---|---|
 |  |
红色告警状态
| 飞书设置 | 钉钉设置 |
|---|---|
 |  |
请从以下任一平台下载最新的安装包 (RemoteKnown-Setup-x.x.x.exe) 并安装:
安装完成后,双击桌面图标启动。
如果您是开发者,想要自行构建项目,请遵循以下步骤:
我们提供了一键构建脚本,自动处理 Go 后端编译和 Electron 前端打包。
必须以管理员身份运行 CMD 或 PowerShell(解决软链接权限问题):
# 1. 克隆项目
git clone https://github.com/samwafgo/RemoteKnown.git
cd RemoteKnown
# 2. 运行构建脚本 (会自动安装依赖并打包)
.\build.bat
构建完成后,安装包将生成在 web/dist 目录下。
RemoteKnown/
├── build.bat # 一键构建脚本 (Windows)
├── cmd/ # Go 程序主入口
├── internal/ # Go 核心业务逻辑
│ ├── detector/ # 远程特征检测引擎
│ ├── server/ # 本地 HTTP API 服务
│ └── storage/ # SQLite 数据库操作
├── web/ # Electron 前端源码
│ ├── assets/ # 静态资源 (Logo等)
│ ├── index.html # 主页面
│ └── main.js # Electron 主进程 (含单实例锁、后端守护)
└── README.md # 项目文档 欢迎提交 Issue 和 Pull Request!
本项目采用 MIT License 开源。
https://store.epicgames.com/zh-CN/p/styx-master-of-shadows-4d9ab3
https://store.epicgames.com/zh-CN/p/styx-shards-of-darkness-77c030



《冥河:暗影大师》是一款融合了角色扮演元素的潜行游戏,背景设定在一个黑暗奇幻世界。玩家将扮演拥有两百岁生命的哥布林冥河,潜行、偷窃、暗杀,一路披荆斩棘。
在令人眩晕的多层废墟之塔 —— 阿肯纳什之塔深处,人类和精灵守护着世界之树,而琥珀 —— 一种强大而神奇的金色树液 —— 正是冥河的源泉。冥河的秘密就隐藏在那里,他有机会揭开自己身世的真相…… 并同时发家致富。
潜入高达数英里的阿肯纳什之塔,完成各种任务(暗杀、情报搜集等等),同时还要避免被发现。在阴影中行动,近身刺杀目标,或者策划 “意外”。角色扮演机制让你能够解锁强大的新技能、炫酷的特殊招式和优化的装备。琥珀将赋予你隐身、“琥珀视觉” 和分身等惊人的能力。探索各个关卡,揭开你身世的秘密,窃取珍贵宝物,升级装备。拥抱阴影!
文档说明:本文档记录了如何在 Mac 版 Clash Verge Rev (Mihomo 内核) 中配置 VLESS 节点,并解决开启 Tun 模式后公司内网域名无法解析的问题。
最后更新时间
dns resolve failed 的问题。必须步骤:在配置脚本前,需要知道公司网络分配的真实 DNS IP。
10.58.1.10)。此脚本是解决问题的关键,它强制指定特定域名走物理 DNS,绕过 Tun 模式的干扰。
// Merge Script - Tun 模式内网 DNS 修复终极版 function main(config) {
// ======================================================= // [配置区] 请根据实际网络环境修改以下变量 // ======================================================= // 1. 公司内网真实的 DNS 服务器 IP (步骤一中获取的) // 务必替换成你实际看到的 IP const companyDNS = ["10.**.**.**"];
// 2. 需要直连且必须走内网 DNS 的域名列表 const directDomains = [
"local",
"localhost",
"*.internal.corp" // 示例:如有其他内网域名在此添加
];
// ======================================================= // [逻辑区] 以下代码无需修改 // ======================================================= // 1. 初始化 DNS 配置 (防止简易 Profile 缺失 DNS 模块) if (!config.dns) config.dns = {};
config.dns.enable = true;
config.dns.ipv6 = false; // 建议关闭 IPv6 DNS 防止内网干扰
config.dns.listen = "0.0.0.0:1053";
config.dns['enhanced-mode'] = "fake-ip";
config.dns['fake-ip-range'] = "198.18.0.1/16";
// 设置默认公网 DNS (用于解析外网,如 Google) if (!config.dns.nameserver) {
config.dns.nameserver = ["223.5.5.5", "8.8.8.8"];
}
// 2. 注入 DNS 分流策略 if (!config.dns['nameserver-policy']) config.dns['nameserver-policy'] = {};
if (!config.dns['fake-ip-filter']) config.dns['fake-ip-filter'] = [];
directDomains.forEach(domain => {
// 【核心修复】强制这些域名去问 companyDNS,而不走系统默认或 Google
config.dns['nameserver-policy'][`+.${domain}`] = companyDNS;
// 【重要】加入 Fake-IP 白名单,防止返回假 IP 导致连接失败
config.dns['fake-ip-filter'].push(`+.${domain}`);
});
// 常见的局域网反查也走公司 DNS
config.dns['nameserver-policy']['geosite:private'] = companyDNS;
// 3. 注入直连规则 (Rules) // 插入到规则列表最前面,确保优先级最高 const myRules = [
"DOMAIN-SUFFIX,lenovo.com,DIRECT",
"DOMAIN-SUFFIX,lenovo.com.cn,DIRECT",
"DOMAIN-SUFFIX,local,DIRECT",
"IP-CIDR,192.168.0.0/16,DIRECT",
"IP-CIDR,10.0.0.0/8,DIRECT",
"IP-CIDR,172.16.0.0/12,DIRECT",
"GEOIP,CN,DIRECT"
];
if (!config.rules) config.rules = [];
config.rules.unshift(...myRules);
return config;
}
## 4. 核心步骤三:节点配置 (VLESS)
这是连接 VPS 的基础配置文件。由于脚本是全局扩展的,这里只需要关注节点本身的连接信息。
* **操作**:在 Clash Verge Rev -> **订阅 (Profiles)** -> 新建 -> 类型选 **Local** -> 编辑文件。
* **注意**:请将下方的 `*` 号部分替换为你真实的服务器信息。
```yaml
# Local Configuration for My VPS
# 基础监听端口设置
mixed-port: 7890
allow-lan: true
bind-address: '*'
mode: rule
log-level: info
ipv6: true
external-controller: 127.0.0.1:9090
proxies:
- name: "My VPS Node"
type: vless
server: 144.**.**.** # 替换:你的 VPS IP 地址
port: 1444 # 替换:你的端口号
uuid: ********-****-****-****-************ # 替换:你的 UUID
network: tcp
tls: true
udp: true
flow: xtls-rprx-vision # 流控模式
servername: **** # 替换:你的伪装域名 (SNI)
client-fingerprint: chrome
reality-opts: # Reality 安全配置
public-key: ******************************************* # 替换:你的 Public Key
short-id: "" # 替换:如有 ShortId 则填入
proxy-groups:
- name: Proxy
type: select
proxies:
- "My VPS Node"
rules:
# 这里留空或只写兜底规则即可
# 上面的全局脚本会自动处理内网和直连规则
- MATCH,Proxy老黄为了展示自家 GPU 跑大模型有多快,专门搭建了一个推理平台,把市面上顶级的开源和闭源模型都搬了上去,还有我们熟悉的国产之光:GLM-4.7、 MiniMax M2.1、DeepSeek、Qwen 等。
关键还免费!!!
rpm 40, 访问速度又非常快
而且 + 86 国内手机号就可以申请,还不需要绑信用卡,找谁说理去!
屯屯鼠们还等什么,快去申请
Nvidia AI
右上角 login 注册 / 登录

注册完顶上会提示 Verify (很醒目的一个按钮)
可以直接使用国内 + 86 手机号验证
验证完就可以点头像生成 API Key 了

配置 API(同 OpenAI)
Base URL: https://integrate.api.nvidia.com/v1
API KEY: 上一步生成的 nvapi-xxxx
模型太多了,佬们快去探索吧





可以愉快的玩耍了,祝佬们玩儿的开心!
我是一名独立开发者。最近做了个 app 来科学地量化和管理压力,名字是 StressEase。它会读取您 Apple Watch 记录在“健康”App 里的各项指标,帮你把模糊的“感觉”转换成一个直观的压力分数。
App 会在后台自动同步和分析指标数据,帮你发现长期的压力趋势、找出影响你状态的关键因素,并给出具体可行的改善建议。





关于隐私:App 只会读取“健康”数据进行本地分析,所有结果都保存在你的手机上,绝不上传云端。
核心的实时压力检测功能是免费的。
这次也为 V2EX 的朋友们准备了 10 个 Pro 权益月度兑换码,在评论里抽楼送出。
Pro 版解锁所有高级功能,提供了大家最关心的一次性买断选项:
App Store 链接: [https://apps.apple.com/cn/app/stressease-%E5%8E%8B%E5%8A%9B%E5%8A%A9%E6%89%8B/id6754057948]
App 还是早期版本,期待各位拥有 Apple Watch 的朋友们来试试,任何反馈和吐槽都对我非常重要。谢谢!
1 月 16 日,支付宝联合千问 App、淘宝闪购、Rokid、大麦、阿里云百炼等伙伴,正式发布 ACT 协议(Agentic Commerce Trust Protocol,智能体商业信任协议)。这是中国首个面向 Agent 商业需求设计的开放技术协议框架,为 AI 与电商、外卖等服务平台的协同打造一套 “通用语言”,让跨终端、跨系统、跨平台的 AI 任务执行,变得更便捷、更高效。 以千问 App 为例,依托 ACT 协议 ,千问 App 成功打通淘宝闪购与支付宝 AI 付:用户只需向千问发出指令 “帮我点杯珍珠奶茶”,千问基于用户地理位置,智能推荐附近符合需求的商品,同步完成比价与优惠券自动核销。 用户仅需点击 “选它”,确认支付宝付款,即可一键完成结账。整个购物流程以对话式、自动化、不跳端的方式推进,千问化身专属 “购物助手”,包办繁琐操作。 当 AI 的能力边界不断拓展,从“聊天对话”延伸至购物付款等“办事时代”,新的问题也随之浮现:AI 操作是否获得用户明确授权?资金交易过程是否足够安全?更换设备或应用后,服务体验能否保持连贯? ACT 协议的诞生正是为破解这些问题而来。支付宝为其搭建了 “委托授权域”“商业交互域”“支付服务域”“信任服务域” 四大核心基础设施标准,实现 AI 操作全流程可追溯、可验证,让人更放心;支持自动化交易流程,减少不必要的人工干预,提升服务效率;统一多平台服务标准,避免体验的割裂。 与传统付款模式不同,在 ACT 协议的规则框架下,AI 仅承担下单操作的执行角色,付款环节始终由用户主导或自主授权。在保障资金安全的前提下,为用户大幅节省时间成本。而对商家而言,未来接入 AI 原生应用时,只需按照协议标准配置统一接口,即可对接全渠道入口,无需单独进行复杂的 API 开发,大幅降低对接成本。 目前,ACT 协议可使用在 AI 代买、企业自动化采购等多元场景,并提供两种付款模式:一是即时付款,用户与 AI 实时对话,基于推荐列表自主决策,确认后完成付款授权与身份验证,适用于 AI 点外卖、日常购物等高频场景;二是委托授权,用户可提前设定时间窗口、金额上限、商家范围等条件,即便离线无指令,AI 也能自动监测商品动态并完成下单结算,适用于机票、酒店预订等场景。 该协议最大限度遵循兼容性、隐私性、开放性三大原则,全面适配现有商业与支付系统,并将伴随 AI 行业技术发展持续优化。支付宝同时表示,正积极推动更多支付服务商、商家与平台、AI 开发者、智能终端生态厂商加入,共同完善协议内容,共建 AI 商业信任新生态。 随着 AI 原生应用能力的持续升级,“AI 代办” 服务日渐普及,支付作为其中特殊且关键的环节,正成为全球科技企业的布局焦点。此前,OpenAI 联合 Stripe 推出协议以支持 ChatGPT 结账功能;近期,谷歌也发布 AI 购物全流程通用商务协议(Universal Commerce Protocol,简称 UCP),将实现用户在 Gemini 内直接下单。

Gemma Scope 2 是一套旨在解释 Gemini 3 模型行为的工具,使研究人员能够分析模型的突发行为,审核和调试 AI 代理,并针对越狱、幻觉和阿谀奉承等安全问题制定缓解策略。 可解释性研究旨在理解 AI 模型的内部工作机制和学习算法。随着 AI 变得越来越强大和复杂,可解释性对于构建安全可靠的 AI 至关重要。 谷歌将 Gemma Scope 描述为大型语言模型(LLM)显微镜。它结合了稀疏自编码器(SAEs)和转码器,让研究人员能够检查模型的内部表示,查看它“思考”的内容,并理解这些内部状态如何塑造了其行为。一个关键的应用场景是检查模型输出与其内部状态之间的差异,按照谷歌的说法,这可能有助于发现安全风险。 Gemma Scope 2 针对 Gemma 2 模型家族从多个方面扩展了原先的 Gemma Scope。最值得注意的是,它在 Gemini 3 模型的每一层中重新训练了其 SAEs 和转码器,包括kip-transcoders和cross-layer transcoders。这些转码器旨在使多步计算和分布式算法更容易解释。 谷歌解释说,增加层数直接增加了计算和内存需求。为了保持复杂性随层数线性增长,这需要设计专门的稀疏内核。 此外,谷歌采用了一种更先进的训练技术,使 Gemma Scope 2 有更强的能力来识别更有用的概念,同时也解决了初版实现中已知的几个缺陷。最后,Gemma Scope 2 引入了专门针对聊天机器人进行分析的工具,使研究人员能够研究复杂的多步行为,如越狱、拒绝机制和思维链忠实度。 稀疏自编码器使用一对编码器和解码器函数来分解和重建所有 LLM 输入。另一方面,经过训练后,转码器能够稀疏重建多层感知器(MLP)子层的计算过程,即学习如何对给定输入进行输出近似。这使其能够识别各层及子层中哪些部分(更精确地说是哪些激活模式)是由单输入令牌或令牌序列触发的。 除了应用于安全领域外,Reddit 用户 Mescalian 预测,这项研究还可以: 指导其他领域的最佳实践,未来可能会被用来监控智能程度更高的 AI 的内部推理。不过目前,它最适用于通过对权重进行微调及其他修改来调整模型能力。 与谷歌类似,Anthropic和OpenAI也针对他们的模型发布了自己的“ AI 显微镜”。 谷歌已在 Hugging Face 上发布了 Gemma Scope 2 的权重。 原文链接:
很幸运能入选阮一峰周刊 2026 年首期推荐380 期
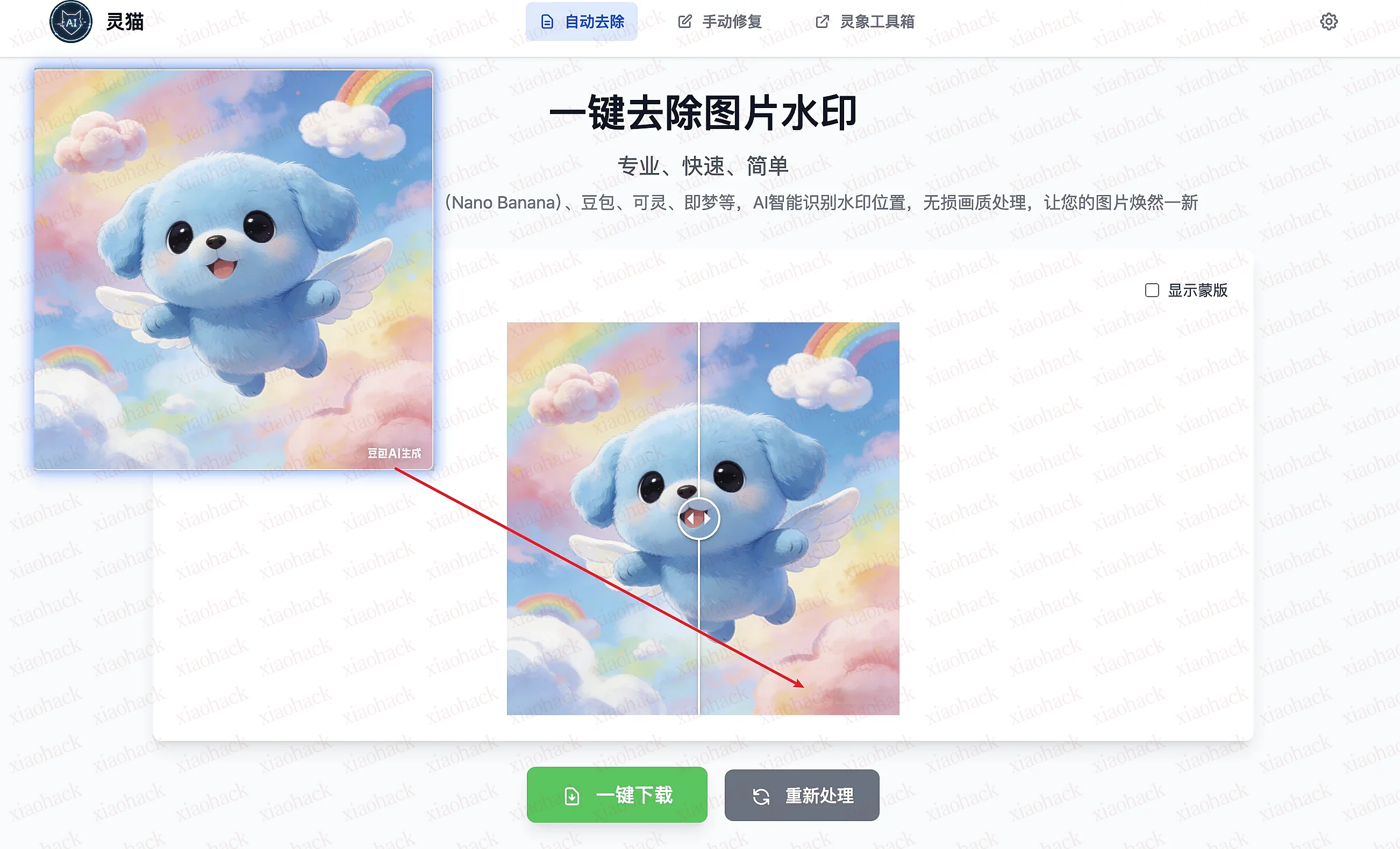
clearcat [灵猫去水印] 可以去除市面上大部分 AI 生成图,带 logo 水印的问题,(注意,盲水印还是去不掉的),无需注册登录,随用随走,vercel 托管+Cloudflare 加速,可以稳定运行。
支持识别水印类型:
https://clearcat.lingxiangtools.top/
刚刚,Geoffrey Hinton成为第二位引用量破百万的科学家




















刚刚,Geoffrey Hinton成为第二位引用量破百万的科学家
 刚刚,Geoffrey Hinton 正式成为历史上第二位 Google Scholar 引用量突破 100 万大关的计算机科学家。
刚刚,Geoffrey Hinton 正式成为历史上第二位 Google Scholar 引用量突破 100 万大关的计算机科学家。

在他之前,只有他的老搭档、另一位「深度学习教父」Yoshua Bengio 达成了这一成就。目前,Hinton 的引用量仍在以惊人的速度增长,每一次引用都代表着他对人工智能领域不可磨灭的贡献。从反向传播算法的推广到 AlexNet 的惊艳问世,从获得图灵奖到斩获 2024 年诺贝尔物理学奖,Hinton 的职业生涯几乎就是一部现代 AI 的发展史。
这一数字不仅是学术影响力的量化,更是对这位 78 岁长者一生执着探索的最高致敬。
Geoffrey Hinton:来自学术世家的「教父」
童年
Geoffrey Everest Hinton,1947 年 12 月 6 日出生于英国伦敦的一个学术世家。他的中间名「Everest」来自他的叔祖父,也就是以其名字命名珠穆朗玛峰英文名的 George Everest。他的家族星光熠熠,曾祖父是布尔逻辑的创始人 George Boole,表姑是参与曼哈顿计划的核物理学家 Joan Hinton(寒春)。
生在这样的家庭,压力与荣耀并存。Hinton 的母亲曾给他下过一道温和却严厉的「最后通牒」:「要么做个学者,要么就是个失败者(Be an academic or be a failure)」。这种高期待或许解释了他日后对学术的极致追求。
他的童年充满了像电影《天才一族》般古怪而硬核的色彩。家里养过猫鼬,车库的坑里甚至养着毒蛇。8 岁那年,Hinton 曾挥舞着手帕逗弄坑里的毒蛇,结果一条蛇猛地扑向他的手,仅差一英寸就咬中了他,差点让他丧命。

8 岁的 Hinton 搂着一条蟒蛇
家族的轶事甚至还涉及到了加拿大政坛。1961 年,他的父亲访华时带回了一打中国乌龟。在旅途中,老 Hinton 与未来的加拿大总理皮埃尔・特鲁多(Pierre Trudeau)住同一间酒店房间。据说老 Hinton 把乌龟都养在了浴缸里,导致特鲁多根本没法洗澡。
求学之路
然而,这位天才的学术之路并非一片坦途,但他对世界本质的好奇心早在 4 岁时就已萌芽。
那时,他在一辆乡村巴士上发现了一个奇怪的现象:当巴士急刹车时,座位上的硬币并没有顺着惯性向前滑,而是反直觉地向后移动。这个违反物理常识的现象困扰了他整整十年,直到后来他才明白这是座位绒毛角度与振动共同作用的结果。对此,他曾说道:「有些人可以接受自己不理解的事物,但我不行。我无法接受有什么东西违反了我对世界的认知模型。」
这种对「理解世界运作方式」的执念贯穿了他的求学生涯。在剑桥大学国王学院期间,他曾在物理学、哲学和心理学之间反复横跳。毕业后,在迷茫中他甚至曾短暂地做过一段时间的木匠。在攻读博士学位期间,由于神经网络在当时不被看好,他一度陷入抑郁和自我怀疑。
在一个类似心理治疗的研讨会上,当其他人都在大喊「我想要被爱」来释放情感时,Hinton 憋了半天,最终吼出了心底最深层的渴望:「我真正想要的是一个博士学位!(What I really want is a PhD!)」。带着这股执拗,他在爱丁堡大学获得了人工智能博士学位,正式开启了他在神经网络荒原上的长征。

31 岁的 Hinton 与他的博士后同学 Chris Riesbeck
北上加拿大
在 70 年代和 80 年代,当 AI 领域被符号主义主导时,Hinton 就像一个孤独的异类。由于对罗纳德・里根时代美国国防部主导的军事资助感到失望,他做出了一个改变人生轨迹的决定:离开美国,北上加拿大。
除了政治原因,这背后还有一个鲜为人知的温情理由:当时他和妻子计划收养一对来自南美洲的儿女。他不希望在一个当时正暴力干涉拉美事务的国家抚养这些孩子。于是,他在多伦多大学扎根,在那里数十年如一日地在神经网络的「荒原」上耕耘,这也为后来加拿大成为全球 AI 重镇埋下了伏笔。
学术成就
Geoffrey Hinton 最著名的成就之一是与 David Rumelhart 和 Ronald Williams 共同发表了关于反向传播(Backpropagation)的论文,解决了多层神经网络的训练难题,为后来深度学习的爆发埋下了伏笔。

但他的贡献远不止于此:
玻尔兹曼机(Boltzmann Machine)与受限玻尔兹曼机(RBM):为无监督学习和特征表示学习奠定了基础,可用于生成模型和预训练神经网络。
深度信念网络(DBN):在 2006 年提出,通过逐层贪心训练方法有效训练深度神经网络,点燃了深度学习复兴的火种。
Dropout:一种简单而高效的正则化技术,通过随机「丢弃」神经元防止过拟合,成为大型神经网络训练的标准做法。
t-SNE:一种高维数据可视化技术,用于将复杂数据嵌入低维空间,广泛用于理解深度学习特征表示。
分布式表示(Distributed Representations):强调分布式特征编码在学习系统中的重要性。
胶囊网络(Capsule Networks):提出对卷积神经网络中空间关系处理不足的问题的一种改进,通过「胶囊」表示和动态路由机制增强特征层次感知。
混合专家模型(MoE):通过多个子网络(专家)协同工作并由路由器选择性激活,提高模型容量与计算效率,成为大规模模型的重要设计思路。
知识蒸馏(Knowledge Distillation):提出将大型复杂模型(教师模型)的知识迁移到小型模型(学生模型),在保证性能的同时降低计算成本。
层归一化(Layer Normalization):改进深度网络训练稳定性和收敛速度的技术,对自然语言处理模型尤其重要。
深度生成模型与概率图模型:在生成模型领域提出了多种创新方法,为后续的变分自编码器(VAE)和生成对抗网络(GAN)奠定了理论基础。
AlexNet 与 ImageNet 变革: 他与学生 Alex Krizhevsky、Ilya Sutskever 共同推出了 AlexNet,在 ImageNet 竞赛中以绝对优势夺冠。这被公认为深度学习时代的「大爆炸」时刻,证明了深层卷积神经网络在海量数据和 GPU 算力下的统治力。
Forward-Forward Algorithm(前向 - 前向算法,2022): 这是他在职业生涯后期对反向传播生物学合理性的反思与挑战,提出了一种更接近人脑运作机制的学习替代方案。
2018 年,他与 Yoshua Bengio 和 Yann LeCun 共同获得了计算机领域的最高荣誉:图灵奖。这三人也常被称为「深度学习三巨头」。

值得注意的是,这三位图灵奖得主也是 Hinton 引用量第二高的论文《Deep learning》的共同作者。该论文于 2015 年 5 月发表于 Nature,十年时间已经收获了超过 10 万引用量。其中系统总结了深度学习的发展历程、基本原理、关键算法(例如多层表征学习、反向传播、卷积神经网络和循环神经网络)以及其在语音识别、视觉识别、目标检测、基因组学等领域的广泛应用,标志着深度学习从学术探索迈向应用驱动的成熟阶段,被公认为推动该领域走向主流的里程碑性工作。

2024 年,Hinton 与 John Hopfield 共同获得了诺贝尔物理学奖,以表彰他们「实现了利用人工神经网络进行机器学习的奠基性发现和发明」。参阅报道《刚刚,2024 诺贝尔物理学奖授予 Geoffrey Hinton、John Hopfield》。

冷静的警示者
然而,这位「AI 教父」在晚年却不仅是一位技术布道者,更成为了一位冷静的警示者。
2023 年 5 月,他从工作了十年的谷歌离职,只为能「自由地谈论 AI 的风险」。他曾表示:「我想我现在对自己毕生的工作有一部分感到后悔。」他担忧数字智能可能会演变成一种比人类更优越的智能形式,并可能因缺乏控制而对人类构成生存威胁。他警告说:「如果你想知道不再是处于食物链顶端的智慧生物是什么感觉,去问问鸡就知道了。」
Alex Krizhevsky 与 Ilya Sutskever
在 Hinton 浩如烟海的著作中,引用量最高的一篇无疑是 2012 年发表在 NeurIPS 上的奠基之作:《ImageNet classification with deep convolutional neural networks》。这篇论文目前的引用量已超过 18 万次(可能仅次于引用量近 30 万的 ResNet 论文和引用量超过 20 万的 Transformer 论文),它不仅标志着深度学习时代的正式开启,也让两位共同作者的名字响彻云霄:Alex Krizhevsky 和 Ilya Sutskever。
作为 Hinton 的两名得意门生,他们在那间多伦多大学的实验室里,共同推开了 AI 新世界的大门。

Alex Krizhevsky 与 Ilya Sutskever 是 Geoffrey Hinton 引用量最高的论文的第一和第二作者。
Alex Krizhevsky:低调的隐士天才
作为那篇传奇论文的第一作者,Alex Krizhevsky 是 AlexNet 的主要构建者。正是他编写了关键的 CUDA 代码,让神经网络得以在两块 GeForce GPU 上高效训练,从而在 2012 年的 ImageNet 挑战赛上以惊人的 10.8% 优势碾压第二名,一举震惊世界。

然而,与他在学术界的赫赫声名形成鲜明对比的是他极度低调的性格。Alex 出生于乌克兰,成长于加拿大。他被很多同行描述为一位「纯粹的工程师」,拥有极深的技术洞察力。在谷歌工作了数年后,他于 2017 年离职,理由是「对工作失去了兴趣」。
此后,他加入了初创公司 Dessa,随后又逐渐淡出公众视野。据悉,他目前可能已处于半退休状态,享受着徒步旅行的乐趣。在科技圈追逐名利的热潮中,Alex Krizhevsky 就像一位事了拂衣去的隐士。尽管 AlexNet 如今在技术上已被更新的模型取代,但正如一位评论者所言:「没有他,就没有今天的 ChatGPT,没有便捷的 3A 大作,也没有先进的医学影像分析。」
Ilya Sutskever:执着的 AI 愿景者
如果说 Alex 是低调的技术天才,那么该论文的第二作者 Ilya Sutskever 则是充满使命感的 AI 领袖。

Ilya 同样出生于前苏联(俄罗斯),并在以色列和加拿大长大。在多伦多大学期间,他与 Hinton 和 Alex 共同缔造了 AlexNet 的辉煌。随后,他在 Google Brain 参与了序列到序列(Seq2Seq)学习算法和 TensorFlow 的开发,并是 AlphaGo 论文的众多作者之一。
2015 年,Ilya 离开谷歌,作为联合创始人兼首席科学家创办了 OpenAI。他是 ChatGPT 和 GPT-4 诞生的关键人物,被誉为能够「通过直觉看到深度学习未来」的人。然而,他对 AI 安全的关注也日益加深。2023 年,他曾主导了 OpenAI 董事会罢免 Sam Altman 的风波,理由是「沟通不坦诚」,尽管后来 Altman 复职,Ilya 对 AI 对齐(Alignment)和安全超级智能(SSI)的执着从未改变。
2024 年,Ilya 成立了新公司 Safe Superintelligence Inc. (SSI),并为其筹集了 10 亿美元资金。与商业化气息浓厚的硅谷公司不同,SSI 宣称其「第一个产品将是安全的超级智能,在此之前不会做任何其他事情」。
结语
Geoffrey Hinton 引用量突破百万,不仅是他个人学术生涯的高光时刻,也是 Alex Krizhevsky 和 Ilya Sutskever 等一代 AI 杰出人才共同奋斗的缩影。

从 Alex 编写的那行 CUDA 代码,到 Ilya 对通用人工智能(AGI)的深邃构想,再到 Hinton 对神经网络半个世纪的坚守与晚年的忧思,这一里程碑背后,是人类探索智能本质的波澜壮阔的历史。
今天,我们致敬 Hinton,也致敬所有为这一刻铺路的研究者。
参考链接
https://scholar.google.com/citations?user=JicYPdAAAAAJ&hl=en
https://www.youtube.com/watch?v=giT0ytynSqg
https://www.britannica.com/biography/Geoffrey-Hinton
https://www.nobelprize.org/prizes/physics/2024/hinton/podcast/
https://torontolife.com/life/ai-superstars-google-facebook-apple-studied-guy/
https://yiqinfu.github.io/posts/hinton-intellectual-dynasty/