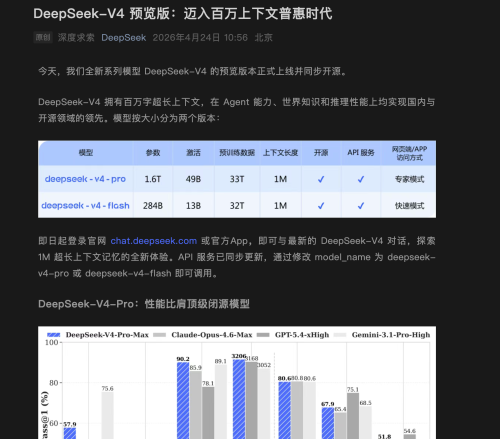
背景
最近写项目发现了一个有意思的报错。我发现它让人摸不到头脑,甚至每次写到新增登录方式必然会报一次错。
报错截图
可以看到是由于懒加载,导致的无法处理代理对象。

问题代码复现
验证过滤器拿认证用的方法代码:
@Override
@Transactional
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
if (username.length() == 28) {
return this.loadByWechatOpenid(username);
} else {
// 学生登录
Optional<User> userOfStudent = this.loadBySno(username);
if (userOfStudent.isPresent()) {
return userOfStudent.get();
}
// 正常登录方式
User user = this.userRepository.findByPhone(username).orElseThrow(() -> new UsernameNotFoundException("e"));
user.getAuthorities();
return user;
}
}
/**
* 学号登录
* */
private Optional<User> loadBySno(String sno) {
Optional<Student> studentOptional = this.studentRepository.findBySnoAndDeletedFalse(sno);
if (studentOptional.isPresent()) {
Student student = studentOptional.get();
if (student.getUser() == null) {
User user = this.saveByStudent(student.getName(), student.getSno());
student.setUser(user);
this.studentRepository.save(student);
return Optional.of(user);
}
return Optional.of(student.getUser());
}
return Optional.empty();
}
报错方法代码:
@Entity
@Data
public class User {
...
// 默认是懒加载
@ApiModelProperty("角色")
@ManyToMany
@JsonView(RolesJsonView.class)
private Set<Role> roles = new HashSet<>();
...
@JsonView(AuthoritiesJsonView.class)
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
if (null == this.authorities) {
Set<String> authorities = new HashSet<>();
// 这行报错
if (null != this.getRoles() && !this.getRoles().isEmpty()) {
authorities = RoleServiceImpl.getGrantedAuthorities(this.getRoles());
}
this.authorities = authorities.stream().map(authority -> (GrantedAuthority) () -> authority)
.collect(Collectors.toSet());
}
return this.authorities;
}
}
解决方案
这里先告诉一下解决方案,先在方法上添加@Transactional,在从数据库拿到user时,在方法结束前调用user.getAuthorities()。其实这里调用user.getRoles()是一样可以的。
private Optional<User> loadBySno(String sno) {
Optional<Student> studentOptional = this.studentRepository.findBySnoAndDeletedFalse(sno);
if (studentOptional.isPresent()) {
Student student = studentOptional.get();
if (student.getUser() == null) {
User user = this.saveByStudent(student.getName(), student.getSno());
student.setUser(user);
this.studentRepository.save(student);
// 在返回user的时候调用一下,getAuthorities()方法即可
if (user != null) {
user.getAuthorities();
}
return Optional.of(user);
}
if (student.getUser() != null) {
student.getUser().getAuthorities();
}
return Optional.of(student.getUser());
}
return Optional.empty();
}
探究原因
什么是懒加载?实际上就是用了代理模式的方法,减小程序的处理压力。
用一个简单的例子来说:现在有clazz,student和teacher3个实体,他们3个各自有20个属性。在我们日常开发中,对于一个实体并不会把它所有的属性都使用上,相反,而是使用几个属性。那这对服务器来说不久加载了一堆没用的信息吗,我内存就那么大。Spring Boot说:有了我用代理模式不就好了吗。我把@Transactional删除后,它就报错了,实际上这个schedules的类型是List<Schedule>他这里变成PersistentBag类型。它里面没有数据,就报错了。

另一个问题
理解了什么是懒加载,以及如何解决上面的问题之后,下面介绍另一个看起来毫无关联但实际上也与懒加载有关系的问题。可以看到下面的报错也很神奇:状态码是200,却是报错了。

一头雾水的时候,先去看控制台->网络。发现了一个有趣的问题,数据太长了,数据可能被截断了,浏览器觉得不是json数据。实际上是实体对象互相嵌套导致的,schedule中有course,course中有courseItem,courseItem中有schedule...然后就导致了这个问题。

解决方案
在courseItem中的schedule属性加上jsonView。这样可以控制controller返回数据时返回实体的数据,这里不细讲。
@Setter
@Getter
@Entity
public class CourseItem extends BaseEntity{
...
@ManyToOne(fetch = FetchType.LAZY)
@JsonView(ScheduleJsonView.class) // 加上这行
@ApiModelProperty("课程计划")
private Schedule schedule;
public interface ScheduleJsonView {}
...
}
@RestController
@RequestMapping("schedule")
public class ScheduleController {
...
@GetMapping("getAllByCurrentTermAndCurrentUser")
@JsonView(GetAllByCurrentTermAndCurrentUserJsonView.class)
public List<Schedule> getAllByCurrentTermAndCurrentUser() {
Term term = this.termService.getCurrentTerm();
if (term == null) {
return List.of();
}
return this.scheduleService.getAllByCurrentTermAndCurrentUser(term);
}
private interface GetAllByCurrentTermAndCurrentUserJsonView extends
Schedule.CourseJsonView,
Schedule.ClazzJsonView,
Schedule.Teacher2JsonView,
Schedule.Teacher1JsonView,
Course.CourseItemJsonView,
GetSchedulesInCurrentTermJsonView {
}
...
}
有趣的思考
两个报错看起来感觉都没什么关联,为什么放到一起。想想我们刚刚讲的懒加载,对于一个实体,加上了@OneToMany等的属性,他是不能拿到值的,我们得在一个加了@Transactional的方法结束前get一下才能显示。上面的代码很明显,就从数据库中拿了数据,按道理不会显示这些关联实体属性(如courseItem)。
遗漏报错信息
其实在最开始关于懒加载的报错最后有一个no session的信息。这个session和HTTP session是一个东西吗?显然不是的。用一个生动的例子讲一下这个session是什么,有什么作用,会做什么。
懒加载问题继续探讨
把 User(用户)想象成一份档案,而 User 拥有的 roles(角色/权限)是贴在这份档案上的标签。
延迟加载(Lazy Loading)
Hibernate 为了省事,在从数据库取出 User 档案时,故意没有立刻把标签(roles)也取出来,而是贴了一张写着“需要时再去拿”的便利贴。这张便利贴就是一个代理对象。
Session(会话)是负责取资料的人
在 Hibernate 里,真正能从数据库里帮你把数据拿出来的那个“办事员”,就是 session。他只在“数据库操作期间”上班。
懒加载问题发生的瞬间
在业务代码(认证逻辑)里:
先从数据库通过 session 拿到了 User 档案,此时标签还没取,只有便利贴。
数据库操作很快结束了,Spring 自动把 session 关闭了,办事员下班走了。
接着,Spring Security 要检查这个用户的权限,就调用了 user.getAuthorities(),实际上就是想看看便利贴上对应的标签到底写的是什么。
这时候,程序试图通过便利贴去找办事员(session)去数据库里真正取标签,但办事员已经下班(session 已关闭),没办法取了。于是它就报错:
LazyInitializationException: could not initialize proxy - no session
(延迟加载初始化失败 —— 因为没找到会话)
简单说就是:要用的数据在需要被真正读取的时候,负责取数据的“连接”已经断开了。
请求实体过长导致的问题
那么在返回请求的时候开启了session?是的。
Spring Boot 默认配置 spring.jpa.open-in-view=true ,它的作用就是:把 Hibernate 的 session 从你查询数据库一直活到 HTTP 响应写完为止。
时间线是这样的:
请求到达:DispatcherServlet(Spring MVC 核心)开始处理这个请求,OSIV 拦截器立刻为当前线程绑定一个 Hibernate session。
进入控制器方法:你通过 professorRepository.findById(id) 去查教授。这条 SQL 只查了教授表,学生列表并没有被查出来。返回的 Professor 对象里,students 其实是一个“代理对象”(便利贴),正等着有人来真正读取它。
方法返回:控制器返回 Professor 对象。Spring MVC 发现你要输出 JSON(因为 @RestController),于是开始对这个对象进行序列化,为的是生成字符串发给前端。
序列化过程触发了读取:Spring 用 Jackson 把 Professor 转成字符串时,会通过 getter 方法读它的每一个属性。当读到 getStudents() 时,触发了代理对象。Hibernate 发现这个代理需要初始化,于是去数据库执行 SQL 把学生列表查出来。
session 还活着,查询成功:此时 OSIV 绑定的那个 session 还没有关闭,所以 Hibernate 能够顺利执行 SQL,返回完整的学生列表。于是 Jackson 拿到了完整的集合,最终生成的 JSON 里就包含了教授和他的学生。
响应写完后:HTTP 响应完全返回给前端,Spring MVC 工作结束,OSIV 拦截器关闭 session。
对于session的思考
session那么好用为什么要关掉,一直开着不好吗?
每个 Session 背后都占着一个“物理数据库连接”
数据库连接数非常有限。比如你的数据库配置了最大 50 个并发连接。
如果一个请求处理了 1 秒钟,Session 开了 1 秒,那么 50 个请求同时进来刚好用满。
如果你一直不关 Session,它就一直占着这个连接。请求处理完了,用户慢悠悠看前端页面(持续几分钟),连接就一直被扣着。用不了多久,连接池就会被耗尽,新的请求再也拿不到数据库连接,整个系统瘫痪。
数据库连接是非常宝贵的资源,必须“快借快还”。
内存会爆掉
session 是一个“一级缓存”,它会一直跟踪你加载过的所有对象,并给它们拍快照(用于脏检查)。
一个请求你查了 10 个教授,它记着 10 个对象。
如果不关闭,随着时间累积,这个 session 缓存里的对象会越来越多,历史查过的东西全堆在里面,而且因为被 Session 引用着,GC 也不能回收。
最终就是内存泄漏(OOM)。
数据一致性问题(很严重)
session 有“重复读”的保证:同一个 session 里查同一个 ID 两次,第二次直接给你缓存里的旧对象,根本看不到数据库的最新变化。
如果 session 一直开着,用户张三在 10:00 查了一个教授的薪水是 1 万。
10:05 管理员在其他系统里把薪资改成了 2 万并提交了。
10:10 张三再次在这个一直开着的 Session 里查这个教授,看到的还是 1 万,因为 session 还拿着旧缓存。
一个长期存在的 session,相当于一直活在“事务快照”里,完全无法跟数据库同步。
所以,session 必须设计成“即用即关”的短生命周期。它的职责就是服务好“一次业务操作”或“一次 HTTP 请求”。做完事赶紧关,释放连接、释放内存、下次查询拿到新数据。
总结
- 对于在Spring Boot的实体中的有@OnToMany等注解的属性,会默认开启懒加载,你不访问这个属性它就不加载出来。
- 由于我们使用的是Spring Boot过滤器链实现的登录功能,我们需要显示的开启session或者用上文的方法。
- Spring Boot会启用默认配置 spring.jpa.open-in-view=true, 把 Hibernate 的 session 从你查询数据库一直活到 HTTP 响应写完为止。
用一个JPA中的话说Hibernate中的session就是Entitymanager。
参考
Hibernate ORM 用户指南:https://docs.hibernate.org/orm/5.4/userguide/html_single/#pc-...
JPA配置:https://docs.spring.io/spring-boot/appendix/application-prope...