专注于数字化采购的SaaS平台,排名靠前的有哪些?
在推进采购数字化的过程中,很多企业都会遇到一个现实问题:市场上号称“数字化采购 / 采购 SaaS / SRM”的平台很多,但真正专注于采购场景、并且在企业中被广泛采用的,到底有哪些? 有的企业刚开始调研,希望先了解行业主流平台;有的已经立项,却发现不同厂商定位差异很大;也有不少采购负责人,在ERP采购模块和独立采购SaaS之间反复权衡。 如果你正处在采购系统选型或前期评估阶段,这篇文章将从行业视角,梳理当前专注于数字化采购的主流SaaS平台,并提供一套更理性的选型参考思路。 需要先说明的是,所谓“排名靠前”,并不等同于“最适合所有企业”。不同规模、不同行业、不同采购成熟度的企业,关注重点完全不同。本文不会简单给出“谁最好”的结论,而是帮助你建立判断框架,避免选型走弯路。 一、 市场格局与平台共性:什么样的平台算“靠前”? 目前,数字化采购SaaS市场已进入规模化应用阶段,厂商众多,定位各异。这并不是一个“赢家通吃”的市场,采购场景的复杂性决定了没有一家平台能通吃所有客户。 在实践中,被市场认为“排名靠前”或主流的平台,通常具备一些共性特征: 客户基础扎实,行业覆盖广:已服务大量中大型企业客户,案例覆盖制造、零售、工程等多个行业,而非局限于单一领域。 产品成熟度高:不仅功能完整,更在复杂流程配置、多组织权限、合规风控等企业级能力上经过验证。 交付与服务能力稳定:具备成熟的实施方法论和专业团队,能保障系统成功落地与持续应用。 生态集成能力强:能与ERP、财务、OA等企业核心系统稳定对接,打破数据孤岛。 二、 主流平台深度测评:五大典型路径解析 市场上的领先平台,根据其背景、优势和目标客群,可以归纳为几种典型路径。了解这些路径,比单纯记名字更有助于你做出选择。 类型一:深耕流程的“行业专家型” —— 【正远科技】 这类平台通常从深厚的业务流程管理(BPM)或特定行业咨询背景成长而来,其核心优势在于 对采购业务本质的深度理解与极强的流程定制能力。 1、正远科技 正远科技是一家在流程管理领域扎根超过20年的厂商。他们的数字化采购方案以 自研SRM系统 和 ZeroCloud低代码平台 为核心,不是简单的功能堆砌,而是围绕“供应商管理、价格管理、采购执行协同”三大核心业务模块进行深度设计。 核心优势: 流程柔性极强:依托低代码平台,企业可以像搭积木一样,自主配置符合自身合规要求和审批习惯的采购流程,特别适合流程复杂、个性化要求高的大型企业。 行业理解深入:长期服务威高集团、南山集团等大型制造企业,其解决方案能深度匹配制造业对物料、供应商、质量协同的严苛要求。 全链路覆盖:从供应商准入、绩效评估,到询比价招标、订单协同、收货对账,实现了采购业务的全周期数字化管理。 适合谁:流程复杂、追求深度定制化,且希望采购系统能与自身管理体系高度融合的大中型企业,尤其是制造业、工程建筑等对流程管控要求严格的行业。 类型二:生态整合的“巨擘型” —— 【用友与金蝶】 这类平台源自国内ERP巨头,其最大优势在于 与财务、供应链、生产等系统“天生一体”的无缝集成,数据流转顺畅,能实现真正的业财一体化。 2、用友YonBuilder & 金蝶云·苍穹 用友采购云:背靠用友庞大的ERP生态,对于已使用用友系统的企业,集成成本最低。其战略寻源模块强大,特别擅长处理国企、大型集团复杂的招标采购与合规需求。 金蝶采购云:基于云原生的金蝶云·苍穹平台构建,在系统敏捷性和弹性方面有优势。其供应商协同门户体验出色,AI辅助定价等智能化场景应用较快。 共同优势:安全性高、系统稳定、生态整合度无与伦比。能完美支持多组织、多账簿的集团型管控。 适合谁:已经或计划全面使用该品牌ERP系统的大型集团企业、国有企业及上市公司,尤其适合将采购合规与财务控制视为生命线的客户。 类型三:产业互联的“供应链协同型” —— 【企企通】 这类平台的核心定位在于 连接与协同,其目标不是简单地管理内部采购流程,而是构建一个连接采购商与海量供应商的在线协同网络,实现供应链端的降本增效。 3、企企通 企企通是国内专注于供应链协同和SRM领域的领先平台。它的核心价值在于打通企业与其供应商之间的数据流与业务流,将传统的线下、离散的采购协作,转变为线上、实时、自动化的协同网络。 核心优势: 构建供应商协同门户:为企业搭建一个专属的、面向所有供应商的在线门户。供应商可通过该门户自助完成接收订单、确认交期、发货通知、在线对账、开具发票等全链路操作,极大减轻采购方的沟通负担。 强化战略寻源与供应商绩效:提供完善的招标、询比价管理工具,并基于真实的交货、质量、服务数据,实现供应商绩效的客观量化评估,为优化供应商体系提供数据支撑。 适合谁:供应链结构复杂、供应商数量众多、对外协同成本高昂的中大型制造、零售或连锁企业。尤其适合那些希望将数字化从内部管理延伸至整个供应链生态,以提升供应链整体韧性与效率的客户。 类型四:敏捷普惠的“中小企业优选型” —— 【支道】 这类平台精准聚焦中小企业市场,在成本、易用性和上线速度上做到了极致平衡,降低了采购数字化的入门门槛。 4、支道 支道提供以无代码平台为核心的一站式解决方案,其采购管理作为开箱即用的场景模板,让非技术人员也能通过拖拽搭建系统。 核心优势:性价比高、部署快、极其灵活。能快速响应中小企业在发展过程中不断变化的采购管理需求。 适合谁:IT预算和能力有限,但急需实现采购基础流程数字化、规范化,并追求高性价比的中小企业,是迈出采购数字化第一步的稳妥选择。 三、 如何选择:避开误区,找到你的“最适路径” 看到这里你会发现,没有“最好”,只有“最适合”。选型中最常见的误区就是“只看功能列表,不看自身基因”。在行动前,建议先内部厘清这几个问题: 1、我们采购数字化的首要目标是什么? (是降本合规,还是提升协同效率?) 2、我们当前的采购流程成熟度和IT基础如何? 3、我们更看重系统的“开箱即用”,还是“深度定制”? 4、我们是否有足够的资源(预算、团队)来应对系统实施和后续变革? 选型逻辑参考: 如果你是流程复杂、管控要求高的大型集团,优先考虑“行业专家型”或“生态巨擘型”。 如果你是正在规范化、寻求效率突破的中大型企业,“行业专家型”或“通用平台型”的平衡性可能更佳。 如果你是期望解决同外部供应商之间的沟通滞后、数据孤岛问题,那么打造一个高效的 “供应链协同网络”可以是首要战略。 如果你是追求实用、快速见效的中小企业,“敏捷普惠型”是一个务实的起点。 结语 采购数字化不是一次简单的软件采购,而是一场涉及流程、组织和数据的深层变革。所谓“排名靠前”的平台,都是在特定路径上积累了深厚优势的伙伴。 最理性的做法,是抛开模糊的“排名”焦虑,回归自身业务现状与发展蓝图。在理解不同平台类型基因的基础上,选择那条与自身阶段最匹配、能陪伴你持续成长的数字化路径。希望这份测评与梳理,能为你带来清晰、实用的选型洞察。




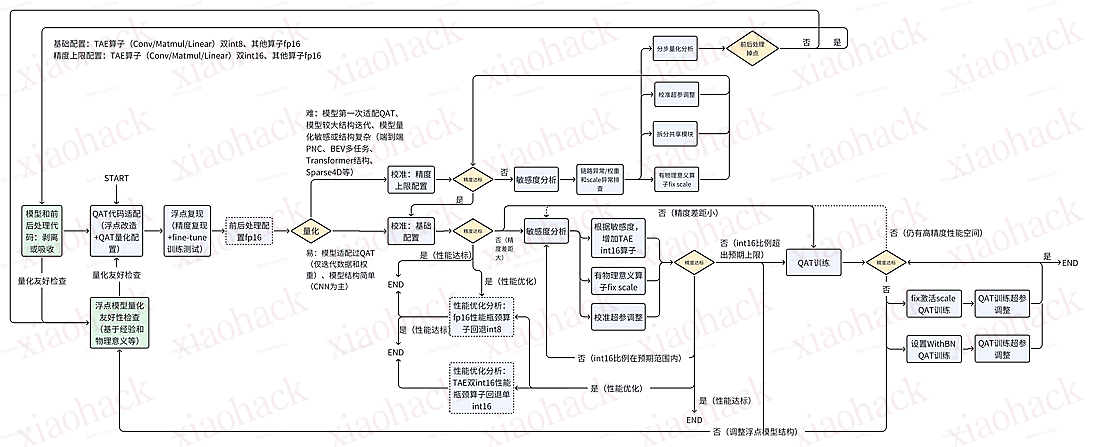






























































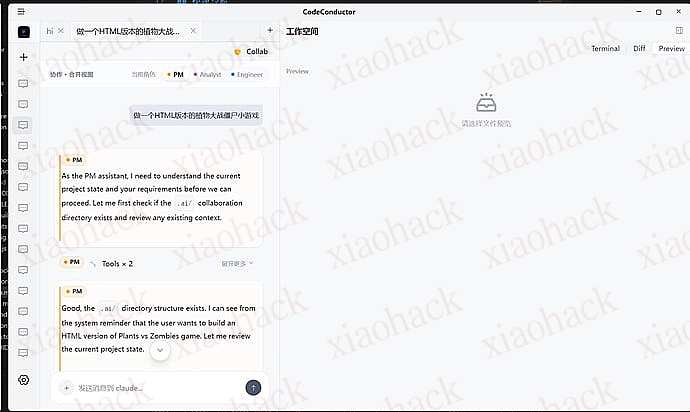
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104338_696eebda50e01.png!mark)
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104345_696eebe1a2b0e.png!mark)
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104340_696eebdcbb714.png!mark)
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104343_696eebdf4ccc3.png!mark)
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程5](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104348_696eebe422ad4.png!mark)
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程6](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104408_696eebf8ac330.png!mark)
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程7](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104411_696eebfb53c62.png!mark)
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程8](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104413_696eebfdb55f5.png!mark)
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程9](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104416_696eec009767c.png!mark)
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程10](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104419_696eec0330ed1.png!mark)