这里记录每周值得分享的科技内容,周五发布。
本杂志开源,欢迎投稿。另有《谁在招人》服务,发布程序员招聘信息。合作请邮件联系([email protected])。
封面图

中法合作的一个艺术项目《挑战第841次》,让路过的行人在黄浦江边的一个玻璃亭子里,弹奏法国作曲家的一个钢琴作品。(via)
为什么人们拥抱"不对称收益"
前两周,我跟大家说,美国现在最流行"预测市场"。我当时没有统计数字,现在有了。
2025年11月,美国前两大预测市场---- Polymarket 和 Kalshi ---- 一共成交了超过100亿美元。

看这个数字,大家可能没感觉。作为对比,美国全国的体育彩票,2024年的销售额是137亿美元。
这就是说,预测市场一个月的交易量,接近了体育彩票全年的销售额。要知道,这两个网站6年前都还不存在!
这么恐怖的增长速度,难怪美国各大公司现在都想挤入这个市场,分一杯羹。
预测市场就是变相的网络彩票,它的火爆只能说明一件事情,美国正出现疯狂的"彩票热"。
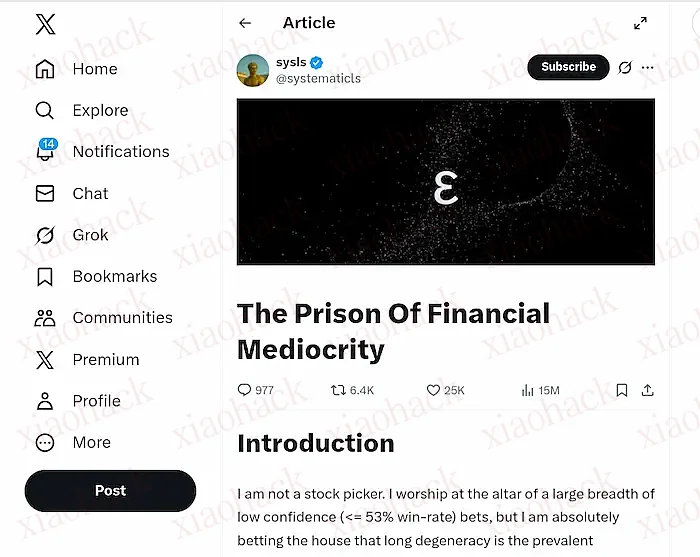
本周,我看到一篇文章(上图),一位风险投资家分析这个现象。我想分享他的观点,他认为,预测市场火爆的根本原因,是社会心态的焦虑和绝望。
(1)财富转移机制失效了,通过正常工作致富,越来越不可能。工资的增长速度,低于消费的增长速度,个人债务正在变多。
虽然资产的价格(比如股票、黄金、房产)也在上涨,但只是让那些拥有资产的人受益,对于没有这些资产的穷人,只是变得更贫穷。
(2)传统的人生模式也失效了。以前的模式是,找一家大公司,每天按时上班,努力工作,对公司忠心耿耿,坚持多年就会得到回报。你会收到公司的奖励,退休后还有养老金。
这种模式现在行不通了。公司的经营短期化,能存活20年的公司并不多,更不要说你的岗位了。一旦失去现在的工作,再次就业非常困难,以前的工作经验很可能用处不大。
(3)AI 的出现,加剧了前两种情况的发展速度。AI 让一切加速了,压缩了时间。以前,你有五年的时间奋斗,AI 让你感到必须在一年里拿到结果,否则就可能为时已晚。
(4)社交媒体则使得人们永远不会对现状满意。
以前,你的参照群体只是周围人群,现在的参照群体是全世界。你每天看到的都是收入高、赚钱容易、生活优渥的人群,永远会让你感到自己的生活不够好,而无论你已经取得了怎样的成就。
(5)结果就是,越来越多的人失去了耐心,不再相信长期投入,不再幻想长期的劳动积累会通往圆满的人生,社会也不奖励耐心。
为什么要苦苦奋斗20年,去争取10年后可能根本不存在的晋升机会?我要的是一条快速的道路,摆脱日常生活的困境,而且越快越好。
(6)这种心态下,人们的风险偏好发生了变化。为了快速摆脱困境,在风险更大的选项上放手一搏,成了合理的选择。
即使只有5%的希望,也比100%的停滞不前更有吸引力。这就是彩票在贫困社区更畅销的原因。
这在经济学上称为"不对称收益"(asymmetric returns),就是风险和收益不对称。失败的可能性很大,但只会损失一小笔钱,成功的可能性很小,但是一旦成功,就会获得巨大收益,简单说就是"小亏大赚"。
追求不对称收益,已经成了一种普遍的心态。它推动了前几年的加密货币和 NFT 的热潮,现在又推动了预测市场。
可以确定,凡是能够产生"不对称收益"的事情,今后都会迅速成为热点。
新人上手 Claude Code 的简单方案
AI 编程工具,我用的是 Claude Code。以前推荐过,非常好用,功能很强。
我现在依然这样认为,但是必须说,Claude Code 不适合所有人,有使用门槛。
它要求用户熟悉命令行,而且 Windows 安装不方便,需要启用 Linux 子系统 WSL。另外,如果在外面,没有自己的计算机,临时想用一下,也很麻烦。
元旦的时候,我在广东听说,有人做了"云端 Claude Code 客户端",解决了这些痛点,就很感兴趣。

他们团队叫做 302.AI,我以前就有接触。他们做云端服务很多年了,现在专注于 AI 模型接入。大家可以去官网看一下,用他们的 API 能够接入几乎所有主流模型,数量有几百个。

他们跟我一样,也感到 Claude Code 的诸多不便,就想能不能再开发一个它的客户端,封装所有复杂性,提供最好用的 AI 编程体验。

(1)跨平台桌面应用。他们提供 Win/Mac/Linux 安装程序,通过桌面窗口去使用云端的 Claude Code。
(2)零配置的云端沙盒。云端的 Claude Code 预装在一个沙盒里,集成了 Node.js、Python、Git、CMake、build-essential 等开发工具,不需要任何本地环境配置,开箱即用。
同时,沙盒也保障了安全,跟本地电脑是隔离的,AI 就不会误删本地文件。
(3)对话界面。对于不习惯命令行的用户,他们提供对话式交互界面(Chat UI),以聊天方式完成编程。

(4)随意更换模型。Claude Code 更换底层模型,需要配置环境变量,他们的客户端不需要这么麻烦,只需要鼠标选中即可。
你可以直接用他们的 API,也可以配置自己的 API Key。
(5)一键部署。他们还提供了部署功能,AI 生成的结果可以一键发布到公网,直接访问,无需购买服务器或配置域名。
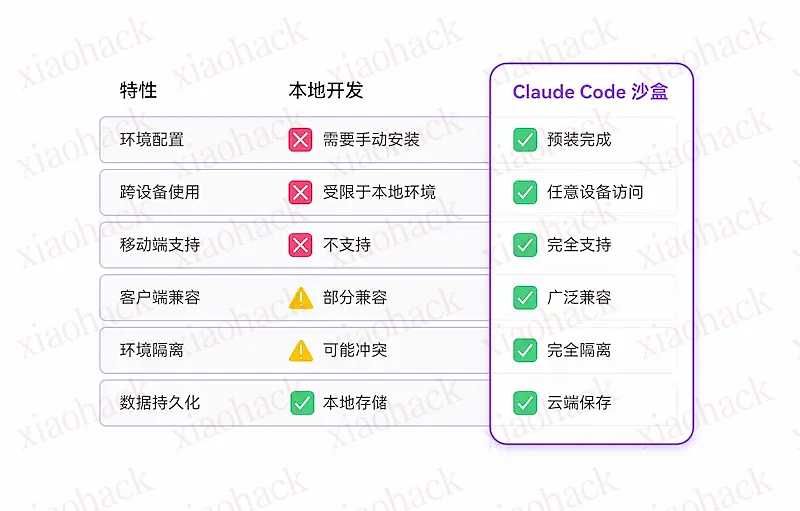
可以说,这个方案完全针对 Claude Code 的各种痛点,目标是打造新手最容易上手的 Vibe Coding 工具。
感兴趣的朋友可以去 studio.302.ai 下载,体验一下。(提醒:使用前需要注册/登录 302.AI 账号。)
科技动态
1、乔布斯写的程序
乔布斯创立苹果公司之前,当过短时间的程序员。1975年,他20岁,从大学退学后,进入雅达利公司写电子游戏。
人们一直不知道,他的编程水平如何,现在终于曝光了。
本周,乔布斯的一些个人档案公开拍卖,其中就有当年他写的程序,打印纸上还有他的亲笔注释。

有人把这个程序还原出来,放到虚拟机上跑,终于让我们看到了乔布斯的软件作品。

这个程序叫做 AstroChart,跟星座有关。用户提供出生的时间地点,它会显示太阳系主要天体的位置。

从代码来看,乔布斯的编程水平可以,他使用三角函数计算行星位置,并且绕过当年硬件没有双精度浮点数的限制,用整数除法代替。
2、世界最大电动船
澳大利亚建造了世界最大的电力轮船,长度130米,里面的电池重达250吨。

这艘船将用作阿根廷与乌拉圭之间的轮渡,可以搭载多达2100名乘客和225辆汽车。

这艘船不仅是史上最大的电动船,可能也是史上最大的电动装置,一次可以携带超过4万度电。

3、最高过山车
2025年的最后一天,沙特阿拉伯在距离首都利雅得40分钟车程的地方,开张了一个乐园。

这个乐园有27个游乐设施,很多都是世界之最,其中就有目前世界最高的过山车。

这个过山车高达195米,相当于60层楼,比先前的世界纪录高出了55米。
整个过山车的长度是4.2公里,最高速度可以达到240公里/小时,全程只有3分多钟。

网上有很多这个过山车的视频,不要说坐在车上,就是看视频都觉得惊心动魄。
文章
1、2025年大模型回顾(英文)

西蒙·威利森(Simon Willison)的 AI 年度回顾,过去一年的大事件基本都提及了,总结和评点得非常好,推荐阅读。
2、华为的 5nm 制程怎么样?(英文)
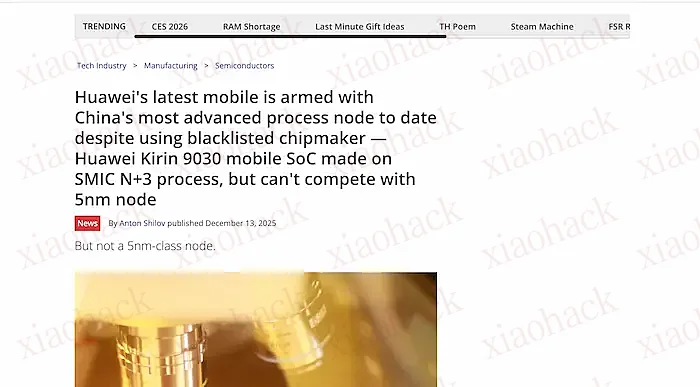
这是一家美国技术媒体对华为麒麟9030芯片(搭载于最新的 Mate 80 手机)的分析文章。
该文认为,该芯片比早先的 7nm 制程有提升,是大陆制造的最先进芯片,但从跑分看,还没达到台积电的 5nm 水平。文章有中文版。
3、Opus 4.5 将会改变一切(英文)

作者不相信 AI 会取代程序员,直到遇到 Anthropic 公司的 Opus 4.5 模型。本文是他的4个项目的编程体会,他现在确信程序员会被替代。
4、HTTP caching, a refresher(英文)

对于 HTTP 缓存机制的一个总体介绍,梳理浏览器缓存的处理逻辑。
5、Vitest 的浏览器模式介绍(英文)

JS 测试框架 Vitest 4.0 引入了浏览器模式,可以进行浏览器自动化,类似于 Playwright,进行 UI 测试,本文是一个简单介绍。
6、如何提高 JS 数组的读写速度(英文)

一篇 JavaScript 中级教程,介绍通过为 JS 数组分配连续内存,提高数组的读写速度。
工具
1、ZenOps

一个命令行工具,在本地终端里查询阿里云/腾讯云等云平台的运行数据,并提供钉钉、飞书、企微机器人,进行自然语言查询。(@eryajf 投稿)
2、白虎面板

轻量级的服务器定时任务管理系统,适合低配置的服务器。(@engigu 投稿)
3、OnlinePlayer

一个网页播放器,可以播放本地视频和云盘视频。(@13068240601 投稿)
4、gitstats

命令行工具,生成 Git 仓库的统计数据。(@shenxianpeng 投稿)
5、云图
一个极简风格的图床,可以搭建到自己的 NAS,提供灵活的 API。(@qazzxxx 投稿)
6、KeyStats
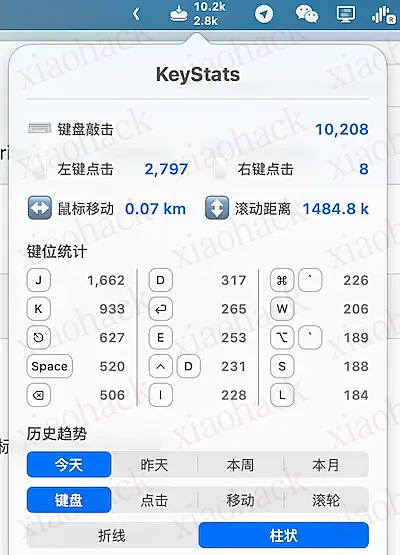
开源的 macOS 小工具,对按键行为进行统计。(@debugtheworldbot 投稿)
7、py2dist
这个工具可以将 Python 脚本编译成二进制模块,方便隐藏源码。(@xxnuo 投稿)
8、Stream Panel

Chrome 浏览器开发者工具的一个扩展,用来调试服务器发送事件 (SSE) 和 Fetch 的流式连接。(@bywwcnll 投稿)
9、Zedis
Redis 的图形客户端,跨平台的桌面应用,不使用 Electron,而是使用 Rust + GPUI,性能更好。(@vicanso 投稿)
10、QDav

这个网站可以为夸克网盘加入 WebDAV 协议,从而挂载到网盘播放器来播放夸克网盘的视频。(@ZhouCai-bo 投稿)
11、XApi
开源的 Chrome 浏览器插件,自动捕获当前网页的 Fetch 与 XHR 网络请求,支持改写 Cookie、Origin、Referer 字段,方便开发调试。(@lustan 投稿)
12、PDFCraft

纯浏览器的 PDF 开源工具集,目前有80多个工具。(@pccprint 投稿)
AI 相关
1、Open-AutoGLM
智源公司的开源安卓应用,使用自然语言,让 AI 操作手机,进行手机自动化,可以接入各种模型,无需电脑端。(@Luokavin 投稿)
2、Claude-Ally-Health
一个基于 Claude Code 的个人医疗数据中心,定义了一组自己的命令和技能,用 AI 分析个人医疗数据(体检报告、影像片子、处方单、出院小结)。(@huifer 投稿)
3、灵猫

免费的 AI 图片去水印网站,但只是去除视觉水印,嵌入的数字水印还在。(@pangxiaobin 投稿)
4、DeepDiagram AI

开源的 AI 应用,用自然语言驱动内置的 mermaid、echarts、mindmap、Draw.io 等绘图工具生成图表。(@twwch 投稿)
资源
1、100万首页截图

这个网站收集了100万个热门网站的首页截图,将它们做在一个页面,可以放大查看。
2、Emulator Gamer

各种老游戏机的经典游戏,通过模拟器免费在线游玩。(@SinanWang 投稿)
图片
1、如今的 Mozilla
Mozilla 浏览器的新任 CEO 宣称,公司的发展方向是AI 浏览器。
这让 Mozilla 社区感到担忧,因为没人是为了 AI 而使用它。一位使用者就画了下面这张图。

Mozilla 的吉祥物----一只小狐狸拿着锯子,把自己正坐着的树枝锯断,旁边还有一只鸟,为它递上更锋利的电动锯子,上面写着"AI"。
这张图比喻 Mozilla 一直在自寻死路,全力转向 AI 只会死得更快。
文摘
1、外卖应用的秘密
我是一个大型外卖应用的开发者,受一项严格的保密协议约束。但是,我已经不在乎了,我昨天向公司递交了离职报告。
说实话,我希望公司能起诉我,这样一来,这些事情就会曝光。
我已经消极工作大约八个月了,只是看着代码被推送到生产环境。一想到自己参与了这台机器,我夜里都睡不着。
人们总怀疑算法对用户不利,现实比这更糟。我是一名后端工程师,每周参加产品会议,产品经理(PM)讨论如何才能挤出额外0.4%的利润,他们把用户当成有待开发的资源。
公司有一个"优先配送"服务,你多付2.99美元,就可以更快拿到外卖。这完全是个骗局,根本没有加快派送的速度,而是人为把非优先订单延迟5到10分钟,让你感觉优先订单更快。我们仅仅通过让标准服务变差,就赚取了数百万美元的纯利润,而不是真正改善服务。
最让我恶心的是"绝望分数",这是一个隐藏的外送员指标,根据外送员的行为判断他们多想赚钱。
如果外送员在晚上10点登录系统,毫不犹豫地立即接下每一个3美元的垃圾订单,算法会将他们标记为"高度绝望"。一旦被标记,系统就会停止向他们显示高价订单,理由是"既然我们知道他绝望到愿意接受3美元,为什么还要让他看到15美元的订单呢?"。系统把高价订单留给"休闲"外送员,即那些不愿接低价单的外送员,吸引他们接单,而全职外送员则被碾压成尘埃。
公司还会从用户的账单扣除一笔1.50美元的"外送员福利费",这个名字让用户感觉在帮助外送员。实际上,这笔钱流入了游说反对外送员成立工会的基金,这是公司用于"政策防御"的费用。用户实际上是在为那些高端律师付费,那些律师为削弱外送员的权益而工作。
最后,虽然公司不再从外送员的小费里面提成,因为被起诉过,但是使用其他方法窃取小费。
如果算法预测你是"可能支付小费的用户",而且你很可能会给10美元小费,那么公司只会给外送员可怜的2美元基本派送费。如果你给了0美元小费,公司会给外送员8美元的基本派送费。结果是用户的小费并没有奖励外送员,而是在补贴公司。用户给外送员付工资,这样我们就不用付了。
言论
1、
在美国东海岸(纽约和华盛顿),人们会问:"中国是否就要失败了",而在西海岸(洛杉矶和旧金山),人们更倾向于问:"万一中国成功了会怎样?"
这一定程度上反映了硅谷的特点:更注重收益最大化,而非风险最小化。东海岸的问题也值得认真对待,但过分关注中国是否失败,会助长一种美国无需做出任何改变就能击败对手的论调,从而削弱美国改革的紧迫性。
-- Dan Wang《2025年度信件》
2、
如果美国或中国在某个方面落后太多,落后者就会奋起直追。这将是未来数年甚至数十年世界变化的动力。
-- Dan Wang《2025年度信件》
3、
程序员对待 AI 有两种态度:一种以结果为导向,渴望通过 AI 更快拿到结果;另一种以过程为导向,他们从工程本身获得意义,对于被剥夺这种体验感到不满。
-- Ben Werdmuller
4、
AI 数据中心的建设热潮,导致内存价格暴涨,进而产生一系列连锁反应。
手机和电脑厂商别无选择,只能提价。我们估计,2026年全球的手机市场和电脑市场都会萎缩。手机萎缩2.9%到5.2%,电脑萎缩4.9%到8.9%。
-- IDC 公司的预测
5、
eSIM 手机卡一旦更换就可能失效,相比之下,实体 SIM 卡可以随意插上插下,几乎不会出现故障。推广 eSIM 的后果就是,手机号丢失的事件会大大增多。
-- 《我后悔使用 eSIM》
往年回顾
一切都要支付两次(#333)
没有目的地,向前走(#283)
生活就像一个鱼缸(#233)
腾讯的员工退休福利(#183)
(完)




























![【CCG 自动化流 安装教程 (孙佬 + 风佬升级装)】 三合一自动化流编程,这波升级顺滑如水啊 !!!助力每位佬友 享受 [自动化流] 氛围编程时代!1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/14/20260114102231_6966fde759fb5.png!mark)
![【CCG 自动化流 安装教程 (孙佬 + 风佬升级装)】 三合一自动化流编程,这波升级顺滑如水啊 !!!助力每位佬友 享受 [自动化流] 氛围编程时代!2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/14/20260114102233_6966fde983135.png!mark)
![【CCG 自动化流 安装教程 (孙佬 + 风佬升级装)】 三合一自动化流编程,这波升级顺滑如水啊 !!!助力每位佬友 享受 [自动化流] 氛围编程时代!3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/14/20260114102235_6966fdeb9e7f9.png!mark)
![【CCG 自动化流 安装教程 (孙佬 + 风佬升级装)】 三合一自动化流编程,这波升级顺滑如水啊 !!!助力每位佬友 享受 [自动化流] 氛围编程时代!4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/14/20260114102238_6966fdee85d69.png!mark)
![【CCG 自动化流 安装教程 (孙佬 + 风佬升级装)】 三合一自动化流编程,这波升级顺滑如水啊 !!!助力每位佬友 享受 [自动化流] 氛围编程时代!5](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/14/20260114102242_6966fdf219e60.png!mark)













 这两天在网络上又有一个东西火了,Twitter 的创始人
这两天在网络上又有一个东西火了,Twitter 的创始人 
 两个月前,我试着想用 ChatGPT 帮我写篇文章《
两个月前,我试着想用 ChatGPT 帮我写篇文章《
 这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《
这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《