这里记录每周值得分享的科技内容,周五发布。
本杂志开源,欢迎投稿。另有《谁在招人》服务,发布程序员招聘信息。合作请邮件联系([email protected])。
封面图

武汉首座电梯升降桥最近建成开放。因为上游有船厂,所以大桥有四根巨大的电梯柱,用来升起桥面,让船通过。(via)
预测是新的互联网热点
大家大概想不到,美国互联网的热点,现在不是 AI 网站,而是一种全新的网站,叫做"预测市场"(prediction market)。
这类网站像雨后春笋一样,每天都在冒出来。最有名的预测市场,目前是 PolyMarket。

预测市场的用途,就是预测各种各样的事情。以 PolyMarket 为例,首页顶部就是各种预测的分类。

热门事件、突发事件、最新预测、政治、体育......
只要是你能想到的事情,它都提供预测。

以上周末为例,首页热门预测如下(上图)。
- 《时代》杂志的年度人物是谁?
- 《时代》杂志年度人物名单会泄露吗?
- 美联储一月份的决定是什么?
- OpenAI 下一次的大模型发布是哪一天?
你随便选一个,点进去就能看到,各种情况的概率。
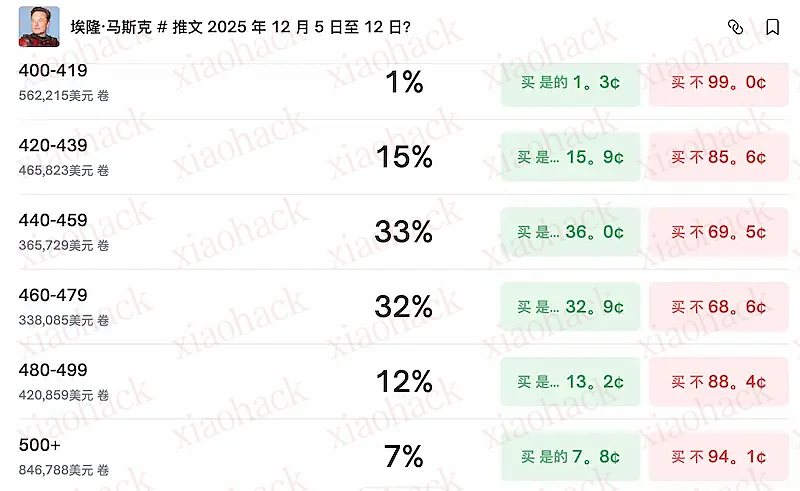
上图预测的是,2025年12月5日至12日期间,马斯克会发多少条推文。
可以看到,概率最高的情况是440条~450条,概率33%,概率最低的情况是400条~419条,概率1%。
正是因为对于几乎任何问题,它都有实时的详细预测,美国人现在已经不怎么看民调了,改成看这种预测网站了。因为民调的抽样方法和样本大小,总是有局限的,反而是预测网站更反映市场的真实看法。
你可能会问,这些预测结果怎么产生?如何确保准确?
答案很简单,结果来自于用户的下注。
你看好哪一种情况,就可以对它下注。看好的人多,这种情况对应的概率就会上升,反之下降。
实质上,它的每一个预测都是一支股票,股价就是它的概率,1%的概率就是股价0.01元,100%的概率就是股价1元。
举例来说,某种情况的当前概率是2%,那么相当于0.02元。你看好这种情况,假定就花了100元买入。
结果,正如你的预测,它变成了现实,概率上升为100%,价格就变成了1元,相比你的买入价,整整上涨了50倍。于是,你投入的100元就变成了5000元。
反之,你预测错了,这个结果没有实现,概率变为0%,也就是0元,你投入的100元将一分都收不回来。
最近,美国的一条热门新闻就是,一个男子在 PolyMarket 上,对一个2%的小概率事件投入3000美元。结果,预测准确,他收回了12.5万美元。

为了方便世界各地的人参与,也是为了保证匿名,这种预测网站都采用稳定币交易。
所以,它的本质就是一个巨大的彩票市场,允许用户买卖自己最感兴趣、最熟悉的事件,这是它快速流行起来的根本原因。参与的人多了以后,反过来提高了预测的准确性。
我觉得,它的前景不可限量,一定会火爆的井喷式发展,传统彩票可能会被它彻底淘汰。
它把任何不确定的事情,都变成了彩票,实时量化了每一种可能性的概率,并且提供了金钱翻倍的途径。这一方面很有参考价值,可以用来判断未来情况,另一方面也非常有娱乐性和刺激性。
国产 Nano Banana Pro 的图片幻灯片生成
上个月,谷歌发布了新一代图像编辑模型 Nano Banana Pro(其实就是 Gemini 3 Pro 的图像分支)。
有一个功能引起了轰动:无论多么枯燥的文字,都能变成有趣的图片,从"读文"变成"读图"。
我当时就想,国产模型一定会马上跟进。
果然,昨天打开秘塔 AI,就看到他们发了这个功能,完全对标 Nano Banana Pro 以及 NotebookLM,而且还加入了自己的特色----讲解。
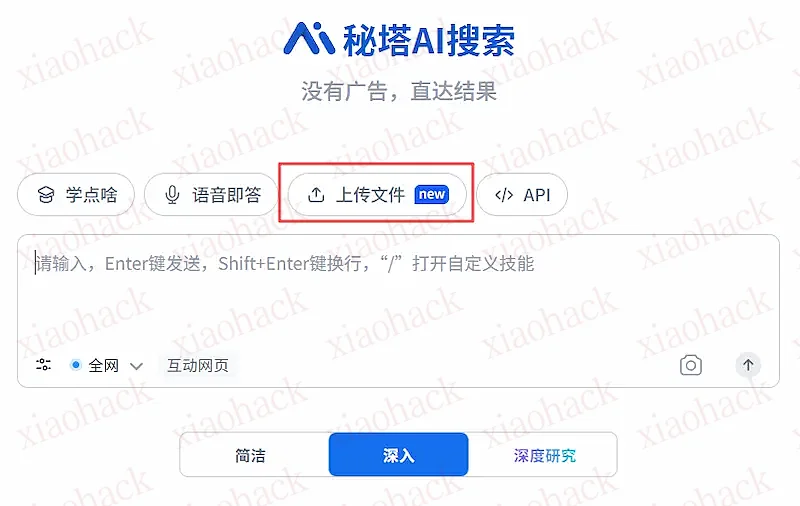
你点击"上传文件"(上图),上传各种资料(可以上传多篇),它就会自动创建一个知识库,输出内容的 AI 总结。这时,还会显示一个"给我讲讲"按钮。

上图是我写的一篇 JS 语法点 Promise 的教程,点击"给我讲讲"就会生成图片幻灯片 + 讲解。

大家可以去它们的官网 metaso.cn (手机 App 同名)试试看,这个功能挺好玩的,操作零门槛,关键是它免费(有赠送的积分)。
除了上传文件,你也可以直接搜索某个主题,再点击下方的"生成幻灯片"按钮。这时就会有"图片幻灯片"选项,并有20多种风格可选,还支持自定义。

科技动态
1、步行环游世界
上个世纪90年代的一天,一个英国青年在酒吧里随口说,他可以从南美洲最南端一路走到英国。他的朋友都不信。
他就跟朋友打赌,他能做到。1998年,他正式从智利最南端开始步行,那一年他29岁。

27年过去了,他已经56岁了,依然在路上。
好消息是,他已经接近行程的尾段,预计将于2026年9月到达终点英国。

下面就是他的路线图,从南美洲最南端到北美洲最北端,再到亚洲和欧洲,最后是英国。

整个行程中,他只能步行或者游泳,不能使用任何交通工具。最难的一段就是北美洲与俄罗斯之间的白令海峡,为了不坐船,他是在冬天从海冰上爬过去的。

这27年中,他也不是每天都在走,有时因为各种原因,会离开一段日子,然后再回来接着走。


他说,依靠个人的力量不可能完成这样的行程,留不开家人的支持、陌生人的友善,以及赞助商的帮助。
至于是什么力量支撑他坚持走了近30年?他说:"你需要看看真实的世界,以及生活在其中的人们,这将是你所能接受的最好的教育之一。"

2、六臂机器人
美的公司展示一个六臂机器人,将用于无锡工厂的生产线。

它可以六只手同时执行三项任务。那样的话,一个机器人就相当于三个工人了。

3、手摇洗衣机
一位前戴森公司的工程师,为不发达地区发明了一种手摇洗衣机。

据介绍,这种洗衣机不需要电,只要手摇几分钟,就能洗净5公斤衣物,并且节省一半的水。

如果它真的有效,我有一个建议,就是把手摇改成脚踏车,只要踩5分钟踏板,就能洗一筒衣服。
文章
1、程序员为自己的工具命名时的彻底迷失(英文)

本文批评很多程序员为软件起名时,尽起一些烂七八糟的名字,根本看不出软件的用途,建议软件名称应该跟用途有相关性。
2、解读斯诺登文件(英文)

这篇文章详细分析了2013年斯诺登泄漏的文件,文章第一部分就是分析对北方工业公司的情报收集,美国的监控令人叹为观止。
3、从文本到词元(英文)

一篇科普文章,通俗地介绍搜索引擎如何将查询的文本转换成标准化的词元(token)。
4、大模型构建 HTML 工具的实用方法(英文)
著名程序员 Simon Willison 的长文,总结他使用大模型生成网页应用的经验。
5、GraphQL 蜜月期已结束(英文)

作者认为,GraphQL 解决的问题远比人们想象的小众,而且可以通过其他方式解决,这项技术最终往往弊大于利。
6、git add -p 的解释(英文)
本文介绍 git add -p 命令。它会显示一个互动界面,让用户逐个确认每个文件的变动,是否要加入暂存区。
工具
1、Cosmic

上周,Cosmic 1.0版正式发布了。它是一个全新的 Linux 桌面,美观且功能强大,为用户提供了 Gnome 和 KDE 之外的另一个选择。
2、Keyden
macOS 菜单栏的开源 TOTP 双因素认证器,密钥加密存储在 macOS Keychain。(@tasselx 投稿)
3、WeMD
开源的 Markdown 微信公众号编辑器。(@tenngoxars 投稿)
4、starling-speak

文本朗读网站,支持多种语言,带有录音功能。(@Keldon-Pro 投稿)
5、shift
一个基于 WebAssembly 的在线代码编辑器,支持直接在网页运行 Python、Lua、Ruby 等语言。(@hubenchang0515 投稿)
6、EasyImg

基于 Nuxt 4 构建的个人图床,丰富的后台配置。(@chaos-zhu 投稿)
7、Go-WXPush

Go 语言开发的微信消息推送服务,提供了一个简单的 API 消息推送接口。代码开源,每天10万次推送额度,个人用不完。(@hezhizheng 投稿)
8、ZeroLaunch-rs

Windows 应用启动器,拼音模糊匹配,基于 Rust + Tauri + Vue.js。(@ghost-him 投稿)
9、MrRSS
跨平台的开源桌面 RSS 阅读器,支持自动翻译、自动总结、新订阅源发现。(@ch3ny4ng 投稿)
10、PVE Touch

为移动设备优化的 Proxmox VE 管理界面,方便通过手机管理虚拟机。(@hanxi 投稿)
AI 相关
1、Disco

谷歌实验室推出的实验性 AI 浏览器,完全跳过网页搜索,目前需要排队等待名额。
2、Flowers

开源的浏览器 AI 助手插件,提供网页翻译、问答、笔记等功能。(@snailfrying 投稿)
3、DeepAudit
开源的代码审计平台,通过智能体实现漏洞挖掘和自动化沙箱 PoC 验证,支持 ollama 私有部署模型,代码可不出内网。(@lintsinghua 投稿)
资源
1、生命的尺寸

这个网站用图形展示各种生命体的大小比较,从 DNA 一直到蓝鲸。
2、写一个你自己的 C 语言编译器(Build Your Own Lisp)

一本面向初学者的免费英文电子书,介绍怎么用 C 语言写编译器,以 Lisp 语言的编译器为例。
3、A Soft Murmur
一个背景音网站,可以开关不同的音效,并调节它们的音量。
图片
1、13个圆画出动物
一个艺术家使用13个圆,画出各种动物。
猫头鹰

兔子

猴子

文摘
1、Claude Opus 4.5 是第一款让我真正担心自己工作会丢掉的大模型
Claude Opus 4.5 真是完全不同于其他模型。还没用过的人根本无法想象未来两三年会发生什么,明年可能就是最终的转折点。
我不知道接下来该如何适应。当然,我可以整天看着 Opus 帮我工作,偶尔出点小问题再干预一下,但再过一段日子连这些都不需要了呢?
编码问题基本上已经解决了,接下来像系统设计、安全之类的问题也会迎刃而解。我估计再过两三个版本,80%的技术人员就基本没用了。当然,公司还需要一些时间来适应,但他们肯定会想方设法尽快摆脱我们。
虽然我很喜欢 AI 这项技术,但一想到这一切最终会走向何方,我就感到难过。
2、为什么学习物理学
(本文摘自理查德·费曼于1963年6月在里约热内卢举行的美洲物理教育会议上发表的演讲。费曼是加州理工学院理论物理学教授。)
我们应该教授物理学,这有五个原因。
(1)物理是一门基础科学,应用于工程学、化学和生物学等各种技术领域。
物理是研究自然界的科学,或者说是认识自然界的科学,它告诉我们事物是如何运作的,以及人类在当前和未来的技术中发明的各种设备是如何工作的。因此,懂物理的人应对本行业出现的技术问题会很有用。
(2)物理教会你如何动手做事情。它教授许多操纵事物的技巧,以及测量和计算技巧,这些技巧的应用范围比特定研究领域要广泛得多。
(3)物理作为一门科学,对许多人来说,是一种极大的乐趣。
科学教育培养出来的科学家,不仅为工业发展和知识发展做出贡献,同时也参与了我们这个时代的伟大冒险,从中获得巨大的乐趣。
即使一个人没有成为一名专业科学家,研究自然也是为了欣赏自然的奇妙和美丽。这种对自然的了解也给人一种稳定和现实的感觉,并驱散了许多恐惧和迷信。
(4)物理教会人们如何认识事物,帮助你质疑很多事情。质疑和自由思想的价值,不仅对科学发展,而且对其他各个领域,都显而易见。
科学教导我们如何认识事物、什么是未知事物、事物被认识到什么程度、如何处理怀疑和不确定性、证据规则是什么、如何思考事物以便做出判断、如何区分真理与欺诈。这些无疑是教授科学,特别是教授物理的重要收获。
(5)在学习科学的过程中,你会学会如何试错,培养发明创造和自由探索的精神,这种精神的价值远远超出了科学本身。
人们会学会问自己:"有没有更好的方法 ?"我们必须想出一些新的技巧或方法,以改进这项技术。这种想法是许多思想、发明创造以及各种人类进步的源泉。
言论
1、
为什么我们有两个鼻孔,而不是一个大洞?
因为肺部持续需要空气,两个鼻孔可以交替工作,让鼻子的一侧得到休息。
-- 美国《大众科学》
2、
报社招我去当撰稿人,我以为是去写稿,结果却是以极低的薪水让我编辑 AI 生成的文案草稿,理由是"大部分工作已经完成了"。
这让我深受打击,我曾经觉得自己很有价值,受人重视,对未来充满希望,渴望拥有辉煌的职业生涯,现在却只能修改 AI 生成的文字。
-- 一位自由撰稿人
3、
SaaS 行业将会萎缩,尤其是那些功能简单的 SaaS,因为企业现在可以用 AI 快速生成内部服务。
-- 《AI 正在蚕食 SaaS》
4、
我发现,中文不喜欢直接说 True,更倾向说 !False。比如,英文说"很好",中文说"不坏",英文说"对的",中文说"没错",英文说"正常",中文说"没问题"。
中文更喜欢双重否定"否定词+否定词",这种表达方式增加了模糊性(含糊其辞)和灵活性(模棱两可),创造了回旋余地,避免了肯定答复导致的态度明确、归类迅速、立场鲜明。
-- 《为什么中文拒绝说 true》
往年回顾
你可能是一个 NPC(#331)
新基建的政策选择(#281)
互联网公司需要多少员工?(#231)
移动支付应该怎么设计?(#181)
(完)